Manuskrypt HTML
W00 - Wstęp i organizacja
Materiały do zajęć dostępne są na platformie GitHub: https://github.com/RafLew84/ProgUM.
Zasady zaliczenia
Warunkiem uzyskania pozytywnej oceny z części laboratoryjnej jest spełnienie następujących kryteriów:
- Przewidzianych jest 6 list zadań.
- Z każdej listy wystawiana jest osobna ocena.
- Dopuszczalne jest nieoddanie lub niezaliczenie jednej listy. Za tą listę student otrzymuje ocenę 2.0.
- Każda lista ma określony termin zwrotu i punktację.
- Za każdy tydzień opóźnienia ocena obniżana jest o 1.
- Listy oddawane są podczas zajęć laboratoryjnych.
- Do list zadań dołączana jest lista pytań, na które student jest zobowiązany odpowiedzieć ustnie podczas zajęć laboratoryjnych. Z każdej listy pytań (o ile istnieje) losowane są pytania. Liczba pytań jest zależna od liczby punktów na liście. Przykładowo, jeśli lista ma 10 punktów, a z zadań praktycznych student może otrzymać 5 punktów, losowane jest 5 pytań. Pytania dotyczą zarówno teorii jak i praktyki.
- Student jest zobowiązany do przekazania kodu źródłowego w repozytorium GitHub. Link do repozytorium należy podać jako odpowiedź na zadanie na platformie MS Teams. Brak linku do repozytorium z rozwiązaniami zadań jest równoznaczny z brakiem zaliczenia przedmiotu.
- Ocena końcowa jest średnią arytmetyczną ocen z list
- Ocena 3,0 – średnia 3,0 – 3,24
- Ocena 3,5 – średnia 3,25 – 3,74
- Ocena 4,0 – średnia 3,75 – 4,24
- Ocena 4,5 – średnia 4,25 – 4,74
- Ocena 5,0 – średnia 4,75 – 5,0
- Dopuszczalne są trzy nieobecności nieusprawiedliwione na zajęciach laboratoryjnych.
- Oceny i punktacja jest dostępna na bieżąco w pliku na platformie MS Teams
Treści programowe
Plan wykładu obejmuje następujące zagadnienia:
- Wstęp: Typy danych, Wyrażenia, Instrukcje, Pętle
- Garbage Collection
- Funkcje
- Kolekcje
- Klasy, Obiekty i Interfejsy
- Inicjalizacja i Delegacja
- Fundamenty Aplikacji Android: Aktywność, Cykl Życia
- Jetpack Compose: Podstawy tworzenia UI, Kompozycja, Rekompozycja, Stan
- Elementy struktury UI (Scaffold) i obsługa kolekcji w UI
- Nawigacja (Compose Navigation, Tab Navigation, Drawer)
- Wzorce projektowe
- Widgety i ich cykl życia
Wprowadzenie do języka Kotlin
Kotlin to statycznie typowany język programowania działający na wirtualnej maszynie Javy (JVM), opracowany przez firmę JetBrains. Został zaprojektowany jako w pełni interoperacyjny z Javą, co pozwala na płynne łączenie obu języków w ramach jednego projektu. Od 2019 roku Kotlin jest rekomendowanym językiem do tworzenia aplikacji na platformę Android.
Do najważniejszych cech języka należą:
- Bezpieczeństwo (Null Safety): Wbudowany mechanizm ochrony przed
Null-Pointer-Exceptionpoprzez rozróżnienie na poziomie systemu typów referencji, które mogą przechowywaćnull, od tych, które nie mogą. - Zwięzłość: Składnia języka znacząco redukuje ilość kodu nadmiarowego (boilerplate) dzięki takim konstrukcjom jak data classes, properties czy automatyczna inferencja typów.
- Wieloplatformowość: Poza JVM, Kotlin może być kompilowany do JavaScriptu oraz kodu natywnego (Kotlin/Native), co umożliwia współdzielenie logiki biznesowej między różnymi platformami (iOS, Android, Desktop, Web).
- Wsparcie dla paradygmatów: Język oferuje zaawansowane wsparcie dla programowania funkcyjnego, mechanizm korutyn do obsługi asynchroniczności oraz funkcje rozszerzające (extension functions), które pozwalają na dodawanie nowych funkcjonalności do istniejących klas bez konieczności dziedziczenia.
W tym rozdziale zbudujemy solidne fundamenty, na których oprzemy całą dalszą naukę. Nie będziemy tylko uczyć się składni; spróbujemy zrozumieć dlaczego pewne mechanizmy działają tak, a nie inaczej, i jakie problemy rozwiązują.
System typów
W Javie, którą zapewne znacie, istnieje podział na typy prymitywne (int, double, boolean) i typy referencyjne (obiekty). Kotlin upraszcza ten obraz, traktując wszystko jako obiekt (przynajmniej z perspektywy programisty).
Na szczycie hierarchii typów w Kotlinie stoi Any. To odpowiednik java.lang.Object, ale z jedną kluczową różnicą: Any nie jest nullowalne (o czym powiemy przy okazji Null Safety). Każda klasa, którą stworzymy, domyślnie dziedziczy po Any.
val liczba: Any = 42
val tekst: Any = "Hello"W językach takich jak C++ czy Java, funkcje, które nie zwracają wyniku, oznacza się słowem kluczowym void. W Kotlinie, w duchu spójności systemu typów, takie funkcje zwracają specjalny obiekt typu Unit.
Można myśleć o Unit jak o pustej paczce. Funkcja zawsze wysyła paczkę (zwraca wynik), tylko w tym przypadku paczka nie zawiera żadnych użytecznych informacji. Unit jest singletonem – istnieje tylko jedna taka pusta paczka w całym systemie.
fun przywitanie(): Unit {
println("Cześć!")
// return Unit - jest tu niejawnie dodane przez kompilator
}Kotlin wprowadza bardzo ciekawy typ: Nothing. Jest to typ, który nie ma instancji. Oznacza to, że nie da się stworzyć zmiennej typu Nothing. Po co więc taki typ?
Służy on do oznaczenia sytuacji, w której funkcja nigdy nie zakończy się poprawnie (nie zwróci sterowania). Przykłady to:
- Funkcja rzucająca wyjątek (wyjątek przerywa normalny przepływ).
- Pętla nieskończona.
fun blad(message: String): Nothing {
throw IllegalArgumentException(message)
}Typ Nothing jest tzw. bottom type - jest podtypem każdego innego typu. Dzięki temu możemy go użyć np. w instrukcji Elvis operator:
val name: String = person.name ?: throw Exception("Brak imienia")Kompilator wie, że prawa strona (Nothing) pasuje do lewej (String), ponieważ Nothing pasuje wszędzie (bo i tak sterowanie tam nie dotrze).
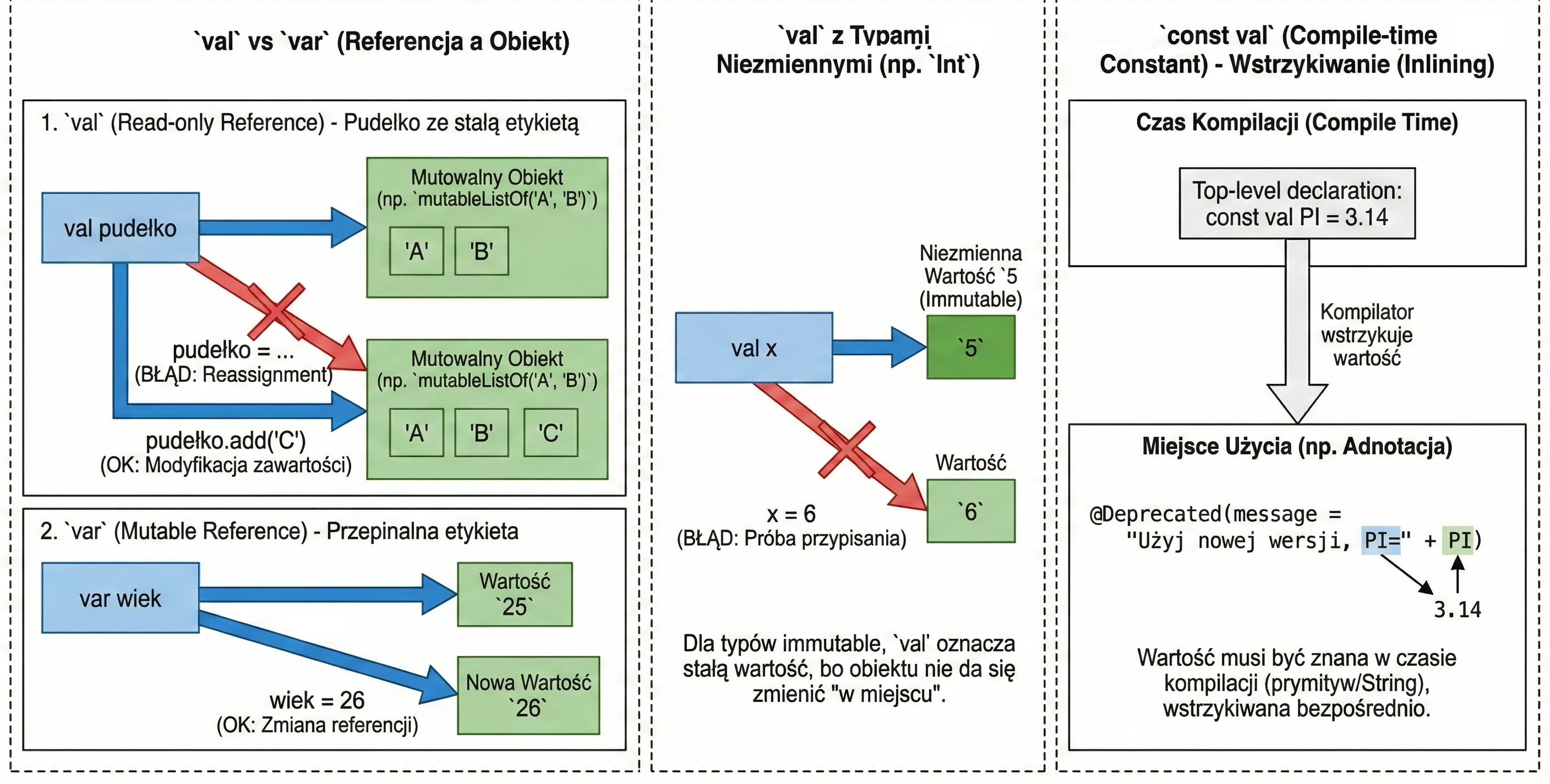
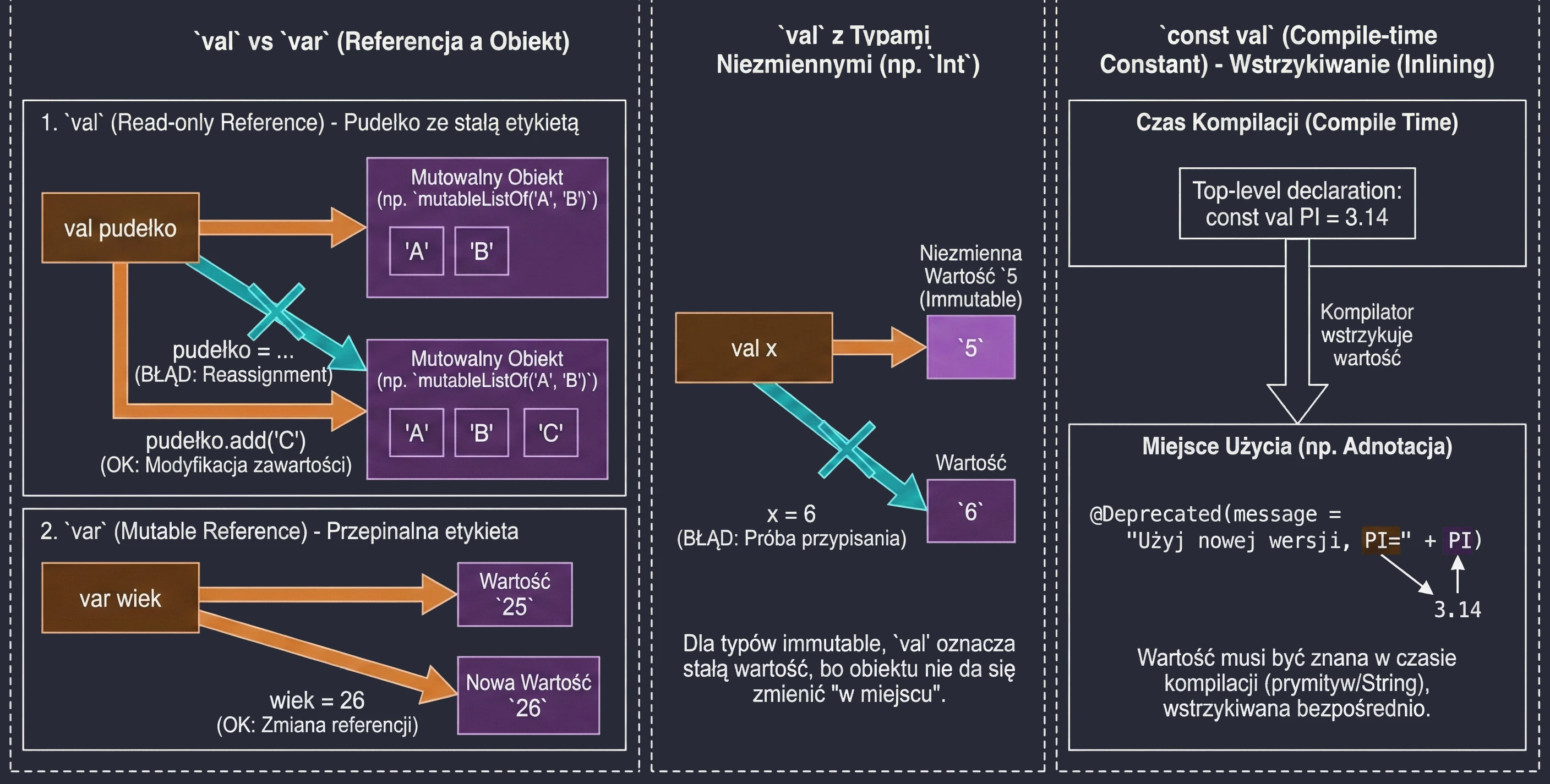
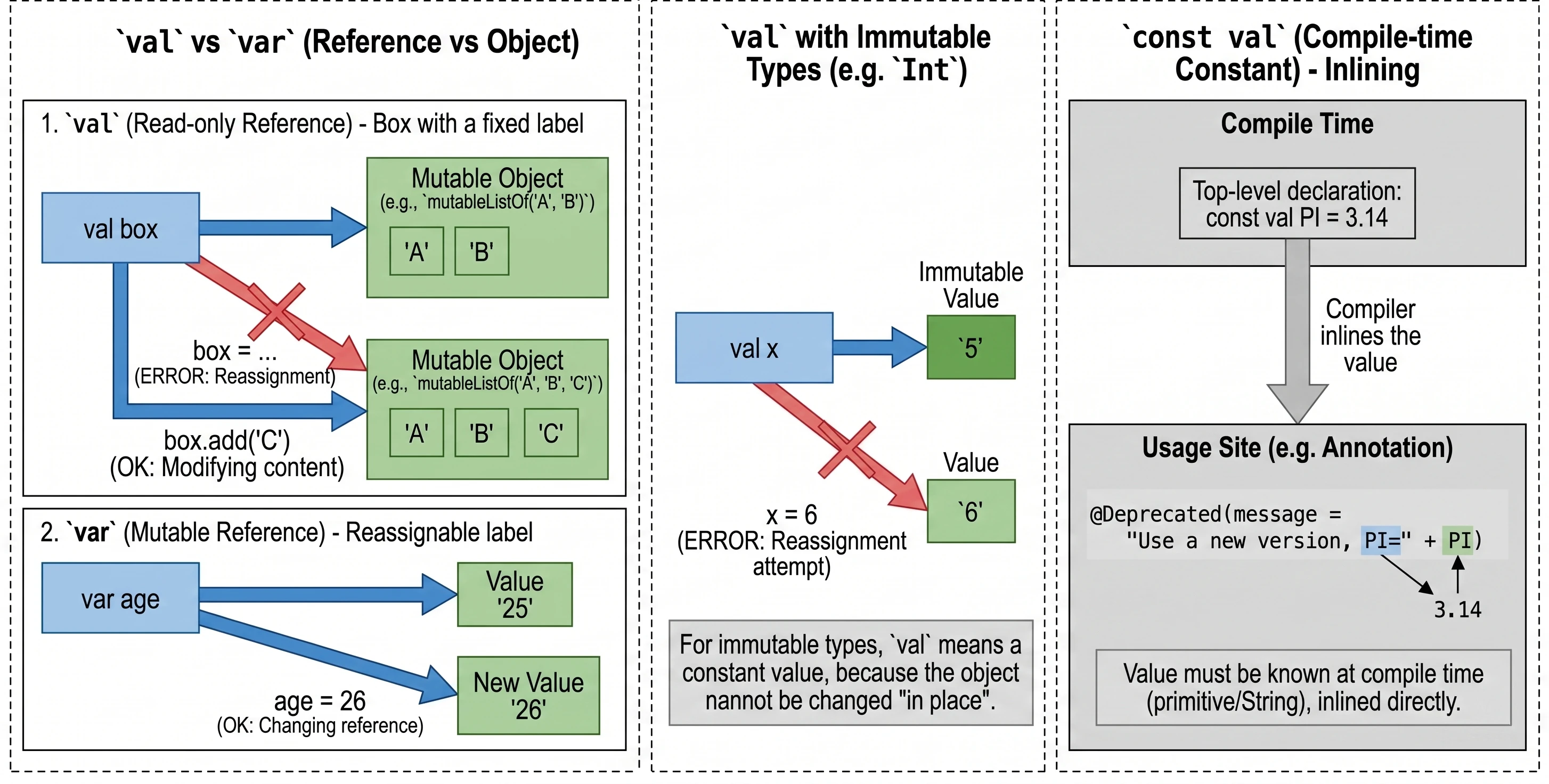
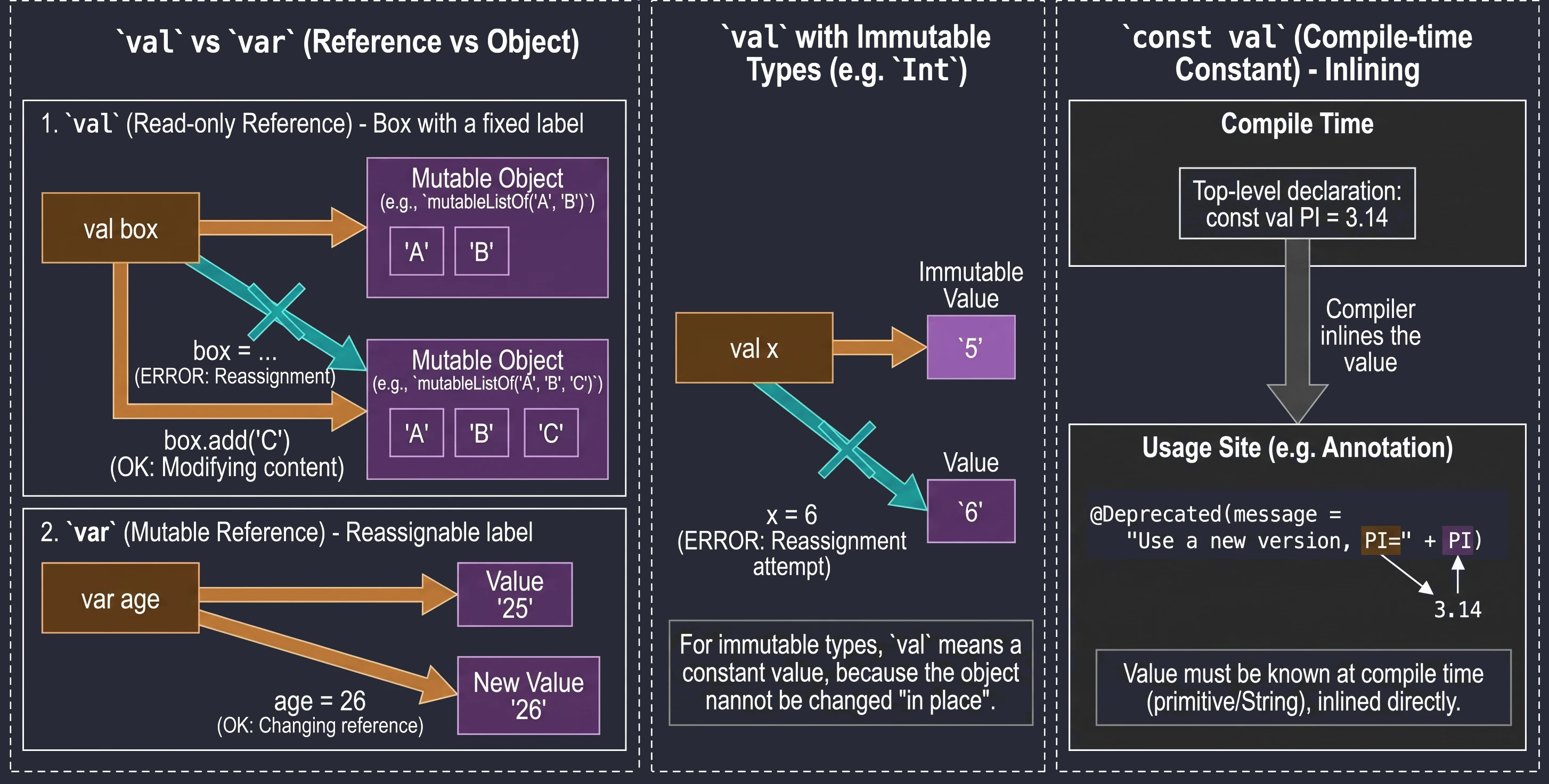
Zmienne: val vs var vs const val
To jedna z najważniejszych decyzji projektowych, którą podejmujemy pisząc kod.
val(od value) – deklaruje referencję tylko do odczytu (read-only).var(od variable) – deklaruje zmienną mutowalną.
val imie = "Anna"
// imie = "Marek" // Błąd: Val cannot be reassignedvar wiek = 25
wiek = 26 // OKUWAGA!!! val gwarantuje niezmienność referencji, a nie obiektu. Wyobraź sobie pudełko z etykietą.
val pudełko: Nie możesz odkleić etykiety i przykleić jej na inne pudełko. Ale możesz otworzyć pudełko i zmienić jego zawartość (np. dodać element do listy wewnątrz).
val lista = mutableListOf("A", "B")
// lista = mutableListOf("C") // BŁĄD! Nie można zmienić referencji val
lista.add("C") // OK! Stan obiektu się zmieniaW przypadku typów takich jak Int, które same w sobie są niezmienne (immutable), val sprawia, że wartość jest definitywnie stała, ponieważ nie możemy zmienić samej liczby w miejscu, a jedynie spróbować przypisać nową:
val x = 5
// x = 6 // BŁĄD! Próba ponownego przypisania (reassignment)
var y = 5
y = 6 // OK! Zmienna 'y' wskazuje teraz na nową wartośćZwykłe val jest wyliczane w czasie działania programu (runtime). Gdy potrzebujemy stałej znanej już w czasie kompilacji (compile-time constant), np. do adnotacji, używamy wtedy const val. Ograniczenia:
- Umiejscowienie: Musi być zadeklarowane na najwyższym poziomie pliku (top-level) lub jako członek
object(w tymcompanion object). Nie może być zmienną lokalną. - Typy danych: Dopuszczalne są wyłącznie typy prymitywne (np.
Int,Double,Boolean) oraz typString. - Inicjalizacja: Wartość musi być znana już w trakcie kompilacji. Nie może być wynikiem wywołania funkcji ani posiadać niestandardowego gettera (custom getter).
Kompilator traktuje const val jako stałą, którą wstrzykuje (inline) bezpośrednio w miejsca jej użycia, co jest niezbędne np. przy definiowaniu parametrów adnotacji.
Null Safety
Tony Hoare, twórca referencji null, nazwał to swoim błędem wartym miliard dolarów. W Javie NullPointerException (NPE) to chleb powszedni – błąd ten występuje w momencie, gdy program próbuje odwołać się do metody lub pola obiektu za pomocą referencji, która w rzeczywistości nie wskazuje na żadne miejsce w pamięci (ma wartość null). Kotlin rozwiązuje ten problem na poziomie systemu typów, wprowadzając rygorystyczne rozróżnienie między referencjami, które mogą być null, a tymi, które muszą zawsze wskazywać na konkretny obiekt.
Przykładowo, zmienna typu String, Int, Boolean nigdy nie może przechowywać null. Jeśli chcesz, aby mogła, musisz użyć typu String?, Int?, Boolean? (zmienna nullowalna).
Kiedy mamy zmienną nullowalną (np. text: String?), kompilator nie pozwoli nam bezpośrednio wywołać metody np. text.length. Musimy obsłużyć potencjalny null:
1. Bezpieczne wywołanie (?.): Jeśli nie null, to wykonaj, w przeciwnym razie zwróć null.
val length: Int? = text?.length2. Operator Elvis (?:): Jeśli lewa strona to null, użyj prawej.
val length: Int = text?.length ?: 03. Operator !! (Not-null assertion): Wiem co robię, to na pewno nie jest null. Jeśli się mylisz -> NPE.
Instrukcje sterujące
W Kotlinie wiele konstrukcji, które w innych językach są instrukcjami (statements), tutaj jest wyrażeniami (expressions) – czyli zwraca wartość.
W Kotlinie if jest wyrażeniem (expression), co oznacza, że zwraca wartość. Z tego powodu w języku tym nie znajdziemy tradycyjnego operatora trójargumentowego (condition ? a : b) – jego rolę pełni po prostu if-else zapisany w jednej linii.
val max = if (a > b) a else bJeśli gałęzie if lub else zawierają bloki kodu w nawiasach klamrowych, wartością zwracaną jest ostatnia linia danego bloku.
val stanSilnika = if (temperatura > 100) {
println("Ostrzeżenie: Przegrzanie!")
"ALARM" // To zostanie przypisane do zmiennej
} else {
"OK"
}Ważną zasadą jest to, że używając if jako wyrażenia (czyli przypisując jego wynik do zmiennej lub zwracając go z funkcji), musimy zawsze dostarczyć gałąź else. Kompilator musi mieć pewność, że w każdej możliwej sytuacji zmienna otrzyma jakąś wartość.
when zastępuje tradycyjny switch, oferując znacznie większe możliwości. Może być używany jako instrukcja (statement) lub jako wyrażenie (expression).
// Jako wyrażenie - musi być wyczerpujące (zazwyczaj wymaga else)
val opis = when (obj) {
1 -> "Jeden" // Pojedyncza wartość
2, 3 -> "Dwa lub trzy" // Kilka wartości (OR)
in 4..10 -> "Liczba w zakresie 4-10" // Sprawdzenie zakresu
is String -> "Tekst o długości ${obj.length}" // Sprawdzenie typu + Smart Cast
!is Int -> "To nie jest liczba całkowita" // Zaprzeczenie typu
else -> "Coś innego" // Przypadek domyślny
}Jedną z cech when jest możliwość użycia go bez argumentu. W takim przypadku każda gałąź musi zawierać wyrażenie logiczne (Boolean). Działa to jak czytelniejszy zamiennik długiego łańcucha if-else if.
when {
x > y -> println("x jest większe")
x < y -> println("y jest większe")
else -> println("Są równe")
}Warto zauważyć, że dzięki mechanizmowi Smart Casts, po sprawdzeniu typu za pomocą is String, kompilator pozwala nam używać zmiennej tak, jakby była typu String (np. wywołać .length) bez ręcznego rzutowania.
Pętla for w Kotlinie służy do iterowania po wszystkim, co udostępnia iterator (posiada funkcję iterator()). W przeciwieństwie do tradycyjnej pętli for znanej z Javy czy C++, tutaj zawsze używamy składni in.
Najczęściej pętli for używamy wraz z zakresami (Ranges):
// Zakres domknięty (włącznie z 5)
for (i in 1..5) print(i) // 12345
// Zakres jednostronnie otwarty (bez 5)
for (i in 1 until 5) print(i) // 1234
// Iteracja wstecz
for (i in 5 downTo 1) print(i) // 54321
// Iteracja z określonym krokiem
for (i in 1..10 step 2) print(i) // 13579Kotlin pozwala również na bardzo wygodną iterację po kolekcjach oraz mapach, wykorzystując mechanizm destrukturyzacji:
val lista = listOf("Kotlin", "Java", "Swift")
for (jezyk in lista) {
println("Język: $jezyk")
}
// Iteracja z indeksem
for ((index, value) in lista.withIndex()) {
println("Pozycja $index to $value")
}
// Iteracja po mapie
val map = mapOf(1 to "Jeden", 2 to "Dwa")
for ((klucz, wartosc) in map) {
println("$klucz -> $wartosc")
}Oprócz pętli for, dostępne są również standardowe pętle while oraz do-while, których działanie jest zgodne z oczekiwaniami programistów innych języków imperatywnych.
// Pętla while - sprawdza warunek przed wykonaniem
var x = 3
while (x > 0) {
println("Odliczanie: $x")
x--
}
// Pętla do-while - wykonuje się przynajmniej raz
var y = 0
do {
println("Wykonam się przynajmniej raz, nawet jeśli warunek jest fałszywy")
} while (y > 0)Warto zauważyć, że w pętli do-while zmienne zadeklarowane wewnątrz bloku do są widoczne w wyrażeniu warunkowym while.
Programując w językach wysokiego poziomu, takich jak Kotlin czy Java, nie myślimy o tym, co dzieje się pod maską. Mamy luksus automatycznego zarządzania pamięcią – tworzymy obiekty, używamy ich, a potem po prostu o nich zapominamy. Maszyna Wirtualna (JVM) lub środowisko uruchomieniowe Androida (ART) zajmuje się resztą.
Nieświadomość kosztów, jakie niosą ze sobą nasze decyzje projektowe, prowadzi do aplikacji, które działają wolno, zacinają się (tzw. jank) i zużywają baterię w zastraszającym tempie. Posiadanie intuicji o sposobie funkcjonowania pamięci, pozwoli nam pisać kod nie tylko poprawny, ale i wydajny.
Typy danych i organizacja pamięci
Zanim przejdziemy do sprzątania (GC), musimy zrozumieć, jak bałagan powstaje – czyli jak dane są układane w pamięci.
Mimo że w Kotlinie wszystko jest obiektem, pod spodem (na poziomie JVM/ART) wciąż operujemy na typach prostych, które mają ściśle określone rozmiary. Warto mieć intuicję, ile ważą nasze dane:
- 1 bajt:
Boolean(teoretycznie 1 bit, ale adresowalny jako bajt),Byte. - 2 bajty:
Short,Char(UTF-16). - 4 bajty:
Int,Float. - 8 bajtów:
Long,Double.
Dlaczego o tym wspominamy, skoro w Kotlinie nie mamy jawnego dostępu do typów prymitywnych?
W przeciwieństwie do Javy, gdzie istnieje wyraźny podział na int (prymityw) i Integer (obiekt), Kotlin oferuje jednolitą składnię opartą na klasach. Pod maską jednak kompilator wykonuje istotną optymalizację: wszędzie tam, gdzie to możliwe, zamienia nasze obiekty na surowe typy prymitywne w bajtkodzie.
Kiedy dochodzi do kosztownego opakowywania (boxing) w obiekt?
- Typy nullowalne:
Int?musi być obiektem, ponieważ surowy prymityw nie może przyjąć wartościnull. - Generyki: Standardowe kolekcje, takie jak
List<Int>, zawsze przechowują obiekty.
To, czy dana jest reprezentowana jako prymityw, czy jako obiekt, wpływa na jej postać w pamięci: prymityw to wartość zapisana bezpośrednio w miejscu deklaracji, natomiast obiekt to referencja (wskaźnik) do obszaru na stercie, gdzie znajdują się faktyczne dane.
Pamięć operacyjną aplikacji możemy podzielić na dwa główne obszary, które działają w zupełnie inny sposób.
Stos (Stack) to pamięć podręczna dla aktualnie wykonywanych metod. Działa bardzo szybko (LIFO - Last In, First Out).
- Przechowuje zmienne lokalne (typy proste) oraz referencje do obiektów.
- Jest czyszczony automatycznie po wyjściu z funkcji (zdjęciu ramki stosu).
- Alokacja tutaj jest niemal natychmiastowa.
Sterta (Heap) to wielki magazyn na obiekty.
- Tutaj ląduje każdy obiekt utworzony przez
new(w Javie) lub konstruktor (w Kotlinie). - Dostęp jest wolniejszy niż do stosu.
- To tutaj działa Garbage Collector.
Wyobraź sobie, że Stos to tablica korkowa nad twoim biurkiem. Przypinasz tam małe karteczki z notatkami (zmienne lokalne) i nitki (referencje). Nitki prowadzą do wielkiego magazynu w piwnicy – Sterty. Tam leżą właściwe teczki z dokumentami (obiekty). Gdy zdejmujesz karteczkę z tablicy (koniec funkcji), nitka znika. Ale teczka w piwnicy zostaje, dopóki ktoś (GC) nie zauważy, że żadna nitka do niej nie prowadzi.
Zarządzanie pamięcią: Ręczne vs Automatyczne
W językach takich jak C czy C++, programista zarządza życiem i śmiercią obiektów.
malloc()– alokujesz pamięć.free()– musisz ją zwolnić.
Daje to pełną kontrolę, ale rodzi poważne problemy:
- Wycieki pamięci (Memory Leaks): Zapomniałeś zwolnić pamięć? Zostaje zajęta na zawsze (do restartu procesu).
- Dangling Pointers: Zwolniłeś pamięć, ale nadal masz do niej referencję ("wskaźnik donikąd"). Próba użycia kończy się błędem (segmentation fault).
Kotlin (działający na JVM/ART) zdejmuje z nas ten obowiązek. Wprowadza Garbage Collector (GC) – automatycznego sprzątacza.
Garbage Collection
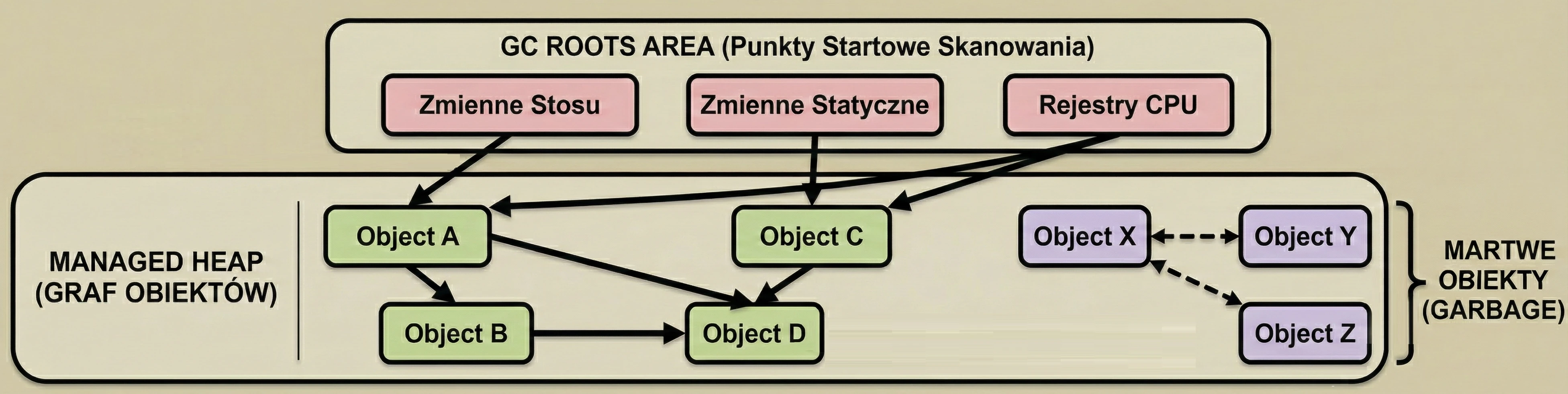
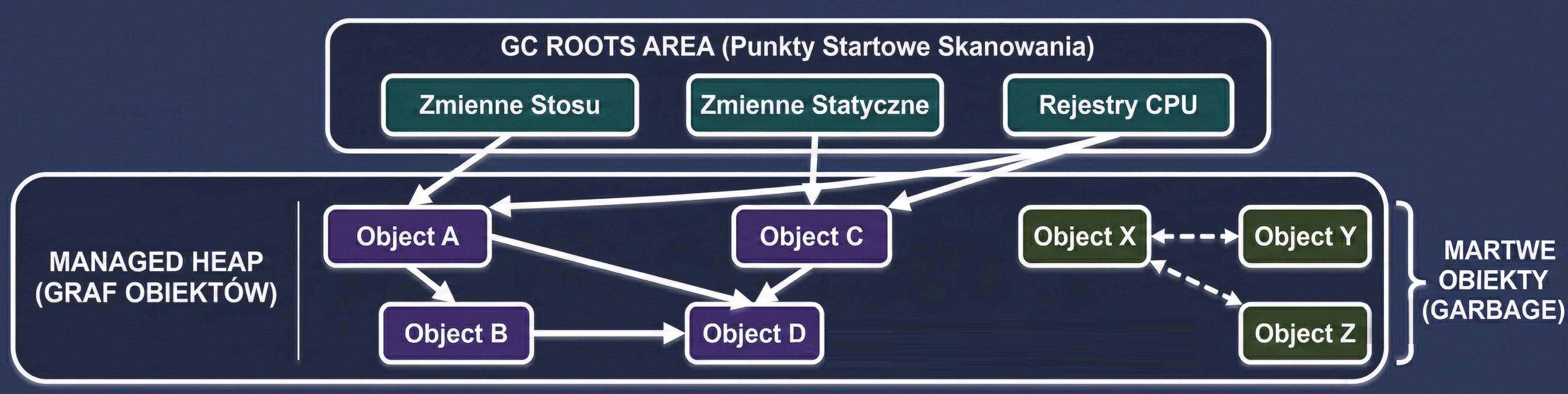
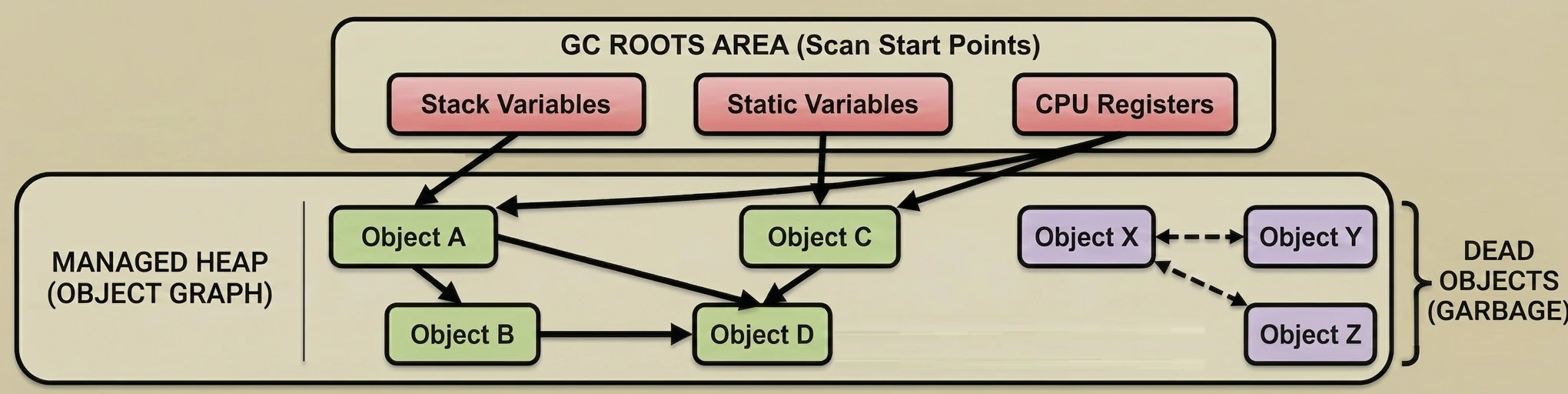
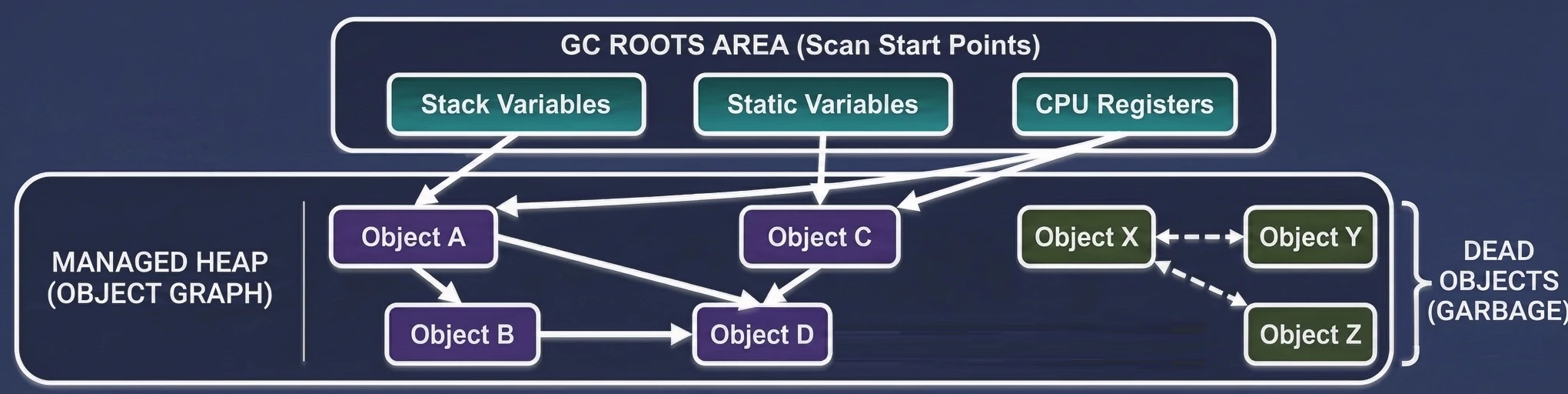
Garbage Collection opiera się na prostym założeniu: Obiekt jest śmieciem, jeśli nie jest osiągalny z żadnego "korzenia" (GC Root).
GC buduje wirtualną mapę powiązań, zwaną grafem obiektów. Każdy nowo utworzony obiekt, do którego przypiszemy referencję, staje się węzłem w tym grafie, a same referencje stanowią krawędzie (połączenia).
Proces ten jest w pełni automatyczny i niewidoczny dla programisty:
- Przy każdym przypisaniu (np.
val user = User()) system odnotowuje nowe połączenie. - Graf rośnie i zmienia się dynamicznie w trakcie działania aplikacji.
- GC okresowo przeszukuje ten graf, zaczynając od punktów startowych, aby sprawdzić, do których wysp pamięci wciąż prowadzi jakaś ścieżka.
Co jest korzeniem, czyli obiektem, który na pewno jest potrzebny?
- Zmienne lokalne na stosie: Wszystko, co jest w aktualnie wykonujących się funkcjach.
- Pola statyczne: Obiekty przypięte do klas (np.
companion object). - Aktywne wątki: Dopóki wątek działa, jego obiekty są żywe.
- Referencje JNI: Obiekty trzymane przez kod natywny (C/C++).
Proces sprzątania można podzielić na trzy fazy (w dużym uproszczeniu):
- Mark (Oznaczanie):
- Sweep (Czyszczenie):
- Compact (Defragmentacja):
GC wstrzymuje działąnie wątków aplikacji (choć nowsze GC robią to współbieżnie). Przechodzi przez cały graf obiektów, zaczynając od GC Roots. Każdy odwiedzony obiekt oznacza jako żywy (Live Object).
GC przegląda stertę. Wszystko, co nie zostało oznaczone w fazie Mark, jest uznawane za śmieci (Dead Objects) i pamięć jest zwalniana.
To kluczowy krok. Po usunięciu śmieci, w pamięci powstają dziury (fragmentacja). GC przesuwa żywe obiekty obok siebie, aby zwolnić duży, ciągły blok pamięci. Dzięki temu alokacja nowych obiektów jest bardzo szybka (wystarczy przesunąć wskaźnik).
Hipoteza Generacyjna (Generational Hypothesis)
Badania nad zachowaniem programów pokazały ciekawą prawidłowość, zwaną Hipotezą Generacyjną:
Większość obiektów umiera młodo.
Obiekty tymczasowe (zmienne w pętlach, iteratory, zdarzenia UI) żyją bardzo krótko. Jeśli obiekt przeżyje ten początkowy okres, prawdopodobnie będzie żył bardzo długo (np. singletony, cache, główne usługi).
Na tej podstawie pamięć sterty podzielono na strefy (Generacje):
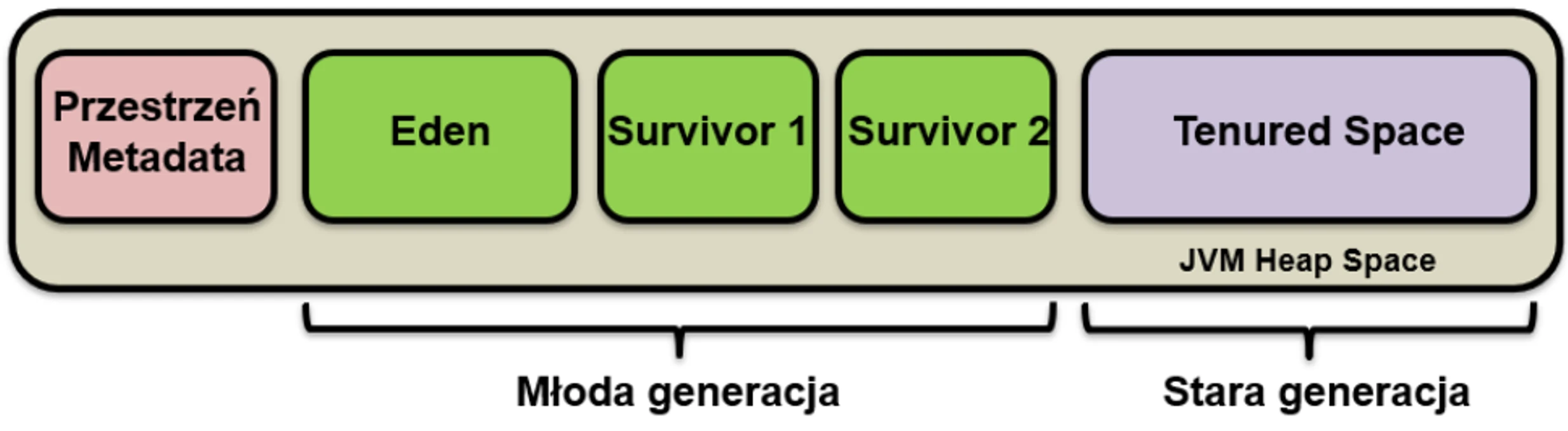
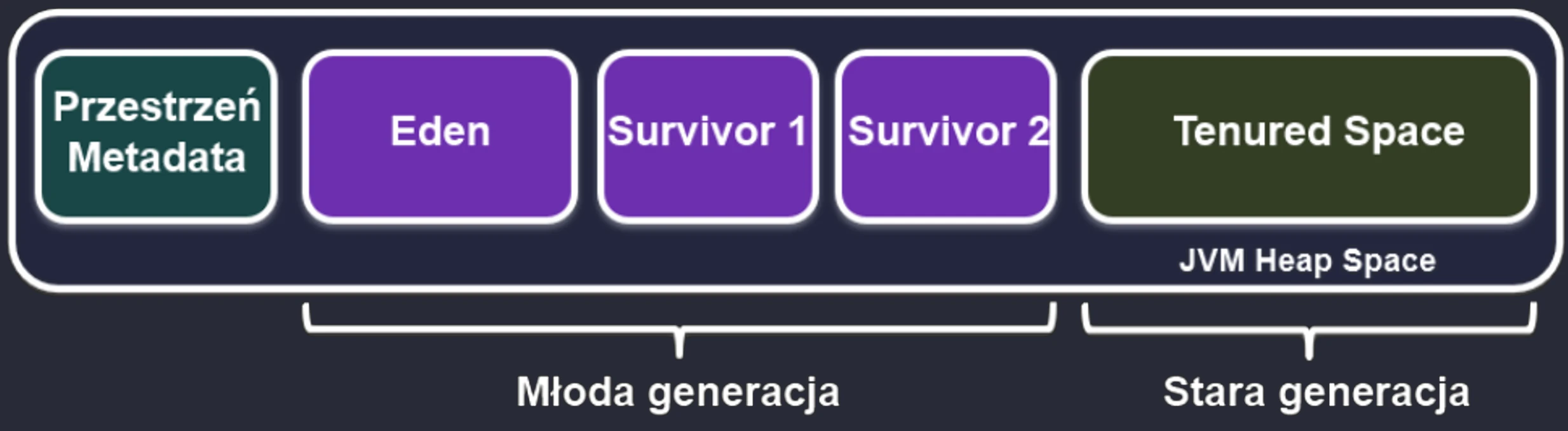
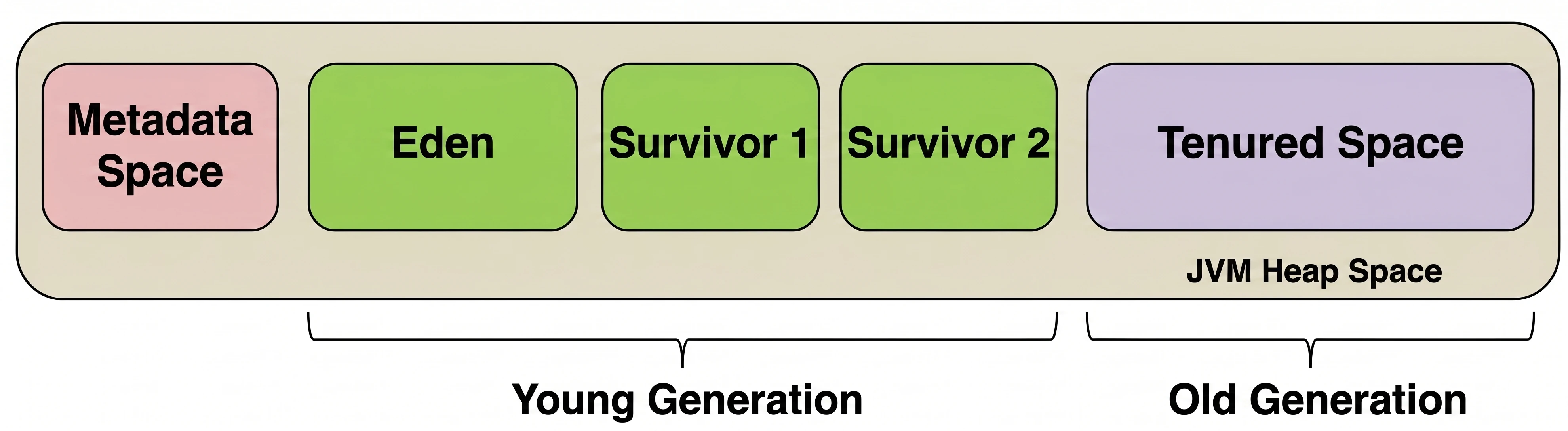
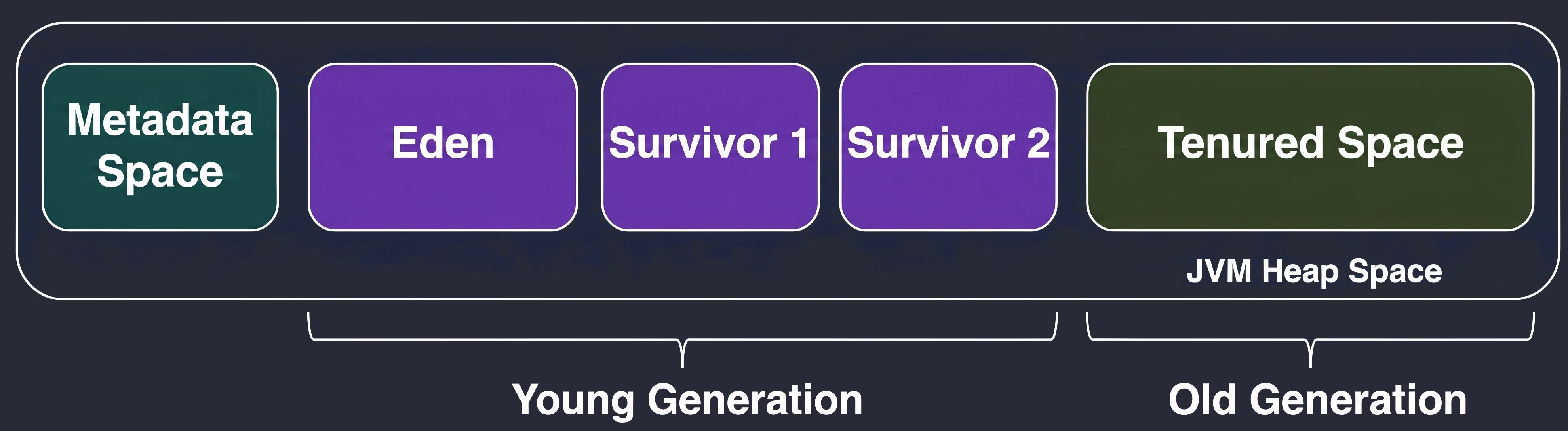
Młoda Generacja
Tu rodzą się wszystkie nowe obiekty. Jest mała i bardzo często czyszczona. Dzieli się na:
- Eden: Miejsce narodzin. Gdy się zapełni, następuje Minor GC.
- Survivor Space (S1 i S2): Dwie bliźniacze przestrzenie dla ocalałych.
Cykl życia w Młodej Generacji:
- Nowe obiekty lądują w Edenie.
- Gdy Eden się zapełni -> Minor GC.
- Żywe obiekty z Edenu i (na przykład) S1 są kopiowane do pustego S2.
- Wiek obiektów (licznik przeżyć) jest zwiększany.
- Eden i S1 są czyszczone do zera (bardzo szybko!).
- W kolejnym cyklu S1 i S2 zamieniają się rolami.
Stara Generacja
Jeśli obiekt przeżyje wystarczająco dużo cykli (np. 15) w Survivor Space, zostaje promowany do Starej Generacji.
- Ta strefa zbiera weteranów.
- Jest czyszczona znacznie rzadziej, ale sprzątanie tutaj (Major GC) jest znacznie bardziej kosztowne i trwa dłużej.
Wnioski
- Unikaj alokacji w pętlach i
onDraw(): Mimo że GC jest szybki, tworzenie tysięcy obiektów w klatce animacji (16 ms) zapcha Eden i wymusi częste pauzy (GC pauses), co użytkownik odczuje jako klatkowanie interfejsu. - Szczelność pamięci (Memory Leaks): GC nie posprząta obiektu, do którego wciąż masz referencję (nawet jeśli już go nie potrzebujesz). Klasyczny błąd na Androidzie: trzymanie referencji do
ActivitylubContextw obiekcie statycznym lub długo żyjącym wątku. To uniemożliwia zwolnienie całego ekranu z pamięci - Wybieraj odpowiednie struktury: Preferuj tablice i
ArrayListnad rozproszonymi strukturami, jeśli zależy ci na wydajności.
Metaspace (Metadata Space)
Przestrzeń Metadata to obszar pamięci JVM przeznaczony na przechowywanie informacji o strukturze uruchamianego kodu, a nie samych danych (obiektów) tworzonych przez programistę.
Co zawiera ta przestrzeń? Przechowywane są tam „przepisy” na klasy, czyli metadane potrzebne maszynie wirtualnej do działania:
- Definicje klas: Nazwy klas, ich rodzice (nadklasy) oraz implementowane interfejsy.
- Definicje metod: Kod bajtowy metod oraz informacje o parametrach.
- Pola: Nazwy i typy pól (zmiennych w klasie).
- Pula stałych (Constant Pool): Referencje do stałych używanych w klasie.
Ważne rozróżnienie: Heap vs Native Memory Na wielu diagramach (w tym powyższym) przestrzeń ta bywa włączana do ramki sterty. Jest to uproszczenie nawiązujące do starszych wersji Javy (przed Java 8), gdzie istniał obszar PermGen będący częścią sterty. W nowszych wersjach:
- Obszar ten nazywa się Metaspace.
- Nie jest już częścią sterty (Heap).
- Znajduje się w Pamięci Natywnej (Native Memory), czyli korzysta bezpośrednio z pamięci RAM, a nie z limitu pamięci przydzielonego dla sterty (
-Xmx).
Gdy aplikacja wczytuje nową klasę, JVM zapisuje informację o jej strukturze właśnie w Metaspace. Jeśli aplikacja wczytuje tysiące klas (np. przy użyciu dużych frameworków), obszar ten rośnie dynamicznie, zajmując dostępną pamięć operacyjną urządzenia.
W Kotlinie funkcje to obywatele pierwszej kategorii (first-class citizens). Oznacza to, że funkcje nie są tylko nazwanymi blokami kodu wewnątrz klas (jak metody np. w Javie). Są to pełnoprawne obiekty, które możemy przekazywać jako parametry, zwracać z innych funkcji i przechowywać w zmiennych.
Fundamenty Funkcji
Definicja funkcji w Kotlinie jest prosta i czytelna. Używamy słowa kluczowego fun.
fun double(x: Int): Int {
return 2 * x
}Typ zwracany podajemy po dwukropku. Jeśli funkcja nic nie zwraca (czyli zwraca Unit), możemy ten typ pominąć.
Kotlin wprowadza wartości domyślne parametrów.
fun connect(
url: String,
timeout: Int = 5000,
retry: Boolean = true
) { /*...*/ }Teraz możemy wywołać tę funkcję na wiele sposobów, korzystając z mechanizmu argumentów nazwanych. Pozwala on na podawanie parametrów w dowolnej kolejności, o ile nazwiemy je tak, jak w definicji.
connect("http://example.com") // timeout=5000, retry=true
connect("http://example.com", retry = false) // timeout=5000
connect(timeout = 1000, url = "http://example.com") // Kolejność nie ma znaczeniaJeśli potrzebujemy funkcji przyjmującej dowolną liczbę argumentów (np. lista ID do usunięcia), używamy modyfikatora vararg. Wewnątrz funkcji taki parametr jest widoczny jako tablica (Array<T>).
fun printScores(vararg scores: Int) {
for (score in scores) {
print("$score ")
}
}
printScores(1, 2, 3, 4, 5)Funkcje w stylu Kotlin (Idiomy)
Kotlin oferuje mechanizmy, które pozwalają pisać kod czytany niemal jak proza. Dwa z nich zasługują na szczególną uwagę: funkcje rozszerzające (Extensions) oraz funkcje infiksowe (Infix).
Funkcje rozszerzające pozwalają dodać nową funkcję do istniejącej klasy bez konieczności dziedziczenia z niej ani używania wzorca Dekorator. Możemy rozszerzać nawet klasy, których nie posiadamy kodu (np. String z biblioteki standardowej JDK).
Definiujemy je, podając nazwę typu przed nazwą funkcji:
// Rozszerzamy klasę String o metodę isEmail()
fun String.isEmail(): Boolean {
// 'this' odnosi się do instancji Stringa, na którym wywołujemy funkcję
return this.contains("@") && this.contains(".")
}
val email = "user@example.com"
if (email.isEmail()) {
println("Poprawny email")
}Pod maską, kompilator zamienia to na statyczną funkcję, która przyjmuje obiekt jako pierwszy parametr. Dzięki temu rozszerzenia nie łamią hermetyzacji (nie mają dostępu do prywatnych pól klasy).
Funkcje infiksowe pozwalają wywoływać funkcje (które mają dokładnie jeden parametr) w sposób przypominający operatory matematyczne lub język naturalny.
infix fun Int.times(str: String): String {
return str.repeat(this)
}
// Wywołanie standardowe
3.times("Hello")
// Wywołanie infiksowe - jak zdanie
3 times "Hello"Infixy są powszechnie stosowane w DSL-ach (Domain Specific Languages) oraz w testach (np. biblioteka AssertK: assertThat(price) isEqualTo 100).
Funkcje Wyższego Rzędu i Lambdy
Funkcja wyższego rzędu to taka funkcja, która przyjmuje inną funkcję jako parametr lub ją zwraca. To fundament programowania funkcyjnego.
Wyrażenia lambda to funkcja anonimowa (bez nazwy), którą możemy zapisać w zwięzły sposób.
Pełna składnia:
val sum: (Int, Int) -> Int = { x: Int, y: Int -> x + y }Uproszczona składnia (typ wnioskowany):
val sum = { x: Int, y: Int -> x + y }Kotlin posiada konwencję, która bardzo upraszcza kod: 1. Jeśli funkcja jest ostatnim parametrem wywołania, lambdę możemy wyciągnąć poza nawias. 2. Jeśli lambda ma tylko jeden parametr, nie musimy go nazywać – jest on dostępny pod domyślną nazwą it.
val numbers = listOf(1, 2, 3, 4, 5)
// Wersja "długa"
numbers.filter({ x -> x > 2 })
// Wersja idiomatyczna (trailing lambda + it)
numbers.filter { it > 2 }To dlatego kod Compose (Column { ... }) czy Gradle (dependencies { ... }) tak wygląda. Te nawiasy klamrowe to właśnie lambdy.
Referencje do Funkcji (Operator ::)
Operator :: służy do tworzenia referencji do funkcji lub właściwości. Pozwala to przekazywać istniejące funkcje jako argumenty do innych funkcji (np. funkcji wyższego rzędu) zamiast definiować nową lambdę.
fun isEven(n: Int): Boolean = n % 2 == 0
val numbers = listOf(1, 2, 3, 4, 5, 6)
// Przekazanie referencji do funkcji zamiast lambdy { isEven(it) }
val evenNumbers = numbers.filter(::isEven)
// Referencja do metody klasy
val list = listOf("a", "bc", "def")
val lengths = list.map(String::length)Funkcje Anonimowe
Funkcje anonimowe to funkcje, które nie mają przypisanej nazwy. Są one wyrażeniem, podobnie jak lambdy, ale ich składnia jest bliższa tradycyjnym funkcjom.
val sum = fun(x: Int, y: Int): Int {
return x + y
}Kluczowe cechy i różnice względem lambd:
- Instrukcja
return: W funkcjach anonimowych słowo kluczowereturndziała tak samo, jak w funkcjach nazwanych – zwraca wartość z samej funkcji anonimowej. W lambdachreturnbez etykiety próbuje zwrócić wartość z funkcji otaczającej (non-local return). - Jawność typów: Funkcje anonimowe wymagają jawnej deklaracji parametrów oraz typu zwracanego (przy użyciu ciała blokowego).
- Zastosowanie: Są użyteczne, gdy potrzebujemy precyzyjnej kontroli nad typem zwracanym lub gdy chcemy uniknąć niejasności związanych z działaniem
returnwewnątrz lambdy.
Funkcje Zakresu (Scope Functions)
To zestaw 5 funkcji standardowych: let, run, with, apply, also. Wszystkie robią coś bardzo podobnego: wykonują blok kodu na obiekcie. Różnią się tylko tym, jak ten obiekt jest dostępny w środku (this czy it) i co zwracają (sam obiekt czy wynik lambdy).
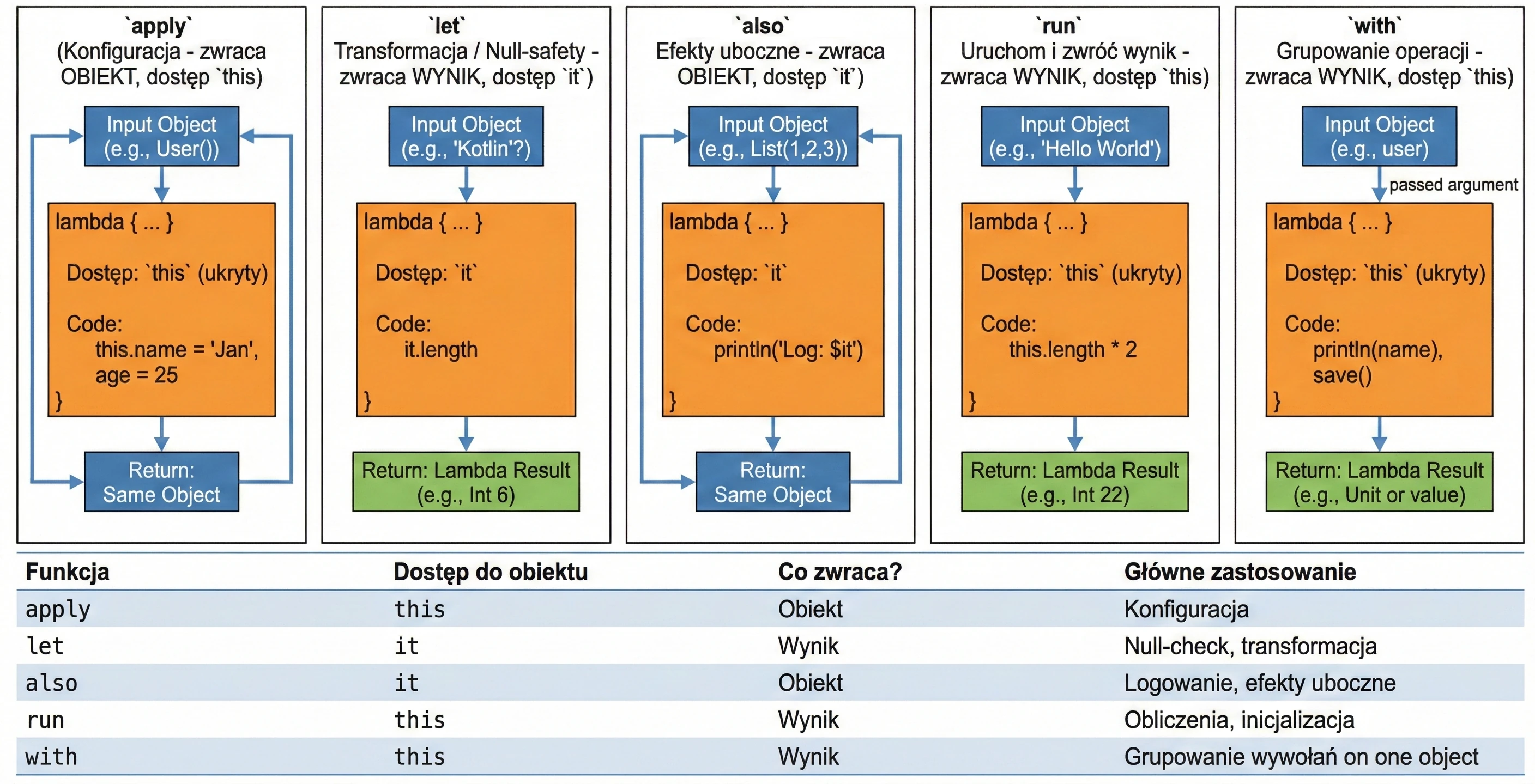
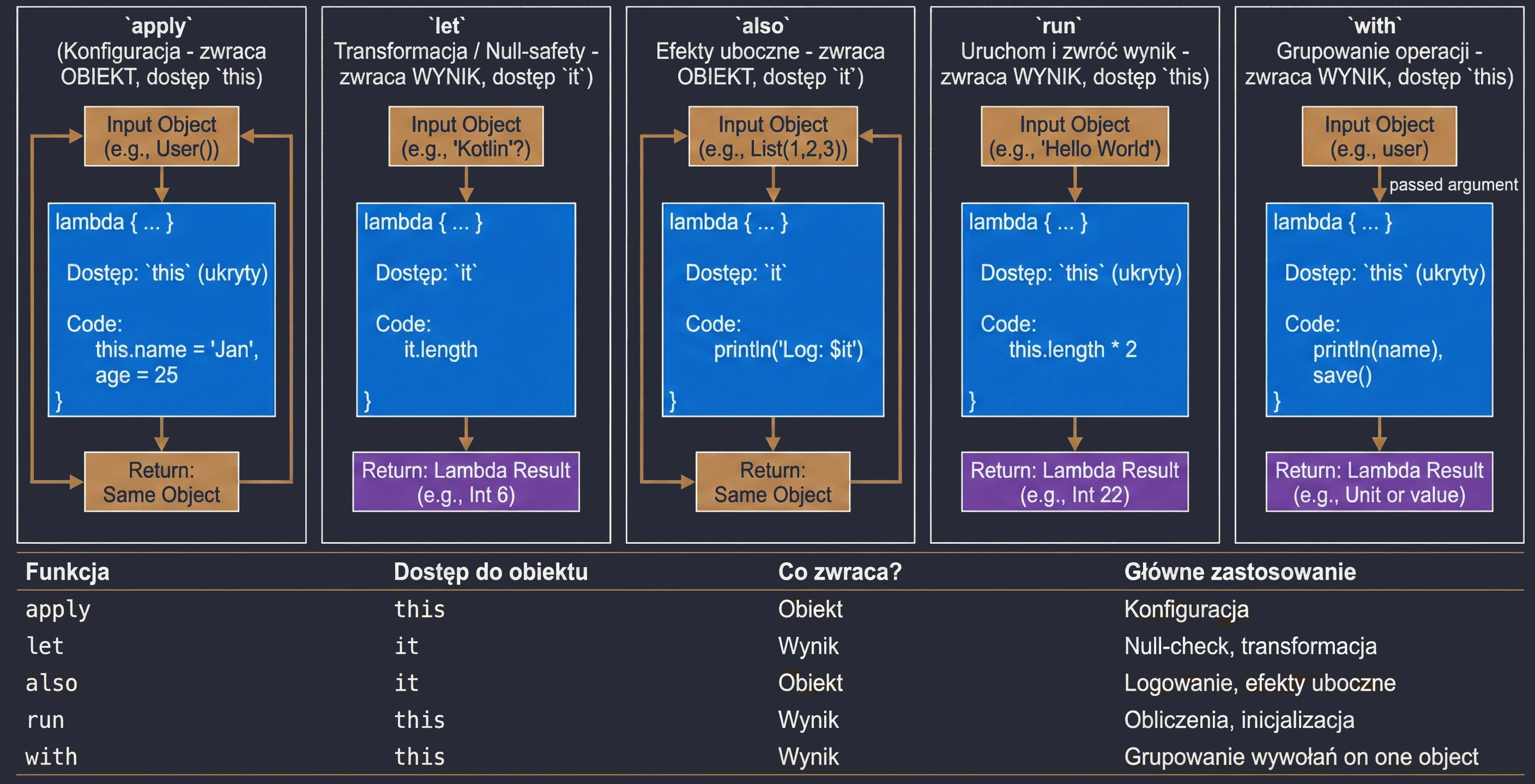
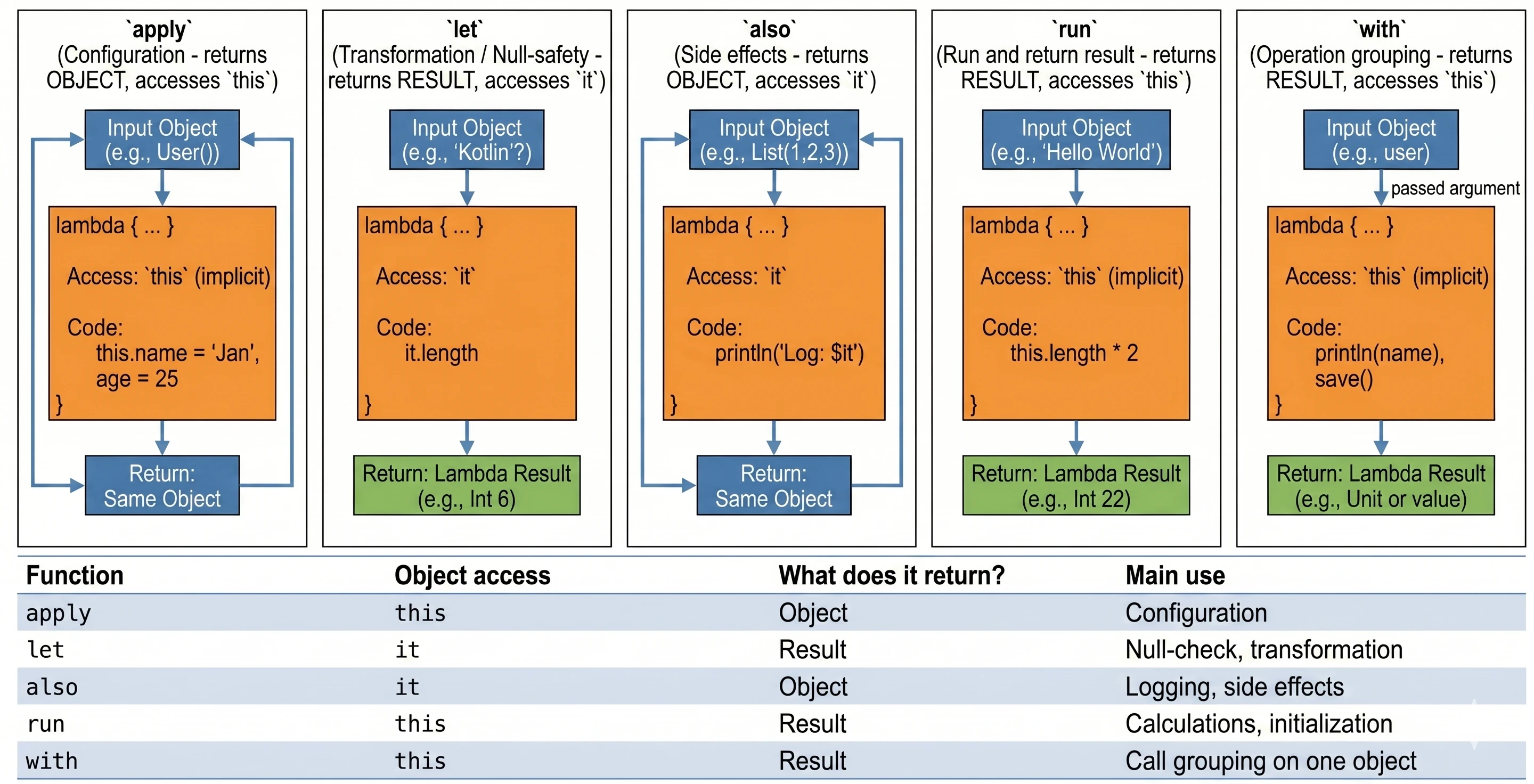
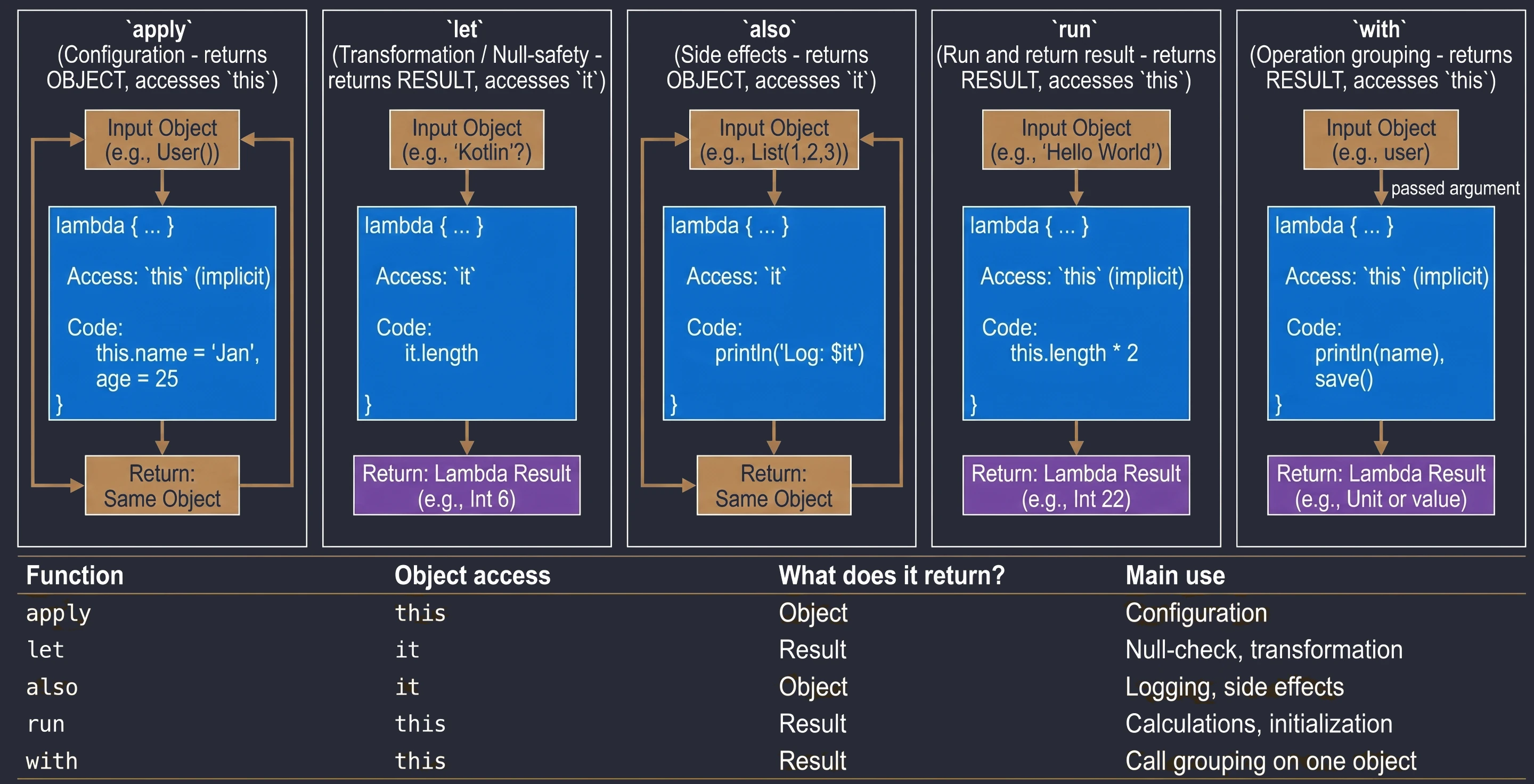
śŚciąga, jak wybierać odpowiednią funkcję:
apply: Konfiguracja obiektu. Dostęp przezthis, zwraca obiekt.let: Praca z obiektami nullowalnymi lub transformacja. Dostęp przezit, zwraca wynik lambdy.also: Wykonywanie dodatkowych operacji, tzw. efektów ubocznych (akcji, które nie zmieniają samego obiektu, ale wpływają na świat zewnętrzny, np. logowanie lub zapis do bazy), bez przerywania łańcucha wywołań. Dostęp przezit, zwraca obiekt.run: Połączeniewithilet. Uruchomienie bloku kodu na obiekcie i zwrócenie wyniku. Dostęp przezthis.with: Podobne dorun, ale obiekt podajemy jako argument. Używane, gdy chcemy wykonać wiele operacji na jednym obiekcie bez powtarzania jego nazwy.
val user = User().apply {
name = "Jan"
age = 25
city = "Kraków"
}val name: String? = "Kotlin"
val length = name?.let {
println("Przetwarzanie: $it")
it.length // wynik lambdy przypisany do length
}val numbers = mutableListOf(1, 2, 3)
.also { println("Log: utworzono listę $it") }
.apply { add(4) }val result = "Hello World".run {
println("Długość tekstu: $length")
length * 2
}with(user) {
println("Imię: $name")
println("Wiek: $age")
saveToDatabase()
}Zaawansowane Koncepcje
Funkcje Inline
Każda lambda w Kotlinie jest kompilowana do anonimowej klasy. Oznacza to, że każde jej wywołanie wiąże się z utworzeniem nowego obiektu, co zajmuje pamięć i czas procesora. W przypadku funkcji wywoływanych miliony razy (np. w pętlach), narzut ten staje się zauważalny.
