Manuskrypt HTML
W01 - Organizacja kursu i nawigacja Compose
Podstawowe informacje o kursie
Organizacja kursu
Zajęcia obejmują łącznie 75 godzin pracy studenta, z czego 15 godzin przeznaczonych jest na wykłady (45 minutowy wykład na tydzień), a 30 godzin na zajęcia laboratoryjne. Dodatkowo przewidziano 30 godzin pracy własnej studenta, niezbędnej do samodzielnego opracowania materiału, przygotowania projektów oraz pogłębiania wiedzy. Kurs kończy się uzyskaniem 3 punktów ECTS.
W trakcie zajęć wykorzystywane są materiały dydaktyczne dostępne pod adresem: https://github.com/RafLew84/ProgUM. Obowiązkowa i zalecana literatura:
- Dokumentacja języka Kotlin (https://kotlinlang.org/docs/home.html
- oficjalne kursy programowania aplikacji mobilnych dostępne na platformie Android Developers (https://developer.android.com/courses).
)
Zasady zaliczenia
- Warunkiem zaliczenia laboratorium jest uzyskanie oceny pozytywnej z list zadań.
- Na zajęcia przewidzianych jest 6 list zadań.
- Z każdej listy wystawiana jest osobna ocena.
- Nie jest konieczne zaliczenie wszystkich list aby otrzymać ocenę pozytywną z laboratorium. Dopuszczalne jest nieoddanie/niezaliczenie jednej listy - za tą listę otrzymuje się ocenę 2,0.
- Każda lista posiada informację o liczbie punktów wymaganych na konkretną ocenę
- Każda lista posiada termin zwrotu.
- Za każdy tydzień opóźnienia otrzymana ocena jest obniżana o 1,0.
- Listy oddawane są podczas zajęć laboratoryjnych.
- Do każdej listy prowadzący zadaje 4 pytania.
- Liczba punktów za listę jest przyznawana na podstawie poprawności wykonania zadań oraz odpowiedzi ustnej.
- Ocena końcowa jest średnią arytmetyczną ze wszystkich ocen z list.
- Na ocenę 3,0 wymagana jest średnia co najmniej 3,0.
- Na zajęciach laboratoryjnych dopuszczalne są trzy nieobecności nieusprawiedliwione.
Treści Programowe
- Zasady zaliczenia, Treści Programowe, Zaawansowana Nawigacja.
- Wprowadzenie do Wielowątkowości: Coroutines. Wątek główny.
- Coroutines. Współbieżność, Równoległość, Asynchroniczność.
- Podstawy Architektury Aplikacji: Wzorce MVx (MVC, MVP, MVVM).
- Reaktywne Zarządzanie Stanem: Flow, StateFlow, SharedFlow.
- Zaawansowane Zarządzanie Stanem: withContext, StateIn, ShareIn, FlowOn, combine.
- Coroutines: Kanały - Asynchroniczna Wymiana Danych Między Coroutines.
- Zapis Danych do Pliku: SharedPreferences, DataStore.
- Baza Danych SQLite + ROOM: Entity, Dao, Database, CRUD, Operacje Asynchroniczne.
- Praca z Zewnętrznymi Źródłami Danych: Retrofit2, Operacje Asynchroniczne.
- Wstrzykiwanie Zależności: Dagger, Hilt.
- Czysta Architektura - Warstwa Domeny i Wzorzec Use Case.
- Wzorzec Single Source of Truth - Strategia Offline Caching.
- Backend w Chmurze: Wprowadzenie do Firebase i Firestore
Android Studio - Rozpoczęcie i konfiguracja projektu - Przypomnienie
Podczas zajęć tworzymy projekty w Android Studio, w Kotlinie, z interfejsem budowanym w Jetpack Compose (bez widoków XML). Najprościej zacząć od kreatora: New Project -> Empty Activity. Ustaw Language: Kotlin, Minimum SDK: 28+ i zaakceptuj ustawienia. Taki szablon tworzy gotowy projekt z poprawną konfiguracją Compose i przykładowym setContent { … }.
UWAGA!!! Nie używaj Empty Views Activity - to rozpoczyna projekt oparty o widoki, gdzie ui definiujemy jako pliki XML.
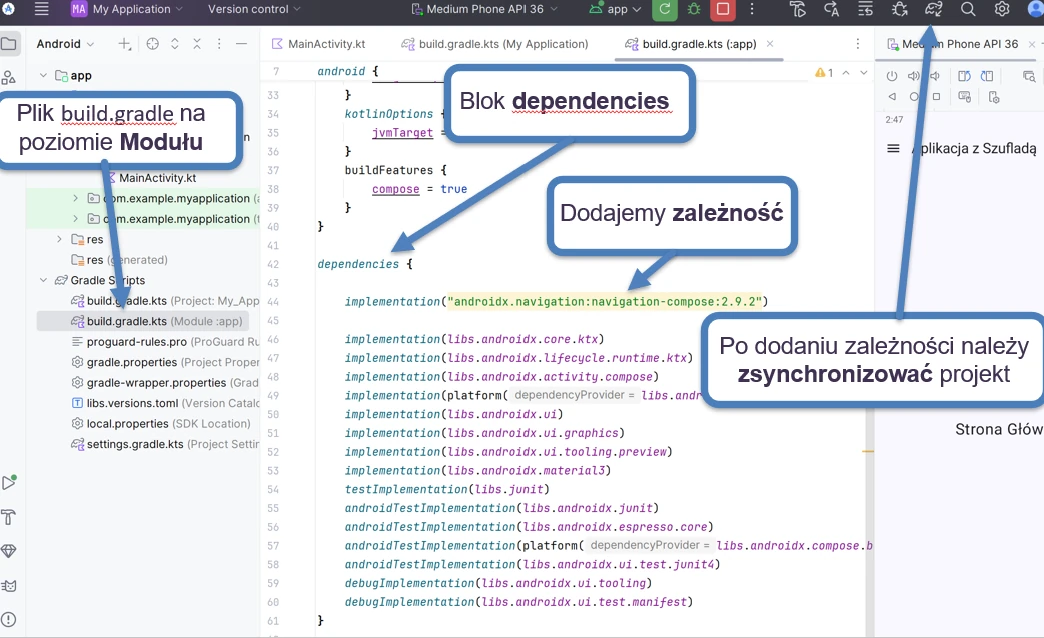
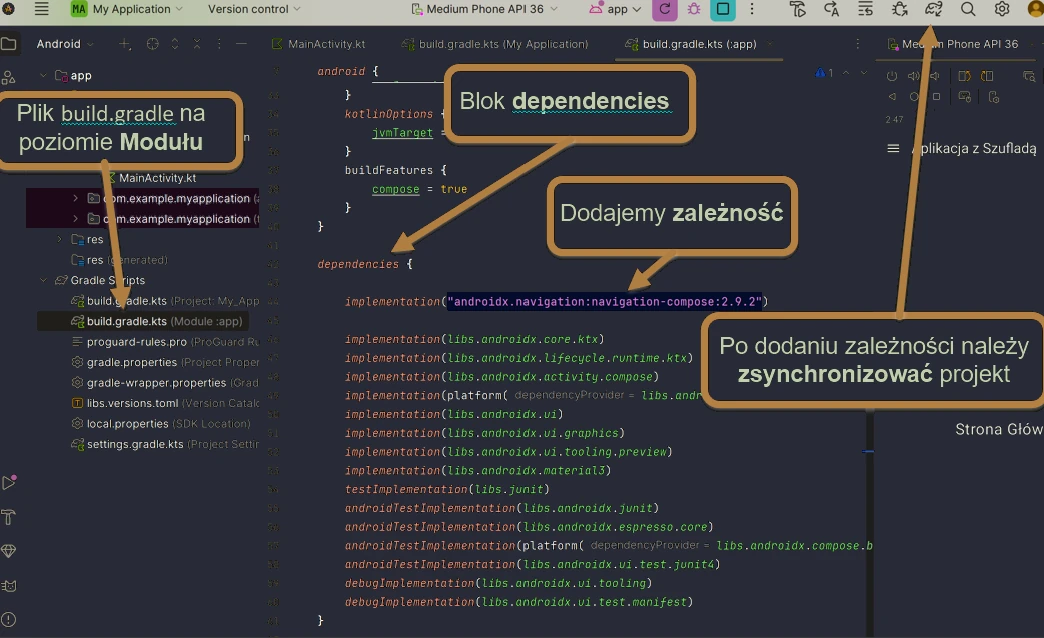
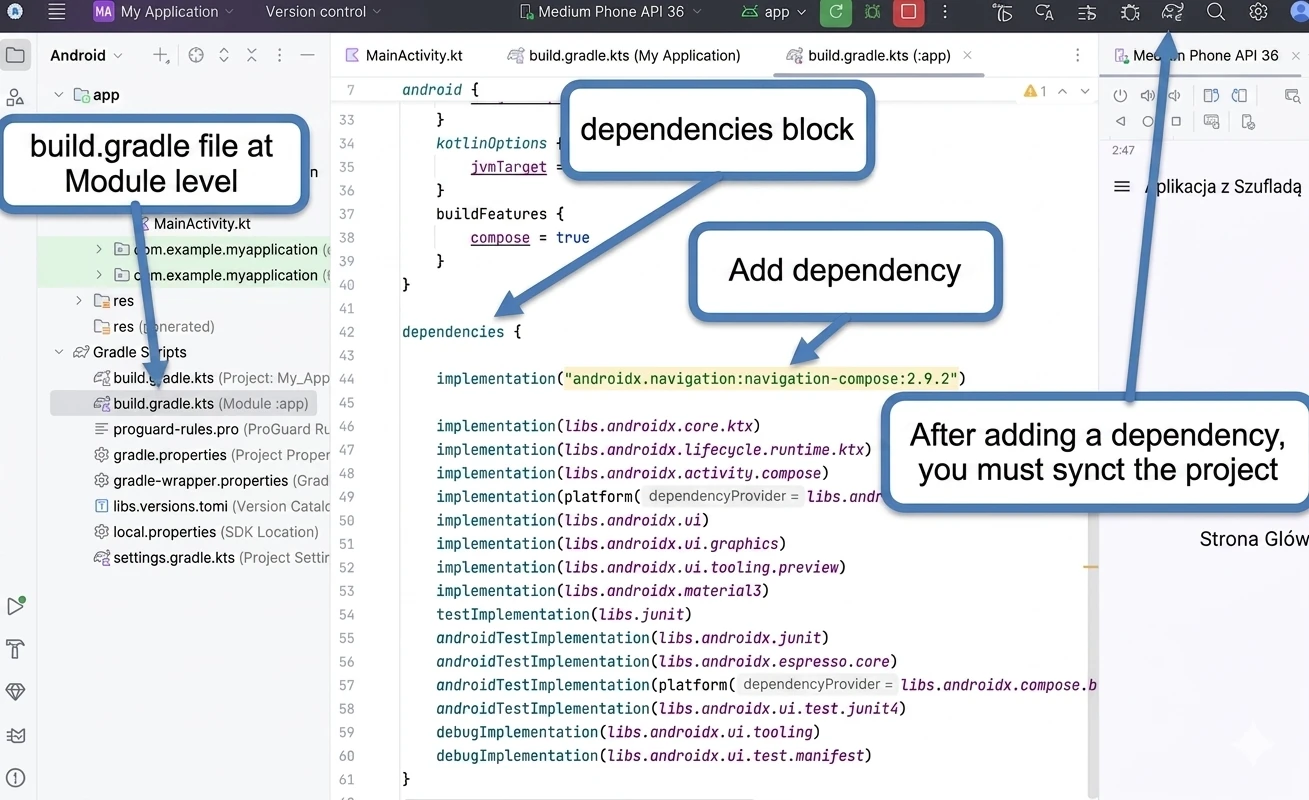
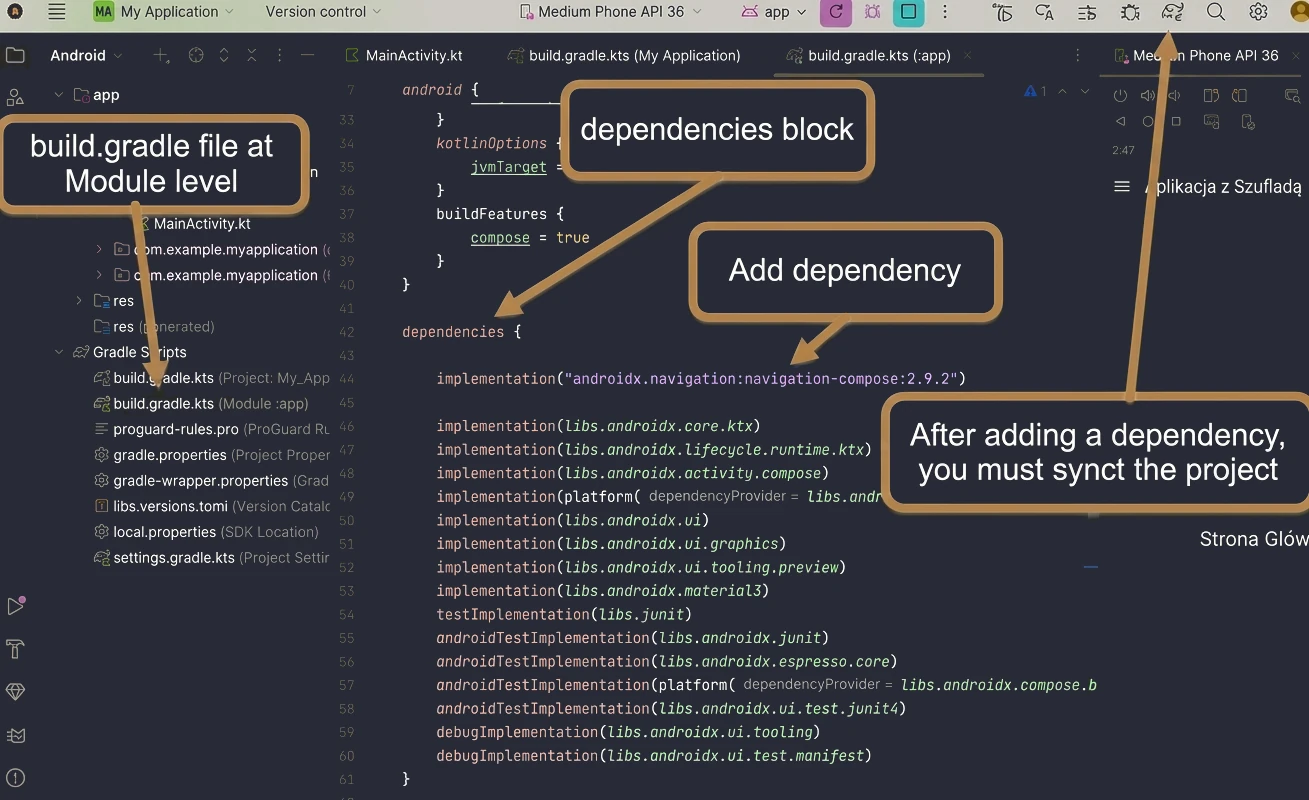
Dodawanie zależności
Wszystkie zależności dopisujemy w bloku dependencies { … } pliku build.gradle(.kts)(Module:App). Przykładowy plik:
UWAGA!!!! NIE KOPIUJ PLIKÓW KONFIGURACYJNYCH - zawierają informacje UNIKALNE DLA PROJEKTU !!!!
plugins {
alias(libs.plugins.android.application)
alias(libs.plugins.kotlin.android)
alias(libs.plugins.kotlin.compose)
}
android {
namespace = "com.example.test"
compileSdk = 36
defaultConfig {
applicationId = "com.example.test"
minSdk = 28
targetSdk = 36
versionCode = 1
versionName = "1.0"
testInstrumentationRunner = "androidx.test.runner.AndroidJUnitRunner"
}
buildTypes {
release {
isMinifyEnabled = false
proguardFiles(
getDefaultProguardFile("proguard-android-optimize.txt"),
"proguard-rules.pro"
)
}
}
compileOptions {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
kotlinOptions {
jvmTarget = "11"
}
buildFeatures {
compose = true
}
}
dependencies {
// tutaj dodajemy zależności
implementation(libs.androidx.core.ktx)
implementation(libs.androidx.lifecycle.runtime.ktx)
implementation(libs.androidx.activity.compose)
implementation(platform(libs.androidx.compose.bom))
implementation(libs.androidx.ui)
implementation(libs.androidx.ui.graphics)
implementation(libs.androidx.ui.tooling.preview)
implementation(libs.androidx.material3)
testImplementation(libs.junit)
androidTestImplementation(libs.androidx.junit)
androidTestImplementation(libs.androidx.espresso.core)
androidTestImplementation(platform(libs.androidx.compose.bom))
androidTestImplementation(libs.androidx.ui.test.junit4)
debugImplementation(libs.androidx.ui.tooling)
debugImplementation(libs.androidx.ui.test.manifest)
}UWAGA!!! Pamiętaj aby wykonać synchronizację (Rys. 1.1) projektu po jakiejkolwiek zmianie w plikach z katalogu gradle
Szuflada Nawigacyjna
W tej części skupimy się na praktycznej implementacji nawigacji w aplikacji Jetpack Compose. Zakładając, znajomość podstawowych bloków konstrukcyjnych: NavHost i NavController, przyjrzymy się, jak zintegrować je z zaawansowanymi komponentami Material 3, takimi jak szuflada nawigacyjna.
Przeanalizujmy kod, który implementuje jeden z najczęstszych wzorców nawigacyjnych w aplikacjach mobilnych: szufladę nawigacyjną (znaną również jako hamburger menu)(Rys. 1.2).