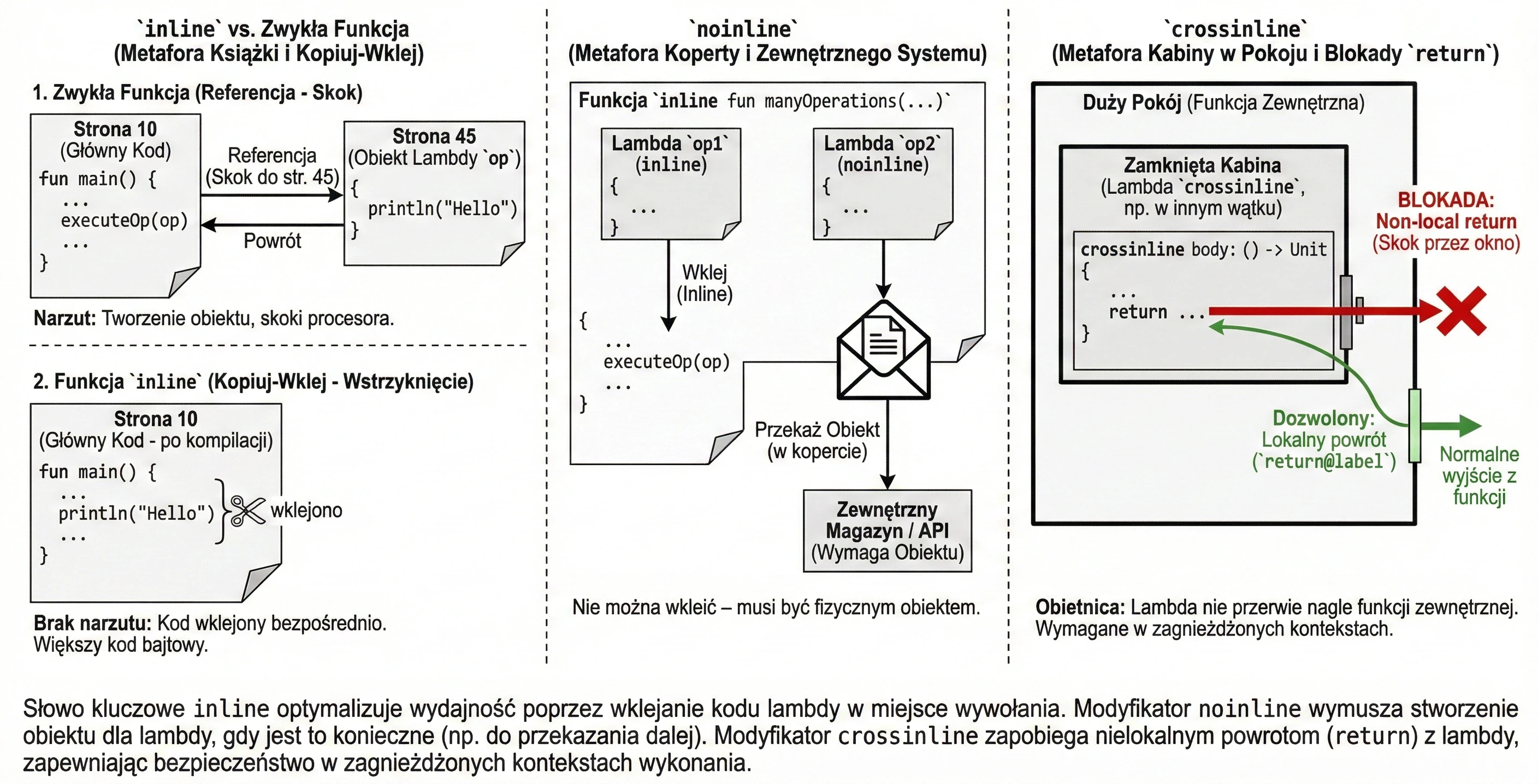
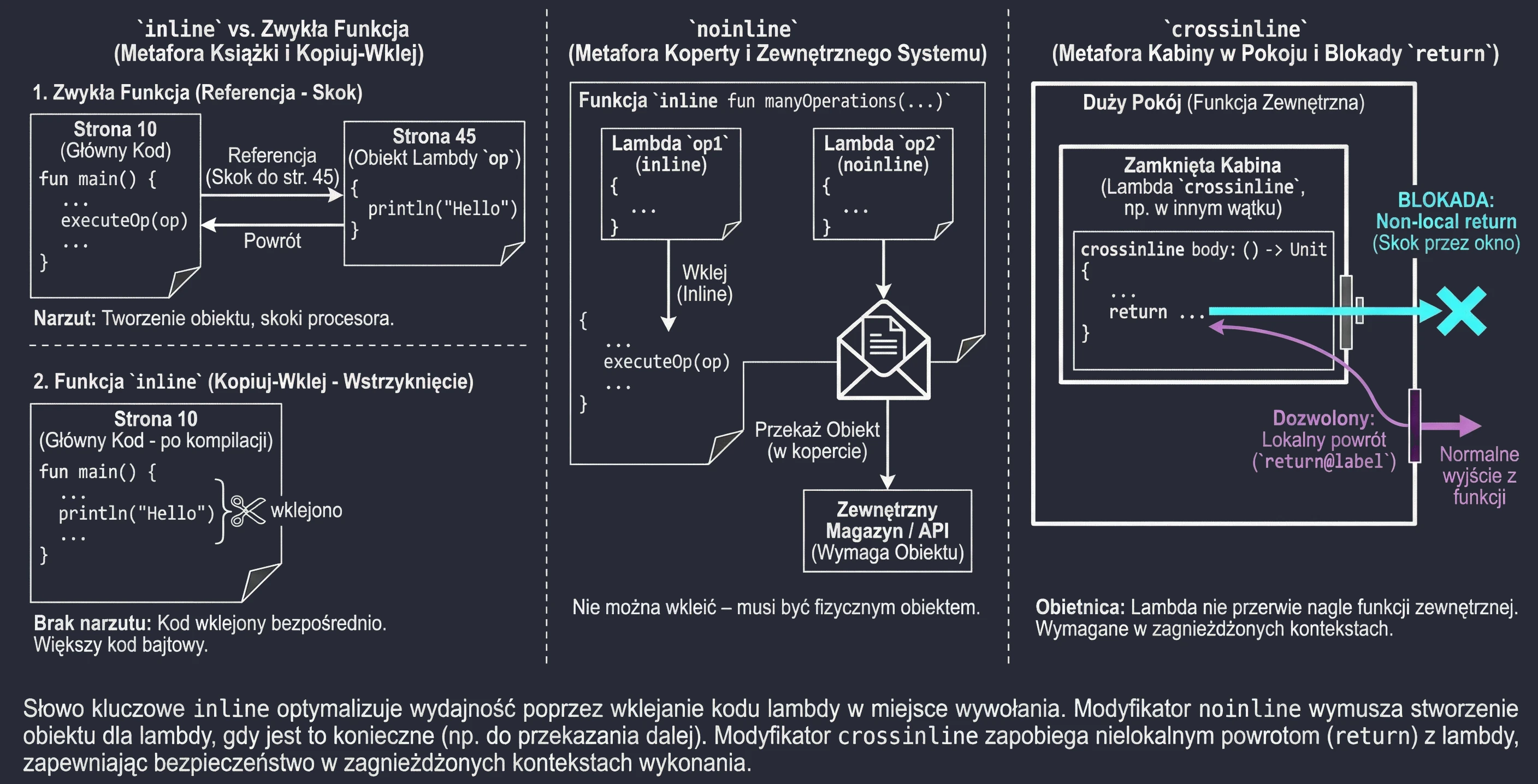
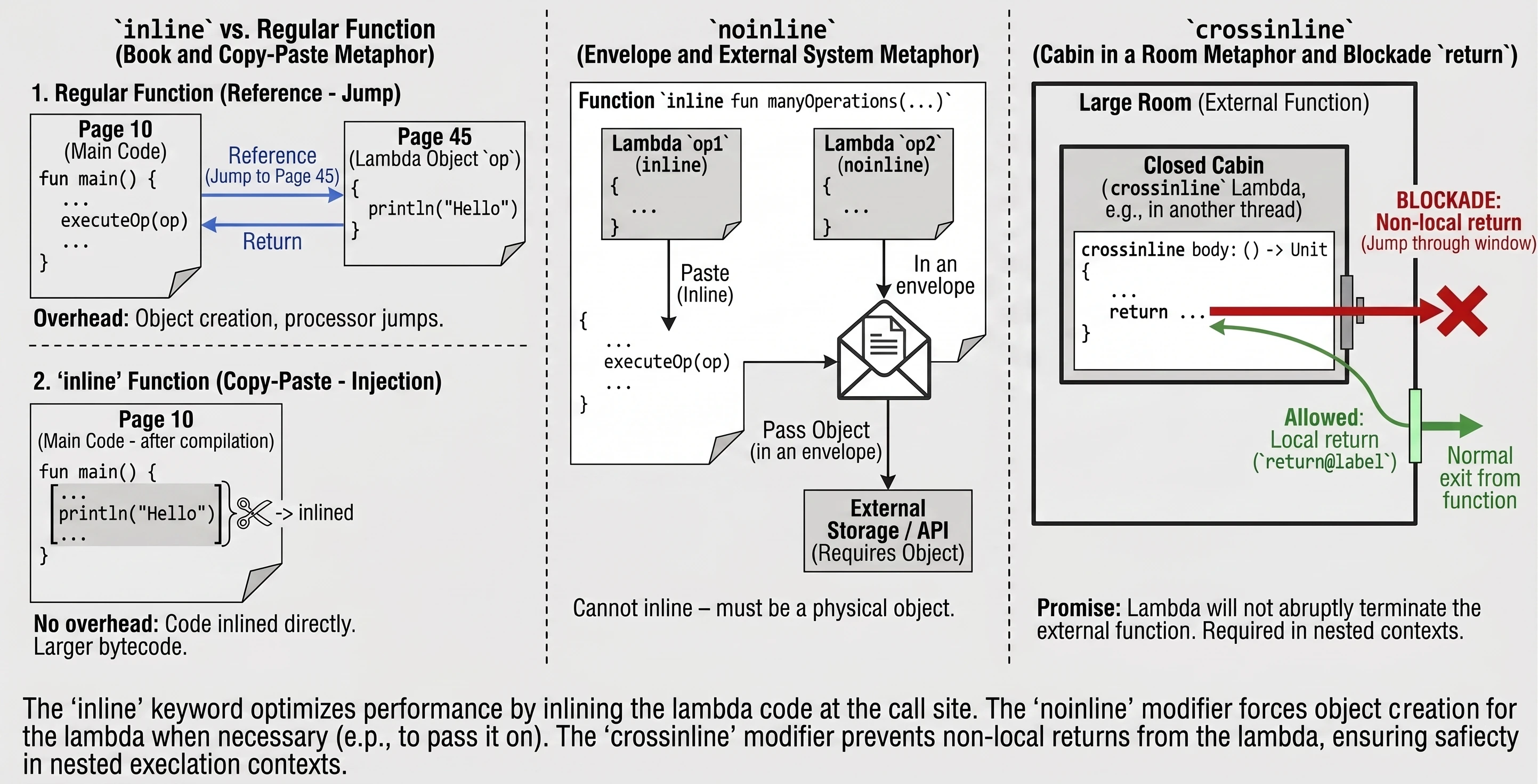
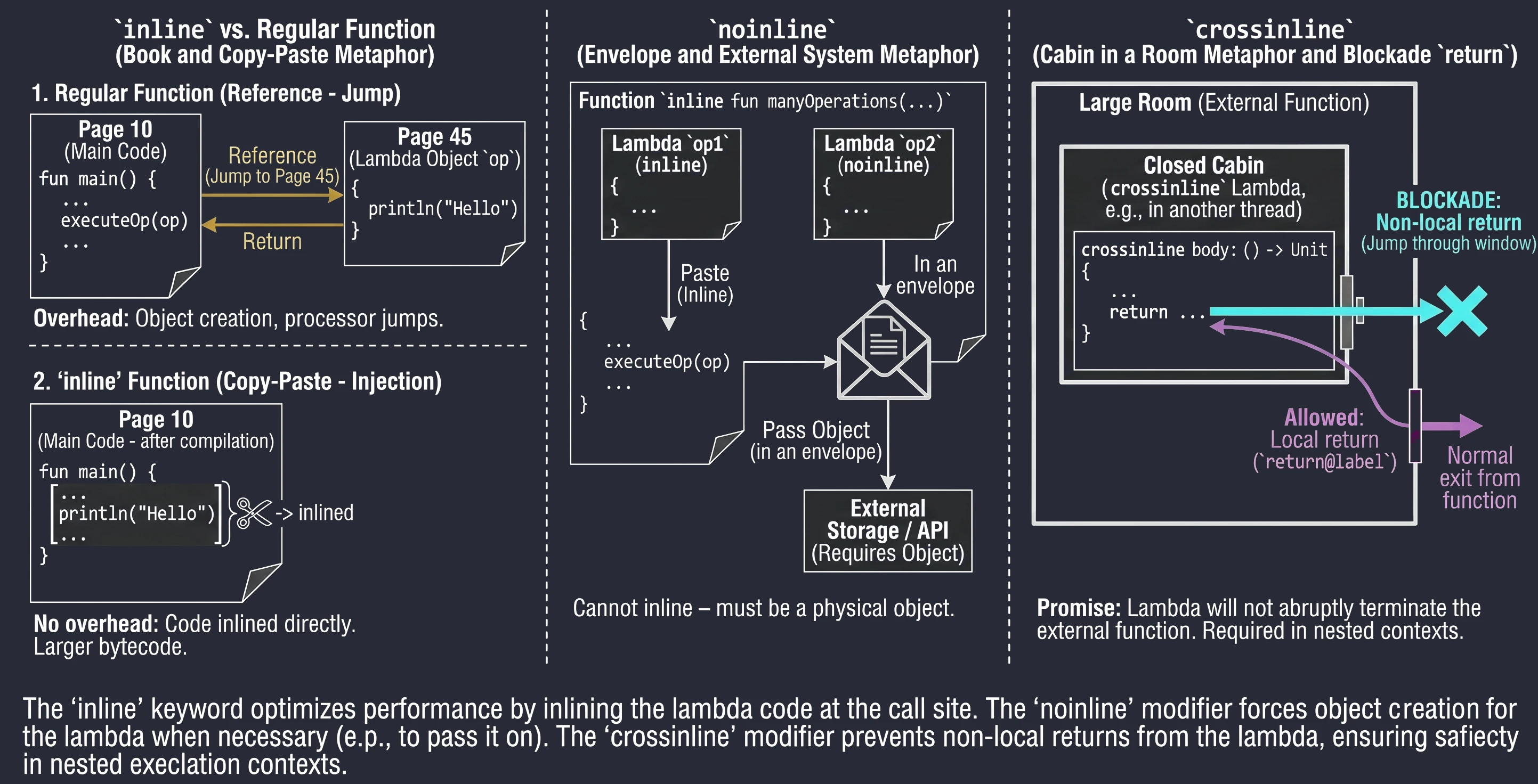
Słowo kluczowe inline to instrukcja dla kompilatora: Nie twórz obiektu dla tej lambdy. Zamiast tego, skopiuj kod tej funkcji i wklej go („kopiuj-wklej”) bezpośrednio w miejsce wywołania.
inline fun executeOp(op: () -> Unit) {
op() // Treść 'op' zostanie tu wklejona
}Wyobraź sobie, że piszesz książkę (program).
- Zwykła funkcja to przypis (referencja): Patrz strona 45. Czytelnik (procesor) musi przerwać czytanie bieżącego wątku, skoczyć na stronę 45, przeczytać i wrócić.
- Funkcja
inlineto operacja Znajdź i Zamień w edytorze. Edytor bierze treść ze strony 45 i fizycznie wkleja ją w każde miejsce, gdzie było odesłanie. Książka robi się grubsza (więcej kodu bajtowego), ale czyta się ją płynnie, bez ciągłego skakania po stronach.
Czasami funkcja inline przyjmuje kilka lambd, ale tylko niektóre z nich chcemy wkleić. Inne mogą być np. przekazywane dalej do innych funkcji (które nie są inline) lub zapisywane w polach klas. W takiej sytuacji, wklejenie jest niemożliwe – musimy mieć fizyczny obiekt lambdy. Używamy wtedy modyfikatora noinline.
inline fun manyOperations(
op1: () -> Unit,
noinline op2: () -> Unit // Ta lambda pozostanie obiektem
) {
op1()
someExternalStore(op2) // Nie można przekazać kodu "wklejonego", trzeba obiektu
}Załóżmy, że mamy dwa dokumenty. Jeden przepisujemy ręcznie do głównego zeszytu (inline), ale drugi musimy włożyć do koperty i wysłać pocztą do urzędu (noinline). Nie możesz wysłać przepisanej treści – urząd wymaga oryginału (obiektu w kopercie).
Jak wspomnieliśmy, w funkcjach inline dozwolony jest return (powrót nielokalny). Czasami jednak lambda jest wykonywana w innym kontekście (np. wewnątrz zagnieżdżonej funkcji lub innego wątku), gdzie nagłe przerwanie funkcji zewnętrznej byłoby niebezpieczne lub niemożliwe.
Słowo kluczowe crossinline blokuje możliwość użycia return w lambdzie, mimo że funkcja jest inline. Pozwala to na bezpieczne użycie lambdy w zagnieżdżonych kontekstach.
inline fun executeLater(crossinline body: () -> Unit) {
val runnable = Runnable {
body() // Wywołanie w innym kontekście – non-local return zabroniony
}
runnable.run()
}Załóżmy że jesteśmy w pokoju (funkcja).
- Zwykły
returnto wyjście głównymi drzwiami. - Lambda
crossinlineto wejście do mniejszej, zamkniętej kabiny wewnątrz tego pokoju. Obiecujemy kompilatorowi (crossinline), że nie spróbujemy wyskoczyć przez okno (return) bezpośrednio z kabiny na zewnątrz budynku, pomijając drzwi pokoju. Możemy zakończyć tylko zadanie w kabinie (return@label).
Rekursja ogonowa (tailrec)
Rekursja grozi przepełnieniem stosu (StackOverflowError). Kotlin oferuje optymalizację: jeśli wywołanie rekurencyjne jest ostatnią operacją w funkcji, możemy dodać modyfikator tailrec. Kompilator zamieni wtedy rekurencję na zwykłą pętlę, co zapobiega przepełnieniu stosu.
tailrec fun silnia(n: Int, run: Int = 1): Int {
return if (n == 1) run else silnia(n - 1, n * run)
}Funkcje Generyczne
Funkcje generyczne pozwalają na tworzenie kodu szablonowego, który może pracować z różnymi typami danych, zachowując pełne bezpieczeństwo typowania i unikając rzutowania. Typ generyczny definiujemy w nawiasach ostrych <T> przed nazwą funkcji.
fun <T> singletonList(item: T): List<T> {
return listOf(item)
}Czasami nasz szablon ma sens tylko dla pewnej grupy typów (np. tylko dla liczb). Możemy to wymusić po dwukropku:
// T musi dziedziczyć po Number (Int, Double, Float...)
fun <T : Number> doubleValue(value: T): Double {
return value.toDouble() * 2
}Jeśli potrzebujemy kilku warunków jednocześnie (np. musi być liczbą oraz dać się porównywać), stosujemy słowo kluczowe where:
fun <T> sortNumbers(list: List<T>)
where T : Number, T : Comparable<T> {
// ...
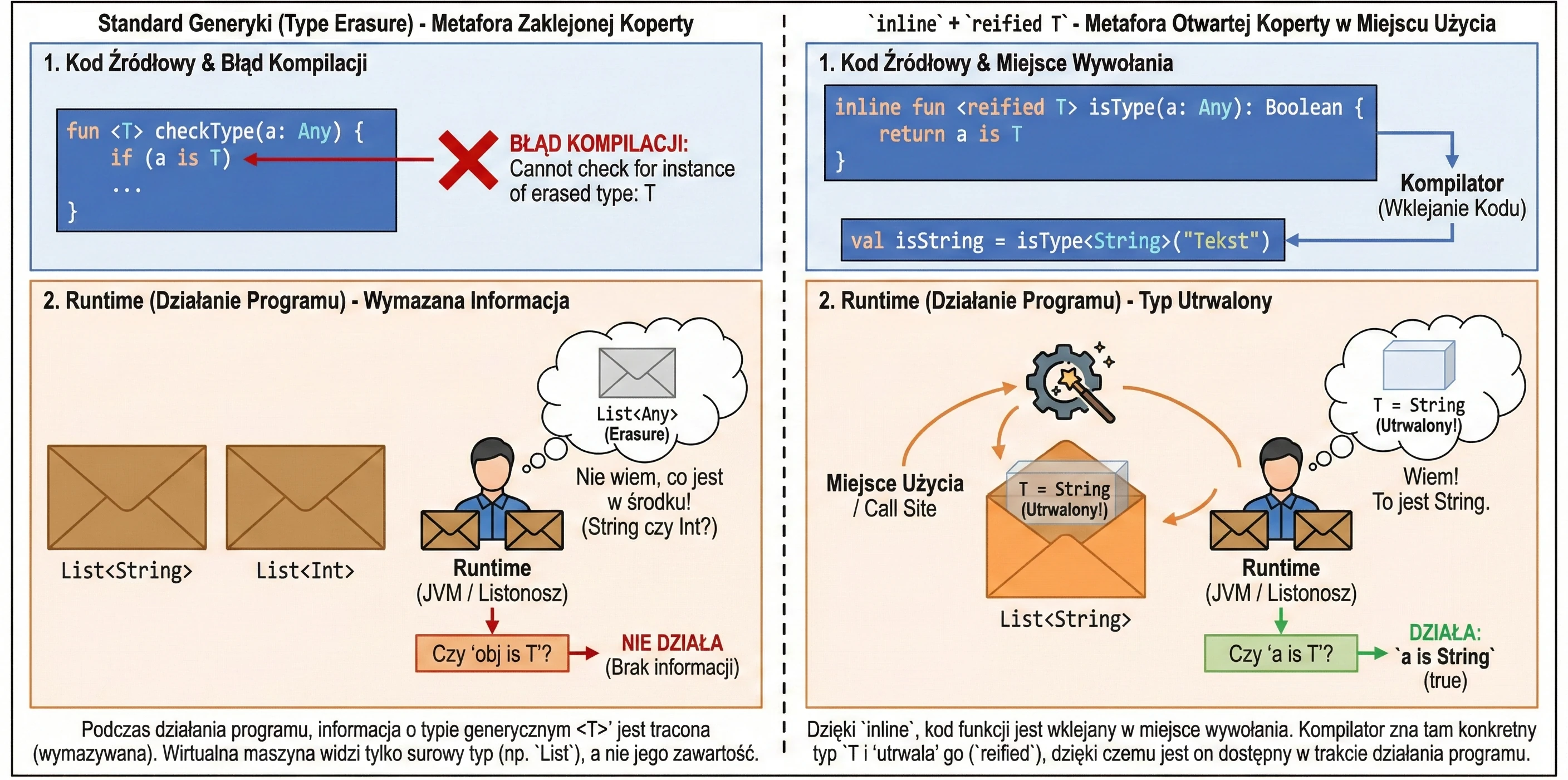
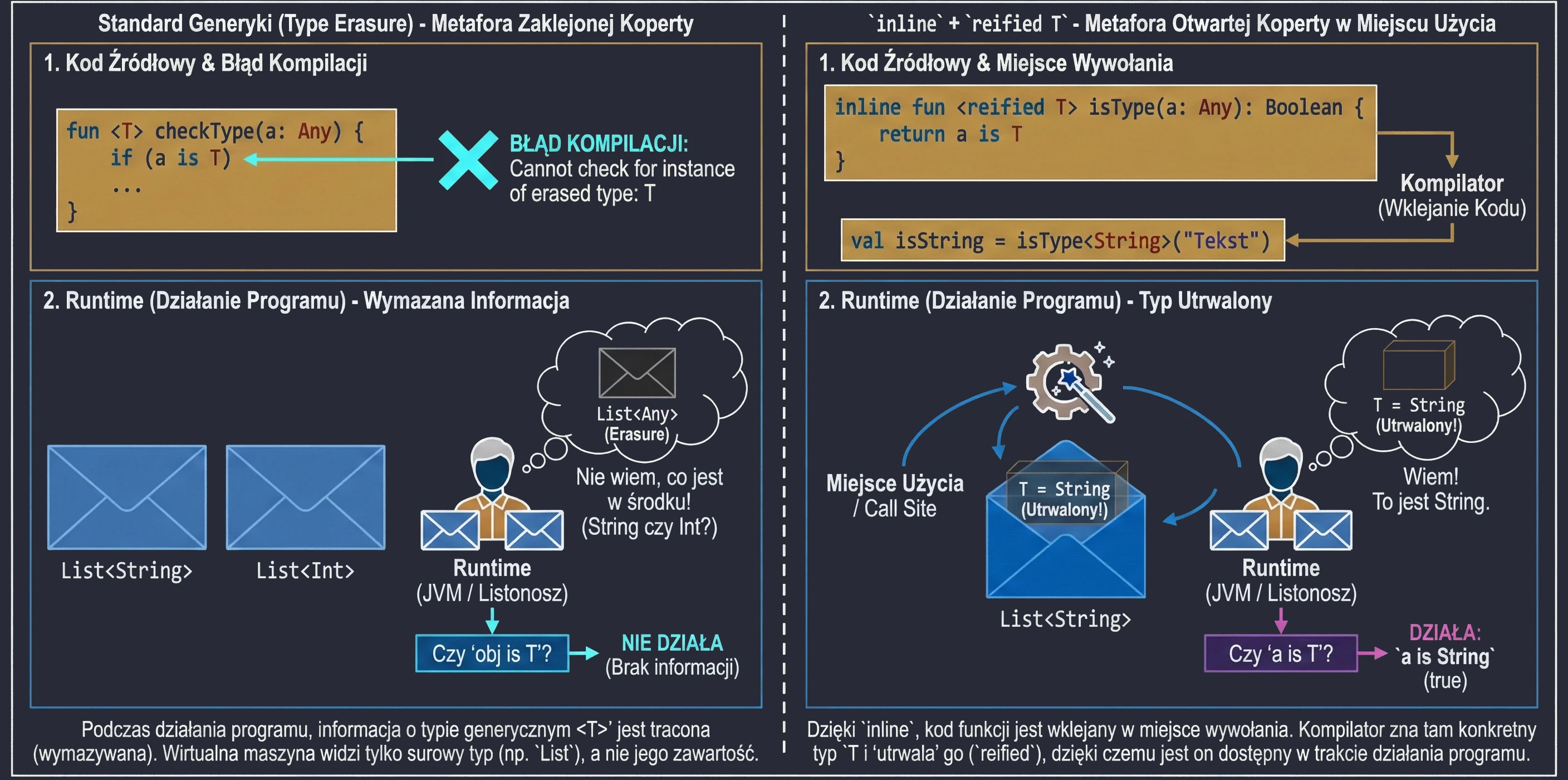
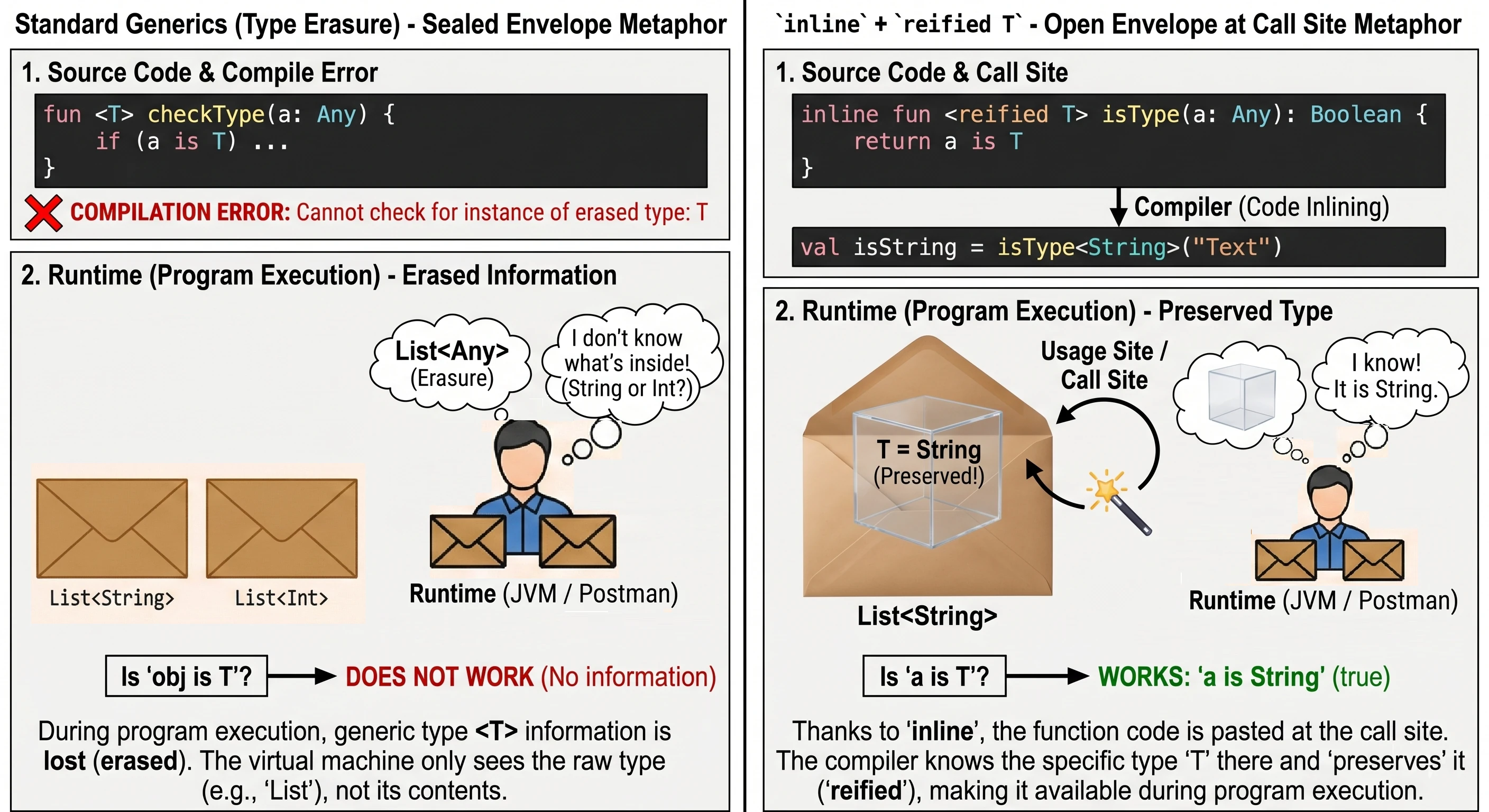
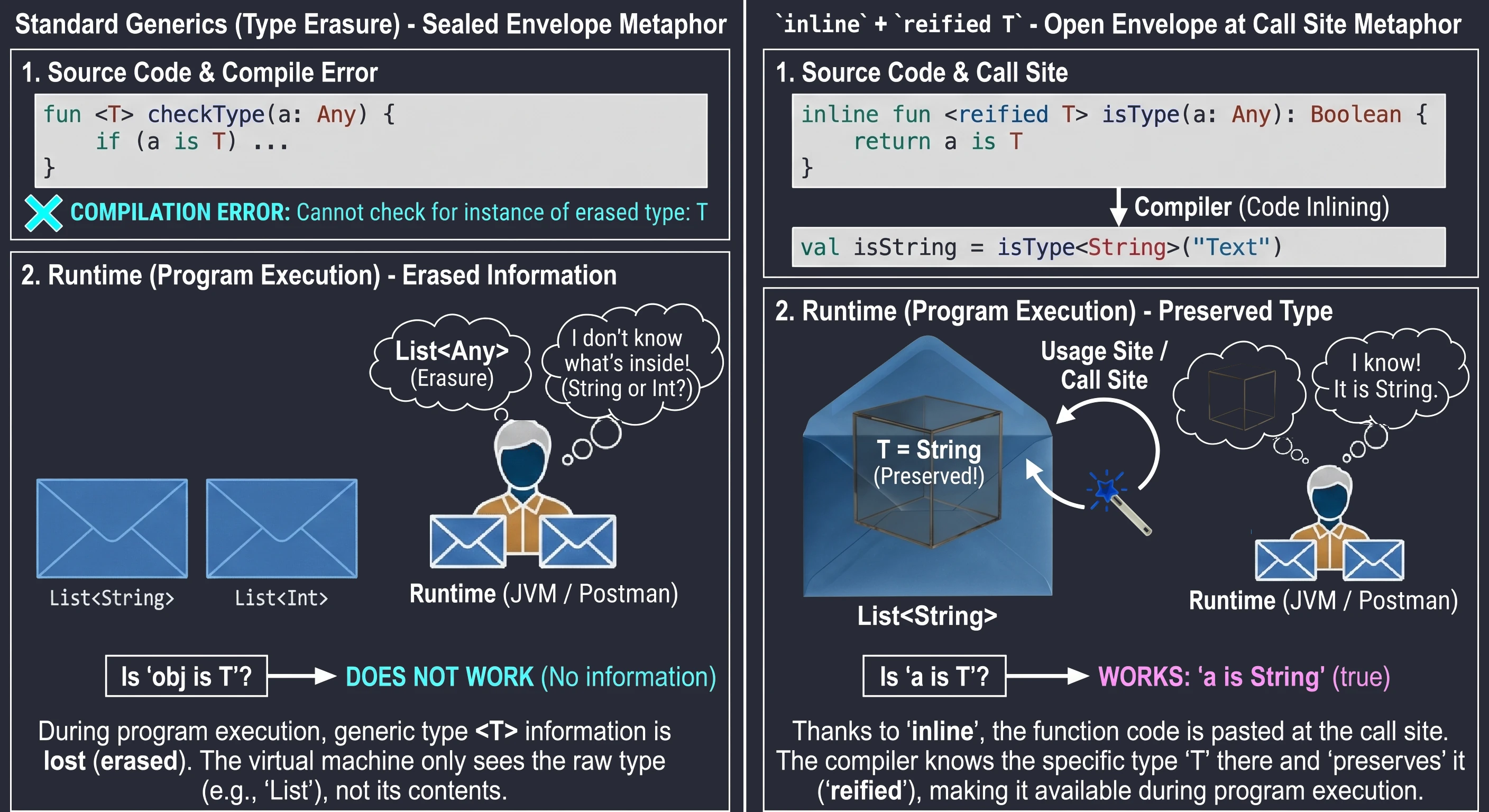
}W Javie (i standardowo w Kotlinie) typy generyczne podlegają wymazywaniu typów (type erasure). Oznacza to, że w trakcie działania programu List<String> i List<Int> są tym samym: po prostu List. Wirtualna maszyna nie wie, co było w środku. Dlatego nie możemy napisać: if (obj is T).
Jednak dzięki funkcjom inline, możemy użyć specjalnego słowa kluczowego reified. Ponieważ kod funkcji jest wklejany w miejsce wywołania, kompilator w tym konkretnym miejscu zna dokładny typ i może go utrwalić (reify).
// Zwykła funkcja - to nie zadziała:
// fun <T> checkType(a: Any) = a is T // Błąd kompilacji! Erasure.
// Funkcja inline + reified
inline fun <reified T> isType(a: Any): Boolean {
return a is T // Teraz działa
}
val isString = isType<String>("Tekst") // true
val isInt = isType<Int>("Tekst") // falsePosłużmy się analogią:
- Zwykłe generyki to list w zaklejonej kopercie. Listonosz (runtime) wie, że niesie List, ale nie wie co jest w środku (String czy Int), bo koperta jest nieprzezroczysta (erasure).
reifiedw funkcjiinlineto sytuacja, w której nadawca (kompilator) otwiera kopertę tuż przed wręczeniem jej tobie w miejscu odbioru. Widzisz zawartość, więc wiesz dokładnie, co to za typ.
Przeciążanie Operatorów (operator fun)
Kotlin umożliwia dostarczenie własnych implementacji dla ustalonego zestawu operatorów (takich jak +, *, ==, czy []). Aby funkcja mogła pełnić rolę operatora, musi być poprzedzona słowem kluczowym operator i posiadać konkretną, zarezerwowaną nazwę.
data class Vector(val x: Int, val y: Int) {
// Przeciążenie operatora +
operator fun plus(other: Vector): Vector {
return Vector(x + other.x, y + other.y)
}
}
val v1 = Vector(1, 2)
val v2 = Vector(3, 4)
val v3 = v1 + v2 // Wynik: Vector(x=4, y=6)Najpopularniejsze operatory to:
plus,minus,times,div,rem(arytmetyczne).get,set(dostęp przez nawiasy kwadratowe[]).invoke(pozwala wywołać obiekt jak funkcję:obiekt()).contains(operatorin).
Kolekcje to jeden z najważniejszych elementów każdego języka programowania. Służą do przechowywania grup obiektów. W Kotlinie podejście do kolekcji jest wyjątkowe ze względu na ścisły podział na kolekcje mutowalne (zmienne) i niemutowalne (tylko do odczytu). Ten podział jest kluczowy dla pisania bezpiecznego i przewidywalnego kodu.
Hierarchia Kolekcji
W standardowej bibliotece Javy (przed wprowadzeniem nowszych API) interfejs List posiadał metody add() czy remove(). Jeśli lista była niemutowalna (np. Arrays.asList()), wywołanie tych metod kończyło się błędem w czasie działania programu (UnsupportedOperationException).
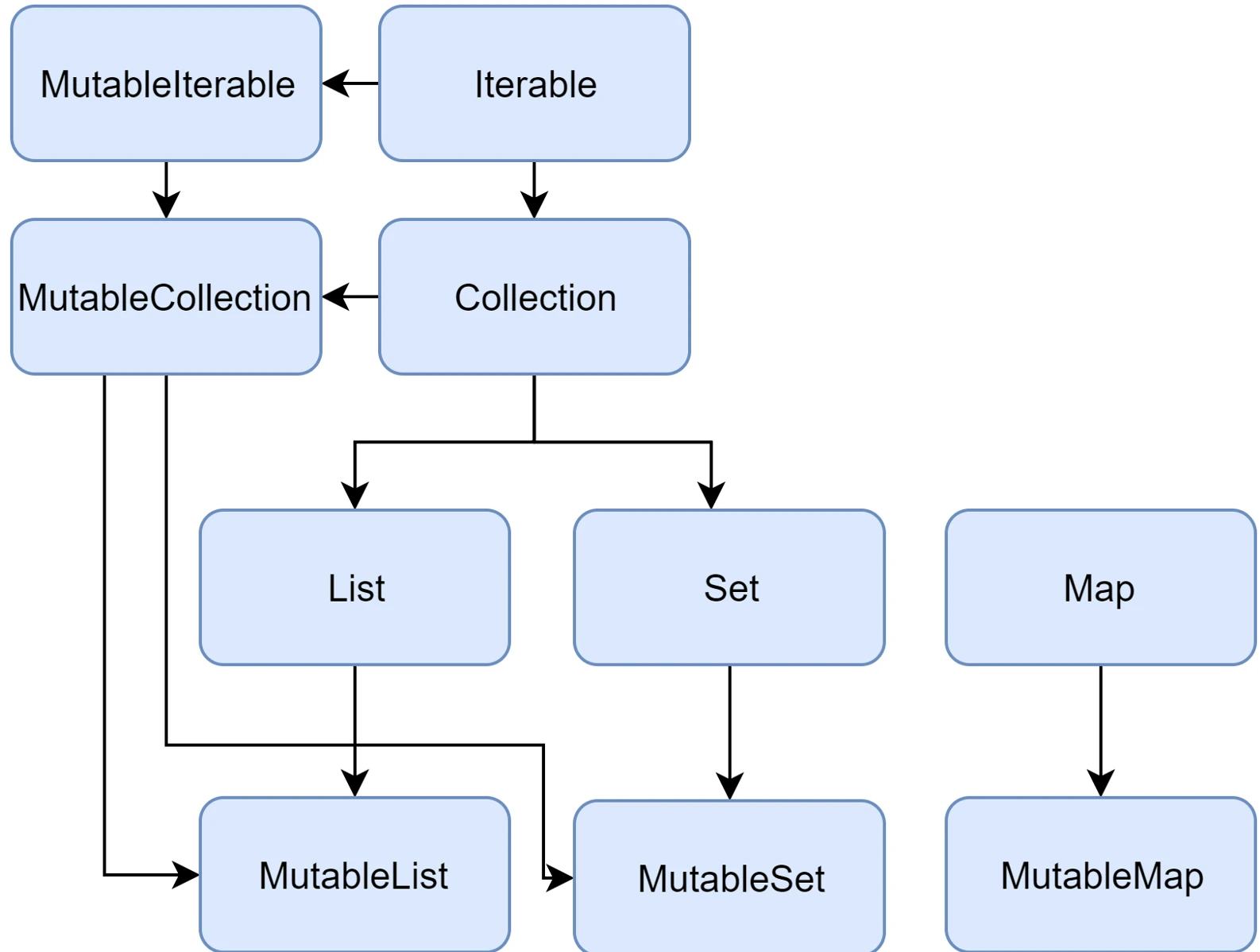
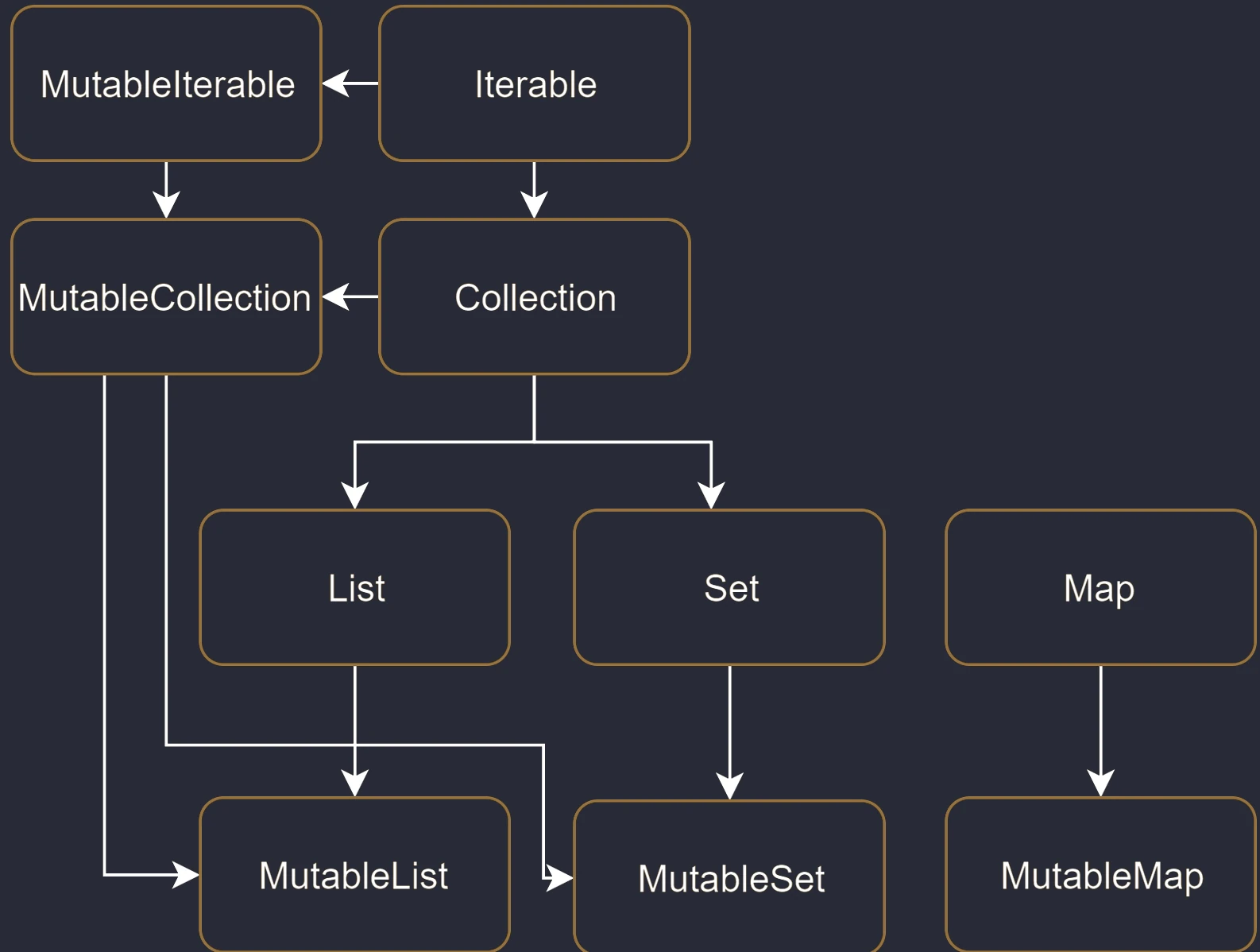
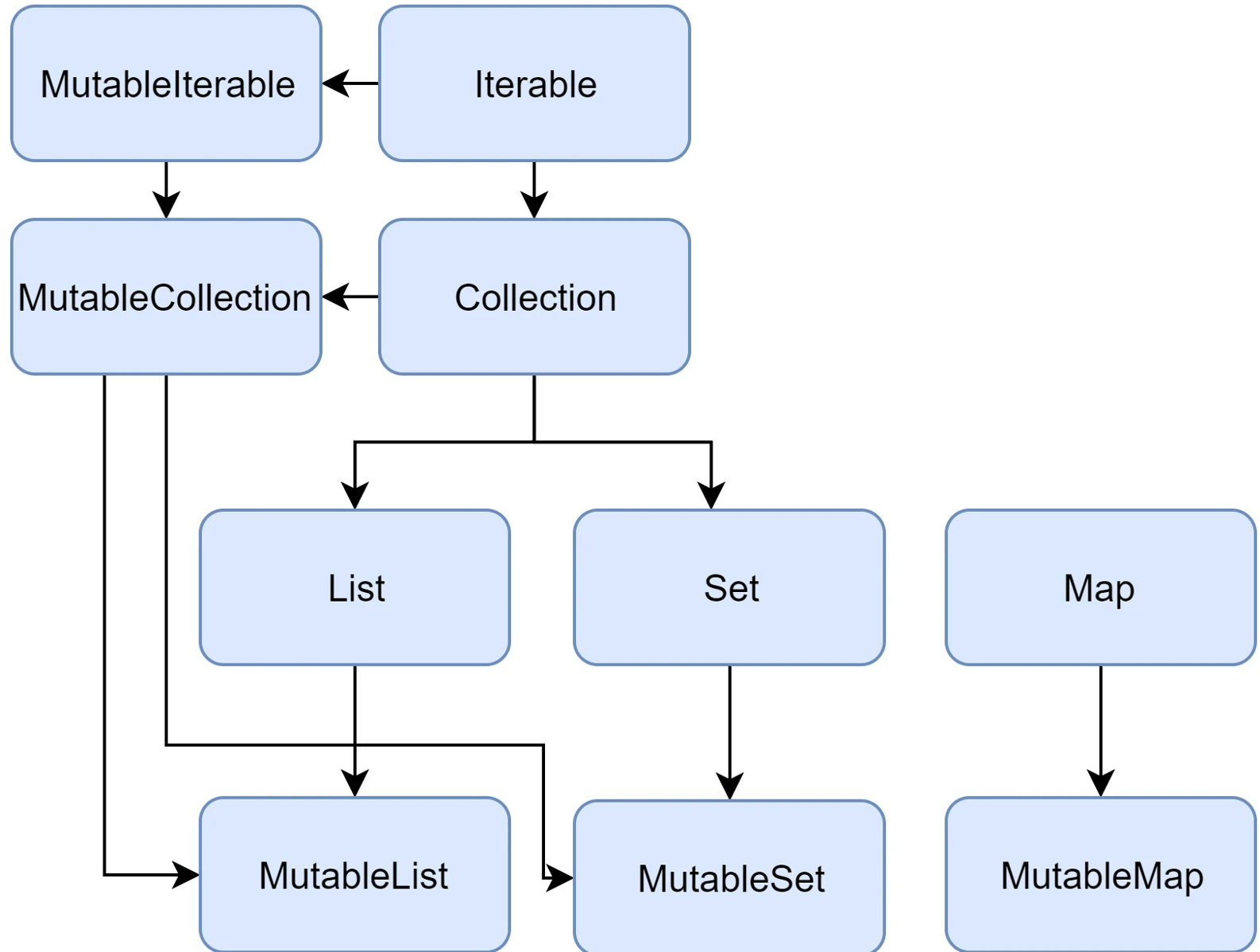
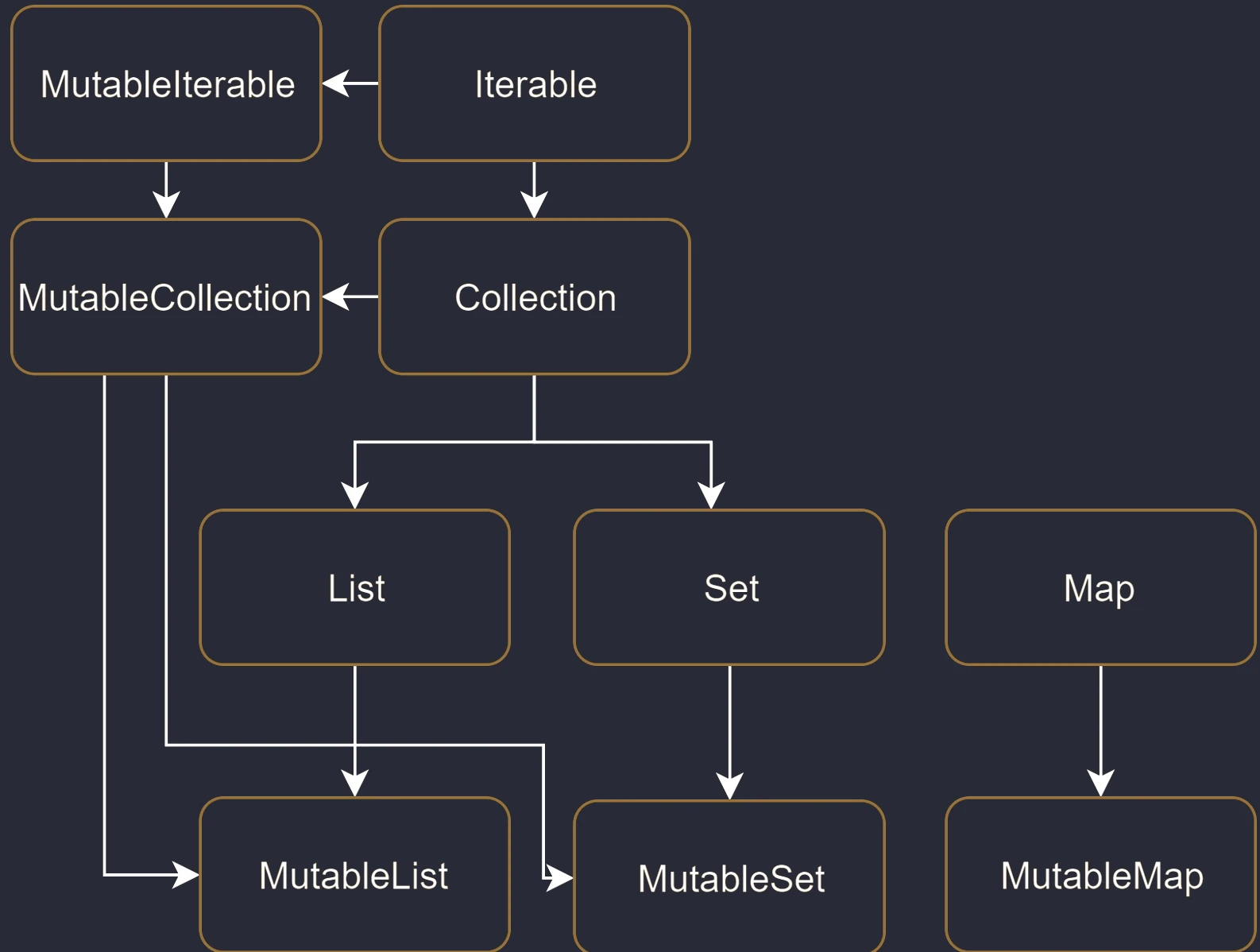
Kotlin rozwiązuje ten problem na poziomie systemu typów, wprowadzając dwa oddzielne zestawy interfejsów:
- Interfejsy tylko do odczytu (Read-only):
List<T>,Set<T>,Map<K, V>. Nie posiadają metod modyfikujących. Gwarantują, że "przez ten interfejs" nie zmienisz zawartości. - Interfejsy mutowalne (Mutable):
MutableList<T>,MutableSet<T>,MutableMap<K, V>. Rozszerzają interfejsy read-only, dodając metody takie jakadd,remove,clear.
// Lista tylko do odczytu
val readOnlyList: List<String> = listOf("A", "B")
// readOnlyList.add("C") // Błąd kompilacji! Brak metody add()
// Lista mutowalna
val mutableList: MutableList<String> = mutableListOf("A", "B")
mutableList.add("C") // OKWażne: Interfejs List jest tylko widokiem (view). To, że mamy referencję typu List, nie oznacza, że obiekt pod spodem jest niezmienny. Może to być ArrayList, do którego ktoś inny ma dostęp jako MutableList i go modyfikuje. Jednak my, mając tylko List, obiecujemy, że my go nie zmienimy.
Podstawowe typy kolekcji
Listy (List)
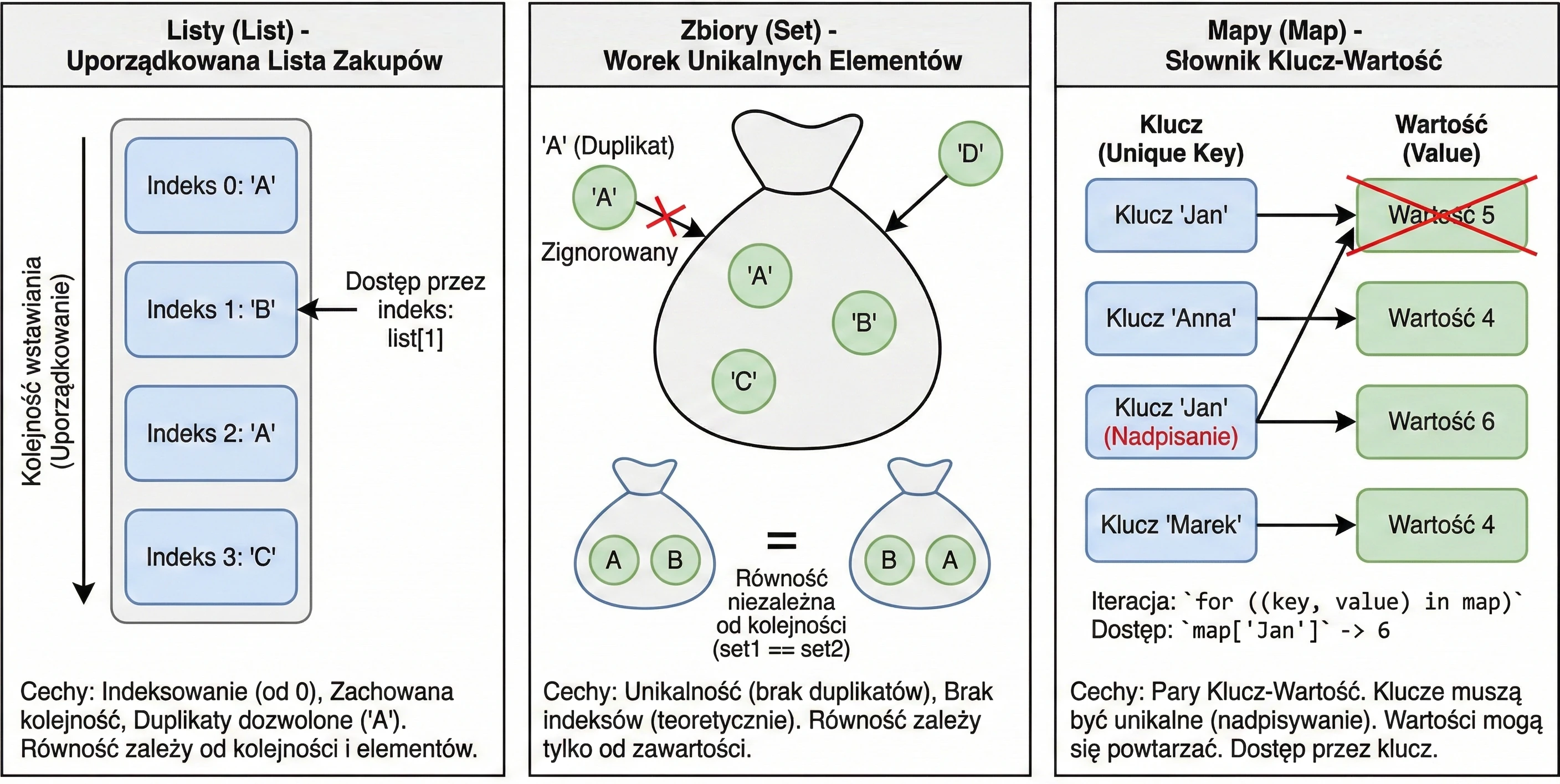
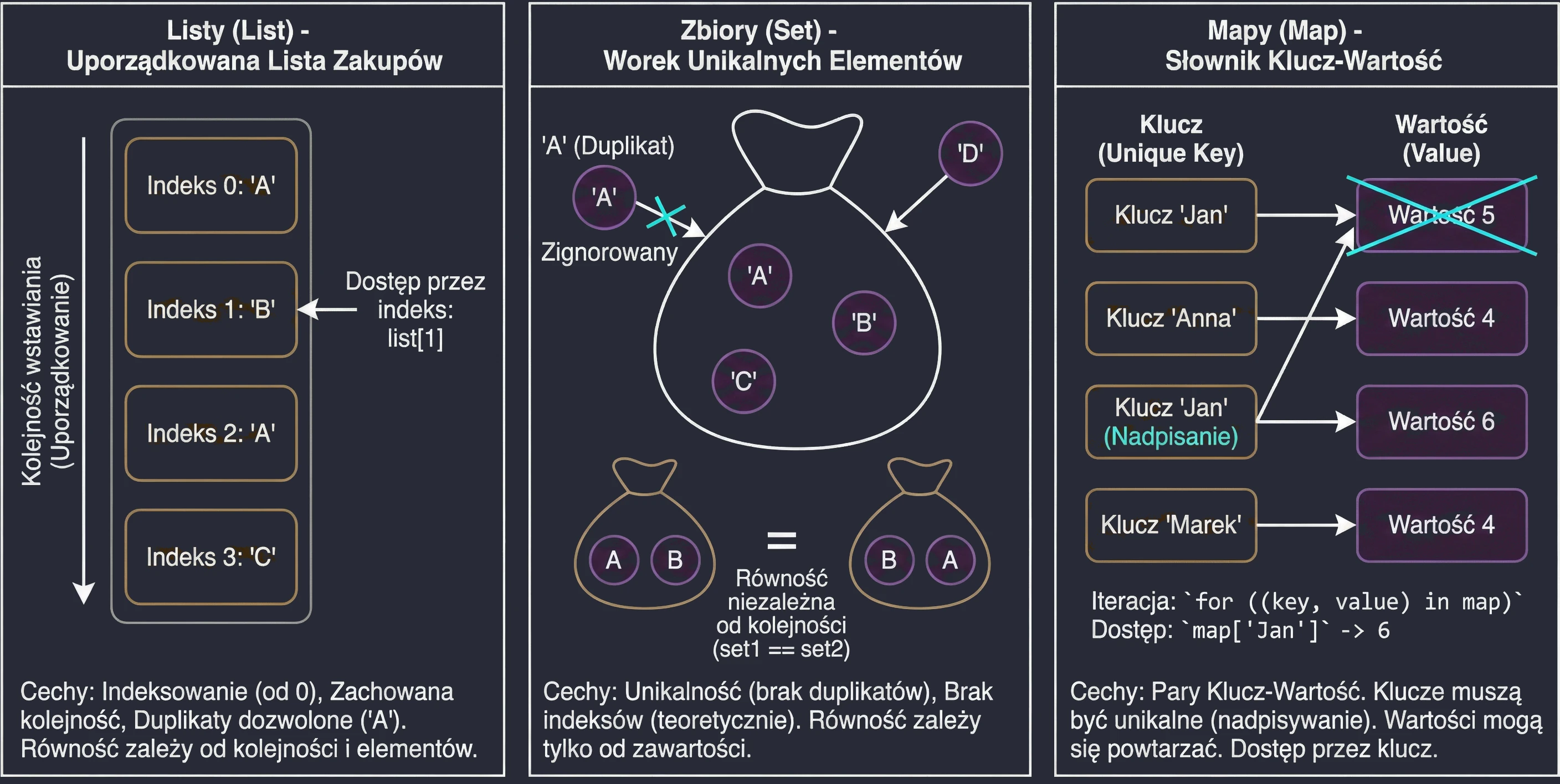
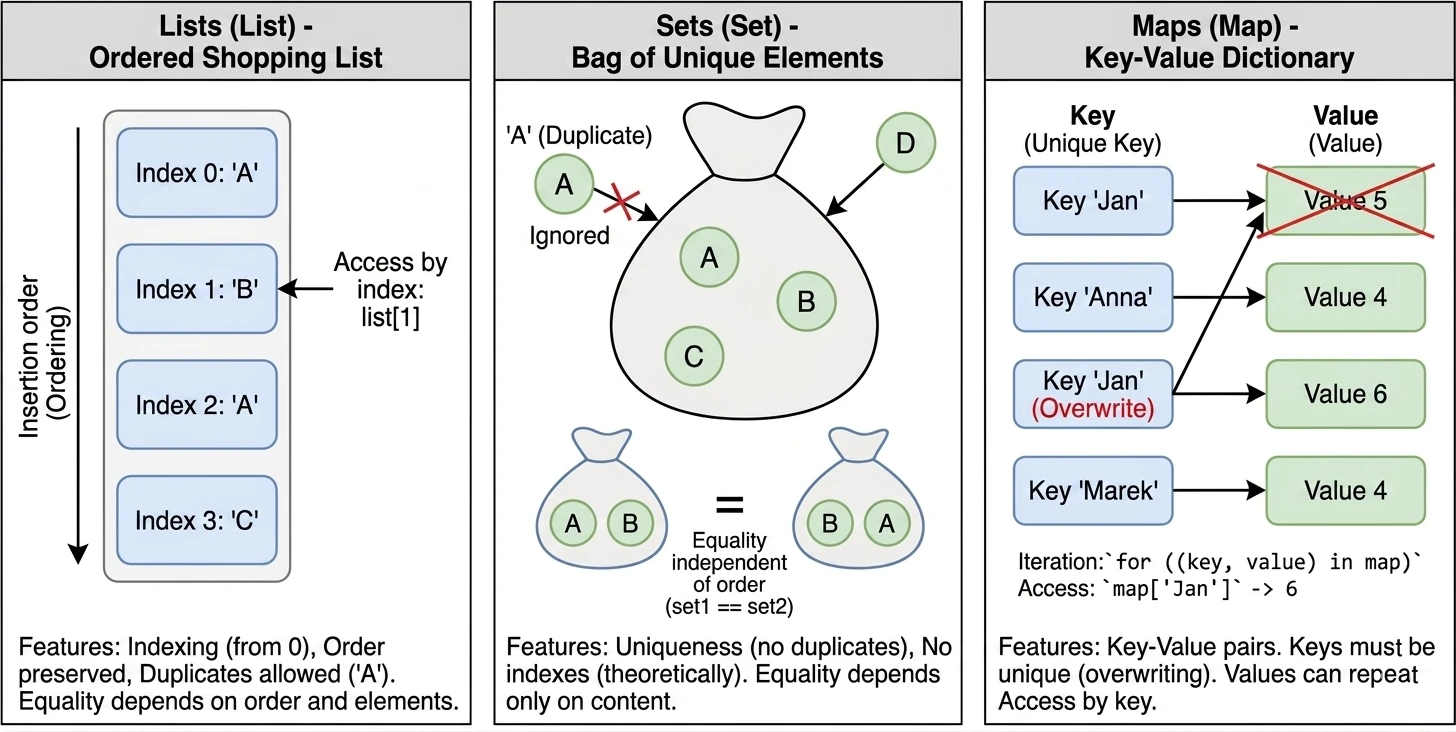
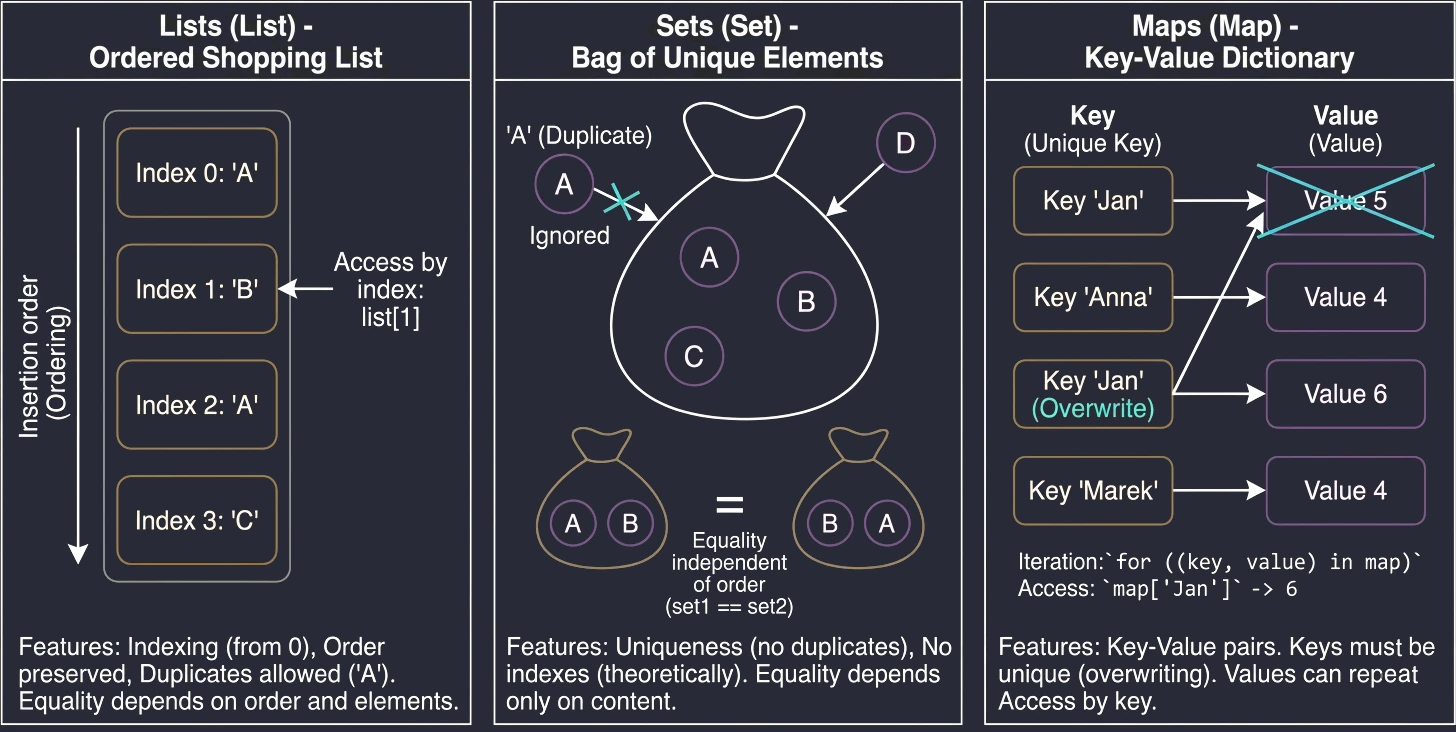
Lista to najbardziej intuicyjny typ kolekcji. Można ją przyrównać do listy zakupów spisanej na kartce – pozycje są ułożone jedna pod drugą, w konkretnej kolejności.
Główne cechy:
- Uporządkowanie: Elementy są przechowywane w takiej kolejności, w jakiej zostały dodane.
- Indeksowanie: Dostęp do elementów uzyskujemy za pomocą indeksu (numeru pozycji), zaczynając od 0.
list[0]to pierwszy element. - Duplikaty: Ta sama wartość może wystąpić na liście wielokrotnie.
- Równość: Dwie listy są uznawane za równe (
equalszwracatrue) tylko wtedy, gdy mają ten sam rozmiar i te same elementy na dokładnie tych samych pozycjach.
val list1 = listOf("A", "B", "A")
val list2 = listOf("A", "B", "A")
println(list1 == list2) // true
println(list1[1]) // "B"Zbiory (Set)
Zbiór przypomina matematyczną definicję zbioru lub worek z unikalnymi przedmiotami. Nie interesuje nas, który element jest pierwszy czy drugi – ważne jest tylko to, czy dany element należy do zbioru.
Główne cechy:
- Unikalność: W zbiorze nie mogą powtarzać się elementy. Jeśli spróbujesz dodać duplikat, zostanie on zignorowany.
- Brak kolejności (teoretycznie): W ogólnym sensie zbiory nie mają indeksów. Nie można spytać o drugi element zbioru.
- Równość: Dwa zbiory są równe, jeśli mają ten sam rozmiar i zawierają te same elementy, niezależnie od ich wewnętrznego ułożenia.
Uwaga: W Kotlinie domyślną implementacją setOf jest LinkedHashSet, co oznacza, że pamięta on kolejność wstawiania elementów przy iteracji (pętli for), ale nadal nie pozwala na dostęp przez indeks set[0].
val set1 = setOf("A", "B")
val set2 = setOf("B", "A", "A") // Duplikat "A" zignorowany, kolejność inna
println(set1 == set2) // trueMapy (Map)
Mapa (nazywana też słownikiem lub tablicą asocjacyjną) służy do przechowywania par Klucz-Wartość. To jak książka telefoniczna (Nazwisko -> Numer) lub słownik (Słowo -> Definicja).
Główne cechy:
- Klucze i Wartości: Każdy element to para. Klucz służy do identyfikacji i wyszukiwania, Wartość to dane przypisane do klucza.
- Unikalność kluczy: W mapie nie mogą istnieć dwa takie same klucze. Jeśli dodasz nową wartość pod istniejący klucz, stara wartość zostanie nadpisana. Wartości mogą się powtarzać.
- Równość: Dwie mapy są równe, jeśli zawierają identyczny zestaw par klucz-wartość, niezależnie od kolejności.
val map = mapOf("Jan" to 5, "Anna" to 4)
println(map["Jan"]) // 5 (dostęp po kluczu, nie indeksie!)W Kotlinie można iterować po Map na kilka wygodnych sposobów.
val map = mapOf("Jan" to 5, "Anna" to 4)
// 1. Po parach (klucz, wartość) - najczęstszy sposób
for ((key, value) in map) {
println("$key -> $value")
}
// 2. Po kluczach (domyślnie, jeśli iterujesz po mapie)
for (key in map.keys) {
println("$key -> ${map[key]}")
}
// 3. Po wartościach
for (value in map.values) {
println(value)
}
// 4. Iteracja z indeksem (rzadziej używane dla map)
for ((index, entry) in map.withIndex()) {
println("$index: ${entry.key} -> ${entry.value}")
}
Przetwarzanie Funkcyjne (Transformacje)
Kotlin oferuje duży zestaw funkcji do przetwarzania kolekcji w stylu funkcyjnym. Zamiast pisać pętle for, opisujemy co chcemy zrobić z danymi.
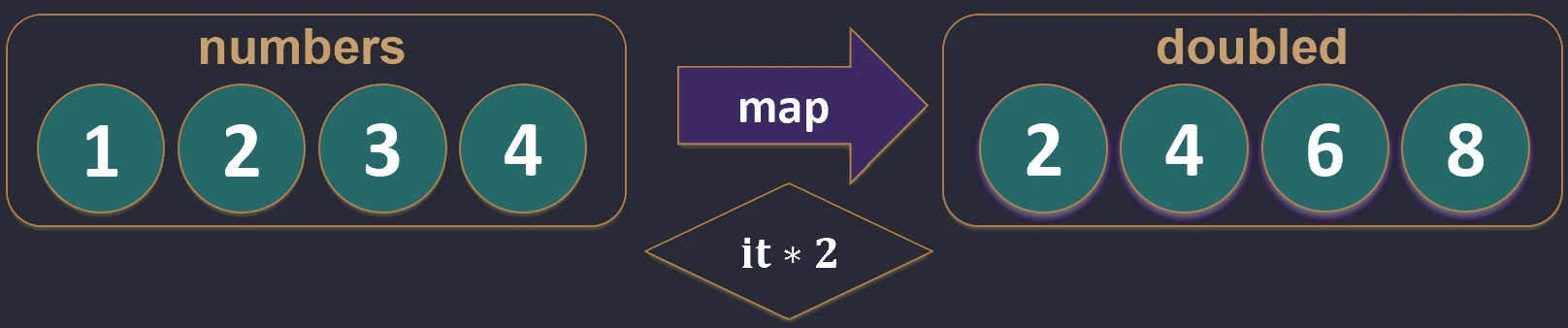
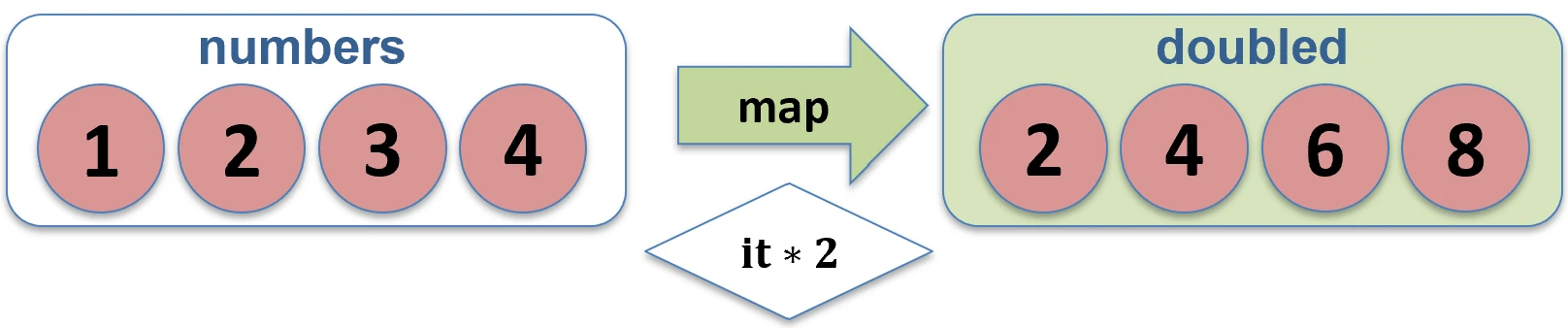
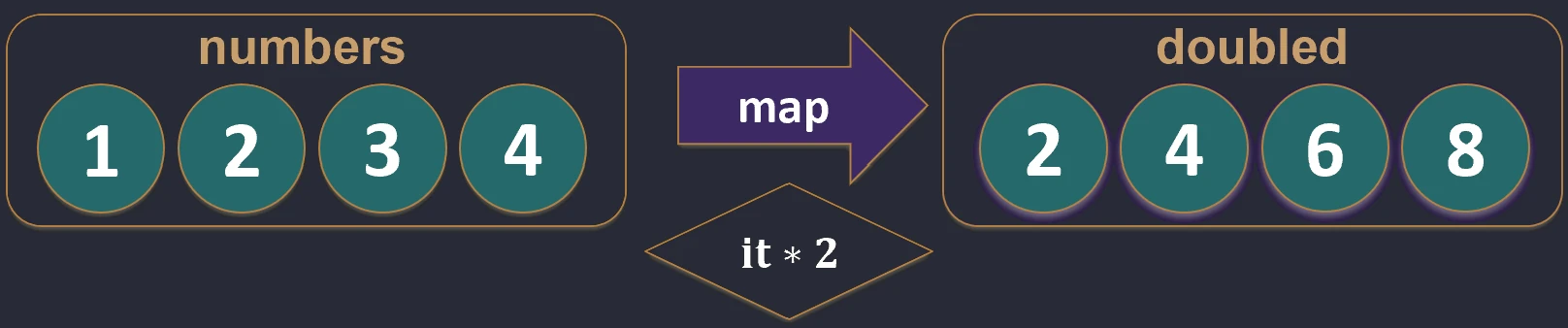
Mapowanie (map)
Przekształca każdy element kolekcji w inny element (potencjalnie innego typu). Wynikiem jest nowa lista o tej samej długości.
val numbers = listOf(1, 2, 3)
val doubled = numbers.map { it * 2 } // [2, 4, 6]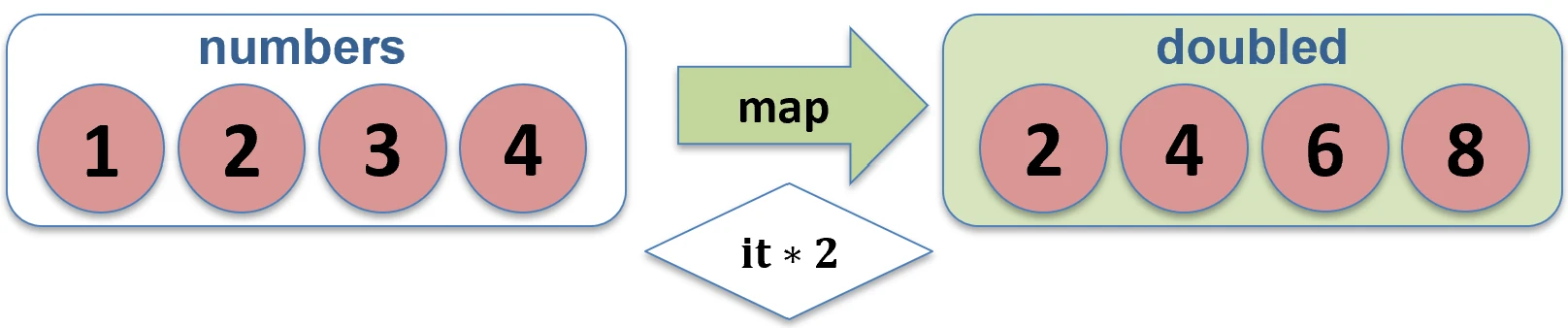
map.Dla Map istnieją dedykowane funkcje mapKeys i mapValues, które pozwalają transformować tylko klucz lub tylko wartość.
val map = mapOf("Jan" to 5, "Anna" to 4)
// Transformacja kluczy
val upperKeys = map.mapKeys { it.key.uppercase() } // {"JAN"=5, "ANNA"=4}
// Transformacja wartości
val doubledValues = map.mapValues { it.value * 2 } // {"Jan"=10, "Anna"=8}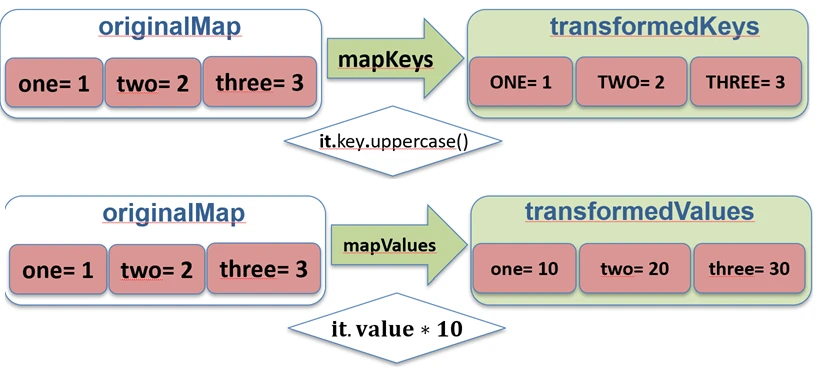
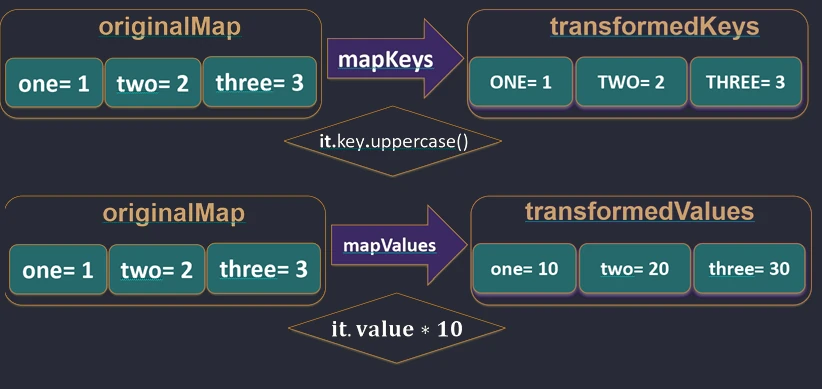
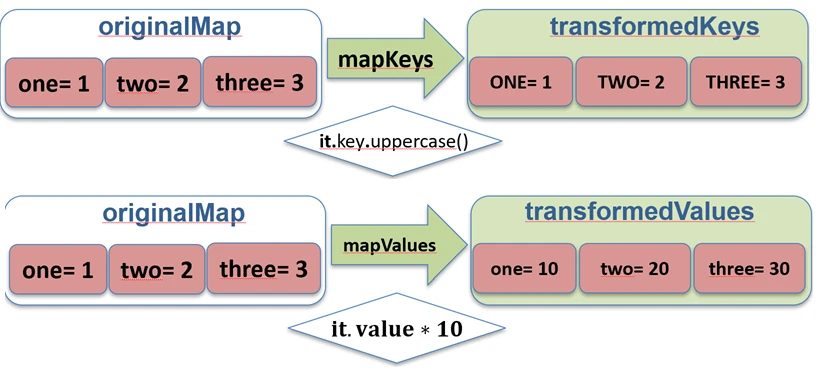
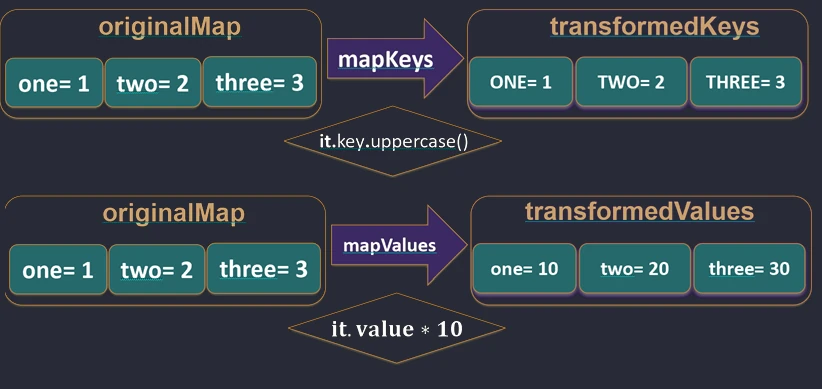
mapKeys i mapValues.Zippowanie (zip i unzip)
Tworzy pary z elementów dwóch kolekcji o tych samych indeksach. Jeśli kolekcje mają różne długości, wynikowa lista ma długość krótszej z nich.
val names = listOf("Jan", "Anna")
val ages = listOf(25, 30)
val pairs = names.zip(ages) // [(Jan, 25), (Anna, 30)]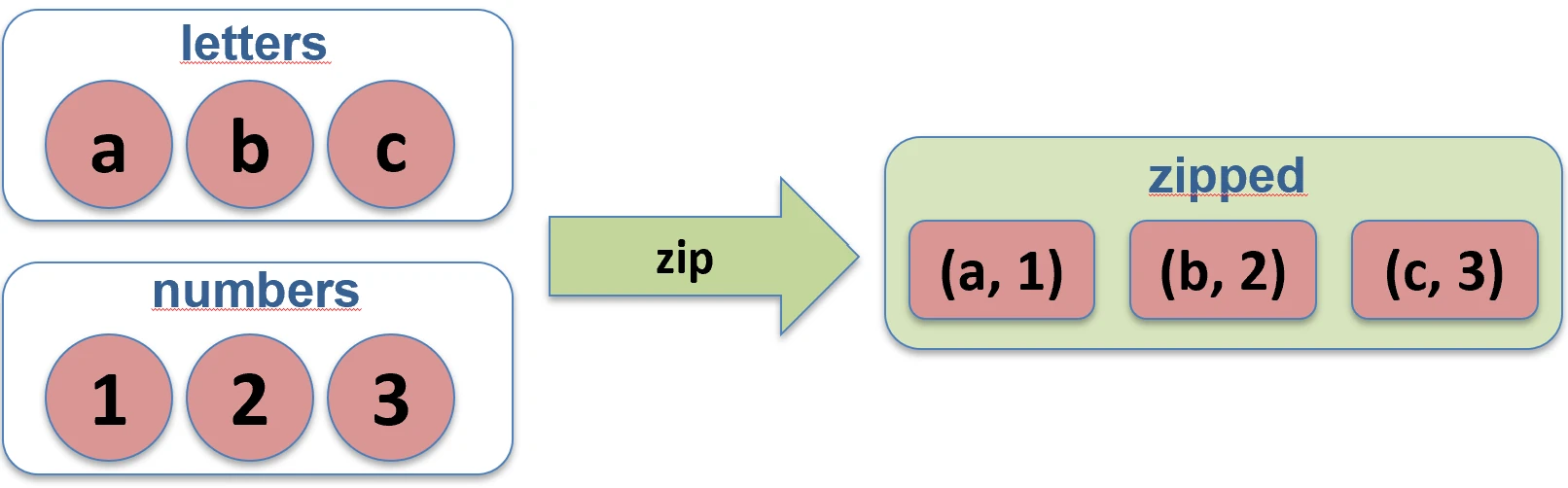
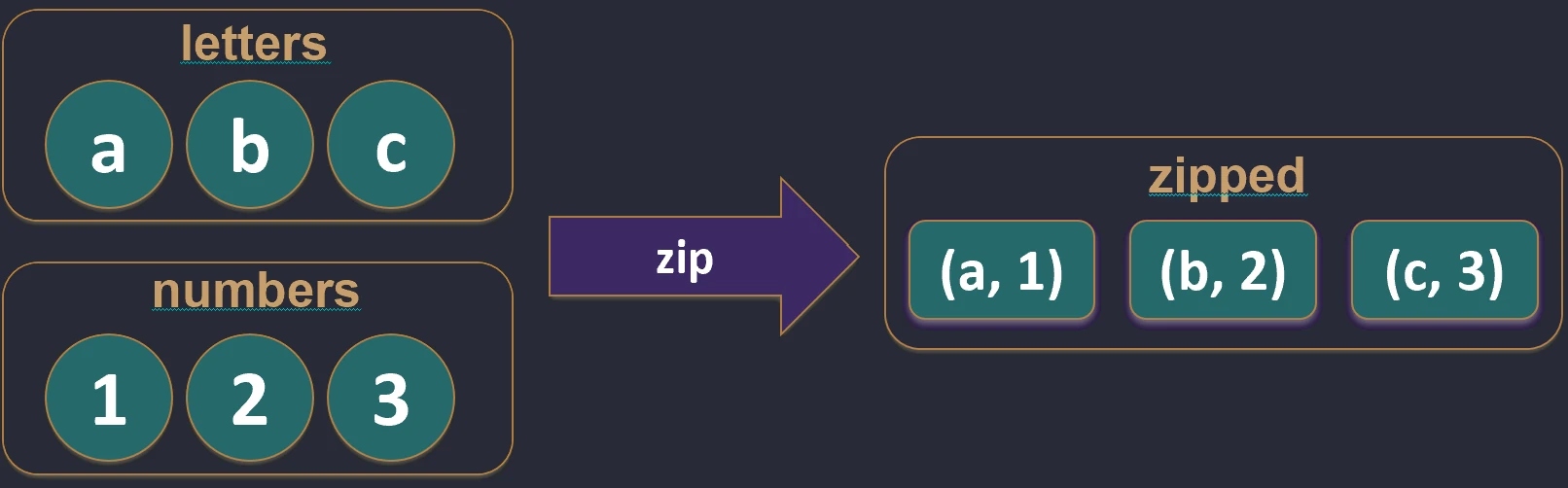
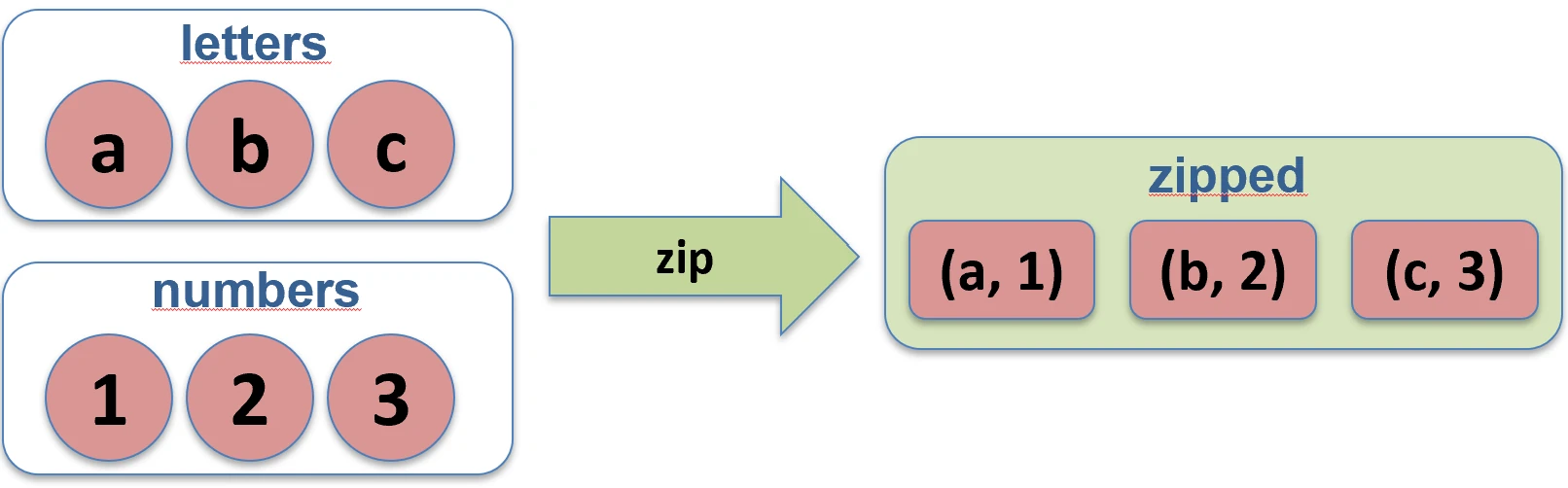
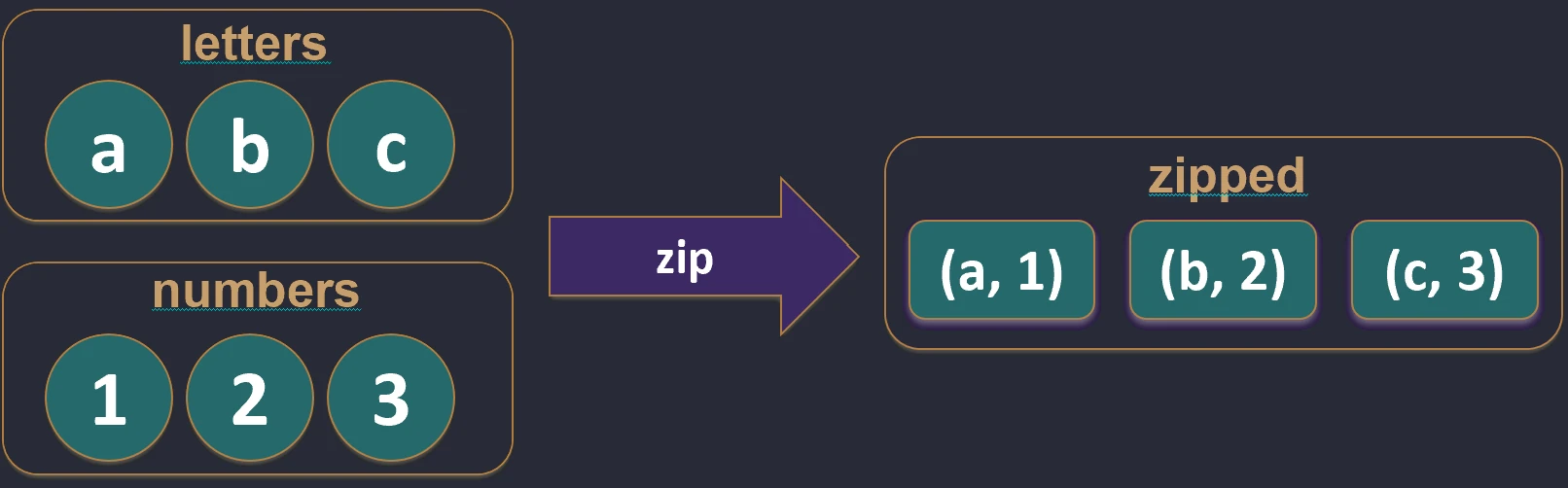
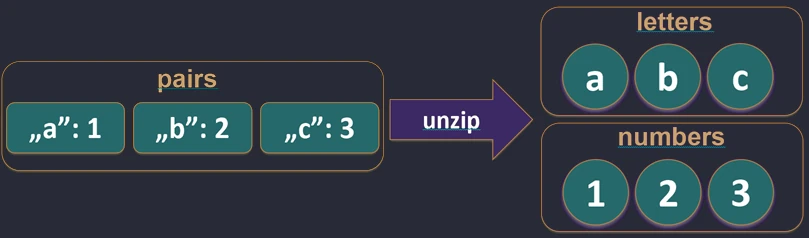
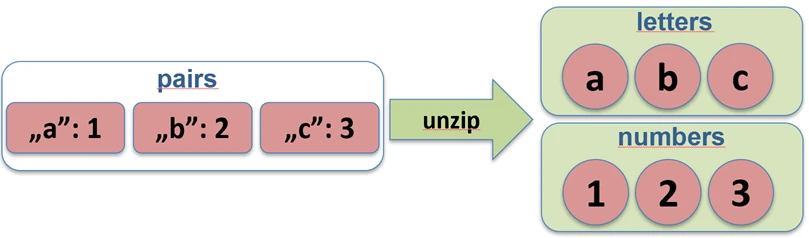
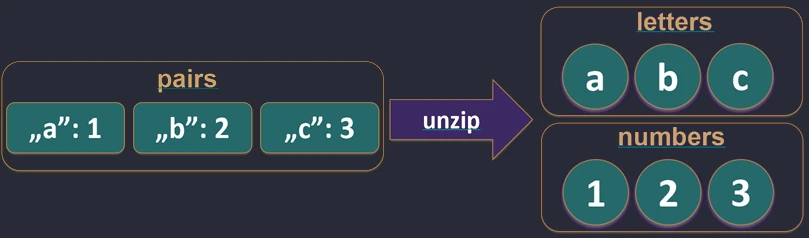
zip.Funkcja unzip robi operację odwrotną – rozdziela listę par na dwie osobne listy.
val pairs = listOf("Jan" to 25, "Anna" to 30)
val (names, ages) = pairs.unzip() // names=["Jan", "Anna"], ages=[25, 30]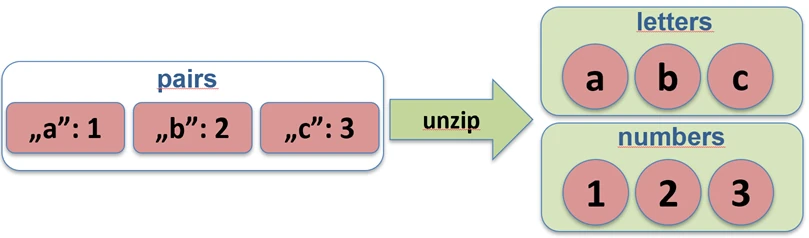
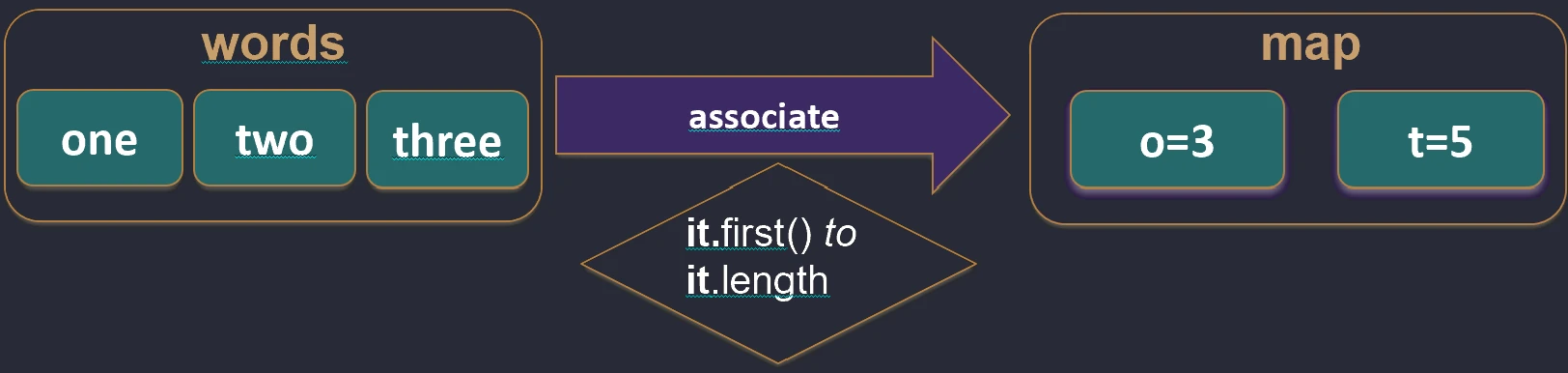
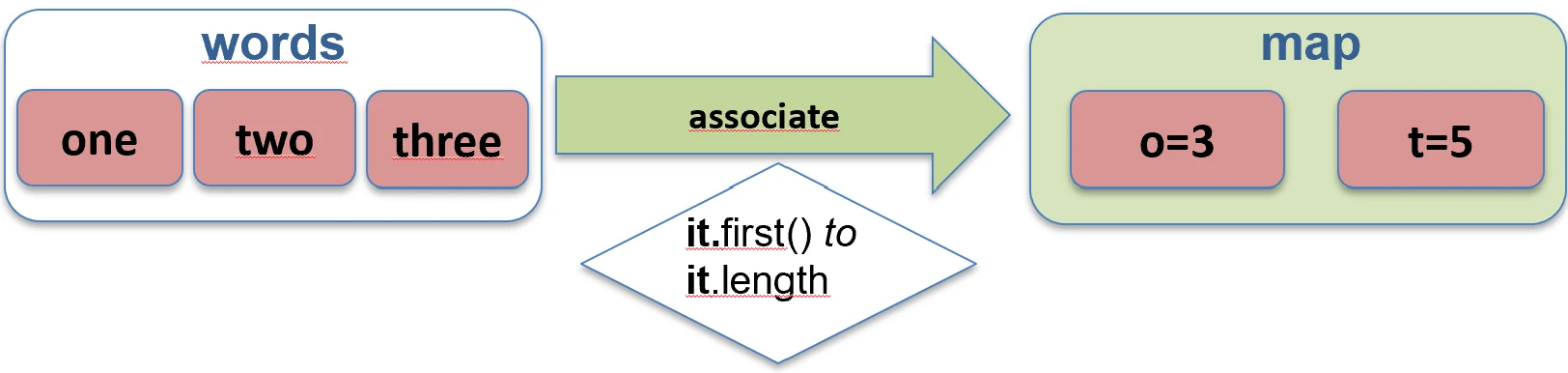
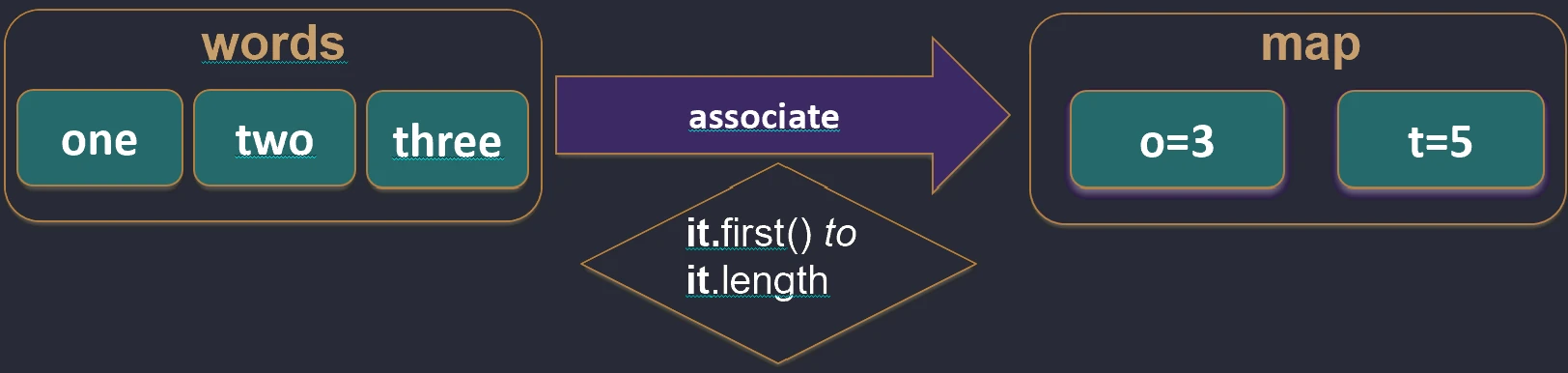
unzip.Asocjacje (associate)
Często chcemy zamienić listę obiektów w mapę, aby móc je szybko wyszukiwać np. po ID.