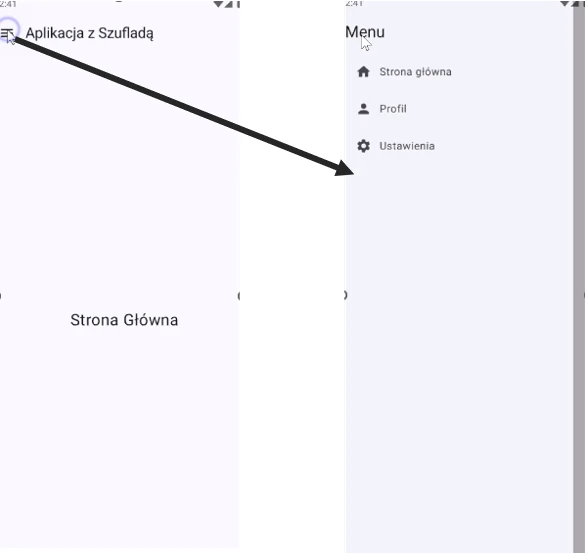
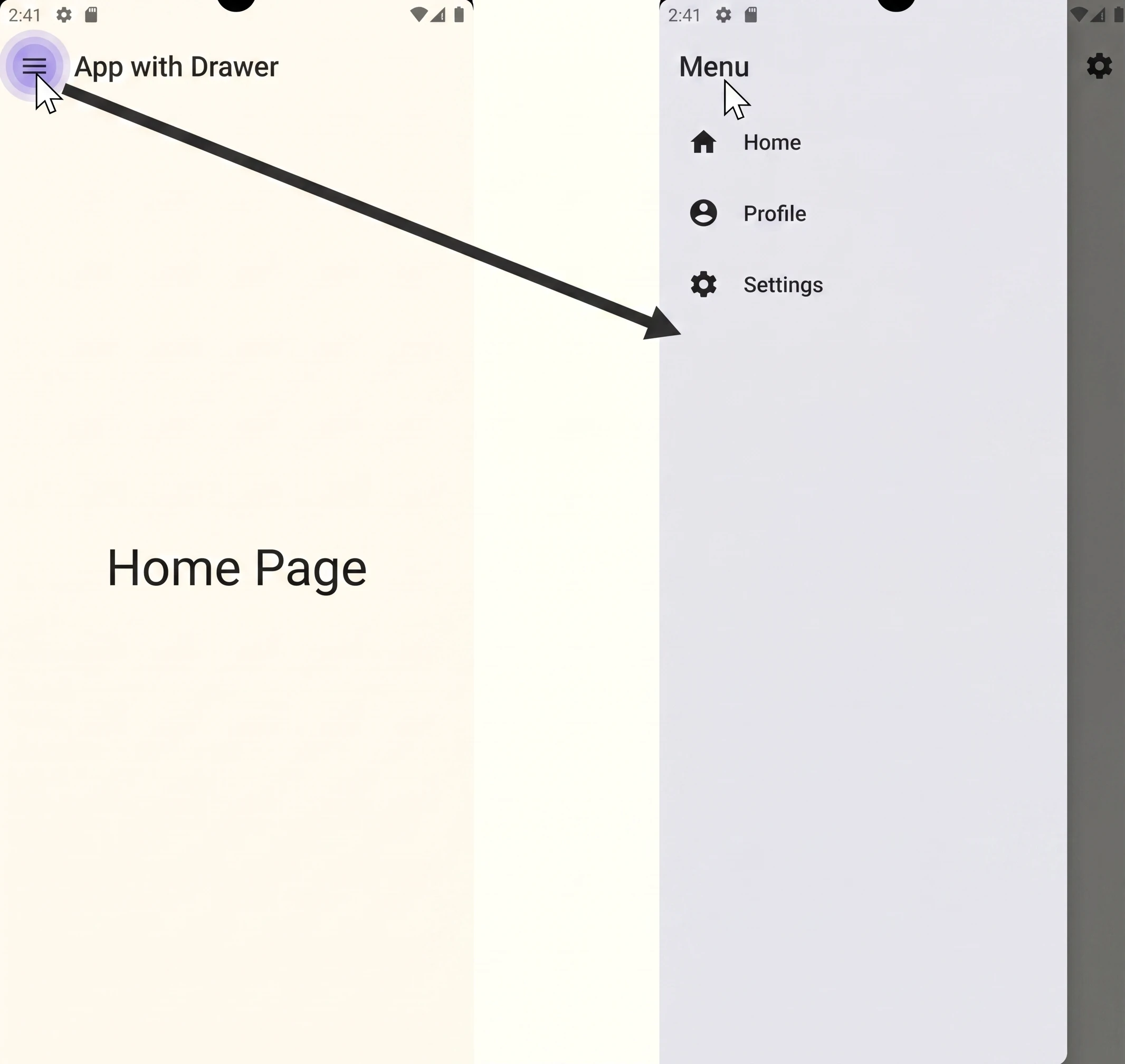
Załączony kod to kompletna, choć minimalistyczna, aplikacja demonstrująca łączenie komponentów Jetpack Navigation, Scaffold oraz ModalNavigationDrawer. Przyjrzyjmy się jej kluczowym elementom krok po kroku.
Aby móc pracować z compose navigation musimy dodać odpowiednią zależność do projektu
dependencies {
implementation("androidx.navigation:navigation-compose:2.9.2")
}Pierwszym elementem jest centralizacja tras nawigacyjnych w obiekcie data object AppDestinations.
data object AppDestinations {
const val HOME = "home"
const val PROFILE = "profile"
const val SETTINGS = "settings"
}Centralizacja zapewnia bezpieczeństwo typów, ułatwia refaktoryzację (zmieniamy nazwę w jednym miejscu).
W aplikacji zagnieżdżamy kilku komponentów . Hierarchia wygląda następująco:
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun MainApp() {
val navController = rememberNavController()
val drawerState = rememberDrawerState(initialValue = DrawerValue.Closed)
val scope = rememberCoroutineScope()
ModalNavigationDrawer(
drawerState = drawerState,
drawerContent = {
DrawerContent(navController = navController, drawerState = drawerState)
}
) {
Scaffold(
topBar = {
TopAppBar(
title = { Text("Aplikacja z Szufladą") },
navigationIcon = {
IconButton(onClick = {
scope.launch { drawerState.apply { if (isClosed) open() else close() } }
}) { Icon(Icons.Filled.Menu, contentDescription = "Menu") }
}
)
}
) { paddingValues ->
NavHost(
navController = navController,
startDestination = AppDestinations.HOME,
modifier = Modifier.padding(paddingValues)
) {
composable(AppDestinations.HOME) { HomeScreen() }
composable(AppDestinations.PROFILE) { ProfileScreen() }
composable(AppDestinations.SETTINGS) { SettingsScreen() }
}
}
}
}ModalNavigationDrawer: Jest to komponent najwyższego poziomu, który zarządza logiką pokazywania i ukrywania wysuwanej szuflady. Przyjmuje on dwa kluczowe parametry:drawerState: Stan szuflady (otwarta/zamknięta).drawerContent: Funkcja kompozycyjna definiująca zawartość samej szuflady (DrawerContent).Scaffold: Umieszczony wewnątrzModalNavigationDrawer,Scaffoldzapewnia standardową strukturę ekranu. W naszym przypadku używamy go do zdefiniowaniatopBar(górnego paska aplikacji).NavHost: Na końcu, wewnątrzScaffold, umieszczamy naszNavHost. To on zarządza faktyczną podmianą treści ekranu (HomeScreen, ProfileScreenitd.). Zwróćmy uwagę na kluczowe powiązanie:modifier = Modifier.padding(paddingValues). Przekazujemy tu wypełnienie (paddingValues) otrzymane zeScaffold, co zapewnia, że nasza treść nie zostanie przysłonięta przezTopAppBar.
W funkcji MainApp zauważymy trzy kluczowe zmienne stanu.
val navController = rememberNavController()
val drawerState = rememberDrawerState(initialValue = DrawerValue.Closed)
val scope = rememberCoroutineScope()Pierwsze dwie są oczywiste: jedna zarządza stosem nawigacji, druga stanem szuflady. Ale dlaczego potrzebujemy scope?
Odpowiedź leży w naturze drawerState. Metody drawerState.open() i drawerState.close() są funkcjami zawieszającymi (suspend functions) - więcej o tych funkcjach w kolejnych rozdziałach. Nie można ich po prostu wywołać z dowolnego miejsca - muszą być uruchomione wewnątrz korutyny. Zmiana drawerState automatycznie spowoduje rekompozycję i wizualne otwarcie szuflady.
{scope.launch { drawerState.apply { if (isClosed) open() else close() } }})Przejdźmy do zarządzania nawigację z wnętrza szuflady. W funkcji MainApp dodaliśmy ModalNavigationDrawer, który posiada parametr drawerContent - jako ten parametr przekazujemy funkcję DrawerContent, zajrzyjmmy do jej wnętrza:
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun DrawerContent(navController: NavController, drawerState: DrawerState) {
val scope = rememberCoroutineScope()
ModalDrawerSheet {
Column(modifier = Modifier.padding(16.dp)) {
Text("Menu", style = MaterialTheme.typography.headlineSmall)
Spacer(modifier = Modifier.height(16.dp))
NavigationDrawerItem(
icon = { Icon(Icons.Default.Home, contentDescription = "Strona główna") },
label = { Text("Strona główna") },
selected = false,
onClick = {
navController.navigate(AppDestinations.HOME)
scope.launch { drawerState.close() }
}
)
NavigationDrawerItem(
icon = { Icon(Icons.Default.Person, contentDescription = "Profil") },
label = { Text("Profil") },
selected = false,
onClick = {
navController.navigate(AppDestinations.PROFILE)
scope.launch { drawerState.close() }
}
)
NavigationDrawerItem(
icon = { Icon(Icons.Default.Settings, contentDescription = "Ustawienia") },
label = { Text("Ustawienia") },
selected = false,
onClick = {
navController.navigate(AppDestinations.SETTINGS)
scope.launch { drawerState.close() }
}
)
}
}
}Wewnątrz ModalDrawerSheet definiujemy elementy będące wyświetlane w szufladzie jako NavigationDrawerItem. Jest to element zaprojektowany według tego samego wzorca (slot-based-layouts). Posiada zdefiniowane sloty w które można wstawić elementy (icon, label, divider), upraszczając tworzenie całego layoutu. Po kliknięciu elementu w szufladzie wykonujemy dwie akcje:
- Nawigujemy: Wywołujemy
navController.navigate(), aby zmienić zawartośćNavHost. - Zamykamy szufladę: Uruchamiamy korutynę (
scope.launch), aby wywołaćdrawerState.close().
Jak widzimy, nawigacja w Jetpack Compose to znacznie więcej niż tylko wywoływanie navController.navigate(). To przemyślana integracja kontrolera nawigacji z innymi komponentami interfejsu, takimi jak ModalNavigationDrawer. Istotnym elementem jest zrozumienie, jak zarządzać wieloma stanami (navController, drawerState) oraz jak obsługiwać asynchroniczne wywołania (funkcje suspend do otwierania/zamykania szuflady) za pomocą odpowiednich narzędzi, takich jak rememberCoroutineScope.
Na kolejnych wykładach zagłębimy się w korutyny, które są fundamentem działania tego przykładu.
Pełny Kod Przykładu
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
enableEdgeToEdge()
setContent {
MyApplicationTheme {
MainApp()
}
}
}
}
data object AppDestinations {
const val HOME = "home"
const val PROFILE = "profile"
const val SETTINGS = "settings"
}
@Composable
fun HomeScreen() {
Box(
modifier = Modifier.fillMaxSize(),
contentAlignment = Alignment.Center
) {
Text("Strona Główna", fontSize = 24.sp)
}
}
@Composable
fun ProfileScreen() {
Box(
modifier = Modifier.fillMaxSize(),
contentAlignment = Alignment.Center
) {
Text("Profil Użytkownika", fontSize = 24.sp)
}
}
@Composable
fun SettingsScreen() {
Box(
modifier = Modifier.fillMaxSize(),
contentAlignment = Alignment.Center
) {
Text("Ustawienia", fontSize = 24.sp)
}
}
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun MainApp() {
val navController = rememberNavController()
val drawerState = rememberDrawerState(initialValue = DrawerValue.Closed)
val scope = rememberCoroutineScope()
ModalNavigationDrawer(
drawerState = drawerState,
drawerContent = {
DrawerContent(navController = navController, drawerState = drawerState)
}
) {
Scaffold(
topBar = {
TopAppBar(
title = { Text("Aplikacja z Szufladą") },
navigationIcon = {
IconButton(onClick = {
scope.launch { drawerState.apply { if (isClosed) open() else close() } }
}) { Icon(Icons.Filled.Menu, contentDescription = "Menu") }
}
)
}
) { paddingValues ->
NavHost(
navController = navController,
startDestination = AppDestinations.HOME,
modifier = Modifier.padding(paddingValues)
) {
composable(AppDestinations.HOME) { HomeScreen() }
composable(AppDestinations.PROFILE) { ProfileScreen() }
composable(AppDestinations.SETTINGS) { SettingsScreen() }
}
}
}
}
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun DrawerContent(navController: NavController, drawerState: DrawerState) {
val scope = rememberCoroutineScope()
ModalDrawerSheet {
Column(modifier = Modifier.padding(16.dp)) {
Text("Menu", style = MaterialTheme.typography.headlineSmall)
Spacer(modifier = Modifier.height(16.dp))
NavigationDrawerItem(
icon = { Icon(Icons.Default.Home, contentDescription = "Strona główna") },
label = { Text("Strona główna") },
selected = false,
onClick = {
navController.navigate(AppDestinations.HOME)
scope.launch { drawerState.close() }
}
)
NavigationDrawerItem(
icon = { Icon(Icons.Default.Person, contentDescription = "Profil") },
label = { Text("Profil") },
selected = false,
onClick = {
navController.navigate(AppDestinations.PROFILE)
scope.launch { drawerState.close() }
}
)
NavigationDrawerItem(
icon = { Icon(Icons.Default.Settings, contentDescription = "Ustawienia") },
label = { Text("Ustawienia") },
selected = false,
onClick = {
navController.navigate(AppDestinations.SETTINGS)
scope.launch { drawerState.close() }
}
)
}
}
}Zagnieżdźona Nawigacja
Przejdźmy do drugiego przykładu w którym zapoznamy się z ideą tworzenia zagnieżdżonych grafów nawigacyjnych.
Załóżmy, że nasza aplikacja ma więcej niż trzy proste ekrany. Prawie każda komercyjna aplikacja ma co najmniej dwa odrębne przepływy (flows):
- Przepływ Uwierzytelniania: Logowanie, Rejestracja, Resetowanie Hasła.
- Główny Przepływ Aplikacji: Ekran główny, Profil, Ustawienia, itd.
Problem polega na tym, że te dwa przepływy mają zupełnie inne zasady. Co najważniejsze: gdy użytkownik pomyślnie się zaloguje, powinien przejść do ekranu głównego, a cały przepływ uwierzytelniania powinien zniknąć z historii. Naciśnięcie przycisku Wstecz na ekranie głównym nie powinno cofać do ekranu logowania, lecz zamykać aplikację. Osiągnąć to można za pomocą zagnieżdżonej nawigacji.
Przeanalizujmy prosty przykład pokazujący takie rozwiązanie. Zamiast traktować NavHost jak jeden wielki kontener, traktujemy go jak folder, który może zawierać zarówno pojedyncze pliki (ekrany), jak i inne foldery (zagnieżdżone grafy).
Zamiast używać surowych ciągów znaków (Stringów) bezpośrednio w kodzie, dobrą praktyką jest stworzenie obiektu, który trzyma wszystkie trasy w jednym miejscu:
data object AppDestinations {
// Grafy
const val AUTH_GRAPH = "auth_graph"
const val MAIN_APP_GRAPH = "main_app_graph"
// Ekrany uwierzytelniania
const val LOGIN = "login"
const val REGISTER = "register"
const val FORGOT_PASSWORD = "forgot_password"
// Główne ekrany aplikacji
const val WELCOME = "welcome"
const val PROFILE = "profile"
}Zauważmy, że nasza aplikacja będzie miała dwa główne podgrafy: AUTH_GRAPH i MAIN_APP_GRAPH
Spójrzmy na główny NavHost w SimpleNestedNavApp. Jest on uderzająco prosty:
NavHost(
navController = navController,
startDestination = AppDestinations.AUTH_GRAPH
) {
// Graf uwierzytelniania (logowanie, rejestracja, itp.)
authGraph(navController)
// Główny graf aplikacji po zalogowaniu
mainAppGraph(navController)
}Zauważmy:
startDestinationnie jest ekranem. Jest toAUTH_GRAPH, czyli cały zagnieżdżony graf. Aplikacja uruchamia się, wchodząc do folderu uwierzytelniania.- Wewnątrz
NavHostnie ma ani jednegocomposable()definiującego ekran. Zamiast tego, są tylko dwie funkcje (authGraphimainAppGraph), które definiują całe grupy ekranów.
Główny NavHost nie musi wiedzieć nic o ekranie logowania czy profilu; musi tylko wiedzieć o istnieniu przepływu uwierzytelniania i przepływu głównego.
Gdy aplikacja rośnie, NavHost staje się nieczytelny. Rozwiązaniem jest podział na zagnieżdżone grafy za pomocą funkcji rozszerzających dla NavGraphBuilder:
fun NavGraphBuilder.authGraph(navController: NavController) {
navigation(
startDestination = AppDestinations.LOGIN,
route = AppDestinations.AUTH_GRAPH
) {
composable(AppDestinations.LOGIN) {
LoginScreen(navController) }
composable(AppDestinations.REGISTER) {
RegisterScreen(navController) }
composable(AppDestinations.FORGOT_PASSWORD) {
ForgotPasswordScreen(navController) }
}
}
fun NavGraphBuilder.mainAppGraph(navController: NavController) {
navigation(
startDestination = AppDestinations.WELCOME,
route = AppDestinations.MAIN_APP_GRAPH
) {
composable(AppDestinations.WELCOME) {
WelcomeScreen(navController) }
composable(AppDestinations.PROFILE) {
ProfileScreen(navController) }
}
}Analiza tego bloku jest kluczowa:
fun NavGraphBuilder.authGraph(...): To czysta organizacja kodu. Zamiast zaśmiecaćNavHost, grupujemy logikę w oddzielnej funkcji.navigation(...): To jest właściwy konstruktor zagnieżdżonego grafu.route = AppDestinations.AUTH_GRAPH: Nadajemy całemu folderowi nazwę. Teraz możemy nawigować do niego.startDestination = AppDestinations.LOGIN: Definiujemy, który ekran jest domyślny wewnątrz tego grafu.
Identyczną strukturę ma mainAppGraph, który grupuje ekrany WELCOME i PROFILE.
Mamy dwa oddzielne światy: AUTH_GRAPH i MAIN_APP_GRAPH. Jak przeskoczyć z jednego do drugiego i – co najważniejsze - posprzątać po sobie?
Spójrzmy na funkcję navigateToMainApp(), wywoływaną po pomyślnym logowaniu:
fun NavController.navigateToMainApp() {
this.navigate(AppDestinations.MAIN_APP_GRAPH) {
popUpTo(AppDestinations.AUTH_GRAPH) {
inclusive = true
}
}
}To jest najważniejszy fragment kodu w całym przykładzie. Rozbijmy go na części:
navigate(AppDestinations.MAIN_APP_GRAPH): Mówimy nawiguj do grafu głównego.NavControllerautomatycznie skieruje nas dostartDestinationtego grafu (czyliWELCOME).popUpTo(AppDestinations.AUTH_GRAPH): To jest polecenie sprzątające. Powraca na stosie aż znajdzieAUTH_GRAPHinclusive = true: Po znalezieniu na stosieAUTH_GRAPHjest on również usuwany.
Prześledźmy wykonanie: Użytkownik klika Zaloguj. NavController następnie:
- Znajduje na stosie powrotu graf
AUTH_GRAPH. - Usuwa ze stosu
LOGIN, REGISTER, FORGOT_PASSWORDi samAUTH_GRAPH. - Dodaje na stos
MAIN_APP_GRAPH(z ekranemWELCOME).
Stos powrotu jest czysty. Zawiera tylko MAIN_APP_GRAPH. Jeśli użytkownik naciśnie teraz przycisk Wstecz, nie wróci do ekranu logowania. Opuści aplikację. Osiągnęliśmy dokładnie taki przepływ, jakiego oczekują użytkownicy.
Zagnieżdżona nawigacja to podstawowe narzędzie do organizacji w każdej aplikacji, która ma więcej niż jeden logiczny przepływ. Jak widzieliśmy w kodzie, ten wzorzec zapewnia trzy kluczowe korzyści:
- Organizację: Grupuje powiązane ekrany.
- Modularność: Utrzymuje główny
NavHostczysty i pozwala definiować przepływy w oddzielnych funkcjach. - Kontrolę nad Stosem Powrotu: Umożliwia nawigowanie między całymi przepływami i usuwanie ich z historii jednym poleceniem.
Pełny kod przykładu
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
enableEdgeToEdge()
setContent {
NestedComposeGraphTheme {
SimpleNestedNavApp()
}
}
}
}
data object AppDestinations {
// Grafy
const val AUTH_GRAPH = "auth_graph"
const val MAIN_APP_GRAPH = "main_app_graph"
// Ekrany autentykacji
const val LOGIN = "login"
const val REGISTER = "register"
const val FORGOT_PASSWORD = "forgot_password"
// Główne ekrany aplikacji
const val WELCOME = "welcome"
const val PROFILE = "profile"
}
@Composable
fun SimpleNestedNavApp() {
val navController = rememberNavController()
NavHost(
navController = navController,
startDestination = AppDestinations.AUTH_GRAPH
) {
// Graf autentykacji (logowanie, rejestracja, itp.)
authGraph(navController)
// Główny graf aplikacji po zalogowaniu
mainAppGraph(navController)
}
}
fun NavGraphBuilder.authGraph(navController: NavController) {
navigation(
startDestination = AppDestinations.LOGIN,
route = AppDestinations.AUTH_GRAPH
) {
composable(AppDestinations.LOGIN) {
LoginScreen(navController) }
composable(AppDestinations.REGISTER) {
RegisterScreen(navController) }
composable(AppDestinations.FORGOT_PASSWORD) {
ForgotPasswordScreen(navController) }
}
}
fun NavGraphBuilder.mainAppGraph(navController: NavController) {
navigation(
startDestination = AppDestinations.WELCOME,
route = AppDestinations.MAIN_APP_GRAPH
) {
composable(AppDestinations.WELCOME) {
WelcomeScreen(navController) }
composable(AppDestinations.PROFILE) {
ProfileScreen(navController) }
}
}
@Composable
fun LoginScreen(navController: NavController) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Logowanie", fontSize = 28.sp)
Spacer(Modifier.height(24.dp))
Button(onClick = { navController.navigateToMainApp() }) {
Text("Zaloguj")
}
Spacer(Modifier.height(12.dp))
Button(onClick = { navController.navigate(AppDestinations.REGISTER) }) {
Text("Przejdź do Rejestracji")
}
Spacer(Modifier.height(12.dp))
TextButton(onClick = { navController.navigate(AppDestinations.FORGOT_PASSWORD) }) {
Text("Zapomniałem hasła")
}
}
}
@Composable
fun RegisterScreen(navController: NavController) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Rejestracja", fontSize = 28.sp)
Spacer(Modifier.height(24.dp))
Button(onClick = { navController.navigateToMainApp() }) {
Text("Zarejestruj i zaloguj")
}
Spacer(Modifier.height(12.dp))
TextButton(onClick = { navController.popBackStack() }) {
Text("Wróć do logowania")
}
}
}
@Composable
fun ForgotPasswordScreen(navController: NavController) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Resetowanie Hasła", fontSize = 24.sp, textAlign = TextAlign.Center)
Spacer(Modifier.height(24.dp))
Button(onClick = { navController.popBackStack() }) {
Text("Powrót")
}
}
}
@Composable
fun WelcomeScreen(navController: NavController) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Witaj w Aplikacji! 🎉", fontSize = 28.sp)
Spacer(Modifier.height(24.dp))
Button(onClick = { navController.navigate(AppDestinations.PROFILE) }) {
Text("Zobacz mój profil")
}
}
}
@Composable
fun ProfileScreen(navController: NavController) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Ekran Profilu 🧑💻", fontSize = 28.sp)
Spacer(Modifier.height(24.dp))
Button(onClick = { navController.popBackStack() }) {
Text("Wróć do ekranu powitalnego")
}
}
}
fun NavController.navigateToMainApp() {
this.navigate(AppDestinations.MAIN_APP_GRAPH) {
popUpTo(AppDestinations.AUTH_GRAPH) {
inclusive = true
}
}
}Problem Zamrożonego UI i Piekło Callbacków - Wątek Główny
Zanim zagłębimy się w to, czym są korutyny, musimy zrozumieć, z jakim fundamentalnym problemem musimy mierzyć się od samych początków Androida. Ten problem ma swoje źródło w jednej, kluczowej koncepcji: Wątku Głównym.
Każda aplikacja na Androida, którą uruchamiasz, żyje i umiera w jednym, głównym procesie. Wewnątrz tego procesu istnieje jeden, niezwykle ważny wątek, znany jako Wątek Główny (Main Thread) lub Wątek UI (UI Thread).
Ten wątek jest odpowiedzialny za wszystko, co użytkownik widzi i z czym wchodzi w interakcję:
- Rysowanie interfejsu: Aktualizowanie widoków, wywoływanie funkcji
@Composable. - Obsługa zdarzeń: Reagowanie na kliknięcia, przewijanie, wpisywanie tekstu.
- Animacje: Płynne przesuwanie elementów po ekranie.
Wątek UI to w zasadzie nieskończona pętla zdarzeń, która musi działać z prędkością co najmniej 60 klatek na sekundę (nowsze modele posiadają odświeżanie na poziomie 144 Hz). Jeśli kiedykolwiek przestanie pracować – choćby na ułamek sekundy – użytkownik natychmiast to zauważy. Aplikacja zacina się, laguje. Dla ekranów 60 Hz mamy do dyspozycji około 16 ms na wykonanie wszystkich operacji (włącznie z renderowaniem UI)(Rys. 2.1).
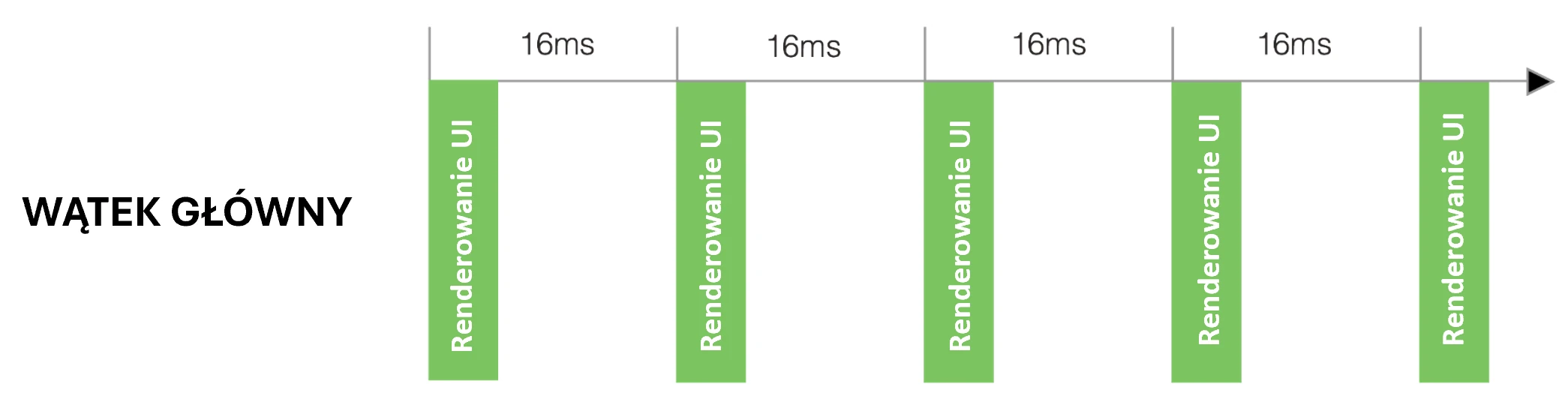
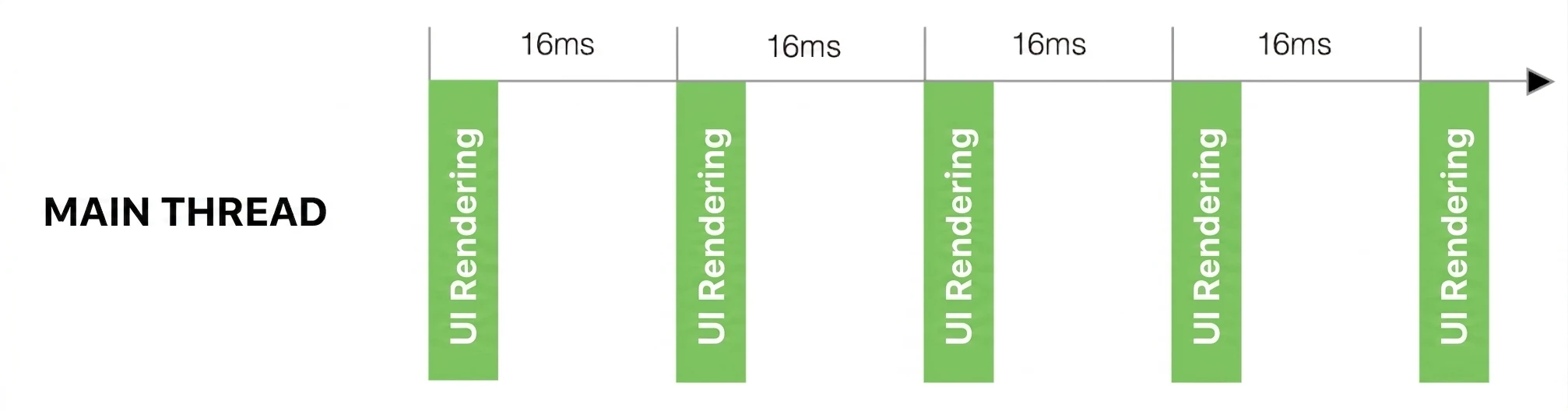
Przeanalizujmy przykład:
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
enableEdgeToEdge()
setContent {
AnrappTheme {
BlockingUiDemoScreen()
}
}
}
}
@Composable
fun BlockingUiDemoScreen() {
var statusText by remember { mutableStateOf("Naciśnij przycisk, aby rozpocząć operację.") }
Column(
modifier = Modifier
.fillMaxSize()
.padding(24.dp).background(Color.Cyan),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = "Demonstracja Blokowania Wątku UI",
)
Spacer(modifier = Modifier.height(50.dp))
Text(
text = statusText,
fontSize = 18.sp,
textAlign = TextAlign.Center,
modifier = Modifier.height(80.dp)
)
Spacer(modifier = Modifier.height(20.dp))
Button(
onClick = {
statusText = "Operacja rozpoczęta..."
try {
Thread.sleep(10000)
} catch (e: InterruptedException) {
}
statusText = "Operacja zakończona!"
},
modifier = Modifier.fillMaxWidth()
) {
Text("Uruchom 10-sekundową operację blokującą")
}
Spacer(modifier = Modifier.height(40.dp))
var sliderPosition by remember { mutableStateOf(0f) }
Slider(
value = sliderPosition,
onValueChange = { sliderPosition = it }
)
}
}Zwróćmy uwagę, że mamy w ui przycisk i suwak. Wewnątrz funkcji onClick przycisku mamy kod:
Button(
onClick = {
statusText = "Operacja rozpoczęta..."
try {
Thread.sleep(10000)
} catch (e: InterruptedException) {
}
statusText = "Operacja zakończona!"
},
modifier = Modifier.fillMaxWidth()
) {
Text("Uruchom 10-sekundową operację blokującą")
}Wywołujemy Thread.sleep(10000), czyli blokujemy wątek UI na 10 sekund. W tym czasie:
- Przycisk nie pokaże animacji kliknięcia.
- Inne animacje na ekranie będą zamrożone.
- Użytkownik, wykonując jakąkolwiek interakcję z ekranem, nie otrzyma żadnej odpowiedzi.
System operacyjny Android szybko zauważa, że nasza aplikacja nie odpowiada na zdarzenia. Po kilku sekundach wyświetla komunikat: Aplikacja nie odpowiada (ANR - Application Not Responding)(Rys. 2.2).


Wszystkie długotrwałe operacje: pobieranie danych z sieci, odczyt z bazy danych, skomplikowane obliczenia – muszą odbywać się w tle.
Przez lata, zanim pojawiły się korutyny, praca w tle oznaczała ręczne zarządzanie wątkami. Jeśli programista chciał pobrać dane z sieci po kliknięciu przycisku, jego plan działania musiał wyglądać tak:
- W
onClick(Wątek UI): Utwórz nowy, ręczny obiektThread. - W metodzie
run()nowego wątku (Wątek Tła): Wykonaj czasochłonną operację sieciową. - Po zakończeniu operacji: Zdobądź wynik (np. dane użytkownika).
- Problem: Nie możesz zaktualizować UI (np.
TextView) z tego Wątku Tła. Spowoduje to awarię aplikacji. - Rozwiązanie: Utwórz obiekt Handler powiązany z Wątkiem UI.
- Użyj
handler.post {... }, aby wysłać wynik z powrotem do Wątku UI, który jako jedyny może bezpiecznie zaktualizować interfejs.
Ten proces był skomplikowany, ale jeszcze gorsze stawało się, gdy operacje były od siebie zależne. Wyobraźmy sobie pobranie danych użytkownika, następnie na ich podstawie pobranie jego zdjęcia, a na końcu zapisanie go w bazie:
button.setOnClickListener(v -> {
// 1. Przechodzimy do tła, by pobrać użytkownika
new Thread(() -> {
User user = api.fetchUser("123");
// 2. Musimy znowu przejść do tła, by pobrać zdjęcie
new Thread(() -> {
ProfilePicture pic = api.fetchPicture(user.getPictureUrl());
// 3. I jeszcze raz do tła, by zapisać w bazie
new Thread(() -> {
database.save(pic);
// 4. Wracamy do Wątku UI, by pokazać sukces
mainThreadHandler.post(() -> {
imageView.setImage(pic);
textView.setText("Gotowe!");
});
}).start();
}).start();
}).start();
});To, co widzimy powyżej, to Piekło Callbacków (Callback Hell). Kod staje się piramidą zagnieżdżonych wywołań. Jest praktycznie nieczytelny, niemożliwy do testowania, a obsługa błędów w każdym z tych kroków staje się koszmarem.
To jest właśnie problem, który doprowadził do rewolucji. Potrzebowaliśmy sposobu na pisanie kodu asynchronicznego, który wyglądałby jak prosty kod synchroniczny; bez callbacków i bez ręcznego zarządzania wątkami.
Korutyny
Wstęp
Po zidentyfikowaniu fundamentalnego problemu blokowania Wątku Głównego, naturalne pytanie brzmi: Jaka jest alternatywa?. Przez lata próbowaliśmy wielu rozwiązań, ale dopiero Kotlin wprowadził model, który zrewolucjonizował programowanie na Androida. Mowa o korutynach.
Aby zrozumieć ich siłę, musimy precyzyjnie zdefiniować, czym są i czym nie są.
Najczęściej spotkasz się z definicją korutyny jako lekkiego wątku (lightweight thread). Jest to użyteczne uproszczenie, pomaga zrozumieć, że korutyny, podobnie jak wątki, wykonują jakąś pracę w tle. Jednak to porównanie jest też mylące, ponieważ pomija ich najważniejszą cechę. UWAGA!!! - Korutyna nie jest wątkiem.
Lepszą, bardziej precyzyjną definicją jest: zawieszalne (suspendable) obliczenie.
Pomyśl o korutynie nie jak o pracowniku, ale jak o zadaniu lub jednostce pracy, którą można w dowolnym momencie wstrzymać (zawiesić) i wznowić w przyszłości, nie blokując przy tym pracownika (wątku), który ją wykonuje.
Kluczowa Różnica: Korutyna kontra Wątek
- Wątek (Thread) jest zarządzany przez System Operacyjny (OS). Jest ciężki, jego utworzenie i utrzymanie zużywa znaczące zasoby systemowe. Przełączanie się między wątkami jest operacją kosztowną dla procesora, ponieważ system musi zapisać stan jednego wątku i wczytać stan drugiego.