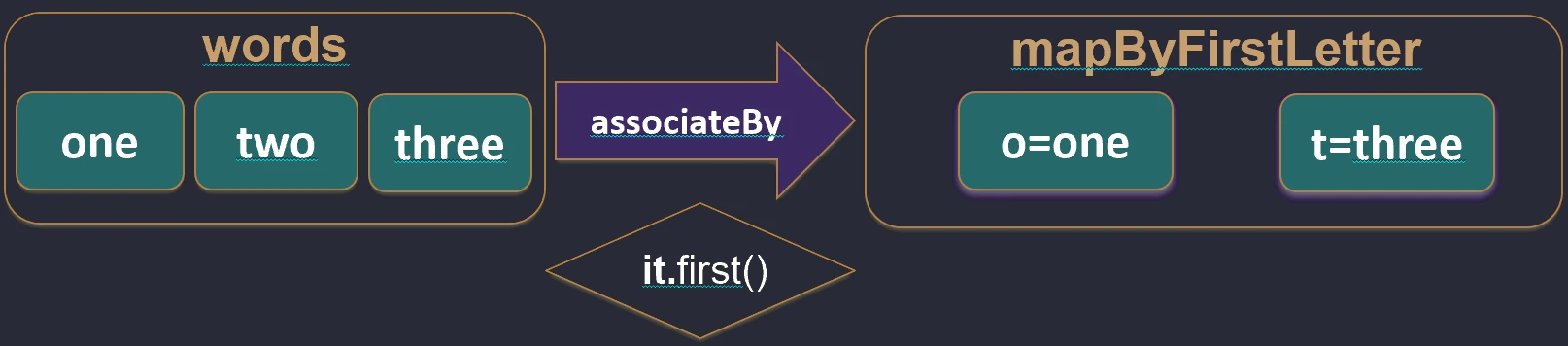
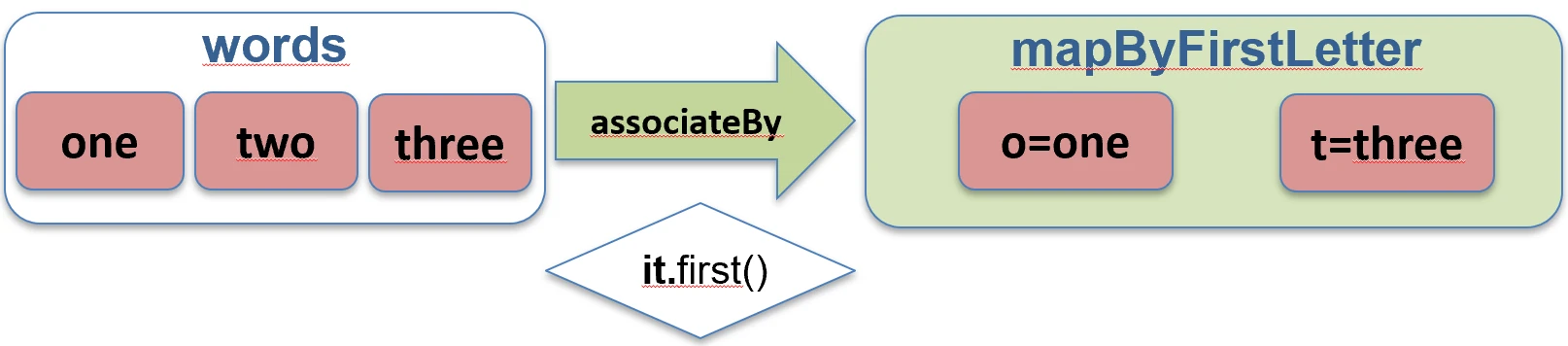
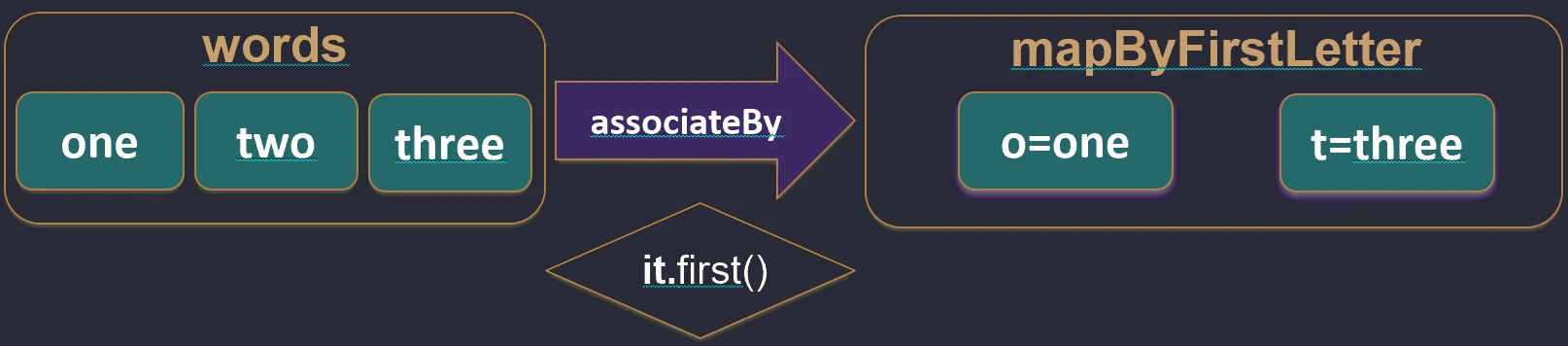
associateBy: Elementy listy stają się wartościami mapy, a my podajemy funkcję generującą klucz.
val users = listOf(User(1, "Jan"), User(2, "Anna"))
val mapById = users.associateBy { it.id } // Map<Int, User>: {1=User(Jan), 2=User(Anna)}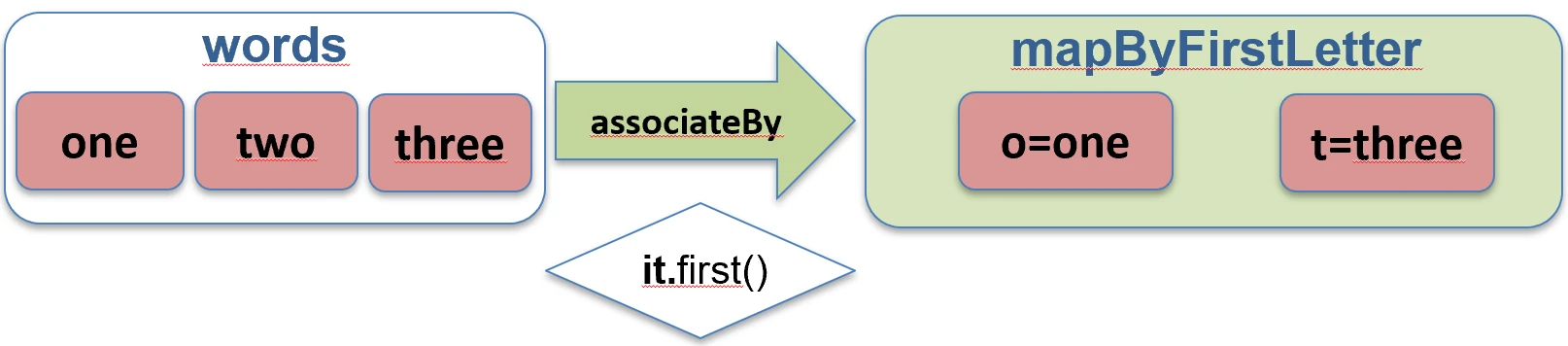
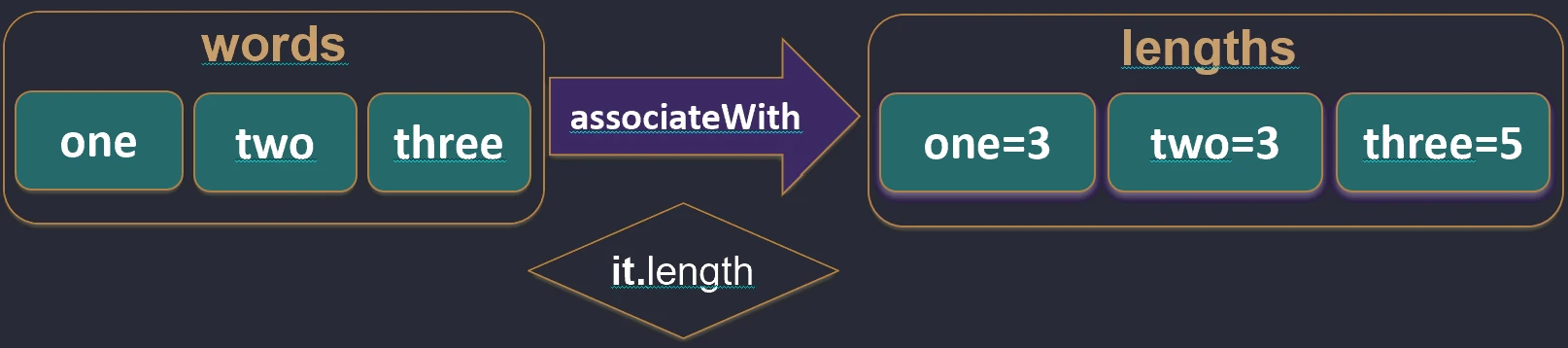
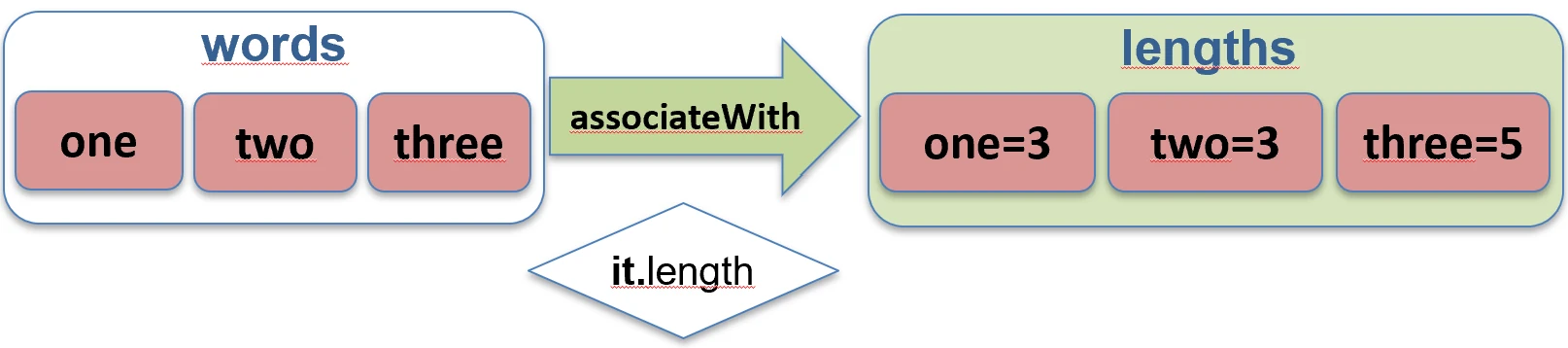
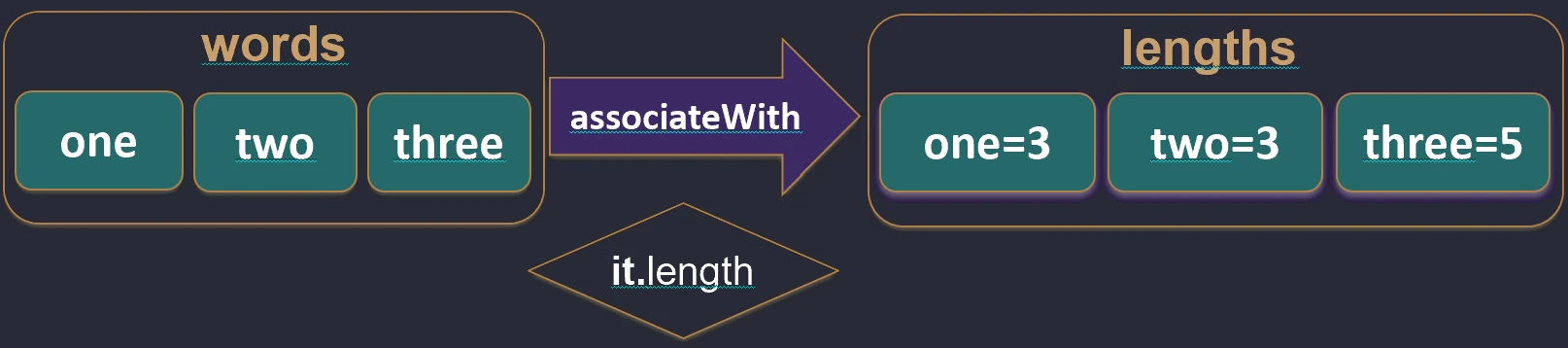
associateBy.associateWith: Elementy listy stają się kluczami, a my generujemy wartości.val items = listOf("A", "B")
val lengths = items.associateWith { it.length } // Map<String, Int>: {"A"=1, "B"=1}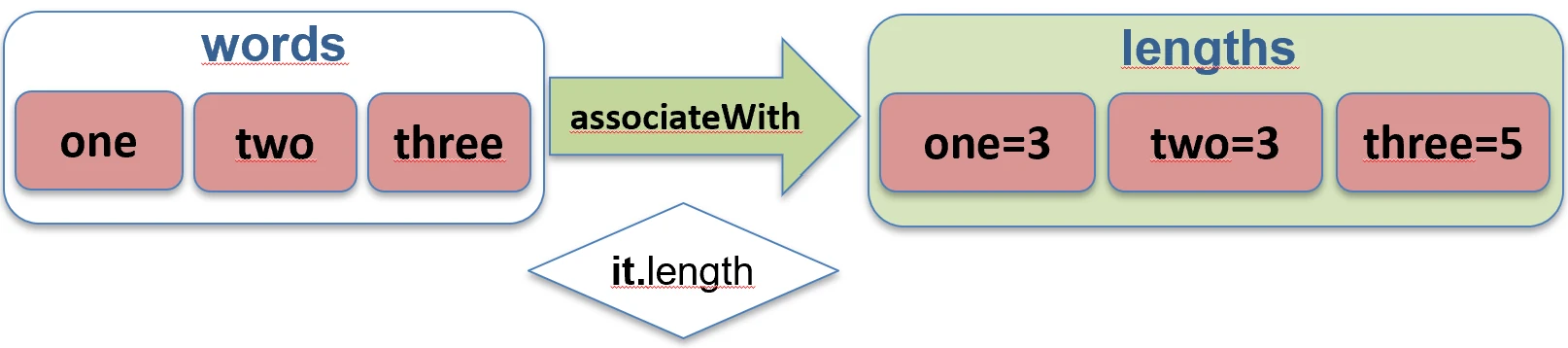
associateWith.associate: Elementy listy stają się kluczami i wartościami mapy, a my generujemy wartości.val items = listOf("A", "B")
val lengths = items.associate { it to it.length } // Map<String, Int>: {"A"=1, "B"=1}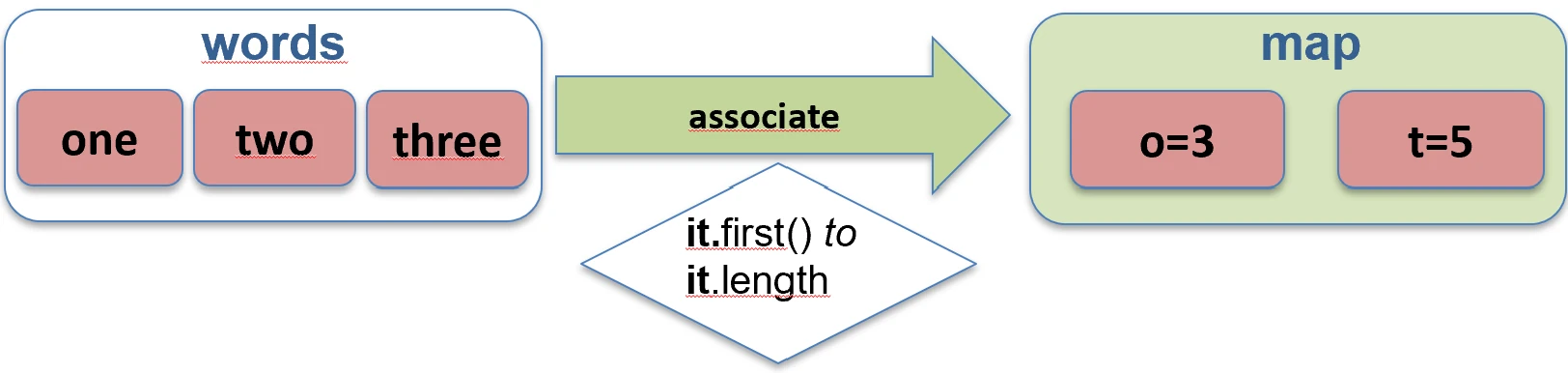
associate.Spłaszczanie (flatten i flatMap)
Gdy mamy kolekcję kolekcji (np. Listę List), często chcemy je połączyć w jedną płaską strukturę.
flatten(): Po prostu łączy zagnieżdżone listy.flatMap(): Najpierw przekształca każdy element w kolekcję (map), a potem spłaszcza wynik (flatten).
Wyobraź sobie, że masz listę pudełek (elementów), a w każdym pudełku jest kilka cukierków.
mapto pomalowanie każdego pudełka na inny kolor (nadal masz listę pudełek).flatMapto wysypanie cukierków ze wszystkich pudełek na jeden duży stół. Nie masz już pudełek, tylko jedną długą listę cukierków.




flatten.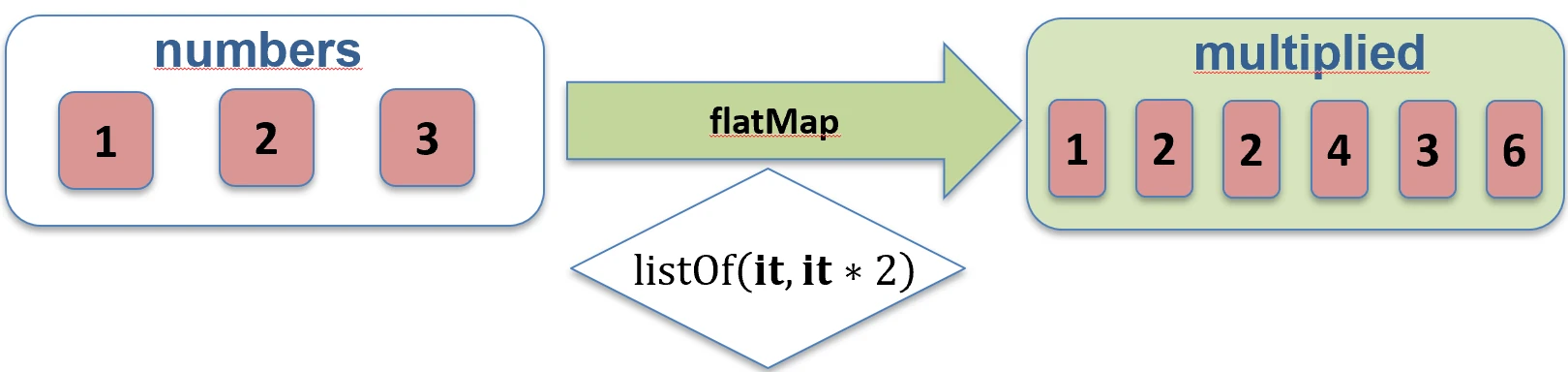
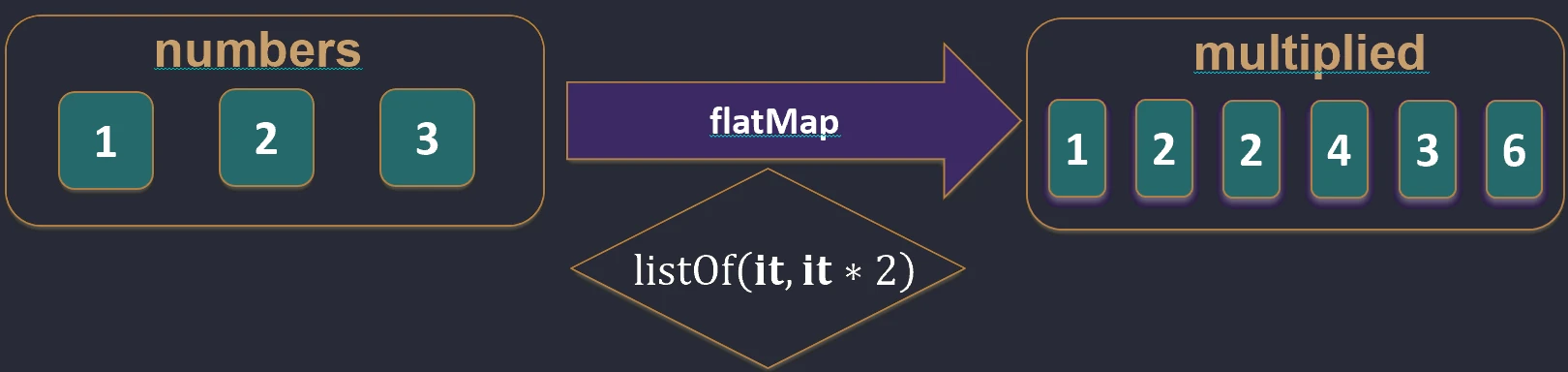
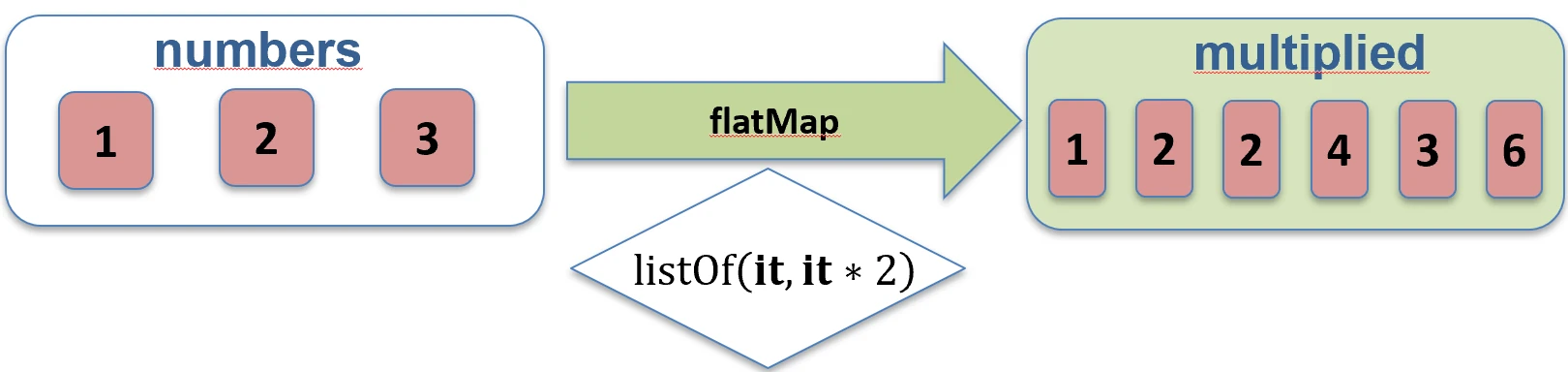
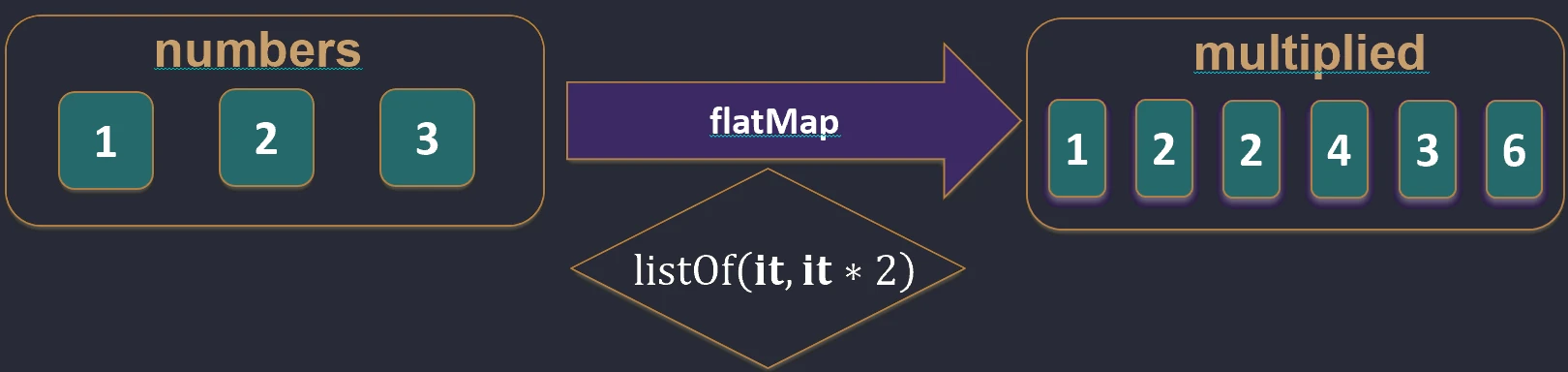
flatMap.Filtrowanie i Wyszukiwanie
Filtrowanie
Wybieranie elementów spełniających warunek (predykat).
filter { ... }: Zwraca elementy, dla których predykat jesttrue.
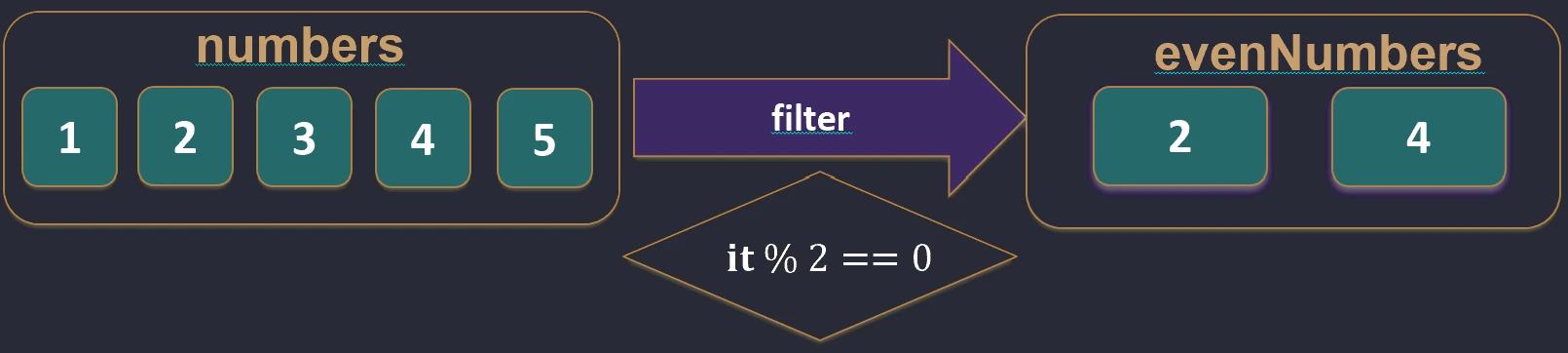
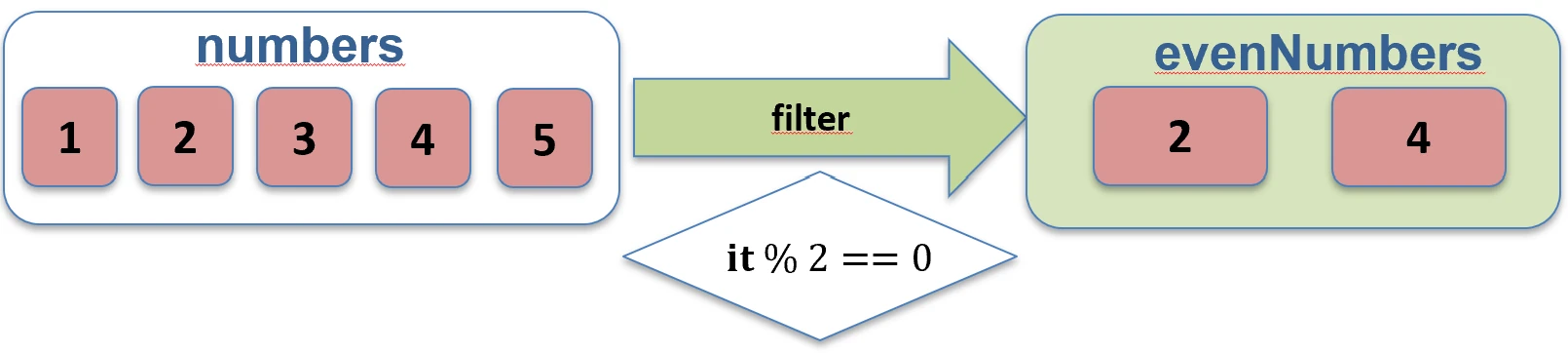
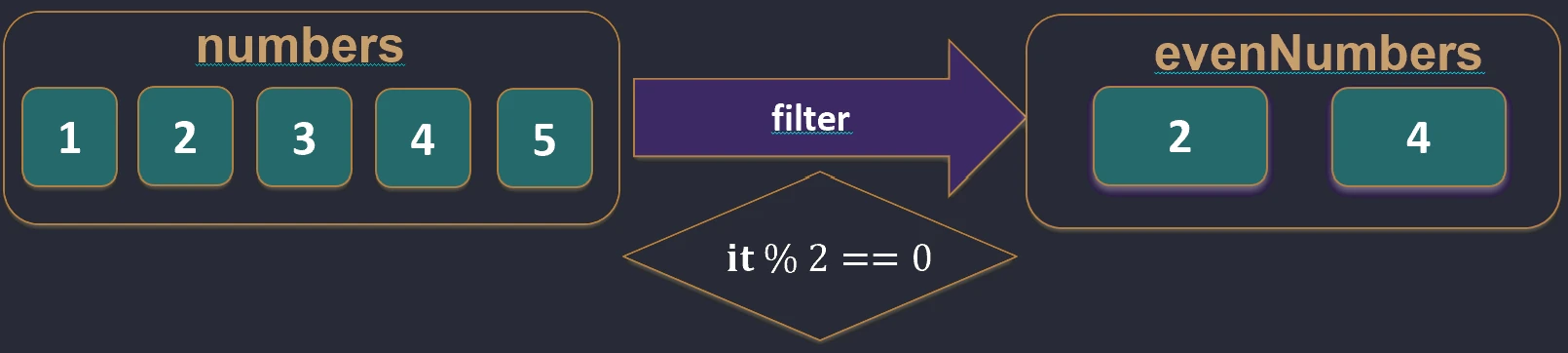
val numbers = listOf(1, 2, 3, 4)
val evens = numbers.filter { it % 2 == 0 } // [2, 4]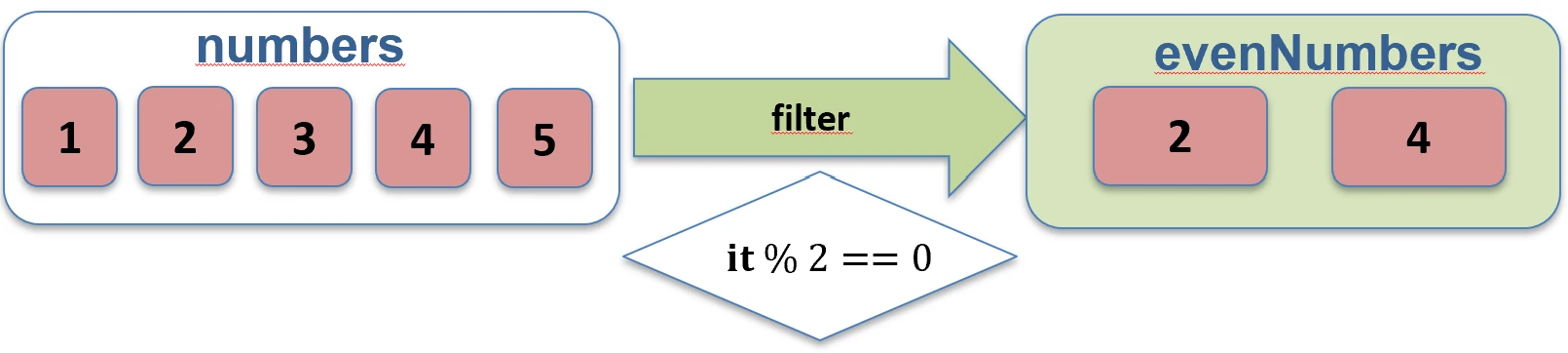
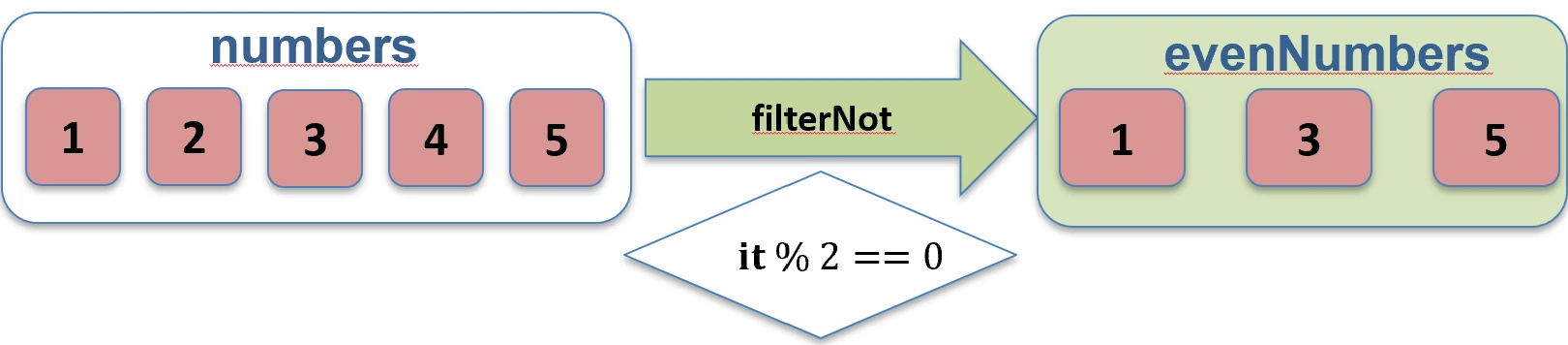
filter.filterNot { ... }: Zwraca elementy, dla których predykat jest false.val numbers = listOf(1, 2, 3, 4)
val odds = numbers.filterNot { it % 2 == 0 } // [1, 3]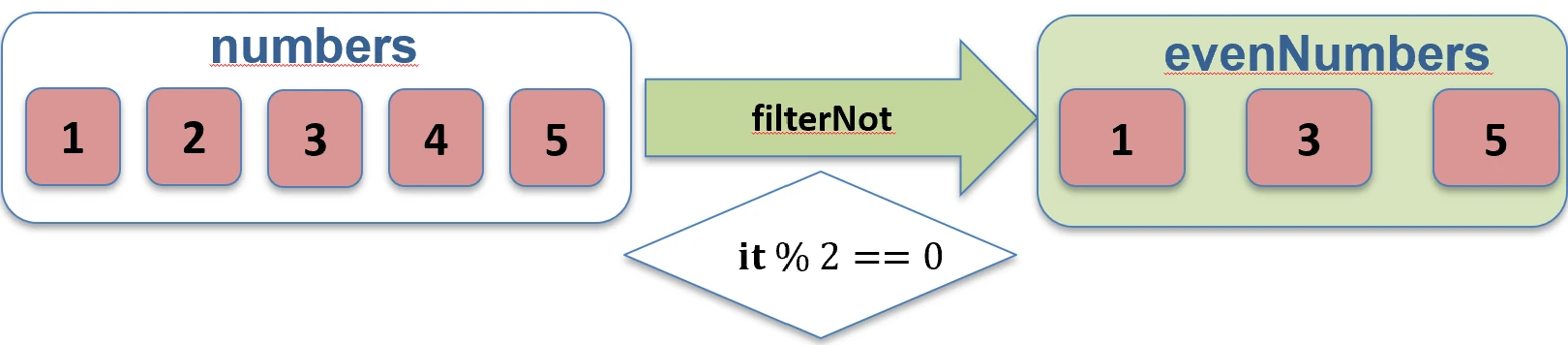


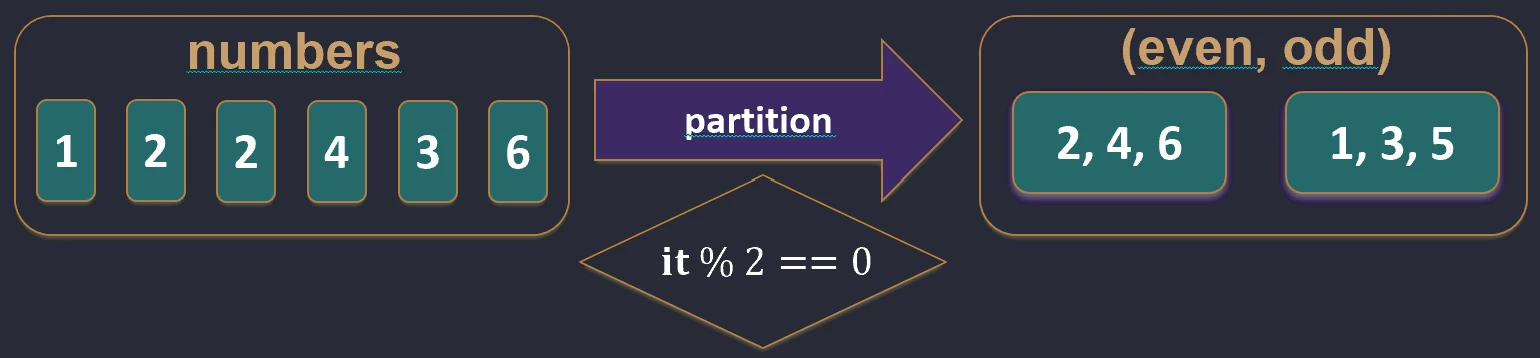
filterNot.partition { ... }: Dzieli kolekcję na dwie listy (Para): tych co spełniają i tych co nie spełniają warunku. Bardzo przydatne, gdy potrzebujemy obu grup.val (even, odd) = listOf(1, 2, 3, 4).partition { it % 2 == 0 }
// even: [2, 4], odd: [1, 3]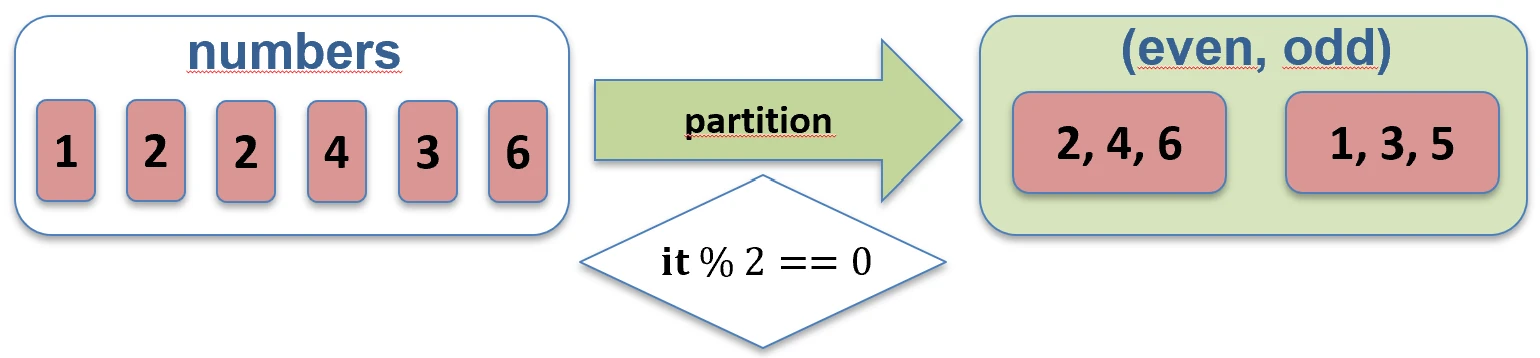
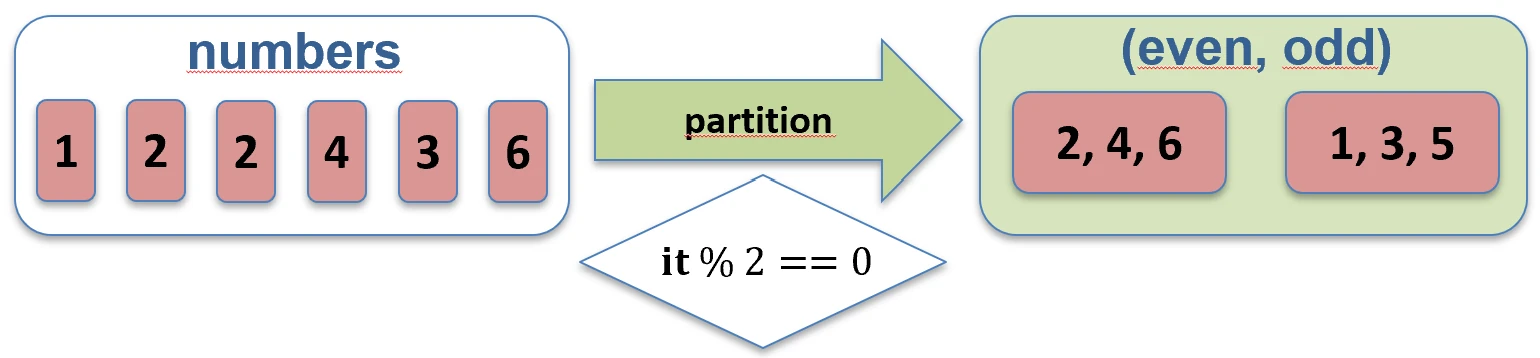
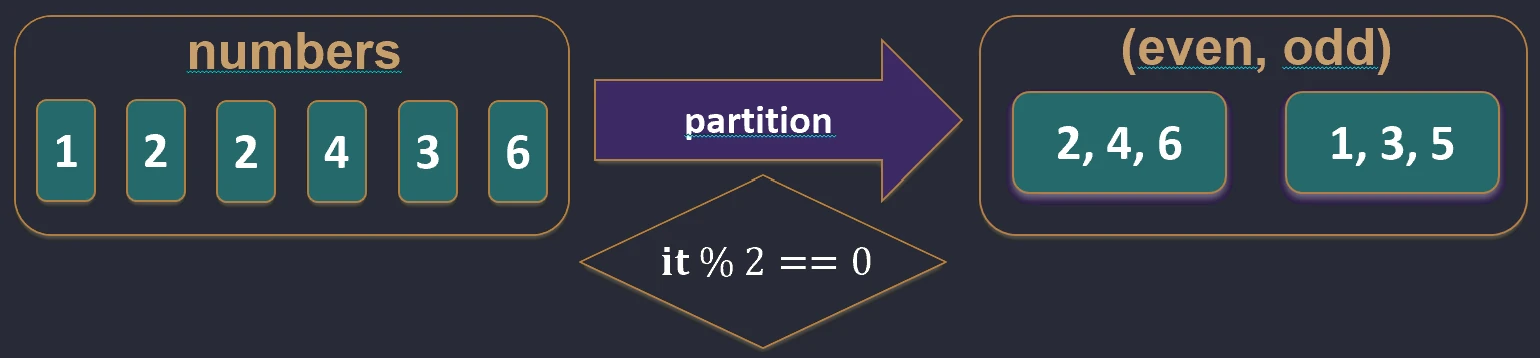
partition.Testowanie (Predykaty)
Zamiast filtrować, możemy sprawdzić, czy elementy spełniają warunki:
any { ... }: Czy przynajmniej jeden element spełnia warunek?all { ... }: Czy wszystkie elementy spełniają warunek?none { ... }: Czy żaden element nie spełnia warunku?
Grupowanie (groupBy)
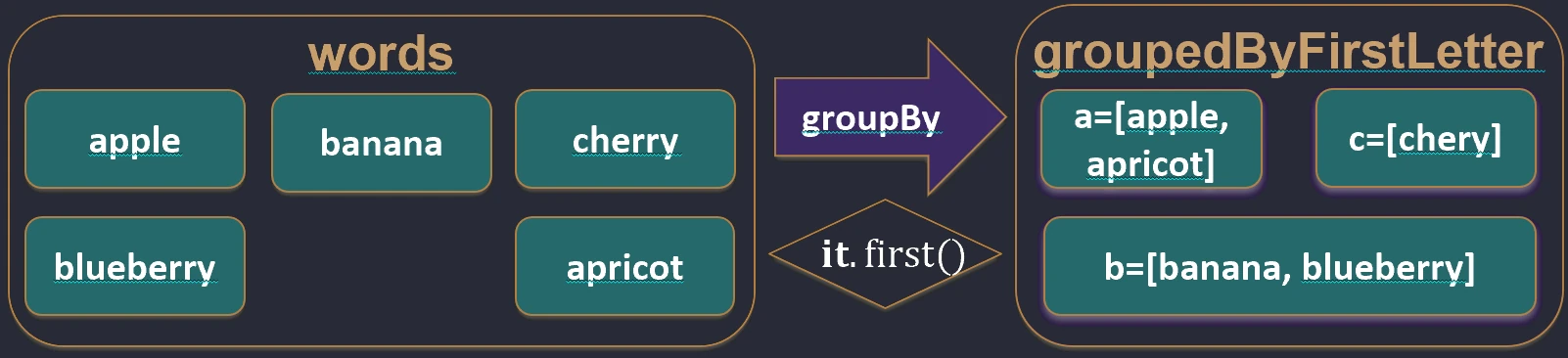
Dzieli kolekcję na grupy według pewnego klucza. Wynikiem jest mapa, gdzie kluczem jest cecha, po której grupujemy, a wartością lista elementów posiadających tę cechę.
val words = listOf("apple", "apricot", "banana", "cherry")
val byFirstLetter = words.groupBy { it.first() }
// Map<Char, List<String>>:
// 'a' -> ["apple", "apricot"]
// 'b' -> ["banana"]
// 'c' -> ["cherry"]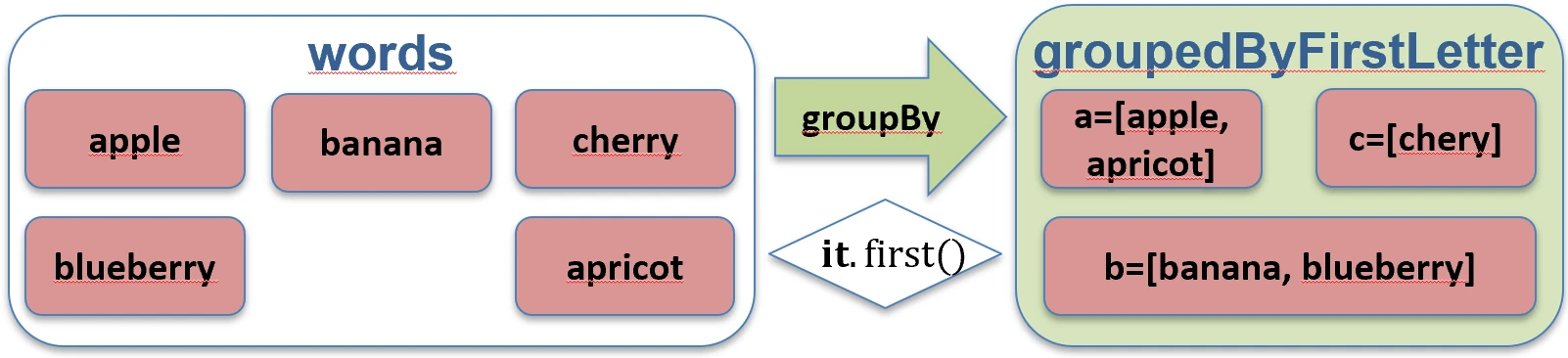
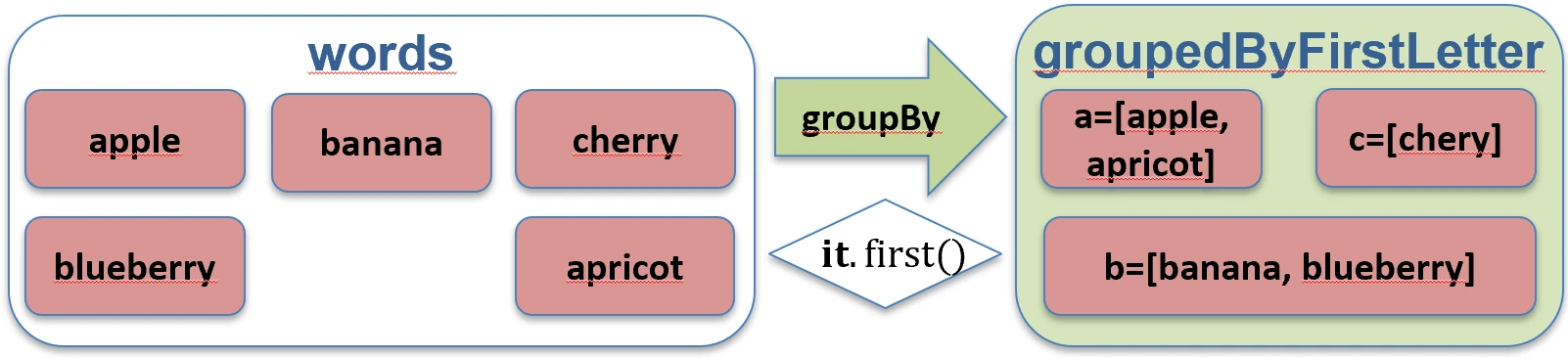
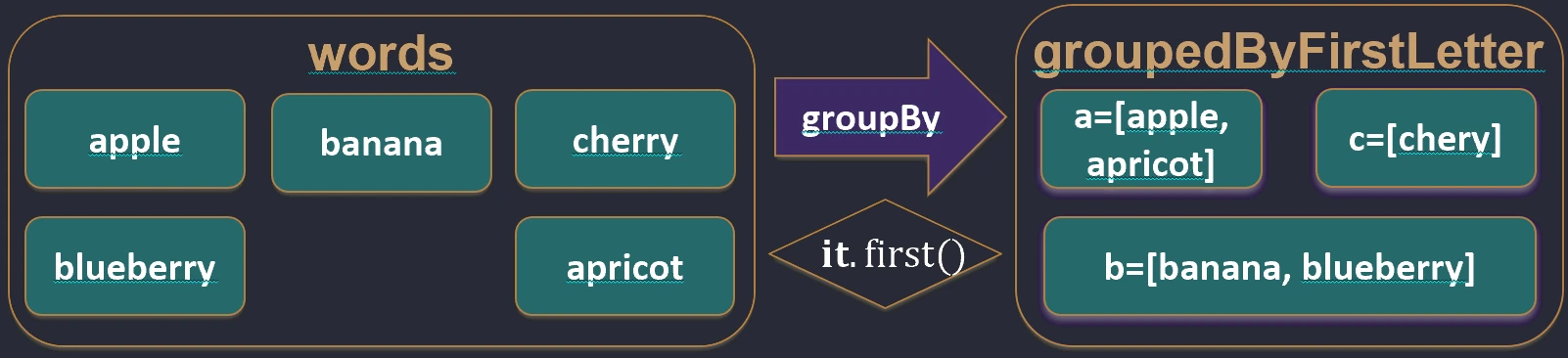
groupBy.Deklaracja Destrukturyzująca (Destructuring Declarations)
Pozwala na rozpakowanie obiektu na zmienne składowe. Działa to dla klas danych (data class), par (Pair), trójek (Triple) oraz map.
val (name, age) = Person("Jan", 30) // Person musi być data class
val pair = "A" to 1
val (letter, number) = pair
// Iteracja po mapie
for ((key, value) in map) {
println("$key -> $value")
}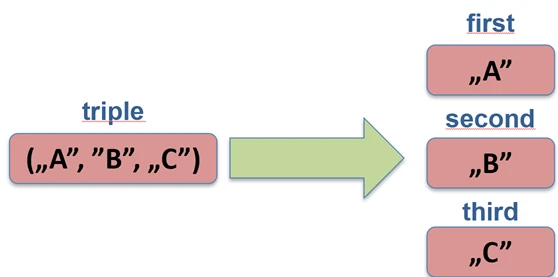
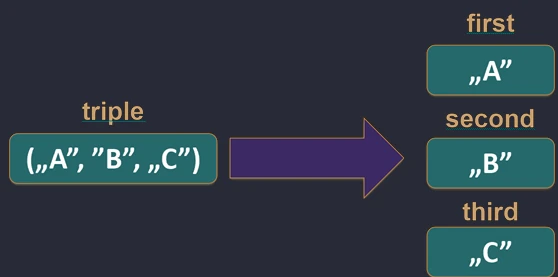
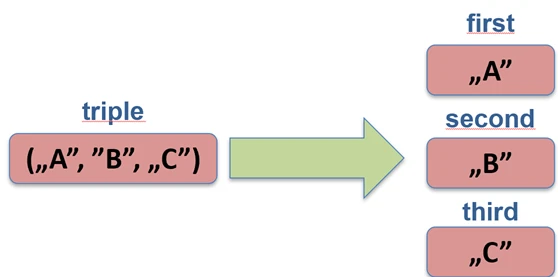
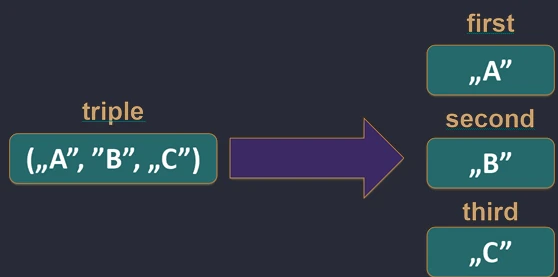
Pod spodem kompilator wywołuje metody component1(), component2() itd.
Programowanie obiektowe (OOP) opiera się na koncepcji klas i obiektów. Klasa to szablon (blueprint), który definiuje strukturę i zachowanie. Obiekt to konkretna instancja stworzona na podstawie tego szablonu.
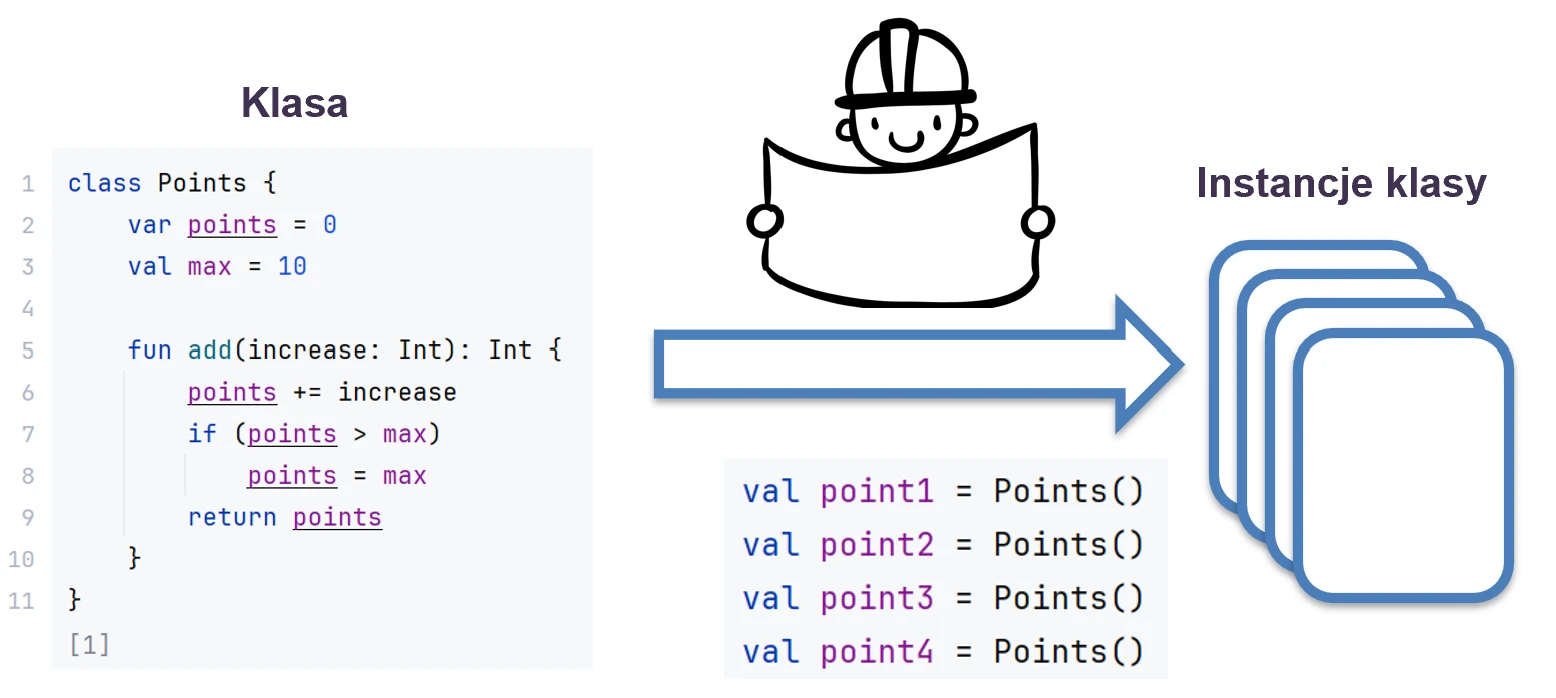
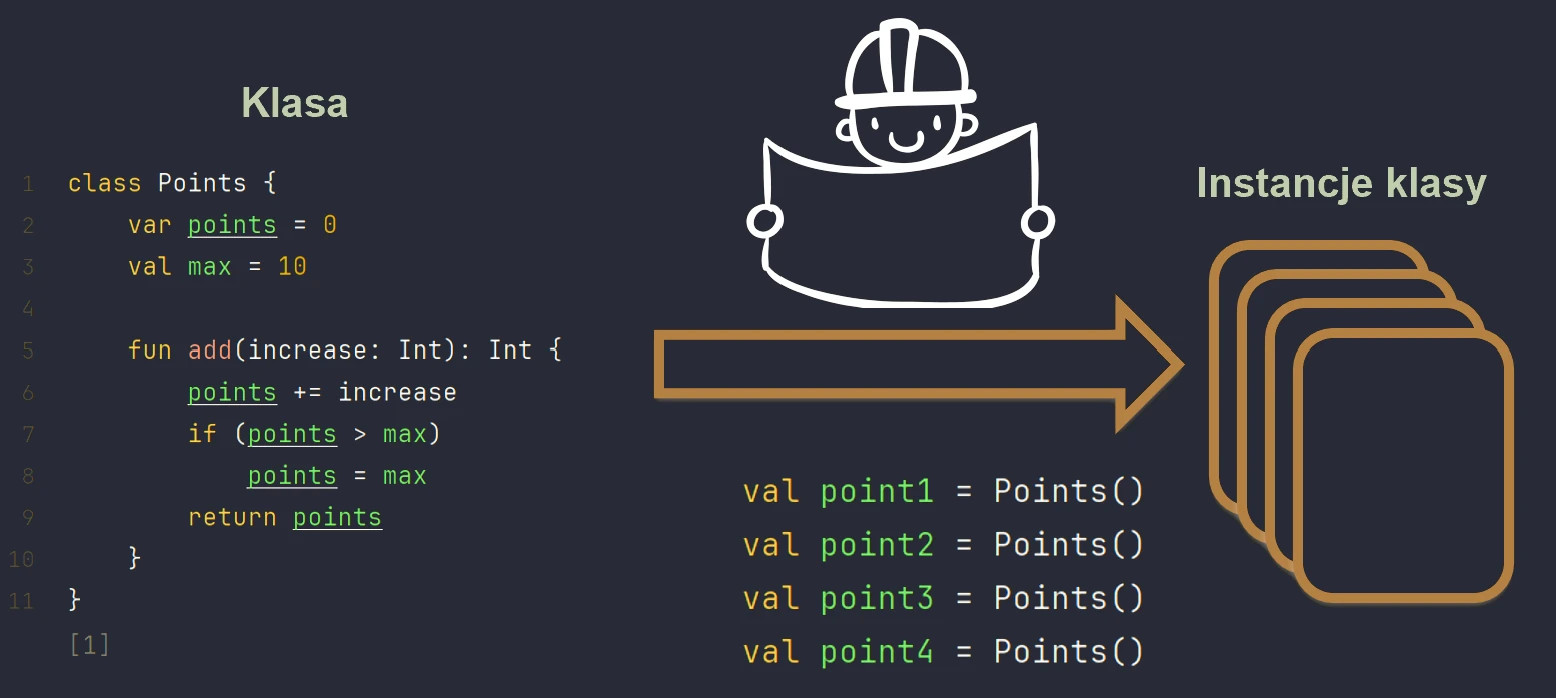
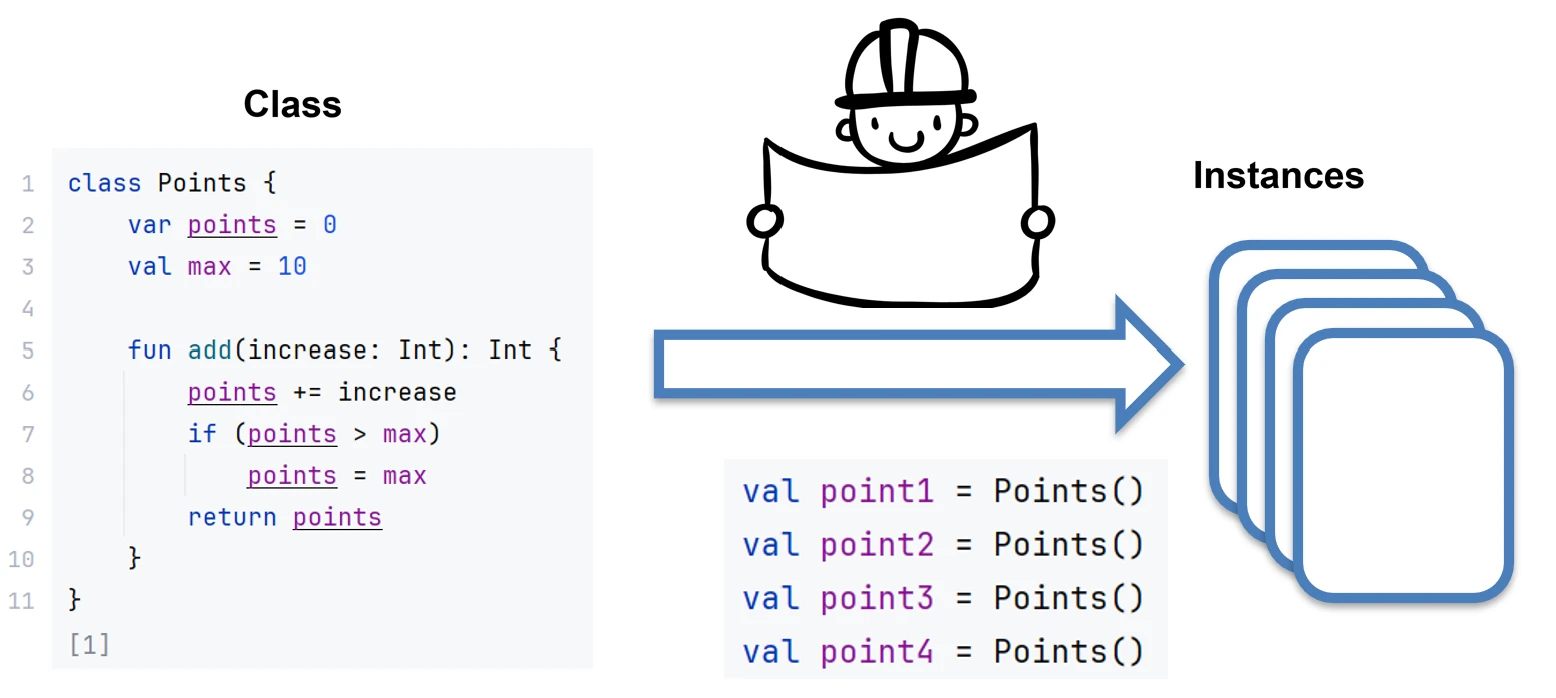
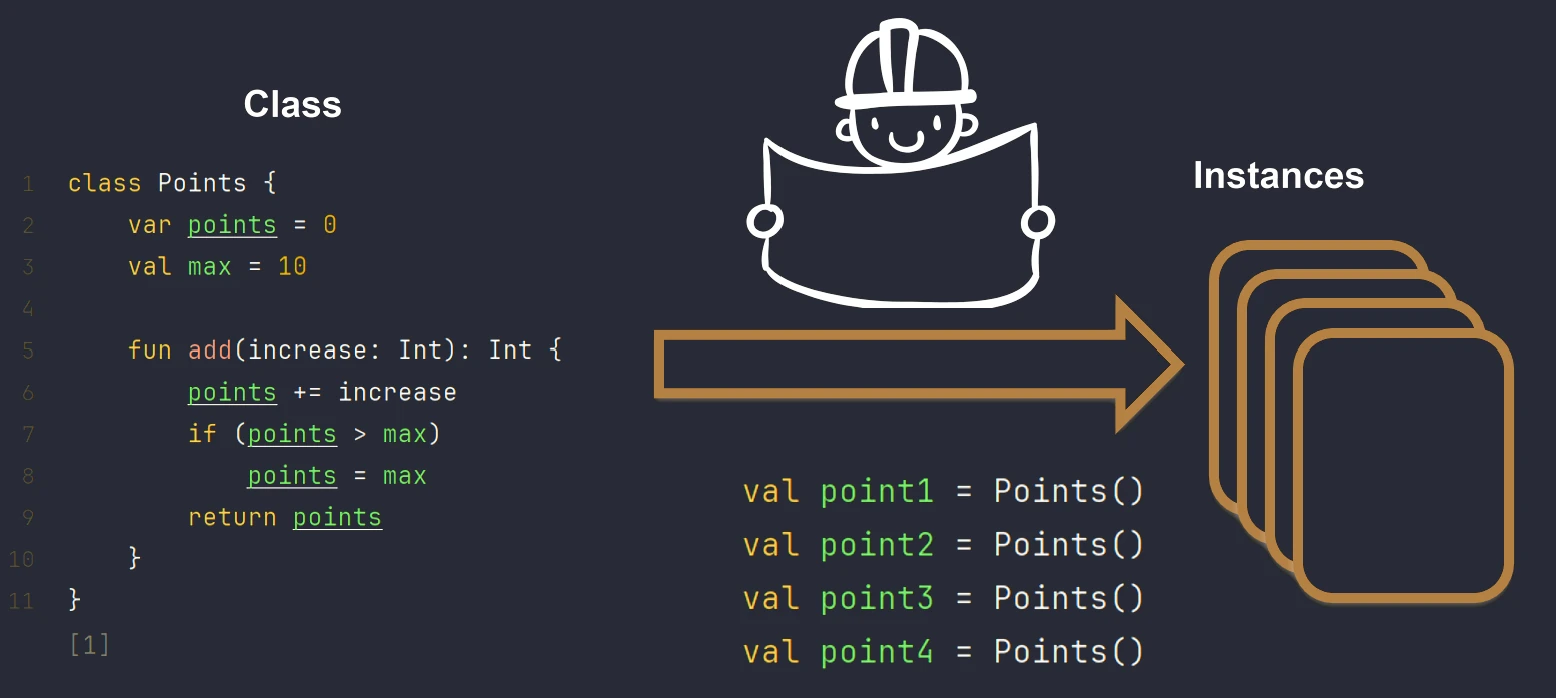
Możemy to sobie wyobrazić na przykładzie domu.
- Klasa to projekt architektoniczny (rysunków technicznych) domu.
- Obiekt to konkretny dom wybudowany na podstawie tego projektu. Możesz wybudować wiele domów (obiektów) z jednego projektu (klasy).
Definicja Klasy
W Kotlinie definicja klasy jest bardzo zwięzła. Jeśli klasa nie ma ciała, możemy pominąć nawiasy klamrowe.
class EmptyZazwyczaj jednak klasa posiada właściwości (stan) oraz funkcje (zachowanie).
class Lamp {
// Właściwość (stan)
var isOn: Boolean = false
// Metoda (zachowanie)
fun turnOn() {
isOn = true
}
}Tworzenie instancji w Kotlinie nie wymaga słowa kluczowego new (znanego z Javy czy C++). Po prostu wywołujemy konstruktor jak funkcję:
val myLamp = Lamp()
myLamp.turnOn()Konstruktory
Kotlin rozróżnia dwa rodzaje konstruktorów: główny (primary) i drugorzędne (secondary).
Konstruktor główny jest częścią definicji klasy. To najbardziej idiomatyczny sposób definiowania klas.
// Zapis skrócony - deklaracja właściwości wprost w konstruktorze
class Person(val name: String, var age: Int)
// To, co powyżej, jest równoważne:
/*
class Person(_name: String, _age: Int) {
val name: String = _name
var age: Int = _age
}
*/Jeśli potrzebujemy wykonać kod podczas inicjalizacji (np. walidację), używamy bloku init. Konstruktor główny nie może zawierać kodu.
class User(val login: String) {
init {
println("Tworzenie użytkownika: $login")
if (login.isEmpty()) {
throw IllegalArgumentException("Login nie może być pusty")
}
}
}Czasami potrzebujemy alternatywnych sposobów tworzenia obiektu. Używamy wtedy słowa kluczowego constructor wewnątrz ciała klasy. Każdy konstruktor drugorzędny musi ostatecznie wywołać konstruktor główny (używając this(...)). W odróżnieniu od kontruktora głównego, konstruktor drugorzędny może zawierać kod. Jest to przydatne, gdy chcemy stworzyć obiekt na podstawie innych danych niż te, które są przekazywane do konstruktora głównego. Nie ma możliwści automatycznego deklarowania właściwości w konstruktorze drugorzędnym, dlatego musimy to zrobić ręcznie. Warto również zauważyć, że konstruktor drugorzędny nie może być wywoływany bezpośrednio z zewnątrz klasy, a jedynie z poziomu konstruktora głównego lub innego konstruktora drugorzędnego. W praktyce w Kotlinie rzadko używa się konstruktorów drugorzędnych, ponieważ mechanizm wartości domyślnych w konstruktorze głównym pokrywa większość przypadków użycia (np. przeciążanie konstruktorów w Javie).
class Rect(val width: Int, val height: Int) {
// Konstruktor pomocniczy dla kwadratu
constructor(side: Int) : this(side, side) {
println("Utworzono kwadrat o boku $side")
}
}Modyfikatory Dostępu
Określają, kto widzi nasze klasy, metody i właściwości.
public(domyślny): Widoczne wszędzie.private: Widoczne tylko wewnątrz pliku (dla funkcji/klas najwyższego poziomu) lub wewnątrz klasy.protected: Widoczne w klasie i jej podklasach (nie ma dostępu pakietowego jak w Javie!).internal: Widoczne w całym module (np. module Mavena, Gradle'a, czy module IntelliJ). To specyfika Kotlina – bardzo przydatne do ukrywania szczegółów implementacyjnych biblioteki.
Klasy Danych (Data Classes)
Często tworzymy klasy, których jedynym celem jest przechowywanie danych (DTO - Data Transfer Object). W Kotlinie mamy specjalny rodzaj klas do tego celu, które oznaczamy słowem kluczowym data class.
data class User(val name: String, val age: Int)Dzięki temu jednemu słowu, kompilator automatycznie generuje dla nas:
toString(): Zwraca czytelny ciąg np."User(name=Jan, age=30)".equals(): Porównuje zawartość pól (a nie referencje).hashCode(): Generuje poprawny hash na podstawie pól.copy(): Pozwala skopiować obiekt zmieniając tylko wybrane pola (niezastąpione przy niemutowalności!).componentN(): Metody umożliwiające destrukturyzację (val (n, a) = user).
Zastosowanie tych metod eliminuje konieczność ręcznego pisania powtarzalnego kodu (boilerplate), co znacząco poprawia czytelność i bezpieczeństwo aplikacji. Metody te są szczególnie przydatne w architekturach opartych na niemutowalności danych, gdzie zamiast modyfikować istniejący obiekt, tworzymy jego kopię ze zmienionymi parametrami.
val u1 = User("Jan", 25)
val u2 = u1.copy(age = 26) // User(name="Jan", age=26)
println(u1 == u2) // falseKonstruktor główny musi mieć co najmniej jeden parametr i wszystkie muszą być oznaczone jako val lub var. Klasy danych nie mogą być dziedziczone (są final).