- Korutyna (Coroutine) jest zarządzana przez środowisko uruchomieniowe Kotlina. Jest lekka, to w zasadzie tylko obiekt w pamięci, który śledzi stan wykonywanego zadania. Tysiące, a nawet miliony korutyn mogą być uruchomione i zarządzane przez jeden wątek. Przełączanie się między korutynami jest niemal darmowe.
Korutyna nie jest wątkiem. Korutyna wykonuje się na wątku.
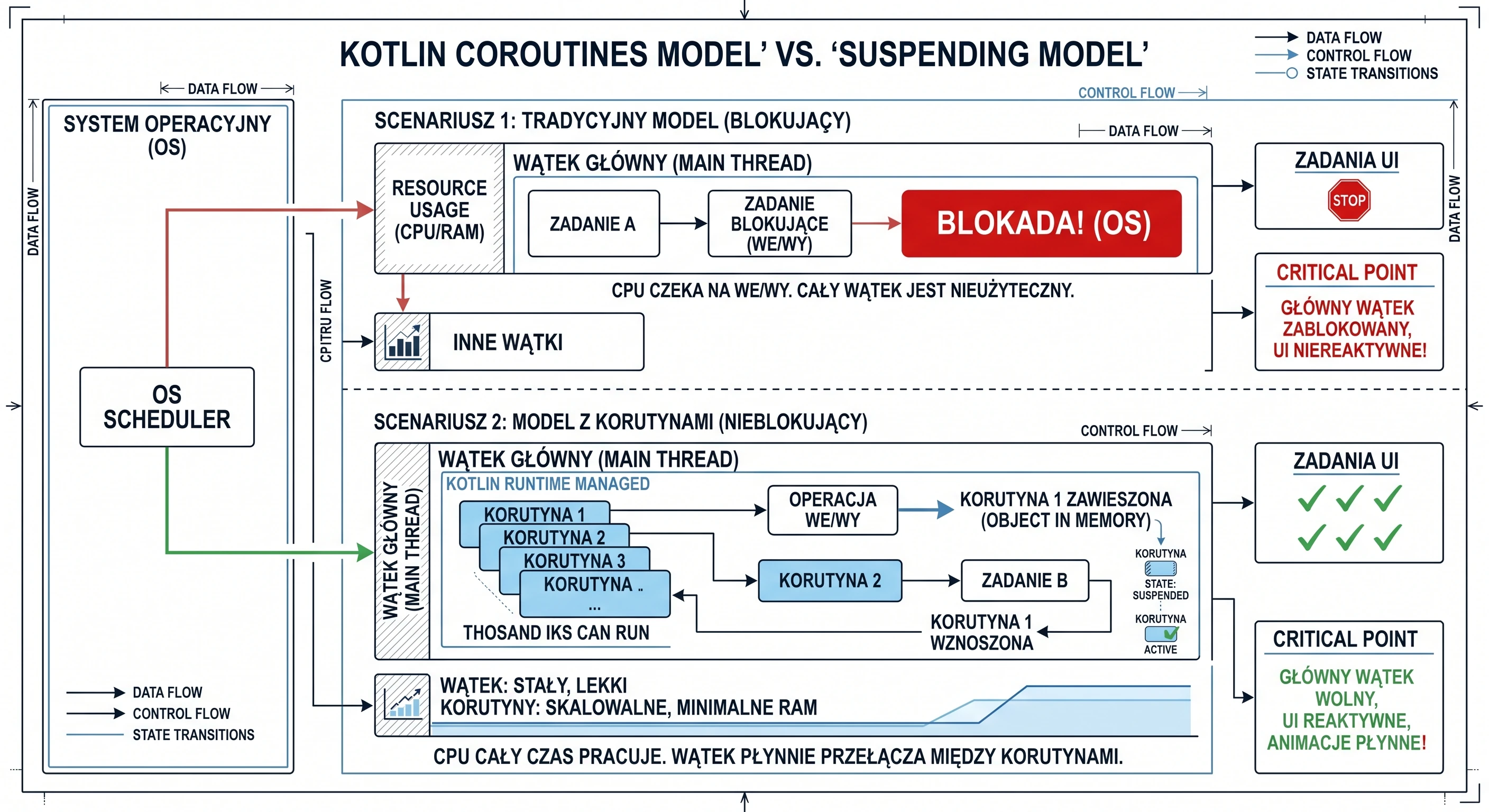
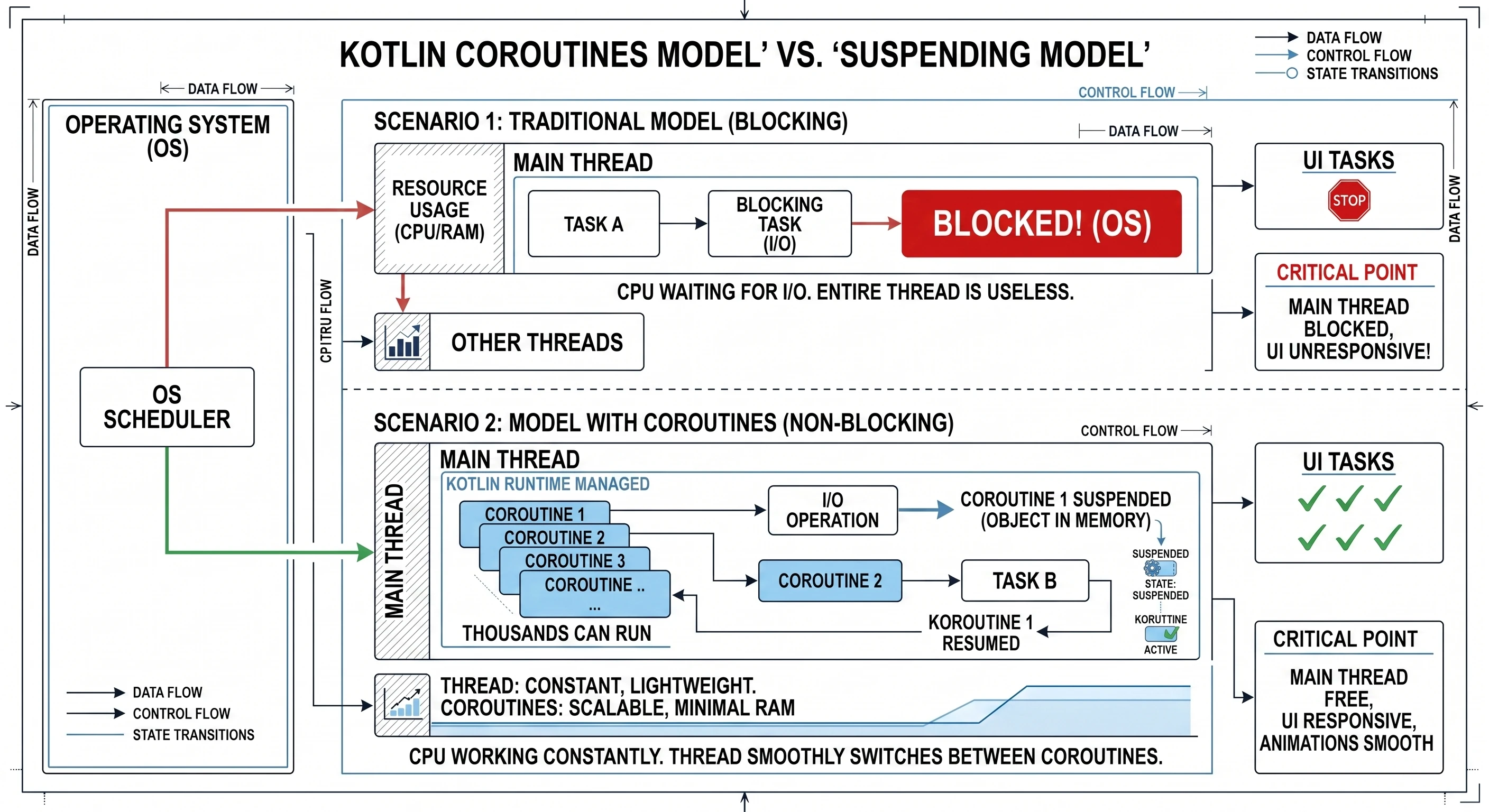
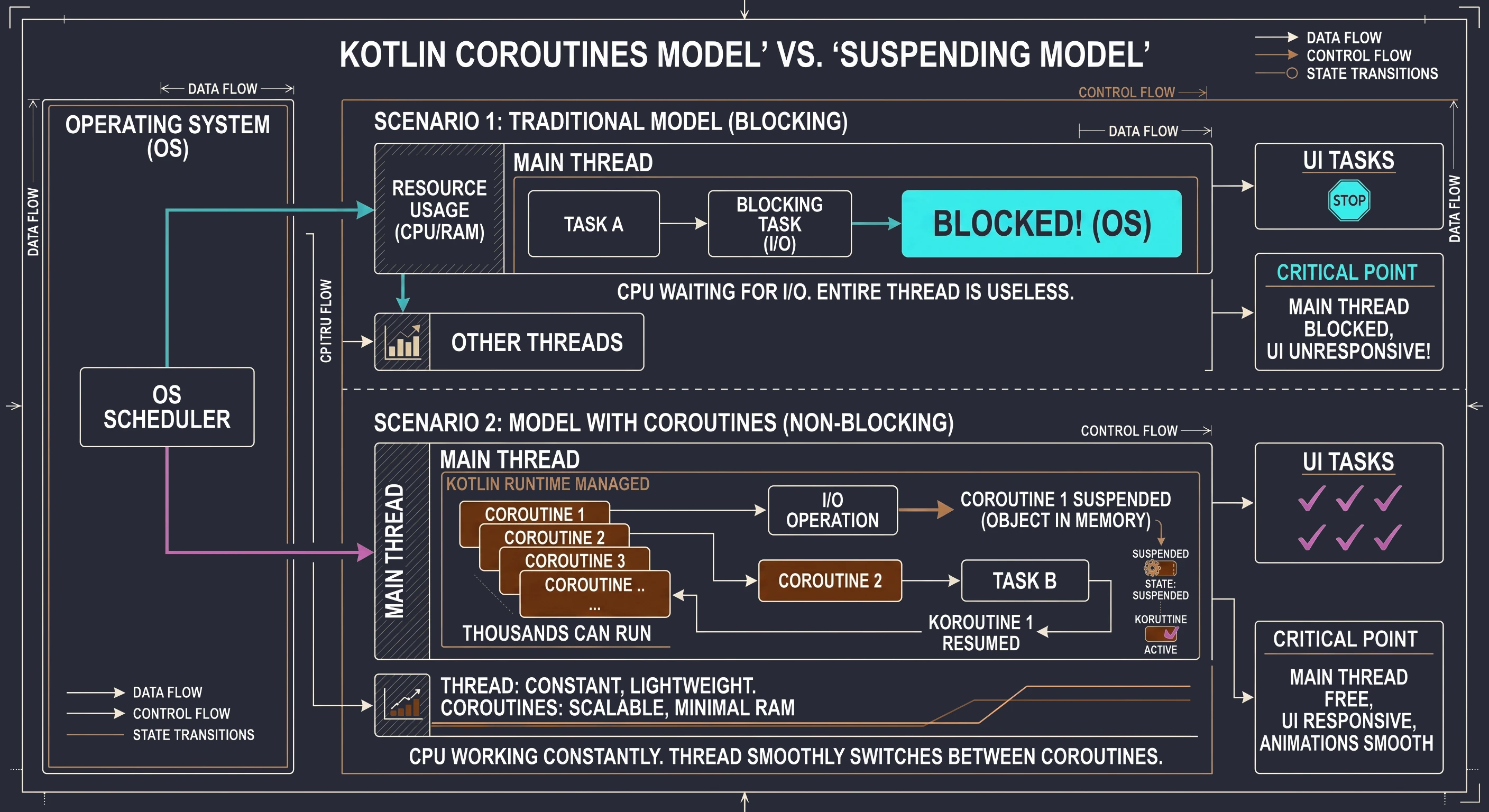
Wyobraźmy sobie kuchnię (naszą aplikację) i kucharza (Wątek).
Scenariusz 1: Kucharz jako Tradycyjny Wątek (Model Blokujący) Kucharz (Wątek UI) bierze przepis (zadanie). Pierwszy punkt przepisu brzmi: Gotuj wodę przez 5 minut. Kucharz włącza kuchenkę, a następnie stoi bezczynnie przez 5 minut, wpatrując się w garnek. W tym czasie w kuchni panuje chaos. Dzwoni telefon (interakcja użytkownika), przychodzą nowi goście (animacje) - ale kucharz jest zablokowany. Nie może zrobić nic innego, dopóki woda się nie zagotuje. To jest właśnie to, co robi Thread.sleep().
Scenariusz 2: Kucharz z Korutynami (Model Nieblokujący) Ten sam kucharz (ten sam Wątek UI) bierze ten sam przepis (teraz jako korutynę). Czyta: Gotuj wodę przez 5 minut. Kucharz nastawia wodę do gotowania (inicjuje operację wejścia/wyjścia), a następnie zawiesza (suspend) ten przepis i odkłada go na bok. Ponieważ jego ręce są wolne, natychmiast przechodzi do innego zadania - na przykład zaczyna kroić warzywa (obsługuje kliknięcie) lub przyprawiać sałatkę (rysuje animację). Kiedy po 5 minutach słyszy gwizdek czajnika (operacja w tle się zakończyła), kucharz wznawia (resume) pierwszy przepis i kontynuuje od miejsca, w którym skończył.
W tym modelu jeden kucharz (jeden wątek) żongluje wieloma przepisami (korutynami) jednocześnie, nigdy nie marnując czasu na bezczynne czekanie. Dodajmy tutaj że to, co nazywamy zawieszeniem (suspend), to nie jest pauza dla całej pracy. To jest pauza dla tej konkretnej korutyny na tym konkretnym wątku. To, kto rzeczywiście wykonuje pracę przy gotowaniu wody, rozwiążemy za chwilę.
Wątek roboczy
Musimy wyjaśnić, czym jest przepis w naszej analogii; jest to byt, który nazywamy funkcją z możliwością zawieszenia wykonania (suspend fun)
suspend fun ma się tak do korutyny, jak klasa ma się do instancji tej klasy; możemy mieć wiele instancji tej samej klasy:
suspend funto definicja lub plan (blueprint). To tylko definicja kroków, które mają zostać wykonane. Sama w sobie nie robi nic. Nie jest aktywna. Nie ma stanu działam lub jestem zawieszona- korutyna to instancja lub aktywne wykonanie tego planu. Powstaje, gdy bierzesz
suspend fun(lub dowolny blok kodususpend) i faktycznie go uruchamiasz. Korutyna ma stan (aktywna, zawieszona, anulowana). To jest ten pracownik, który wykonuje kroki z planu.
Kiedy piszesz w kodzie scope.launch {... } (zaraz wyjaśnimy czym jest scope), ten blok kodu launch (nazywany konstruktorem korutyny) tworzy i uruchamia nową korutynę (nową instancję pracy). Ta nowa, żywa korutyna zaczyna wykonywać kod wewnątrz bloku {...}. Może działać następująco:
- Korutyna (instancja) wywołuje
suspend fun(plan). - Ta
suspend fun(np.delay) mówi do korutyny: muszę teraz poczekać 1 sekundę. Możesz mnie zawiesić. - Korutyna (instancja) przechodzi w stan zawieszona. Zwalnia kucharza (wątek), który może iść robić coś innego (np. obsługiwać UI).
- Po 1 sekundzie
delaysię kończy. - Korutyna (instancja) jest wznawiana na dowolnym wolnym wątku i kontynuuje pracę od następnej linii.
Słowo kluczowe suspend nie oznacza, że funkcja automatycznie wykonuje się na wątku w tle! Oznacza jedynie, że funkcja może zostać zawieszona. Jeśli wewnątrz funkcji suspend wykonasz kosztowną operację (np. ciężkie obliczenia matematyczne) bez jawnego przełączenia dyspozytora (o dyspozytorach nieco później), nadal zablokujesz wątek wywołujący (w tym przypadku Wątek UI).
Wracając do pytania: kto gotuje wodę gdy kucharz pójdzie np. kroić warzywa?
W tej analogii kucharz będzie naszym wątkiem UI (wątkiem głównym), którego nie chcemy blokować długimi operacjami. Ale nie jest on jedynym pracownikiem kuchni, są również pomocnicy kuchenni (wątki robocze/poboczne). Nasza analogia wygląda teraz następująco:
- Szef Kuchni (Wątek UI) bierze przepis (korutynę). Czyta pierwszy punkt: Gotuj wodę przez 5 minut (np. pobierz dane z sieci, co robi
suspend fun). - Szef Kuchni nie gotuje wody osobiście. To strata jego cennego czasu (musi obsługiwać UI).
- Zamiast tego, woła Pomocnika Kuchennego. Daje mu garnek z wodą i mówi: Nastaw to na gazie (wykonaj operację sieciową). Jak się zagotuje, daj mi znać.
- Ten Pomocnik idzie i faktycznie wykonuje pracę. Patrzy na garnek (czeka na odpowiedź sieci).
- Szef Kuchni (Wątek UI), natychmiast po wydaniu polecenia, zawiesza (
suspend) ten przepis - odkłada go na bok z notatką czekam na wodę od pomocnika. - Ponieważ jego ręce są wolne, Szef Kuchni (Wątek UI) natychmiast przechodzi do krojenia warzyw (obsługuje kliknięcie) i przyprawiania sałatki (rysuje animację).
- Po 5 minutach Pomocnik (wątek IO) kończy pracę. Przybiega do Szefa Kuchni i mówi: Woda dla przepisu nr 5 jest gotowa! (sygnał zwrotny trafia z powrotem do Wątku Głównego).
- Szef Kuchni (Wątek UI), gdy tylko skończy kroić sałatkę, bierze zawieszony przepis nr 5 i wznawia (
resume) go od następnego kroku.
CoroutineScope
Kucharz nie może pracować w próżni, potrzebuje kuchni; przestrzeni przystosowanej do obsługiwania zadań kucharza, oraz posiadającej przygotowanych pomocników. Kuchnia to środowisko, w którym przepisy są realizowane, podobnie, nie możesz po prostu uruchomić korutyny w powietrzu; musisz ją uruchomić wewnątrz jakiegoś CoroutineScope. Nową korutynę tworzymy i włączamy za pomocą metody launch i możemy to zrobić tylko na CoroutineScope; przykładowo scope.launch{}. Wtedy mówimy: Chcę, aby ten przepis (korutyna) został wykonany w tej kuchni (scope).