Porównywanie Obiektów
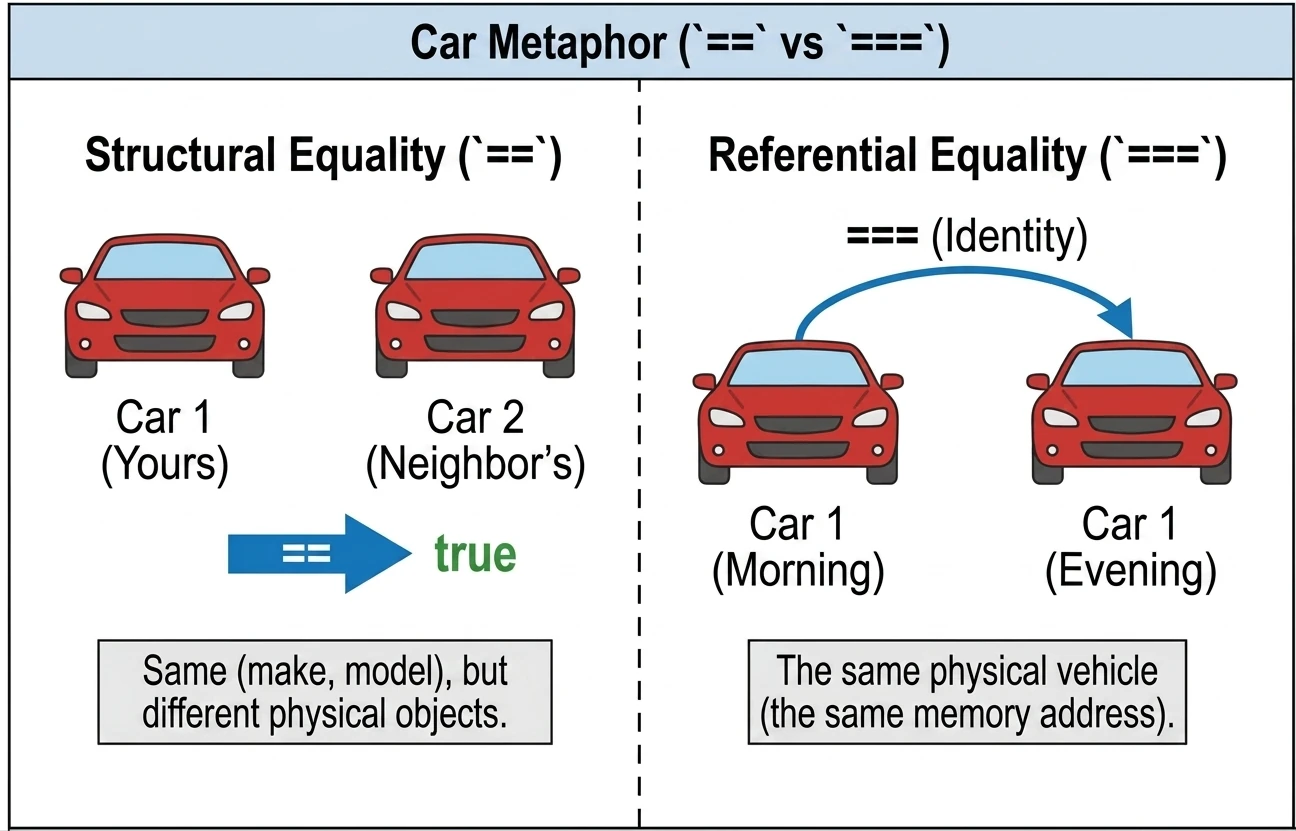
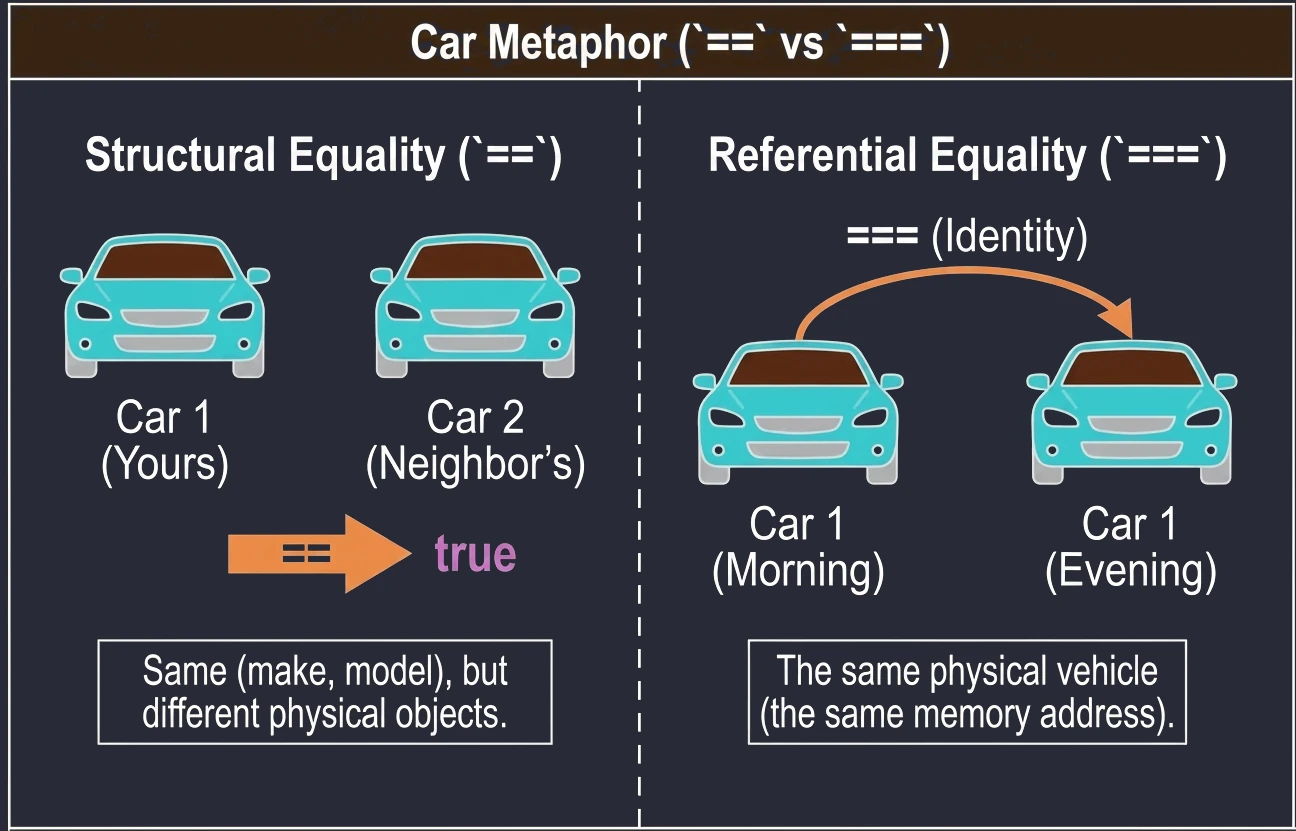
W Kotlinie mamy dwa rodzaje równości:
- Równość Strukturalna (
==): Sprawdza, czy obiekty są takie same (mają taką samą zawartość). Pod spodem wywołujeequals(). To bezpieczne dla null (np.null == nullzwróci true). - Równość Referencyjna (
===): Sprawdza, czy dwie zmienne wskazują na ten sam obiekt w pamięci (ten sam adres).
Zachowanie operatora == zależy od tego, czy pracujemy ze zwykłą klasą, czy z data class. W zwykłej klasie == sprawdza referencję (chyba że ręcznie nadpiszemy equals()), natomiast w data class porównuje zawartość pól.
class Person(val name: String, val age: Int)
data class User(val name: String, val age: Int)
val p1 = Person("Ewa", 30)
val p2 = Person("Ewa", 30)
println(p1 == p2) // false (zwykła klasa porównuje adresy)
val u1 = User("Ewa", 30)
val u2 = User("Ewa", 30)
val u3 = u1
println(u1 == u2) // true (data class porównuje zawartość)
println(u1 === u2) // false (dwa różne obiekty w pamięci)
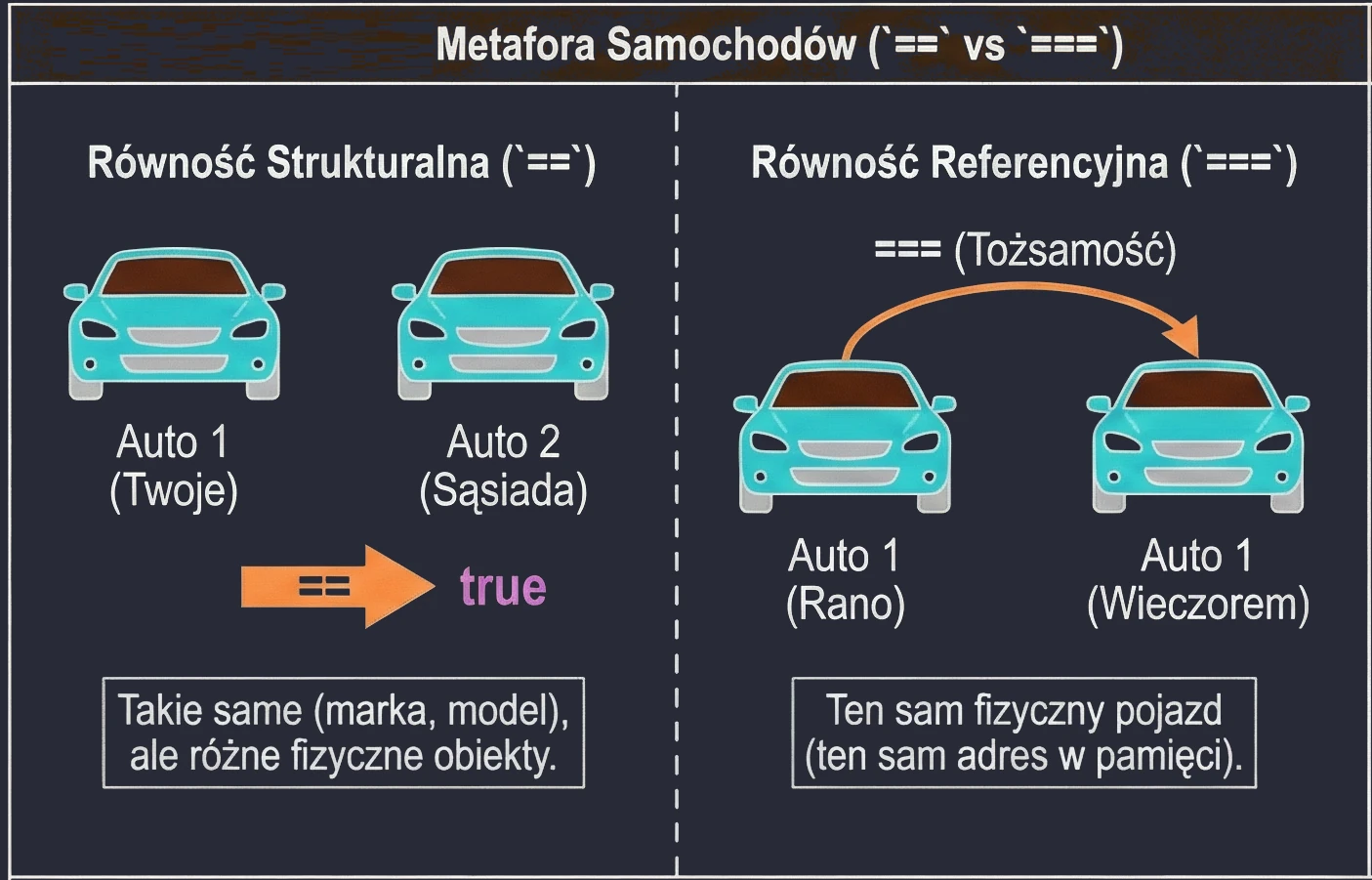
println(u1 === u3) // true (u3 wskazuje na to samo co u1)Możemy to sobie wyobrazić na przykładzie samochodów:
==(Równość strukturalna): Twoje auto i auto sąsiada. Są takie same (marka, model, kolor), ale to dwa różne fizyczne samochody.===(Równość referencyjna): Twoje auto rano i Twoje auto wieczorem. To ten sam, fizyczny pojazd.
Dodajmy, że w przypadku klas danych w przypadku porównania strukturalnego, porównywane są tylko pola z konstruktora głównego. Pola dodane w klasie, ale niebędące parametrami konstruktora głównego, nie są brane pod uwagę przy porównywaniu.
data class User(val name: String, val age: Int) {
var email: String = ""
}
val u1 = User("Ewa", 30)
val u2 = User("Ewa", 30)
u1.email = "ewa@gmail.com"
u2.email = "e.w.q@gmail.com"
println(u1 == u2) // true (data class porównuje zawartość pól z konstruktora głównego)Warto zauważyć, że dla typów, które w czasie wykonania są reprezentowane jako typy proste (np. Int, Double, Boolean), operator === jest równoważny operatorowi ==. Wynika to z faktu, że wartości te nie posiadają odrębnej tożsamości obiektowej.
val a = 100
val b = 100
println(a === b) // true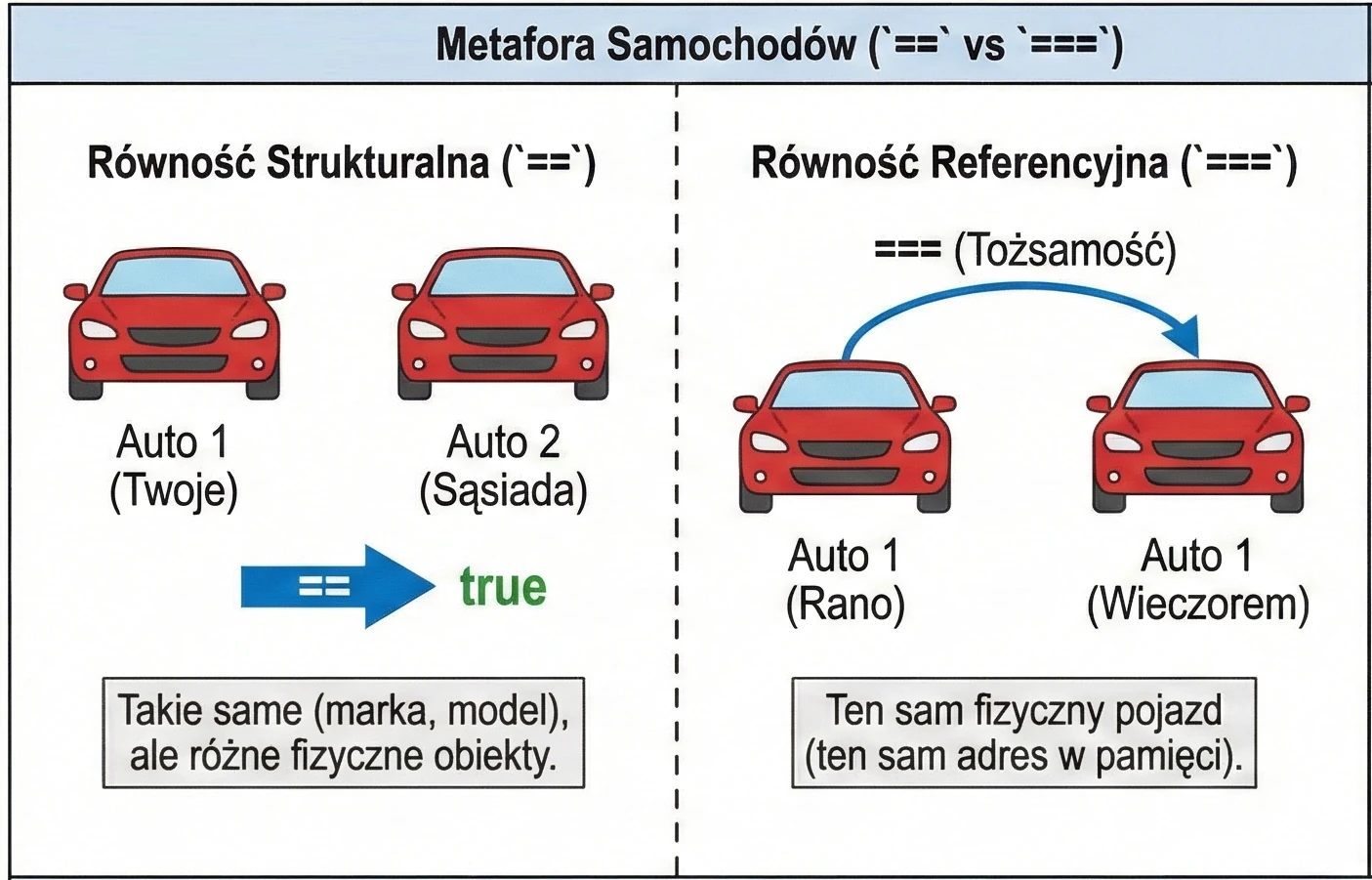
Klasy Wyliczeniowe (Enum Classes)
Służą do definiowania stałego zbioru wartości (np. pory roku, stany zamówienia, kierunki świata).
enum class Direction {
NORTH, SOUTH, EAST, WEST
}Enumu mogą mieć też właściwości i metody:
enum class Color(val hex: String) {
RED("#FF0000"),
GREEN("#00FF00"),
BLUE("#0000FF"); // średnik wymagany przy metodach
fun rgb() = "Color: $hex"
}
val color = Color.RED
println(color.hex)Dziedziczenie i Modyfikatory Dostępu
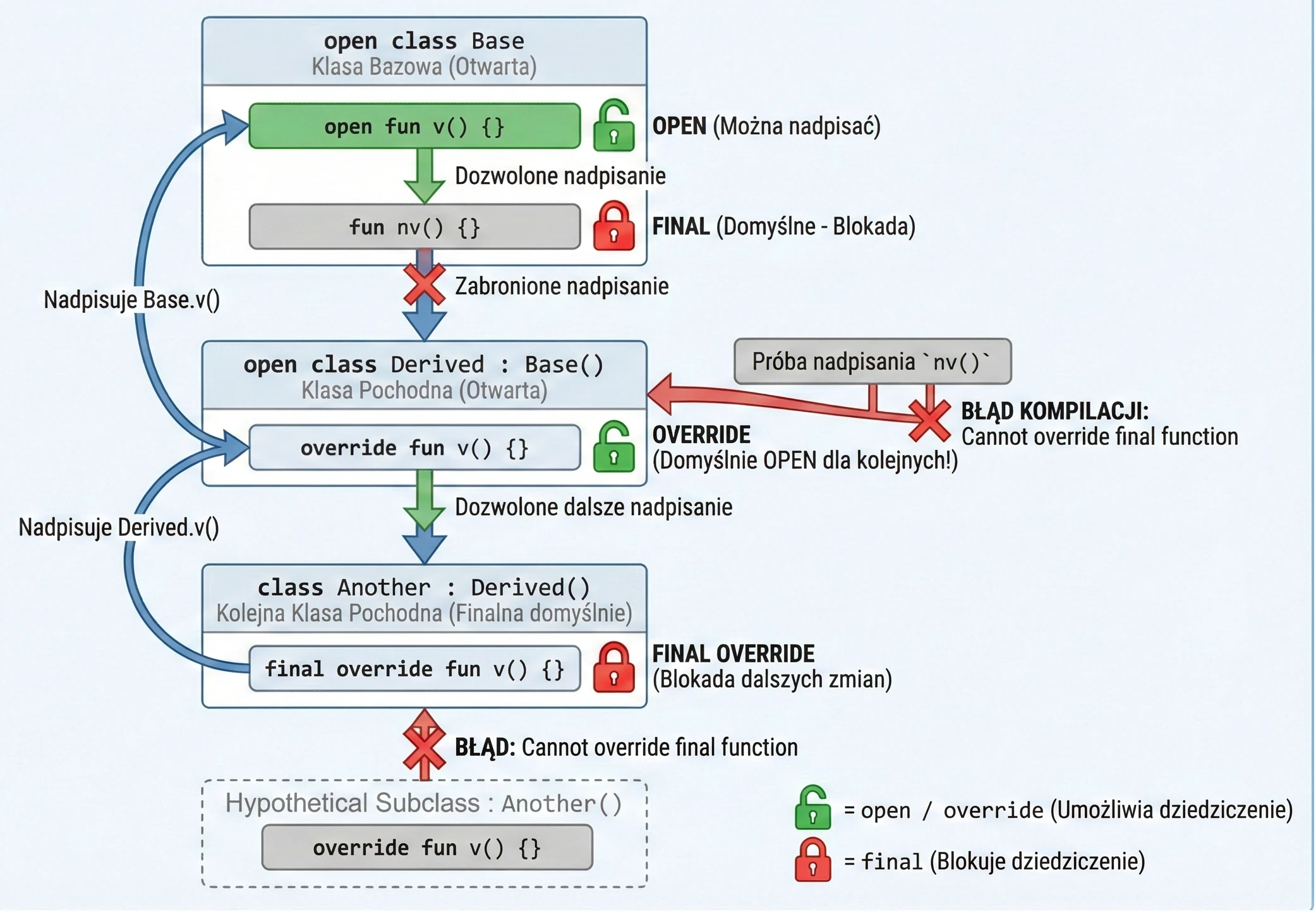
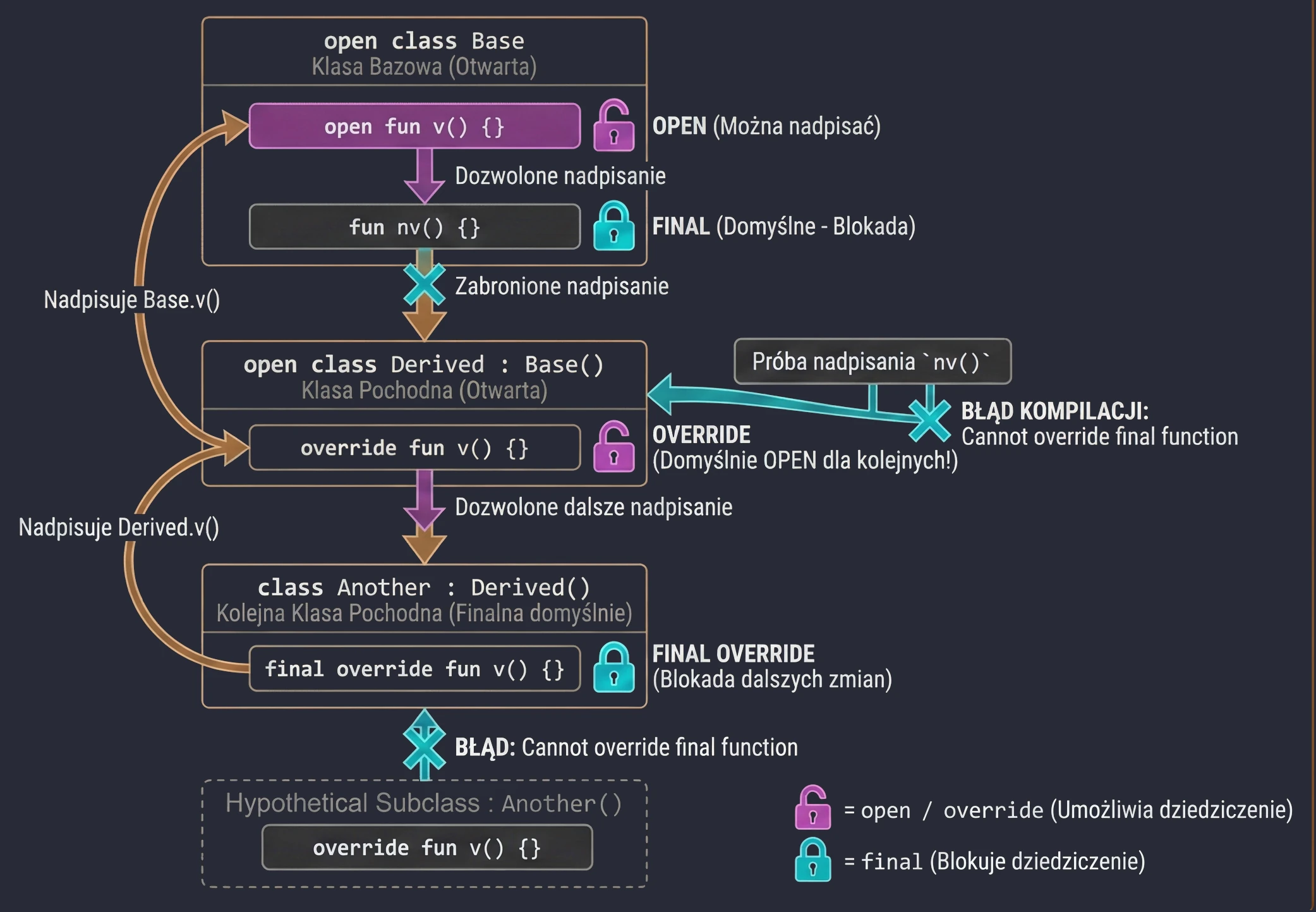
W Kotlinie podejście do dziedziczenia jest restrykcyjne ("zamknięte domyślnie"). W przeciwieństwie do Javy, gdzie wszystko można dziedziczyć (chyba że jest final), w Kotlinie wszystkie klasy i metody są domyślnie finalne.
Aby umożliwić dziedziczenie lub nadpisywanie, musimy jawnie użyć słowa kluczowego open.
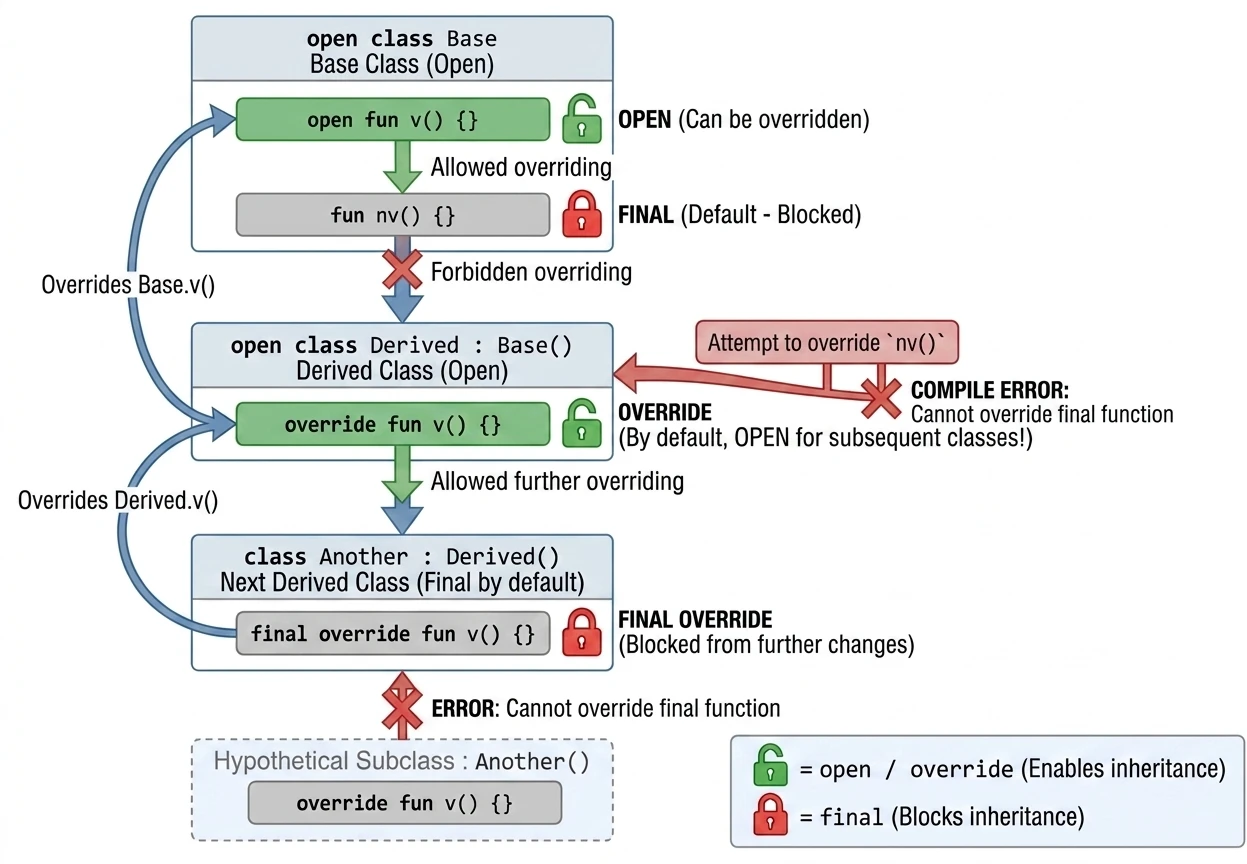
Słowa kluczowe w dziedziczeniu
final(domyślne): Blokuje możliwość dziedziczenia po klasie lub nadpisywania metody. Nie trzeba go pisać, jest domyślne.open: Otwiera klasę na dziedziczenie lub metodę na nadpisanie.override: Wymagane, gdy nadpisujemy metodę z klasy bazowej. Co ważne: funkcja oznaczona jakooverridejest domyślnieopen. Oznacza to, że kolejna klasa dziedzicząca może ją ponownie nadpisać.final override: Jeśli w klasie pochodnej nadpisaliśmy metodę, ale chcemy zabronić dalszego jej nadpisywania w kolejnych podklasach, musimy użyć kombinacjifinal override.
open class Base {
open fun v() {} // Metoda otwarta, można nadpisać
fun nv() {} // Metoda finalna (domyślnie), nie można nadpisać
}
open class Derived() : Base() {
override fun v() {} // Nadpisanie metody v()
// Ta metoda jest nadal OPEN dla kolejnych klas!
}
class Another : Derived() {
final override fun v() {} // Nadpisanie i ZABLOKOWANIE dalszych zmian
}
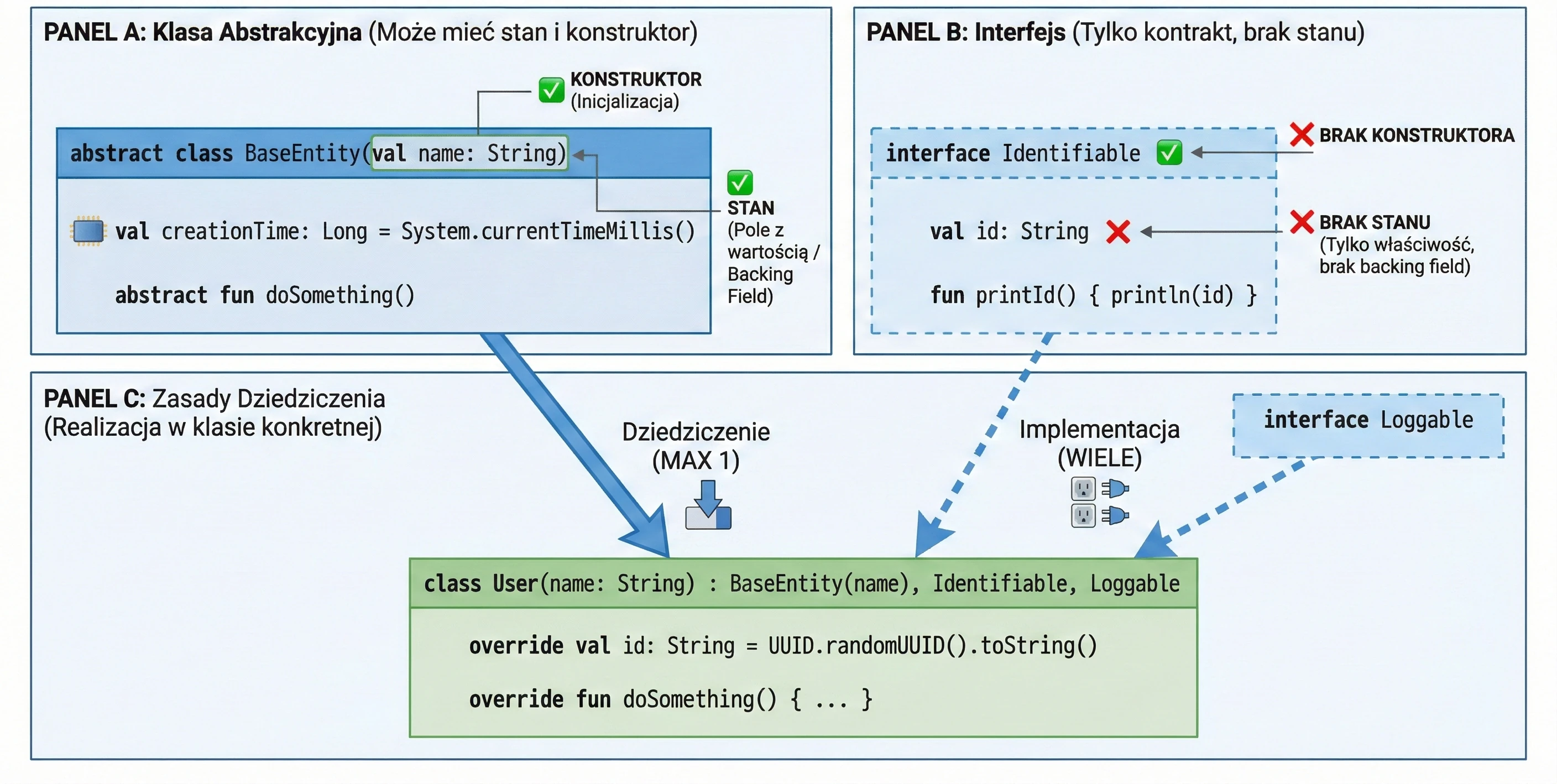
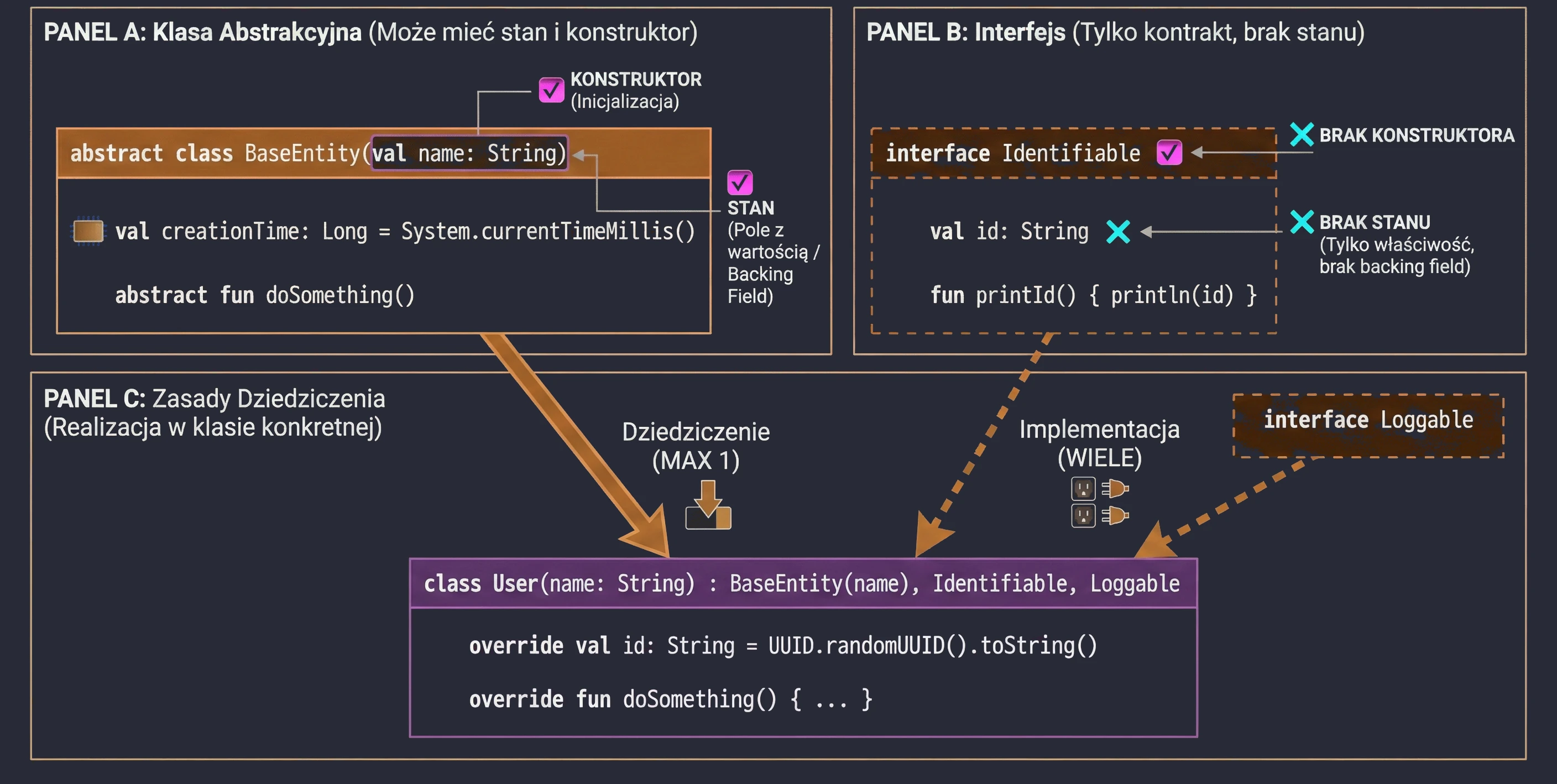
Klasy Abstrakcyjne
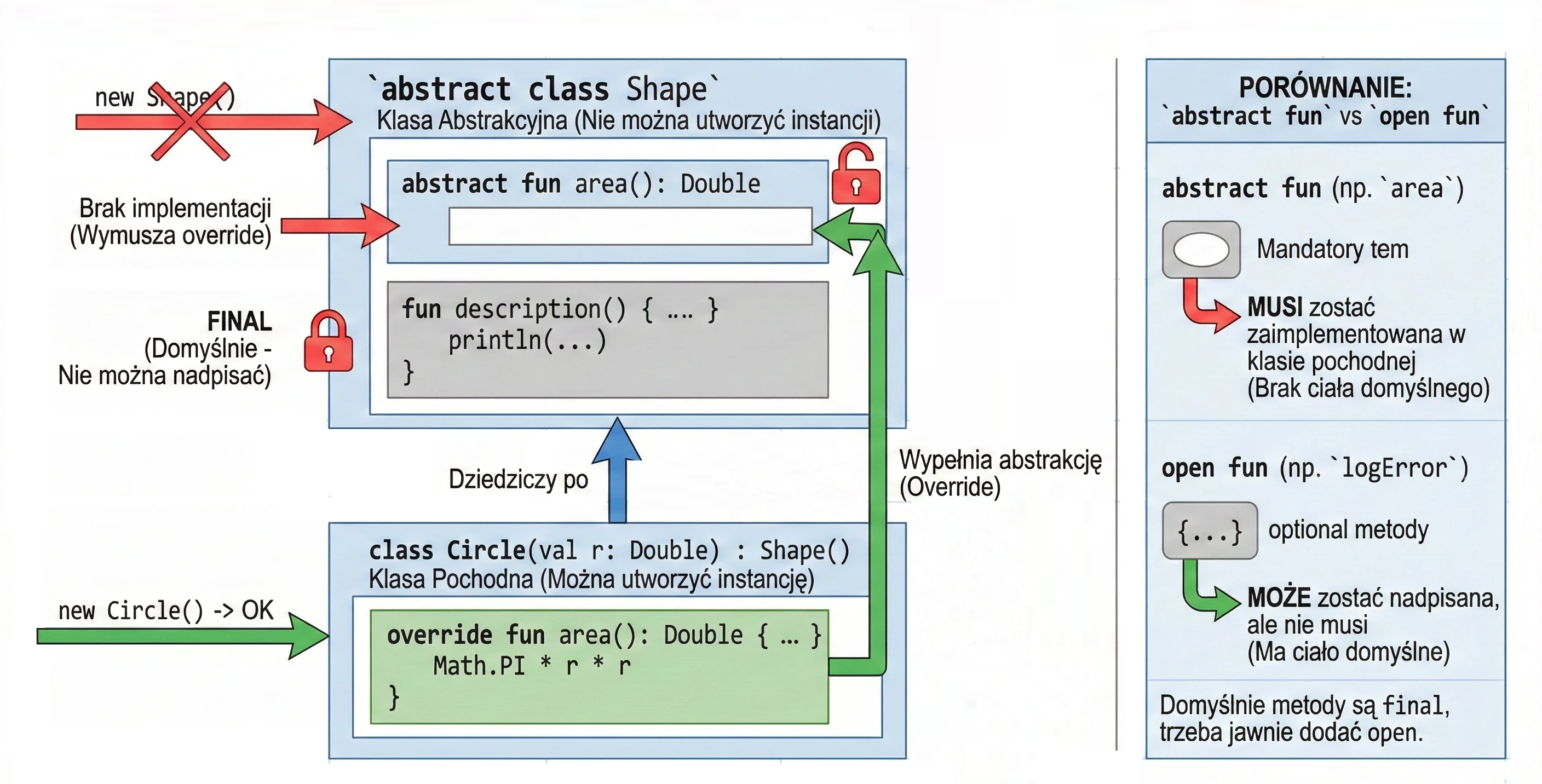
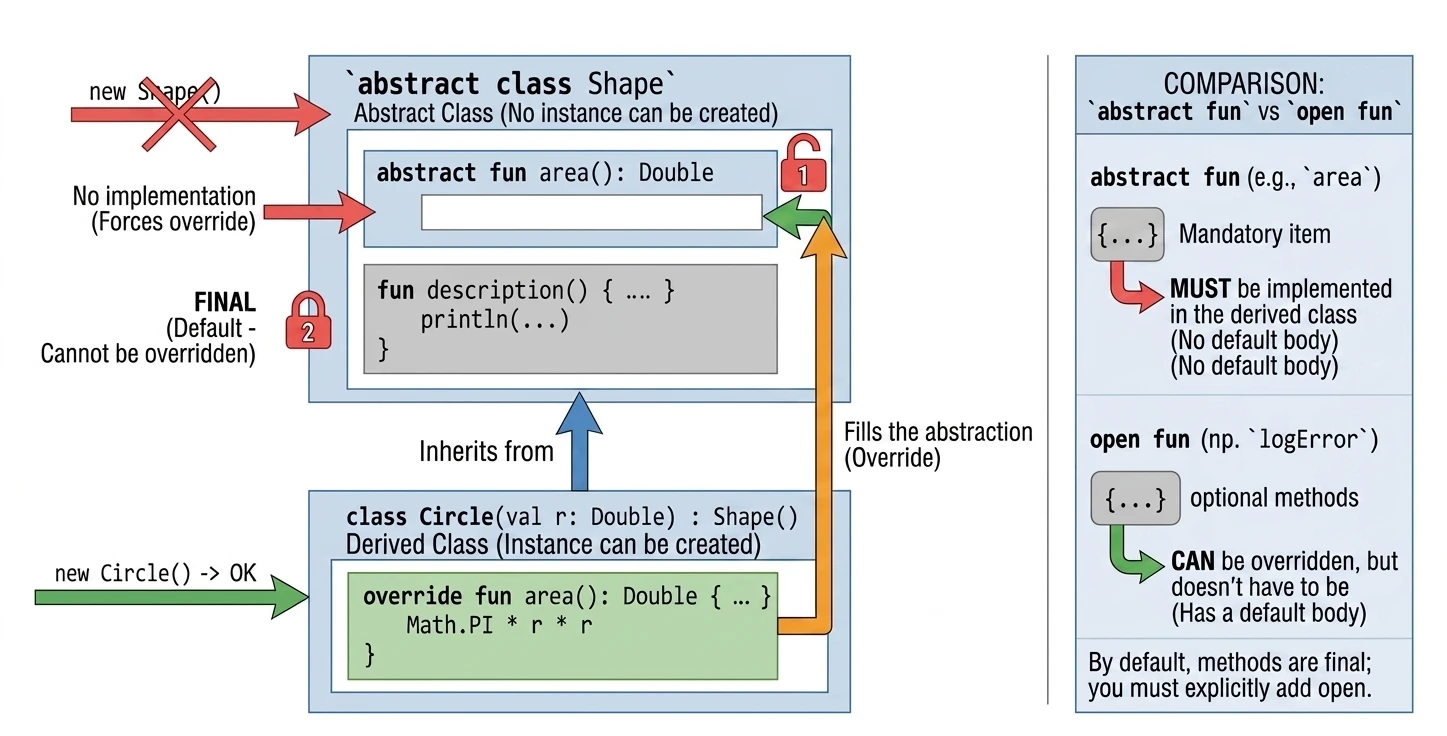
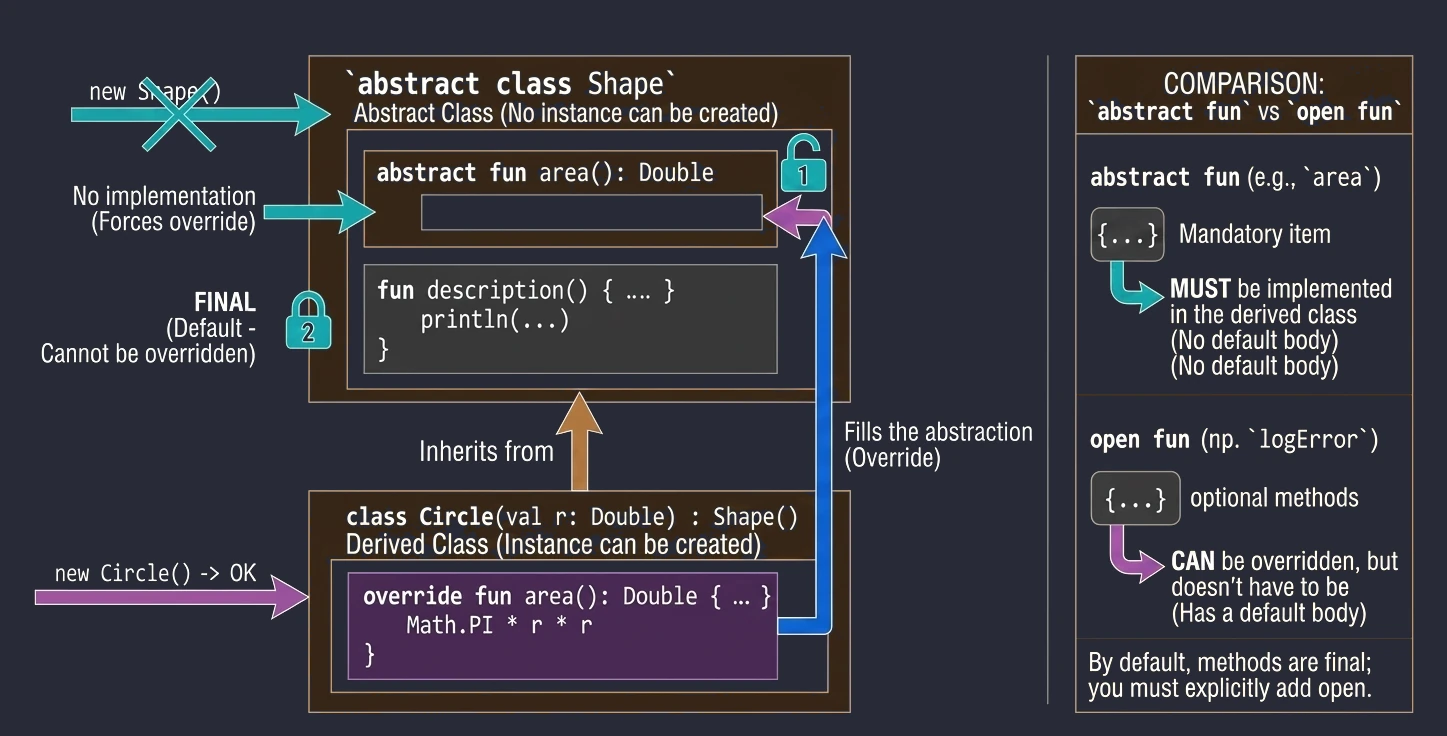
Klasa abstrakcyjna może zawierać metody bez implementacji (abstrakcyjne), które muszą zostać zaimplementowane w klasach pochodnych. Nie można utworzyć instancji klasy abstrakcyjnej.
abstract class Shape {
abstract fun area(): Double // Brak ciała metody
// Metoda z implementacją (domyślnie final, chyba że damy open)
fun description() {
println("To jest jakiś kształt o polu ${area()}")
}
}
class Circle(val r: Double) : Shape() {
override fun area(): Double = Math.PI * r * r
}Abstract vs Open
W klasach abstrakcyjnych często mamy dylemat: użyć abstract czy open?
abstract fun: Nie ma ciała (implementacji). Klasa pochodna musi ją zaimplementować (chyba że sama jest abstrakcyjna). Używamy, gdy nie ma sensownej implementacji domyślnej (np.calculateArea()dla ogólnego kształtu).open fun: Ma ciało (implementację domyślną). Klasa pochodna może ją nadpisać, ale nie musi. Używamy, gdy istnieje sensowne zachowanie domyślne (np.logError()wypisujące na konsolę), które w specyficznych przypadkach chcemy zmienić (np. zapis do pliku).
Klasy Zapieczętowane (Sealed Classes)
sealed class to klasa, która ma ograniczoną, z góry znaną liczbę potomków. Wszystkie klasy dziedziczące muszą znajdować się w tym samym pakiecie.
Jest to idealne narzędzie do modelowania stanów.
sealed class UiState {
object Loading : UiState()
data class Success(val data: String) : UiState()
data class Error(val message: String) : UiState()
}Gdy używamy instrukcji when, kompilator wie, że pokryliśmy wszystkie możliwe przypadki. Nie potrzebujemy sekcji else.
fun handleState(state: UiState) {
when(state) {
is UiState.Loading -> showProgressBar()
is UiState.Success -> showData(state.data)
is UiState.Error -> showError(state.message)
// Brak else. Kompilator wie, że to wszystkie opcje.
}
}Klasy Zagnieżdżone i Wewnętrzne
Często chcemy zdefiniować klasę wewnątrz innej klasy, aby zgrupować logikę i ukryć szczegóły implementacyjne. Kotlin oferuje tu dwa podejścia, które kluczowo różnią się dostępem do pamięci i instancji.
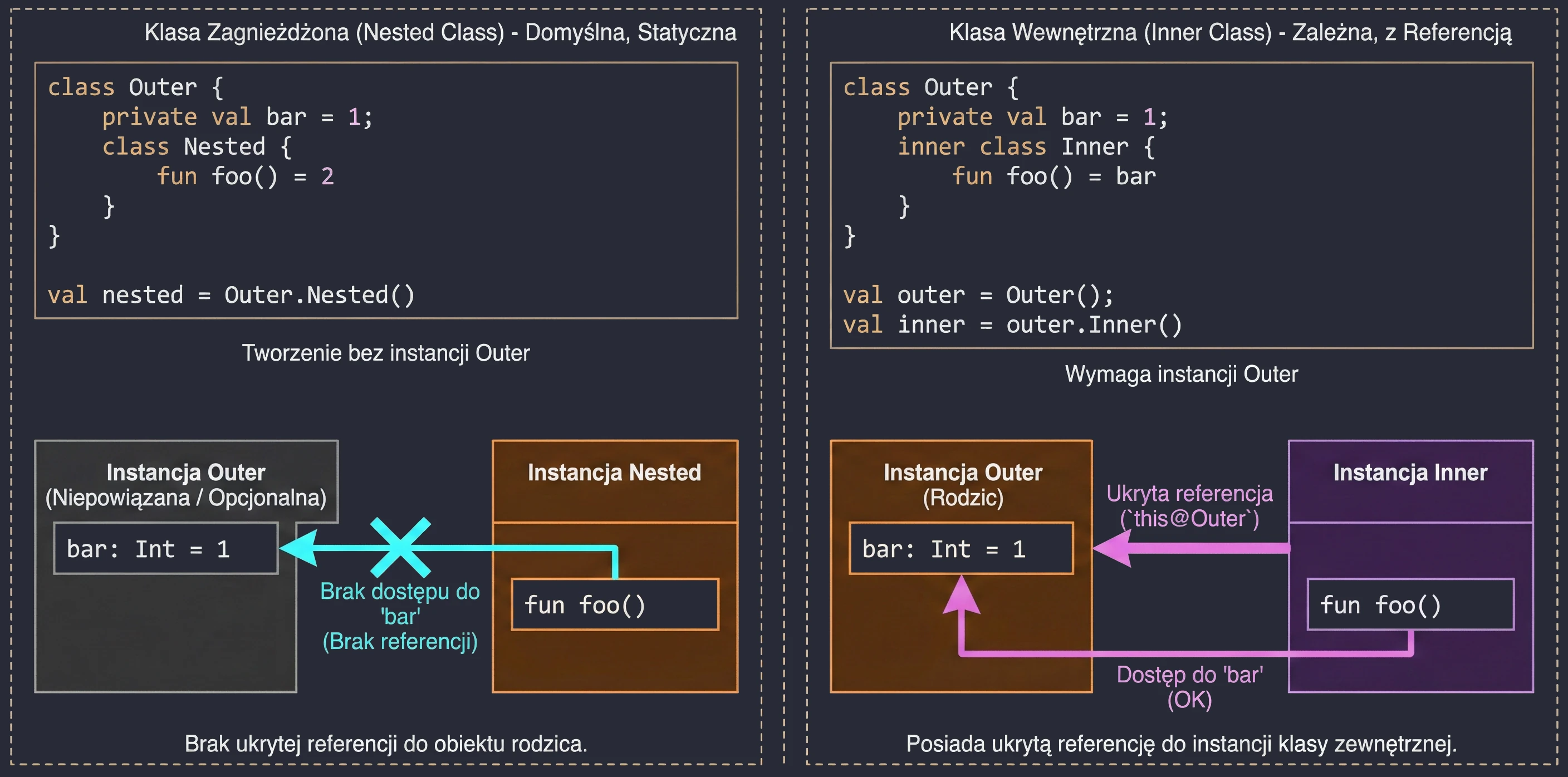
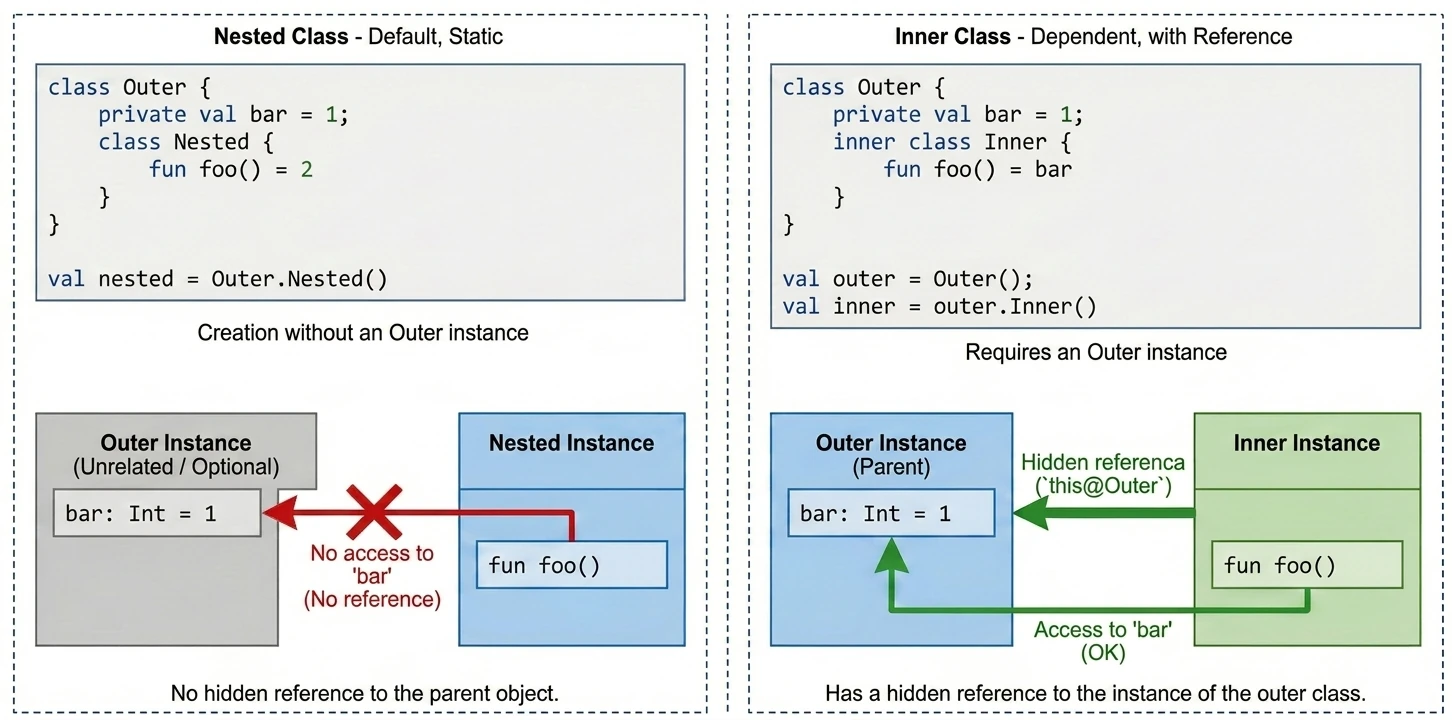
Klasa Zagnieżdżona (Nested Class)
Jest to zachowanie domyślne (gdy nie użyjemy żadnego modyfikatora). Klasa zagnieżdżona jest bytem niezależnym. Nie posiada referencji do obiektu klasy zewnętrznej.
- Zastosowanie: Gdy klasa pomocnicza jest logicznie powiązana z klasą zewnętrzną, ale nie potrzebuje dostępu do jej pól (danych). Działa jak
static classw Javie. - Zaleta: Mniejsze zużycie pamięci (brak ukrytej referencji do rodzica).
class Outer {
private val bar: Int = 1
class Nested {
fun foo() = 2
// fun getBar() = bar // BŁĄD! Nie widzi 'bar' klasy Outer
}
}
val nested = Outer.Nested() // Tworzenie bez instancji OuterKlasa Wewnętrzna (Inner Class)
Oznaczona słowem kluczowym inner. Taka klasa posiada ukrytą referencję do instancji klasy zewnętrznej, w której została utworzona.
- Zastosowanie: Gdy klasa pomocnicza musi operować na danych klasy głównej. Klasyczny przykład to Adaptery w Androidzie (ViewHolder często musi wywołać metodę z Adaptera) lub implementacje wzorca Listener, gdzie nasłuchiwacz musi zmodyfikować stan widoku.
- Dostęp do rodzica: Aby odwołać się do instancji zewnętrznej, używamy składni
this@NazwaKlasyZewnetrznej.
class Outer {
private val bar: Int = 1
inner class Inner {
fun foo() = bar // OK! Widzi 'bar'
fun getOuterReference(): Outer {
return this@Outer // Dostęp do instancji Outer
}
}
}
val outer = Outer()
val inner = outer.Inner() // Musimy mieć instancję Outer, by stworzyć Inner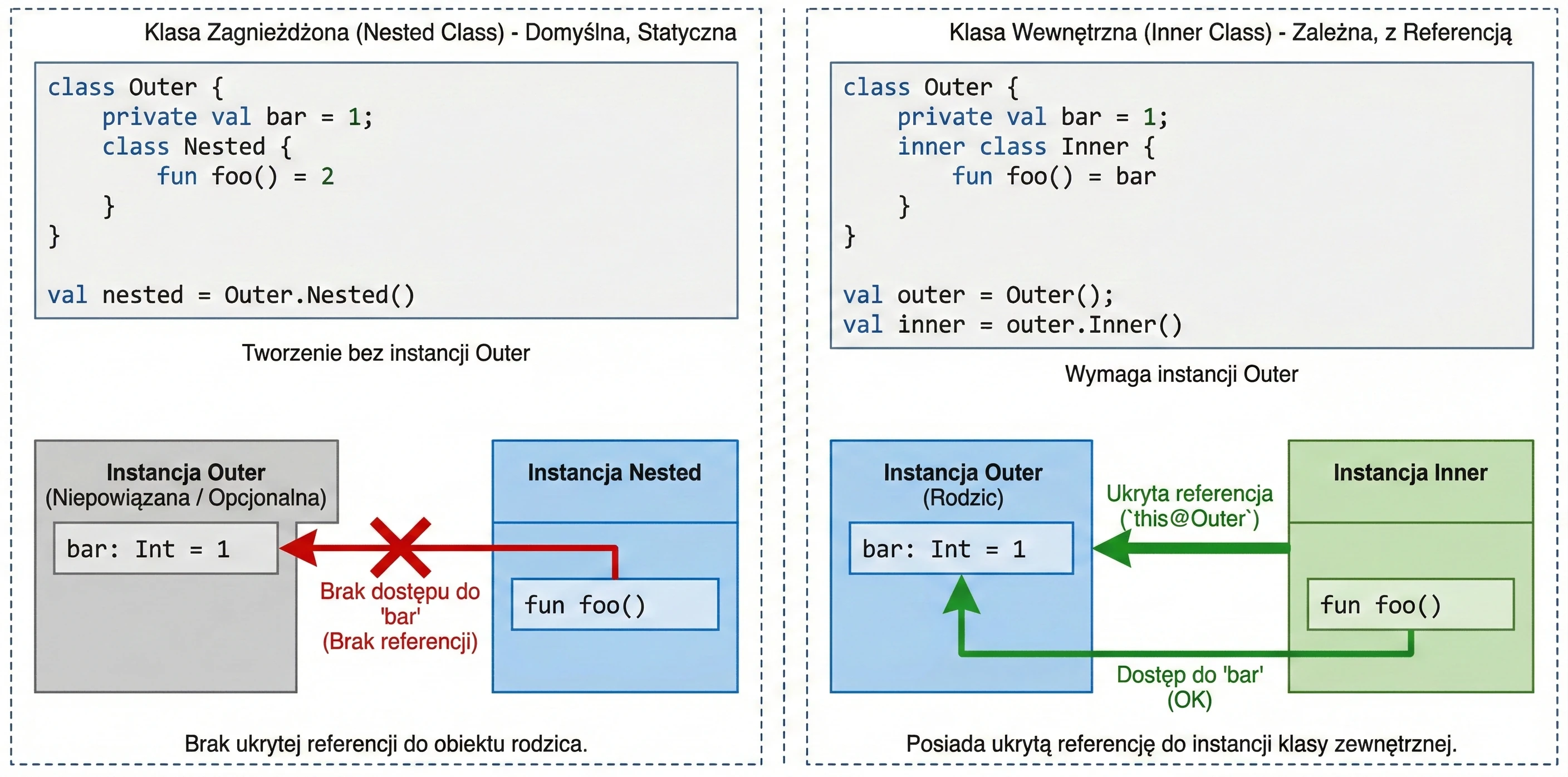
Obiekty Towarzyszące (Companion Object)
W Kotlinie nie ma słowa kluczowego static. Zamiast tego, jeśli chcemy mieć metodę lub pole powiązane z klasą, a nie z obiektem (np. fabrykę lub stałą), umieszczamy je w companion object.
class User {
companion object {
const val MAX_AGE = 120
fun createDefault(): User = User()
}
}
// Użycie (jak static w Javie)
val max = User.MAX_AGE
val user = User.createDefault()Generics (Typy Generyczne)
O typach generycznych w funkcjach wspominaliśmy w Rozdziale 3. Teraz czas na klasy.
class Box<T>(val item: T)
val intBox = Box(1) // Box<Int>
val strBox = Box("Hej") // Box<String>Wariancja (Variance)
To trudny temat, ale kluczowy dla zrozumienia kolekcji w Kotlinie. Załóżmy, że Dog dziedziczy po Animal. Czy Box<Dog> jest podtypem Box<Animal>? Domyślnie nie.
Gdyby było, moglibyśmy do pudełka z psami (Box<Animal>) włożyć kota, co zepsułoby pudełko z psami.
Kotlin pozwala jednak sterować tym zachowaniem za pomocą słów kluczowych out i in (Declaration-site variance).
- Kowariancja (
out): Producent. Klasa tylko zwraca (produkuje) typT. - Kontrawariancja (
in): "Konsument". Klasa tylko przyjmuje typT.
// List<out T> w Kotlinie jest kowariantna
val dogs: List<Dog> = listOf(Dog(), Dog())
val animals: List<Animal> = dogs // OK! Bo List jest <out T>Możemy bezpiecznie czytać Animal z listy psów, bo każdy pies to zwierzę.
interface Consumer<in T> {
fun consume(item: T)
}
val animalConsumer: Consumer<Animal> = ...
val dogConsumer: Consumer<Dog> = animalConsumer // OK!Jeśli coś potrafi obsłużyć każde zwierzę, to potrafi też obsłużyć psa. Kierunek dziedziczenia się "odwraca".
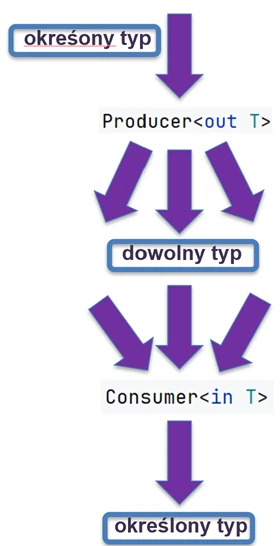
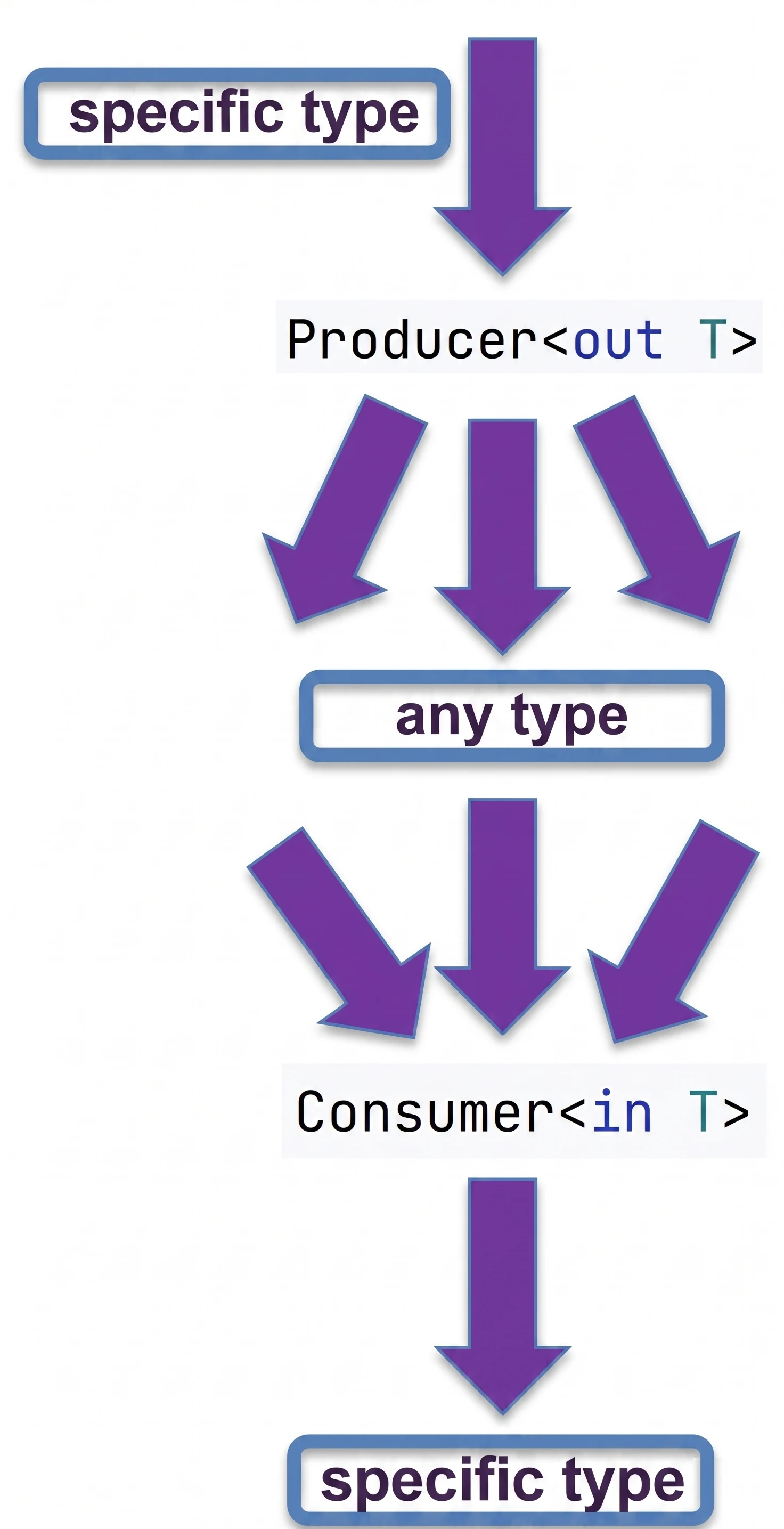
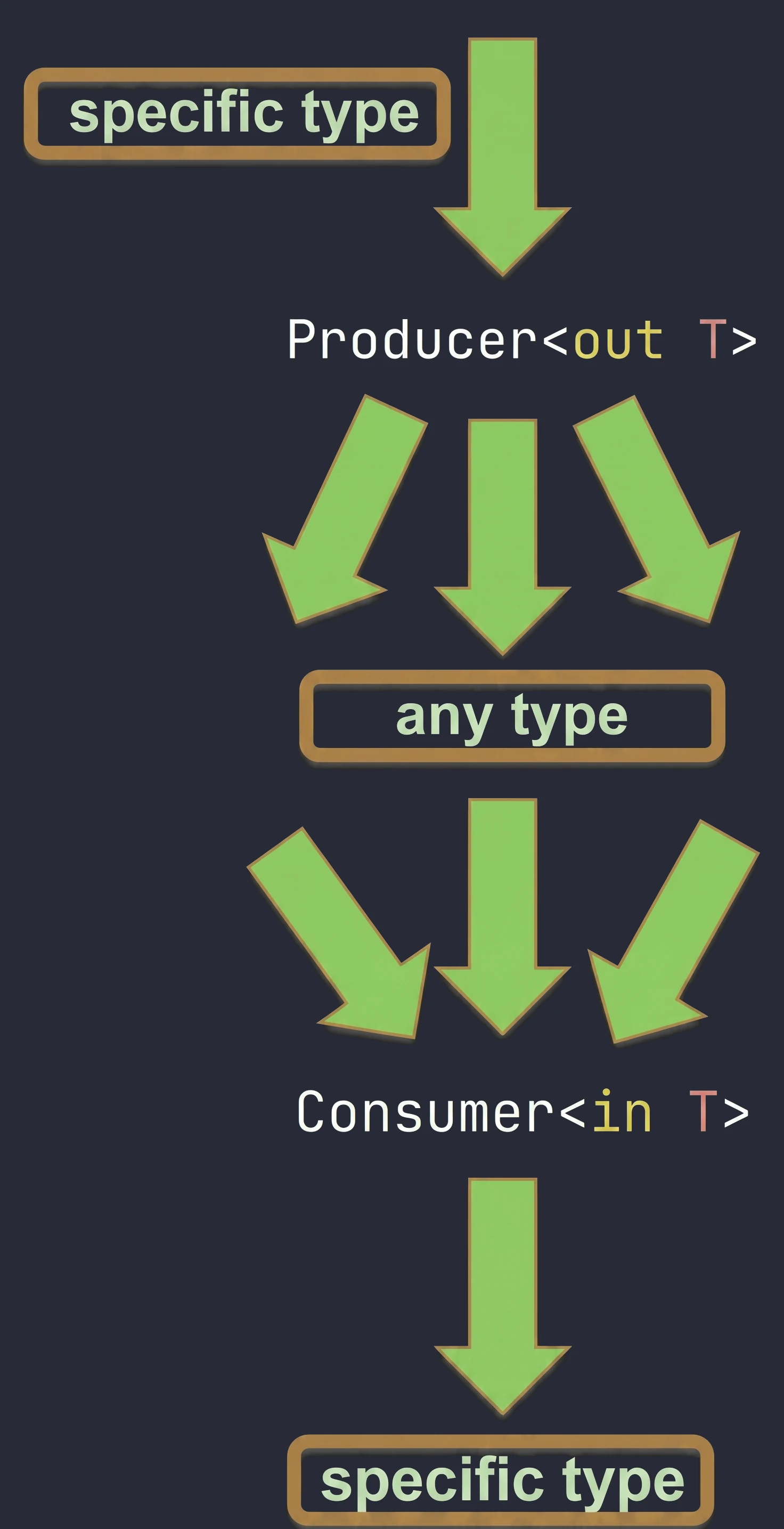
Możemy zapamiętać to sobie w następujący sposób:
out(Producent): Skupiamy się na tym, co wychodzi z obiektu. Jeśli ze źródła wychodzą psy, to bezpiecznie możemy uznać, że wychodzą z niego zwierzęta.in(Konsument): Skupiamy się na tym, co wchodzi do obiektu. Jeśli ktoś potrafi zaopiekować się dowolnym zwierzęciem (np. weterynarz), to poradzi sobie również, gdy wejdzie do niego konkretnie pies.
W poprzednim rozdziale omówiliśmy klasy i dziedziczenie. Kotlin wprowadza jednak kilka unikalnych konstrukcji, które znacznie upraszczają typowe wzorce projektowe, takie jak Singleton czy anonimowe klasy wewnętrzne. Mowa o słowie kluczowym object.
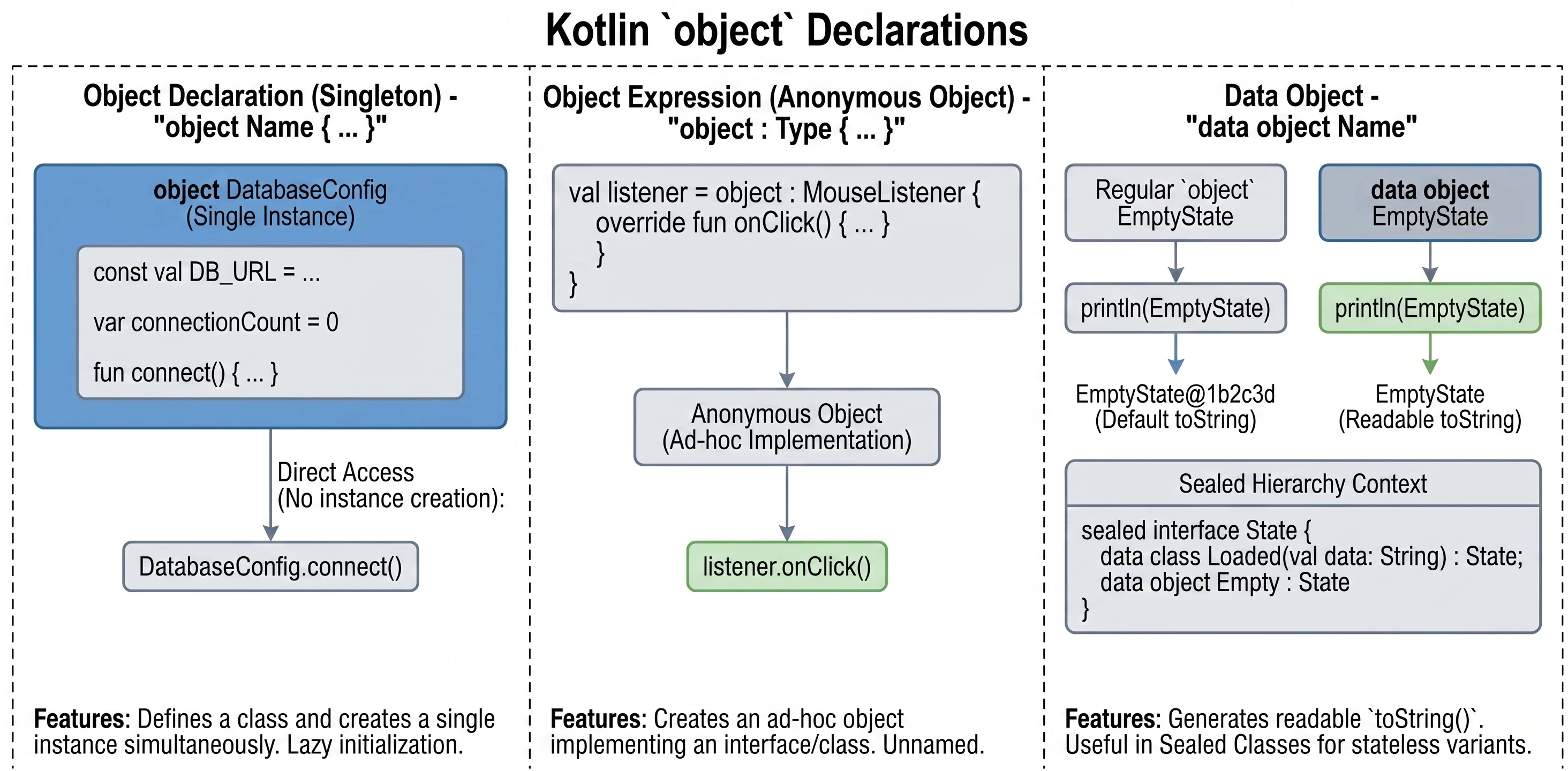
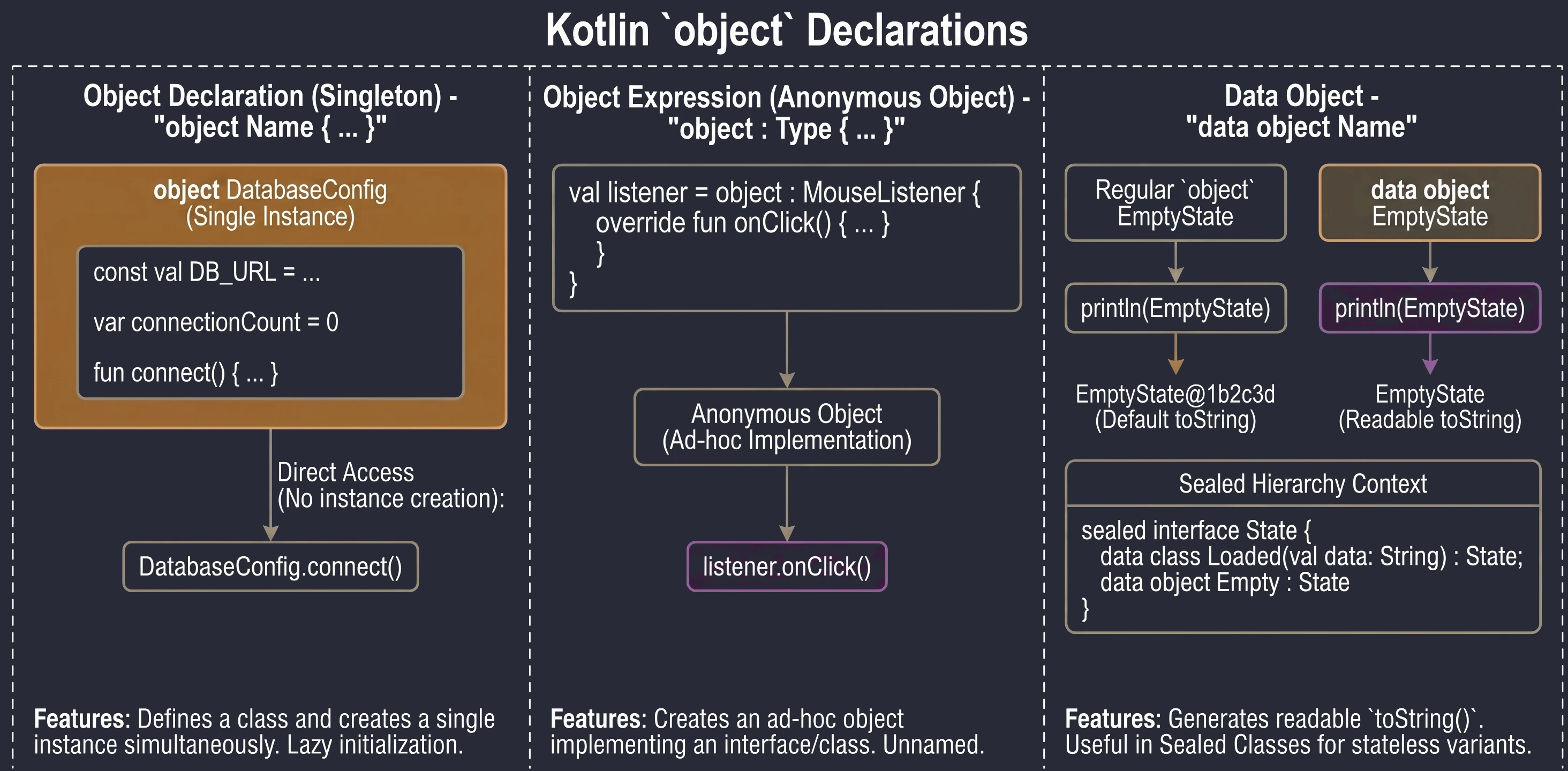
Słowo kluczowe object
W Kotlinie object to specjalna konstrukcja, która jednocześnie definiuje klasę i tworzy jej jedyną instancję. Jest to realizacja wzorca Singleton (wbudowana w język).
Gdy chcemy mieć pewność, że w całej aplikacji istnieje tylko jeden egzemplarz danej klasy (np. konfiguracja, menedżer bazy danych), używamy deklaracji obiektu:
object DatabaseConfig {
const val DB_URL = "jdbc:mysql://localhost:3306/db"
var connectionCount = 0
fun connect() {
connectionCount++
println("Connected to $DB_URL")
}
}Do składowych takiego obiektu odwołujemy się bezpośrednio przez nazwę (bez tworzenia instancji operatorem ()):
DatabaseConfig.connect()
println(DatabaseConfig.connectionCount)Obiekty te są inicjalizowane leniwie (lazy) – dopiero przy pierwszym odwołaniu się do nich.
Czasami potrzebujemy obiektu danej klasy (lub implementującego interfejs) tylko w jednym miejscu (ad-hoc), bez konieczności nadawania mu nazwy. W Javie używalibyśmy anonimowych klas wewnętrznych. W Kotlinie używamy wyrażeń obiektowych (object expression).
interface MouseListener {
fun onClick()
}
// Tworzymy obiekt anonimowy implementujący interfejs
val listener = object : MouseListener {
override fun onClick() {
println("Kliknięto myszką!")
}
}Możemy też dziedziczyć po klasie i implementować wiele interfejsów jednocześnie:
open class A(x: Int)
interface B
val ab = object : A(1), B {
val y = 15
}Od nowszych wersji Kotlina, obiekty (object) mogą być oznaczane jako data object. Działa to analogicznie do data class – generuje czytelną metodę toString().
data object EmptyState
println(EmptyState) // Wypisze "EmptyState" zamiast "EmptyState@1b2c3d"Jest to szczególnie przydatne przy Sealed Classes/Interfaces, gdzie część wariantów to klasy z danymi, a część to proste bezstanowe obiekty.
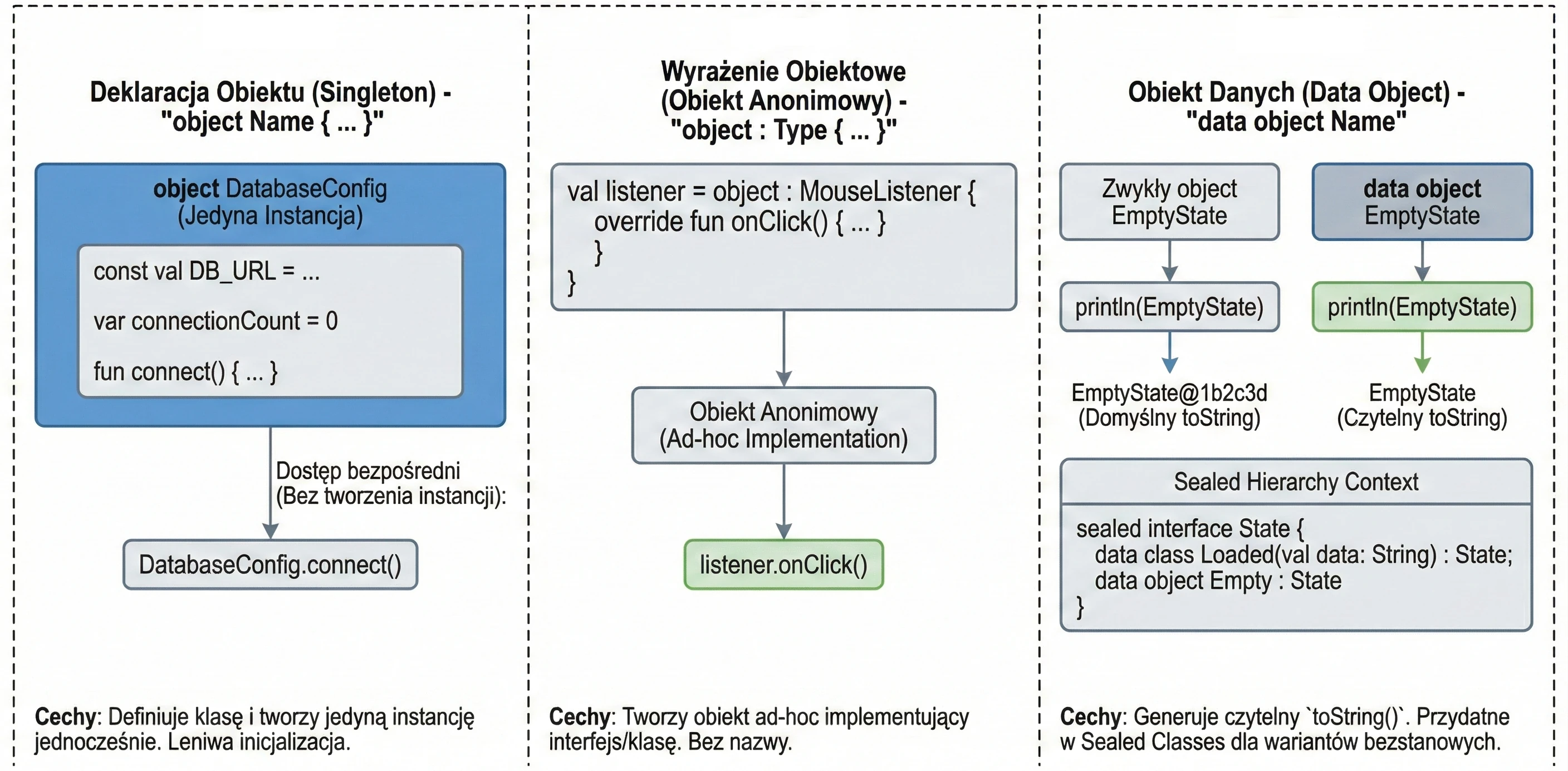
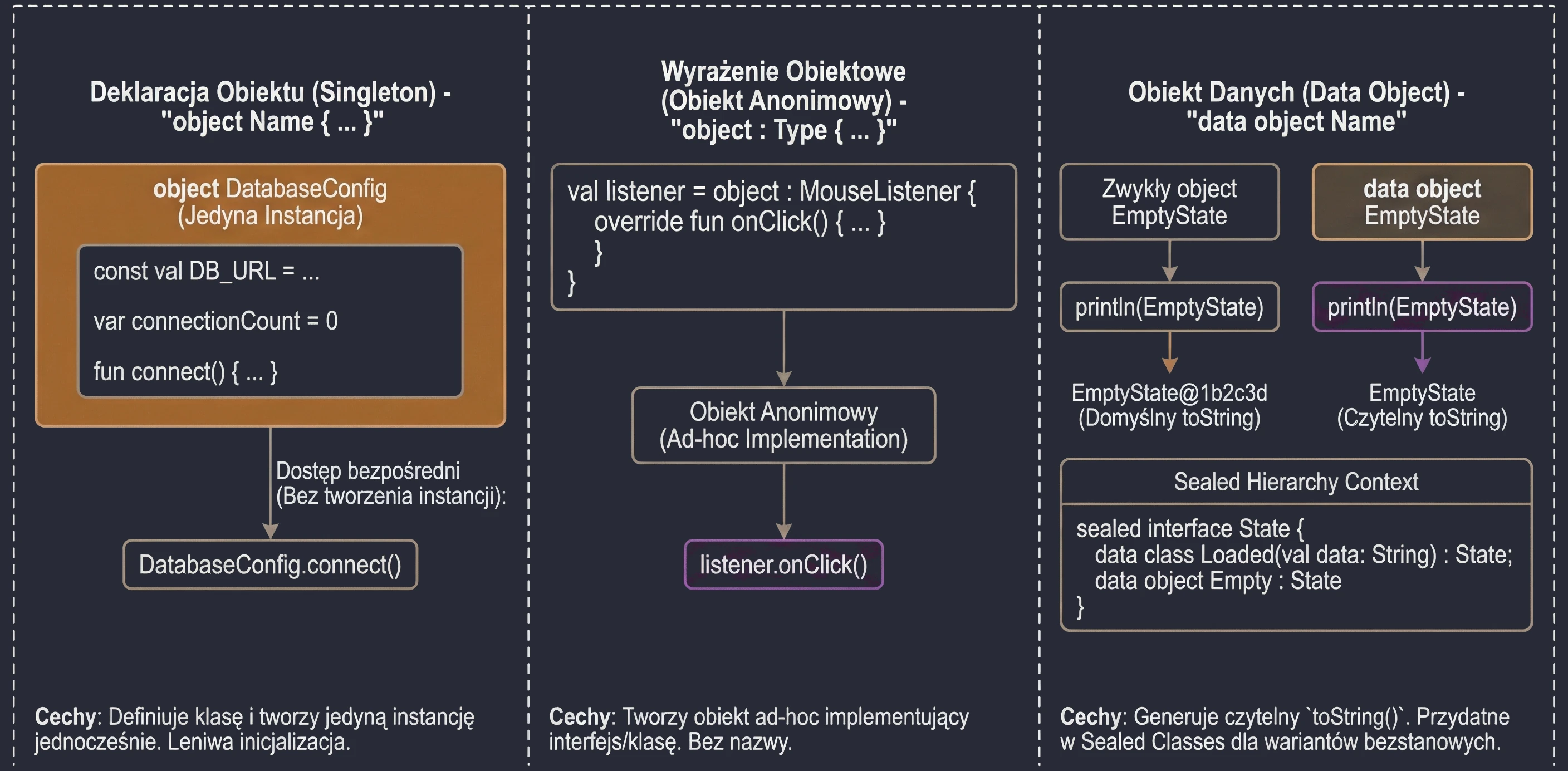
object w Kotlinie.Interfejsy
Interfejs definiuje kontrakt – zestaw metod i właściwości, które klasa implementująca musi dostarczyć. W Kotlinie interfejsy są bardzo elastyczne: mogą zawierać metody abstrakcyjne oraz metody z domyślną implementacją.
interface Drivable {
val maxSpeed: Int // Właściwość abstrakcyjna
fun drive() // Metoda abstrakcyjna (brak ciała)
// Metoda z domyślną implementacją
fun stop() {
println("Zatrzymuję się.")
}
}Klasa implementująca interfejs używa tej samej składni co przy dziedziczeniu (:):
class Car : Drivable {
override val maxSpeed = 200 // Musimy nadpisać właściwość
override fun drive() {
println("Jadę autem z prędkością $maxSpeed")
}
// Metody stop() nie musimy nadpisywać, użyje domyślnej
}Interfejsy w Kotlinie nie mogą przechowywać stanu (nie mają pól instancji). Mogą jednak deklarować właściwości:
- Abstrakcyjne (klasa musi je nadpisać).
- Zdefiniowane akcesorami (getter), o ile nie odwołują się do
field.
interface Named {
val name: String // abstrakcyjne
val nameLength: Int
get() = name.length // OK, oblicza na podstawie 'name'
}Klasa może implementować wiele interfejsów jednocześnie. Jeśli pojawi się konflikt nazw metod (dwa interfejsy mają metodę o tej samej sygnaturze i obie mają domyślną implementację), musimy jawnie wskazać, którą wersję wywołać, używając super<Typ>.
interface A {
fun foo() { print("A") }
}
interface B {
fun foo() { print("B") }
}
class C : A, B {
override fun foo() {
super<A>.foo() // Wywołaj wersję z A
super<B>.foo() // Wywołaj wersję z B
}
}Zastosowania Interfejsów
Interfejsy w programowaniu obiektowym pełnią kluczową rolę, wykraczającą poza proste definiowanie metod.
Interfejs tworzy nowy typ danych, którym możemy posługiwać się w kodzie. Zmienna, parametr funkcji czy pole w klasie może być typu interfejsu. Dzięki temu kod staje się niezależny od konkretnej implementacji.
fun playMusic(player: Playable) { // Parametr jest typu interfejsu
player.play()
}Interfejs narzuca klasom implementującym obowiązek dostarczenia kodu dla zdefiniowanych metod. Gwarantuje to, że każdy obiekt spełniający kontrakt (implementujący interfejs) posiada określone zachowania.
Dzięki traktowaniu interfejsu jako typu, możemy uzyskać polimorfizm. Obiekty różnych klas (np. Car, Bike, Plane) mogą być traktowane w jednolity sposób (jako Drivable), o ile implementują ten sam interfejs. Pozwala to na pisanie uniwersalnego kodu, operującego na abstrakcjach, a nie konkretach.
val vehicles: List<Drivable> = listOf(Car(), Bike())
for (v in vehicles) {
v.drive() // Zadziała dla każdego obiektu, niezależnie od konkretnej klasy
}Czasami interfejs nie posiada żadnych metod ani właściwości, jest to tak zwany interfejs marker (interfejs znacznikowy). Służy wtedy jedynie do oznaczenia klasy, by nadać jej pewną cechę lub poinformować framework o jej specjalnym traktowaniu. Przykładem w Javie/Kotlinie jest Serializable (oznacza, że obiekt można serializować) lub Cloneable. Taki interfejs jest często używany w frameworkach, które muszą wiedzieć, że dana klasa może być używana w określonym kontekście.
Interfejsy pozwalają nadać wspólną cechę klasom, które nie są ze sobą powiązane w hierarchii dziedziczenia. Np. interfejs Comparable sprawia, że obiekty można porównywać (i sortować), a Iterable pozwala iterować po obiekcie w pętli for.
Interfejsy Funkcyjne (SAM)
Jeśli interfejs posiada dokładnie jedną metodę abstrakcyjną, nazywamy go interfejsem funkcyjnym lub SAM (Single Abstract Method).
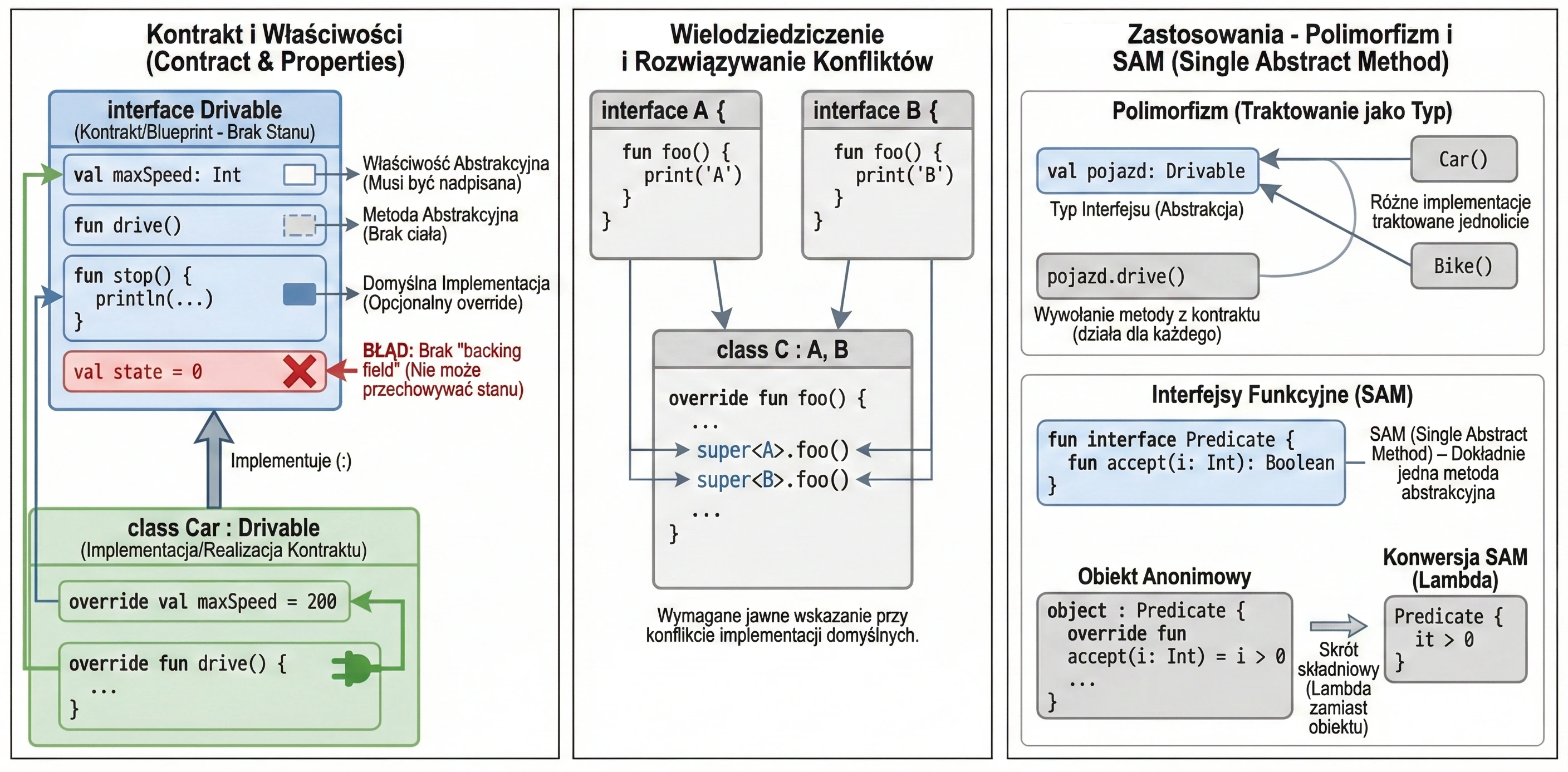
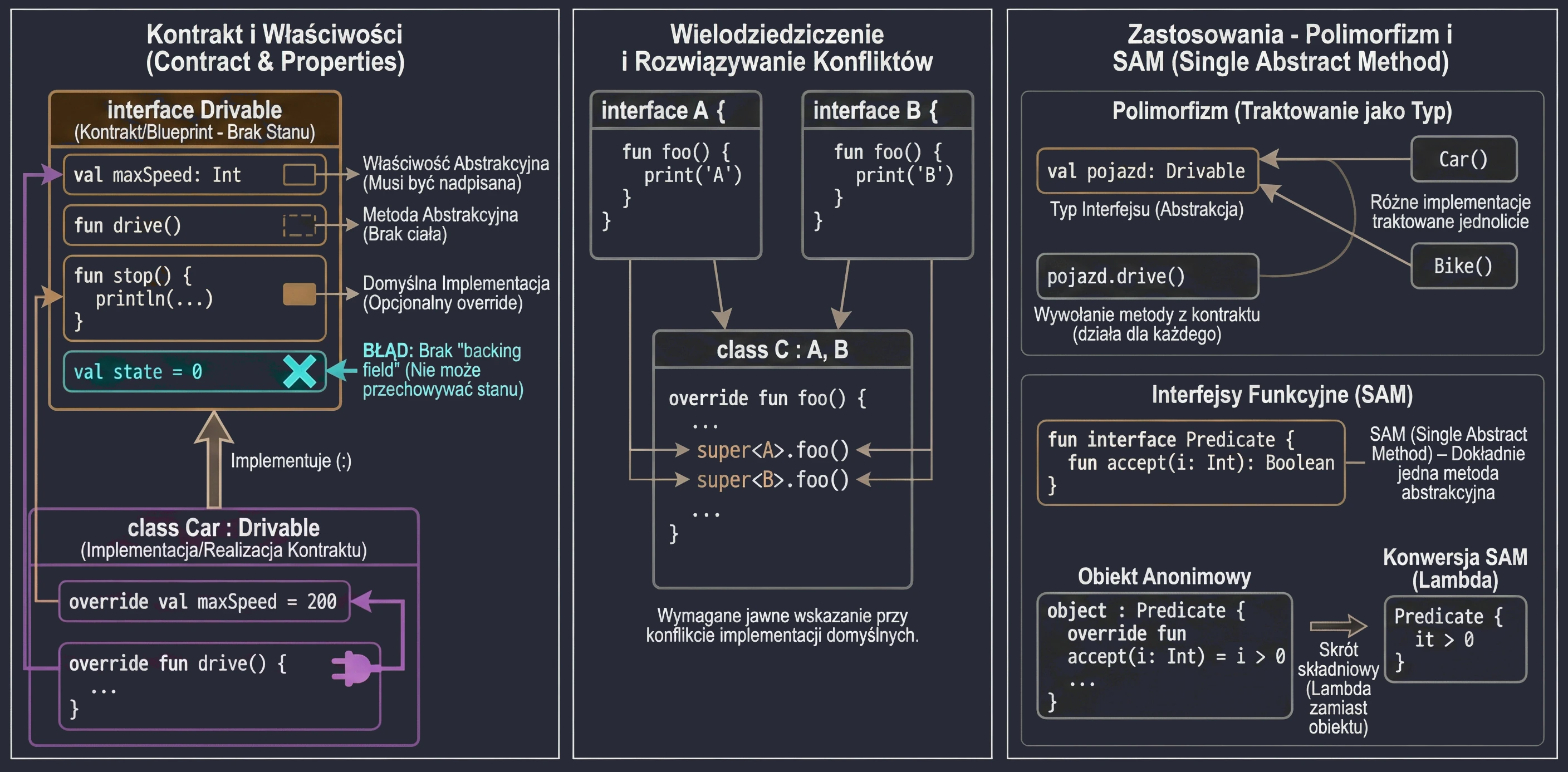
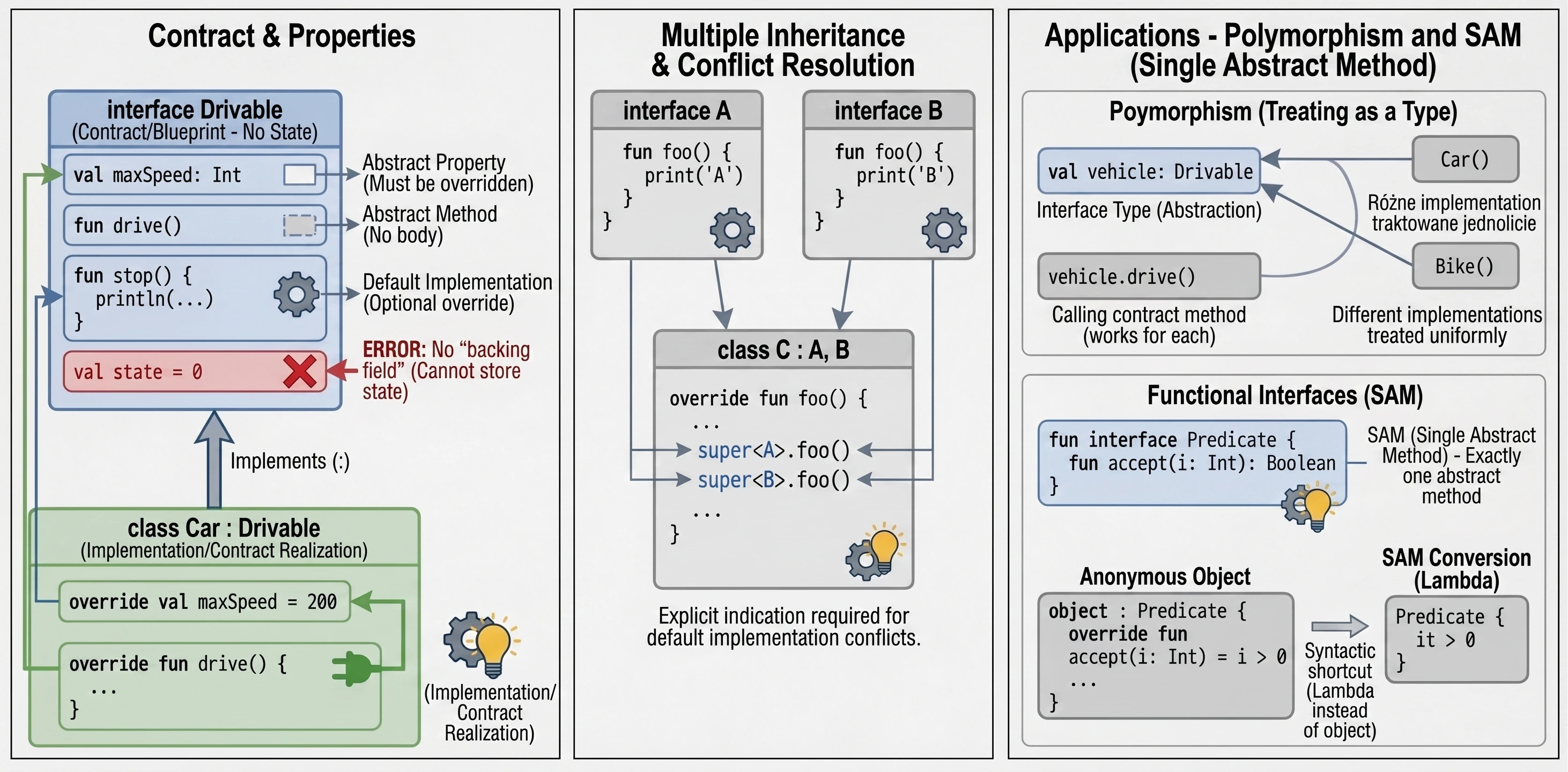
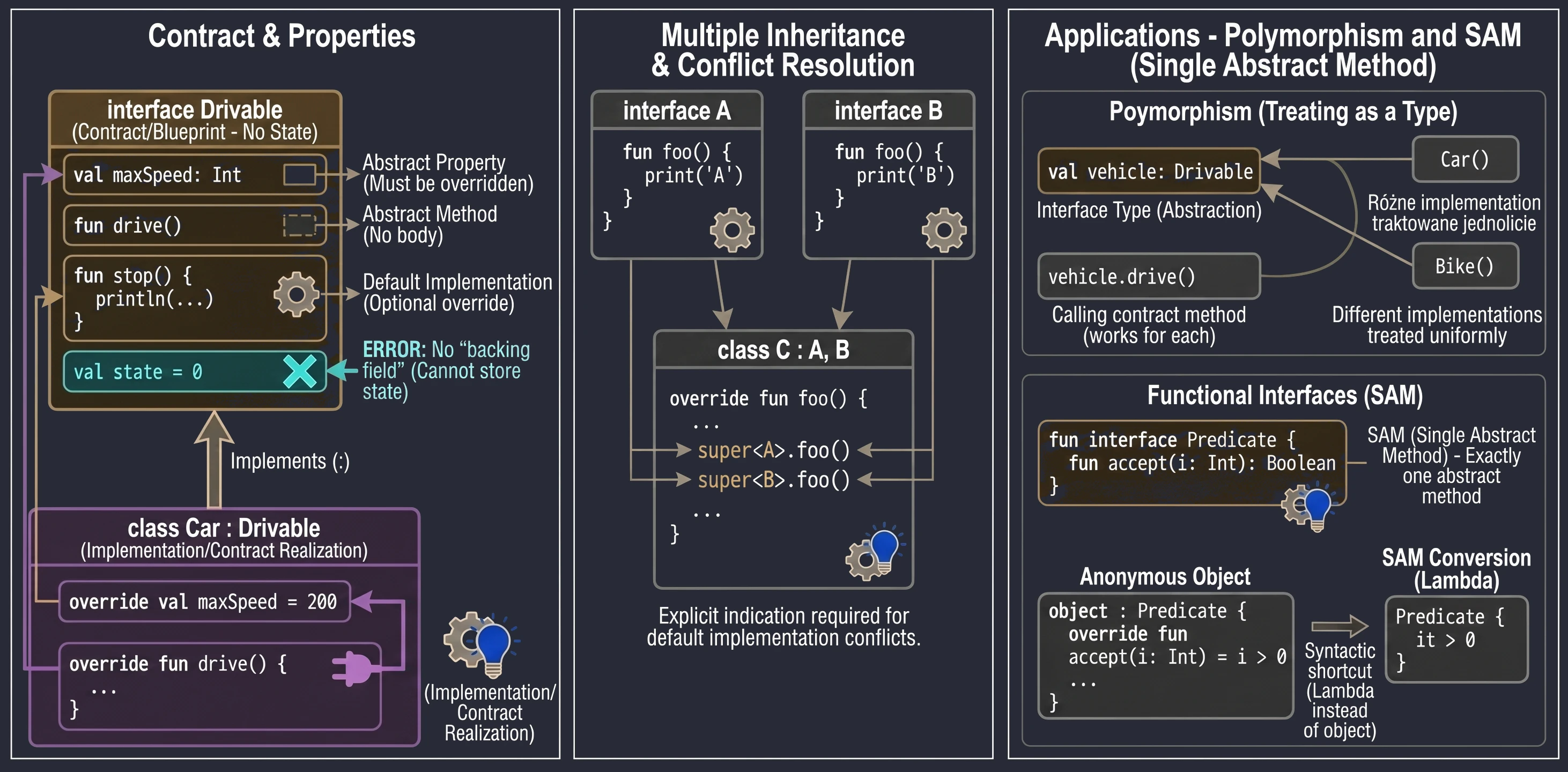
W Kotlinie oznaczamy takie interfejsy słowem fun interface.
fun interface Predicate {
fun accept(i: Int): Boolean
}Dzięki temu możemy używać konwersji SAM – zamiast tworzyć obiekt anonimowy, możemy przekazać wyrażenie lambda:
// Tradycyjnie (obiekt anonimowy)
val p1 = object : Predicate {
override fun accept(i: Int) = i > 0
}
// Z użyciem konwersji SAM (lambda)
val p2 = Predicate { it > 0 }To znacznie skraca kod, zwłaszcza przy obsłudze zdarzeń w UI (np. OnClickListener).
Klasa Abstrakcyjna vs Interfejs
Skoro interfejsy mogą mieć metody z implementacją, czym różnią się od klas abstrakcyjnych?
- Stan: Klasy abstrakcyjne mogą mieć stan (pola, zmienne instancji). Interfejsy nie mogą (tylko właściwości bez backing field).
- Konstruktory: Klasy abstrakcyjne mają konstruktory, interfejsy nie.
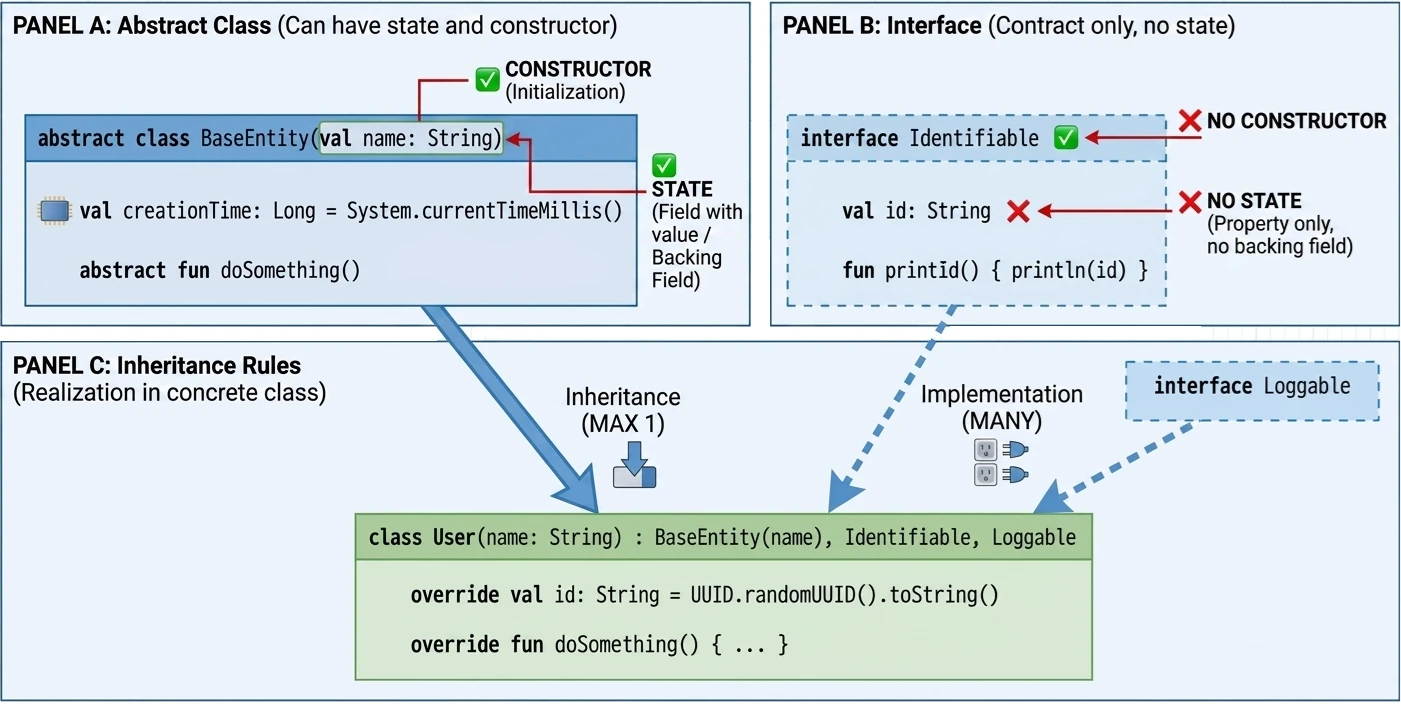
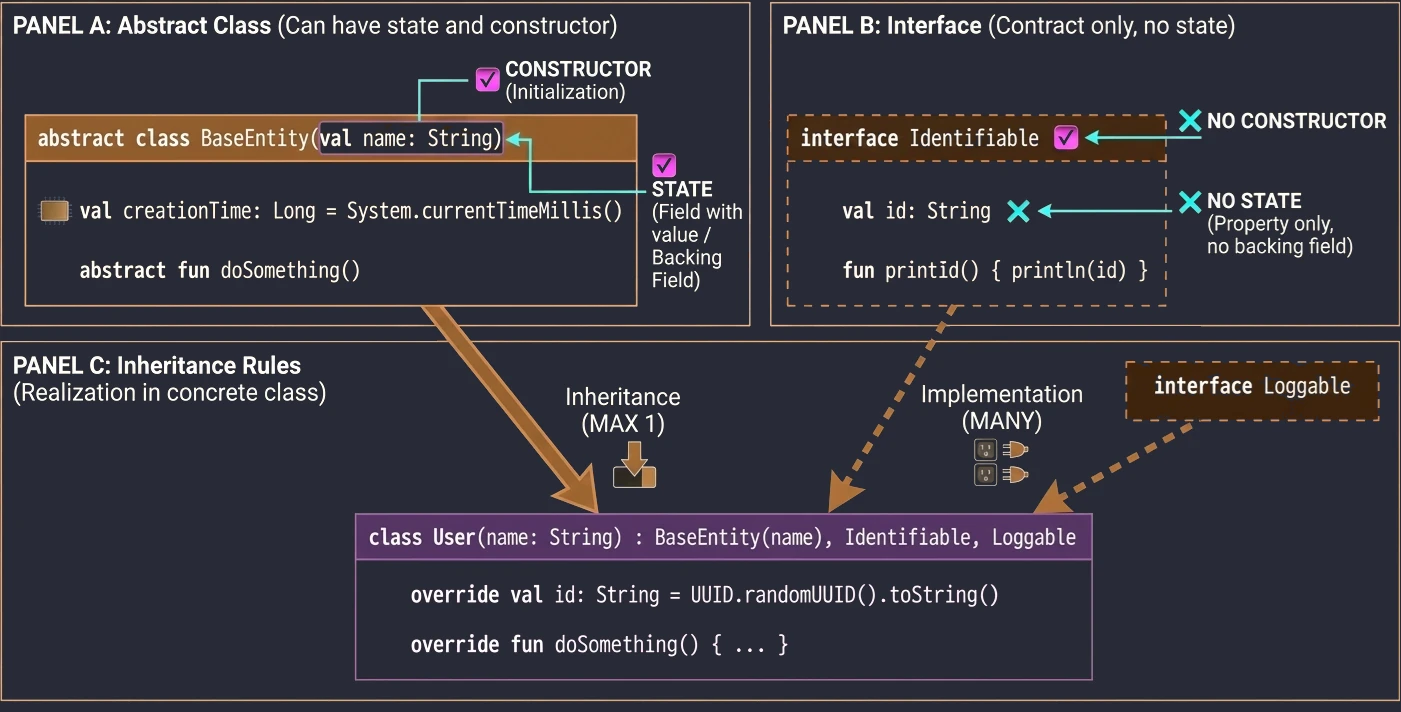
- Wielodziedziczenie: Klasa może dziedziczyć tylko po jednej klasie (abstrakcyjnej lub nie), ale może implementować wiele interfejsów.
W tym rozdziale zajmiemy się mechanizmami, które pozwalają na efektywne zarządzanie inicjalizacją właściwości oraz przekazywaniem odpowiedzialności za ich obsługę do innych obiektów. Poznamy słowa kluczowe lateinit, by lazy oraz wzorzec Delegata.
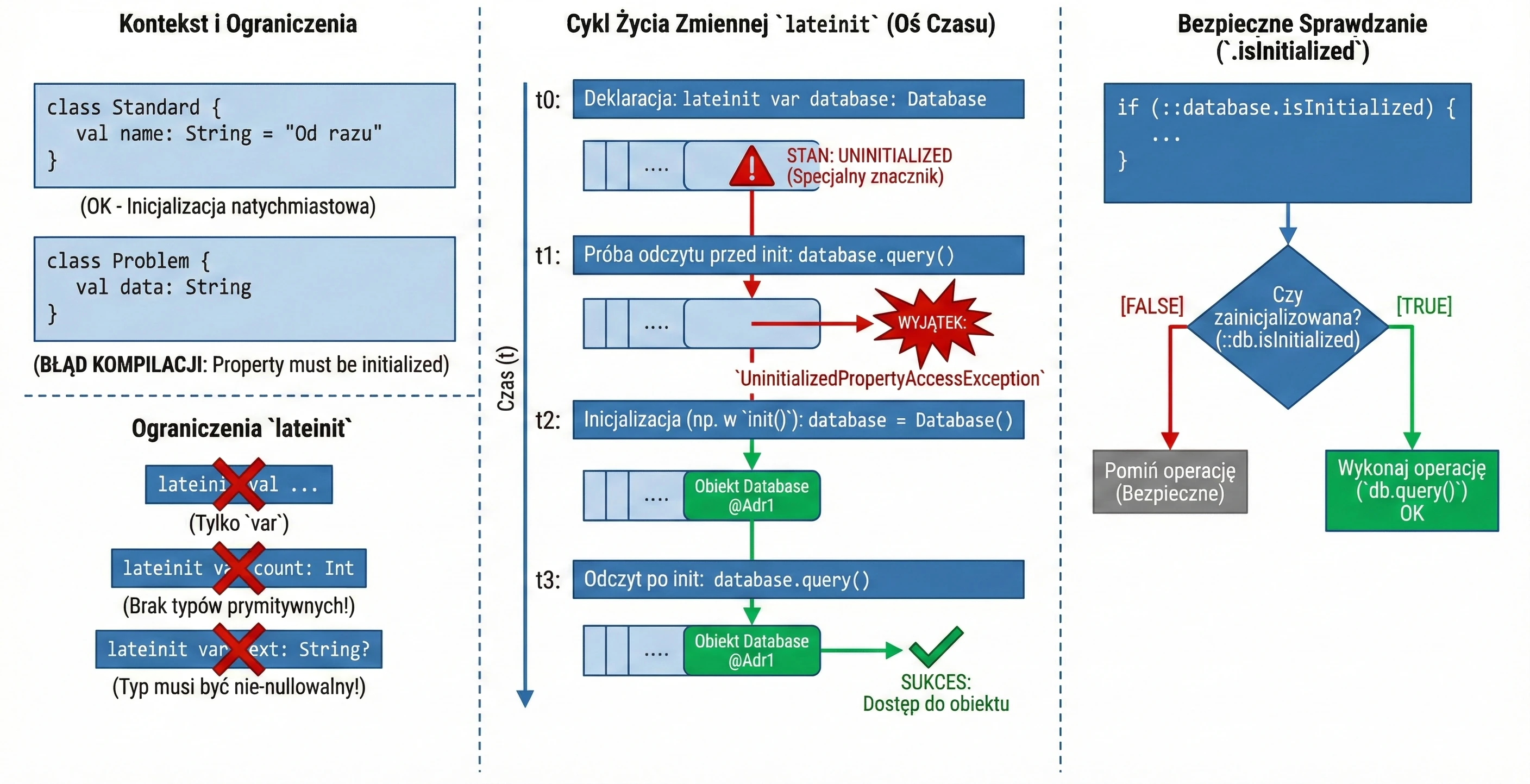
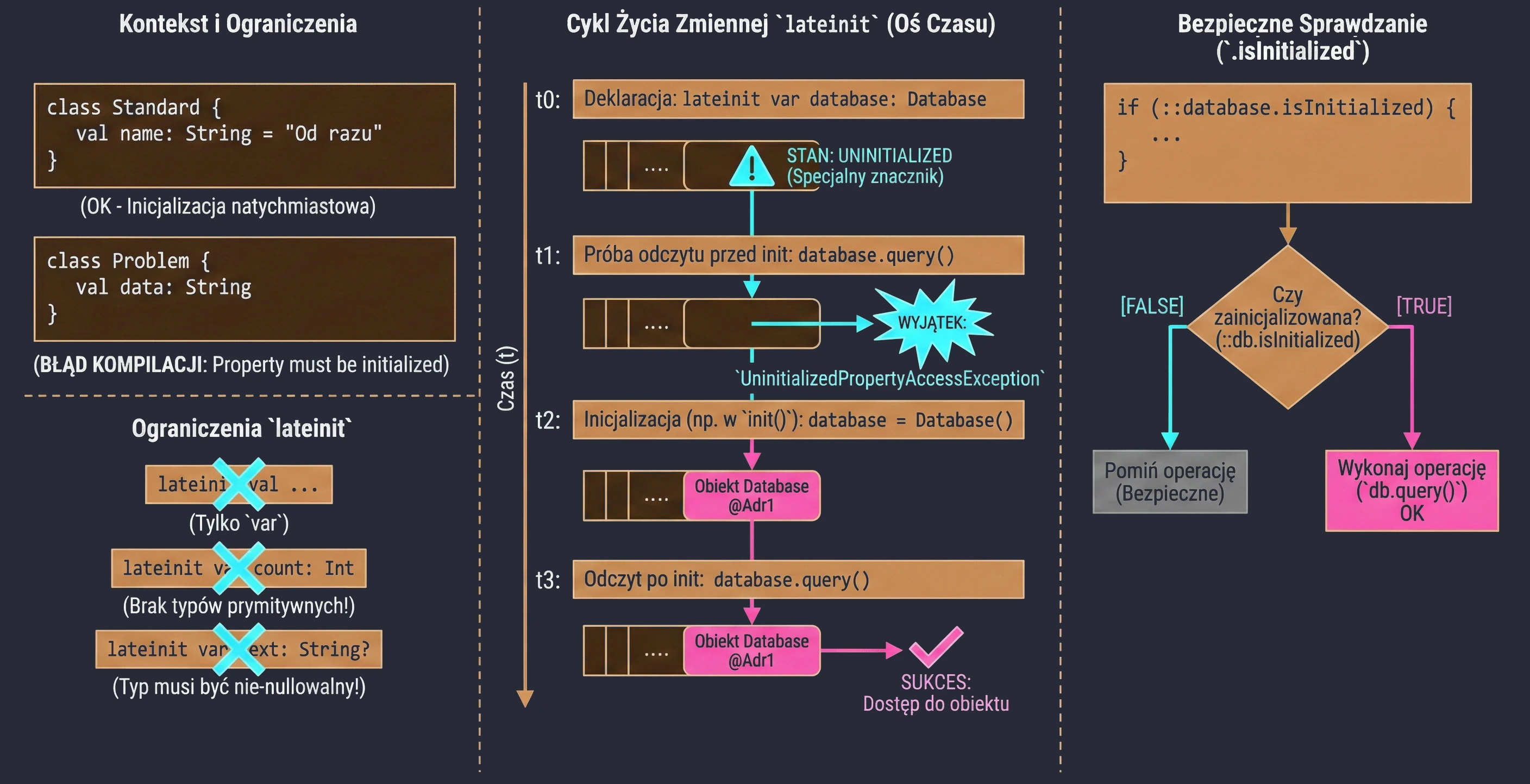
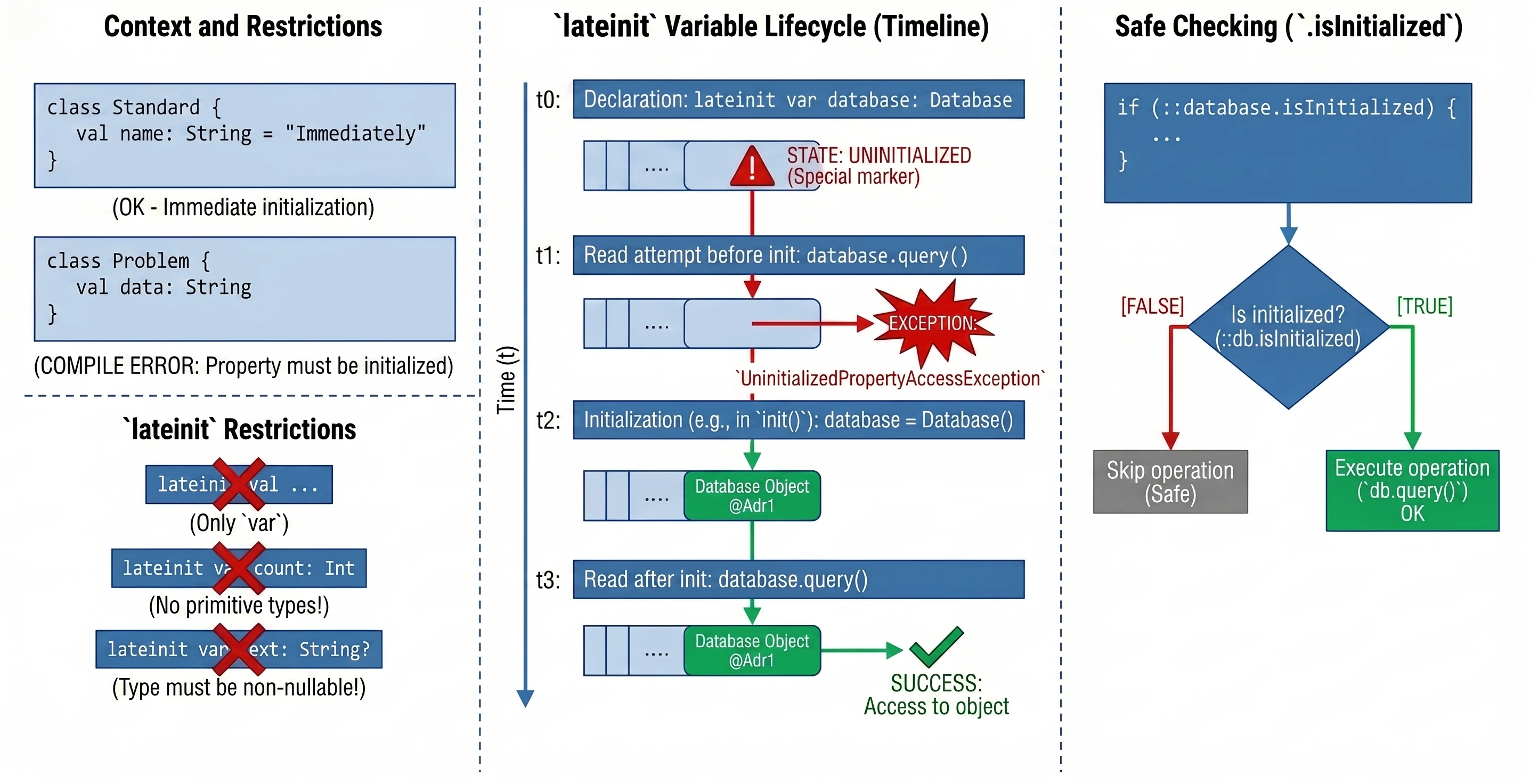
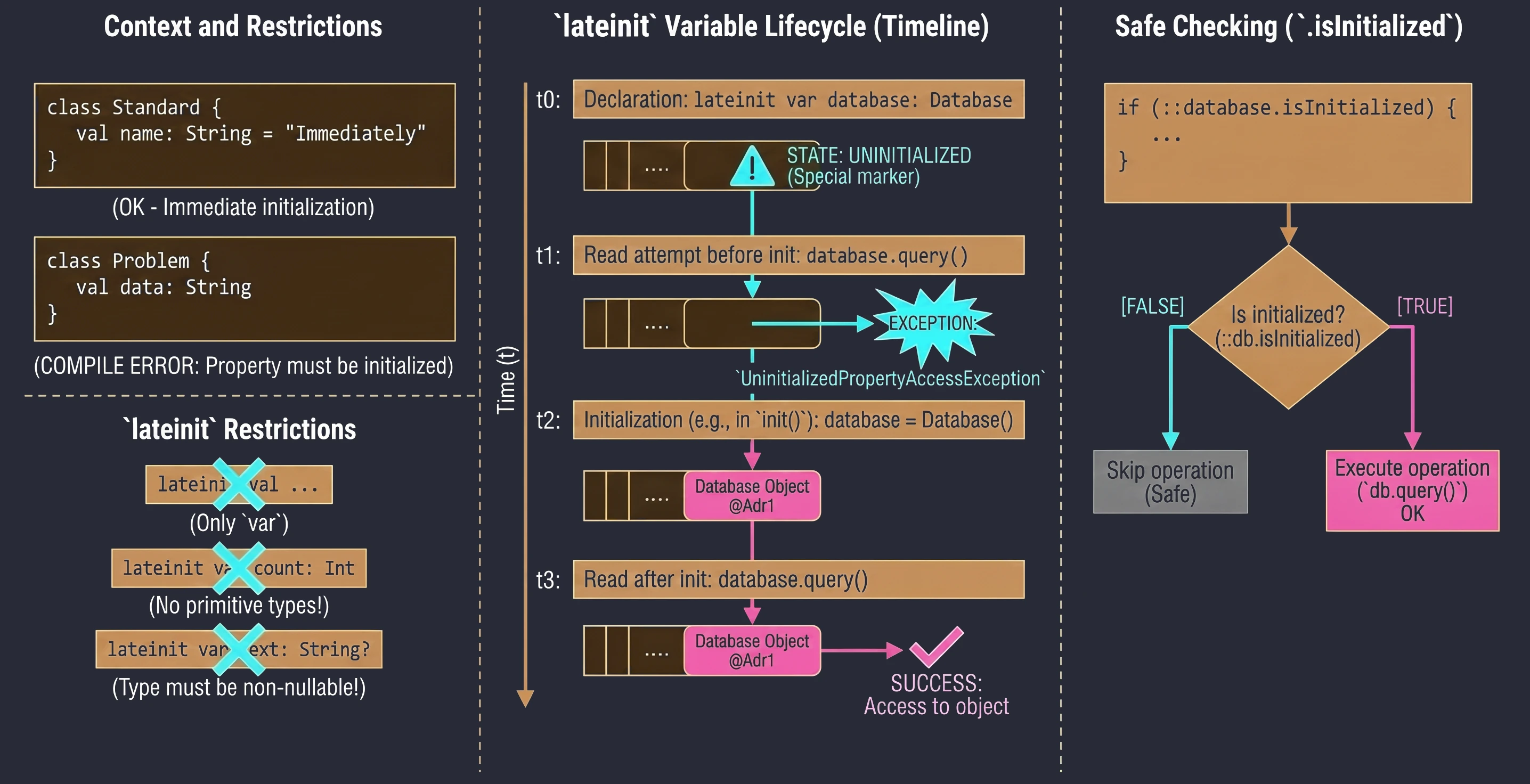
Opóźniona Inicjalizacja (lateinit)
W Kotlinie właściwości klasy, które nie są nullowalne (nie mają ?), muszą zostać zainicjalizowane w konstruktorze lub od razu przy deklaracji. Czasami jednak nie znamy wartości początkowej w momencie tworzenia obiektu – np. gdy jest ona wstrzykiwana przez framework (np. Dependency Injection w Androidzie).
W takich sytuacjach używamy modyfikatora lateinit. Jest to zmienna, która nie jest nullowalna, ale nie jest zainicjalizowana w konstruktorze.
class MyService {
lateinit var database: Database // Nie musimy od razu przypisywać wartości
fun init() {
database = Database() // Inicjalizacja później
}
fun query() {
// Jeśli wywołamy to przed init(), dostaniemy wyjątek
database.query()
}
}Ograniczenia:
- Tylko dla zmiennych
var. - Nie można używać z typami prostymi (prymitywnymi) jak
Int,Double,Boolean. - Typ nie może być nullowalny.
Aby upewnić się, czy zmienna została zainicjalizowana, możemy użyć referencji .isInitialized:
if (::database.isInitialized) {
println("Baza gotowa")
}
Delegaty (Delegated Properties)
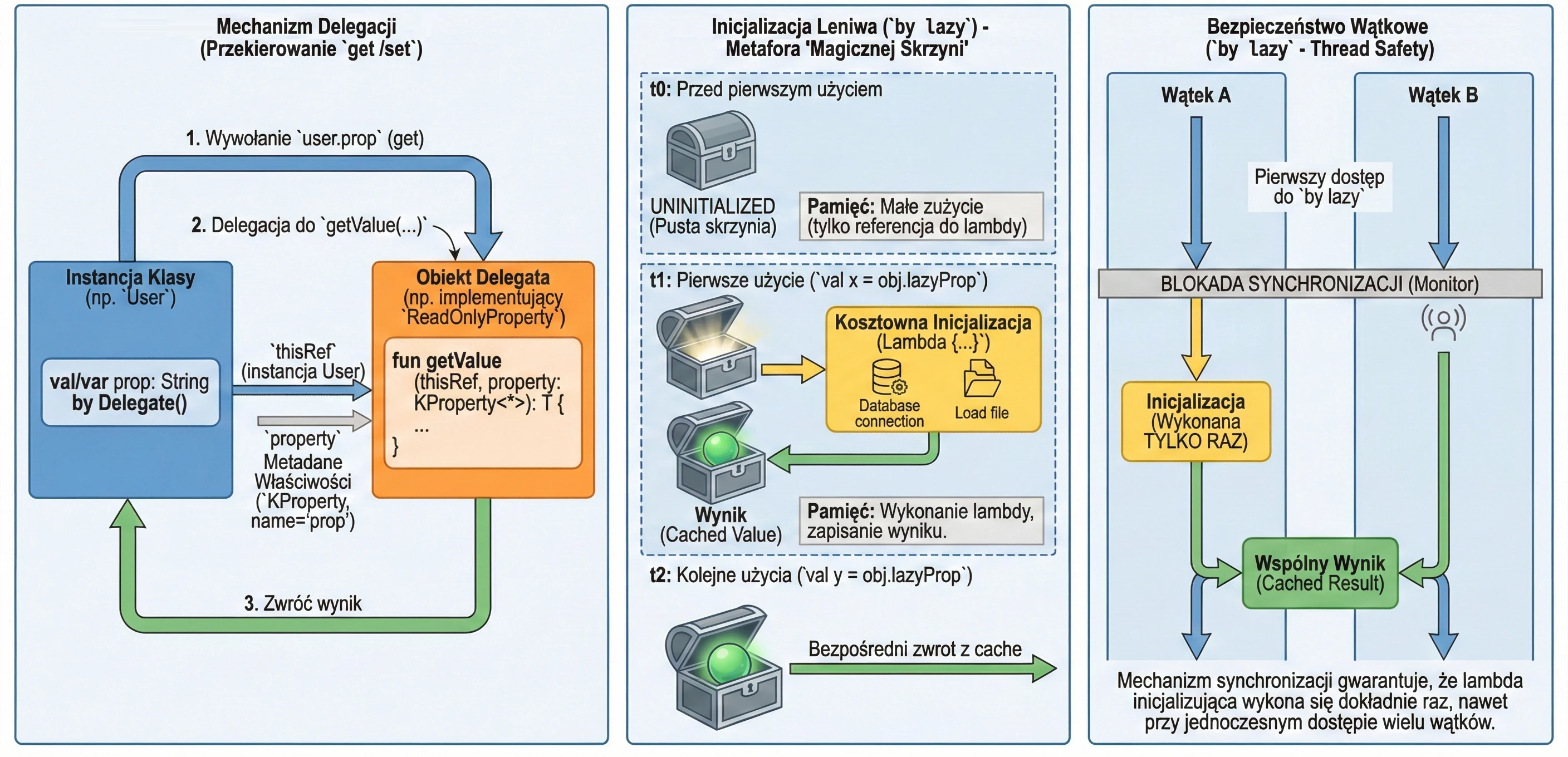
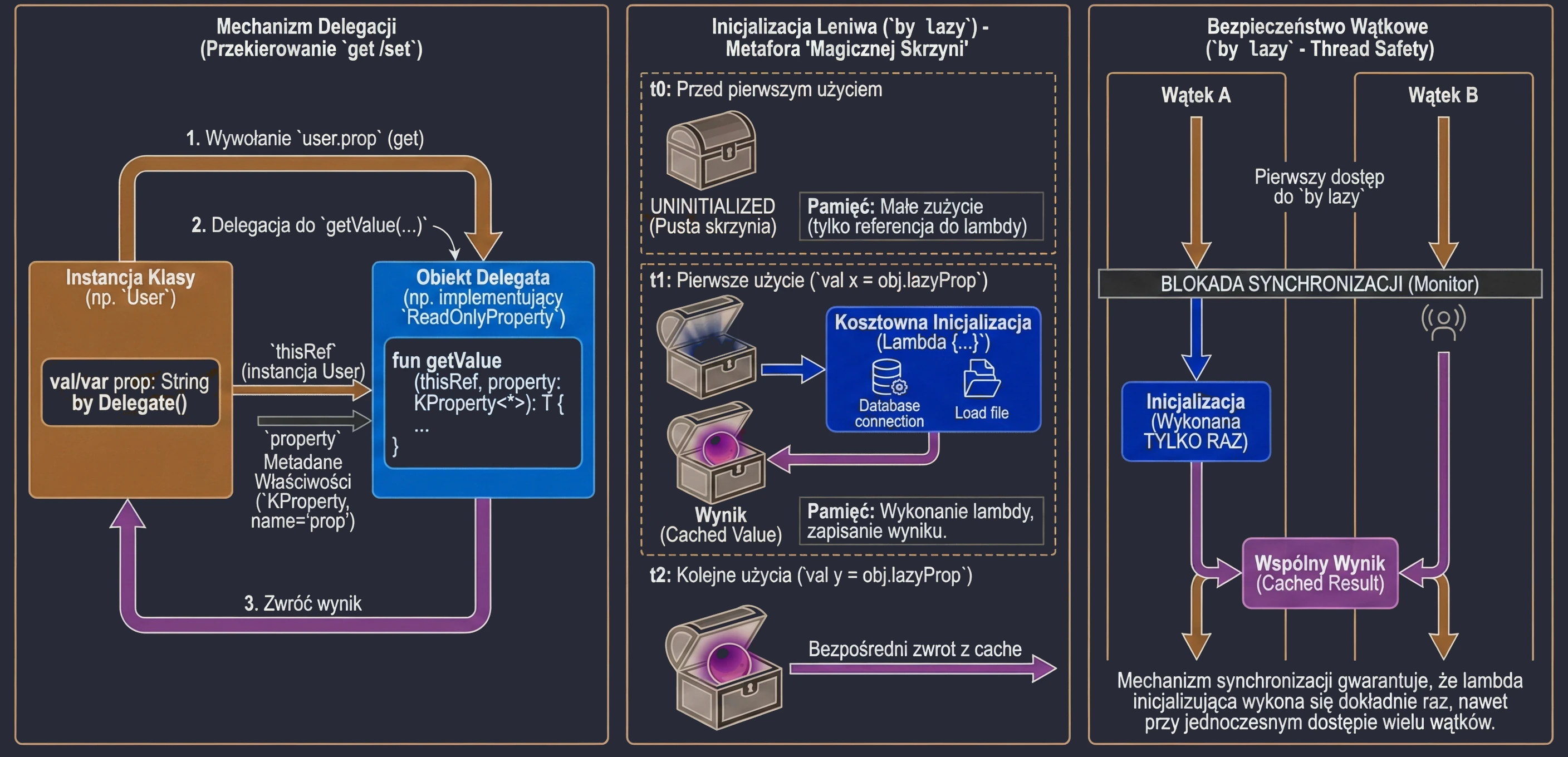
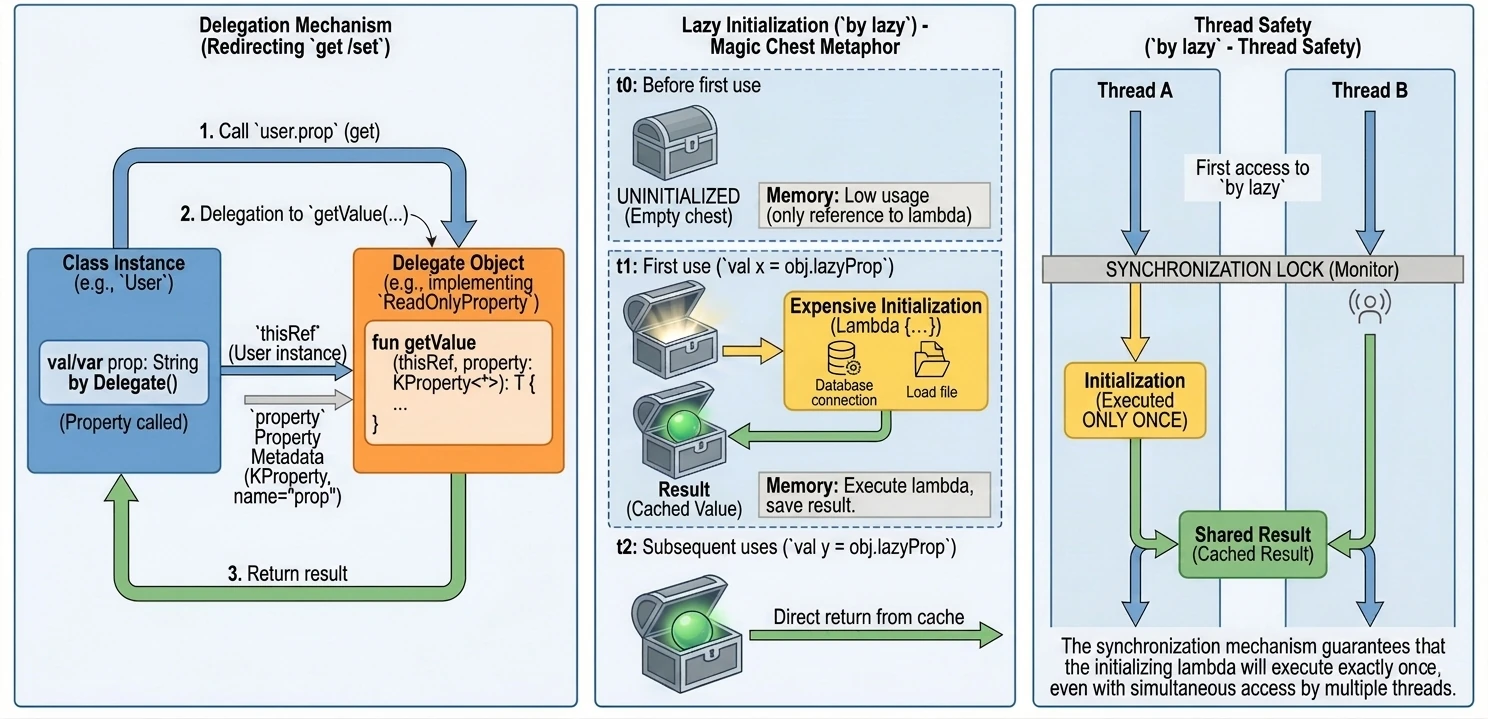
Delegacja właściwości to mechanizm, w którym obsługa metod get() (i ew. set()) jest przekazywana do innego obiektu. Składnia wykorzystuje słowo kluczowe by.
Delegaty to mechanizm pozwalający na przekazywanie odpowiedzialności za implementację właściwości innemu obiektowi - przekazanie wywołania metod get() i set() do innego obiektu.
Do dyspozycji mamy dwa wbudowane interfejsy definiujące sygnatury metod tylko do odczytu oraz do odczytu i zapisu właściwości.
interface ReadOnlyProperty<in R, out T> {
operator fun getValue(thisRef: R, property: KProperty<*>): T
}
interface ReadWriteProperty<in R, T> {
operator fun getValue(thisRef: R, property: KProperty<*>): T
operator fun setValue(thisRef: R, property: KProperty<*>, value: T)
}KProperty to interfejs z biblioteki refleksji (kotlin.reflect), który reprezentuje deklarację właściwości. Dzięki niemu w metodzie delegata (getValue/setValue) mamy dostęp do metadanych właściwości, do której delegat jest przypisany – przede wszystkim do jej nazwy (name), ale też np. typu czy adnotacji.
Zapis KProperty<*> wykorzystuje tak zwaną projekcję gwiazdkową (star-projection). Oznacza ona, że delegat może obsługiwać właściwość dowolnego typu, a my nie potrzebujemy znać tego konkretnego typu w miejscu deklaracji metody getValue.
Mówiąc prościej: KProperty<*> pasuje do każdej właściwości (KProperty<String>, KProperty<Int> itd.), ponieważ wewnątrz delegata zazwyczaj interesują nas tylko metadane samej właściwości (np. jej nazwa), a nie typ wartości, jaką ona przechowuje. Jest to bezpieczny sposób na powiedzenie nie obchodzi mnie, jaki to dokładnie typ generyczny, o ile jest to KProperty.
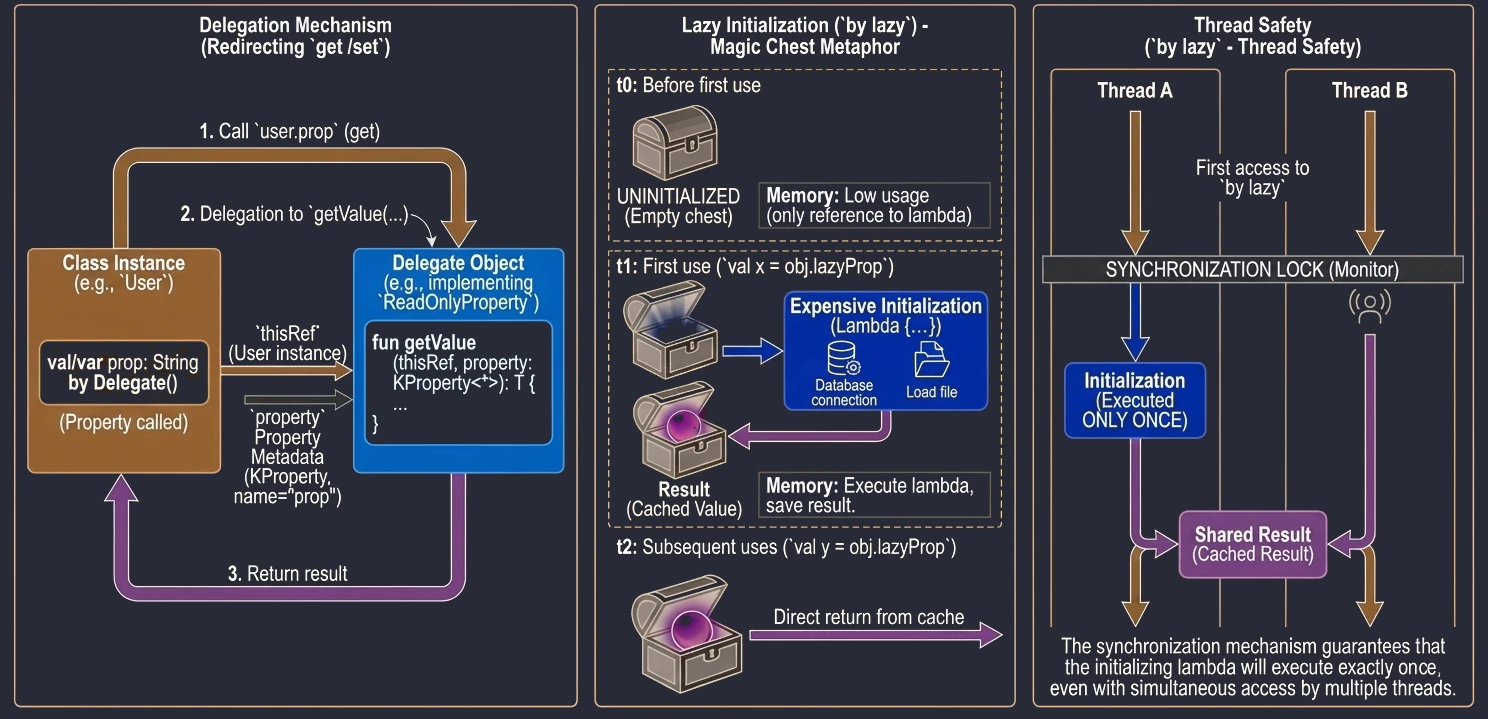
Inicjalizacja Leniwa (by lazy)
Najpopularniejszym delegatem w Kotlinie jest lazy. Pozwala on na obliczenie wartości właściwości dopiero przy jej pierwszym użyciu. Wynik jest zapamiętywany i zwracany przy wszystkich kolejnych odwołaniach. Jest to idealne rozwiązanie dla kosztownych operacji (np. wczytywanie pliku, nawiązywanie połączenia z bazą danych, skomplikowane obliczenia), których nie chcemy wykonywać, jeśli nie będą potrzebne.
Wyobraź sobie, że masz w domu magiczną skrzynię, która rzekomo zawiera bardzo ciężki przedmiot (np. kowadło). Dopóki nie otworzysz skrzyni (nie spróbujesz użyć przedmiotu), w środku tak naprawdę nic nie ma (pamięć nie jest zajęta). Dopiero w momencie pierwszego otwarcia (pierwszy dostęp do zmiennej), przedmiot jest "materializowany" (tworzony). Od tej pory, każde kolejne otwarcie skrzyni pokazuje ten sam, już istniejący przedmiot.
class DataProcessor {
val heavyData: List<String> by lazy {
println("Ładowanie danych z dysku...") // Wykona się tylko raz!
Thread.sleep(1000) // Symulacja długiej operacji
listOf("Dane 1", "Dane 2", "Dane 3")
}
}
fun main() {
val processor = DataProcessor()
println("Procesor utworzony")
// "Ładowanie danych..." jeszcze się nie pojawiło
println(processor.heavyData) // Pierwsze użycie: Inicjalizacja + Wypisanie
println(processor.heavyData) // Drugie użycie: Tylko wypisanie (pamięć podręczna)
}Delegat lazy domyślnie jest bezpieczny wątkowo (thread-safe). Oznacza to, że jeśli wiele wątków spróbuje jednocześnie odczytać właściwość by lazy po raz pierwszy, mechanizm synchronizacji zagwarantuje, że kod inicjalizujący wykona się tylko raz, a wszystkie wątki otrzymają tę samą instancję.
Dzięki temu by lazy jest świetnym sposobem na implementację wzorca Singleton dla pojedynczej właściwości lub kosztownego zasobu. Nie musimy martwić się o ręczną synchronizację (jak w Javie synchronized czy double-check locking) – Kotlin robi to za nas.
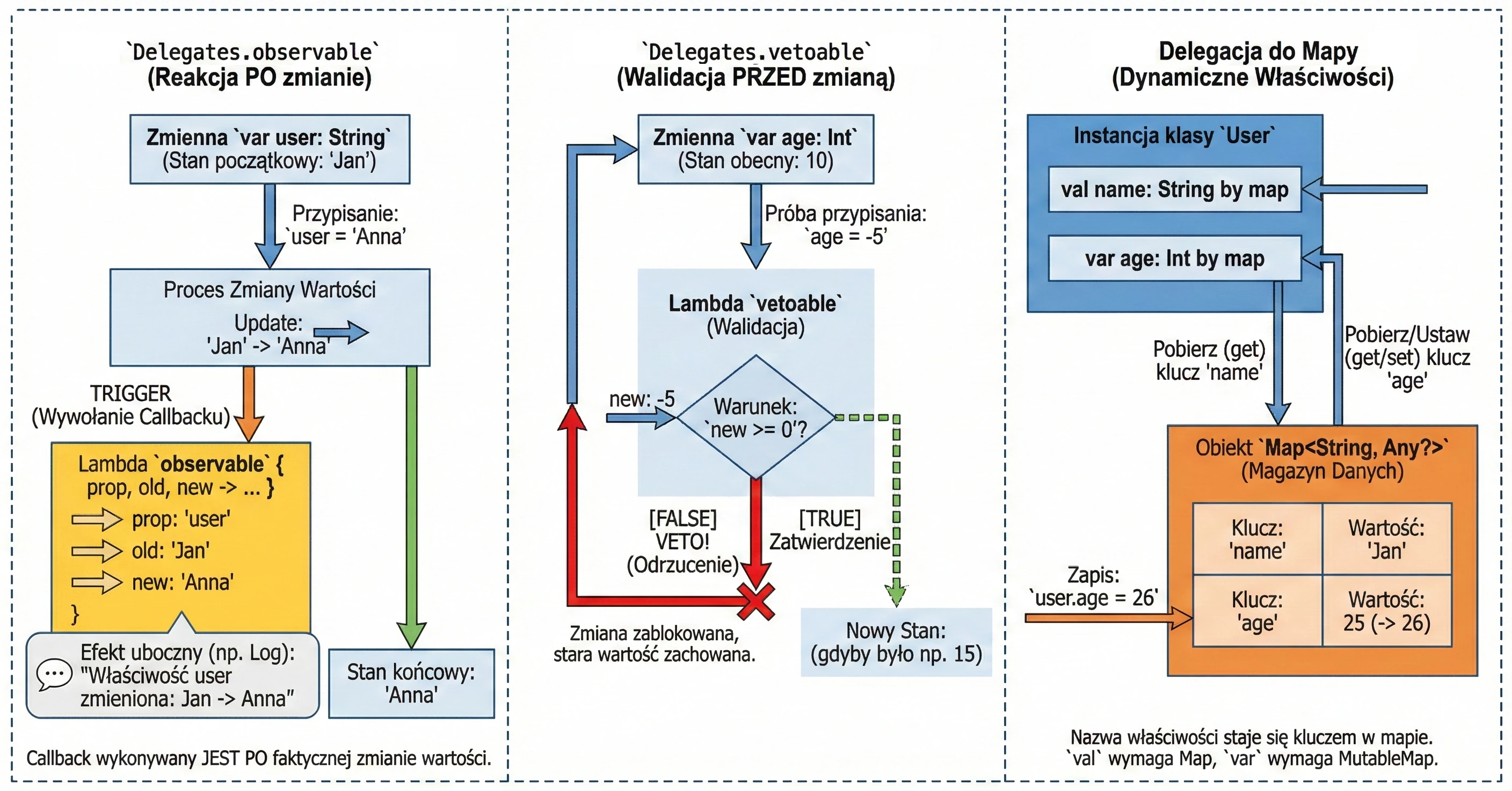
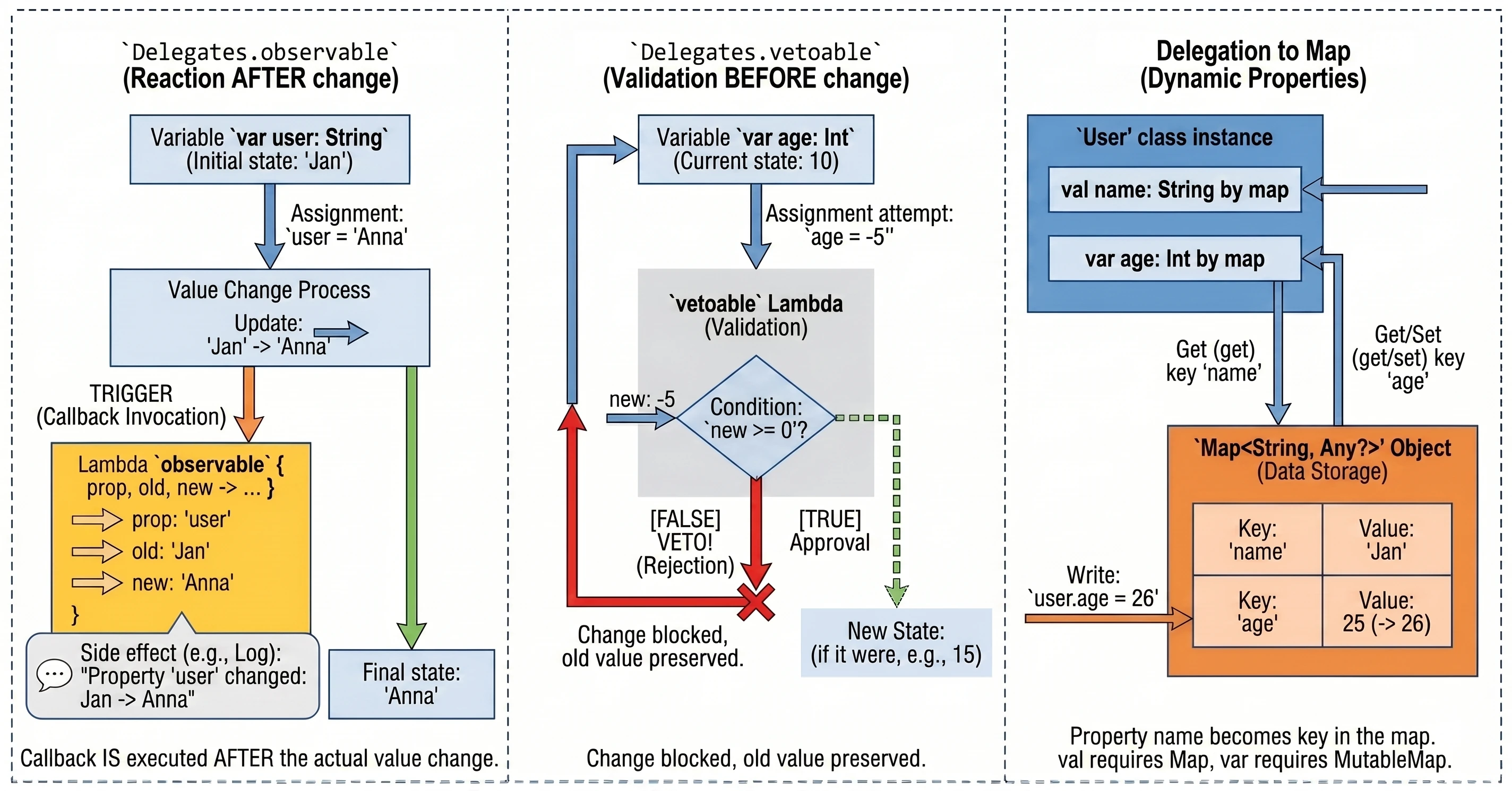
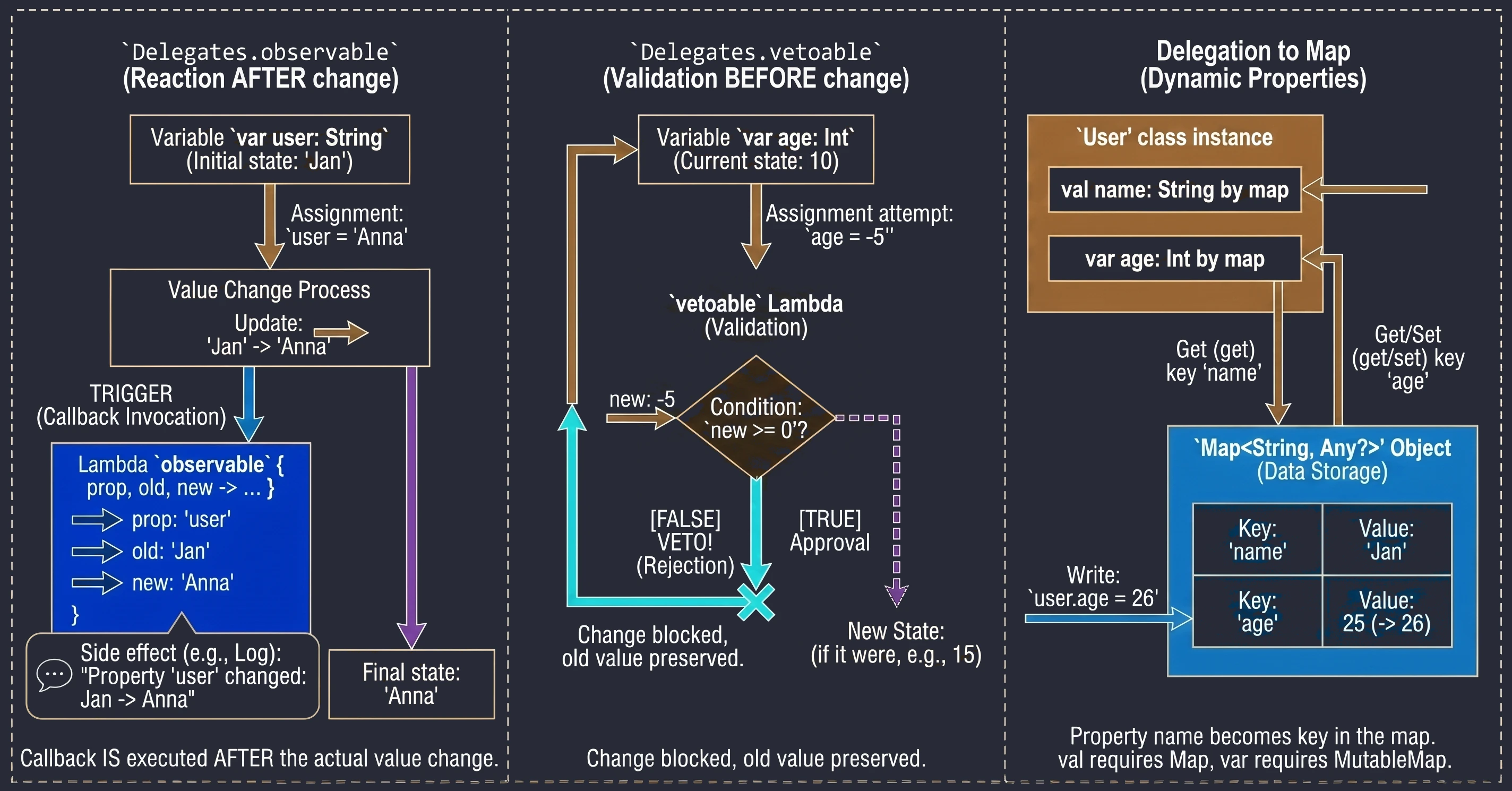
Obserwowanie zmian (Delegates.observable)
Ten delegat pozwala na przypięcie obserwatora do właściwości. Za każdym razem, gdy wartość właściwości ulegnie zmianie, wywoływana jest funkcja lambda (callback) z informacją o zmianie. Jest to bardzo przydatne do logowania, aktualizacji UI po zmianie danych, czy powiadamiania innych części systemu.
Delegat przyjmuje dwa argumenty:
- Wartość początkową (default value).
- Funkcję lambda wywoływaną po każdej zmianie. Lambda ta otrzymuje trzy parametry:
property: Metadane właściwości (KProperty).oldValue: Poprzednia wartość.newValue: Nowa wartość.
import kotlin.properties.Delegates
var user: String by Delegates.observable("<brak>") { prop, old, new ->
println("Właściwość '${prop.name}' zmieniona: '$old' -> '$new'")
}
fun main() {
user = "Jan" // Wypisze: Właściwość 'user' zmieniona: '<brak>' -> 'Jan'
user = "Anna" // Wypisze: Właściwość 'user' zmieniona: 'Jan' -> 'Anna'
}Callback wywoływany jest po przypisaniu nowej wartości (dlatego wewnątrz lambdy pole ma już nową wartość).
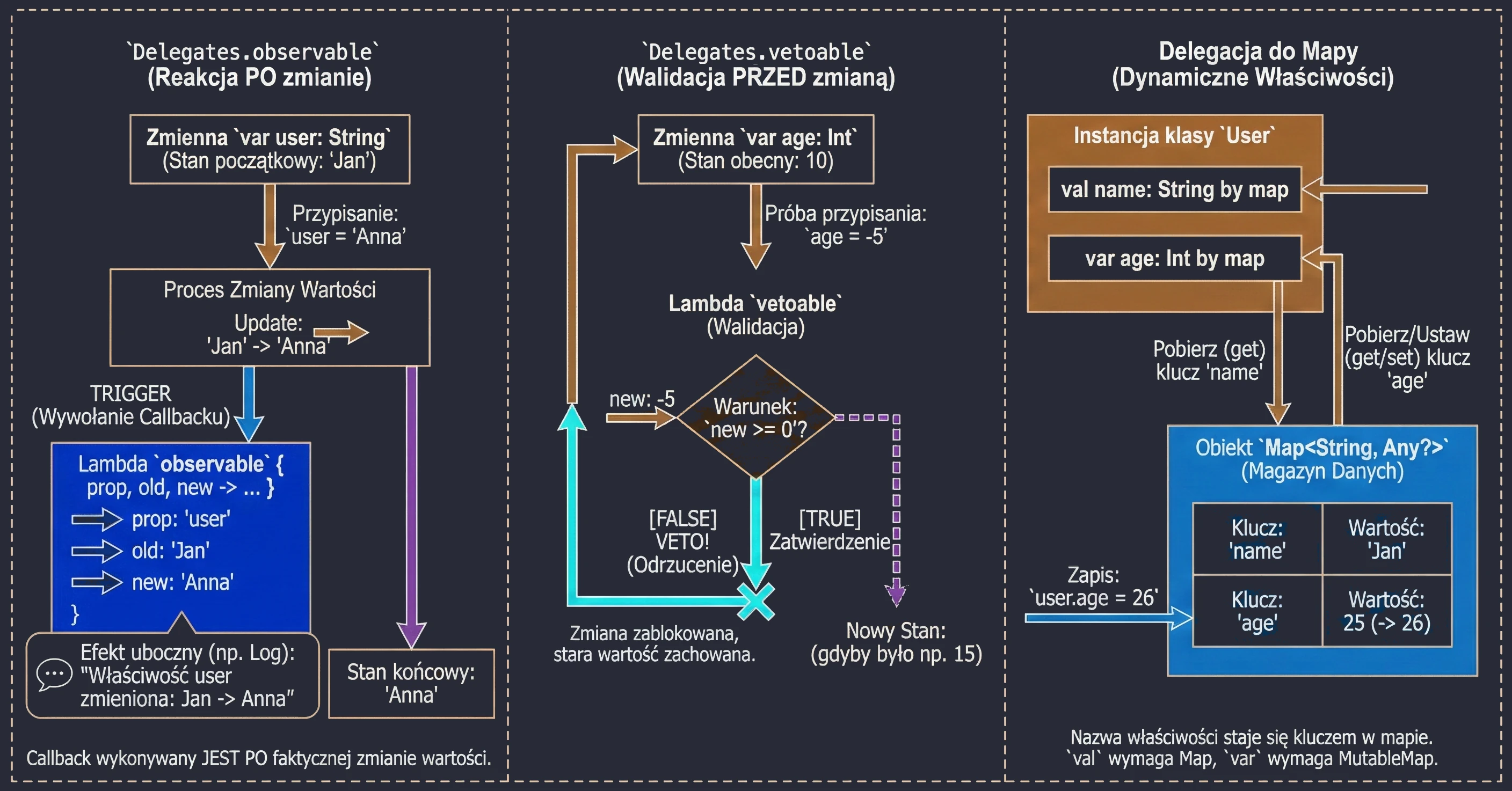
Wetowanie zmian (Delegates.vetoable)
Ten delegat działa podobnie do observable, ale daje możliwość zablokowania (zawetowania) zmiany. Funkcja lambda jest wywoływana przed przypisaniem nowej wartości i musi zwrócić wartość typu Boolean:
true: Zmiana zostaje zatwierdzona.false: Zmiana zostaje odrzucona (zmienna zachowuje starą wartość).
Jest to idealne miejsce na prostą walidację danych "w locie".
var age: Int by Delegates.vetoable(0) { prop, old, new ->
println("Próba zmiany ${prop.name} z $old na $new")
new >= 0 // Warunek: wiek nie może być ujemny
}
age = 10 // Zatwierdzone (10 >= 0)
println(age) // 10
age = -5 // Odrzucone (-5 < 0) - pozostaje stara wartość
println(age) // 10Delegowanie do Mapy
Kotlin pozwala na użycie mapy jako delegata dla właściwości. W tym mechanizmie nazwa właściwości jest używana jako klucz do pobrania wartości z mapy.
Jest to szczególnie przydatne w sytuacjach, gdy pracujemy z dynamicznymi zestawami danych, takimi jak:
- Parsowanie obiektów JSON, bez tworzenia dedykowanych klas DTO dla każdej struktury.
- Praca z konfiguracjami aplikacji, gdzie parametry są wczytywane do mapy (np. z pliku .properties).
- Interakcja z zewnętrznymi API lub bibliotekami, które zwracają dane w postaci par klucz-wartość.
class User(val map: Map<String, Any?>) {
val name: String by map
val age: Int by map
}
val data = mapOf("name" to "Jan", "age" to 25)
val u = User(data)
println(u.name) // "Jan"Wymogiem jest, aby klucze w mapie (String) odpowiadały dokładnie nazwom właściwości.
Jeśli użyjemy MutableMap, możemy delegować również właściwości zmienne (var). Wtedy przypisanie wartości do właściwości zaktualizuje odpowiedni wpis w mapie.
W tym rozdziale przechodzimy od czystego języka Kotlin do tworzenia aplikacji na platformę Android. Zrozumienie podstawowych komponentów i cyklu życia aplikacji jest kluczowe dla pisania stabilnego i wydajnego oprogramowania mobilnego.
Struktura Aplikacji i Manifest
Każda aplikacja Android składa się z zestawu komponentów, które są zadeklarowane w pliku AndroidManifest.xml. Jest to dowód tożsamości aplikacji. System operacyjny Android odczytuje ten plik przed uruchomieniem jakiegokolwiek kodu aplikacji. Zawiera on:
- Nazwę pakietu (unikalny identyfikator aplikacji, np.
com.example.myapp). - Deklaracje komponentów: Aktywności (
<activity>), Usługi (<service>), Odbiorniki (<receiver>) i Dostawcy treści (<provider>). - Uprawnienia: Czego aplikacja potrzebuje do działania (np. dostęp do Internetu, kamery).
Przykładowy fragment:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.myapp">
<uses-permission android:name="android.permission.INTERNET" />
<application ... >
<activity android:name=".MainActivity"
android:exported="true">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>W powyższym przykładzie kluczowe są dwa elementy filtru intencji (intent-filter):
- Action MAIN: Informuje system, że ta aktywność jest głównym punktem wejścia do aplikacji.
- Category LAUNCHER: Powoduje, że ikona aplikacji zostanie umieszczona w menu (launcherze) systemu Android. Bez tej kategorii aplikacja nie byłaby widoczna na liście zainstalowanych programów, a jej ręczne uruchomienie przez użytkownika byłoby niemożliwe.
Aplikacja musi posiadać co najmniej jedną aktywność, aby użytkownik mógł wejść z nią w bezpośrednią interakcję. Choć system dopuszcza pakiety bez interfejsu graficznego (np. biblioteki lub specyficzne usługi systemowe), to właśnie Aktywność jest jedynym komponentem zdolnym do renderowania pełnoekranowego okna i bezpośredniego odbierania zdarzeń dotykowych. Inne elementy, takie jak powiadomienia czy widżety, służą jedynie jako pomocnicze punkty, które w większości przypadków i tak mają za zadanie przekierować użytkownika do konkretnej aktywności w celu wykonania pełnej akcji.