Każda Kuchnia (CoroutineScope) ma swój regulamin i swoje zasoby. Ten regulamin to obiekt o typie CoroutineContext (Kontekst Korutyny). Posiada on zestaw atrybutów dla tej konkretnej kuchni. Dwa najważniejsze elementy w tym kontekście to:
Job(Szef Zmiany): To jest komponent odpowiedzialny za cykl życia.Dispatcher(Szef Kucharzy): To jest komponent odpowiedzialny za przydzielanie pracy.
Dispatcher (Szef Kucharzy), który jest częścią CoroutineContext danej Kuchni, posiada własnych pomocników (własną pulę wątków). Dispatcher to w zasadzie strateg planowania. Mówi on, na którym wątku (lub puli wątków) dany przepis (korutyna) ma być w danym momencie wykonywany. Mamy kilku głównych Szefów Kucharzy (Dispatcherów), których możemy wybrać:
Dispatchers.Main: Ten Szef ma pod sobą tylko jednego, specjalistycznego kucharza - Wątek UI. Każde zadanie, które mu dasz, zostanie wykonane tylko przez ten jeden wątek. Idealny do aktualizowania interfejsu.Dispatchers.IO: Ten Szef zarządza dużą, współdzieloną pulą wątków (pulą kucharzy) zoptymalizowaną do zadań wejścia-wyjścia (operacje sieciowe, dyskowe). Kiedy dajesz mu 100 przepisów (korutyn), on efektywnie rozdziela je między dostępnych kucharzy w swojej puli.Dispatchers.Default: Ten Szef również zarządza pulą wątków, ale jest ona zoptymalizowana pod zadania obciążające procesor (np. sortowanie ogromnej listy).
Kiedy korutyna (przepis) uruchomiona na Dispatchers.IO musi poczekać na odpowiedź z sieci (zawiesza się, suspend), zwraca pomocnika (wątek) z powrotem do puli, aby ten mógł zająć się innym zadaniem. Kiedy odpowiedź z sieci wraca, korutyna jest wznawiana i dostaje dowolnego wolnego pomocnika (wątek) z puli Dispatchers.IO, aby kontynuować pracę. Korutyna nie ma puli wątków. Korutyna używa puli wątków udostępnianej przez jej Dispatcher.
Drugim kluczowym elementem CoroutineScope jest Job (w naszej analogii będzie to odpowiednik Szefa Zmiany). Śledzi wszystkie korutyny aktualnie gotowane w danym zakresie (kuchni). Działa jak rodzic dla wszystkich korutyn uruchomionych w tym scope. Kiedy uruchamiasz korutynę za pomocą launch, funkcja ta zwraca właśnie obiekt Job.
val job = scope.launch {... }Job to jedyny sposób, aby dowiedzieć się, co dzieje się z korutyną. Działa jak interaktywny bilet zamówienia w restauracji. Przechowuje on aktualny stan wykonania przepisu:
- New: Zamówienie przyjęte, ale jeszcze nie zaczęte.
- Active: Kucharz właśnie nad tym pracuje (lub czeka na wodę).
- Completed: Danie gotowe.
- Cancelled: Klient wyszedł, wyrzucamy składniki do kosza.
- Dzięki Job możesz programowo zapytać:
job.isActive(czy jeszcze pracujemy?) lubjob.isCancelled.
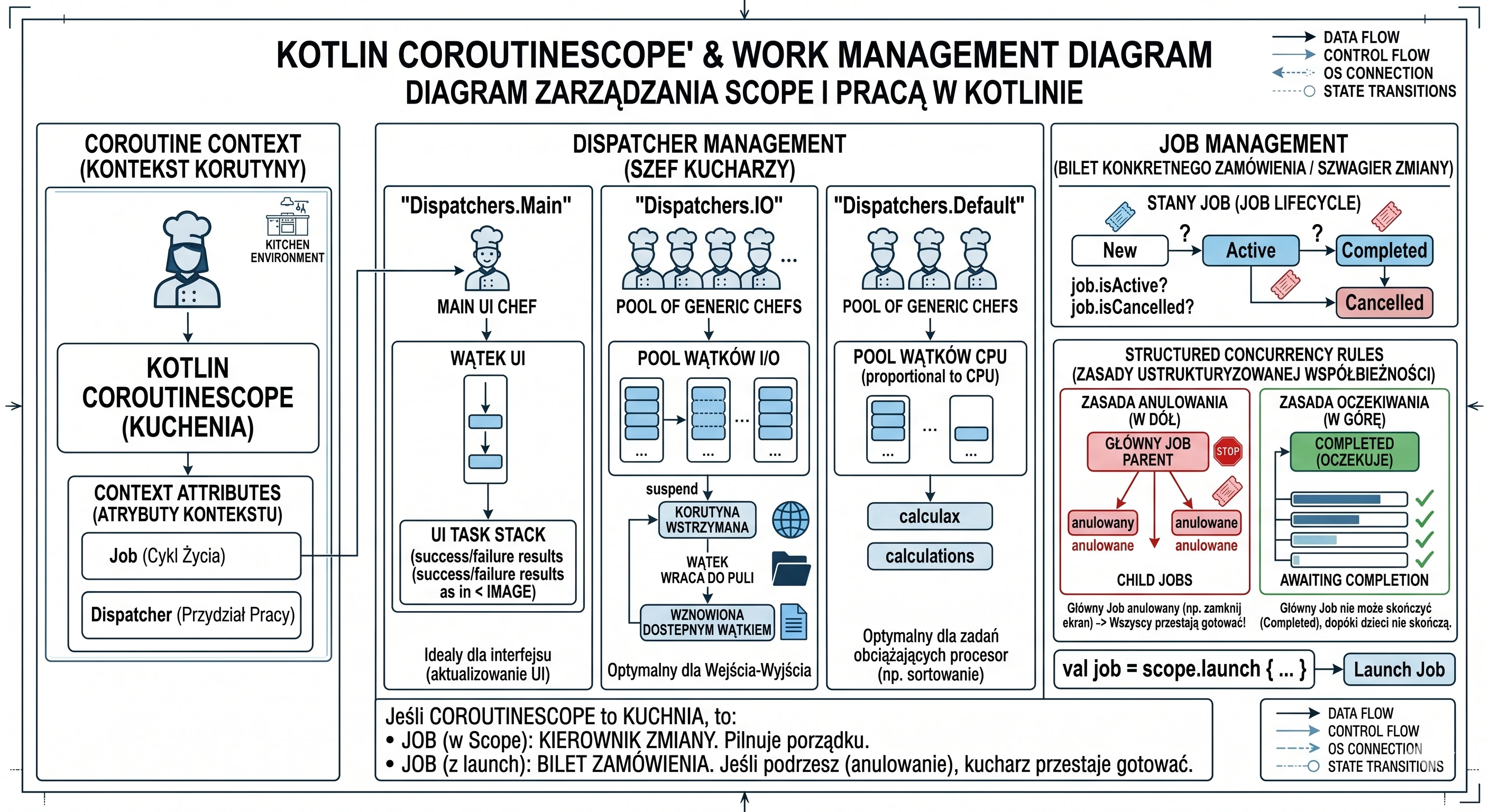
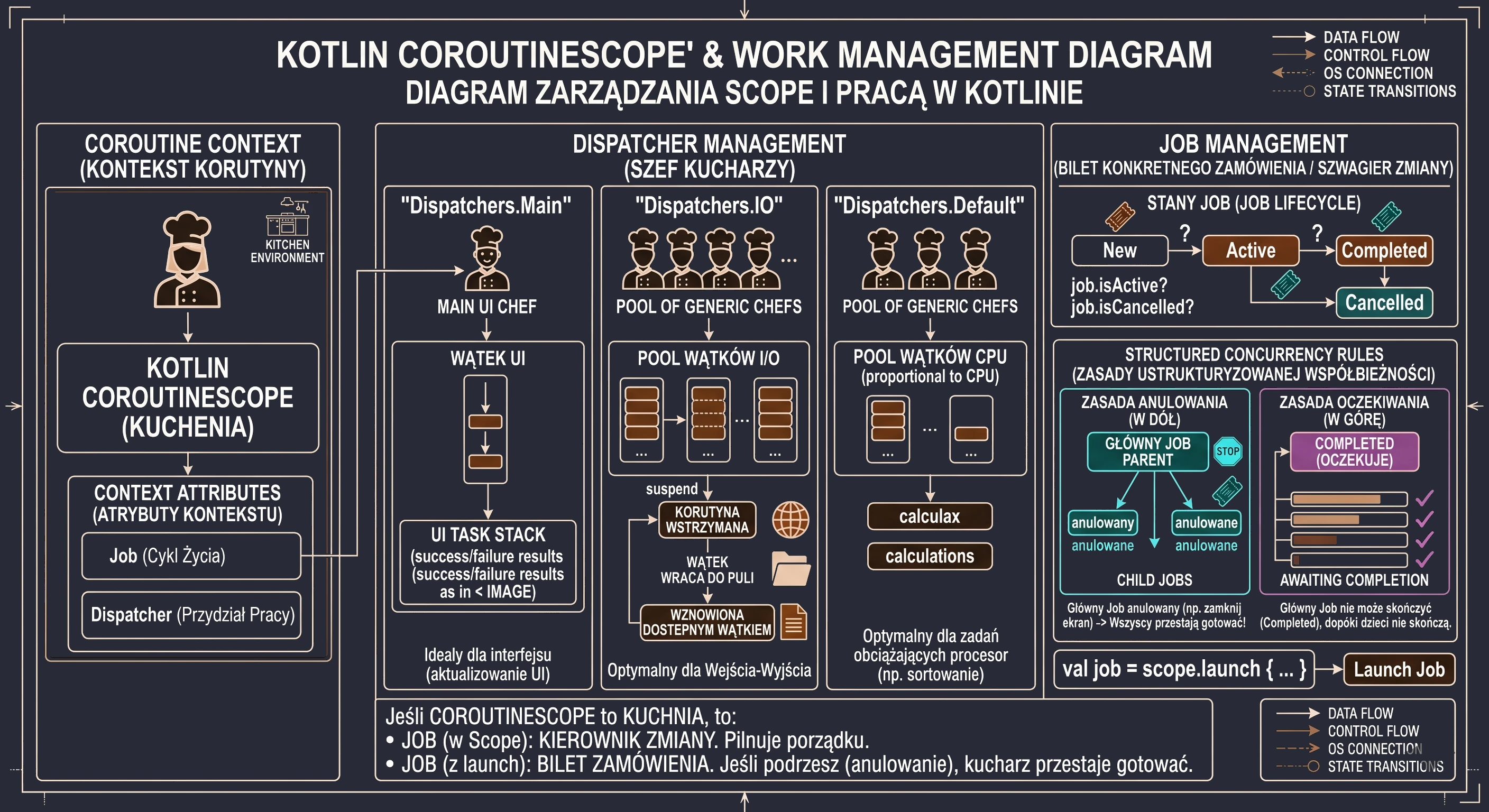
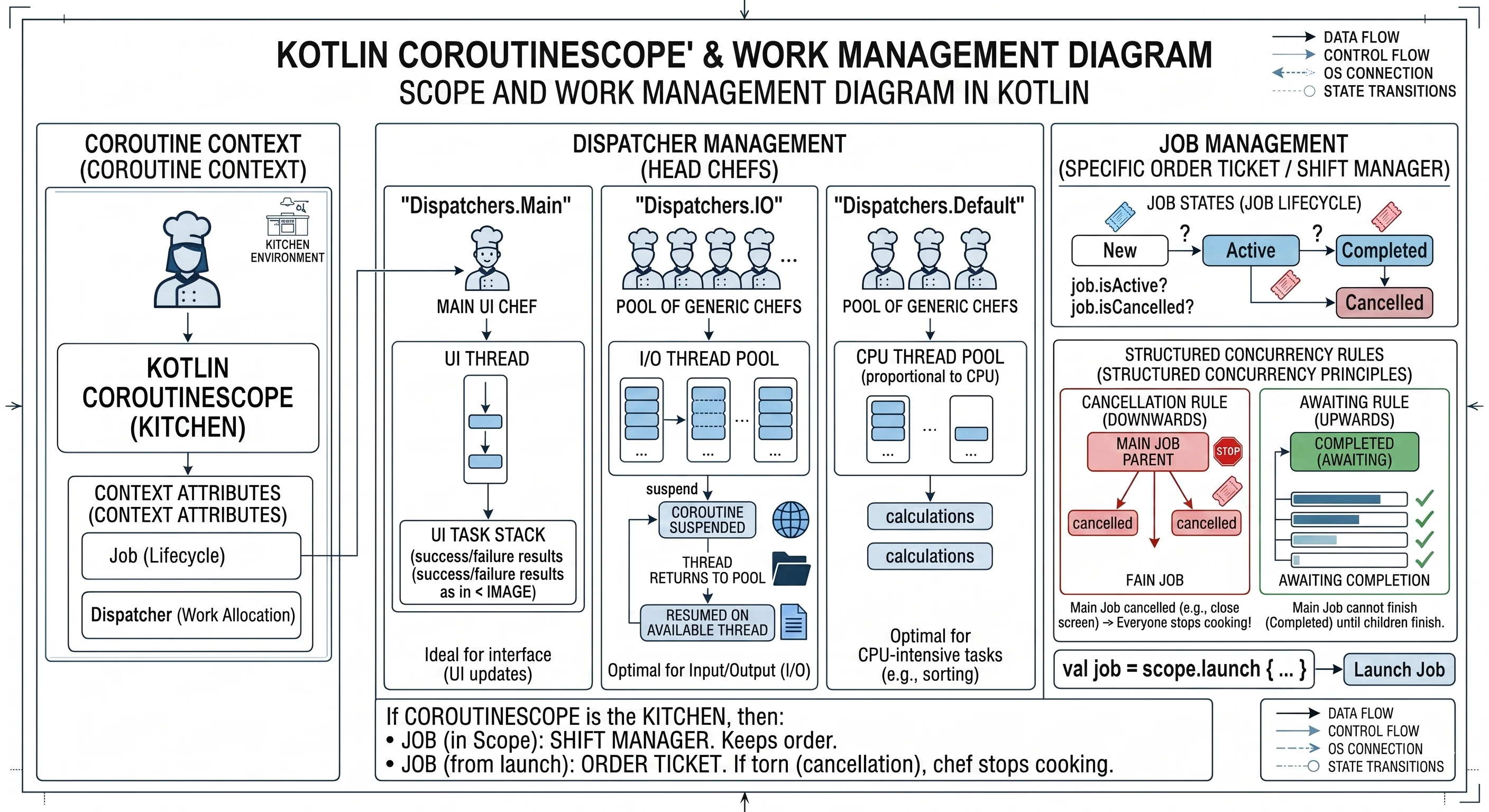
W świecie korutyn każdy Job może mieć rodzica i dzieci. Kiedy tworzysz CoroutineScope, ma on w sobie Główny Job (Szefa Zmiany). Kiedy w tym Scope uruchamiasz launch, powstaje nowy Job, który automatycznie staje się dzieckiem Głównego Joba. Tworzy to nierozerwalne drzewo zależności. Działają tu dwie żelazne zasady Ustrukturyzowanej Współbieżności:
- Zasada Anulowania (W dół): Jeśli anulujesz Rodzica (np. zamkniesz ekran i anulujesz
coroutineScope), wszystkie dzieci są automatycznie anulowane (Canceled). Szef Zmiany mówi: Zamykamy kuchnię!, więc wszyscy kucharze natychmiast przestają gotować swoje dania. Nikt nie zostaje w pracy po godzinach. - Zasada Oczekiwania (W górę): Rodzic nie może zakończyć pracy (Completed), dopóki wszystkie jego dzieci nie skończą. Szef Zmiany nie może wyjść do domu, dopóki ostatni pomocnik nie skończy zmywać naczyń.
Podsumowanie w naszej analogii: Jeśli CoroutineScope to Kuchnia, to:
Job(w Scope): To Kierownik Zmiany. Pilnuje, żeby nikt nie pracował, gdy restauracja jest zamknięta.Job(zwracany przezlaunch): To Bilet Konkretnego Zamówienia. Jest przypięty do tablicy korkowej Kierownika. Jeśli Kierownik zdejmie bilet z tablicy i podrze go (anulowanie), kucharz natychmiast przestaje nad nim pracować.
Rozwiązanie problemu ANR
Wróćmy do przykładu z początku rozdziału. W poprzedniej wersji, gdy klikaliśmy przycisk, który wywoływał Thread.sleep(10000), cała aplikacja zawieszała się. Suwak (Slider) przestawał działać, przyciski nie reagowały, a po chwili system wyświetlał błąd ANR. Zaimplementujmy kod rozwiązujący ten problem, rozpoczniemy od dodania przepisu, czyli funkcji suspend
// Zmiana 1: Słowo kluczowe 'suspend'
suspend fun fetchDataFromServer(): String {
println("Korutyna:...")
// Zmiana 2: 'delay' zamiast 'Thread.sleep'
delay(10000) // delay jest również funkcja suspend
println("Korutyna:...")
return "Dane pobrane pomyślnie!"
}To, co nazywamy zawieszeniem (suspend), to nie jest pauza dla całej pracy. To jest pauza dla tej konkretnej korutyny na tym konkretnym wątku.
Thread.sleepmówi do Wątku UI: Stój i nic nie rób przez 10 sekund.delaymówi do Wątku UI: Odkładam to zadanie na półkę na 10 sekund. Ty idź zajmij się czymś innym (np. rysowaniem suwaka). Wrócimy do tego później.
Wewnątrz Composable (CoroutineSolutionScreen) pojawia się nowa linijka:
val scope = rememberCoroutineScope()Jest to niezbędne, ponieważ funkcja onClick przycisku jest zwykłą funkcją (nie jest suspend). Nie możemy z niej bezpośrednio wywołać fetchDataFromServer ani delay. Potrzebujemy bramy lub pomostu, który pozwoli nam wejść w świat asynchroniczny. Tym pomostem jest CoroutineScope powiązany z cyklem życia tego ekranu.