Aktywność (Activity)
Aktywność (Activity) historycznie, to podstawowy komponent reprezentujący pojedynczy ekran interfejsu użytkownika, z którym użytkownik może wchodzić w interakcję.
- Klasycznie (View System): Aktywność była centralnym punktem zarządzania UI. Odpowiadała za ładowanie layoutu XML, znajdowanie widoków (
findViewById) i obsługę zdarzeń. Często prowadziło to do powstania ogromnych klas (God Activity). - Jetpack Compose: Aktywność staje się lekkim kontenerem (hostem). Jej głównym zadaniem jest ustawienie zawartości (
setContent) i ewentualnie obsługa specyficznych zdarzeń systemowych. Całe UI jest budowane z funkcji@Composable.
Android zarządza aplikacjami w sposób agresywny, aby oszczędzać baterię i zasoby. Aktywność może zostać w każdej chwili zniszczona (np. obrót ekranu, przyjście połączenia, brak pamięci). Dlatego system powiadamia aktywność o zmianach jej stanu poprzez metody cyklu życia:
onCreate(): Aktywność jest tworzona. Tu inicjalizujemy UI i zmienne. Wywołuje się tylko raz.onStart(): Aktywność staje się widoczna dla użytkownika, ale nie jest jeszcze interaktywna.onResume(): Aktywność jest na pierwszym planie i użytkownik może z nią wchodzić w interakcję.onPause(): Aktywność traci focus (np. pojawia się okno dialogowe lub użytkownik wychodzi). Tu zatrzymujemy animacje czy zapisujemy lekkie dane.onStop(): Aktywność nie jest już widoczna. Zwalniamy cięższe zasoby.onDestroy(): Aktywność jest usuwana z pamięci.
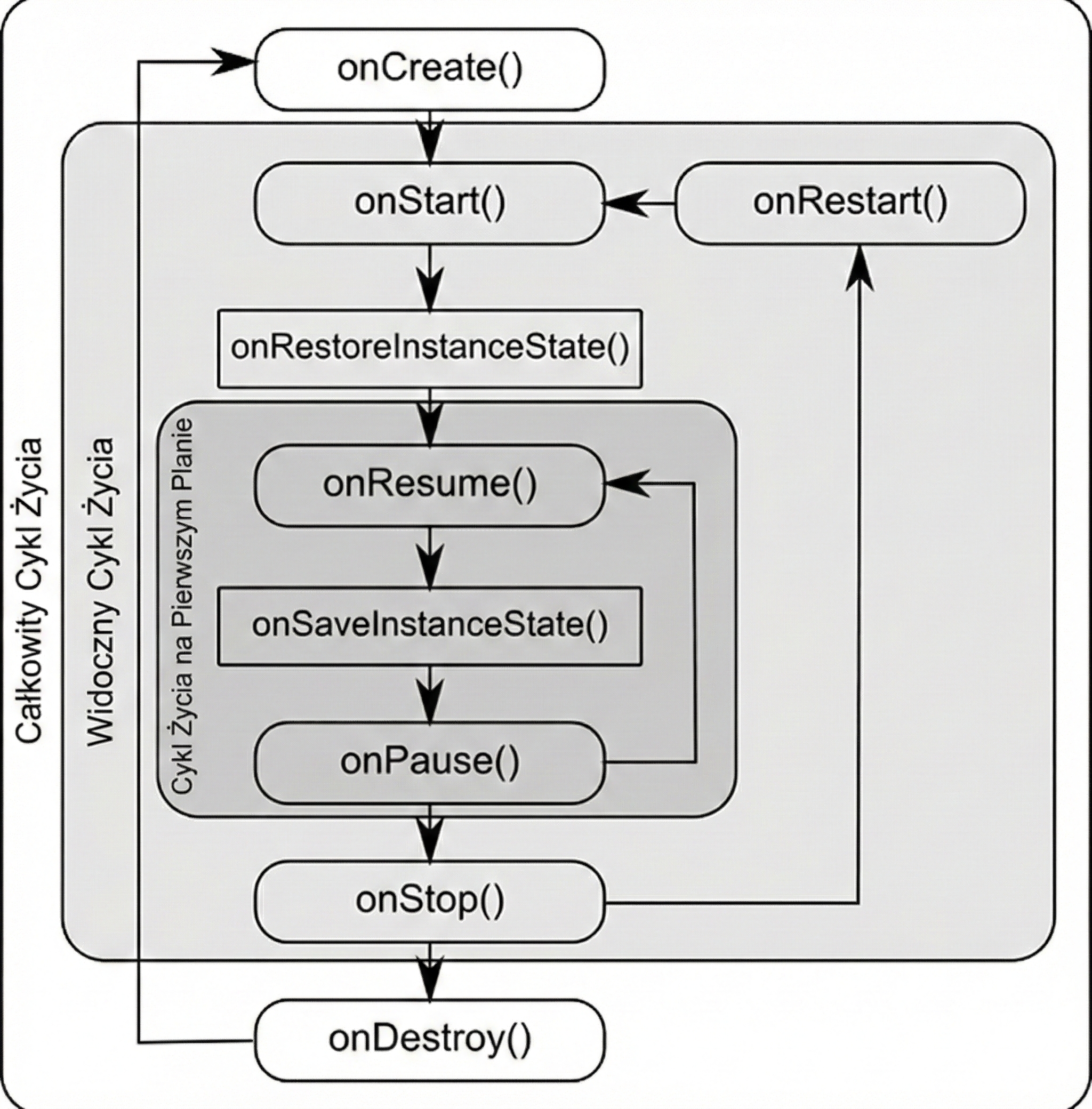
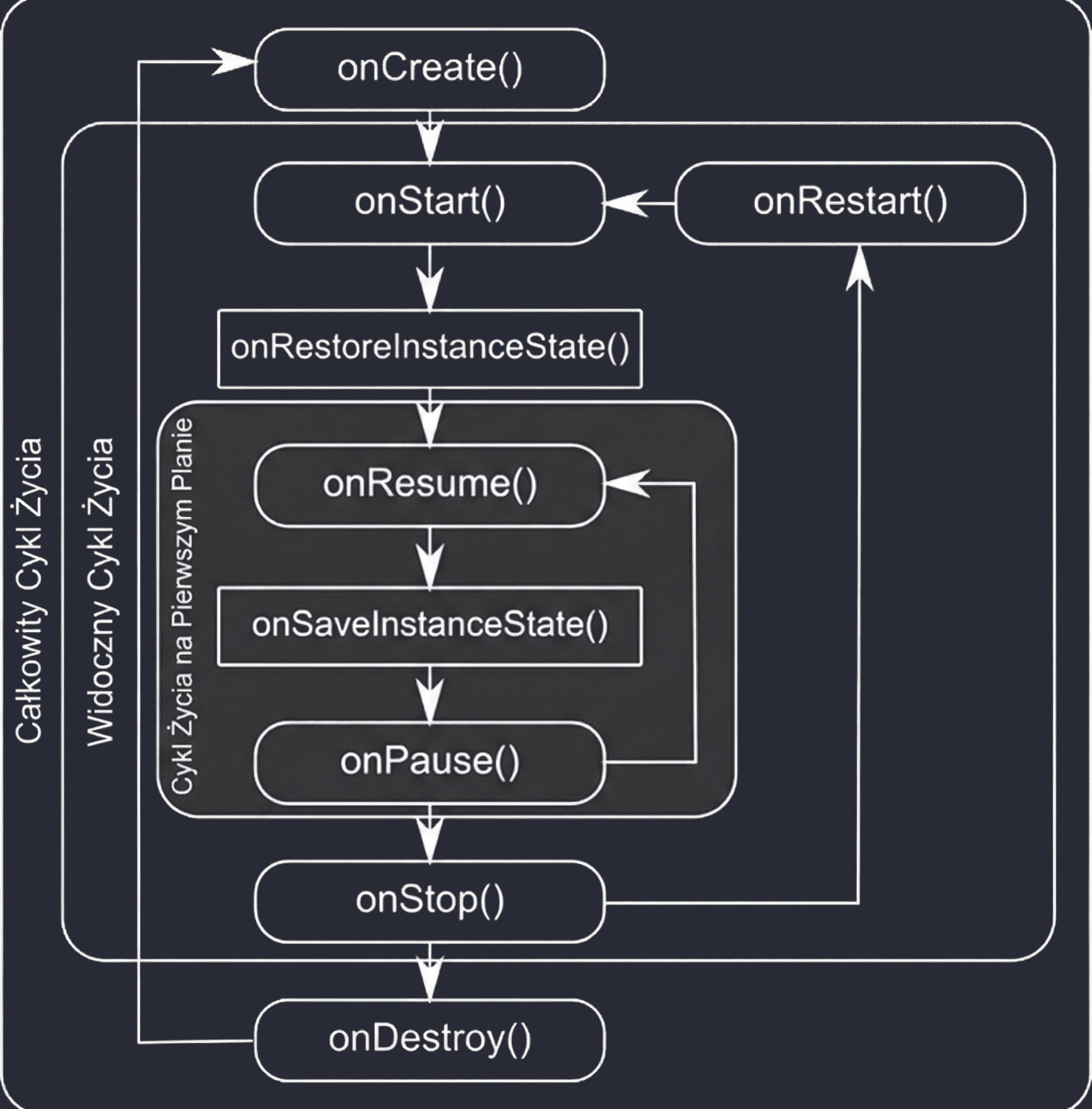
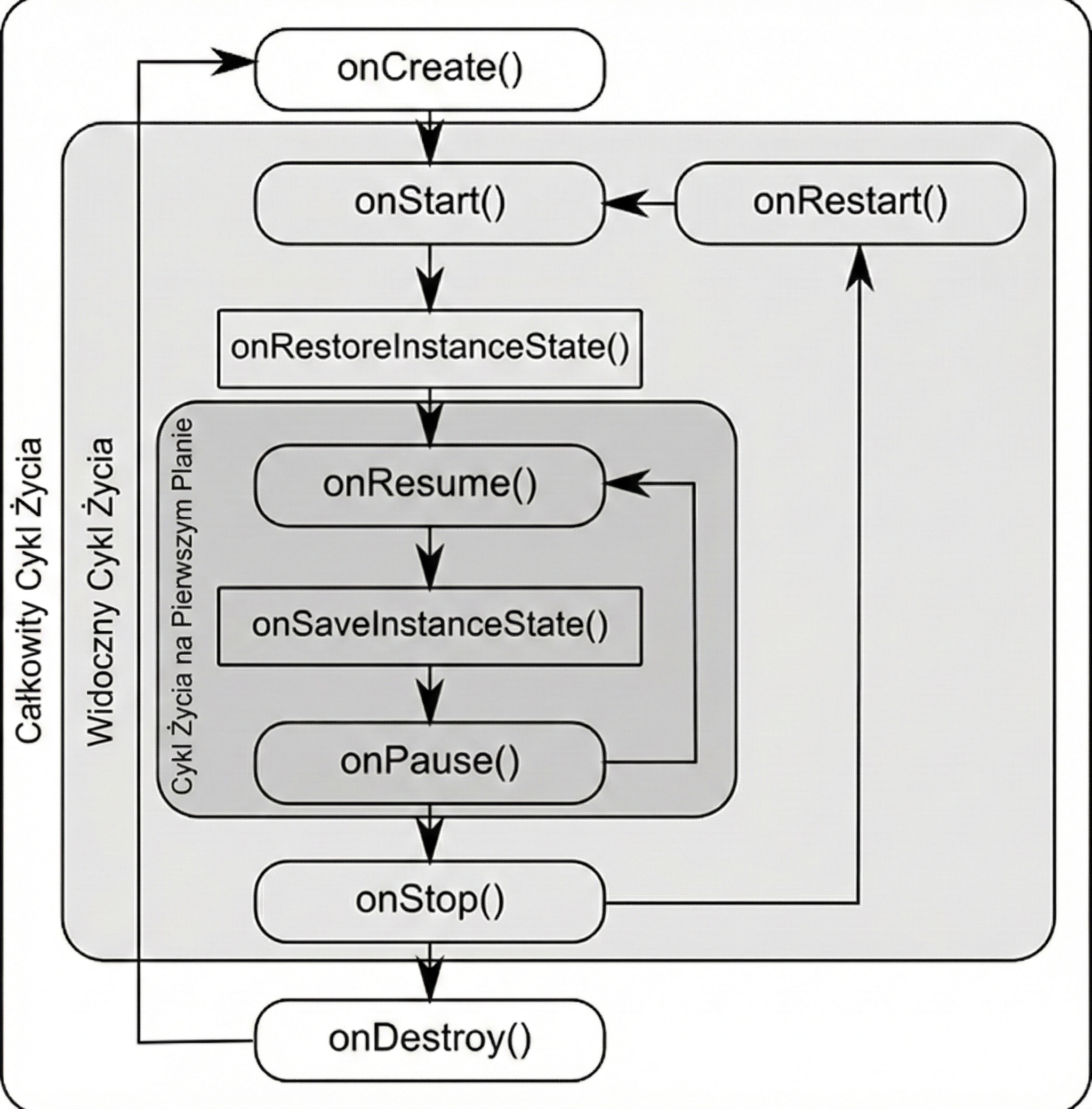
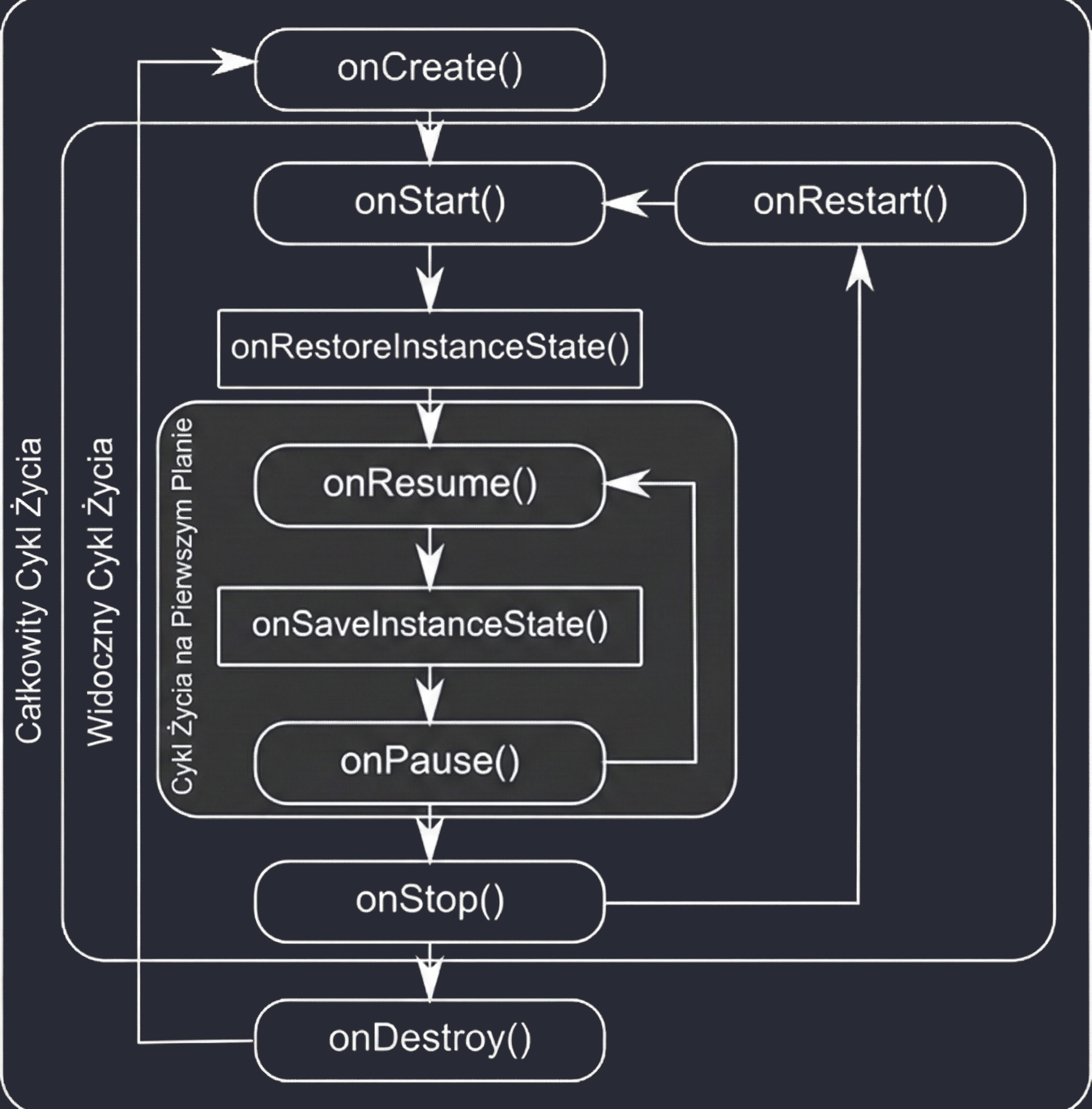
Dlaczego wprowadzono aż tyle metod? Taka granularność pozwala na precyzyjne zarządzanie zasobami poprzez podział życia aktywności na trzy zagnieżdżone cykle:
- Pełny cykl (Entire Lifetime): Między
onCreateaonDestroy. To czas, w którym obiekt aktywności w ogóle istnieje w pamięci. Tu inicjalizujemy globalny stan. - Widoczny cykl (Visible Lifetime): Między
onStartaonStop. Użytkownik widzi aplikację na ekranie, co pozwala nam np. utrzymywać zasoby potrzebne do wyświetlania interfejsu. - Cykl pierwszoplanowy (Foreground Lifetime): Między
onResumeaonPause. Aktywność znajduje się na samym wierzchu i posiada tzw. focus.
Dobrym sposobem na zapamiętanie tej hierarchii jest analogia aktora w teatrze:
onCreate: Aktor przychodzi do teatru i przygotowuje się w garderobie (inicjalizacja).onStart: Aktor wchodzi na scenę. Jest widoczny dla publiczności, ale może jeszcze stać w cieniu.onResume: Na aktora pada światło reflektora – zaczyna on swoją kwestię i główną interakcję.onPause: Reflektor gaśnie. Aktor wciąż jest na scenie, ale uwaga widzów przenosi się na kogoś innego.onStop: Aktor schodzi ze sceny za kulisy.onDestroy: Aktor zdejmuje kostium i opuszcza budynek teatru (zwalnianie pamięci).
Dzięki takiemu podziałowi system może inteligentnie zarządzać zasobami. Przykładowo, w trybie split-screen (podzielony ekran), jedna aplikacja może być w stanie onResume (ta, w której aktualnie piszemy), a druga w onPause, ale wciąż widoczna. Pozwala to np. na dalsze odtwarzanie wideo w tej drugiej aplikacji (onStart/onStop), mimo że nie jest ona w centrum uwagi.
Warto podkreślić istotny szczegół techniczny: onPause() jest często przywoływana jako ostatnia bezpieczna metoda przed potencjalnym ubiciem procesu przez system. Wynika to z historycznych założeń systemu Android (przed wersją 3.0), gdzie faktycznie po onPause() proces mógł zostać natychmiast usunięty z pamięci w sytuacjach krytycznego braku zasobów. W nowszych wersjach system gwarantuje wykonanie aż do metody onStop(), jednak to onPause() pozostaje momentem, w którym aplikacja przestaje być interaktywna, co czyni tę metodę najlepszym miejscem na szybkie zapisanie kluczowych danych, zanim użytkownik całkowicie opuści ekran.
Zachowanie stanu (State Restoration)
Gdy system niszczy aktywność z powodów od niego niezależnych (np. obrót ekranu, zmiana języka systemowego lub wymuszone zwolnienie pamięci), stan zmiennych lokalnych wewnątrz klasy zostaje utracony. Aby zapewnić użytkownikowi ciągłość doświadczenia, Android udostępnia mechanizm zapisu i odczytu stanu przy użyciu obiektu Bundle.
Bundle to zoptymalizowana mapa klucz-wartość, która służy do przesyłania danych między procesami (IPC). Ze względu na ograniczenia systemowe (bufor transakcji Binder ma limit ok. 1MB na cały proces), w Bundle należy przechowywać jedynie lekkie dane, takie jak identyfikatory, tekst wpisany w pola czy stany przełączników.
Proces zachowania stanu opiera się na trzech kluczowych punktach:
- Zapis danych (
onSaveInstanceState): System wywołuje tę metodę, gdy aktywność przechodzi do tła i istnieje ryzyko jej zniszczenia. Otrzymujemy obiektoutState: Bundle, do którego wkładamy dane za pomocą metod typuputInt(),putString()itp. - Odczyt w
onCreate(savedInstanceState: Bundle?): To najczęstsze miejsce przywracania stanu. Jeśli aktywność jest tworzona od zera, parametr ten wynosinull. Jeśli jednak jest odtwarzana po zniszczeniu, zawiera on zapisane wcześniej klucze. - Odczyt w
onRestoreInstanceState(savedInstanceState: Bundle): Metoda ta jest wywoływana poonStart(). Różni się odonCreatetym, że system wywołuje ją tylko wtedy, gdy faktycznie istnieje stan do odtworzenia, więc przekazanyBundlenigdy nie jest nullem. Pozwala to na oddzielenie logiki inicjalizacji od logiki przywracania UI.
Współcześnie, w architekturze polecanej przez Google, większość stanu interfejsu powinna być przechowywana w ViewModel, który przetrwa proste zmiany konfiguracji (jak obrót ekranu). Jednak Bundle (często poprzez SavedStateHandle w ViewModelu) pozostaje niezbędny do obsługi sytuacji, w której system zabija proces aplikacji z powodu braku zasobów.
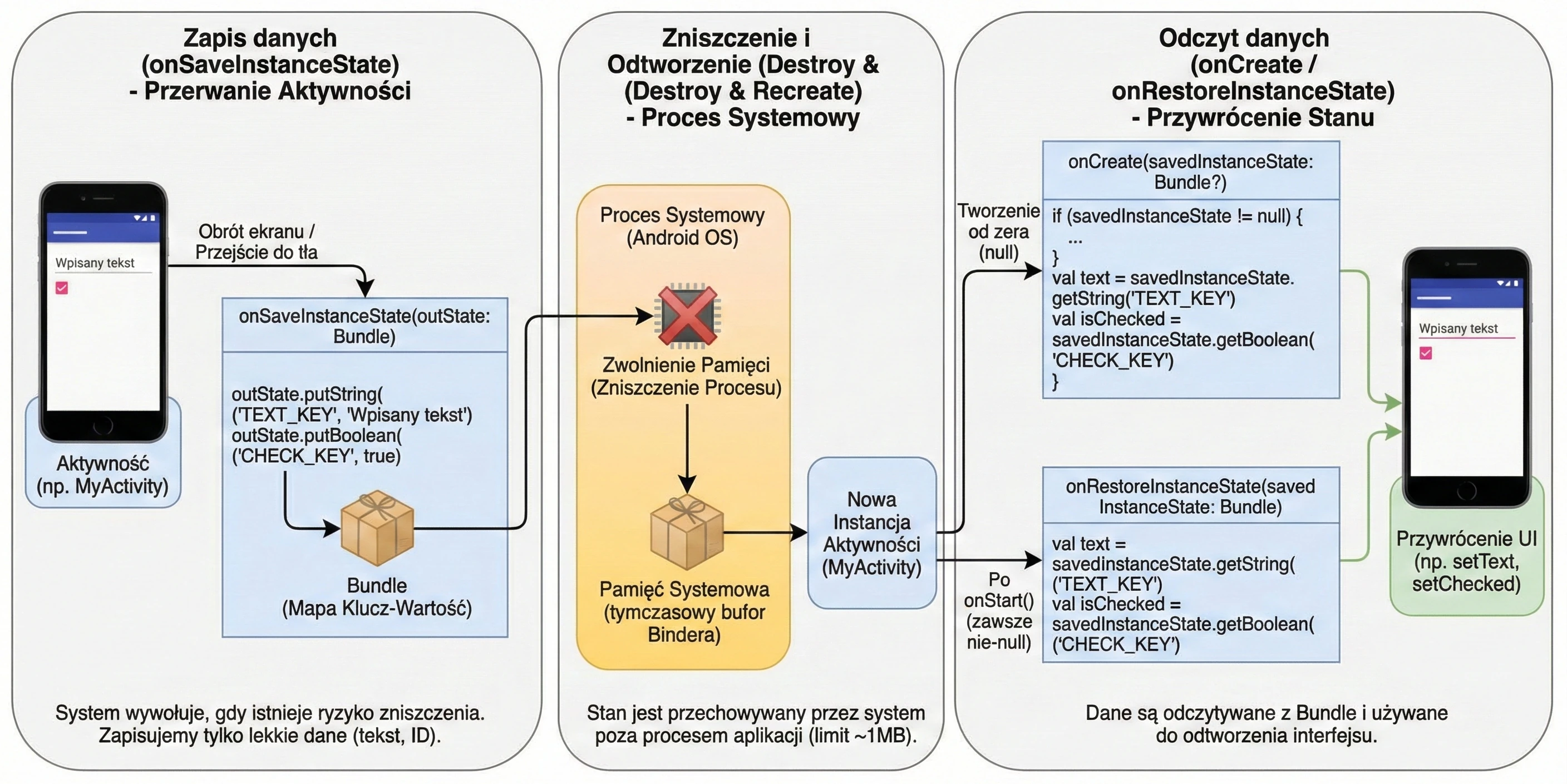
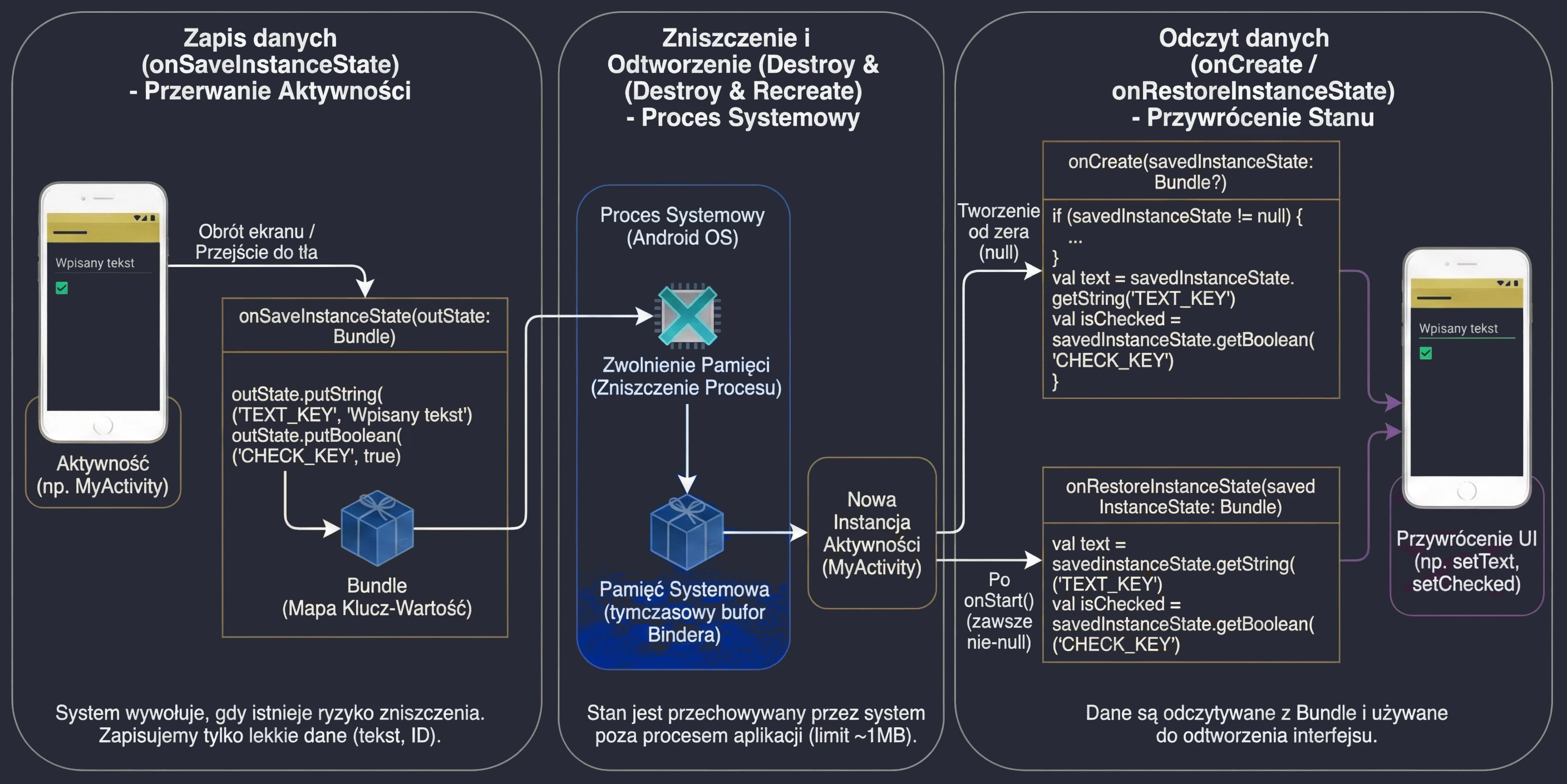
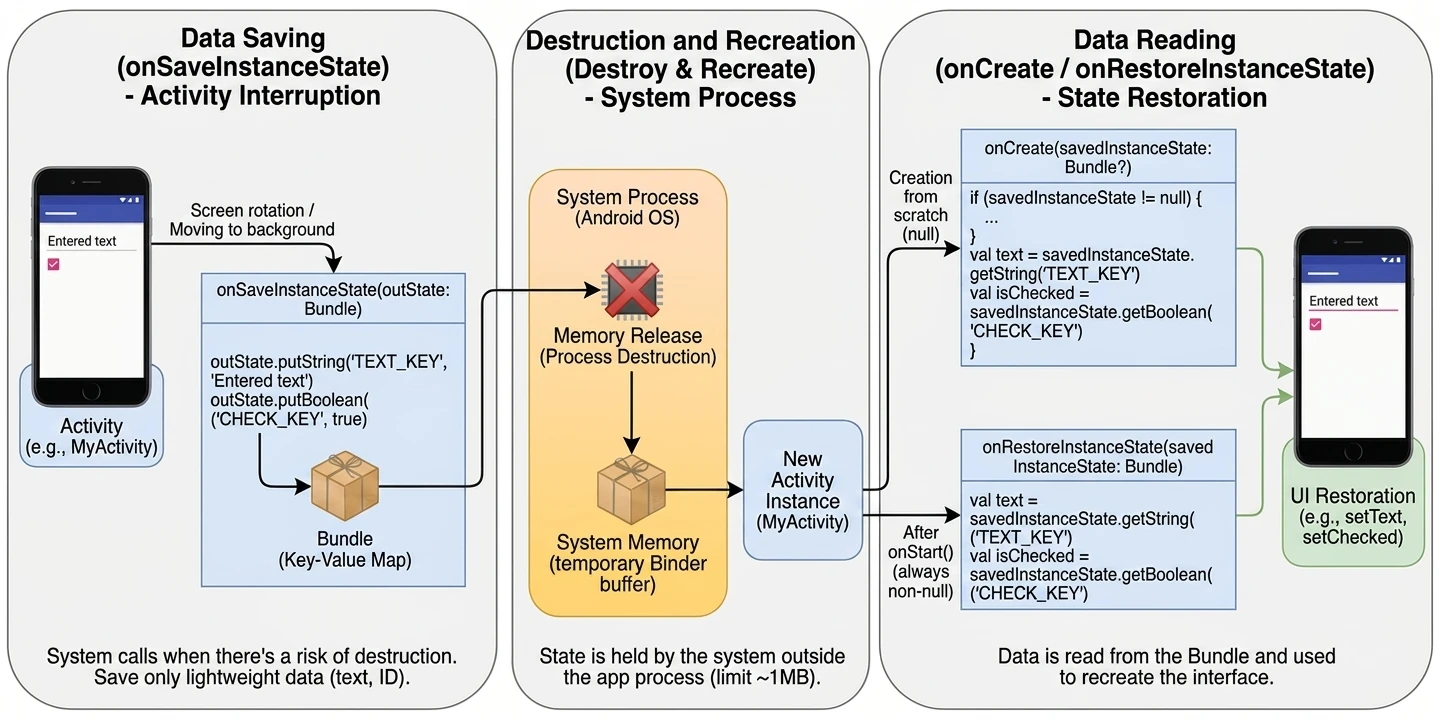
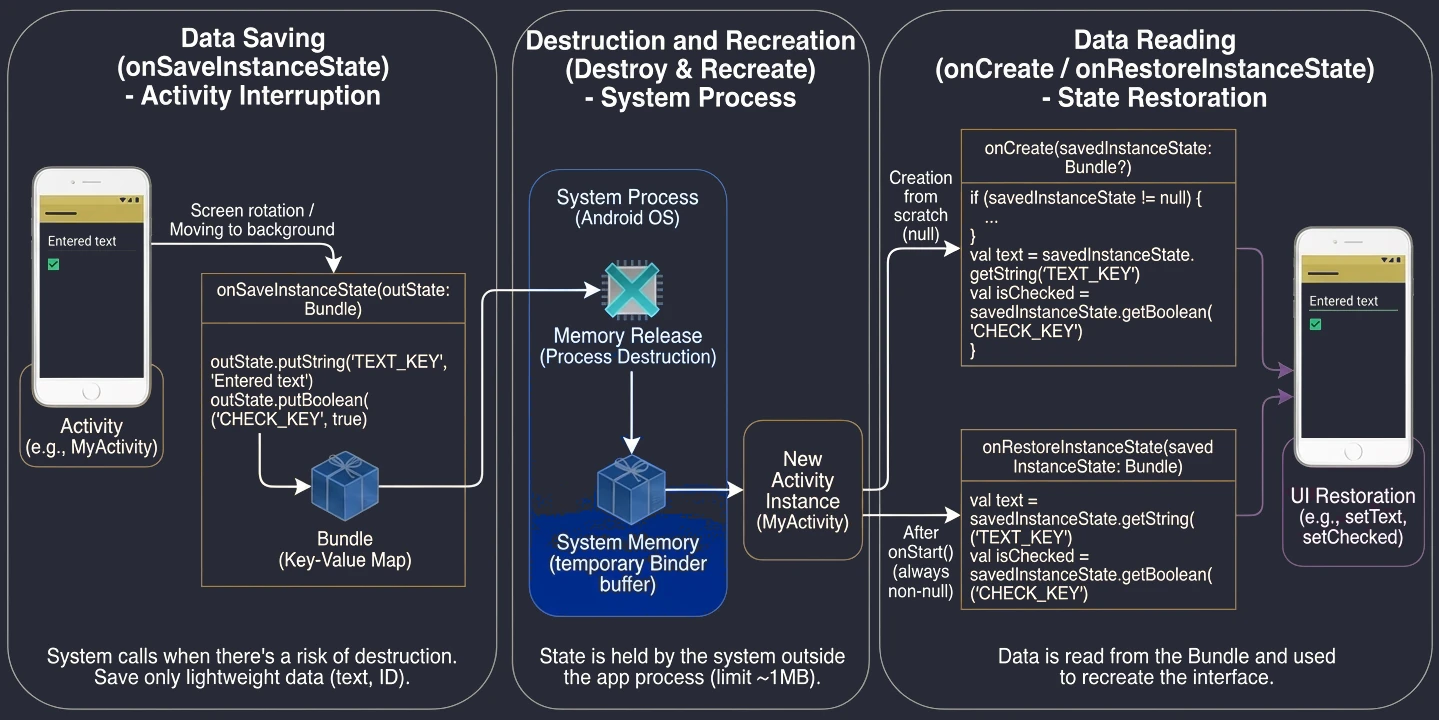
Kontekst (Context)
Context to klasa abstrakcyjna, która jest uchwytem do środowiska, w którym działa aplikacja. Daje dostęp do zasobów systemowych (pliki, bazy danych, preferencje, launchery).
Rodzaje kontekstu:
- Application Context: Żyje tak długo jak cała aplikacja. Jest singletonem. Bezpieczny do użycia w warstwie danych, singletonach czy długotrwałych operacjach w tle. Nie posiada wiedzy o motywach (theme) ani UI.
- Activity Context: Żyje tak długo jak aktywność. Posiada wiedzę o UI i stylach. Używany do tworzenia widoków, wyświetlania dialogów i nawigacji.
Uwaga na wycieki pamięci: Przekazanie Activity Context do obiektu, który żyje dłużej niż aktywność (np. do Singletona), spowoduje, że Garbage Collector nie będzie mógł usunąć zniszczonej aktywności z pamięci.
Warto zadać pytanie: dlaczego w ogóle potrzebujemy obiektu Context, skoro w aplikacjach desktopowych (np. w Javie SE czy C#) dostęp do plików czy zasobów systemowych odbywa się często bezpośrednio przez standardowe biblioteki języka?
Różnica wynika z architektury Androida i faktu, że aplikacje mobilne działają w środowisku o bardzo ograniczonych zasobach:
- Izolacja (Sandboxing): Każda aplikacja działa w swoim własnym procesie z unikalnym identyfikatorem użytkownika (UID). Nie może ona po prostu otworzyć dowolnego pliku na dysku.
Contextjest przepustką, która pozwala systemowi zidentyfikować aplikację i nadać jej uprawnienia do korzystania z zasobów systemowych. - Zarządzanie cyklem życia: W przeciwieństwie do aplikacji desktopowej, która zazwyczaj działa dopóki użytkownik jej nie zamknie, komponenty Androida są stale tworzone i niszczone przez system. Istnienie wielu rodzajów kontekstu pozwala systemowi precyzyjnie określić, jak długo dany zasób powinien być zarezerwowany.
Dlaczego tworząc klasy odpowiedzialne za bazę danych (np. Room) lub warstwę sieciową (np. Retrofit + OkHttp) czasem musimy przekazać Context?
- Baza danych: Musi wiedzieć, gdzie fizycznie utworzyć plik
.db. Ścieżka do chronionego folderu danych aplikacji (/data/data/nazwa.pakietu/databases) jest dostępna wyłącznie poprzez metodęgetDatabasePath(), która należy do kontekstu. - Retrofit/OkHttp: Sam
Retrofitnie wymagaContext.Contextbywa potrzebny na etapie konfiguracji klientaOkHttp(np.cacheDirdla HTTP cache) albo przy dostępie do usług systemowych (np.ConnectivityManager).
W takich przypadkach kluczowe jest przekazanie Application Context. Ponieważ baza danych czy klient sieciowy to zazwyczaj obiekty typu Singleton (żyjące przez cały czas działania programu), trzymanie w nich referencji do Activity Context uniemożliwiłoby systemowi usunięcie zamkniętego ekranu z pamięci, prowadząc do jej wycieku.
Z punktu widzenia programisty, Activity jest pełnoprawnym obiektem typu Context dzięki wielopoziomowemu dziedziczeniu. Hierarchia klas w systemie Android prezentuje się następująco:
- Any (Kotlin) / Object (Java): Korzeń hierarchii klas.
- Context: Klasa abstrakcyjna definiująca kontrakt (interfejs) do usług systemowych.
- ContextWrapper: Implementacja wzorca projektowego Dekorator (Proxy). Zamiast samodzielnie implementować logikę, posiada referencję do innego kontekstu i deleguje do niego wszystkie wywołania.
- Application i Service: Dziedziczą bezpośrednio po
ContextWrapper. - ContextThemeWrapper: Rozszerzenie
ContextWrapper, które dodaje obsługę motywów (Themes) i stylów graficznych. - Activity: Dziedziczy po
ContextThemeWrapper.
Mimo że Activity dziedziczy po Context, sama w sobie nie zawiera kodu odpowiedzialnego za niskopoziomowe operacje systemowe (jak dostęp do systemu plików). Gdy system Android uruchamia proces aplikacji, tworzy obiekt wewnętrznej, ukrytej klasy ContextImpl. Jest to właściwa implementacja, która komunikuje się z jądrem systemu.
Podczas inicjalizacji aktywności, system wywołuje metodę attachBaseContext(contextImpl), wstrzykując ten obiekt do środka. Dzięki temu wywołanie w kodzie openFileInput() wewnątrz aktywności jest de facto przekazywane do obiektu ContextImpl, który wykonuje faktyczną pracę. Ten mechanizm pozwala na zachowanie lekkiej struktury komponentów przy jednoczesnym dostępie do potężnych funkcji systemowych.
Intencje (Intent)
Intent (Intencja) to obiekt-wiadomość, służący do komunikacji między komponentami (nawet z różnych aplikacji). System Android działa tu jak listonosz.
Intencje Jawne (Explicit)
Wskazujemy dokładnie, którą klasę chcemy uruchomić. Używane wewnątrz własnej aplikacji. W aplikacjach opartych na Jetpack Compose, nawigację pomiędzy ekranami realizuje się za pomocą biblioteki Navigation Compose, która wewnętrznie również wykorzystuje intencje jawne. Nie tworzymy już jawnie obiektów Intent, a jedynie wywołujemy funkcje nawigacyjne. Poniżej znajduje się przykład użycia intencji jawnej w tradycyjnym podejściu z użyciem Activity.
val intent = Intent(context, SecondActivity::class.java)
intent.putExtra("USER_ID", 123) // Przekazywanie danych (Bundle) pod maską
context.startActivity(intent)Intencje Niejawne (Implicit)
Deklarujemy co chcemy zrobić (akcję), a system szuka odpowiedniego wykonawcy.
val intent = Intent(Intent.ACTION_VIEW, Uri.parse("https://google.com"))
context.startActivity(intent)Proces dopasowania intencji niejawnej do konkretnego komponentu nazywamy Rozwiązywaniem Intencji (ang. Intent Resolution). System operacyjny (poprzez PackageManager) analizuje wiadomość na podstawie trzech kryteriów:
- Akcja (Action): Nazwa operacji do wykonania (np.
ACTION_VIEW,ACTION_SEND). - Dane (Data): Adres URI danych oraz ich typ MIME (np.
image/jpeg). - Kategoria (Category): Dodatkowe informacje o rodzaju komponentu, który powinien obsłużyć intencję (np.
CATEGORY_BROWSABLE).
Aby aplikacja mogła obsłużyć intencję niejawną, musi zadeklarować <intent-filter> w pliku AndroidManifest.xml. Jest to deklaracja możliwości komponentu.
Kiedy wywołujemy startActivity z intencją niejawną, system wykonuje następujący proces:
- Przeszukiwanie:
PackageManagerskanuje manifesty wszystkich zainstalowanych aplikacji w poszukiwaniu filtrów pasujących do żądania. - Testy dopasowania: Intencja musi przejść trzy testy:
- Test akcji: Akcja w intencji musi znajdować się na liście akcji filtra.
- Test kategorii: Wszystkie kategorie zawarte w intencji muszą być obecne w filtrze (filtr może mieć ich więcej, ale nie mniej).
- Test danych: Schemat URI (np.
https), host oraz typ MIME muszą być zgodne z definicją w tagu<data>. - Reakcja:
- Jeśli pasuje dokładnie jeden komponent, system uruchamia go bezpośrednio.
- Jeśli pasuje wiele komponentów, system wyświetla okno wyboru (Resolver Activity), pozwalając użytkownikowi wybrać preferowaną aplikację.
- Jeśli nie zostanie znaleziona żadna pasująca aktywność, aplikacja rzuca wyjątek
ActivityNotFoundException.
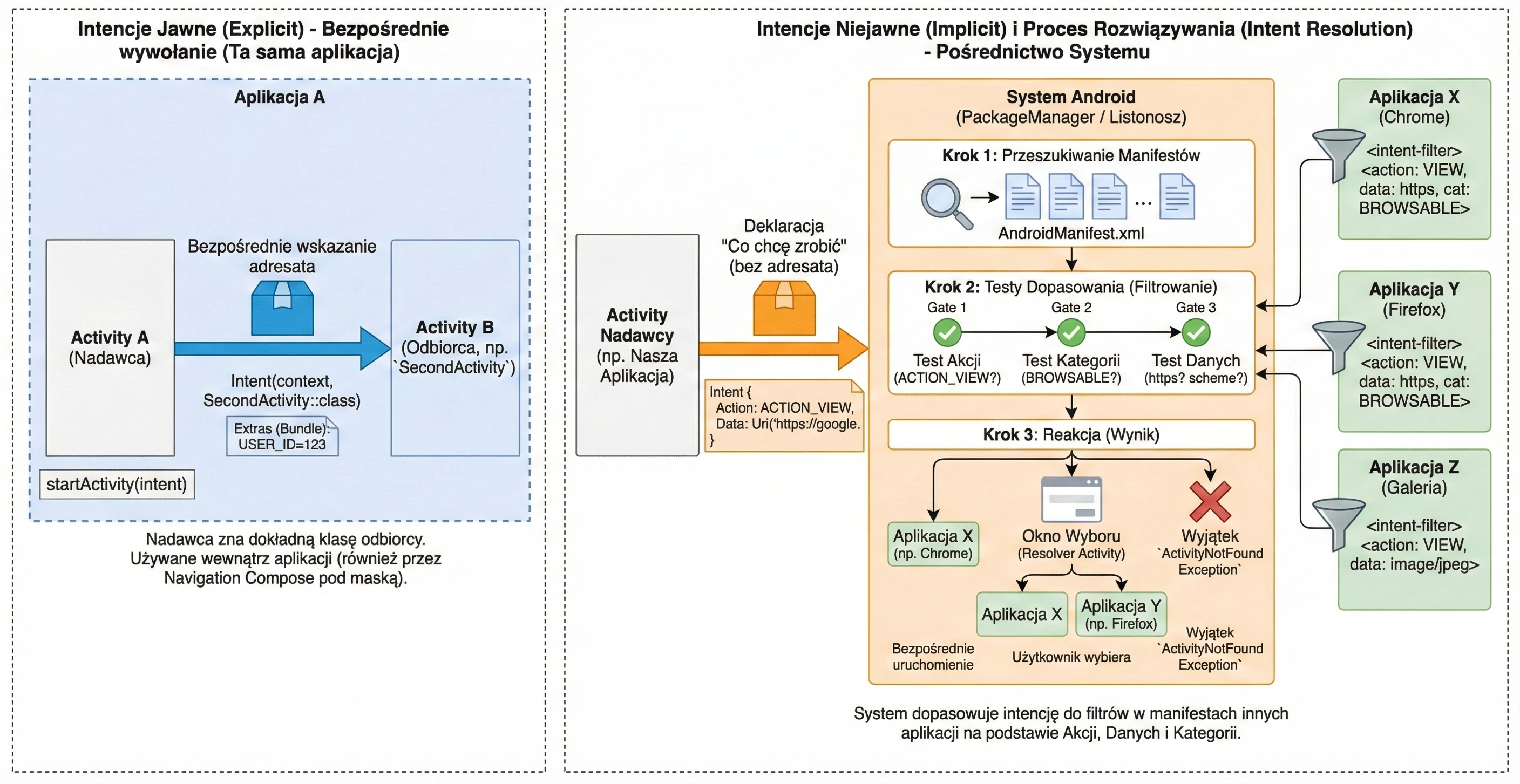
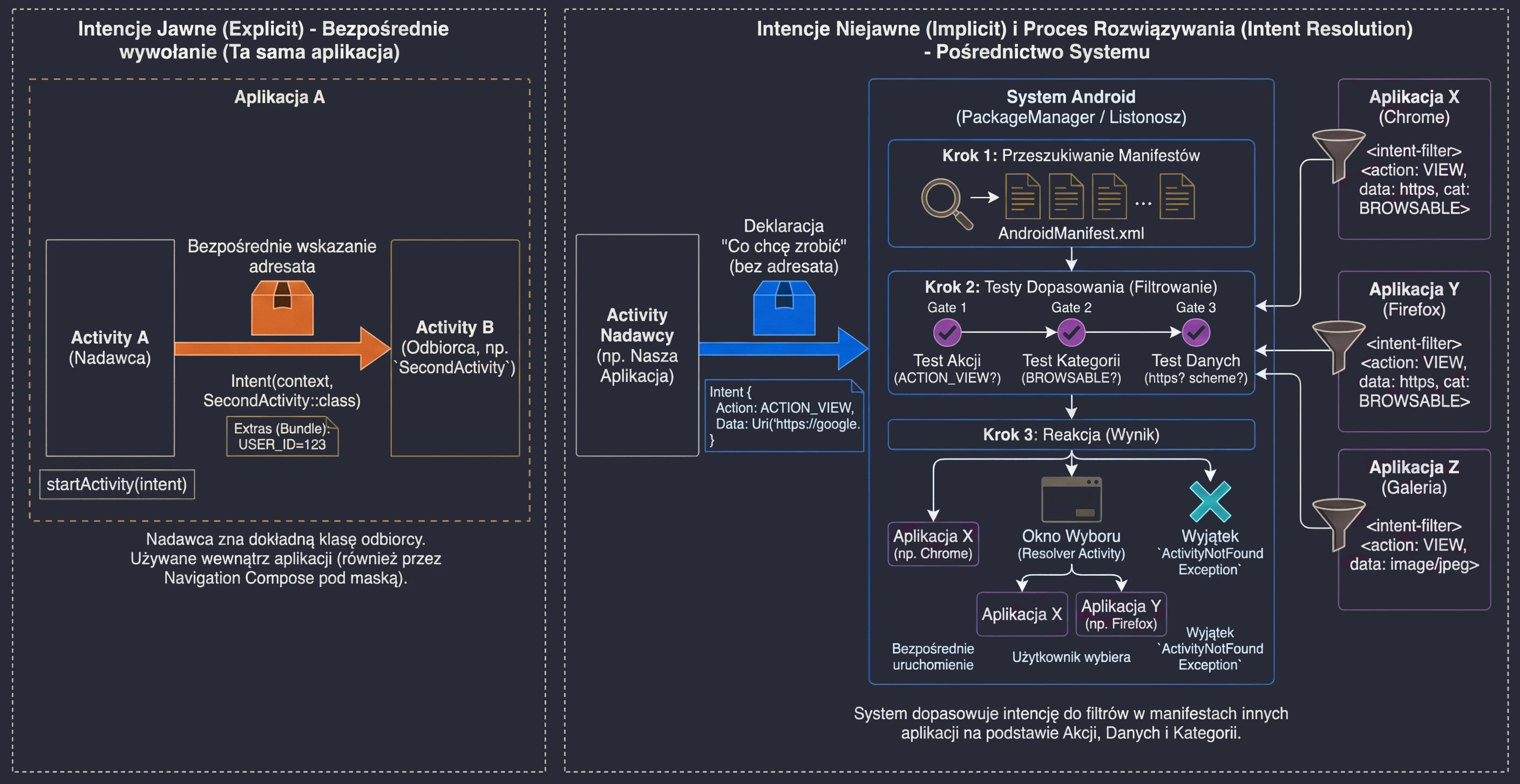
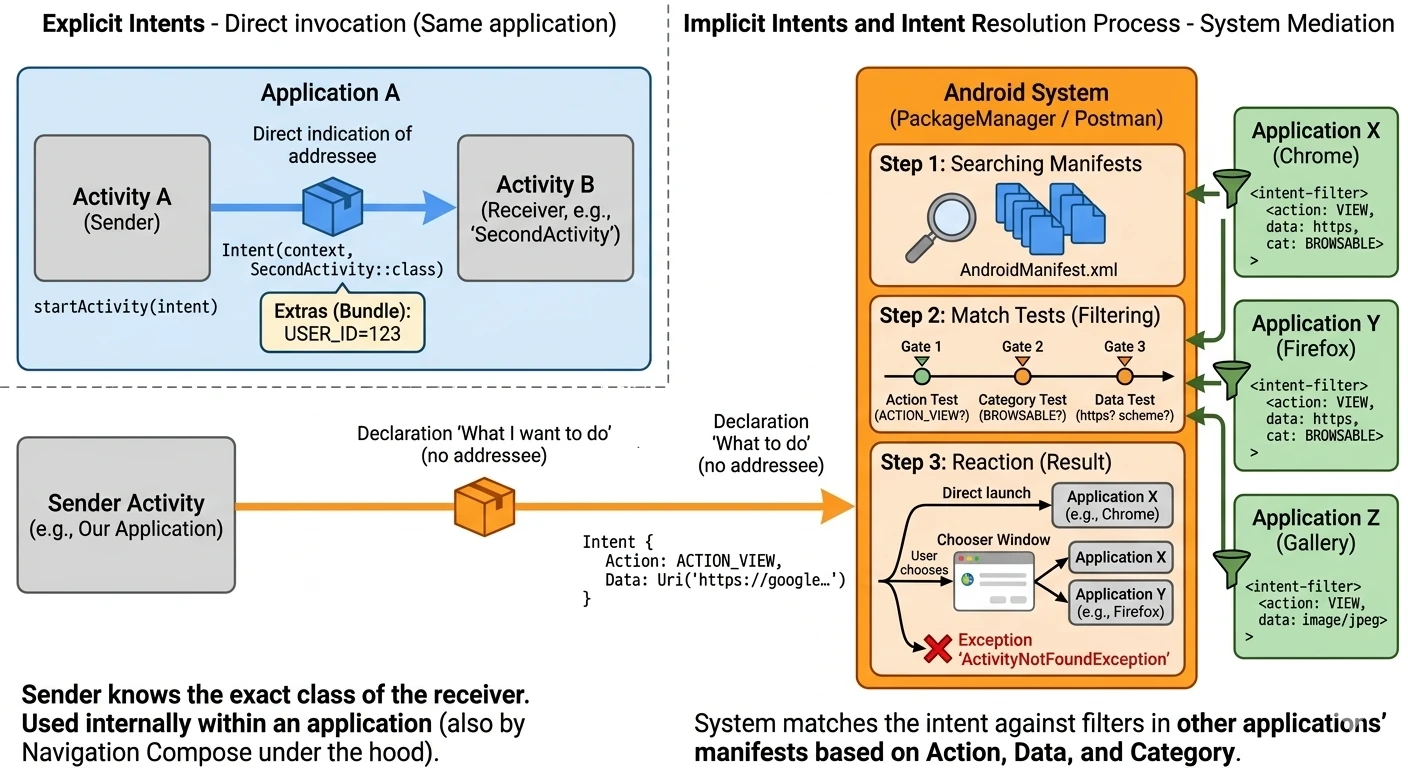
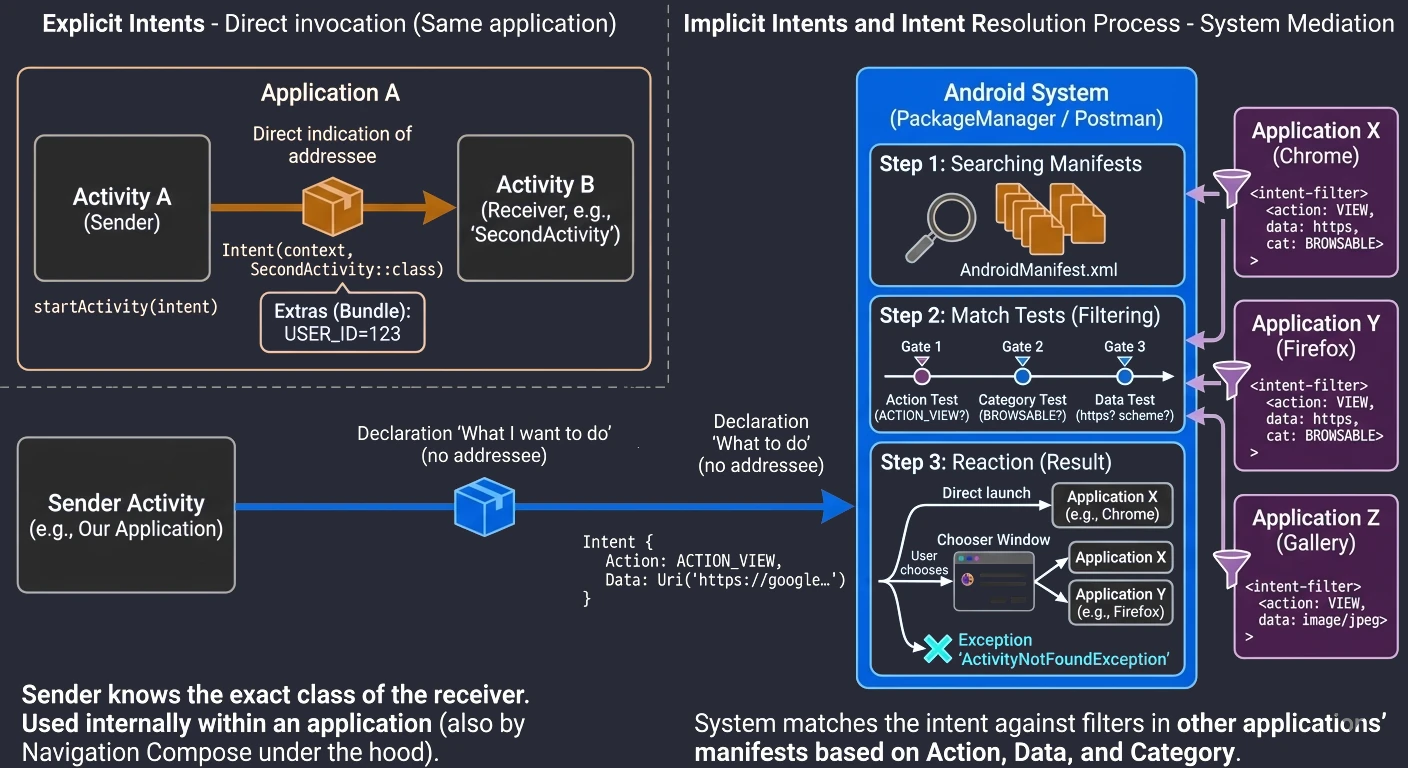
Pełny Przykład Niejawnej Intencji
package com.example.openurlapp
import android.content.ActivityNotFoundException
import android.content.Intent
import android.net.Uri
import android.os.Bundle
import android.widget.Toast
import androidx.activity.ComponentActivity
import androidx.activity.compose.setContent
import androidx.compose.foundation.layout.*
import androidx.compose.material3.*
import androidx.compose.runtime.*
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
// Ważny import dla LocalContext
import androidx.compose.ui.platform.LocalContext
import androidx.compose.ui.unit.dp
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Punkt startowy Jetpack Compose
setContent {
MaterialTheme {
Surface(modifier = Modifier.fillMaxSize()) {
UrlOpenerScreen()
}
}
}
}
}
@Composable
fun UrlOpenerScreen() {
// 1. Pobieramy Context bieżącej aktywności
val context = LocalContext.current
// Stan: tekst wpisany przez użytkownika
var urlText by remember { mutableStateOf("https://developer.android.com") }
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text("Otwieranie URL (Intencja Niejawna)")
Spacer(modifier = Modifier.height(16.dp))
OutlinedTextField(
value = urlText,
onValueChange = { urlText = it },
label = { Text("Wpisz adres URL") },
modifier = Modifier.fillMaxWidth()
)
Spacer(modifier = Modifier.height(16.dp))
Button(onClick = {
try {
// 2. Tworzymy intencję: "Chcę ZOBACZYĆ (View) te DANE (Uri)"
val intent = Intent(Intent.ACTION_VIEW, Uri.parse(urlText))
// 3. Uruchamiamy - system szuka odpowiedniej aplikacji
context.startActivity(intent)
} catch (e: ActivityNotFoundException) {
// 4. Obsługa błędu, gdy brak przeglądarki
Toast.makeText(
context,
"Nie znaleziono aplikacji do otwarcia linku!",
Toast.LENGTH_LONG
).show()
}
}) {
Text("Otwórz w przeglądarce")
}
}
}Powyższy kod demonstruje kompletną mini-aplikację. Omówmy kluczowe elementy specyficzne dla Androida:
setContent\\LocalContext.current\\- Context: Kontekst aplikacji (gdzie wyświetlić).
- Tekst: Treść komunikatu.
- Czas trwania:
LENGTH_SHORTlubLENGTH_LONG.
Jest to most między światem Aktywności a światem Composable. Wszystko, co znajduje się wewnątrz bloku setContent, jest drzewem UI budowanym przez Jetpack Compose.
W Jetpack Compose funkcje UI (@Composable) są niezależne od klasy Activity, w której się znajdują. Nie mamy więc bezpośredniego dostępu do słowa kluczowego this (reprezentującego Aktywność). Aby uzyskać dostęp do Context (potrzebnego np. do uruchamiania intencji), używamy mechanizmu CompositionLocal. LocalContext.current sięga w górę drzewa UI i pobiera Kontekst, który został tam udostępniony przez system. Jest to bezpieczny sposób na zdobycie referencji do środowiska aplikacji wewnątrz dowolnej funkcji Composable.
\item[Toast] To prosty mechanizm wyświetlania krótkich komunikatów, które nie blokują interfejsu (pojawiają się jako dymek na dole ekranu) i znikają automatycznie. Metoda makeText przyjmuje trzy parametry:
Należy pamiętać o wywołaniu .show() na końcu – bez tego Toast się nie pojawi.
Jetpack Compose to deklaratywny toolkit do budowania natywnego interfejsu użytkownika na Androida. Jego premiera (wersja 1.0 w 2021 roku) oznaczała największą rewolucję w tworzeniu UI od początku istnienia systemu.
Aby zrozumieć, dlaczego powstał Compose, musimy cofnąć się do roku 2008. Klasyczny system widoków (View System), oparty na XML, towarzyszył Androidowi od wersji 1.0. Przez ponad dekadę ewoluował, ale dźwigał bagaż wczesnych decyzji projektowych:
- Globalny stan i mutowalność: W klasycznym podejściu programista musiał ręcznie zarządzać stanem widoku. Należało znaleźć widok (
findViewById), a następnie wywołać metodę mutującą jego stan (np.textView.setText()). Prowadziło to często do błędów, gdy stan danych w aplikacji rozjeżdżał się ze stanem wyświetlanym na ekranie. - Dziedziczenie: Klasa
View.javama obecnie ponad 30 000 linii kodu. Wszystkie komponenty dziedziczą po niej ogromną ilość funkcjonalności, której często nie potrzebują (np.Buttondziedziczy poTextView). - Zależność od systemu: Klasyczne widoki są częścią frameworka systemu Android (
android.jar). Naprawienie błędu wCheckBoxwymagało aktualizacji całego systemu operacyjnego u użytkownika.
Jetpack Compose rozwiązuje te problemy, będąc biblioteką niezależną od wersji systemu (tzw. unbundled). Możemy używać nowych funkcji UI nawet na starszych telefonach, po prostu aktualizując wersję biblioteki w projekcie.
Imperatywny vs Deklaratywny Model UI
Różnica między starym a nowym podejściem jest fundamentalna:
- Podejście Imperatywne (XML + View): Skupiamy się na tym, JAK zmienić UI.
// XML
val button = findViewById<Button>(R.id.button)
// Imperatywna zmiana stanu:
button.setOnClickListener {
button.text = "Kliknięto!"
button.setBackgroundColor(Color.RED)
}// Compose
@Composable
fun MyButton(isClicked: Boolean) {
// UI jest funkcją stanu
Button(
colors = if (isClicked) Color.Red else Color.Blue
) {
Text(if (isClicked) "Kliknięto!" else "Kliknij mnie")
}
}W Compose nie zmieniamy tekstu przycisku. My opisujemy interfejs na nowo dla nowych danych, a framework zajmuje się tym, by odświeżyć (zrekomponować) tylko te elementy, które faktycznie uległy zmianie.
Podstawowe Komponenty Layoutu
W Jetpack Compose interfejs budujemy, składając ze sobą funkcje oznaczone adnotacją @Composable. Zamiast znanych z XML LinearLayout czy FrameLayout, używamy ich odpowiedników:
Column układa elementy w pionie (jeden pod drugim). Odpowiednik LinearLayout z orientacją pionową.
@Composable
fun ColumnExample() {
Column {
Text("Element 1 (Góra)")
Text("Element 2 (Środek)")
Text("Element 3 (Dół)")
}
}
Column i RowRow układa elementy w poziomie (jeden obok drugiego). Odpowiednik LinearLayout z orientacją poziomą.
@Composable
fun RowExample() {
Row {
Text("Lewa")
Text("Prawa")
}
}Box układa elementy jeden na drugim (warstwowo). Odpowiednik FrameLayout. Pierwszy element w kodzie ląduje na samym spodzie, a kolejne są rysowane na nim.
@Composable
fun BoxExample() {
Box {
Text("Tło (Pod spodem)")
Text("Napis (Na wierzchu)")
}
}Siłą Compose jest łatwość łączenia tych komponentów. Poniżej przykład prostego layoutu, gdzie elementy zewnętrzne są ułożone w poziomie, a elementy wewnętrzne w pionie.
@Composable
fun UserProfile(name: String) {
Row {
// Tekst po lewej
Text(text = "A")
// Tekst po prawej, ułożony pionowo
Column {
Text("Witaj,")
Text(name)
}
}
}Do wyświetlania tekstu służy komponent Text. Przy określaniu rozmiarów w Androidzie używamy dwóch jednostek:
- dp (density-independent pixels): Używane do wymiarów (marginesy, szerokość, wysokość). Zapewniają ten sam fizyczny rozmiar elementu na ekranach o różnej gęstości pikseli.
- sp (scale-independent pixels): Używane tylko do rozmiaru czcionki. Działają jak
dp, ale dodatkowo uwzględniają ustawienia systemowe użytkownika (np. powiększony tekst dla osób słabowidzących).
Modyfikatory (Modifiers)
Modifier to potężne narzędzie w Compose, które pozwala modyfikować wygląd i zachowanie komponentu (np. dodać tło, margines, obsługę kliknięcia).
Kluczową zasadą jest to, że modyfikatory działają sekwencyjnie (jak łańcuch). Kolejność wywołań ma znaczenie!
// Przykład: Kolejność paddingu i tła
Box(
modifier = Modifier
.background(Color.Red) // 1. Najpierw czerwone tło
.padding(16.dp) // 2. Potem wcięcie (padding) wewnątrz czerwonego tła
.background(Color.Blue) // 3. Niebieskie tło wewnątrz paddingu
) {
Text("Hej!")
}Gdybyśmy zamienili kolejność padding i background, efekt wizualny byłby zupełnie inny.
Najczęstsze modyfikatory:
.fillMaxSize(): Zajmij całą dostępną przestrzeń..padding(): Odstęp wewnętrzny..clickable { }: Reakcja na dotyk.
Układ i Wyrównanie (Alignment vs Arrangement)
Rozmieszczanie elementów w kontenerach Row i Column opiera się na dwóch kluczowych pojęciach: osi głównej (Main Axis) i osi poprzecznej (Cross Axis).
- Arrangement (Rozmieszczenie): Kontroluje układ elementów wzdłuż osi głównej.
- Alignment (Wyrównanie): Kontroluje układ elementów wzdłuż osi poprzecznej.
Oznacza to, że dostępne właściwości zależą od używanego kontenera:
| Kontener | Oś Główna (Arrangement) | Oś Poprzeczna (Alignment) |
|---|---|---|
Column | Pionowa (verticalArrangement) | Pozioma (horizontalAlignment) |
Row | Pozioma (horizontalArrangement) | Pionowa (verticalAlignment) |
Parametr Arrangement pozwala na precyzyjne określenie odstępów między elementami (dziećmi). Najpopularniejsze opcje to:
Arrangement.Start(dla Row) /Top(dla Column): Elementy przyklejone do początku osi.Arrangement.End(dla Row) /Bottom(dla Column): Elementy przyklejone do końca osi.Arrangement.Center: Elementy zgrupowane na środku osi, stykające się ze sobą.Arrangement.SpaceBetween: Pierwszy i ostatni element są przy krawędziach, a pozostała przestrzeń jest równo rozdzielona między nimi.Arrangement.SpaceAround: Podobnie jak SpaceBetween, ale dodaje odstęp również przed pierwszym i po ostatnim elemencie (połowa odstępu wewnętrznego).Arrangement.SpaceEvenly: Wszystkie odstępy (również te skrajne) są identycznej wielkości.


Czasami zamiast odstępów chcemy, aby element zajmował proporcjonalną część dostępnego miejsca. Służy do tego modyfikator weight. Jeśli w Row mamy dwa elementy, oba z .weight(1f), to podzielą one szerokość po równo (50% / 50%). Jeżeli chcemy zmienić proporcje, dostosowujemy wagi elementów.
Row(modifier = Modifier.fillMaxWidth()) {
// Lewy element zajmie 1/3 (1f / (1f+2f))
Box(Modifier.weight(1f).background(Color.Red))
// Prawy element zajmie 2/3 (2f / (1f+2f))
Box(Modifier.weight(2f).background(Color.Blue))
}Poniższy kod centruje element zarówno w pionie, jak i w poziomie. Zauważ, że nazwy parametrów są precyzyjne (verticalArrangement vs horizontalAlignment), co zapobiega pomyłkom.
Column(
modifier = Modifier.fillMaxSize(),
// Oś główna Column = Pionowa -> Arrangement
verticalArrangement = Arrangement.Center,
// Oś poprzeczna Column = Pozioma -> Alignment
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Na samym środku ekranu")
}
Zarządzanie Stanem (State)
Najtrudniejszą zmianą mentalną w Compose jest zrozumienie, czym jest stan i jak wpływa on na UI.
Wyobraź sobie, że interfejs użytkownika (UI) to odbicie w lustrze. Jeśli jesteś niezadowolony z tego, co widzisz w lustrze (np. masz potargane włosy), nie próbujesz naprawiać samego lustra ani malować po jego powierzchni. Aby zmienić odbicie, musisz zmienić obiekt stojący przed lustrem (czyli uczesać włosy).
W tej analogii:
- Lustro to Framework (Compose). Jest ono nienaruszalne.
- Odbicie to Twój Ekran (UI). Jest tylko skutkiem, a nie przyczyną.
- Obiekt przed lustrem to Stan (Dane). To tutaj zachodzą zmiany.
Równanie $UI = f(state)$ oznacza, że interfejs jest tylko i wyłącznie wizualną reprezentacją aktualnych danych. Nie można zmienić tekstu na ekranie bezpośrednio; można jedynie zmienić zmienną (stan), a Compose (lustro) automatycznie zaktualizuje to, co widzi użytkownik.
W tym miejscu wprowadźmy pojęcia kompozycji i rekompozycji.
- Kompozycja (Composition): To proces, w którym Compose wykonuje Twoje funkcje
@Composable, aby zbudować w pamięci opis (drzewo) interfejsu. To definicja UI nakarmiona aktualnymi danymi. Nie jest to jeszcze samo rysowanie pikseli, a raczej tworzenie planu tego, co ma zostać narysowane. - Rekompozycja (Recomposition): To aktualizacja tego opisu. Gdy zmieniają się dane (stan), Compose wykonuje ponownie tylko niezbędne funkcje, aby dostosować drzewo UI do nowej rzeczywistości.
Jeśli zmieni się tylko jedna mała liczba w stanie, Compose nie przerysuje całego ekranu. Uruchomi ponownie (zrekomponuje) tylko te funkcje, które korzystają z tej konkretnej liczby. Reszta pozostanie nienaruszona.
Anatomia Funkcji @Composable
Skoro kompozycja to proces wykonywania funkcji @Composable, musimy zrozumieć, czym one właściwie są. Adnotacja @Composable zmienia typ funkcji w oczach kompilatora.
- Emisja UI, nie zwracanie wartosci: Funkcje te zazwyczaj zwracają
Unit. Ich celem nie jest zwrócenie obiektu widoku, ale wyemitowanie opisu interfejsu do drzewa kompozycji. - Kontekst wywołania: Funkcję
@Composablemożna wywołać tylko z innej funkcji@Composable. Tworzy to hierarchię wywołań, która startuje od metodysetContentw Activity. - Zawartość: Wewnątrz funkcji kompozycyjnej możemy:
- Wywoływać inne funkcje
@Composable(np.Text,Column). - Używać standardowej logiki Kotlina (
if,for,when) do sterowania tym, co zostanie wyemitowane. - Zarządzać stanem (
remember).
// Zwykła funkcja - zwraca String
fun formatName(name: String): String {
return name.uppercase()
}
// Funkcja Composable - emituje UI
@Composable
fun Greeting(name: String) {
// Możemy używać logiki
if (name.isNotEmpty()) {
// I wywoływać inne funkcje Composable
Text("Witaj, ${formatName(name)}")
}
}Przechowywanie Stanu
Funkcje w Kotlinie są z natury bezstanowe – gdy funkcja się kończy, jej zmienne lokalne znikają. Jak więc zachować np. stan licznika między odświeżeniami ekranu?
@Composable
fun Counter() {
// 1. mutableStateOf tworzy obserwowalny stan (startujemy od 0)
// 2. remember sprawia, że ta zmienna "przeżyje" rekompozycję
var count by remember { mutableStateOf(0) }
Button(onClick = { count++ }) { // Zmiana stanu wyzwala rekompozycję
// Podczas rekompozycji, Compose widzi nową wartość count
Text("Kliknięto $count razy")
}
}Tutaj wchodzą dwaj gracze:
mutableStateOf(value): To specjalne pudełko na dane, które jest obserwowalne. Gdy zmienisz zawartość tego pudełka (np.count.value++), Compose dostaje sygnał: "Musisz odświeżyć wszystkich, którzy na to patrzą".remember { ... }: To instrukcja dla kompilatora: Zapisz ten obiekt w pamięci podręcznej obok drzewa UI. Gdy funkcjaCounterzostanie wywołana ponownie (rekompozycja),rememberodda nam zachowaną wcześniej wartość, zamiast tworzyć nową (zresetowaną do zera).
Bez remember, przy każdym kliknięciu funkcja Counter startowałaby od nowa z wartością 0. Bez mutableStateOf, zmiana zmiennej nie dałaby sygnału do odświeżenia ekranu (interfejs byłby martwy).
Mimo że remember działa podczas rekompozycji, ma jedną wadę: zapomina wszystko przy zmianie konfiguracji (np. obrót ekranu, zmiana języka, tryb ciemny). Wtedy cała aktywność jest niszczona i tworzona od nowa, a pamięć podręczna remember jest czyszczona.
Aby zachować stan nawet po śmierci i odrodzeniu się aktywności (lub procesu), używamy rememberSaveable. Pod maską wykorzystuje on mechanizm Bundle (ten sam co w onSaveInstanceState z klasycznego Androida).
@Composable
fun ResilientCounter() {
// rememberSaveable przeżyje obrót ekranu!
var count by rememberSaveable { mutableStateOf(0) }
Button(onClick = { count++ }) {
Text("Kliknięto $count razy")
}
}Dla prostych typów (Int, String, Boolean) działa to automatycznie. Dla własnych obiektów musimy dostarczyć tzw. Saver (np. implementując Parcelable i używając @Parcelize).
Składnia: = vs by
Często spotkamy się z dwoma zapisami stanu:
// 1. Przypisanie (=)
val nameState = remember { mutableStateOf("Jan") }
Text(text = nameState.value) // Musimy pisać .value
// 2. Delegacja (by)
var name by remember { mutableStateOf("Jan") }
Text(text = name) // Używamy jak zwykłej zmiennejSłowo kluczowe by (delegacja właściwości) odpakowuje dla nas stan.
- Przy
by, zmiennanamejest typuString(kompilator ukrywaStatepod spodem). Aby zmienić wartość, piszemyname = "Ewa". - Przy
=, zmiennanameStatejest typuMutableState<String>. Aby zmienić wartość, musimy pisaćnameState.value = "Ewa".
Używanie by wymaga importów (które czasami nie są dodawane automatycznie przez IDE): import androidx.compose.runtime.getValue import androidx.compose.runtime.setValue
Wzorzec State Hoisting
Aby komponenty były wielokrotnego użytku i łatwe w testowaniu, stosujemy wzorzec State Hoisting (wynoszenie stanu w górę). Polega on na tym, że komponent nie zarządza swoim stanem wewnętrznie, ale otrzymuje go od rodzica.
Cechy komponentu Stateless (bezstanowego):
- Otrzymuje stan przez parametr (np.
value: String). - Zgłasza zdarzenia przez lambdę (np.
onValueChange: (String) -> Unit).
// Komponent Stateful (zarządza stanem - trudniejszy do testowania i reużycia)
@Composable
fun HelloScreen() {
var name by remember { mutableStateOf("") }
HelloContent(name = name, onNameChange = { name = it })
}
// Komponent Stateless (czysta funkcja UI)
@Composable
fun HelloContent(name: String, onNameChange: (String) -> Unit) {
Column {
Text("Cześć $name")
TextField(
value = name,
onValueChange = onNameChange
)
}
}Dzięki temu HelloContent jest niezależny od tego, skąd pochodzi stan (może to być remember, ViewModel, czy stała z testu). Wzorzec ten promuje Unidirectional Data Flow (Jednokierunkowy Przepływ Danych):
- Dane płyną w dół (od rodzica do dziecka).
- Zdarzenia płyną w górę (od dziecka do rodzica).
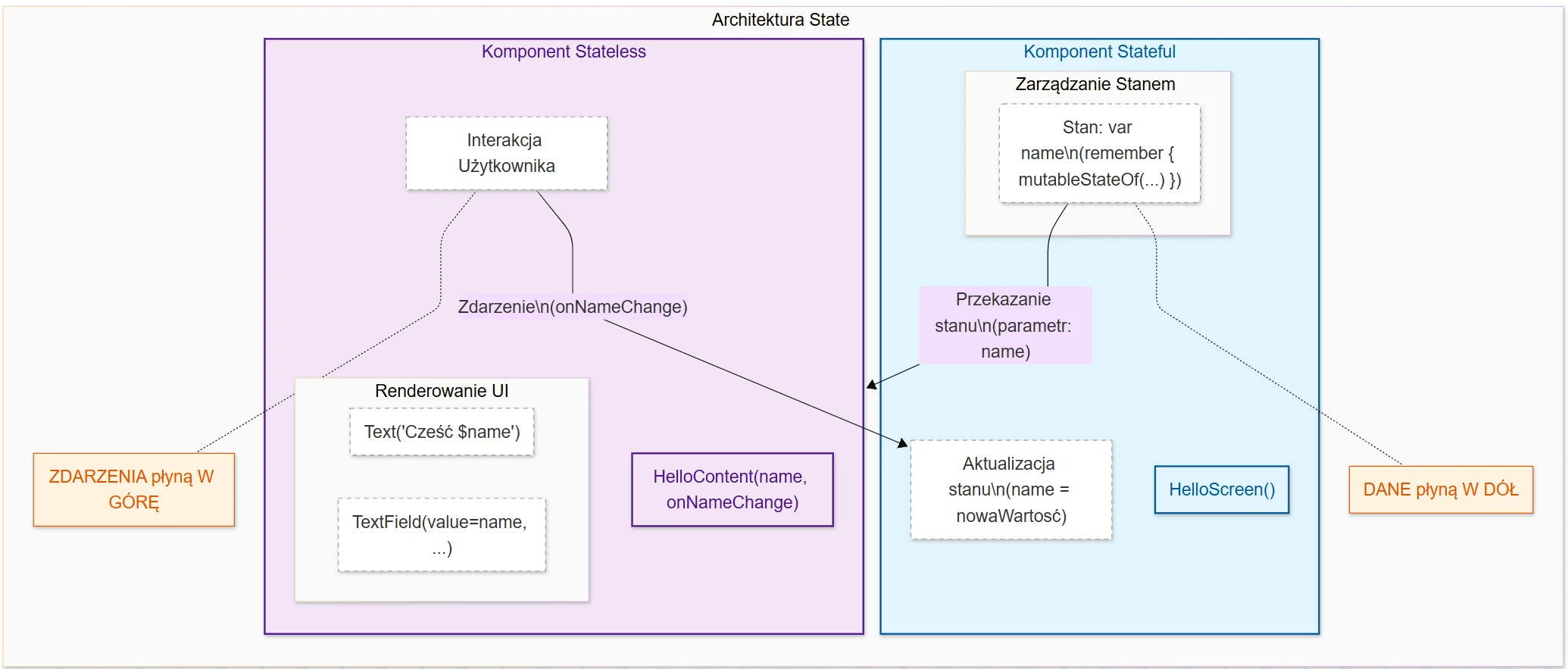
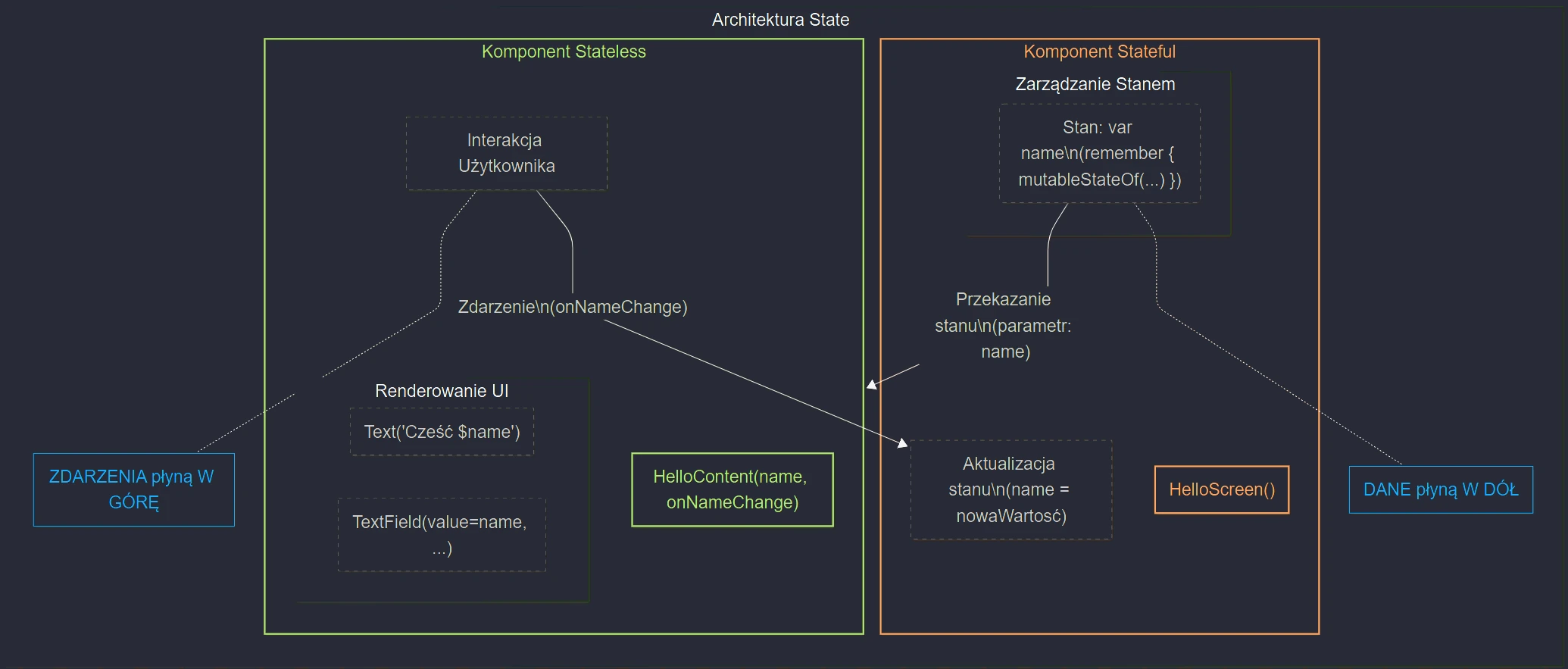
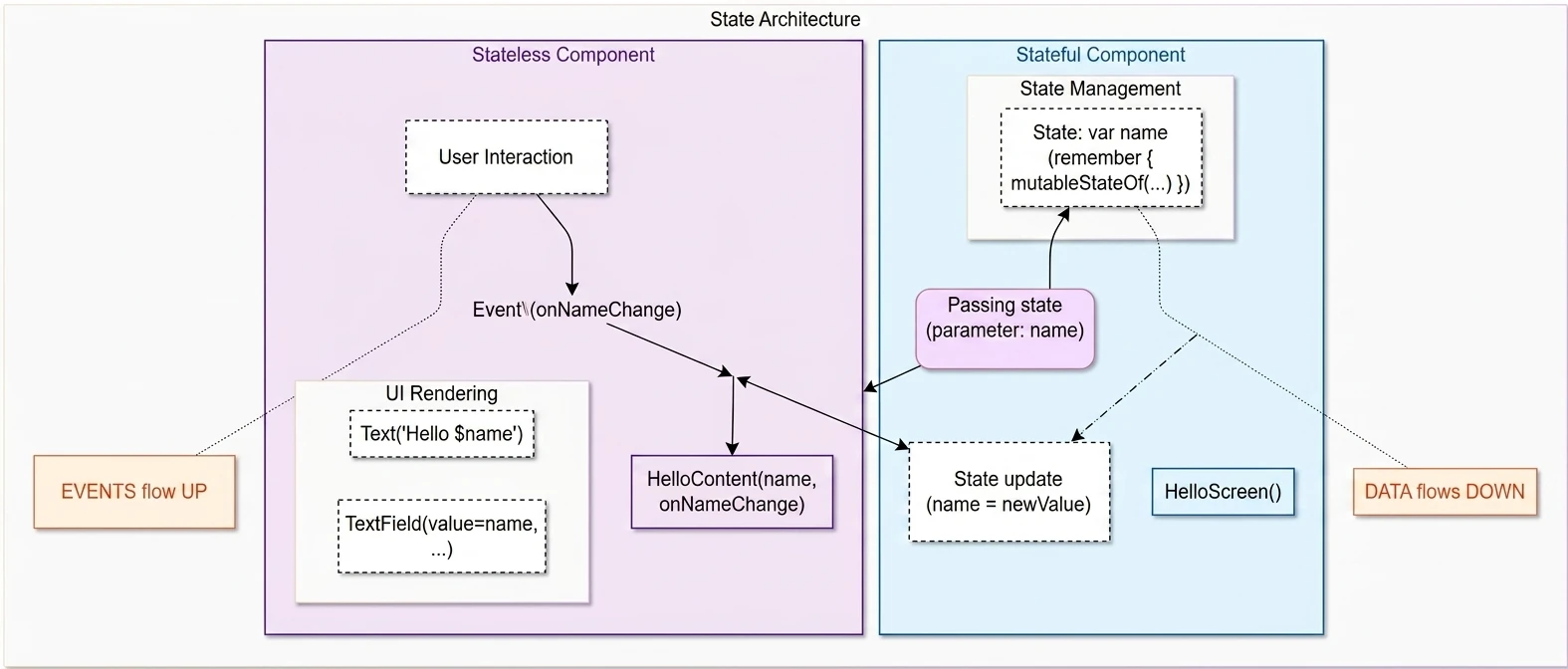
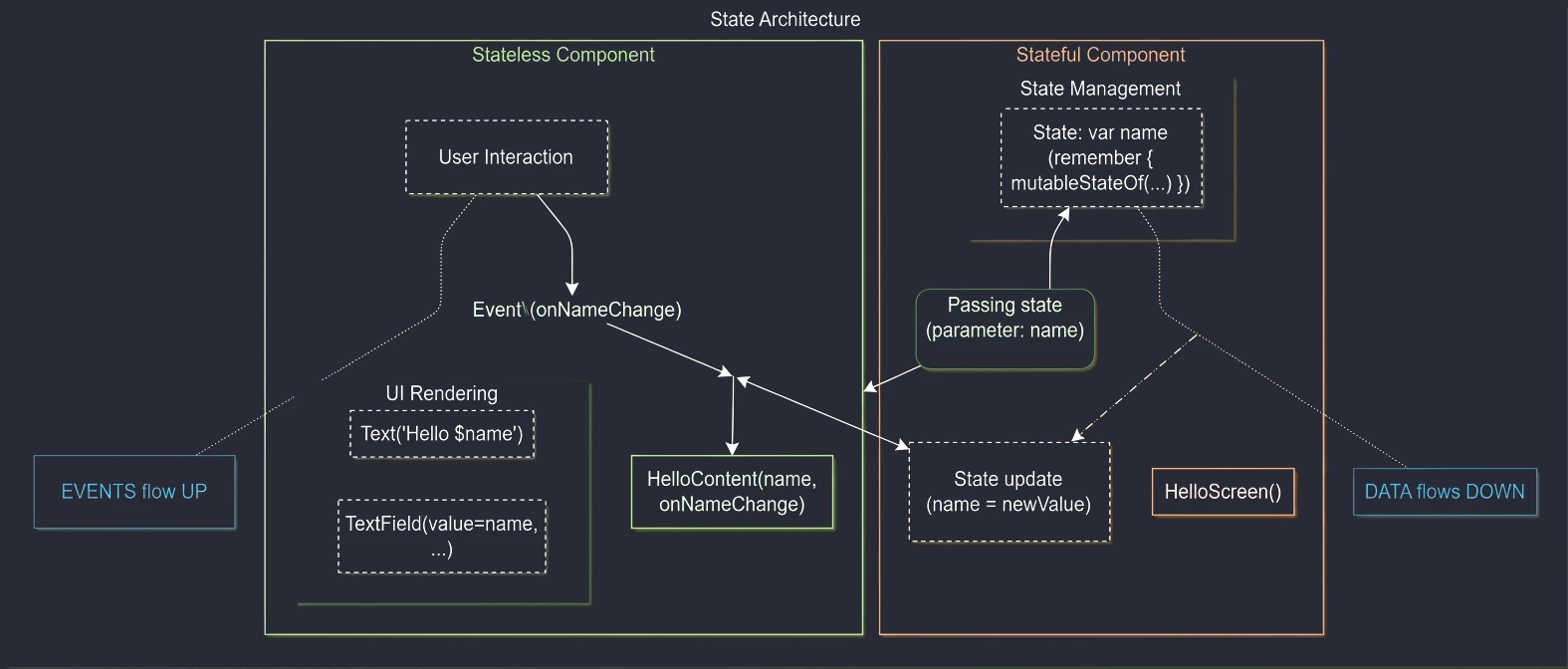
W poprzednim rozdziale poznaliśmy podstawowe bloki budulcowe (Row, Column, Box) oraz mechanizm stanu. Teraz przejdziemy do budowania ekranów aplikacji, zgodnych z wytycznymi Material Design. Omówimy szkielet ekranu (Scaffold) oraz efektywne wyświetlanie długich list danych (LazyColumn).