Warto zauważyć, że CoroutineScope uzyskany przez rememberCoroutineScope() w Jetpack Compose domyślnie wykorzystuje Dispatchers.Main (a konkretnie Main.immediate). Oznacza to, że kod wewnątrz launch wykonuje się na wątku głównym.
Zakres rememberCoroutineScope() jest ściśle powiązany z punktem w kompozycji, w którym został wywołany. Jeśli użytkownik opuści ten ekran (komponent zostanie usunięty z drzewa UI), scope zostanie automatycznie anulowany. Dzięki temu wszelkie trwające w nim operacje (np. nasze 10-sekundowe pobieranie danych) zostaną natychmiast przerwane, zapobiegając wyciekom pamięci i marnowaniu zasobów.
Wewnątrz onClick widzimy:
Button(onClick = {
statusText = "Operacja rozpoczęta..." // 1. Natychmiastowa aktualizacja UI
scope.launch { // 2. Start korutyny (Fire-and-forget)
val result = fetchDataFromServer() // 3. Punkt zawieszenia (suspend)
statusText = result // 4. Wznowienie i aktualizacja UI
}
})Co tu się dzieje krok po kroku?
- Użytkownik klika.
- Tekst zmienia się na "Operacja rozpoczęta...".
scope.launchtworzy nową korutynę.- Korutyna wchodzi do
fetchDataFromServer, dochodzi dodelay(10000)i zawiesza się. - Wątek UI jest wolny! Przez te 10 sekund Wątek Główny obsługuje przesuwanie suwaka (Slider), animacje i inne kliknięcia.
- Po 10 sekundach korutyna budzi się, przypisuje wynik do
resulti aktualizujestatusText.
| Cecha | Stara Wersja (Thread.sleep) | Nowa Wersja (delay + Korutyny) |
|---|---|---|
| Reakcja na przycisk | Przycisk pozostaje wciśnięty (zamrożony). | Przycisk klika się normalnie, pokazuje animację ripple. |
| Suwak (Slider) | Zablokowany. Nie można go przesunąć. | Płynny. Możesz nim ruszać przez całe 10 sekund oczekiwania. |
| Wątek UI | Zablokowany (Blocked). Kucharz stoi nad garnkiem. | Wolny (Free). Kucharz nastawił minutnik i kroi warzywa. |
| Ryzyko ANR | Bardzo wysokie (system zabije aplikację). | Zerowe (aplikacja jest responsywna). |
| Styl kodu | Sekwencyjny (linia po linii). | Sekwencyjny! Mimo asynchroniczności, kod czyta się tak samo łatwo. |
Ustrukturyzowana Współbieżność
Poprzednio nauczyliśmy się, jak uruchamiać zadania w tle (nastawiać wodę) i nie blokować przy tym kuchni. Co w sytuacji, gdy przygotowanie dania wymaga wykonania kilku czynności na raz, a my musimy mieć pewność, że wszystkie zostały ukończone, zanim wydamy posiłek?
Tu z pomocą przychodzi funkcja join(), która jest fundamentem synchronizacji w świecie korutyn.
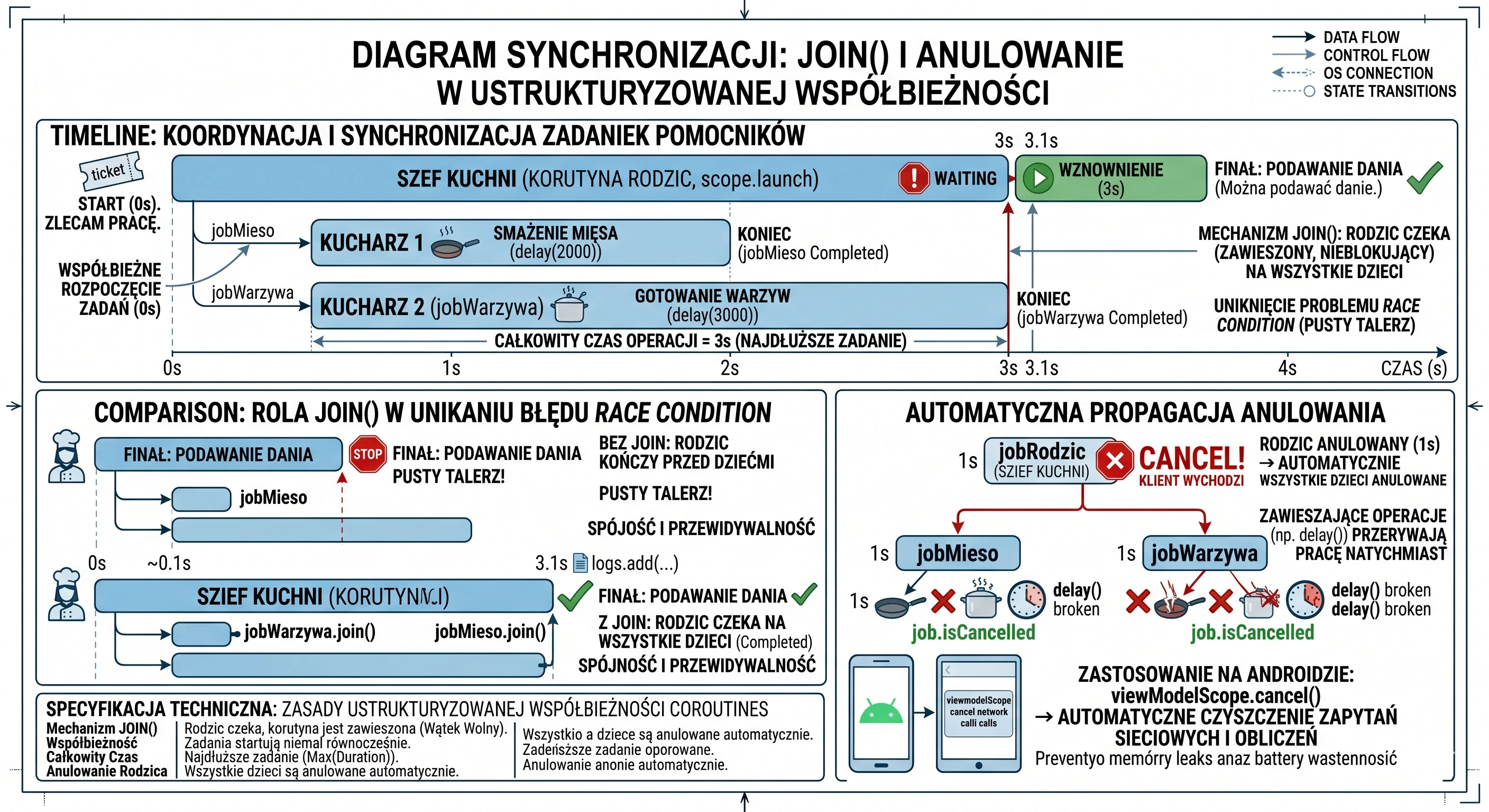
Wyobraź sobie, że jesteś Szefem Kuchni (Korutyna-Rodzic). Masz przygotować główne danie: Stek z warzywami. Nie będziesz robić wszystkiego sam.
- Wołasz Pomocnika nr 1: Usmaż mięso! (zajmie to 2 sekundy).
- Wołasz Pomocnika nr 2: Ugotuj warzywa! (zajmie to 3 sekundy).
Obaj pomocnicy ruszają do pracy w tym samym momencie (współbieżność). Główna korutyn jest wolna i może zająć się innymi sprawami. Ale nie może wydać dania dopóki nie będzie gotowe. To czekanie wykonujemy za pomocą join().
Zobaczmy kod, któy symuluje taką sytuację:
// 1. Szef Kuchni (Rodzic) rozpoczyna pracę
scope.launch {
logs.add("Szef kuchni (rodzic): Zaczynamy!")
// 2. Zlecenie zadania Pomocnikowi 1 (Dziecko 1)
val jobMieso = launch {
delay(2000) // Symulacja smażenia
logs.add("Kucharz 1: Mięso usmażone (2s).")
}
// 3. Zlecenie zadania Pomocnikowi 2 (Dziecko 2)
val jobWarzywa = launch {
delay(3000) // Symulacja gotowania
logs.add("Kucharz 2: Warzywa gotowe (3s).")
}
logs.add("Szef kuchni: Zadania zlecone, scope czeka na zakończenie...")
// 4. synchronizacja: Szef czeka na wyniki
jobWarzywa.join()
jobMieso.join()
// 5. Finał
logs.add("Szef kuchni: Wszyscy skończyli! Można podawać danie.")
}W przykładzie widzimy koordynację zadań podrzędnych. Cały proces rozpoczyna się w momencie, gdy korutyna nadrzędna - nasz metaforyczny Szef Kuchni - uruchamia podzadania za pomocą funkcji launch. Jest to swego rodzaju bilet zamówienia, który daje nam unikalny uchwyt do konkretnej, trwającej korutyny. W naszym przypadku tworzymy dwa takie uchwyty: jobMieso oraz jobWarzywa, które stają się dziećmi głównej korutyny uruchomionej w scope.
Oba zadania startują niemal w tym samym momencie, co oznacza, że nie czekamy z gotowaniem warzyw do momentu, aż mięso będzie gotowe. Dzięki temu całkowity czas operacji nie jest sumą czasów poszczególnych zadań (5 sekund), lecz odpowiada czasowi najdłuższego z nich (3 sekundy). Jednak ta niezależność podzadań rodzi problem synchronizacji: co, jeśli Szef Kuchni zakończy swoją pracę szybciej niż jego pomocnicy? Bez odpowiedniej kontroli, log Można podawać danie pojawiłby się natychmiast po zleceniu zadań, co w naszej metaforze oznaczałoby wydanie klientowi pustego talerza, zanim składniki zdążą się ugotować.
Rozwiązaniem problemu wyścigu (race condition) jest funkcja join(). Z technicznego punktu widzenia jest to funkcja zawieszająca (suspend function), która służy do synchronizacji cyklu życia korutyn. Kiedy korutyna nadrzędna (rodzic) napotyka instrukcję jobWarzywa.join(), jej wykonanie zostaje zawieszone. Należy wyraźnie podkreślić różnicę między zawieszeniem a zablokowaniem: wątek obsługujący tę korutynę nie jest blokowany i może w tym czasie wykonywać inne operacje systemowe. Mechanizm join wprowadza korutynę wywołującą w stan oczekiwania, który trwa dopóki obserwowany obiekt Job nie osiągnie stanu końcowego (Completed lub Cancelled). Dopiero gdy podzadanie faktycznie zakończy swoje działanie, maszyna stanów wznawia korutynę rodzica od kolejnej linii kodu. Dzięki jawnemu wywołaniu join() na obu obiektach Job, realizujemy kontrakt Ustrukturyzowanej Współbieżności, w którym rodzic świadomie koordynuje pracę swoich dzieci i gwarantuje, że żadna operacja nie zostanie zakończona przedwcześnie, zapewniając spójność danych i przewidywalność przepływu aplikacji.
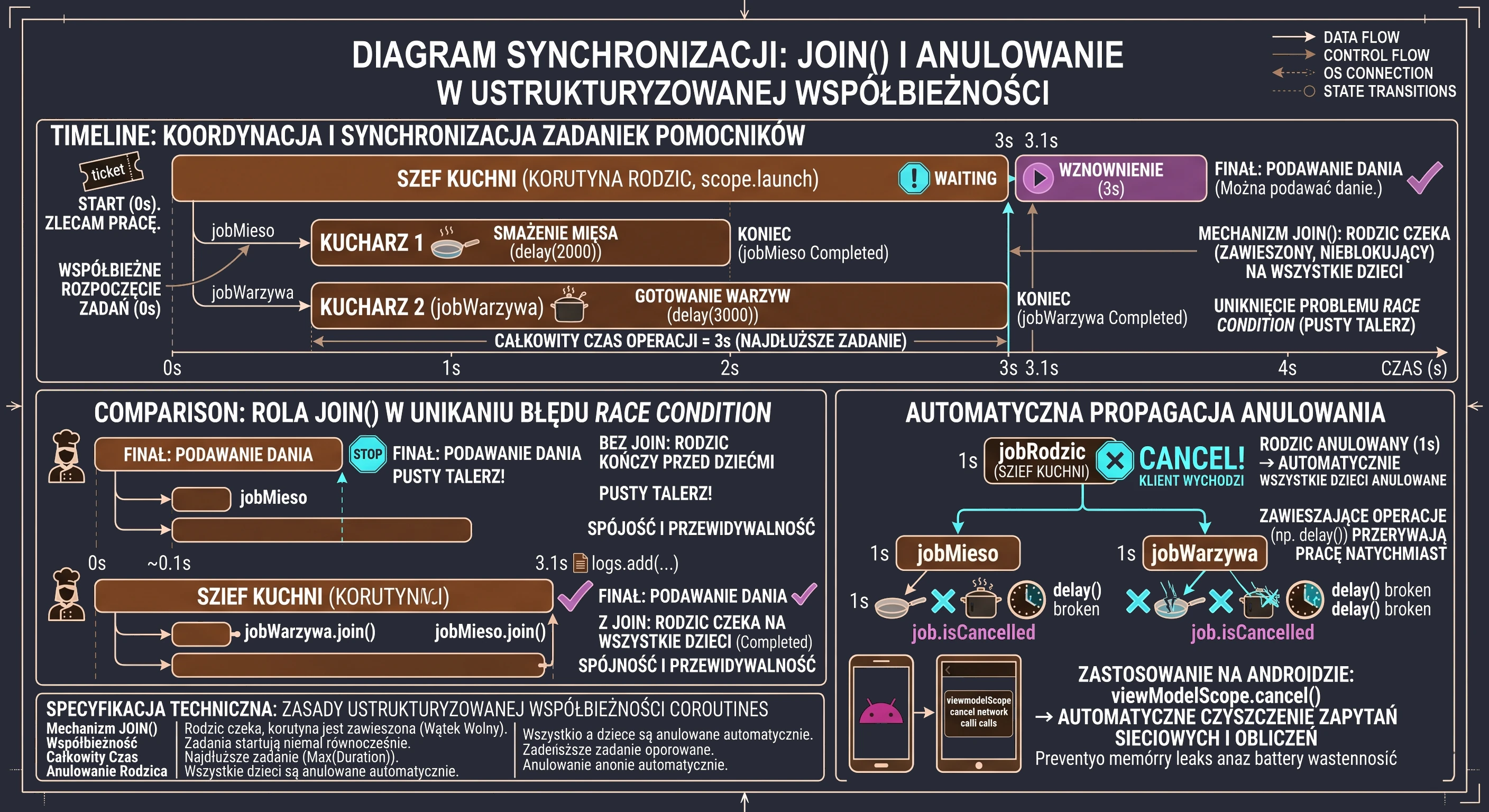
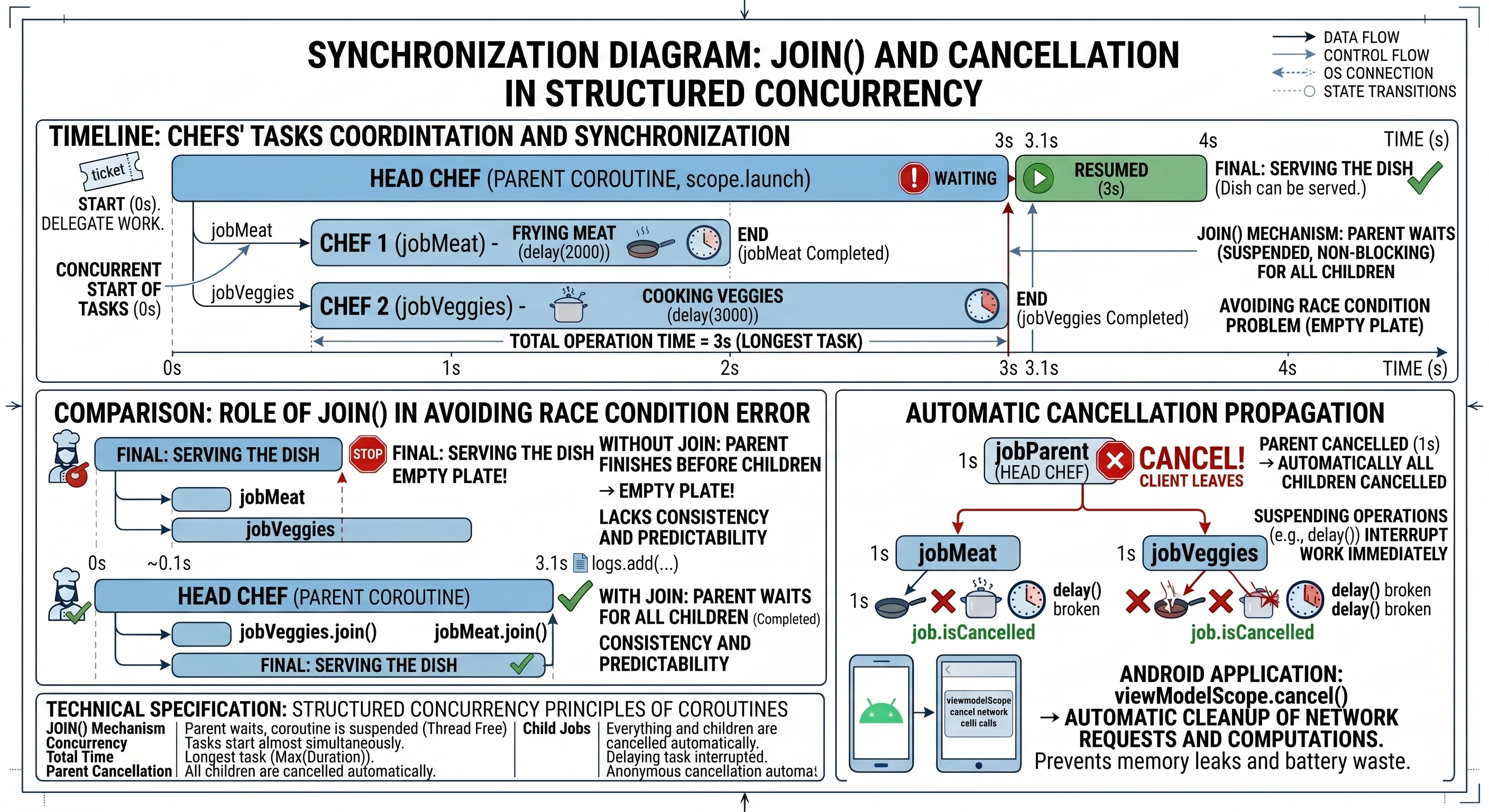
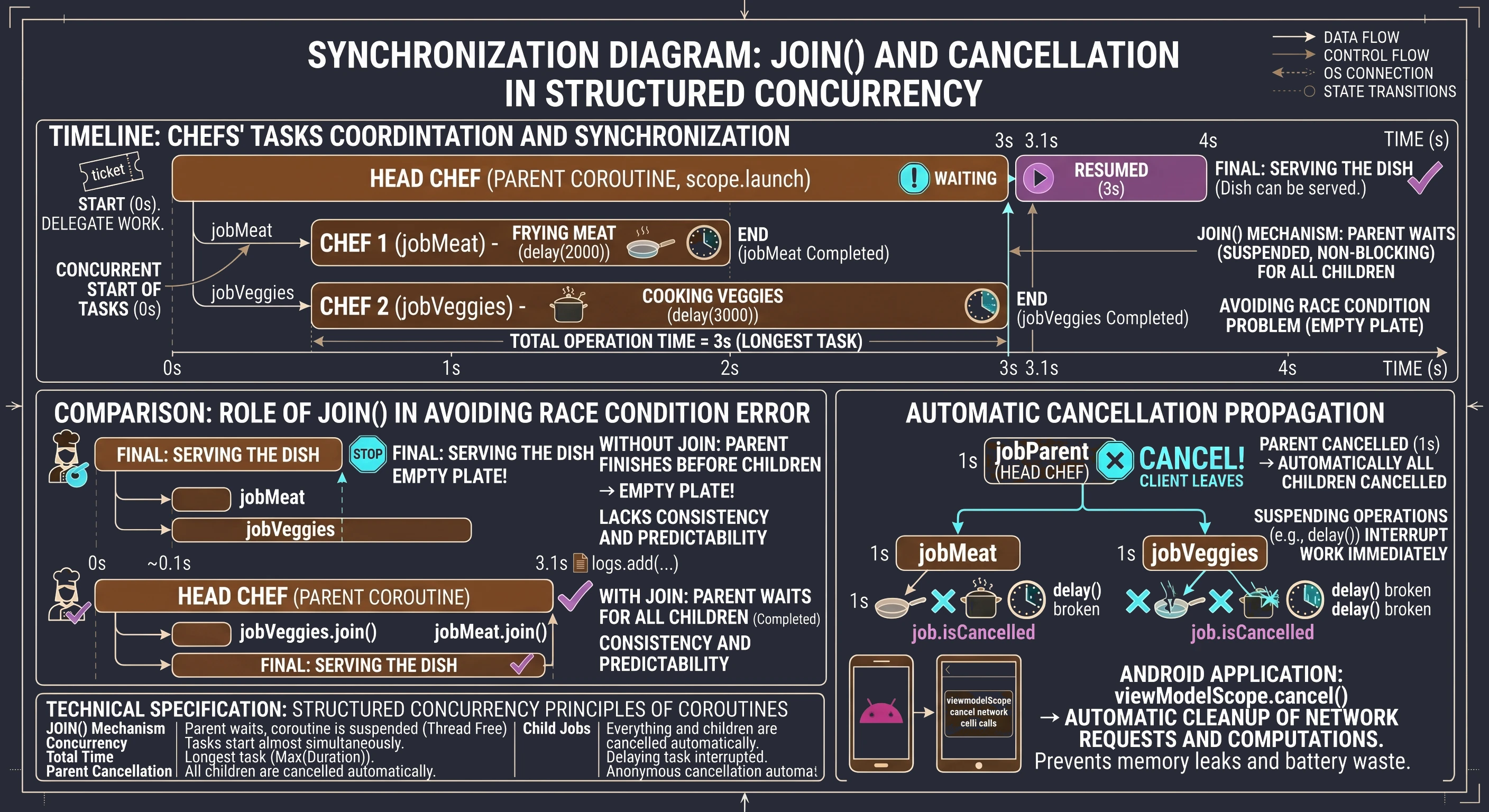
Warto zatrzymać się przy aspekcie, który czyni ustrukturyzowaną współbieżność bezpieczną - jest to automatyczna propagacja anulowania - wpominaliśmy już o tym wcześniej. Ale omówmy to jeszcze raz.