Scaffold - Szkielet Ekranu
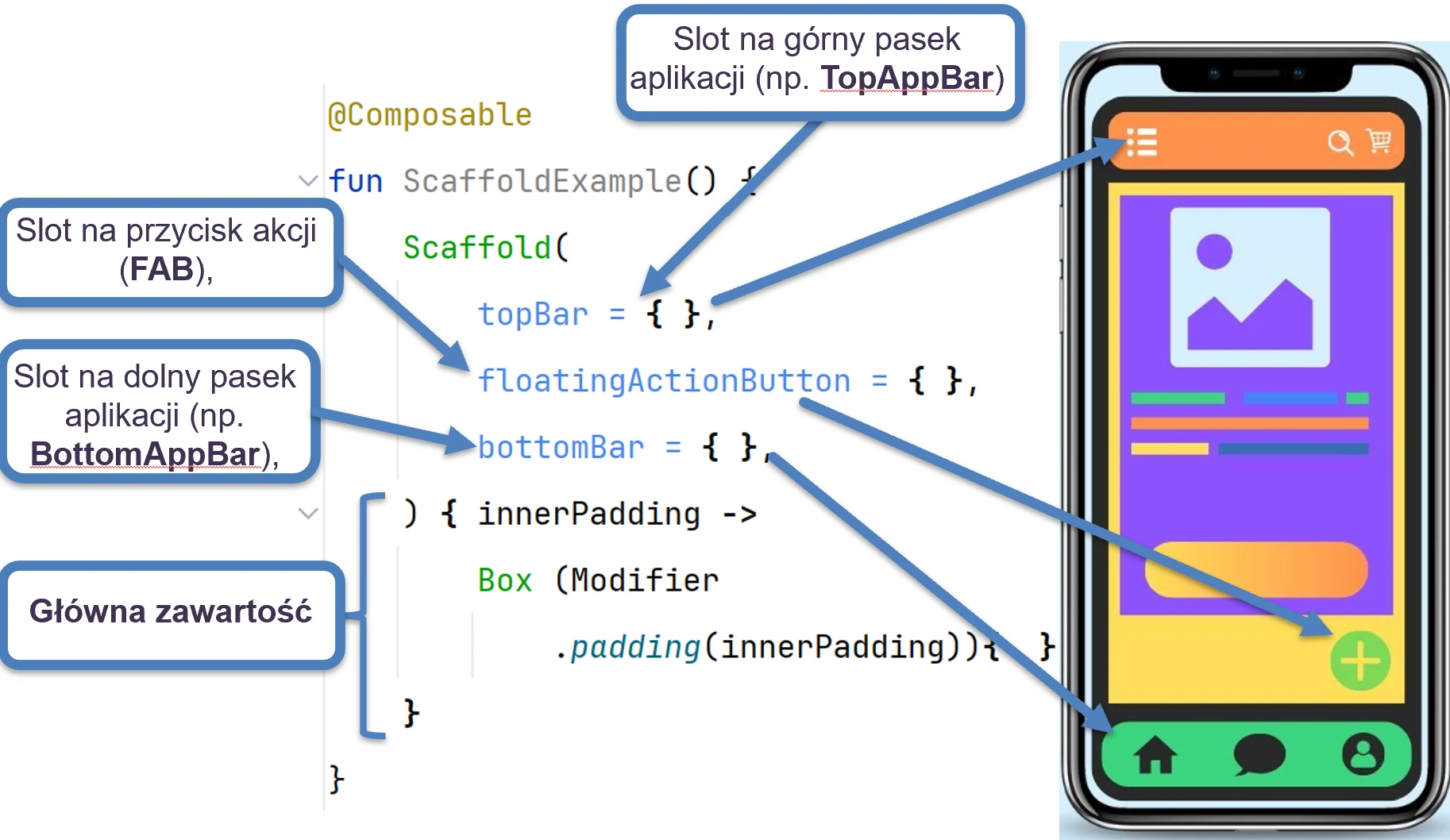
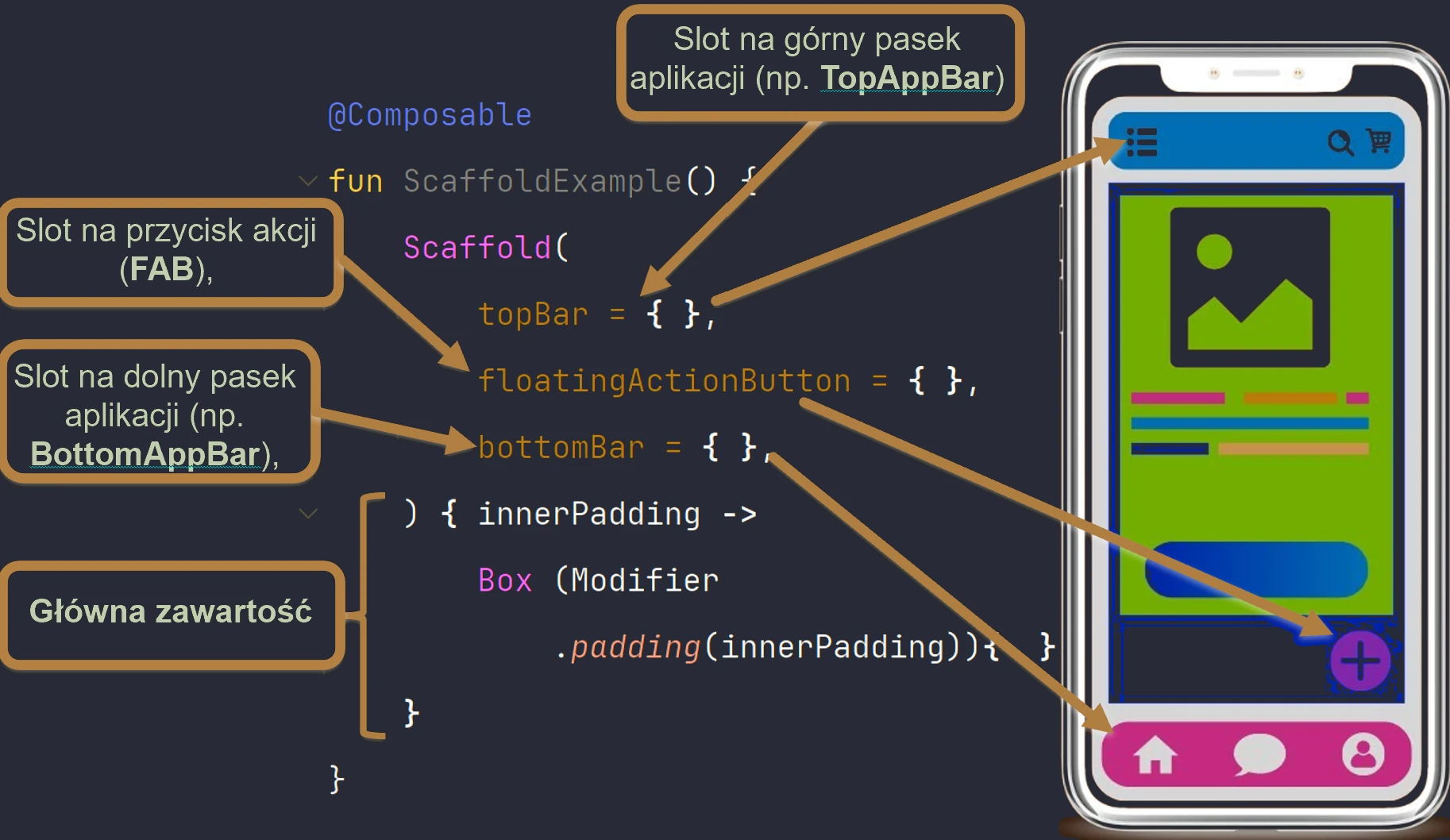
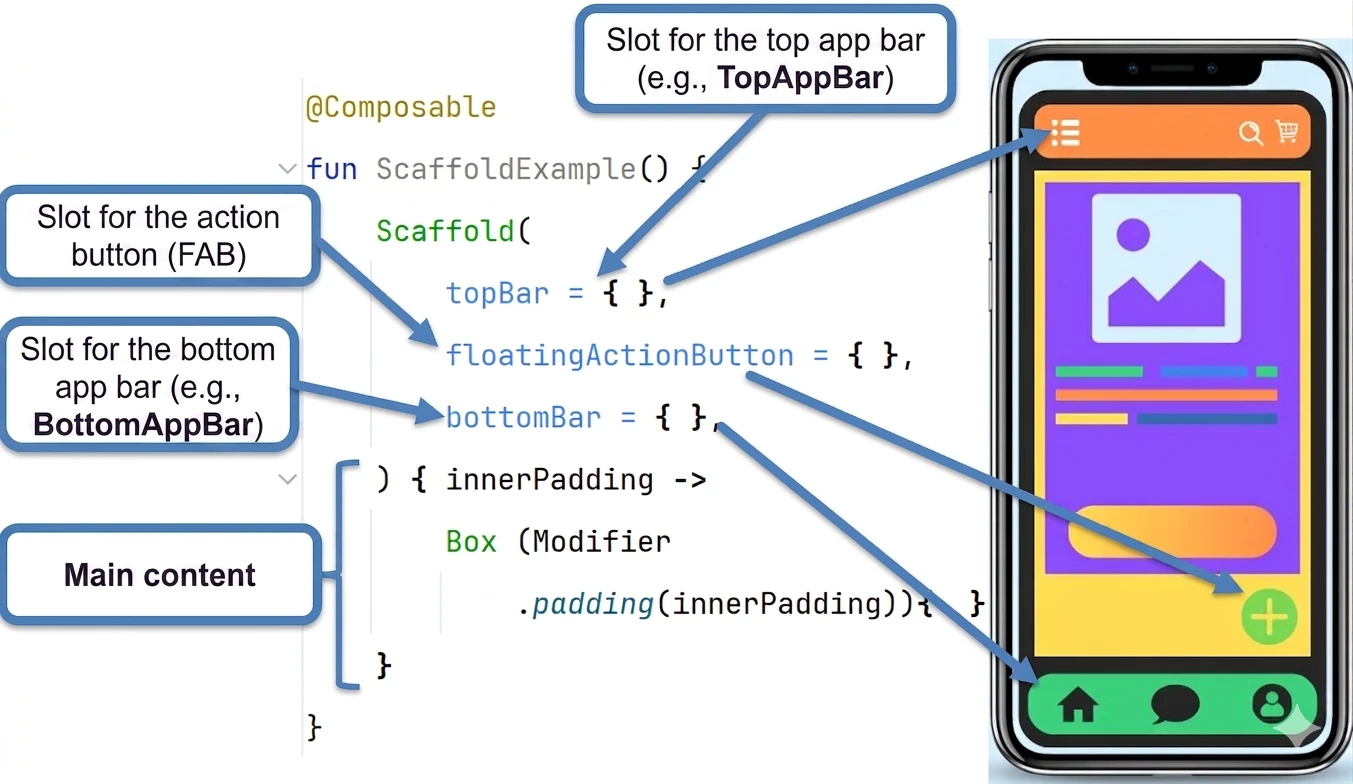
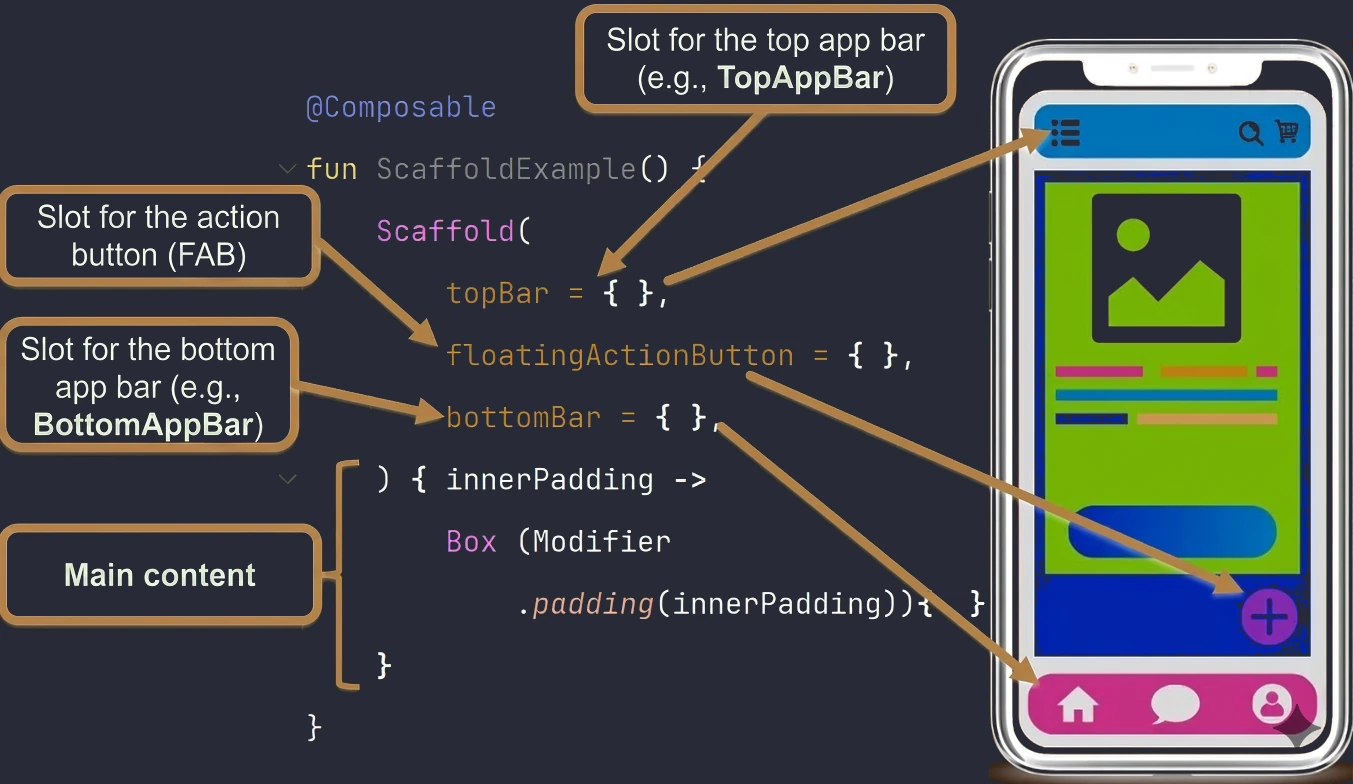
Scaffold (rusztowanie) to gotowy komponent implementujący podstawową strukturę wizualną Material Design. Zapewnia on sloty (miejsca) na standardowe elementy interfejsu, takie jak:
- Górny pasek aplikacji (
TopAppBar) - Dolny pasek nawigacji (
BottomBar) - Pływający przycisk akcji (
FloatingActionButton) - Zawartość główną (Content)
Najważniejszą cechą Scaffold jest to, że automatycznie oblicza on przestrzeń zajmowaną przez paski systemowe i aplikacyjne, przekazując nam odpowiedni PaddingValues do głównej zawartości.
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun MainScreen() {
Scaffold(
topBar = {
TopAppBar(
title = { Text("Moja Aplikacja") }
)
},
floatingActionButton = {
FloatingActionButton(onClick = { /* akcja */ }) {
Icon(Icons.Default.Add, contentDescription = "Dodaj")
}
}
) { innerPadding ->
// WAŻNE: Musimy użyć innerPadding!
Column(
modifier = Modifier
.padding(innerPadding) // Aplikujemy padding od Scaffolda
.fillMaxSize()
.padding(16.dp) // Nasz własny padding
) {
Text("Treść ekranu...")
}
}
}Częstym błędem jest ignorowanie parametru innerPadding w lambdzie zawartości. Jeśli go nie użyjemy, nasza treść wjedzie pod górny pasek aplikacji (TopAppBar), stając się niewidoczną.
TopAppBar - Górny Pasek
W Material Design 3 (Compose 1.1+) komponent TopAppBar jest oznaczony jako eksperymentalny (@OptIn(ExperimentalMaterial3Api::class)). Oferuje on cztery główne wersje:
TopAppBar(mały, standardowy)CenterAlignedTopAppBar(tytuł na środku)MediumTopAppBar(średni, zwijany)LargeTopAppBar(duży, zwijany)
Konfiguracja akcji (przycisków po prawej) i nawigacji (ikona po lewej) jest bardzo prosta:
TopAppBar(
title = { Text("Szczegóły") },
navigationIcon = {
IconButton(onClick = { /* nawigacja wstecz */ }) {
Icon(Icons.Filled.ArrowBack, "Wróć")
}
},
actions = {
IconButton(onClick = { /* udostępnij */ }) {
Icon(Icons.Filled.Share, "Udostępnij")
}
IconButton(onClick = { /* ustawienia */ }) {
Icon(Icons.Filled.Settings, "Ustawienia")
}
}
)Dolny Pasek Nawigacji (BottomBar)
W slocie bottomBar komponentu Scaffold najczęściej umieszczamy NavigationBar (Material 3) lub BottomAppBar. Służą one do nawigacji między głównymi ekranami aplikacji.
NavigationBar {
NavigationBarItem(
icon = { Icon(Icons.Filled.Home, contentDescription = "Home") },
label = { Text("Start") },
selected = true, // Logika zaznaczenia
onClick = { /* nawigacja */ }
)
NavigationBarItem(
icon = { Icon(Icons.Filled.Person, contentDescription = "Profil") },
label = { Text("Profil") },
selected = false,
onClick = { /* nawigacja */ }
)
}Każdy NavigationBarItem reprezentuje jeden cel nawigacji. Stan selected powinien być sterowany przez aktualny stan nawigacji (np. sprawdzając, czy obecna trasa to home).
Listy Leniwe (Lazy Lists)
W Compose do obsługiwania list służą komponenty LazyColumn (pionowa lista) i LazyRow (pozioma lista).
Dlaczego nazywamy je leniwymi?
- Zwykła
Column: Renderuje natychmiast wszystkie elementy, które w niej umieścisz. Jeśli dodasz tam 1000 elementów tekstowych, Compose stworzy 1000 węzłów w pamięci, nawet jeśli użytkownik widzi tylko pierwsze 10. To zabójstwo dla wydajności. LazyColumn: Renderuje tylko te elementy, które są aktualnie widoczne na ekranie. Gdy przewijasz listę, elementy znikające z góry są usuwane, a nowe elementy pojawiające się od dołu są tworzone w locie.
Aby przewijanie było płynne, Compose utrzymuje mały bufor (zazwyczaj po 1-2 elementy) tuż poza widocznym obszarem ekranu. Dzięki temu, gdy użytkownik zaczyna przesuwać palcem, system nie musi tworzyć nowego elementu.
Dzięki tej strategii możemy wyświetlać listy z dziesiątkami tysięcy elementów, zużywając tyle pamięci, ile potrzeba na wyświetlenie np. tylko 10 z nich.
val names = listOf("Anna", "Bob", "Charlie", "David")
LazyColumn {
// 1. Pojedynczy element
item {
Text("Nagłówek listy")
}
// 2. Wiele elementów z kolekcji
items(names) { name ->
Text("Witaj, $name!")
}
// 3. Elementy z indeksem
itemsIndexed(names) { index, name ->
Text("Pozycja $index: $name")
}
}Stan w Kolekcjach (mutableStateListOf)
Standardowa lista w Kotlinie (MutableList) nie jest obserwowalna przez Compose. Jeśli dodasz element do zwykłej listy, UI się nie odświeży.
Aby lista była reaktywna, musimy użyć mutableStateListOf.
@Composable
fun TodoList() {
// ŹLE: Zmiany nie odświeżą UI
// val list = remember { mutableListOf<String>() }
// DOBRZE: Specjalna lista obserwowalna
val list = remember { mutableStateListOf<String>() }
Column {
Button(onClick = { list.add("Zadanie ${list.size + 1}") }) {
Text("Dodaj zadanie")
}
LazyColumn {
items(list) { task ->
Text(task)
}
}
}
}Dzięki mutableStateListOf, każda operacja (add, remove, clear) automatycznie wyzwala rekompozycję tych fragmentów UI, które korzystają z listy.
Wielu programistów myli różne sposoby tworzenia list w Compose.
val list = remember { mutableStateListOf<String>() }\\val list = mutableListOf<String>()\\val list = remember { mutableListOf<String>() }\\val list = remember { mutableStateOf(mutableListOf<String>()) }\\list.value.add("X")-> UI się nie odświeży (referencja się nie zmieniła).list.value = mutableListOf("Y")-> UI się odświeży (zmieniliśmy cały obiekt).
To jest standardowy sposób. Lista jest zapamiętana (przeżywa rekompozycję) i obserwowalna (zmiana w liście odświeża UI).
Brak remember oznacza, że przy każdej rekompozycji lista jest tworzona od nowa (resetowana). Brak State oznacza, że zmiany w liście nie odświeżają UI.
Lista przeżywa rekompozycję (dzięki remember), ale nie jest obserwowalna. Możesz dodawać elementy, ale UI ich nie pokaże, dopóki coś innego nie wymusi odświeżenia ekranu.
Tutaj obserwowalna jest referencja do listy, a nie sama lista.
ListItem - Standardowy element listy
Do budowania powtarzalnych elementów wewnątrz LazyColumn często wykorzystuje się komponent ListItem. Posiada on predefiniowane sloty (analogicznie do pól w formularzu) na treść, co eliminuje potrzebę ręcznego układania elementów w Row.
ListItem(
headlineContent = { Text("Nazwa kontaktu") },
supportingContent = { Text("Ostatnia wiadomość...") },
leadingContent = { Icon(Icons.Default.Person, contentDescription = null) },
trailingContent = { Checkbox(checked = false, onCheckedChange = {}) }
)Główne parametry:
headlineContent– główny tekst (tytuł).supportingContent– mniejszy tekst pomocniczy pod tytułem.leadingContent– element na początku wiersza (np. ikona, avatar).trailingContent– element na końcu wiersza (np. checkbox, data).
ListItemStickyHeader - Nagłówki przypięte
W listach często zachodzi potrzeba pogrupowania elementów (np. kontaktów na literę A, B, C). Funkcja stickyHeader pozwala przypiąć nagłówek sekcji do górnej krawędzi ekranu. Pozostaje on widoczny, dopóki cała sekcja nie zostanie przewinięta poza widok.
@OptIn(ExperimentalFoundationApi::class)
@Composable
fun GroupedList(contacts: Map<Char, List<String>>) {
LazyColumn {
contacts.forEach { (initial, names) ->
stickyHeader {
Text(
text = initial.toString(),
modifier = Modifier
.fillMaxWidth()
.background(Color.LightGray)
.padding(8.dp)
)
}
items(names) { name ->
Text(text = name, modifier = Modifier
.padding(16.dp))
}
}
}
}Zauważmy, że stickyHeader wymaga adnotacji @OptIn(Experimental-Foundation-Api::class), ponieważ jest to funkcja z pakietu fundamentów Compose, która może ulec zmianie w przyszłych wersjach biblioteki.


stickyHeaderLazyVerticalGrid - Siatki
Do wyświetlania elementów w siatce (np. galeria zdjęć) służy LazyVerticalGrid. Wymaga on zdefiniowania układu kolumn:
LazyVerticalGrid(
columns = GridCells.Adaptive(minSize = 120.dp), // Responsywne kolumny
// lub columns = GridCells.Fixed(3) // Sztywne 3 kolumny
) {
items(100) { photoId ->
PhotoItem(photoId)
}
}Zwykła siatka (LazyVerticalGrid) układa elementy w równych wierszach. Jeśli jednak nasze elementy mają różną wysokość (np. notatki w Google Keep lub zdjęcia na Pinterest), powstaną puste przestrzenie.
Rozwiązaniem jest LazyVerticalStaggeredGrid. Układa ona elementy jeden pod drugim w kolumnie, dopasowując je tak, by zminimalizować puste miejsce.
LazyVerticalStaggeredGrid(
columns = StaggeredGridCells.Adaptive(minSize = 150.dp),
verticalItemSpacing = 4.dp,
horizontalArrangement = Arrangement.spacedBy(4.dp)
) {
items(photos) { photo ->
// Zdjęcia mogą mieć różne Ratio (wysokość)
PhotoCard(photo)
}
}


LazyVerticalGrid oraz LazyVerticalStaggeredGridTen komponent jest idealny do wyświetlania treści o zróżnicowanej długości, np. kart produktów z opisami czy galerii zdjęć o różnych proporcjach.
W Jetpack Compose nawigacja jest w pełni deklaratywna i opiera się na bibliotece Navigation Compose. Cała nawigacja odbywa się w ramach jednej Aktywności, gdzie po prostu wymieniamy wyświetlane komponenty @Composable w zależności od aktualnego stanu aplikacji.
Podstawowe Elementy Nawigacji
System nawigacji składa się z trzech głównych komponentów:
- NavController: "System GPS". Centralny obiekt, który zarządza stosem nawigacji (Back Stack). To on wie, gdzie jesteś i jak dotrzeć do celu. Jego używasz, aby wywołać
navigate()lubpopBackStack(). - NavHost: "Ekran nawigacji". Kontener UI, który wyświetla aktualną pozycję (mapę/widok drogi) na podstawie stanu
NavController. - NavGraph: "Mapa całej okolicy". Definiuje wszystkie dostępne ekrany (destynacje) i możliwe połączenia między nimi.
Aby korzystać z Navigation Compose, musimy dodać odpowiednią zależność do pliku build.gradle. Biblioteka ta nie jest częścią standardowego zestawu startowego Compose.
dependencies {
implementation("androidx.navigation:navigation-compose:<numer_wersji>")
}Po zsynchronizowaniu projektu, możemy stworzyć NavController. Robimy to zazwyczaj w głównym komponencie naszej aplikacji (np. wewnątrz Scaffold), używając rememberNavController().
@Composable
fun AppNavigation() {
val navController = rememberNavController()
NavHost(navController = navController, startDestination = "home") {
// Definicja ekranu "home"
composable("home") {
HomeScreen(
onProfileClick = { navController.navigate("profile") }
)
}
// Definicja ekranu "profile"
composable("profile") {
ProfileScreen()
}
}
}Analiza powyższego kodu:
rememberNavController(): Tworzy i zapamiętuje instancjęNavHostController. Obiekt ten przetrwa rekompozycję (dziękiremember) i jest odpowiedzialny za sterowanie nawigacją. Należy przekazać go doNavHost.NavHost: To jest kontener, w którym podmieniane są ekrany. Działa jak ramka na zdjęcia.navController: Łączy ten host z kontrolerem.startDestination: Określa, który ekran ma zostać wyświetlony jako pierwszy po uruchomieniu aplikacji (ekran startowy).composable("route"): Funkcja ta definiuje pojedynczy węzeł w grafie nawigacji.- Łączy unikalny identyfikator trasy (np. "home") z konkretnym widokiem Composable (
HomeScreen). - To tutaj decydujemy, co wyświetlić, gdy użytkownik nawiguje pod dany adres.
W powyższym przykładzie używamy prostych stringów ("home", "profile") jako identyfikatorów tras (Routes). Działa to podobnie do adresów URL w przeglądarce.
Dobrą praktyką jest zdefiniowanie tras jako obiektów, np. za pomocą sealed class.
// Definicja tras
sealed class Screen(val route: String) {
data object Home : Screen("home")
data object Profile : Screen("profile")
data object Settings : Screen("settings")
}
// Użycie w NavHost
NavHost(navController, startDestination = Screen.Home.route) {
composable(Screen.Home.route) { /* ... */ }
composable(Screen.Profile.route) { /* ... */ }
}Przekazywanie Danych (Argumenty)
Ponieważ trasy w Compose Navigation wzorowane są na adresach URL, argumenty przekazujemy w ścieżce.
Jeśli argument jest niezbędny (np. ID użytkownika w profilu), dodajemy go do ścieżki: "profile/{userId}".
// 1. Definicja trasy z parametrem
composable(
route = "profile/{userId}",
arguments = listOf(navArgument("userId") { type = NavType.StringType })
) { backStackEntry ->
// 2. Odczytanie argumentu
val userId = backStackEntry.arguments?.getString("userId")
UserProfile(id = userId)
}
// 3. Wywołanie nawigacji
navController.navigate("profile/123")Kluczowe elementy:
arguments: Lista oczekiwanych parametrów. Navigation Compose musi wiedzieć, że{userId}to coś więcej niż fragment tekstu – że jest to zmienna.navArgument: Konfiguracja pojedynczego parametru. Określamy tu typ (np.-NavType.-StringType,IntType) oraz ewentualnie wartość domyślną (defaultValue) lub czy może być nullem (nullable).backStackEntry: To obiekt reprezentujący wpis na stosie nawigacji. Przechowuje stan ekranu, w tym Sparsowane argumenty. To z niego wyciągamy przekazaną wartość (podobnie jakIntent.extrasw starym systemie).UserProfile: To zwykła funkcja@Composable, która przyjmujeidjako parametr. Zauważ, że nie wie ona nic o nawigacji. Nie wie, skąd przyszłoid– czy z URL-a, czy ze stałej. To dobra praktyka: uniezależnia widok od mechanizmu nawigacji (Decoupling).
Jeśli argument jest opcjonalny, używamy składni znanej z zapytań HTTP: "search?-query-={text}".
composable(
route = "search?query={text}",
arguments = listOf(
navArgument("text") {
defaultValue = ""
nullable = true
}
)
) { /* ... */ }Pełny Przykład
@Composable
fun ArgumentNavigationDemo() {
val navController = rememberNavController()
NavHost(navController = navController, startDestination = "list") {
// Ekran 1: Lista Elementów
composable("list") {
Column(
modifier = Modifier.fillMaxSize(),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = "Wybierz element:",
)
Spacer(modifier = Modifier.height(16.dp))
Button(onClick = { navController.navigate("details/1") }) {
Text("Pokaż szczegóły elementu #1")
}
Spacer(modifier = Modifier.height(8.dp))
Button(onClick = { navController.navigate("details/42") }) {
Text("Pokaż szczegóły elementu #42")
}
}
}
// Ekran 2: Szczegóły (odbiera ID)
composable(
route = "details/{itemId}",
arguments = listOf(navArgument("itemId") { type = NavType.IntType })
) { backStackEntry ->
val id = backStackEntry.arguments?.getInt("itemId")
Column(
modifier = Modifier.fillMaxSize(),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = "Otrzymane ID: $id",
)
Spacer(modifier = Modifier.height(16.dp))
Button(onClick = { navController.popBackStack() }) {
Text("Wróć na listę")
}
}
}
}
}Nawigacja z Dolnym Paskiem (Scaffold + BottomBar)
Integracja nawigacji z BottomBar wymaga połączenia stanu NavController z widokiem paska. Musimy wiedzieć, na którym ekranie jesteśmy, aby podświetlić odpowiednią ikonę.
val navController = rememberNavController()
// Obserwujemy aktualną trasę (state)
val navBackStackEntry by navController.currentBackStackEntryAsState()
val currentRoute = navBackStackEntry?.destination?.route
Scaffold(
bottomBar = {
NavigationBar {
NavigationBarItem(
selected = currentRoute == Screen.Home.route,
onClick = {
navController.navigate(Screen.Home.route) {
// Ważne flagi dla dolnej nawigacji:
// 1. Unikaj tworzenia wielu kopii tego samego ekranu na stosie
popUpTo(navController.graph.startDestinationId) {
saveState = true
}
// 2. Przywróć stan ekranu (np. scroll) przy powrocie
restoreState = true
// 3. Nie twórz nowej instancji, jeśli już tam jesteśmy
launchSingleTop = true
}
},
icon = { Icon(Icons.Default.Home, contentDescription = null) },
label = { Text("Start") }
)
}
}
) { innerPadding ->
NavHost(
navController = navController,
startDestination = Screen.Home.route,
modifier = Modifier.padding(innerPadding)
) {
composable(Screen.Home.route) { HomeScreen() }
// ... inne ekrany
}
}
Flagi popUpTo, saveState, restoreState i launchSingleTop są istotne dla poprawnego działania dolnej nawigacji ("Bottom Navigation Patterns"), zapewniając intuicyjne zachowanie przycisku Wstecz i zachowanie stanu formularzy/list przy przełączaniu zakładek.
W inżynierii oprogramowania często napotykamy powtarzające się problemy. Zamiast wymyślać koło na nowo, korzystamy ze sprawdzonych rozwiązań zwanych wzorcami projektowymi (ang. design patterns). Są to uniwersalne, abstrakcyjne recepty na rozwiązanie konkretnych problemów architektonicznych. Wzorce dzielimy zazwyczaj na trzy grupy:
- Kreacyjne: Dotyczą mechanizmów tworzenia obiektów (np. Singleton, Builder, Factory).
- Strukturalne: Dotyczą składania obiektów i klas w większe struktury (np. Adapter, Decorator).
- Behawioralne: Dotyczą komunikacji i podziału odpowiedzialności między obiektami (np. Observer, Strategy).
W tym rozdziale omówimy wybrane wzorce, które są szczególnie istotne w ekosystemie Kotlin i Android.
Singleton
Singleton to wzorzec kreacyjny, który gwarantuje, że dana klasa będzie miała tylko jedną instancję w całym systemie i zapewnia do niej globalny punkt dostępu.
W Kotlinie tworzenie Singletona jest niezwykle proste dzięki słowu kluczowemu object. Kompilator automatycznie generuje kod, który zapewnia, że powstanie tylko jedna instancja tej klasy, w sposób bezpieczny dla wątków (thread-safe).
// Najprostszy Singleton w Kotlinie
object DatabaseConnection {
val url = "jdbc:mysql://localhost:8801/db"
fun connect() {
println("Connecting to $url")
}
}
// Użycie
DatabaseConnection.connect()Cechy object:
- Leniwa inicjalizacja (Lazy Initialization): Obiekt jest tworzony dopiero przy pierwszym odwołaniu się do niego (np.
DatabaseConnection.connect()). - Bezpieczeństwo wątkowe: Kotlin (działając na JVM) gwarantuje, że inicjalizacja statyczna jest bezpieczna. Nie musimy martwić się wyścigami wątków.
- Brak publicznego konstruktora: Nie ma możliwości utworzenia drugiej instancji ręcznie.
Czasami potrzebujemy większej kontroli nad tworzeniem instancji, np. gdy inicjalizacja wymaga parametrów dostarczanych w trakcie działania aplikacji lub gdy chcemy opóźnić tworzenie ciężkiego obiektu.
Jeśli inicjalizacja Singletona wymaga argumentów (np. Context w Androidzie), słowo object nie wystarczy, bo nie przyjmuje ono parametrów konstrukcyjnych. W takim przypadku używamy companion object wewnątrz zwykłej klasy oraz delegacji by lazy.
class NetworkClient private constructor(val baseUrl: String) {
companion object {
// Leniwa inicjalizacja - kod w bloku wykona się tylko raz,
// przy pierwszym użyciu pola 'instance'.
// Domyślnie jest to bezpieczne wątkowo (thread-safe).
val instance: NetworkClient by lazy {
NetworkClient("https://api.example.com")
}
}
}W przypadkach, gdy by lazy nie wystarcza (np. chcemy resetować Singletona lub mamy bardzo nietypową logikę inicjalizacji), stosujemy wzorzec Double-Checked Locking. Sprawdza on istnienie instancji dwa razy: raz bez blokady (dla szybkości), a drugi raz wewnątrz bloku synchronizowanego (dla bezpieczeństwa).
Oto przykład implementacji dla klienta biblioteki Retrofit (służącej do komunikacji z API):
class RetrofitClient private constructor() {
companion object {
// @Volatile zapewnia, że zmiana wartości jest natychmiast widoczna
// dla wszystkich wątków (omija cache procesora)
@Volatile
private var instance: Retrofit? = null
fun getInstance(): Retrofit {
// Pierwsze sprawdzenie (bez blokady - szybkie)
val currentInstance = instance
if (currentInstance != null) {
return currentInstance
}
// Blokada (synchronized) - wpuszcza tylko jeden wątek na raz
synchronized(this) {
// Drugie sprawdzenie (wewnątrz blokady)
val i2 = instance
if (i2 != null) {
return i2
} else {
// Tworzenie instancji
val created = Retrofit.Builder()
.baseUrl("https://api.example.com")
.build()
instance = created
return created
}
}
}
}
}Choć w Kotlinie zazwyczaj wystarcza nam object lub delegacja by lazy (która pod spodem również używa mechanizmów synchronizacji), zrozumienie Double-Checked Locking jest ważne dla świadomości, jak działają te mechanizmy pod maską.
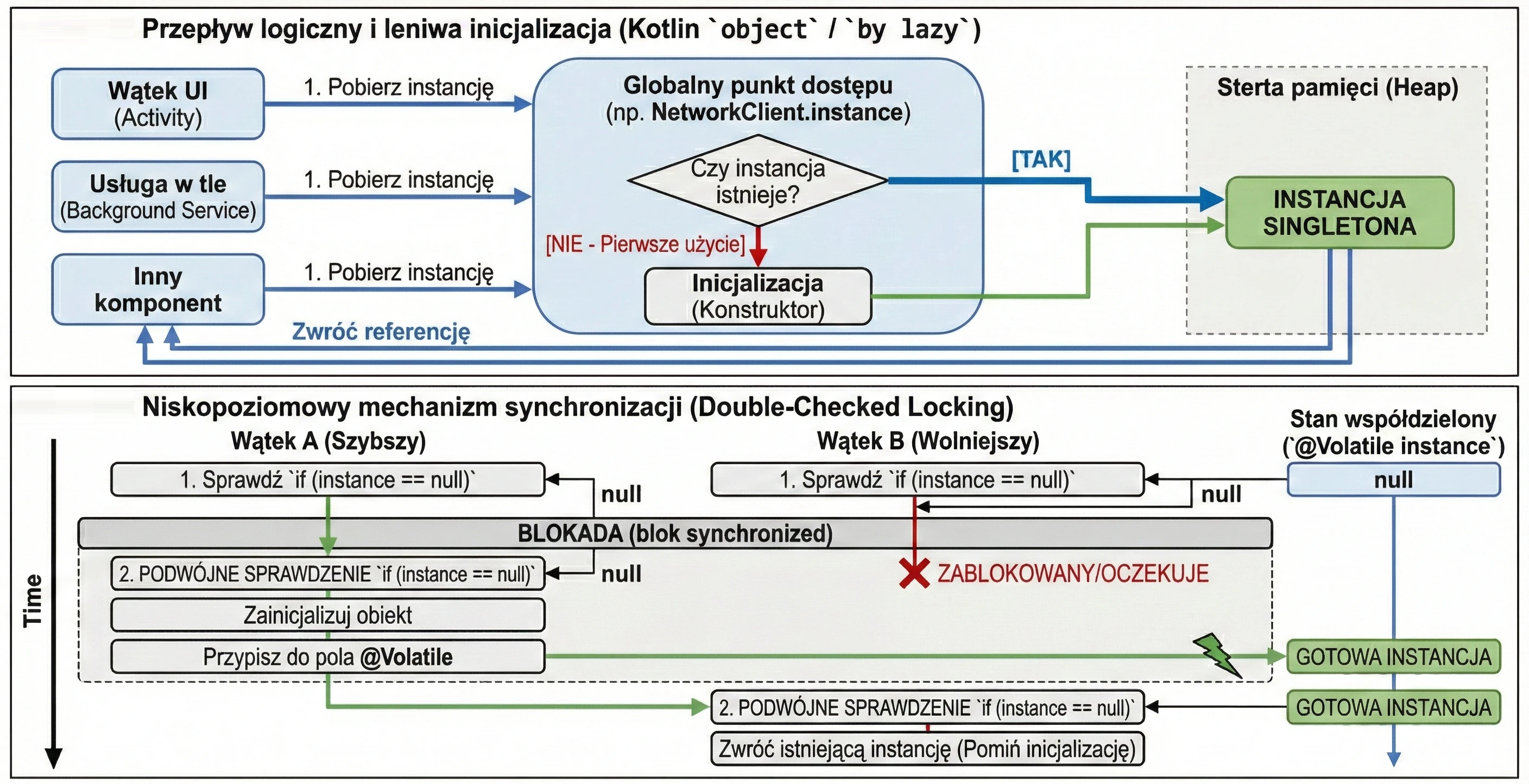
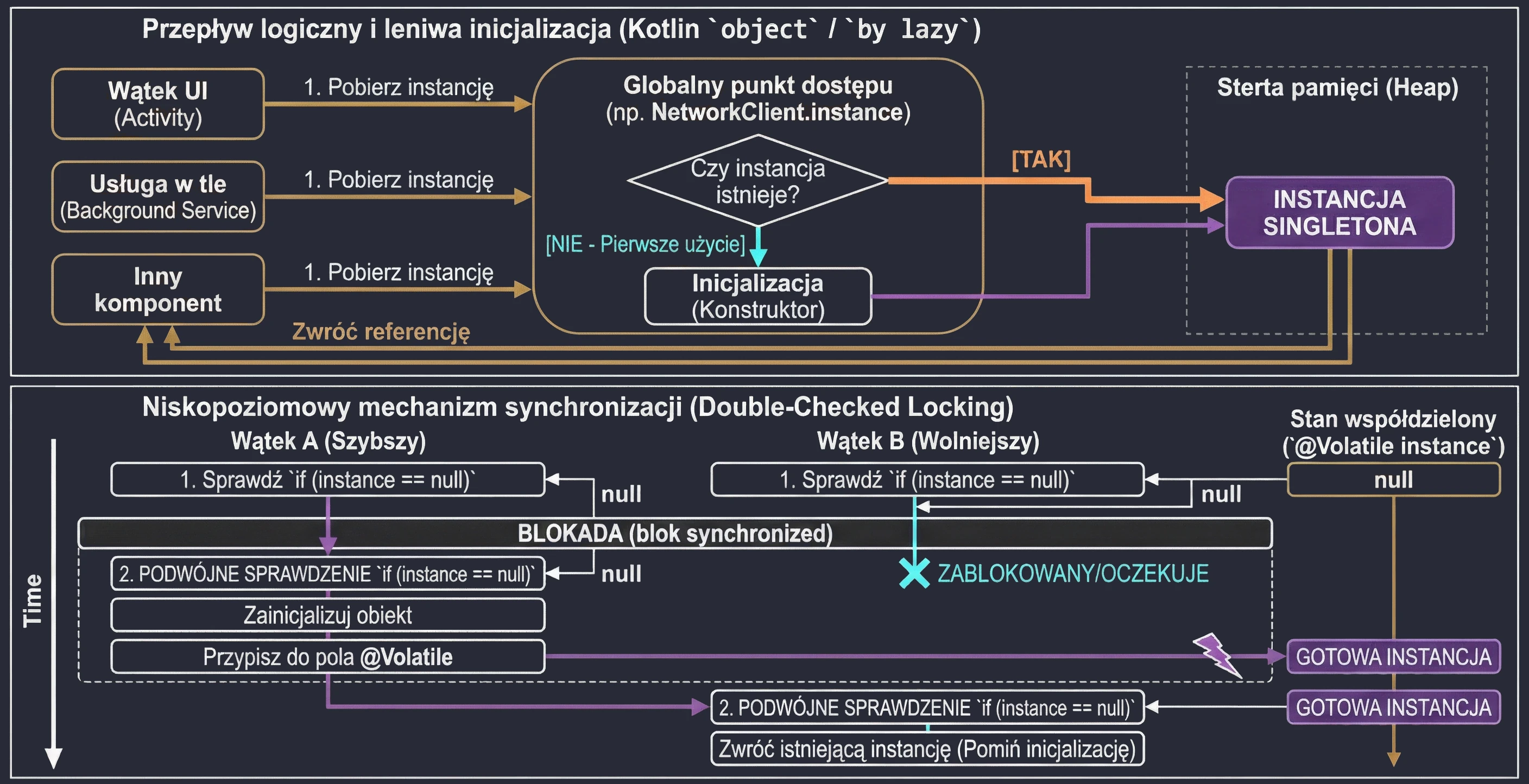
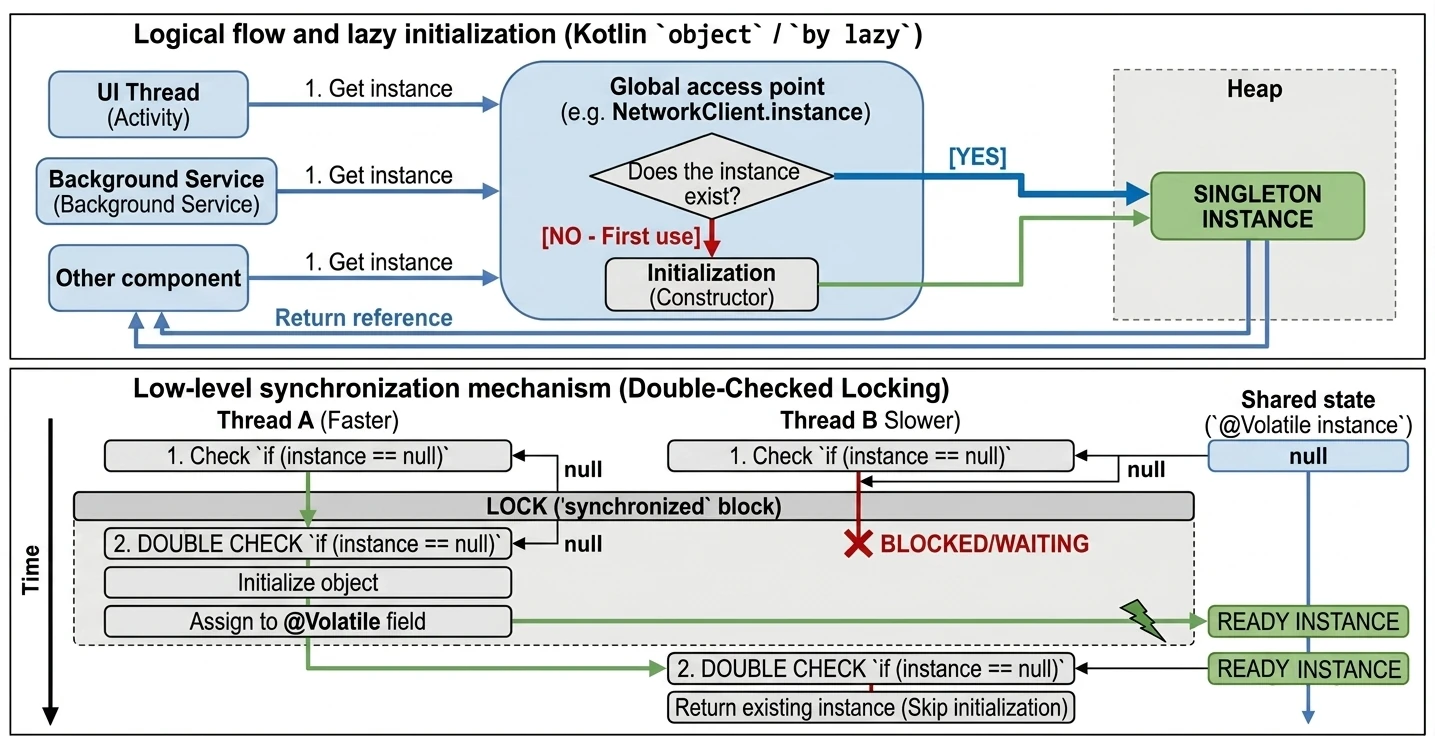
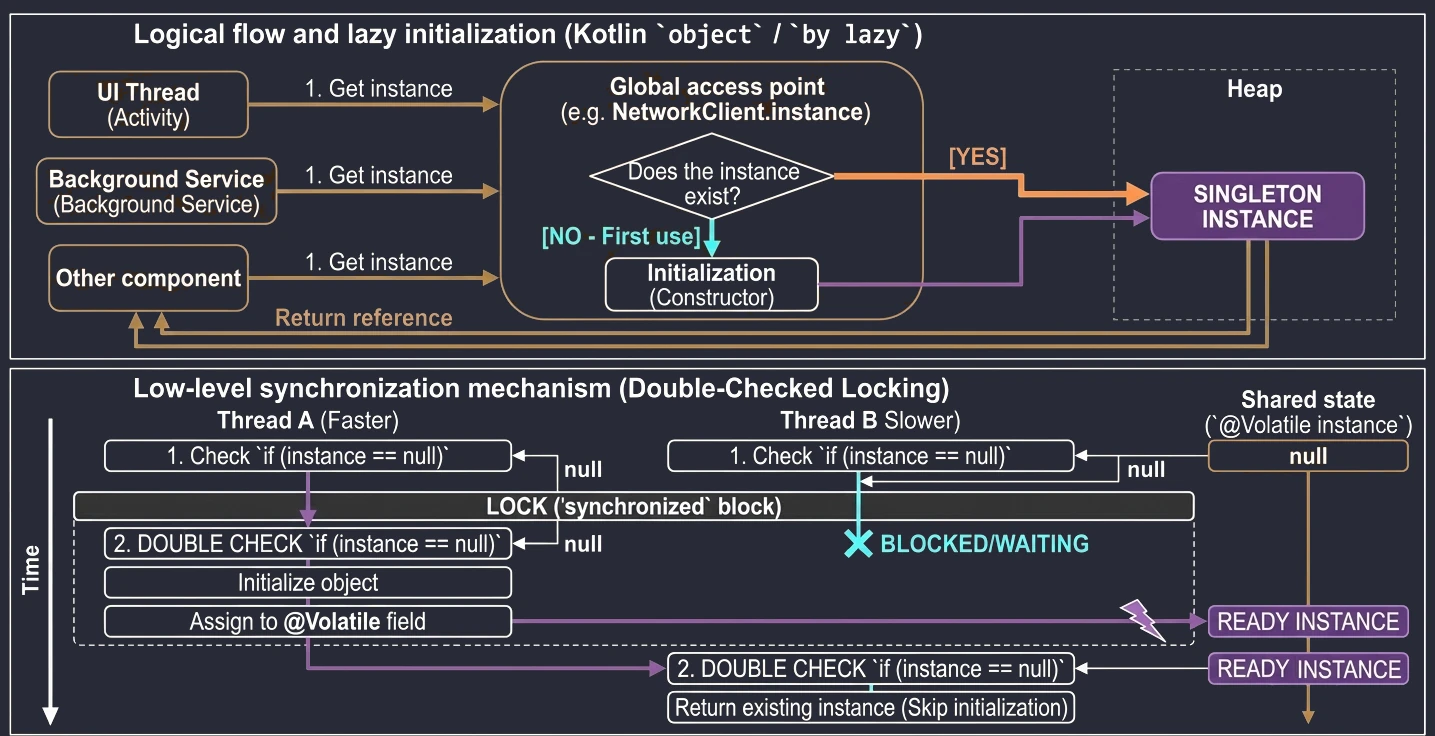
Builder (Budowniczy)
Wzorzec Builder służy do konstruowania złożonych obiektów krok po kroku. Oddziela proces budowania od reprezentacji obiektu. Jest to szczególnie przydatne, gdy obiekt ma wiele opcjonalnych parametrów konfiguracyjnych.
Dzięki argumentom nazwanym i wartościom domyślnym implementacja wzorca Builder w Kotlinie jest bardzo prosta.
// Zamiast Buildera: parametry domyślne
data class Pizza(
val size: String = "Medium",
val cheese: Boolean = true,
val pepperoni: Boolean = false,
val mushrooms: Boolean = false
)
// Użycie
val myPizza = Pizza(
size = "Large",
pepperoni = true
)Jeśli jednak konfiguracja jest bardziej złożona i wymaga walidacji lub operacji pobocznych, możemy użyć funkcji apply do symulacji Buildera:
class NotificationBuilder {
var title: String = ""
var body: String = ""
fun build(): Notification {
require(title.isNotEmpty()) { "Title cannot be empty" }
return Notification(title, body)
}
}
// Użycie
val notification = NotificationBuilder().apply {
title = "Hello"
body = "World"
}.build()Klasyczna implementacja (Java Style)
Mimo że w Kotlinie mamy lepsze narzędzia, jako programiści Androida często korzystamy z bibliotek napisanych w Javie (lub w stylu Javy), które stosują klasyczny wzorzec Builder. Warto go znać, aby efektywnie z nich korzystać.
Cechy klasycznego Buildera:
- Posiada prywatny konstruktor głównej klasy (np.
Notification). - Posiada statyczną klasę wewnętrzną
Builder. - Metody ustawiające pola zwracają
this(obiekt Buildera), co pozwala na łańcuchowanie wywołań. - Posiada metodę
build(), która tworzy finalny obiekt.
Przykład (styl Java w składni Kotlina):
class Pizza private constructor(val size: String, val cheese: Boolean) {
class Builder {
private var size: String = "Medium" // wartość domyślna
private var cheese: Boolean = false
// Metoda zwraca 'Builder' umożliwiając łańcuchowanie
fun setSize(size: String): Builder {
this.size = size
return this
}
fun setCheese(cheese: Boolean): Builder {
this.cheese = cheese
return this
}
fun build(): Pizza {
return Pizza(size, cheese)
}
}
}
// Użycie (wygląda znajomo dla programistów Java/Android SDK)
val pizza = Pizza.Builder()
.setSize("Large")
.setCheese(true)
.build()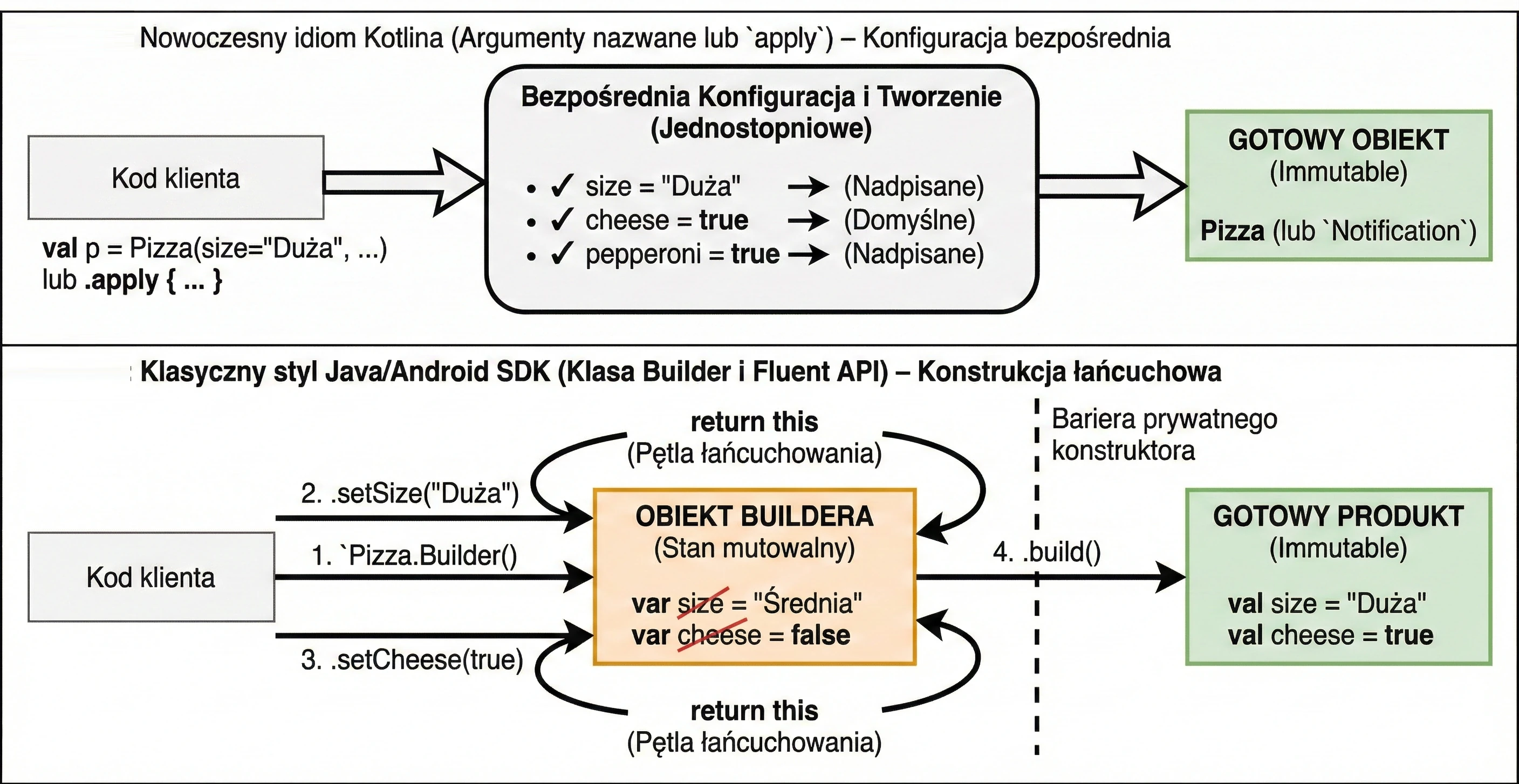
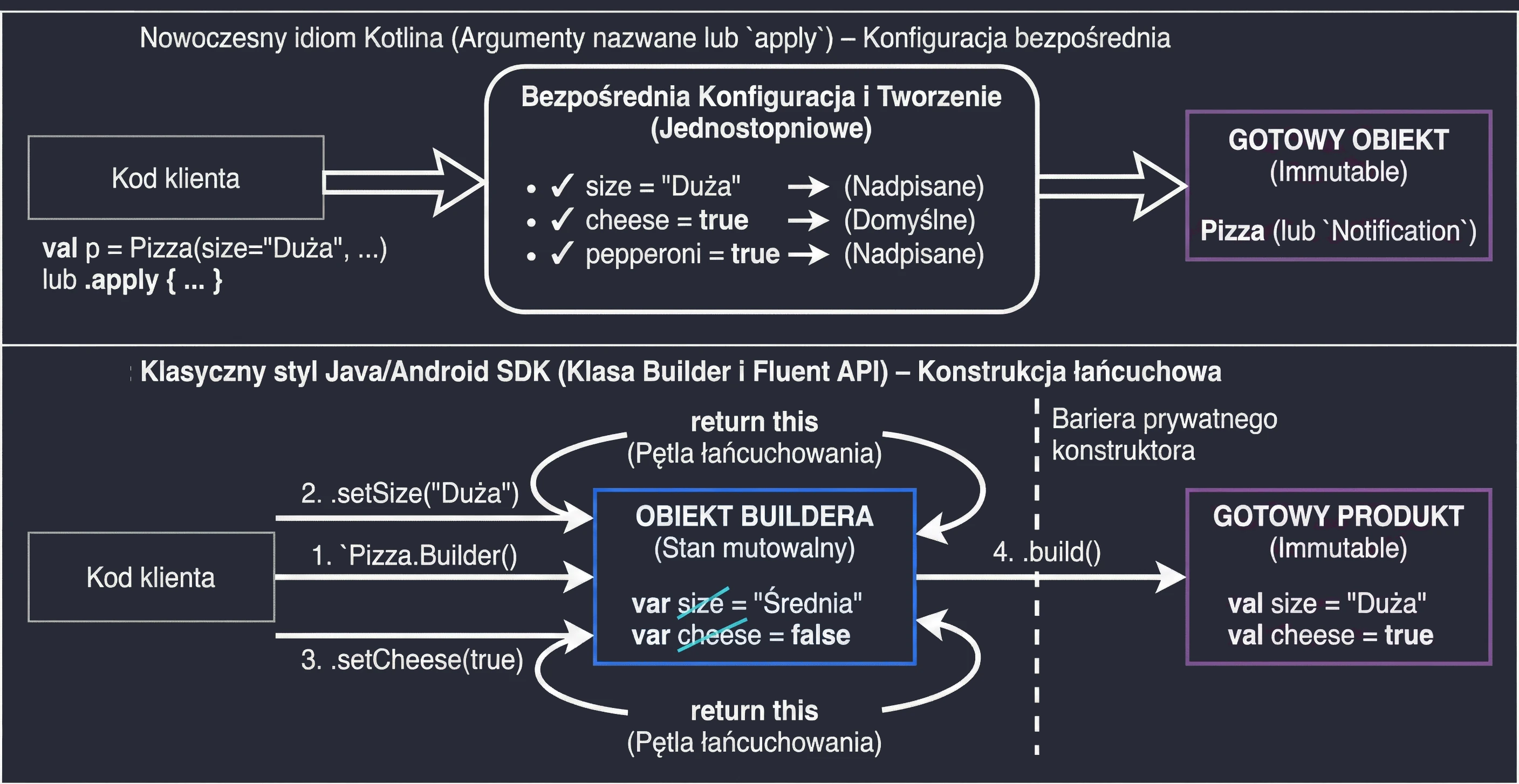
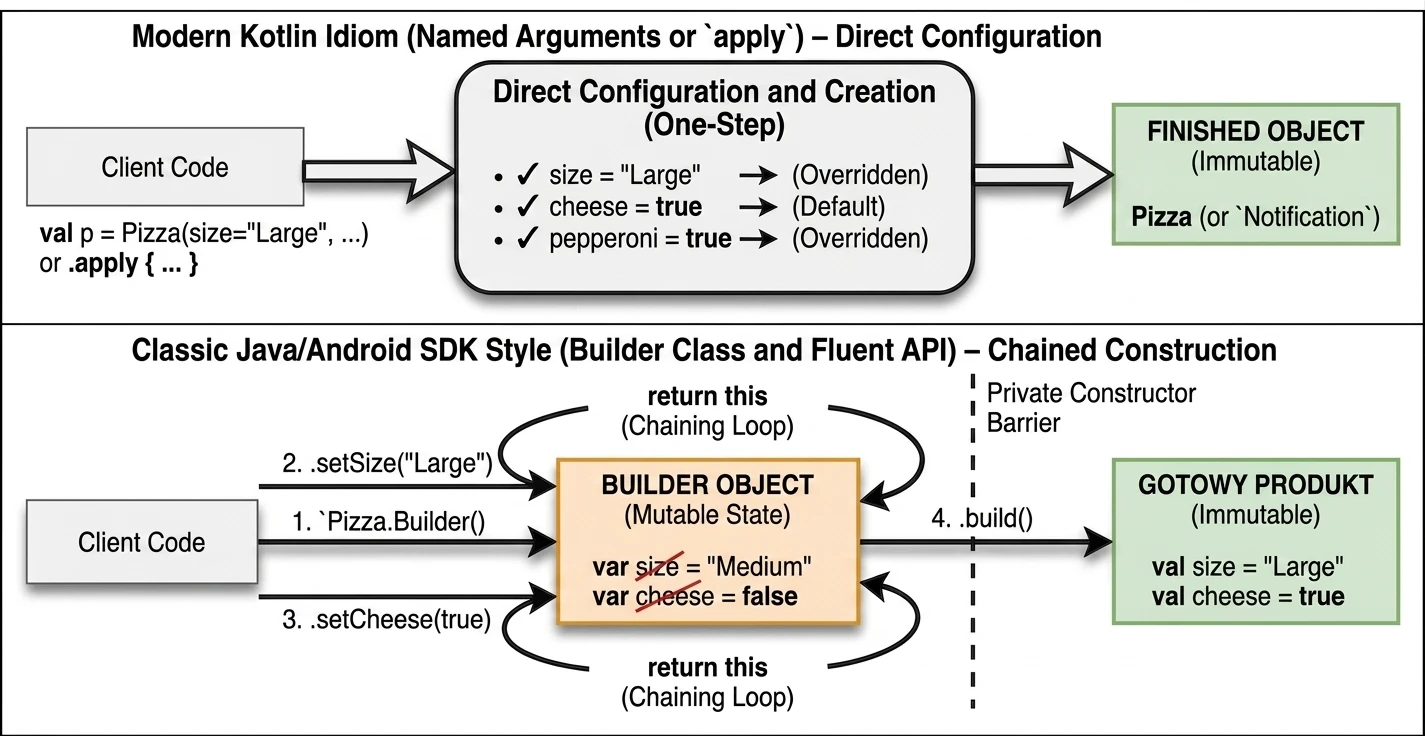
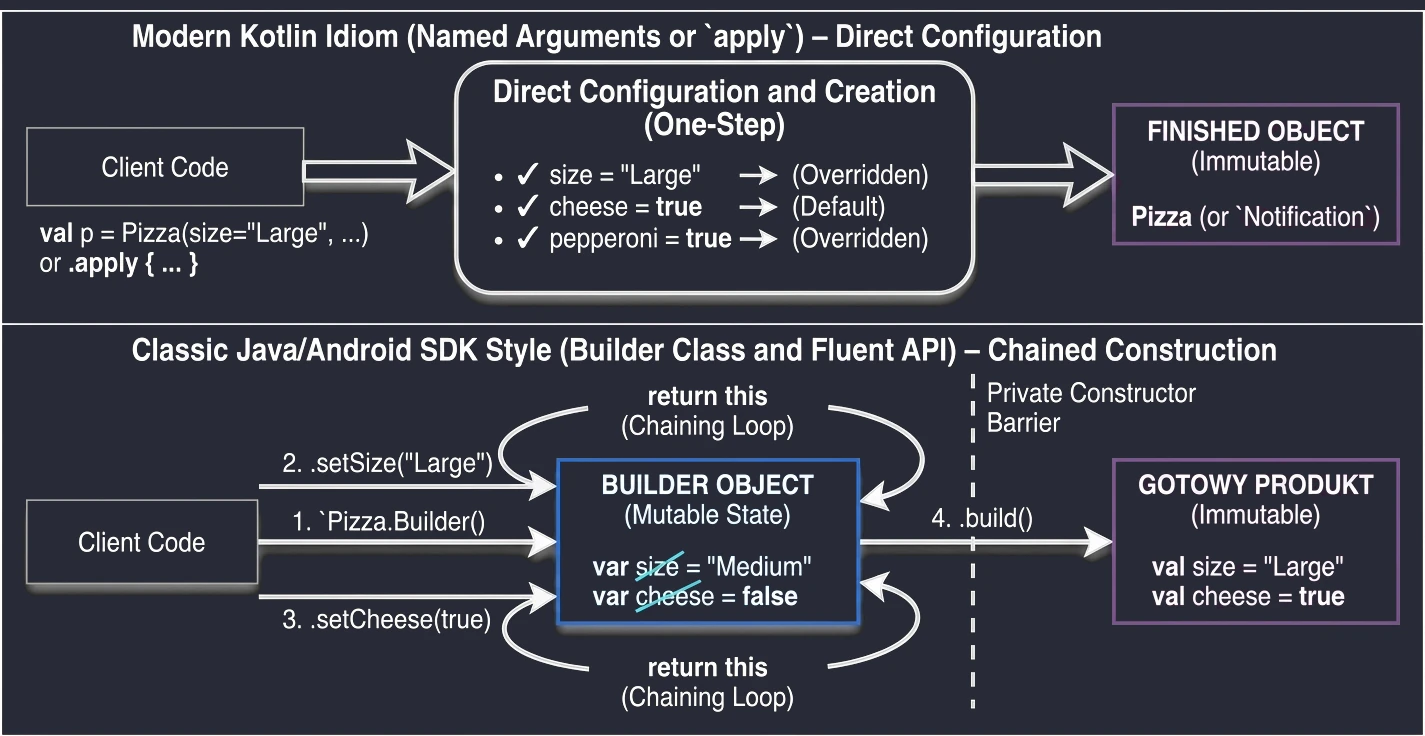
BuilderFactory (Fabryka)
Wzorzec Factory (lub Factory Method) to jeden z najczęściej wykorzystywanych wzorców kreacyjnych. Służy do tworzenia obiektów bez ujawniania klientowi logiki ich tworzenia oraz bez wiązania kodu klienta z konkretną klasą implementującą.
Zamiast wywoływać konstruktor bezpośrednio (np. new ConsoleLogger()), klient prosi fabrykę o dostarczenie obiektu spełniającego określony interfejs. Pozwala to na:
- Ukrycie skomplikowanej logiki tworzenia: Jeśli obiekt wymaga wielu zależności (np. konfiguracji, dostępu do plików), fabryka "chowa" ten kod w jednym miejscu. Dzięki temu klient nie musi wiedzieć jak stworzyć obiekt, a jedynie co chce otrzymać. Ułatwia to też późniejsze zmiany (Zasada Otwarte-Zamknięte) – zmiana sposobu konstrukcji obiektu nie wymaga zmian w kodzie, który go używa.
- Zwracanie różnych implementacji: Metoda fabrykująca może zwrócić dowolną podklasę w zależności od parametrów (np.
FileLoggerw produkcji,ConsoleLoggerw debugu).
W Kotlinie idiomatycznym sposobem implementacji prostych fabryk jest wykorzystanie companion object:
interface Logger {
fun log(message: String)
}
class ConsoleLogger : Logger {
override fun log(message: String) = println(message)
}
class FileLogger : Logger {
override fun log(message: String) { /* pisz do pliku */ }
}
class LoggerFactory {
companion object {
fun create(type: String): Logger = when(type) {
"file" -> FileLogger()
else -> ConsoleLogger()
}
}
}
// Użycie
val logger = LoggerFactory.create("console")Możemy też użyć operatora invoke, aby fabryka wyglądała jak konstruktor:
companion object {
operator fun invoke(type: String): Logger { ... }
}
// Użycie: val logger = LoggerFactory("console")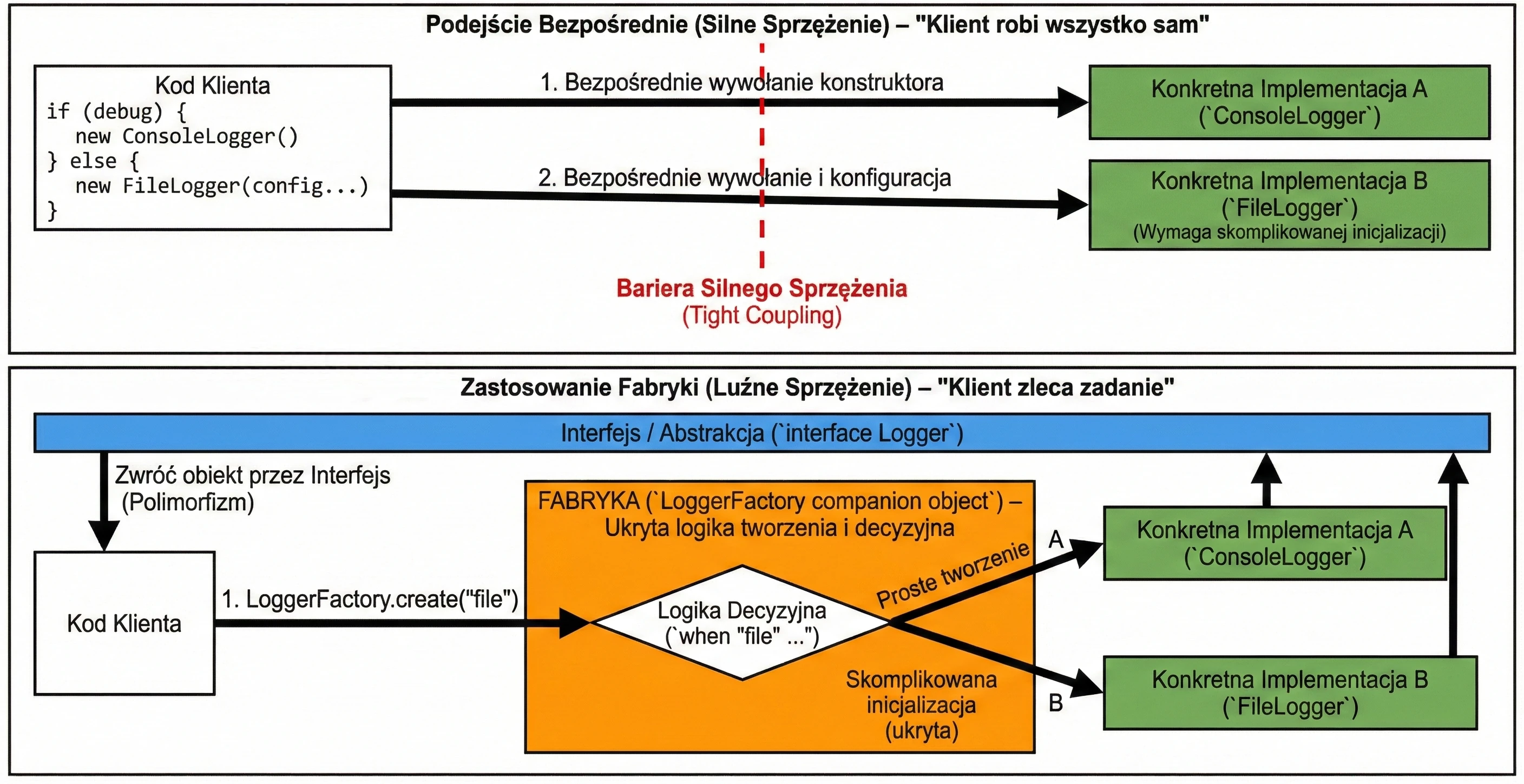
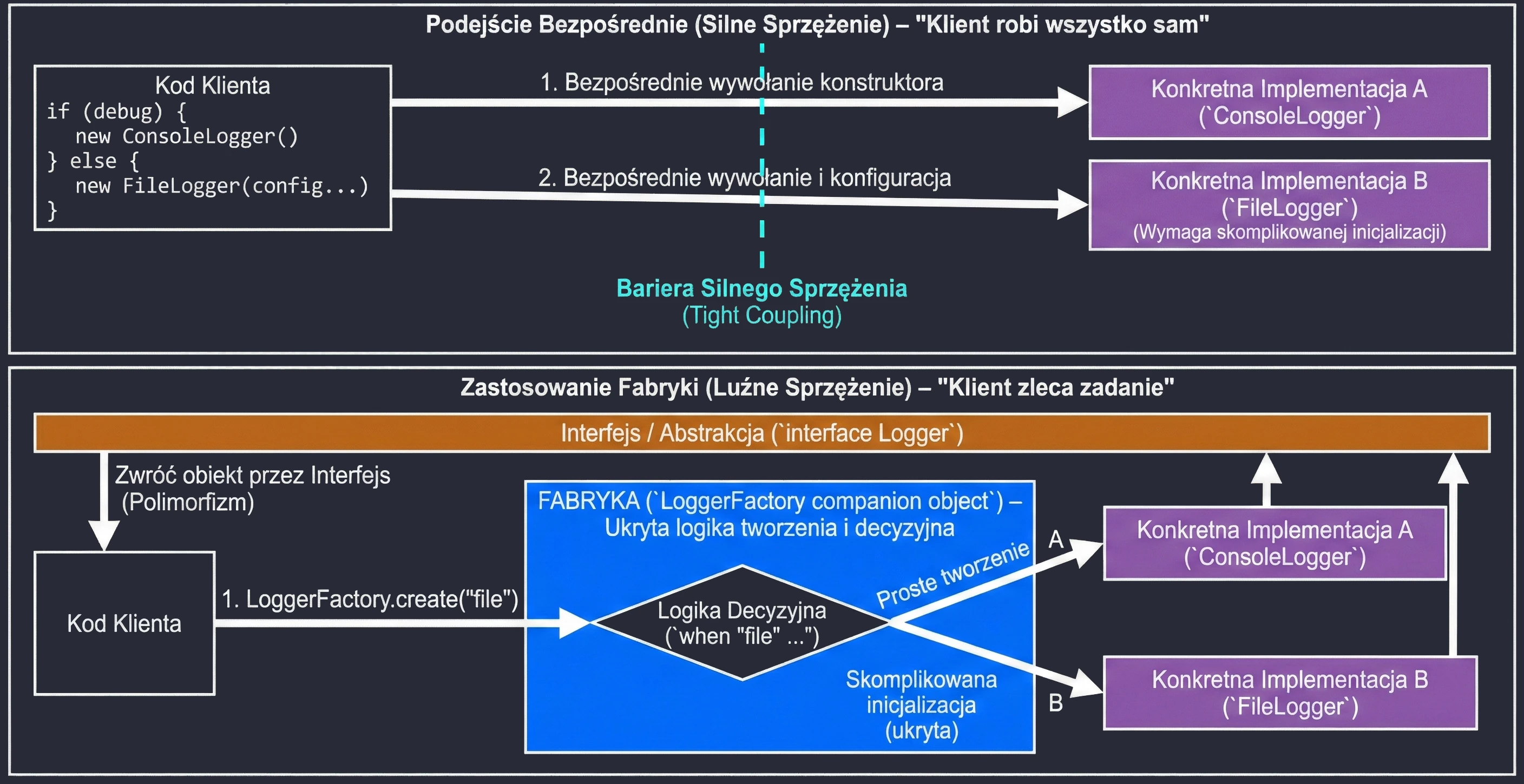
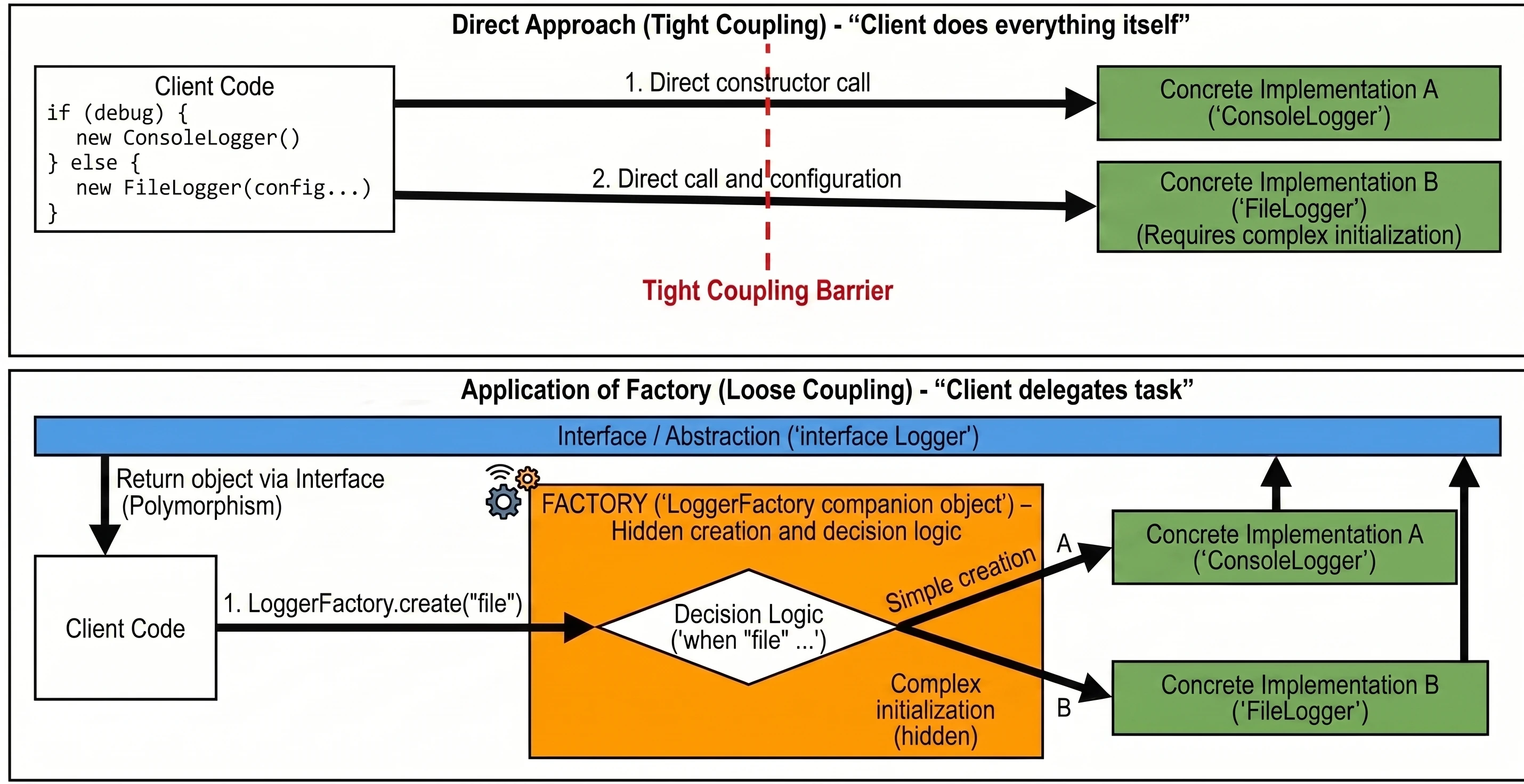
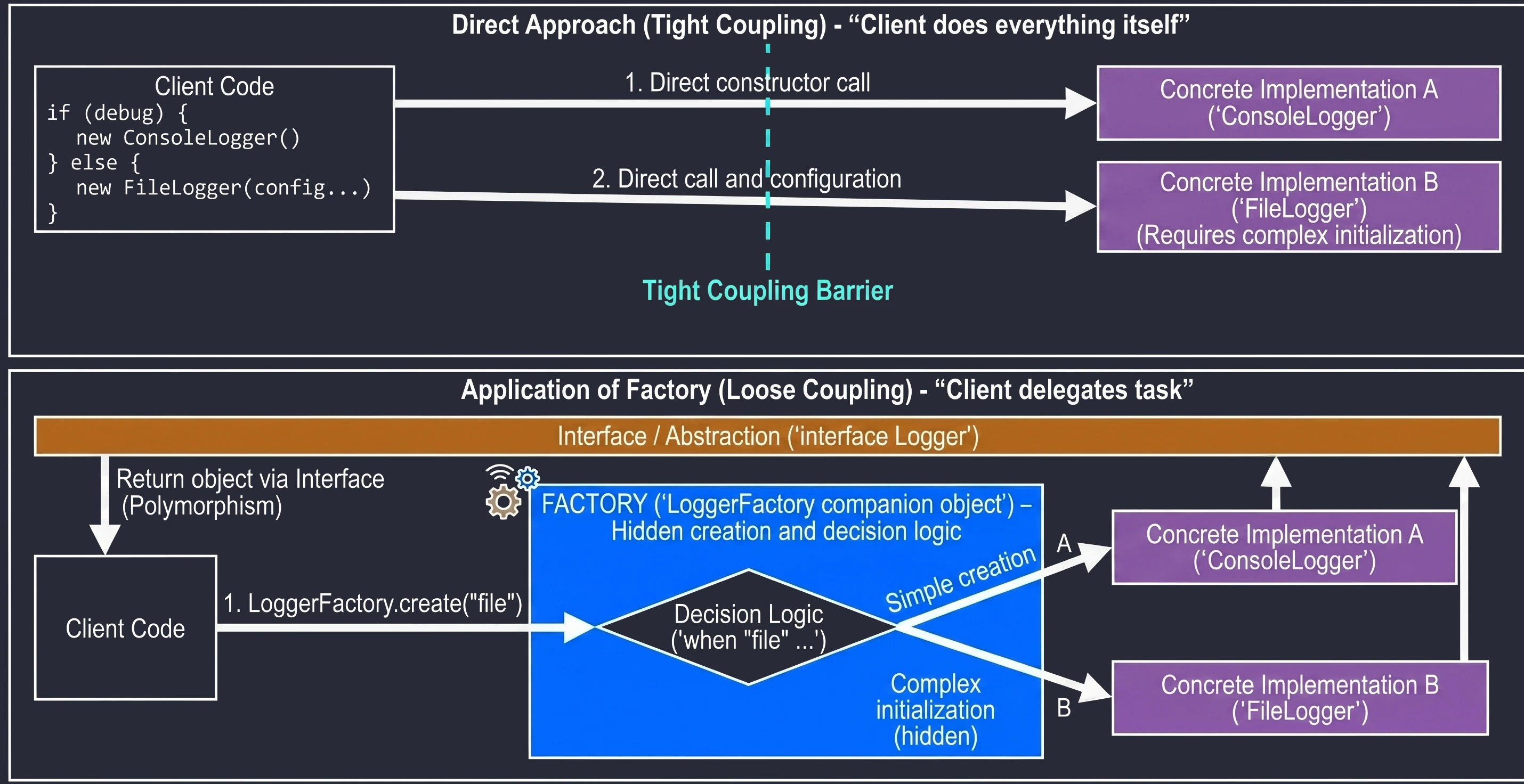
Repository (Repozytorium)
Repozytorium to jeden z ważniejszych wzorców architektonicznych w tworzeniu aplikacji mobilnych. Służy on do abstrakcji źródeł danych i działa jako mediator między domeną aplikacji a warstwą danych.
Warstwa widoku (View/ViewModel) nie powinna wiedzieć, skąd pochodzą dane – czy z lokalnej bazy danych (Room), z API REST-owego (Retrofit), czy może z plików systemowych. Powinna jedynie poprosić o dane i je otrzymać (zazwyczaj jako Flow lub suspend function). To Repozytorium podejmuje decyzję, czy zwrócić dane z pamięci podręcznej (dla szybkości), czy pobrać świeże dane z sieci (dla aktualności). Działa ono jak fasada, ukrywając przed resztą aplikacji złożoność operacji I/O.
Zalety Repozytorium
- Single Source of Truth (SSOT): Repozytorium zarządza danymi i dba o ich spójność (np. pobiera z API i zapisuje do bazy lokalnej).
- Testowalność: Łatwo podmienić prawdziwe repozytorium na fake w testach jednostkowych.
- Decoupling: Zmiana biblioteki do API (np. z Retrofit na Ktor) nie wymaga zmian w kodzie UI.
// Interfejs (kontrakt)
interface UserRepository {
suspend fun getUser(id: String): User
}
// Konkretna implementacja
class UserRepositoryImpl(
private val api: ApiService,
private val database: UserDao
) : UserRepository {
override suspend fun getUser(id: String): User {
// 1. Sprawdź czy user jest w bazie lokalnej (cache)
val cachedUser = database.getUser(id)
if (cachedUser != null) {
return cachedUser
}
// 2. Jeśli nie ma, pobierz z API
val networkUser = api.fetchUser(id)
// 3. Zapisz do bazy na przyszłość
database.saveUser(networkUser)
return networkUser
}
}Dzięki takiemu podejściu, ViewModel po prostu wywołuje repository.getUser("123") i nie martwi się logiką cache'owania ani obsługą sieci.
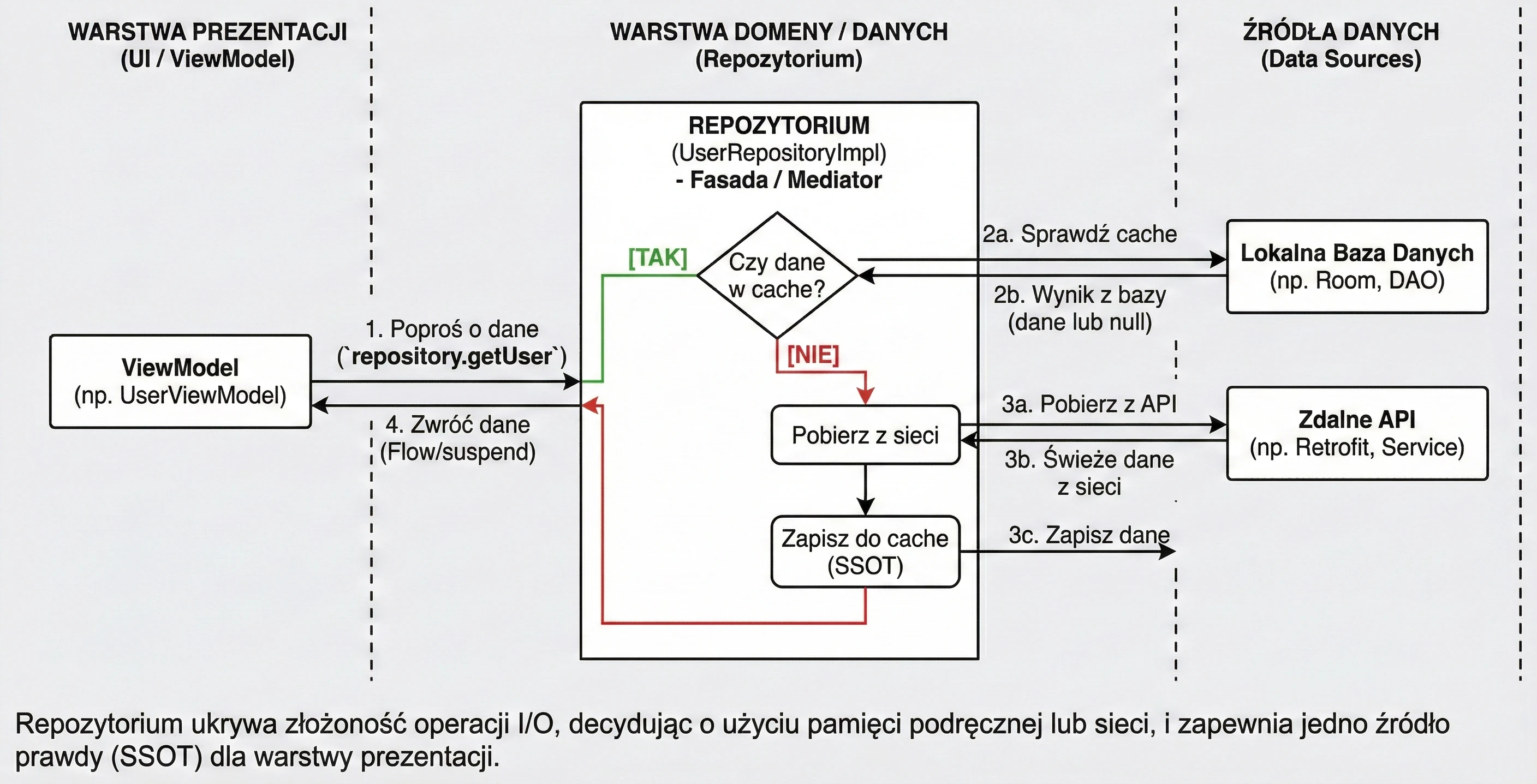
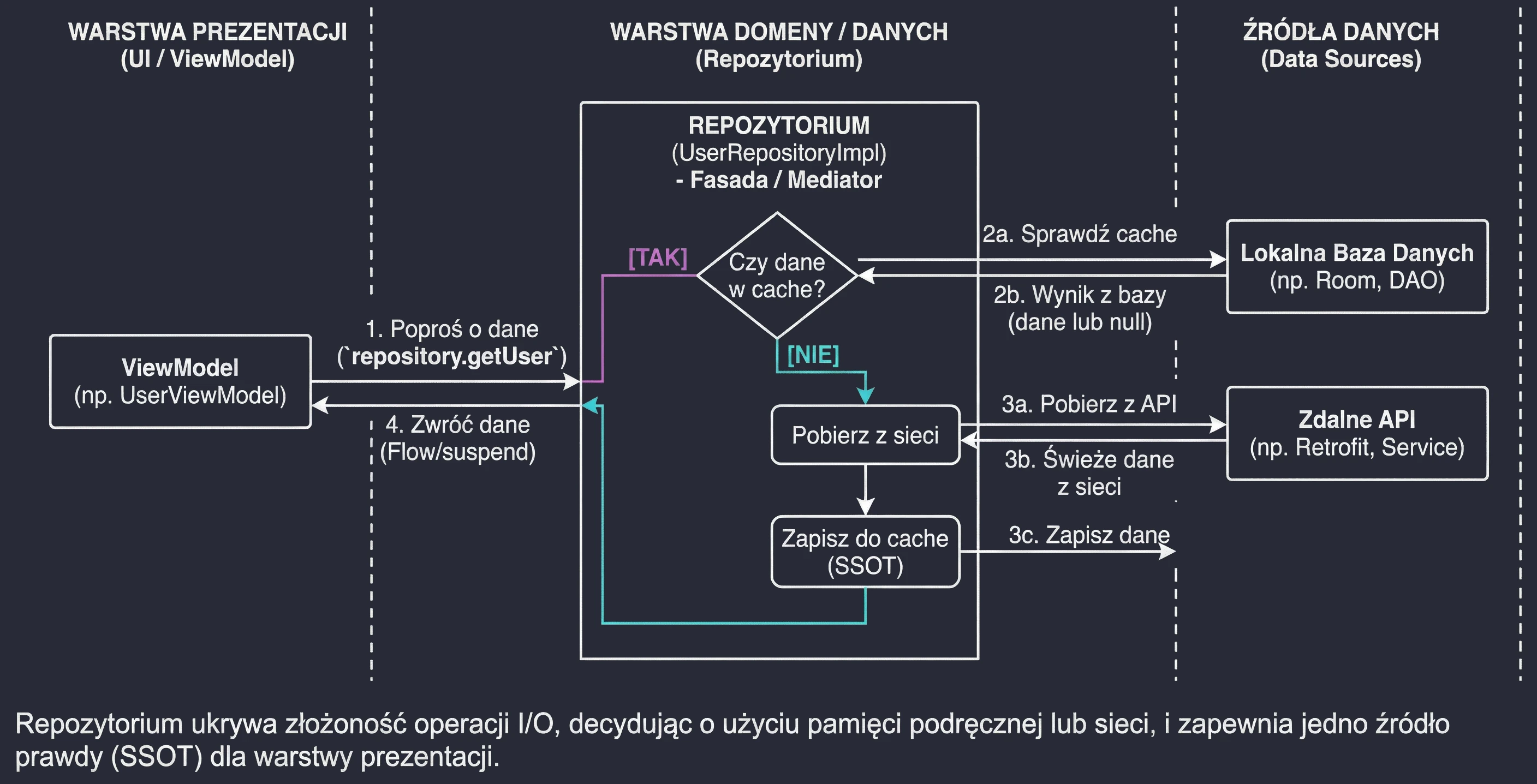
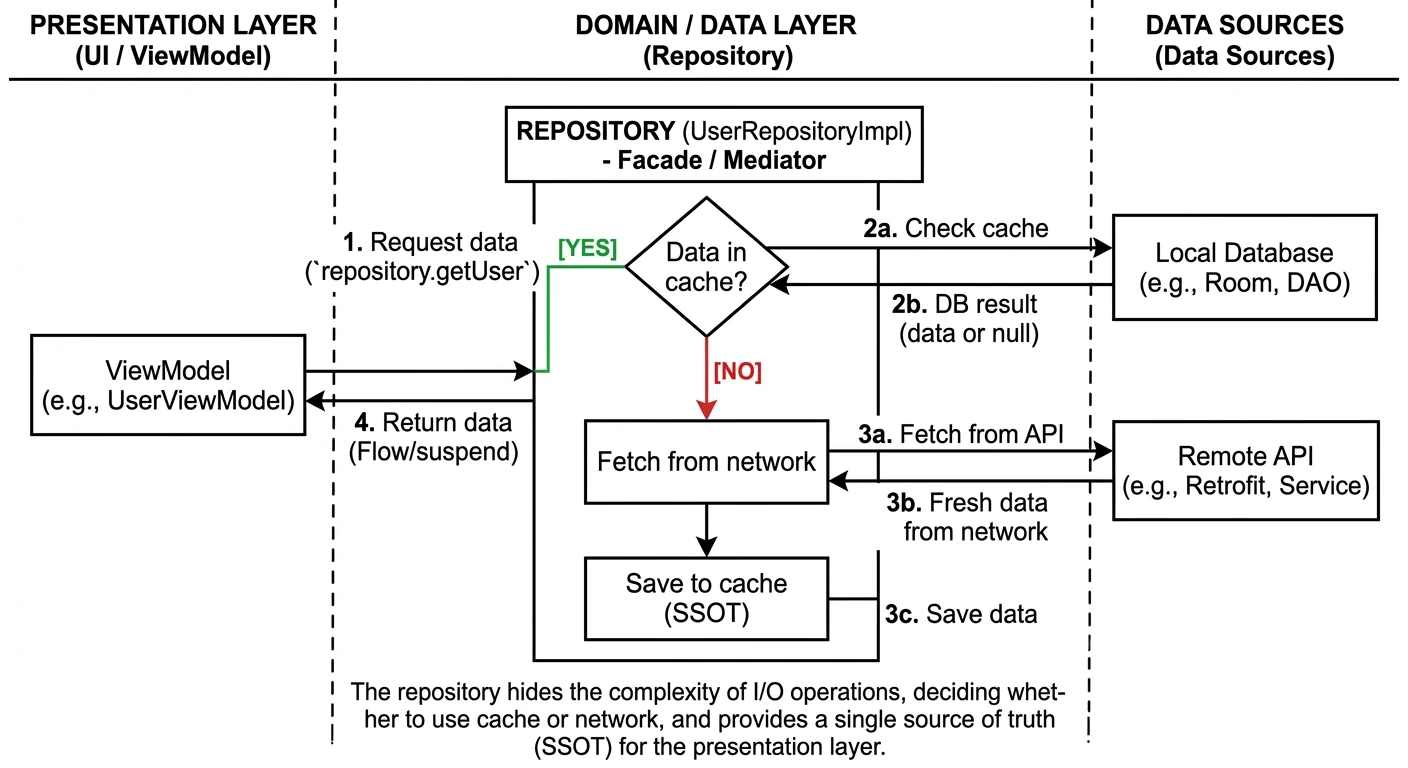
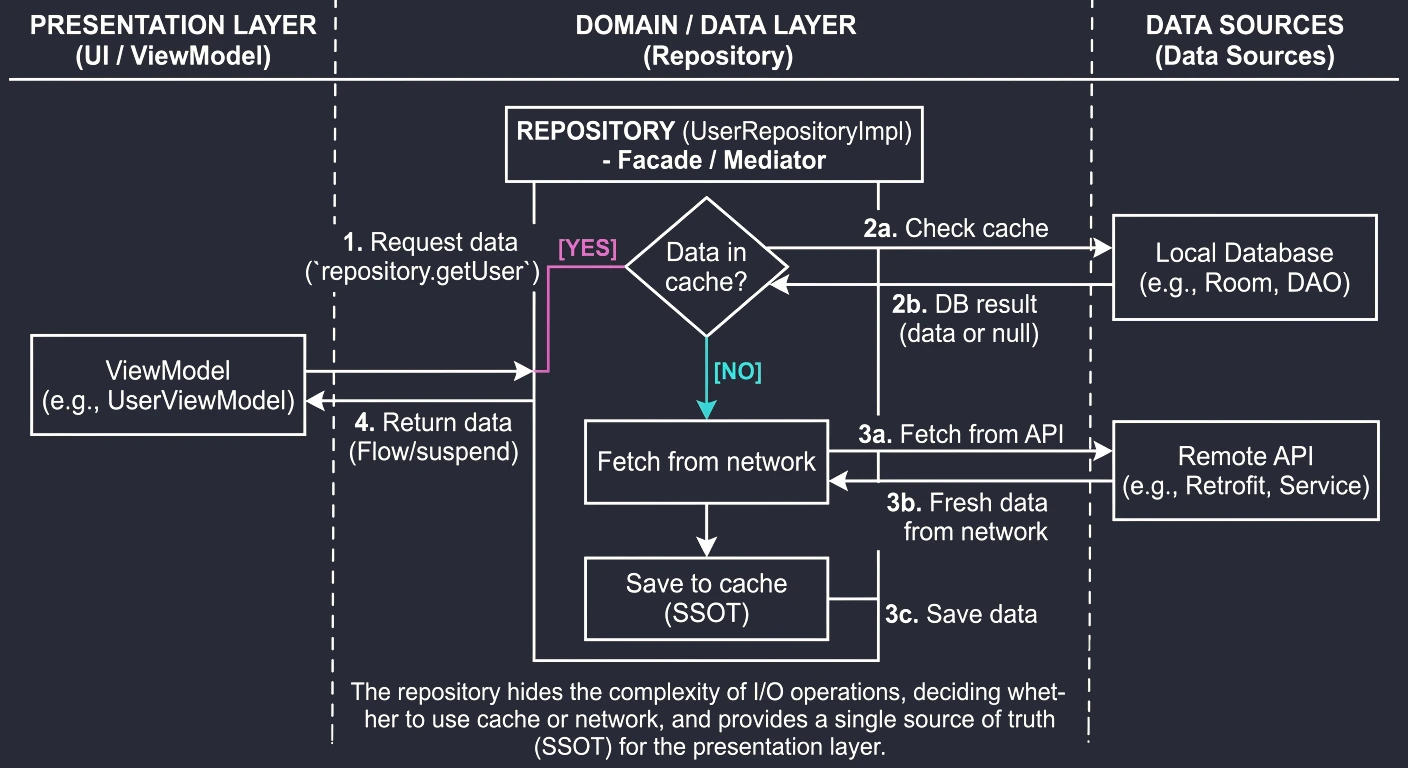
Adnotacje i Przetwarzanie (Annotation Processing)
Adnotacje (np. @Override, @Composable, @GET) to metadane dołączane do kodu. Same w sobie nie zmieniają działania programu, ale mogą być odczytywane przez kompilator lub inne narzędzia.
Dlaczego w ogóle ich używamy?
- Generowanie kodu (Code Generation): To najważniejsze zastosowanie w Androidzie. Biblioteki takie jak Room (baza danych) czy Hilt (wstrzykiwanie zależności) czytają adnotacje i na ich podstawie generują skomplikowany kod "boilerplate", którego nie musimy pisać ręcznie.
- Konfiguracja: Zamiast plików XML czy JSON, konfigurujemy zachowanie klas bezpośrednio w kodzie (np.
@GET("/users")w Retrofit mówi, pod jaki adres uderzyć). - Walidacja: Kompilator może sprawdzić poprawność kodu (np.
@Overrideupewnia się, że faktycznie nadpisujemy metodę).
W ekosystemie Kotlina mamy dwie główne technologie przetwarzania adnotacji:
- KAPT (Kotlin Annotation Processing Tool):
- Starsze rozwiązanie.
- Działa na bazie Java Annotation Processing (APT).
- Wymaga wygenerowania "stubów" (zaślepek) w Javie dla kodu Kotlina.
- KSP (Kotlin Symbol Processing):
- Natywne rozwiązanie dla Kotlina.
- Nie generuje stubów Java -> działa szybciej niż KAPT.
- Rozumie specyficzne dla Kotlina konstrukcje (np.
internal,sealed class). - Zalecane dla bibliotek takich jak Room, Moshi czy Hilt.
Stuby to wygenerowane pliki Java, które zawierają same deklaracje klas i metod z kodu Kotlina (bez ciał funkcji). Są one potrzebne, aby procesory adnotacji napisane dla Javy mogły "zrozumieć" kod Kotlina. Generowanie stubów jest kosztowne i spowalnia kompilację.
Analogia: Wyobraź sobie, że piszesz książkę po polsku (Kotlin), ale Twój redaktor (procesor adnotacji) mówi tylko po angielsku (Java). Stuby to takie "streszczenie" lub "spis treści" przetłumaczone na angielski – redaktor nie widzi całej treści, ale wie, jakie są rozdziały (klasy) i podrozdziały (metody).
Przykład użycia KSP (w build.gradle):
plugins {
id("com.google.devtools.ksp") version "1.9.0-1.0.13"
}W poprzednim rozdziale poznaliśmy wzorce kreacyjne (Singleton, Builder, Factory), które pomagają w tworzeniu obiektów. Teraz skupimy się na wzorcach behawioralnych. Dotyczą one komunikacji między obiektami, podziału odpowiedzialności oraz sposobów, w jaki obiekty ze sobą współpracują.
W świecie Androida i Jetpack Compose, gdzie reaktywność i przepływ danych są kluczowe, wzorce behawioralne odgrywają ogromną rolę.
Observer (Obserwator)
Observer to jeden z najważniejszych wzorców w programowaniu mobilnym. Definiuje on mechanizm subskrypcji, który pozwala wielu obiektom (Observers) obserwować inny obiekt (Subject) i reagować na jego zmiany.
Wyobraź sobie, że masz ekran wyświetlający kursy walut. Dane te zmieniają się w czasie. Bez Obserwatora, ekran musiałby ciągle pytać serwer lub bazę danych: "Czy coś się zmieniło?" (tzw. polling). Co gorsza, po pobraniu nowych danych, musielibyśmy ręcznie wywołać metodę aktualizującą UI (np. updateUI()).
Zamiast pytać, ekran zapisuje się (subskrybuje) na powiadomienia. Gdy kurs waluty się zmieni, źródło danych (Subject) samo powiadomi wszystkich zainteresowanych (Observers).
W historii Androida mieliśmy wiele implementacji tego wzorca:
- Callbacki / Listenery: (np.
OnClickListener,TextWatcher) – klasyczna forma, gdzie przekazujemy interfejs, którego metoda zostanie wywołana po zdarzeniu. - LiveData: Obiekt przechowujący dane, świadomy cyklu życia (Activity/Fragment), który powiadamia obserwatorów tylko gdy widok jest aktywny.
- StateFlow / SharedFlow (Kotlin Coroutines): Obecny standard. Strumienie danych, na które nasłuchujemy (
collect).
W Jetpack Compose cały system opiera się na obserwacji stanu (State<T>). Gdy wartość stanu się zmienia, Compose automatycznie powiadamia funkcje @Composable i przerysowuje (rekomponuje) interfejs.
Przykład: Klasyczny Observer vs StateFlow
Spójrzmy, jak ewoluował ten wzorzec w Kotlinie i Androidzie.
1. Starsze podejście w Kotlinie (Listener/Callback) Wymaga ręcznego definiowania interfejsu i zarządzania listą słuchaczy.
// Definicja interfejsu (Observer)
interface UserListener {
fun onUserUpdated(newName: String)
}
// Źródło danych (Subject)
class UserRepository {
private val listeners = mutableListOf<UserListener>()
fun addListener(listener: UserListener) = listeners.add(listener)
fun updateUser(name: String) {
// Powiadom wszystkich
listeners.forEach { it.onUserUpdated(name) }
}
}2. Nowsze podejście w Kotlinie (StateFlow) Zamiast listy listenerów, używamy strumienia danych, który zawsze posiada aktualną wartość.
class UserViewModel {
// Subject (można zmieniać)
private val _userName = MutableStateFlow("Jan")
// Observer interface (tylko do odczytu)
val userName: StateFlow<String> = _userName.asStateFlow()
fun updateName(name: String) {
_userName.value = name // Automatyczne powiadomienie subskrybentów
}
}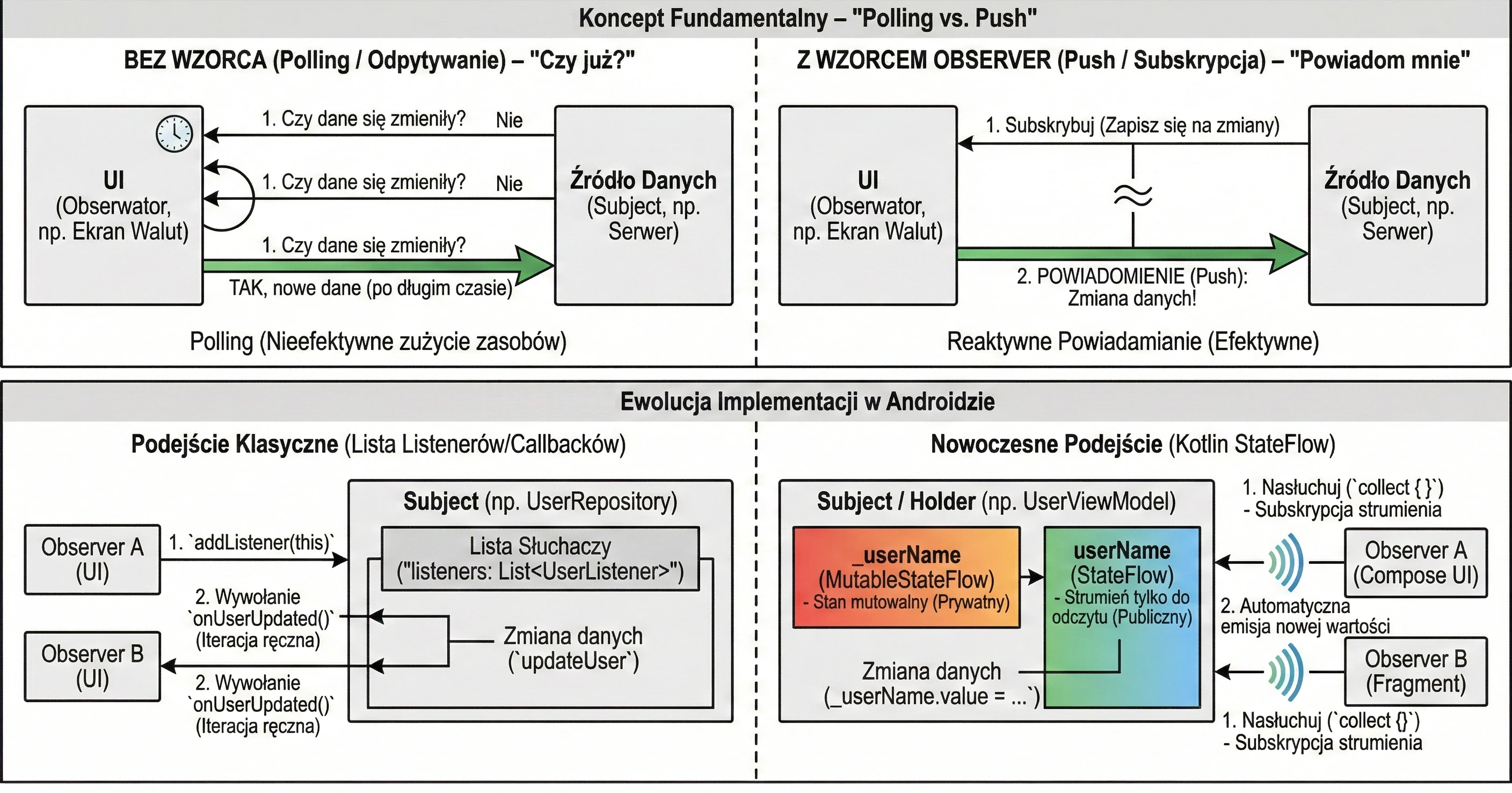
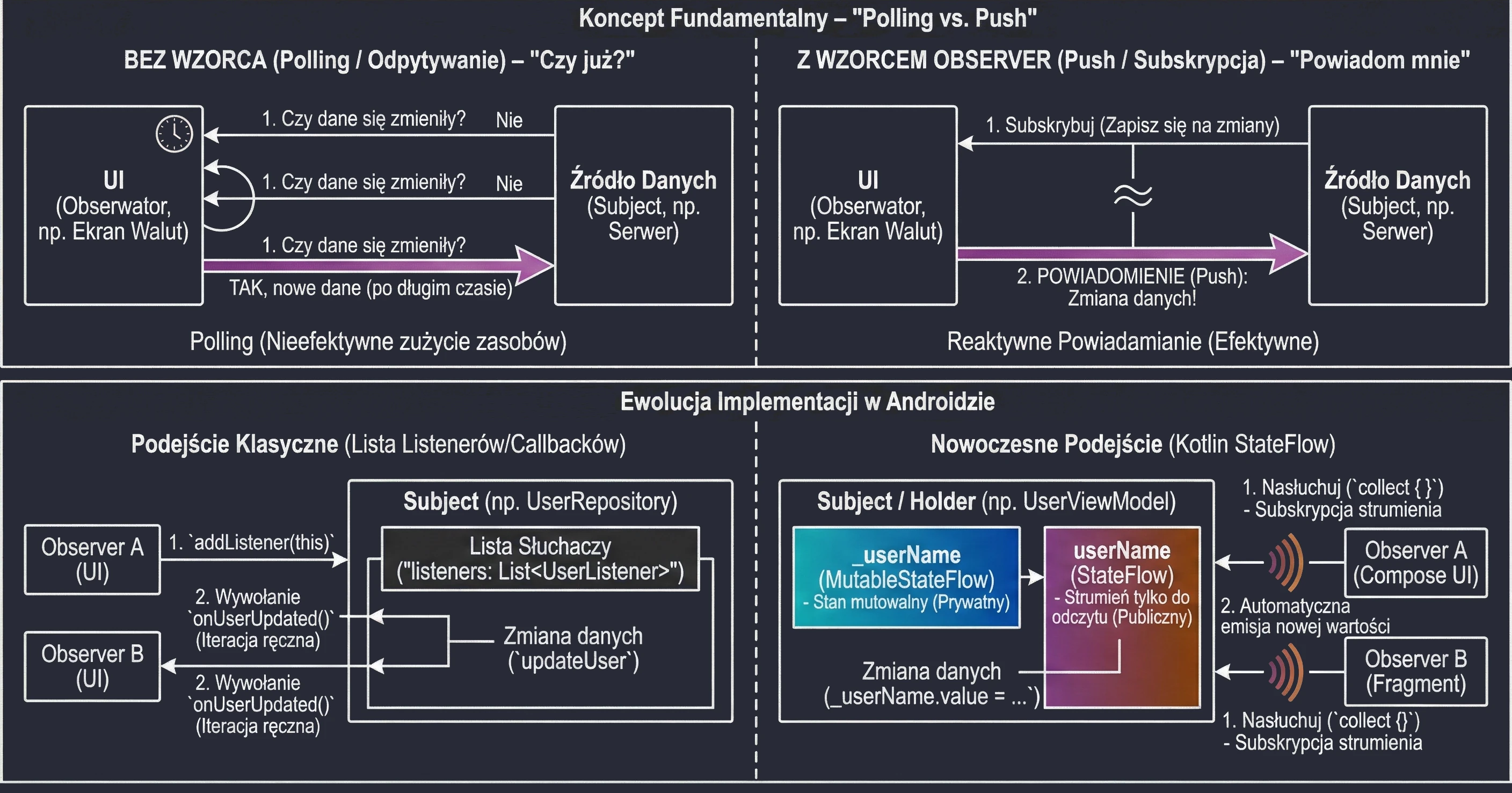
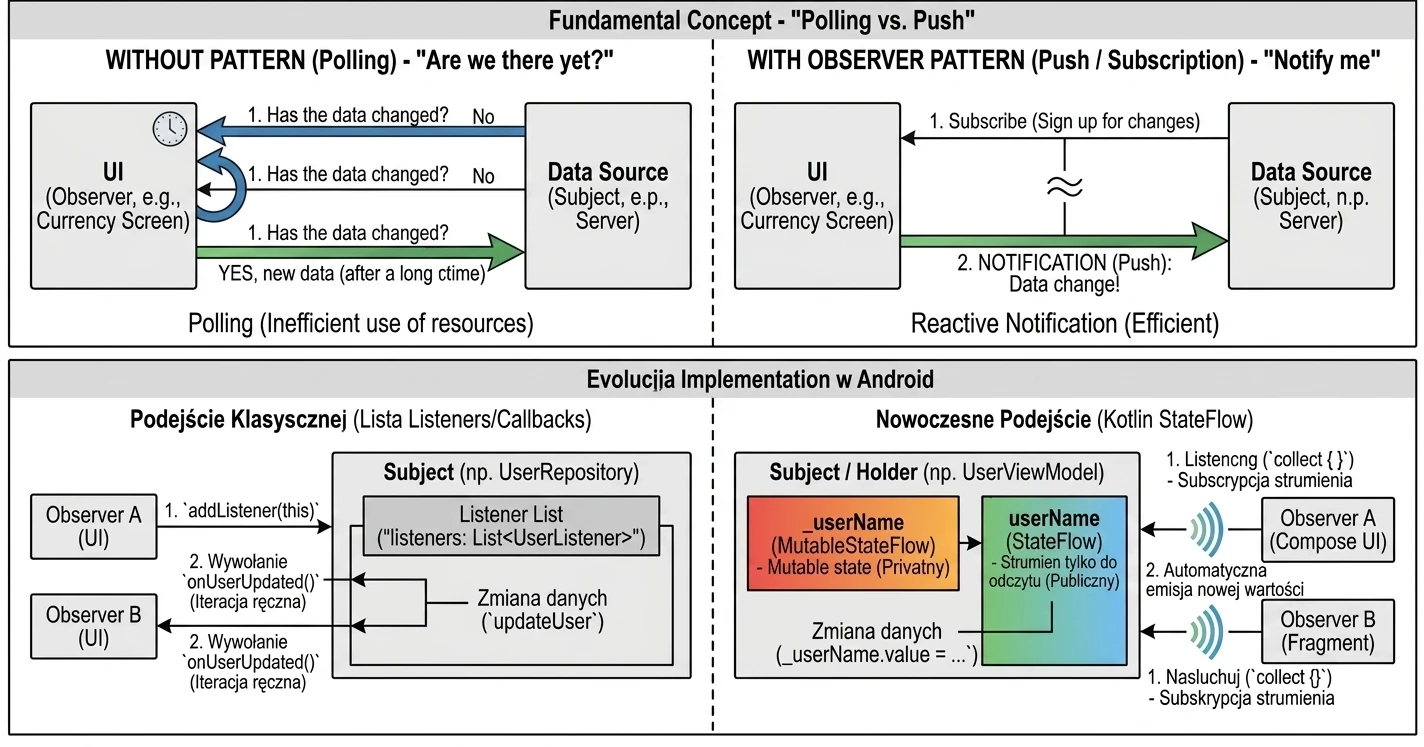
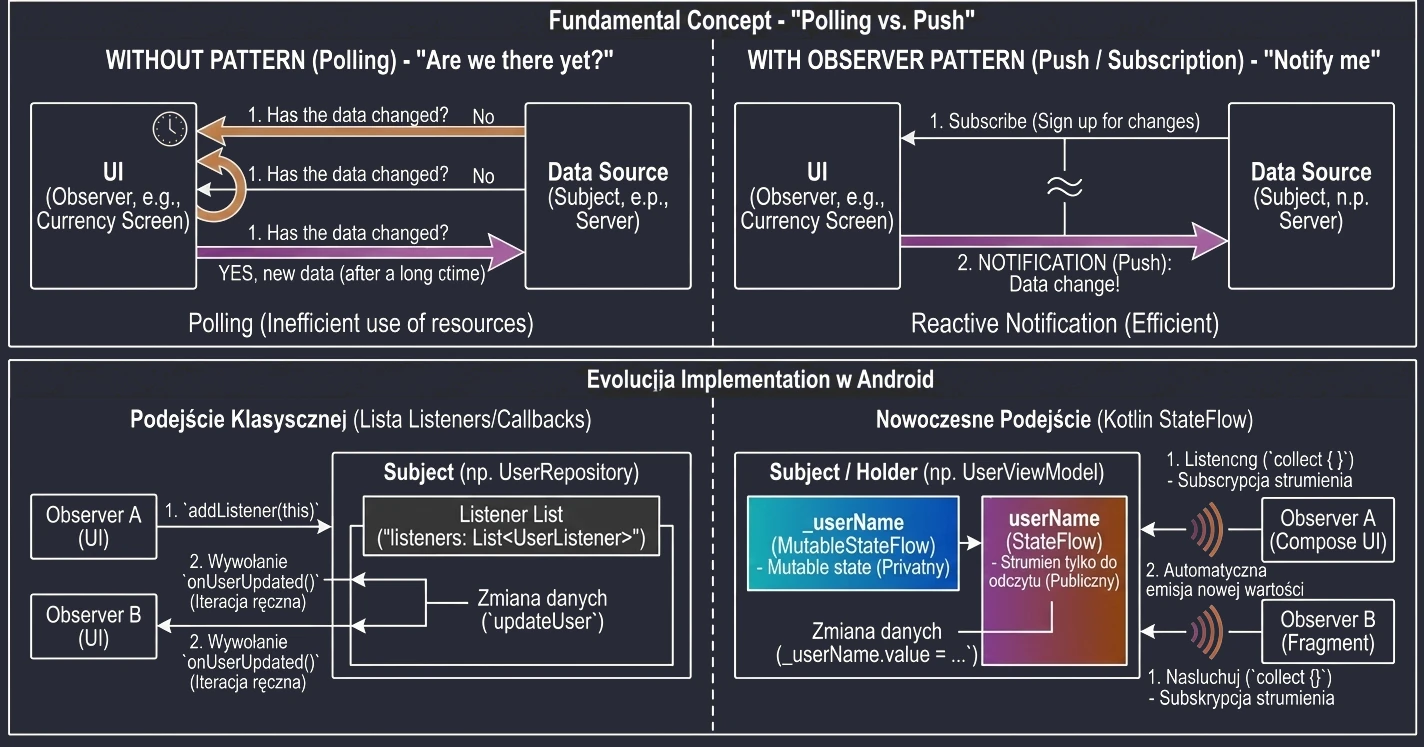
State (Stan)
Wzorzec State pozwala obiektowi zmieniać swoje zachowanie w zależności od wewnętrznego stanu. Unikamy dzięki temu gigantycznych instrukcji if-else lub switch/when rozrzuconych po całym kodzie.
W aplikacjach (MVVM/MVI) stan ekranu modelujemy często jako osobne klasy (zazwyczaj sealed class lub sealed interface).
// Definicja możliwych stanów ekranu
sealed interface ScreenState {
object Loading : ScreenState
data class Success(val data: List<String>) : ScreenState
data class Error(val message: String) : ScreenState
}
// Obsługa w UI (Jetpack Compose)
@Composable
fun MyScreen(state: ScreenState) {
when (state) {
is ScreenState.Loading -> CircularProgressIndicator()
is ScreenState.Success -> Text("Data: ${state.data}")
is ScreenState.Error -> Text("Error: ${state.message}", color = Color.Red)
}
}Dzięki temu, widok jest głupi – tylko wyświetla to, co nakazuje mu stan. Logika przejść między stanami (np. po pobraniu danych przejdź z Loading do Success) znajduje się w ViewModelu.
Wzorzec State vs State w Compose
Warto rozróżnić:
- Wzorzec State: Architektoniczne podejście do modelowania zachowania (np.
sealed class). - Compose State: Mechanizm biblioteczny (
mutableStateOf), który służy do przechowywania danych, których zmiana wymusza odświeżenie widoku.
Często używamy ich razem: ViewModel trzyma StateFlow<ScreenState>, a Compose obserwuje go i zamienia na State<ScreenState>, by sterować widokiem.
Strategy (Strategia)
Strategia pozwala zdefiniować rodzinę algorytmów, opakować je w osobne klasy (lub funkcje) i wymieniać w czasie działania programu. Klient używający strategii nie musi wiedzieć, jak algorytm działa w środku.
Możemy mieć interfejs SortStrategy, a konkretne implementacje to BubbleSortStrategy, QuickSortStrategy itp. Użytkownik wybiera metodę sortowania z listy, a kod wywołujący po prostu woła strategy.sort(list).
W Kotlinie: Funkcje jako Strategie
W Kotlinie funkcje są obywatelami pierwszej kategorii, więc strategią może być po prostu lambda:
fun processNumbers(numbers: List<Int>, filterStrategy: (Int) -> Boolean): List<Int> {
return numbers.filter(filterStrategy)
}
// Użycie różnych strategii "w locie"
val nums = listOf(1, 2, 3, 4, 5)
val evens = processNumbers(nums) { it % 2 == 0 } // Strategia: parzyste
val bigs = processNumbers(nums) { it > 3 } // Strategia: większe od 3To znacznie upraszcza kod.
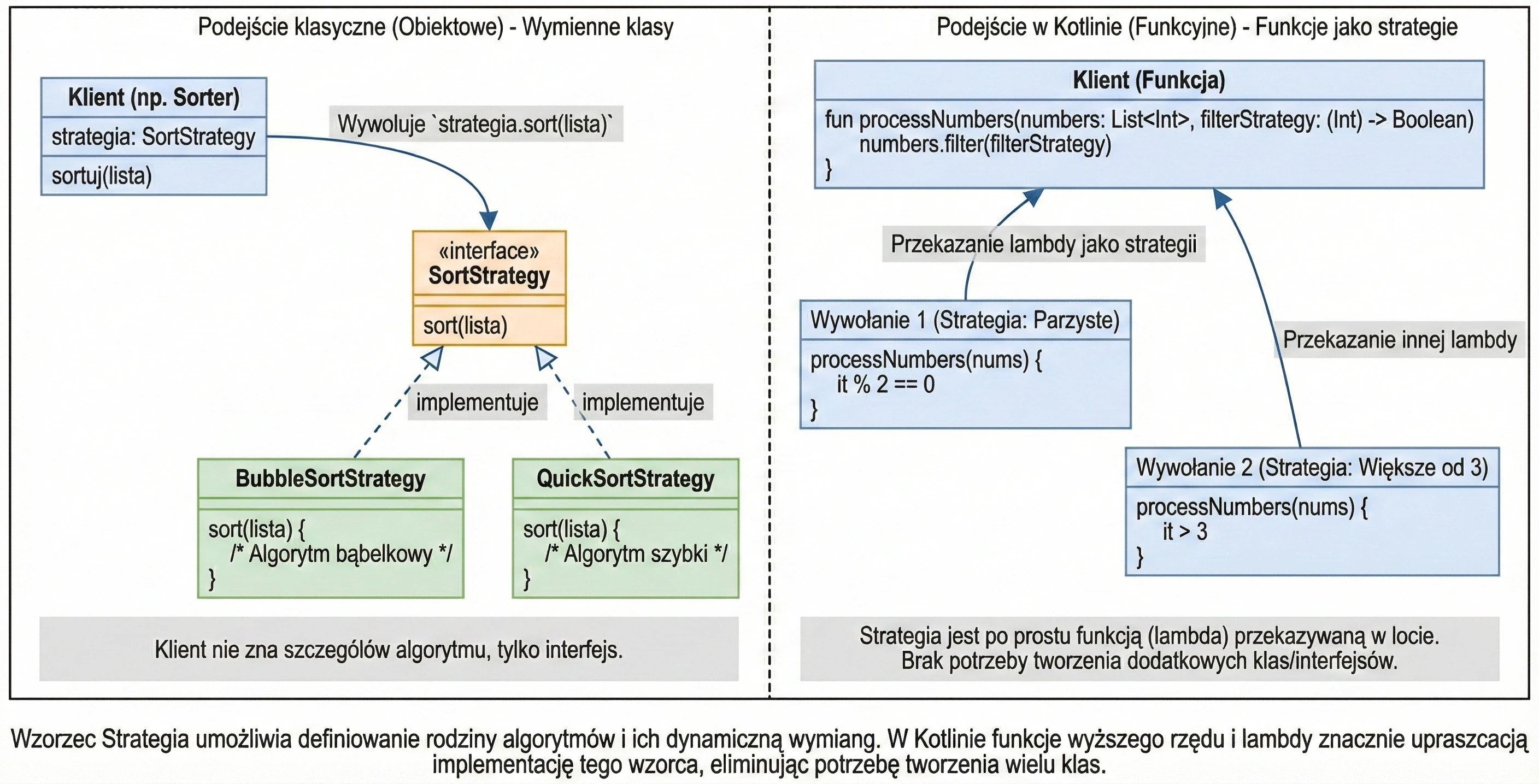
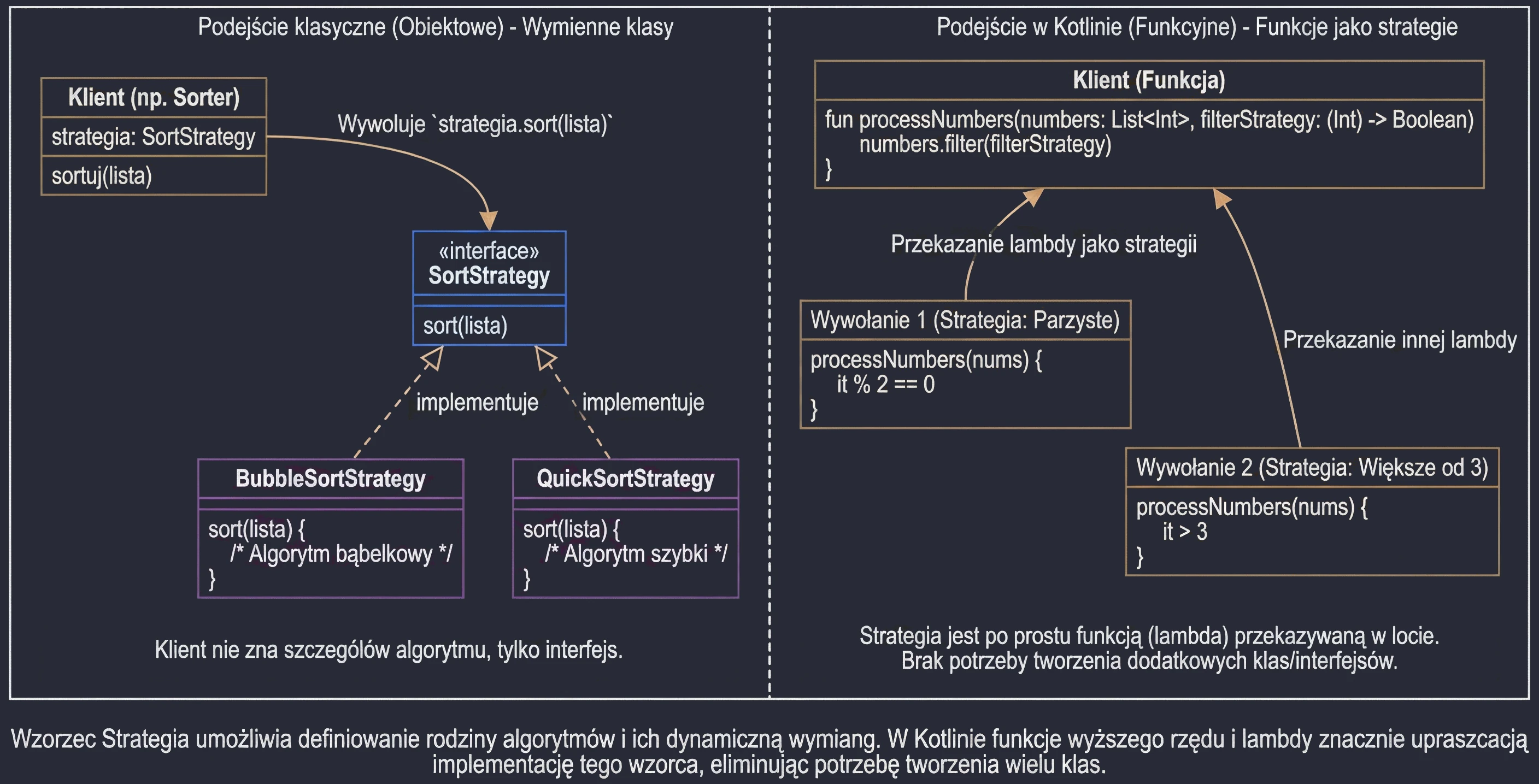
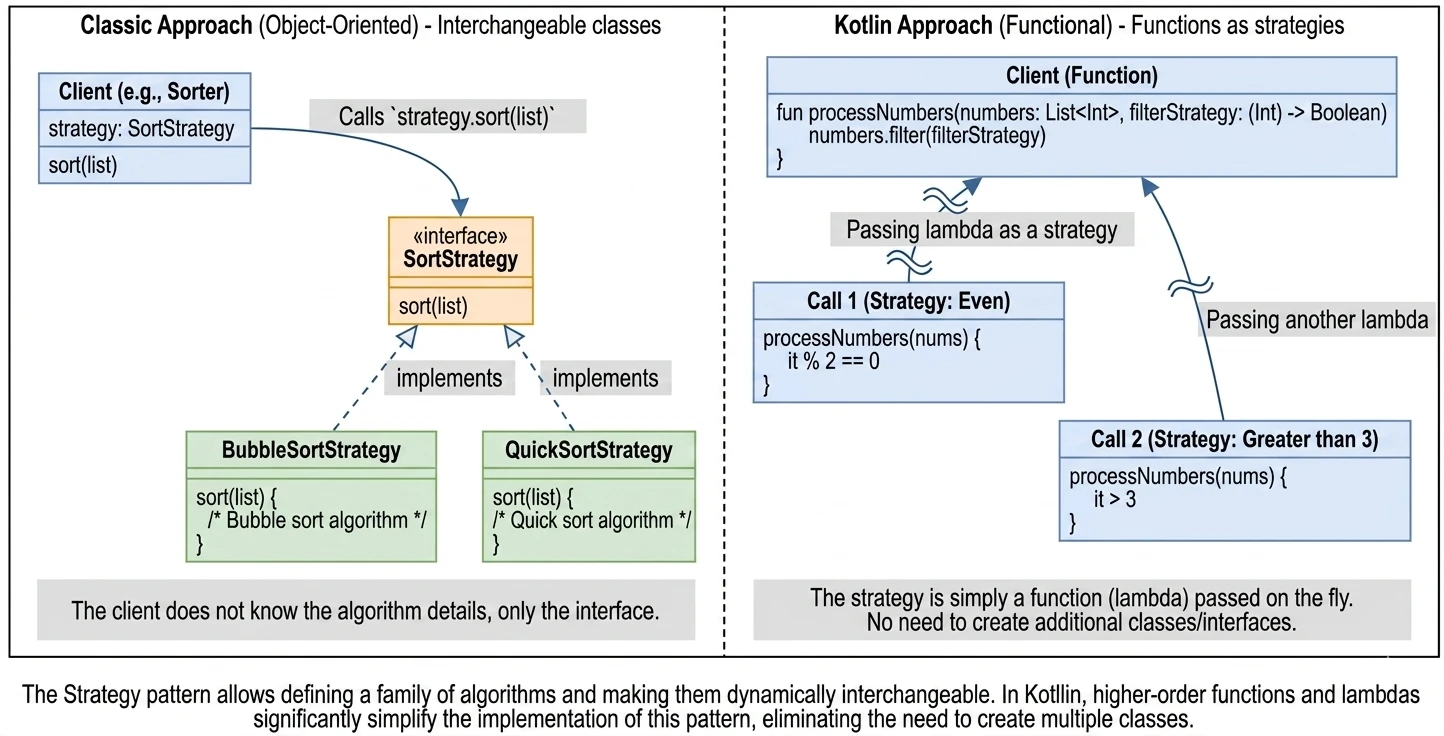
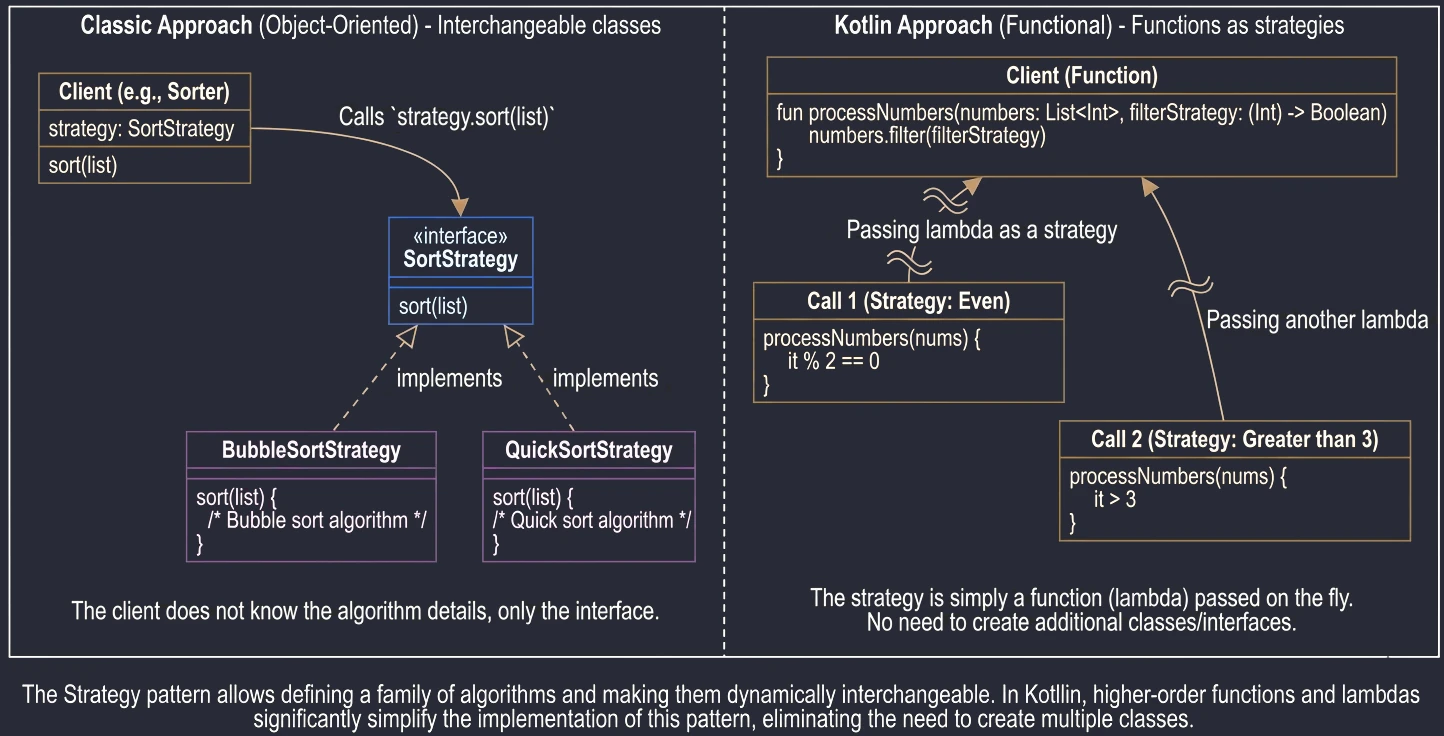
Mediator
Mediator to wzorzec, który służy do zmniejszenia powiązań (coupling) między wieloma klasami. Zamiast obiekty komunikować się każdy z każdym (tworząc sieć zależności jak spaghetti), komunikują się tylko z Mediatorem. Mediator decyduje, co z tym zrobić.
Analogicznie, samoloty (komponenty) nie rozmawiają bezpośrednio ze sobą (Cześć Boeing, ląduję). Rozmawiają z wieżą (Mediator). Wieża wie o wszystkich samolotach i steruje ruchem, zapobiegając kolizjom.
Jeśli masz skomplikowany formularz, gdzie zmiana CheckBoxa A wpływa na widoczność Pola B, a wpisanie tekstu w C, blokuje Przycisk D – zamiast pisać logikę wewnątrz każdego elementu UI (onCheckedChange w CheckBoxie zmieniające visibility pola B), lepiej użyć Mediatora (np. ViewModelu).
Wszystkie zdarzenia (Events) lecą do ViewModelu (Mediatora), on aktualizuje Stan, a Stan wraca do Widoku. Komponenty UI nie wiedzą o swoim istnieniu – wiedzą tylko o Mediatorze.
Przykład: Formularz Rejestracji
W tym przykładzie RegistrationViewModel pełni rolę Mediatora. Pola tekstowe i przycisk nie wiedzą o sobie nawzajem. Przycisk Zarejestruj staje się aktywny tylko wtedy, gdy Username jest poprawny, ale to Mediator o tym decyduje.
// Stan formularza
data class RegistrationState(
val username: String = "",
val isButtonEnabled: Boolean = false
)
// Mediator (ViewModel)
class RegistrationViewModel : ViewModel() {
// Używamy mutableStateOf zamiast Flow (prościej dla początkujących)
var state by mutableStateOf(RegistrationState())
private set // Setter prywatny, tylko ViewModel może zmieniać
fun onUsernameChange(newName: String) {
// Logika mediacji: Zmiana nazwy wpływa na przycisk
val isValid = newName.length >= 3
state = state.copy(
username = newName,
isButtonEnabled = isValid
)
}
fun onRegisterClick() {
println("Rejestracja użytkownika: ${state.username}")
}
}
// Widok (Colleagues)
@Composable
fun RegistrationScreen(viewModel: RegistrationViewModel) {
val state = viewModel.state
Column {
// Komponent A: Pole tekstowe
TextField(
value = state.username,
onValueChange = { viewModel.onUsernameChange(it) },
label = { Text("Nazwa użytkownika") }
)
// Komponent B: Przycisk (zależy od A, ale pośrednio)
Button(
onClick = { viewModel.onRegisterClick() },
enabled = state.isButtonEnabled // Decyzja Mediatora
) {
Text("Zarejestruj")
}
}
}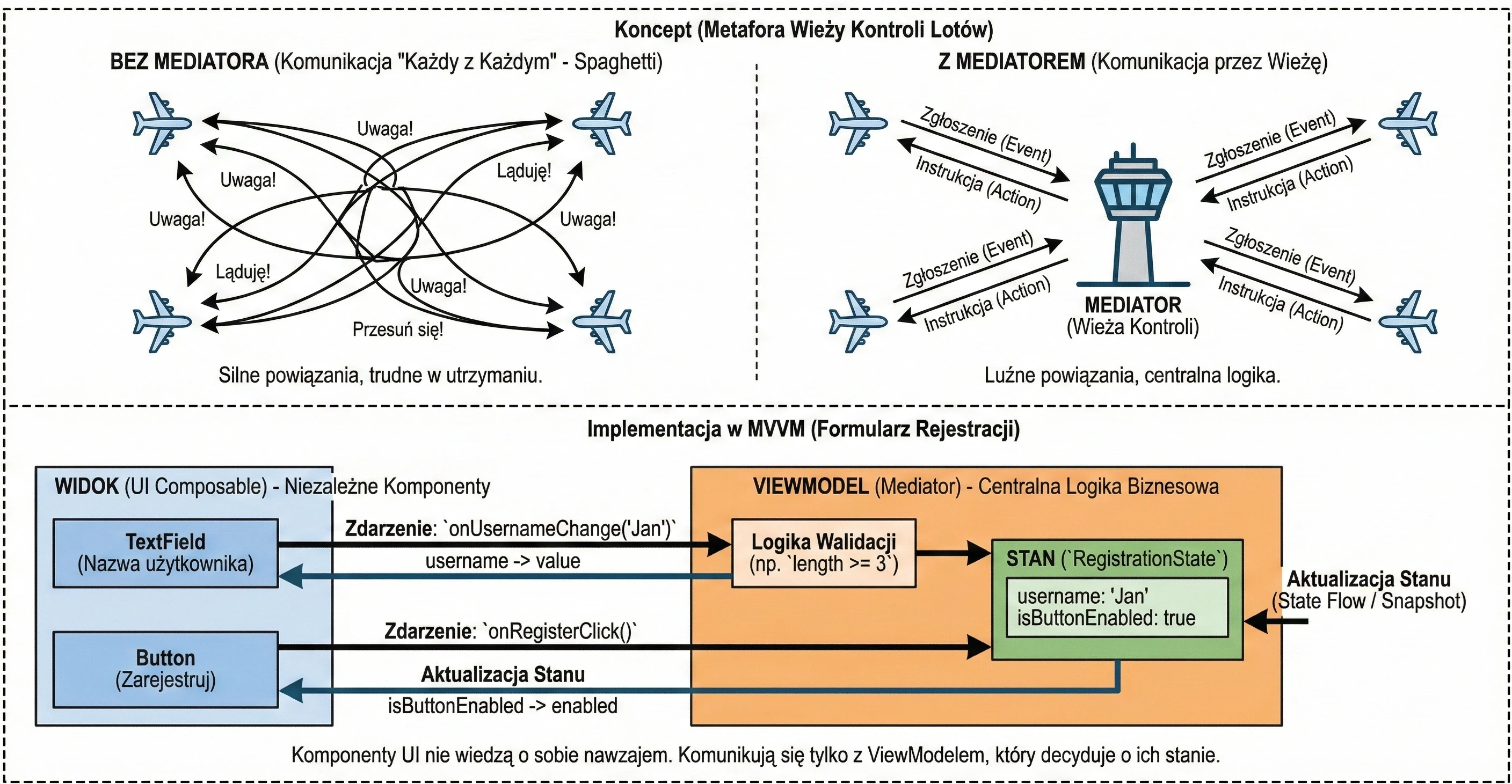
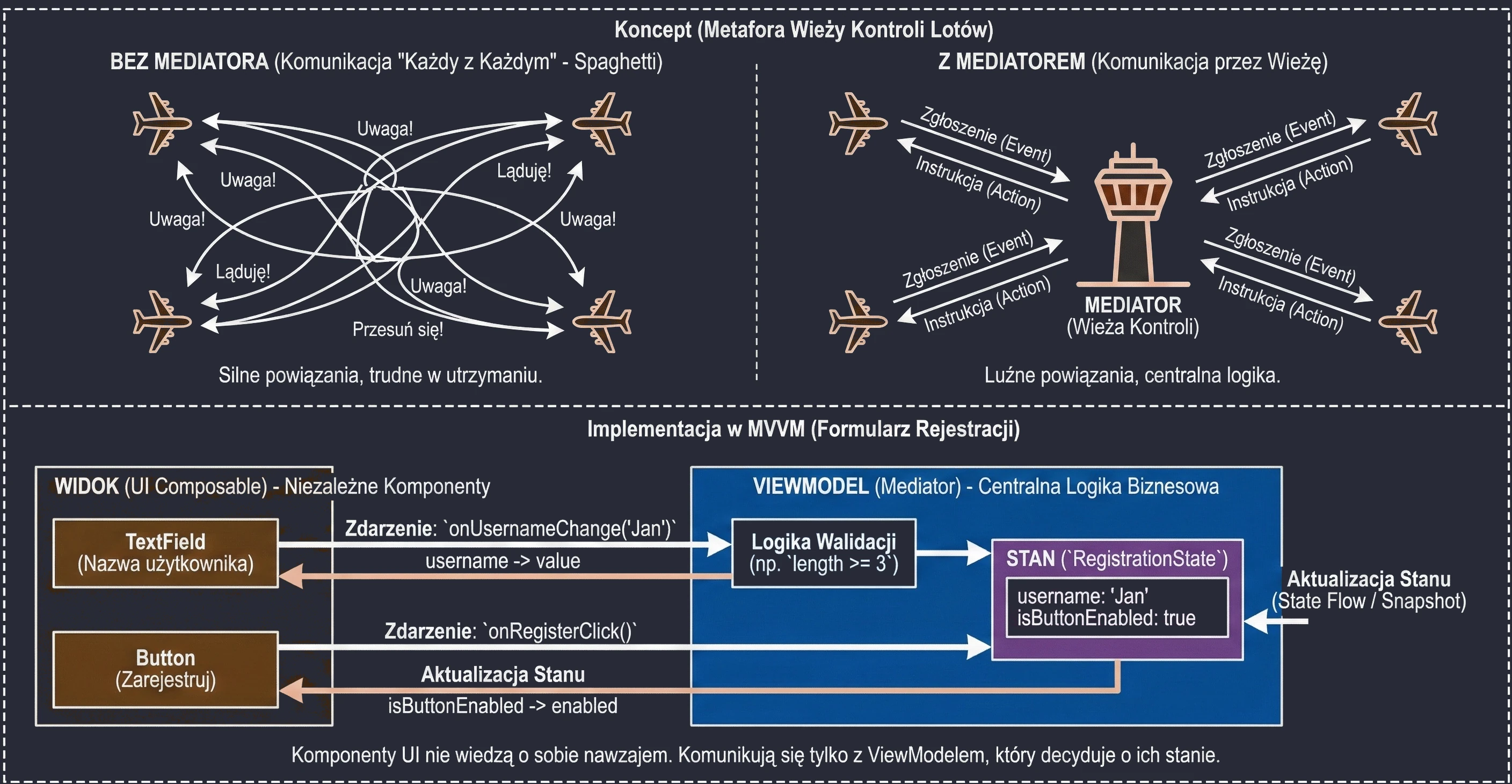
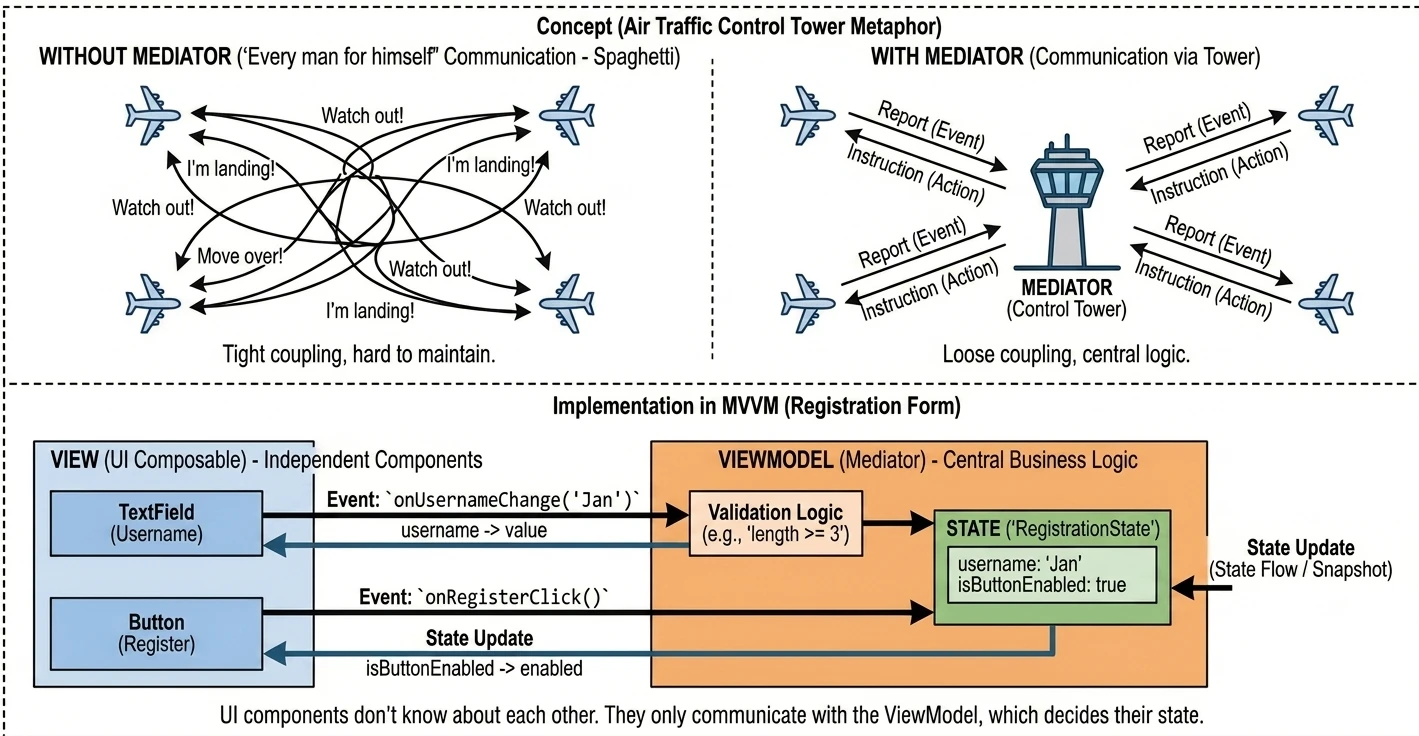
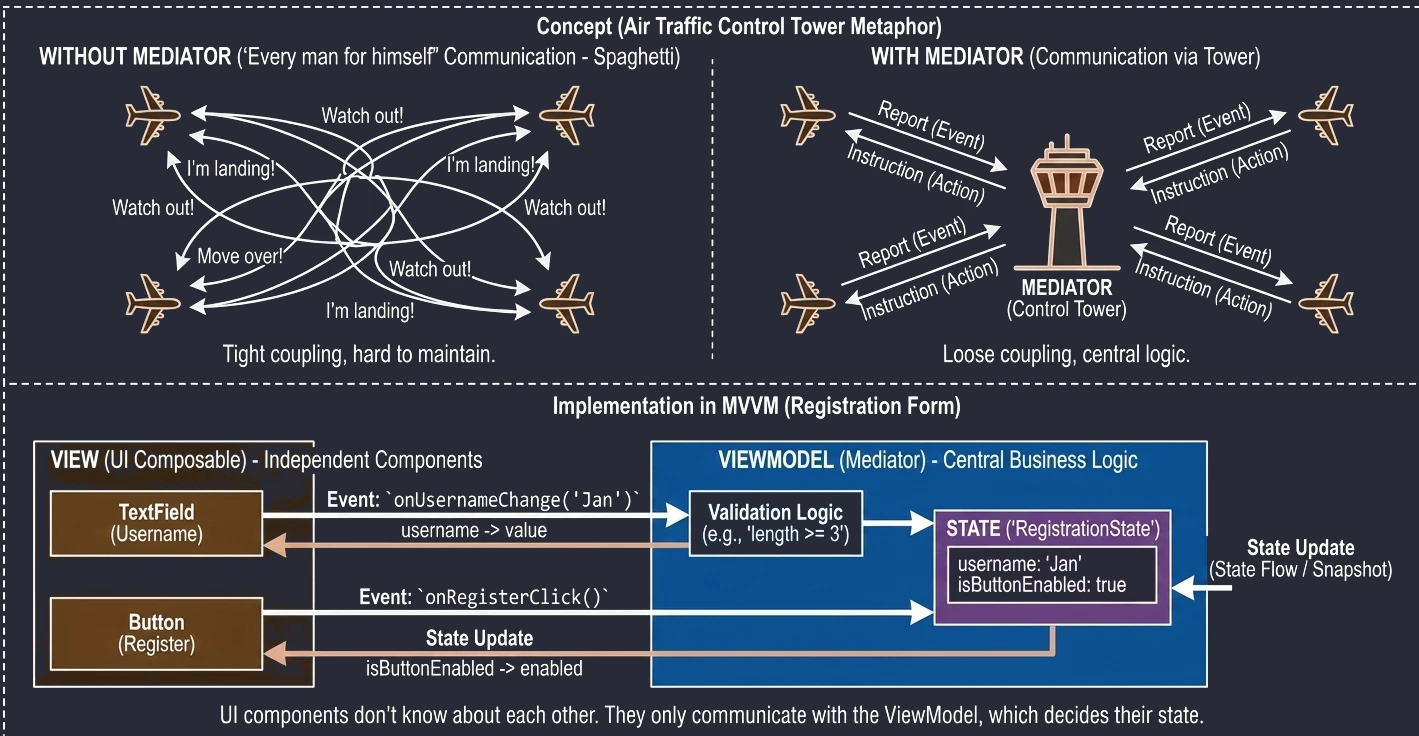
Możemy spotkać się z architekturą hybrydową tworząc aplikację na Androida. Nie chodzi tu o aplikacje webowe (Flutter/React Native), ale o łączenie Jetpack Compose z klasycznymi, starszymi komponentami systemu Android, takimi jak AppWidgets (widżety ekranowe).
Widżety w Androidzie (te na ekranie głównym) wciąż opierają się na technologii RemoteViews i XML. Biblioteka dostępna w Compose jest w tej chwili na wczesnym etapie rozwoju (Jetpack Glance - omówiony w dalszej części rozdziału). Dlatego musimy umieć komunikować te dwa światy.
Architektura Aplikacji Hybrydowej
Załóżmy, że tworzymy prosty licznik (Counter). Chcemy, aby:
- Aplikacja (Activity) była napisana w Jetpack Compose.
- Widżet na ekranie głównym był klasycznym AppWidgetem.
- Stan licznika był wspólny – zmiana w aplikacji aktualizuje widżet i odwrotnie.
Aby to osiągnąć, potrzebujemy Wspólnego Źródła Prawdy (Single Source of Truth). W tym prostym przypadku idealnie sprawdzą się SharedPreferences.
SharedPreferences
SharedPreferences to mechanizm do przechowywania prostych danych w formacie klucz-wartość (plik XML). Teraz omówimy jego podstawowe cechy i użycie, w następnym semestrze poznamy bardziej zaawansowane techniki.
- Obsługuje typy proste:
boolean,float,int,long,String,Set<String>. - Działa synchronicznie (odczyt/zapis blokuje wątek, chyba że użyjemy
apply()). - Pozwala nasłuchiwać zmian za pomocą
OnSharedPreferenceChangeListener.
// Pobranie instancji
val prefs = context.getSharedPreferences("AppPrefs", Context.MODE_PRIVATE)
// Zapis (Edycja -> Put -> Apply)
prefs.edit()
.putInt("count", 5)
.apply() // Asynchroniczny zapis
// Odczyt
val count = prefs.getInt("count", 0) // 0 to wartość domyślnaIntegracja z Jetpack Compose
Compose działa reaktywnie – odświeża się, gdy zmienia się State. SharedPreferences nie są State, więc musimy stworzyć most. Posłuży nam do tego DisposableEffect.
Czym jest Efekt Uboczny (Side Effect)?
Funkcje @Composable z założenia powinny być czyste i deterministyczne, co oznacza, że dla tych samych danych wejściowych zawsze generują ten sam wygląd UI, nie zmieniając niczego w otoczeniu.
Wszelkie operacje wykraczające poza ten schemat – np. komunikacja z bazą danych, uruchomienie timera, odtworzenie dźwięku czy rejestracja listenera – nazywamy efektami ubocznymi. Gdybyśmy umieścili taki kod bezpośrednio w ciele funkcji, wykonywałby się on przy każdym odświeżeniu ekranu (rekompozycji), co prowadziłoby do błędów i wycieków pamięci.
DisposableEffect
Jest to bezpieczny mechanizm obsługi efektu ubocznego, który pozwala wykonać kod przy wejściu komponentu do drzewa kompozycji i (co kluczowe) posprzątać po sobie przy wyjściu. Idealne do rejestrowania i wyrejestrowywania listenerów.
@Composable
fun CounterScreen(context: Context) {
// 1. Stan w Compose
var count by remember { mutableStateOf(0) }
val prefs = context.getSharedPreferences("AppPrefs", Context.MODE_PRIVATE)
// 2. Efekt uboczny: Nasłuchiwanie zmian w SharedPreferences
DisposableEffect(Unit) {
val listener = SharedPreferences.OnSharedPreferenceChangeListener { sharedPreferences, key ->
if (key == "count") {
// Gdy zmieni się plik, aktualizujemy stan Compose
count = sharedPreferences.getInt("count", 0)
}
}
// Rejestracja listenera (onStart)
prefs.registerOnSharedPreferenceChangeListener(listener)
// Inicjalny odczyt
count = prefs.getInt("count", 0)
// Czyszczenie (onStop/onDispose)
onDispose {
prefs.unregisterOnSharedPreferenceChangeListener(listener)
}
}
// 3. UI
Text(text = "Licznik: $count")
}Dzięki temu, gdy zewnętrzny proces (np. Widżet) zmieni wartość w SharedPreferences, nasz ekran w Compose automatycznie się odświeży!
App Widgets (Widżety Ekranowe)
Widżety działają w procesie Systemu (Launchera), a nie naszej aplikacji. Dlatego mają bardzo ograniczone możliwości UI (tylko podstawowe widoki jak TextView, Button, ImageView).
Ponieważ widżet żyje na ekranie innej aplikacji (Launchera), nie mamy bezpośredniego dostępu do jego widoków. Nie możemy napisać findViewById ani composeView.setContent. Zamiast tego musimy przygotować paczkę z opisem wyglądu (RemoteViews) i wysłać ją do systemu (AppWidgetManager).
Aby wiedzieć, kiedy taką paczkę wysłać (np. gdy użytkownik dodał widżet na ekran), potrzebujemy mechanizmu powiadomień - tą rolę pełni AppWidgetProvider.
BroadcastReceiver i AppWidgetProvider
BroadcastReceiver to jeden z czterech głównych komponentów Androida (obok Activity, Service i ContentProvider). Służy do odbierania komunikatów (intencji) wysyłanych przez system lub inne aplikacje (np. "Bateria słaba", "Włączono Wi-Fi"). Działa w tle, ale bardzo krótko – tylko tyle, by obsłużyć zdarzenie.
AppWidgetProvider to nic innego jak specjalny BroadcastReceiver, który został przygotowany do obsługi cyklu życia widżetu (odbiera intencje takie jak APPWIDGET_UPDATE, APPWIDGET_DELETED itd.).
Uwaga: Mimo że nazwa klasy zawiera słowo Provider, AppWidgetProvider nie jest ContentProviderem. ContentProvider służy do udostępniania danych innym aplikacjom (np. baza kontaktów), podczas gdy AppWidgetProvider służy do odbierania zdarzeń systemowych (Broadcastów).
class CounterWidget : AppWidgetProvider() {
// Wywoływane, gdy trzeba odświeżyć widżet (np. co 30 min lub na żądanie)
override fun onUpdate(context: Context, appWidgetManager: AppWidgetManager, appWidgetIds: IntArray) {
for (appWidgetId in appWidgetIds) {
updateAppWidget(context, appWidgetManager, appWidgetId)
}
}
}
fun updateAppWidget(context: Context, appWidgetManager: AppWidgetManager, appWidgetId: Int) {
val prefs = context.getSharedPreferences("AppPrefs", Context.MODE_PRIVATE)
val count = prefs.getInt("count", 0)
// Budowanie widoku dla innego procesu (RemoteViews)
val views = RemoteViews(context.packageName, R.layout.widget_counter)
views.setTextViewText(R.id.widget_text, count.toString())
// Obsługa kliknięcia (PendingIntent -> BroadcastReceiver)
val intent = Intent(context, CounterReceiver::class.java).apply {
action = "INCREMENT"
}
// PendingIntent pozwala innej aplikacji (Launcherowi) uruchomić nasz Intent
val pendingIntent = PendingIntent.getBroadcast(
context, 0, intent, PendingIntent.FLAG_UPDATE_CURRENT or PendingIntent.FLAG_IMMUTABLE
)
views.setOnClickPendingIntent(R.id.widget_button_plus, pendingIntent)
// Wysłanie widoku do menedżera
appWidgetManager.updateAppWidget(appWidgetId, views)
}PendingIntent to token, który przekazujemy innej aplikacji (np. Launcherowi), pozwalając jej wykonać akcję w naszym imieniu, nawet gdy nasza aplikacja jest zabita.
W powyższym przykładzie, kliknięcie przycisku na widżecie (przez Launchera) wyśle Broadcast do naszej klasy CounterReceiver.
Zamykanie Pętli (CounterReceiver)
Ostatni element układanki. CounterReceiver odbiera sygnał z widżetu, zmienia dane w SharedPreferences i wymusza odświeżenie widżetu.
class CounterReceiver : BroadcastReceiver() {
override fun onReceive(context: Context, intent: Intent) {
if (intent.action == "INCREMENT") {
val prefs = context.getSharedPreferences("AppPrefs", Context.MODE_PRIVATE)
val current = prefs.getInt("count", 0)
// 1. Zapisz nową wartość (to wywoła listener w Compose!)
prefs.edit().putInt("count", current + 1).apply()
// 2. Ręcznie odśwież widżet (bo AppWidgetProvider nie nasłuchuje Prefs automatycznie)
// ... kod pobierający instancję AppWidgetManagera i wołający updateAppWidget ...
}
}
}Podsumowanie Przepływu
- Użytkownik klika "+" na Widżecie.
- Launcher używa
PendingIntent-> wysyła BroadcastINCREMENT. CounterReceiverodbiera Broadcast -> Zwiększa licznik wSharedPreferences.SharedPreferencespowiadamia listenerów.DisposableEffectw Compose odbiera zmianę -> Aktualizuje UI aplikacji.CounterReceiverwymusza odświeżenie Widżetu -> Aktualizuje UI widżetu.
To przykład architektury zdarzeniowej, gdzie różne, niezależne komponenty komunikują się przez wspólny stan.
Jetpack Glance
Tradycyjne podejście z RemoteViews jest uciążliwe – wymaga XML, ma ograniczone API i inną składnię niż reszta aplikacji pisanej w Compose. Odpowiedzią Google na ten problem jest biblioteka Jetpack Glance.
Glance to framework, który pozwala budować interfejs widżetów (oraz kafelków na Wear OS) przy użyciu składni znanej z Jetpack Compose.
Uwaga: Pod spodem Glance nadal generuje RemoteViews. To tylko nakładka (kompilator), która tłumaczy kod Compose na instrukcje zrozumiałe dla procesu systemowego. Dzięki temu mamy zalety Compose (deklaratywność, stan) przy zachowaniu kompatybilności z mechanizmem widżetów.
Przykład: Licznik w Glance
Zwróć uwagę, jak bardzo kod przypomina zwykłą aplikację Compose. Nie ma tu XML ani RemoteViews.
class CounterGlanceWidget : GlanceAppWidget() {
// Definicja stanu (używamy Preferences z DataStore lub file-based)
override val stateDefinition = PreferencesGlanceStateDefinition
@Composable
override fun Content() {
// Odczyt stanu (podobne do collectAsState)
val prefs = currentState<Preferences>()
val count = prefs[intPreferencesKey("count")] ?: 0
Column(
modifier = GlanceModifier
.fillMaxSize()
.background(Color.White),
horizontalAlignment = Alignment.Horizontal.CenterHorizontally,
verticalAlignment = Alignment.Vertical.CenterVertically
) {
Text(
text = "Licznik: $count",
style = TextStyle(fontSize = 20.sp)
)
Button(
text = "Zwiększ",
onClick = actionRunCallback<IncrementActionCallback>()
)
}
}
}
// Obsługa akcji (zamiast BroadcastReceivera)
class IncrementActionCallback : ActionCallback {
override suspend fun onAction(
context: Context,
glanceId: GlanceId,
parameters: ActionParameters
) {
updateAppWidgetState(context, glanceId) { prefs ->
val current = prefs[intPreferencesKey("count")] ?: 0
prefs[intPreferencesKey("count")] = current + 1
}
CounterGlanceWidget().update(context, glanceId)
}
}Kluczowe różnice
- Modifier: Używamy
GlanceModifiera nie zwykłegoModifier. - Akcje: Zamiast
PendingIntent, mamy bezpieczniejsze typowane callbacki (actionRunCallback). - Komponenty: To nie są te same komponenty co w
androidx.compose.material. To specjalne wersje (androidx.glance.text.Text,androidx.glance.Button) dostosowane do ograniczeńRemoteViews.
Glance to przyszłość tworzenia widżetów, eliminująca większość boilerplate code związanego z AppWidgetProvider.