Wyobraźmy sobie, że nasz Szef Kuchni (rodzic) otrzymuje informację, że klient anulował zamówienie i wychodzi z restauracji. W świecie ustrukturyzowanej współbieżności Szef nie musi biegać po kuchni i osobiście prosić każdego pomocnika o przerwanie pracy. Wywołanie job.cancel() na korutynie-rodzicu automatycznie przesyła sygnał anulowania do wszystkich dzieci (jobMieso, jobWarzywa). Jeśli pomocnicy wykonują funkcje zawieszające (takie jak delay), natychmiast przerwą pracę.
W programowaniu aplikacji na Androida ten mechanizm jest niezwykle istotny. Kiedy użytkownik zamyka ekran (Activity), powiązany z nim zakres (viewModelScope lub lifecycleScope) zostaje anulowany. Dzięki hierarchii rodzic-dziecko, wszystkie trwające zapytania sieciowe czy obliczenia w tle zostają posprzątane automatycznie. Zapobiega to wyciekom pamięci i marnowaniu baterii na procesy, których wyniku nikt już nie zobaczy.
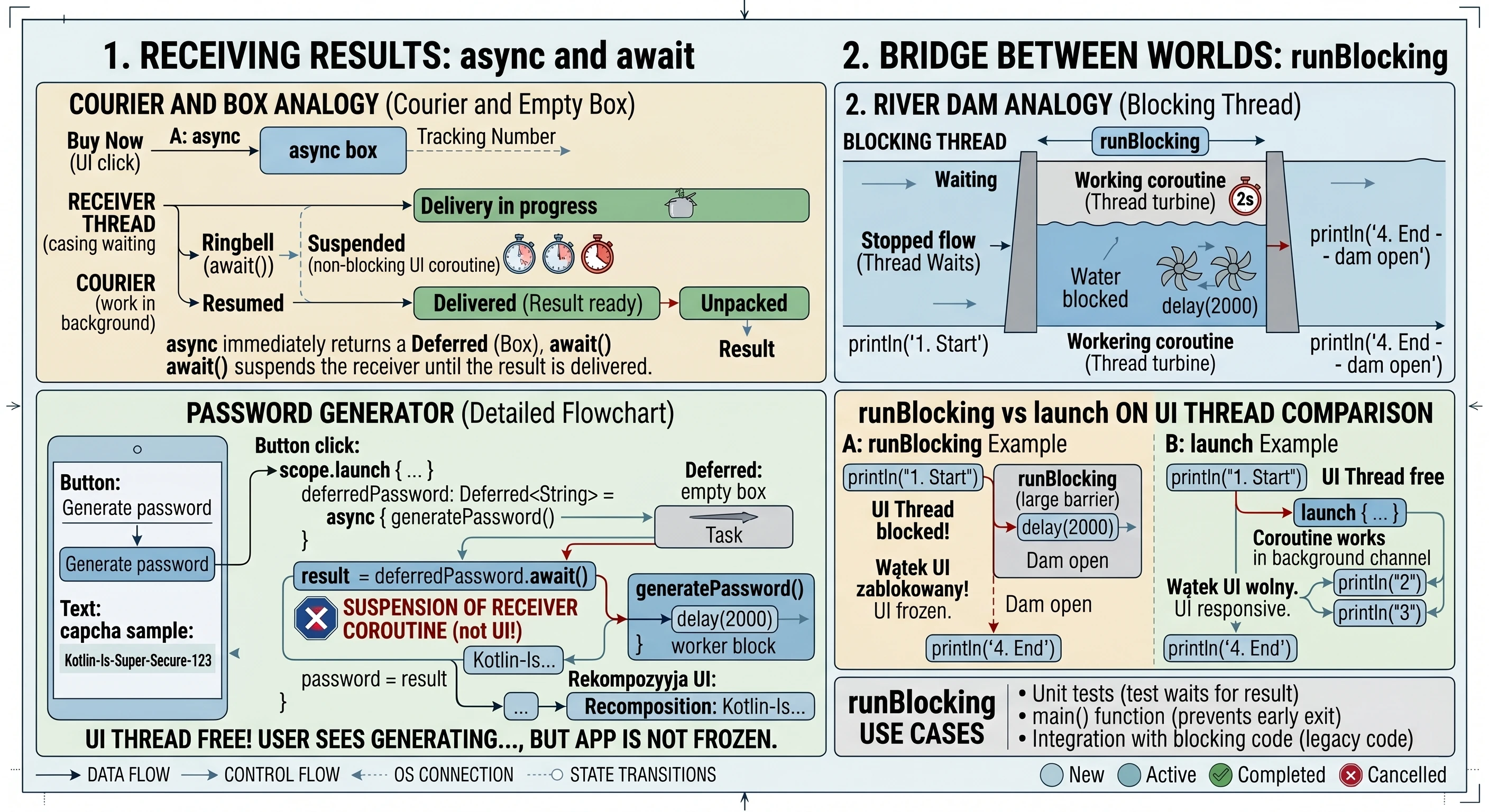
Odbieranie Wyników: Mechanizm async i await
Mimo że funkcja launch jest niezwykle przydatna, posiada jedno istotne ograniczenie: działa na zasadzie odpal i zapomnij (fire-and-forget). Zwraca ona obiekt Job, który pozwala nam sprawdzić czy praca trwa, lub ją przerwać, ale nie pozwala nam wyjąć ze środka żadnej wartości. W świecie rzeczywistym nie zawsze chcemy tylko zlecić zadanie; często potrzebujemy, aby pracownik coś nam przyniósł (np. konkretny składnik z magazynu). Do takich zadań służy funkcja async.
Analogia: Kurier i Pusta Skrzynka
Zanim przeanalizujemy kod, posłużmy się analogią zamówienia przesyłki:
- async: To moment kliknięcia Kup teraz. Sklep nie daje nam towaru natychmiast, ale daje nam numer śledzenia przesyłki (to jest nasz obiekt
Deferred). - Deferred: To metaforyczne puste pudełko. Pudełko istnieje fizycznie (mamy do niego referencję w kodzie), ale w tej chwili nie możemy z niego skorzystać, bo zawartość jest jeszcze w drodze.
- await(): To moment, w którym czekamy na dzwonek kuriera. Jeśli kurier już był - odbieramy zawartość natychmiast. Jeśli jeszcze jedzie - zawieszamy nasze inne czynności i czekamy, aż pudełko zostanie odpakowane.
Przykład Praktyczny: Generator Tajemniczego Hasła
Rozważmy implementację ekranu, który symuluje złożony proces generowania bezpiecznego hasła. Proces ten trwa 3 sekundy i musi zwrócić wynik bezpośrednio do zmiennej stanu interfejsu.
@Composable fun PasswordGeneratorScreen() {
var password by remember { mutableStateOf("...") }
val scope = rememberCoroutineScope()
// Funkcja symulująca ciężkie obliczenia w tle
suspend fun generatePassword(): String {
delay(3000) // Symulacja pracy
return "Kotlin-Is-Super-Secure-123"
}
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text("Generator Tajemniczego Hasła", style = MaterialTheme.typography.headlineSmall)
Spacer(Modifier.height(20.dp))
Button(onClick = {
password = "Generowanie..."
// Uruchamiamy korutynę nadrzędną (szkielet operacji)
scope.launch {
// 1. Zlecenie zadania (async) - natychmiast dostajemy 'pudełko' Deferred
val deferredPassword: Deferred<String> = async { generatePassword() }
// 2. Oczekiwanie (await) - korutyna zawiesza się tutaj na 3 sekundy
val result = deferredPassword.await()
// 3. Po 3 sekundach korutyna wznawia pracę z gotowym wynikiem
password = result
}
}) {
Text("Wygeneruj hasło")
}
Spacer(Modifier.height(20.dp))
Text(password, fontSize = 20.sp, fontFamily = FontFamily.Monospace)
}
}W powyższym kodzie kluczowy jest moment kliknięcia przycisku. Wywołujemy scope.launch, aby wejść do świata współbieżności. Wewnątrz niego dzieją się dwie rzeczy: Po pierwsze, linia async { generatePassword() } nie blokuje wykonania kodu. Funkcja async natychmiast zwraca obiekt typu Deferred<String>. Gdybyśmy w tym momencie sprawdzili wartość deferredPassword, dowiedzielibyśmy się jedynie, że zadanie jest w toku. Po drugie, wywołanie deferredPassword.await() jest instrukcją dla mechanizmu korutyn: Zatrzymaj tę konkretną korutynę w tym miejscu i czekaj, aż deferredPassword dostarczy wartość. Co niezwykle ważne - wątek UI pozostaje wolny. Użytkownik widzi napis Generowanie..., ale aplikacja nie jest zamrożona; system może w tym czasie obsłużyć inne zdarzenia.
Gdy funkcja generatePassword() skończy pracę i zwróci String, await() odpakuje go i przypisuje do zmiennej result. Dopiero wtedy wykonuje się ostatnia linia: password = result, co powoduje rekompozycję interfejsu i wyświetlenie hasła.
Most między światami: runBlocking
Wszystkie funkcje, które poznaliśmy do tej pory - launch oraz async - wymagają do działania istniejącego zakresu (CoroutineScope). Istnieją jednak sytuacje, w których musimy poczekać, aż świat korutyn zakończy swoją pracę, zanim pozwolimy światu zewnętrznemu (blokującemu) ruszyć z miejsca. Do tego celu służy runBlocking. Jak sama nazwa wskazuje, jest to funkcja, która blokuje bieżący wątek, na którym została wywołana, dopóki wszystkie korutyny wewnątrz jej bloku nie zostaną zakończone.
Wyobraź sobie strumień kodu asynchronicznego jako płynącą rzekę - korutyny płyną swobodnie, nie przeszkadzając sobie nawzajem. runBlocking jest jak tama, którą stawiamy w poprzek rzeki.
- Woda (wątek) przestaje płynąć dalej za tamę.
- Cały nurt zostaje zatrzymany tak długo, aż praca wewnątrz tamy nie zostanie ukończona.
- Dopiero gdy ostatnia korutyna w bloku
runBlockingskończy działanie, tama zostaje otwarta i wątek może kontynuować wykonywanie kolejnych linii kodu pod blokiem.
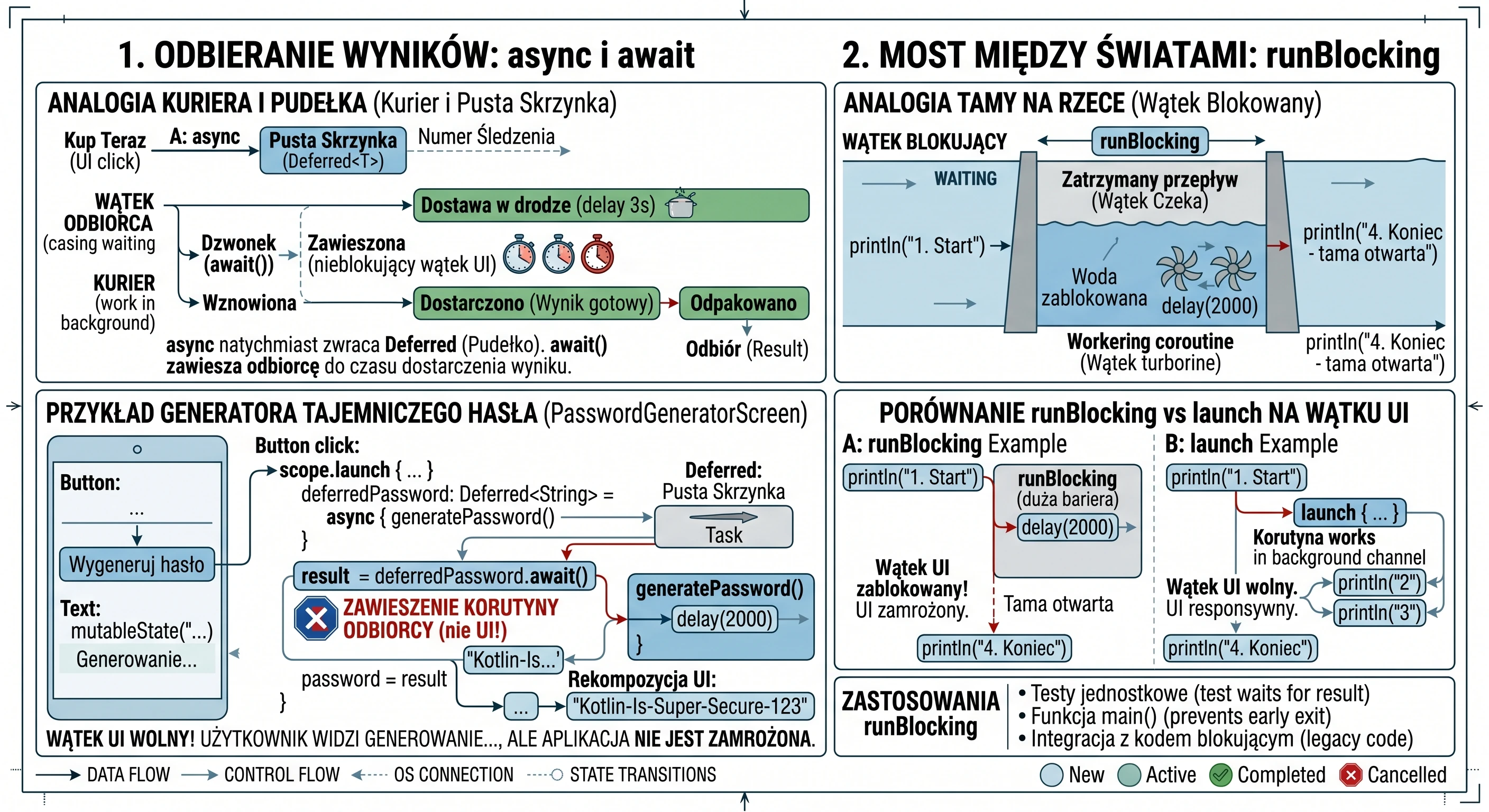
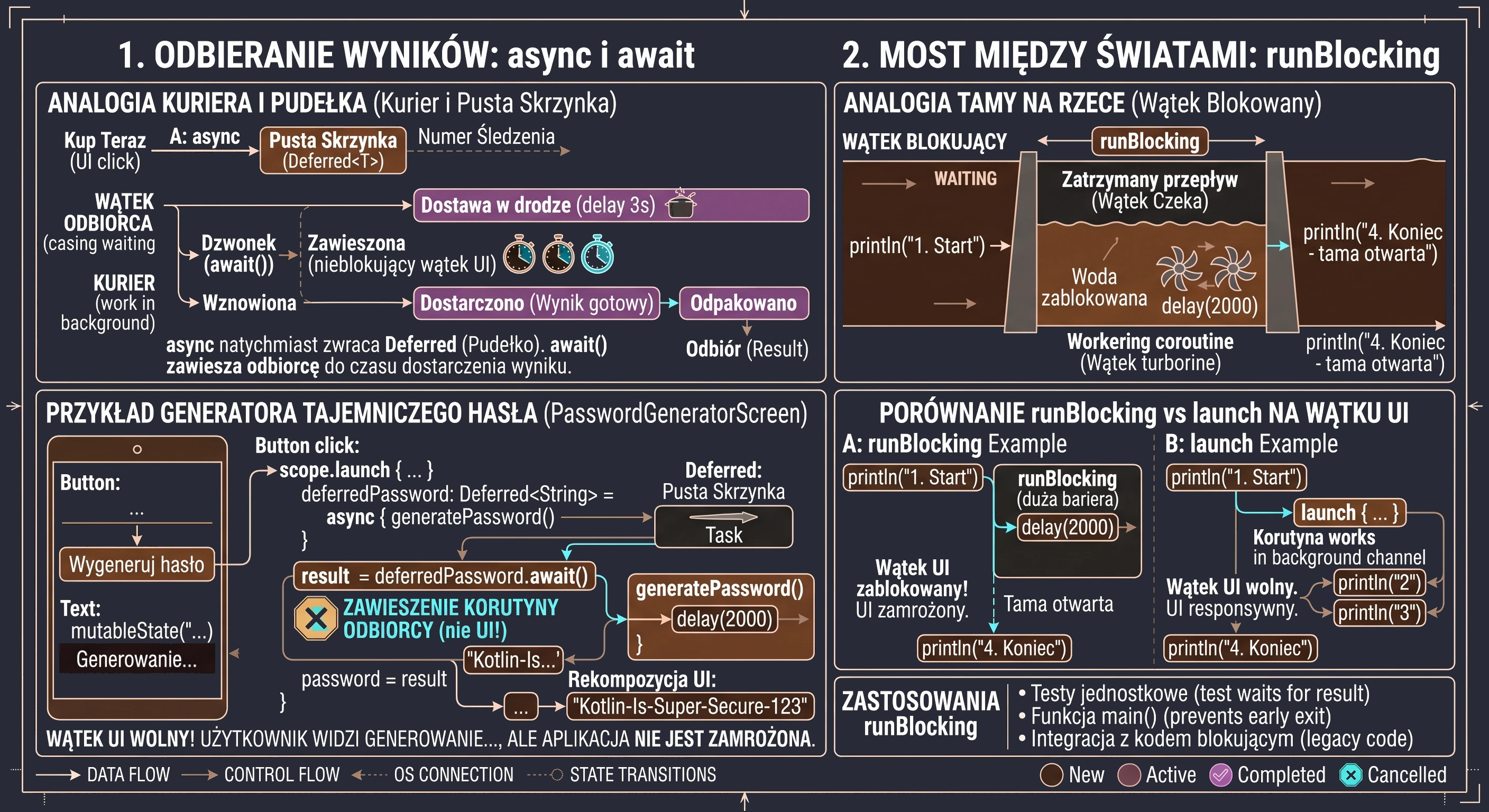
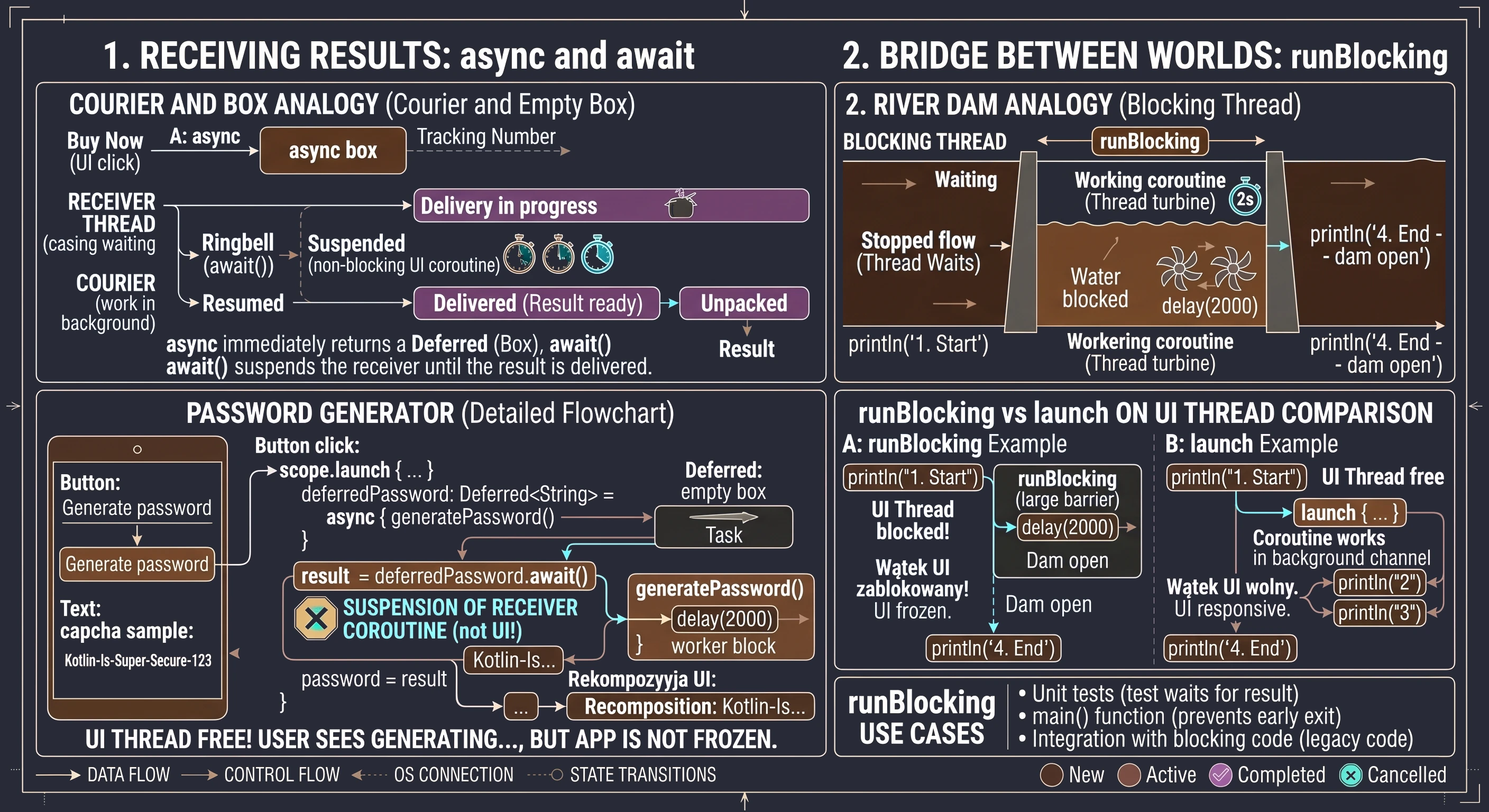
Zastosowanie
Ponieważ runBlocking blokuje wątek, wywołanie go na wątku UI spowoduje natychmiastowe zamrożenie interfejsu użytkownika na cały czas trwania operacji wewnątrz bloku. Jest to powrót do problemu, który korutyny miały rozwiązać.
Kiedy zatem jest to przydatne?
- Testy jednostkowe: W testach chcemy, aby proces testowy poczekał na wynik operacji asynchronicznej, zanim sprawdzi poprawność wyniku (asercję).
- Funkcja main(): W prostych programach konsolowych Kotlin, gdzie musimy zatrzymać program przed zamknięciem, dopóki korutyny nie skończą pracy.
- Integracja z kodem blokującym: Gdy musimy wywołać kod asynchroniczny wewnątrz biblioteki, która nie wspiera korutyn i wymaga natychmiastowego zwrotu wartości.
Porównanie mechanizmów
Poniższy przykład pokazuje, jak runBlocking wpływa na przepływ programu w porównaniu do launch.
fun runBlockingExample() {
println("1. Start programu")
// Ten blok zatrzyma wątek na 2 sekundy!
runBlocking {
println("2. Wewnątrz runBlocking - start")
delay(2000)
println("3. Wewnątrz runBlocking - koniec")
}
println("4. Koniec programu - ta linia czekała na tamę")
}W powyższym kodzie napis 4. Koniec programu pojawi się dopiero po 2 sekundach. Gdybyśmy zamiast runBlocking użyli launch (w odpowiednim scope), napis 4 pojawiłby się natychmiast po napisie 2, ponieważ rzeka płynęłaby dalej, podczas gdy korutyna pracowałaby obok.
Problem Monolitycznego Kodu
Na początku przygody z Jetpack Compose naturalnym odruchem jest pisanie całego kodu wewnątrz funkcji @Composable. Skoro UI to tylko funkcja, dlaczego nie umieścić w niej również pobierania danych z sieci czy logiki biznesowej?
Spójrzmy na kod, który działa, ale łamie zasady inżynierii oprogramowania. Nazywamy to antywzorcem "God Composable" - funkcją, która wie i robi wszystko.
// KROK 1: Kod "naiwny"
@Composable
fun UserProfileScreen() {
// Stan UI + Logika w jednym miejscu
var userData by remember { mutableStateOf("Ładowanie...") }
val scope = rememberCoroutineScope() // Scope powiązany z cyklem życia UI
Column {
Button(onClick = {
// Operacja sieciowa bezpośrednio w UI
scope.launch {
try {
val user = api.getUser() // Symulacja pobierania (2 sekundy)
userData = user.name.uppercase() // Logika biznesowa
} catch (e: Exception) {
userData = "Błąd!"
}
}
}) {
Text("Pobierz dane")
}
Text(userData)
}
}Uruchamiamy aplikację, klikamy przycisk, dane się pobierają. Wszystko wygląda świetnie. Do momentu, gdy obrócimy telefon. Android przy zmianie konfiguracji (np. obrót ekranu) niszczy i tworzy aktywność od nowa. Funkcja remember traci pamięć. Użytkownik, który czekał na dane, nagle znów widzi ekran początkowy Ładowanie....
Rozwiązanie tego problemu już znamy z poprzedniego semestru. Spróbujmy więc naprawić nasz kod:
// rememberSaveable
var userData by rememberSaveable { mutableStateOf("Ładowanie...") }Czy to rozwiązuje problem? Tylko pozornie i tylko w trywialnych przypadkach. Gdy spróbujemy zastosować to w większej aplikacji, napotkamy trzy krytyczne problemy, których rememberSaveable nie rozwiąże:
- Śmierć Korutyny:
rememberCoroutineScopejest ściśle powiązany z widokiem. Gdy obracasz ekran w trakcie pobierania danych (np. wolne WiFi), stary widok ginie, a wraz z nim anulowana jest korutyna. Pobieranie zostaje przerwane w połowie. Nowy ekran powstaje, ale nic nie wie o tym, że poprzedni coś pobierał. Użytkownik klika, czeka i nic nie dostaje. - Ograniczenia Pamięci (Bundle):
rememberSaveablezapisuje dane w systemowymBundle. Jest on przeznaczony dla małych danych (tekst, liczby). Jeśli spróbojemy tam zapisać listę 500 obiektów JSON pobranych z API, aplikacja wyrzuci błądTransactionTooLargeExceptioni się zamknie. - Testowalność: Jak przetestować, czy nazwisko jest poprawnie zamieniane na wielkie litery? W obecnym kodzie jest to niemożliwe bez uruchamiania emulatora, bo logika jest zabetonowana wewnątrz przycisku.
Dochodzimy do wniosku, że funkcja Composable nie jest odpowiednim miejscem na trzymanie danych ani wykonywanie operacji. Potrzebujemy miejsca, które:
- Przeżyje rotację ekranu (nie jak
rememberSaveable). - Pozwoli korutynom dokończyć pracę, nawet gdy widok jest niszczony.
- Nie ma limitu wielkości danych (nie jak
Bundle).
Aby zrozumieć potrzebę architektury, posłużmy się analogią budowlaną:
- Budowanie budy dla psa (Brak architektury): Możesz to zrobić sam. Jeśli wbijesz gwóźdź w złym miejscu, łatwo to poprawić. To są małe, proste aplikacje.
- Budowanie wieżowca (Z architekturą): Tutaj potrzebujesz planu. Elektryk (Data Layer) nie maluje ścian, a malarz (UI Layer) nie kładzie instalacji gazowej. W dużym projekcie, jeśli Composable zajmuje się logiką API, to tak jakby malarz próbował naprawiać windę.
Potrzebujemy więc Kierownika Budowy, który ma plany w biurze (bezpiecznym od remontów) i zarządza pracami. Tym kierownikiem będzie komponent, który za chwilę poznamy.
Ewolucja Wzorców Architektonicznych
Skoro wiemy już, że wrzucanie wszystkiego do jednego worka ("God Composable") jest nie najlepszym rozwiązaniem, musimy zastanowić się, jak podzielić aplikację. W inżynierii oprogramowania ten problem nie jest nowy. Przez dekady wykształciło się wiele różnych podejść do tego problemu. Jednym z nich jest rodzina wzorców MVx, które różnią się sposobem, w jaki warstwa danych komunikuje się z warstwą wizualną.
Aby zrozumieć różnice między nimi, posłużymy się prostymi analogiami.
MVC (Model-View-Controller)
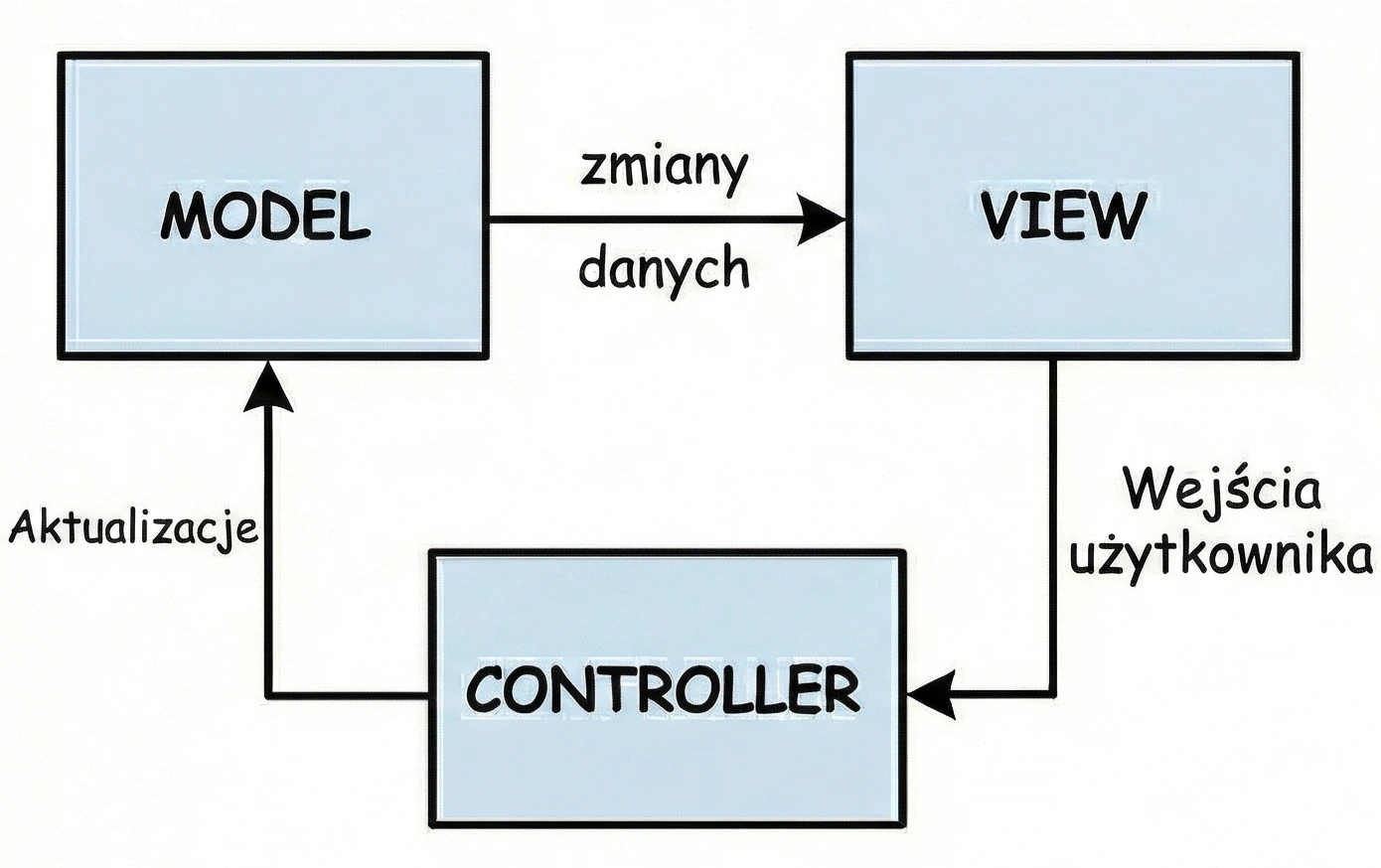
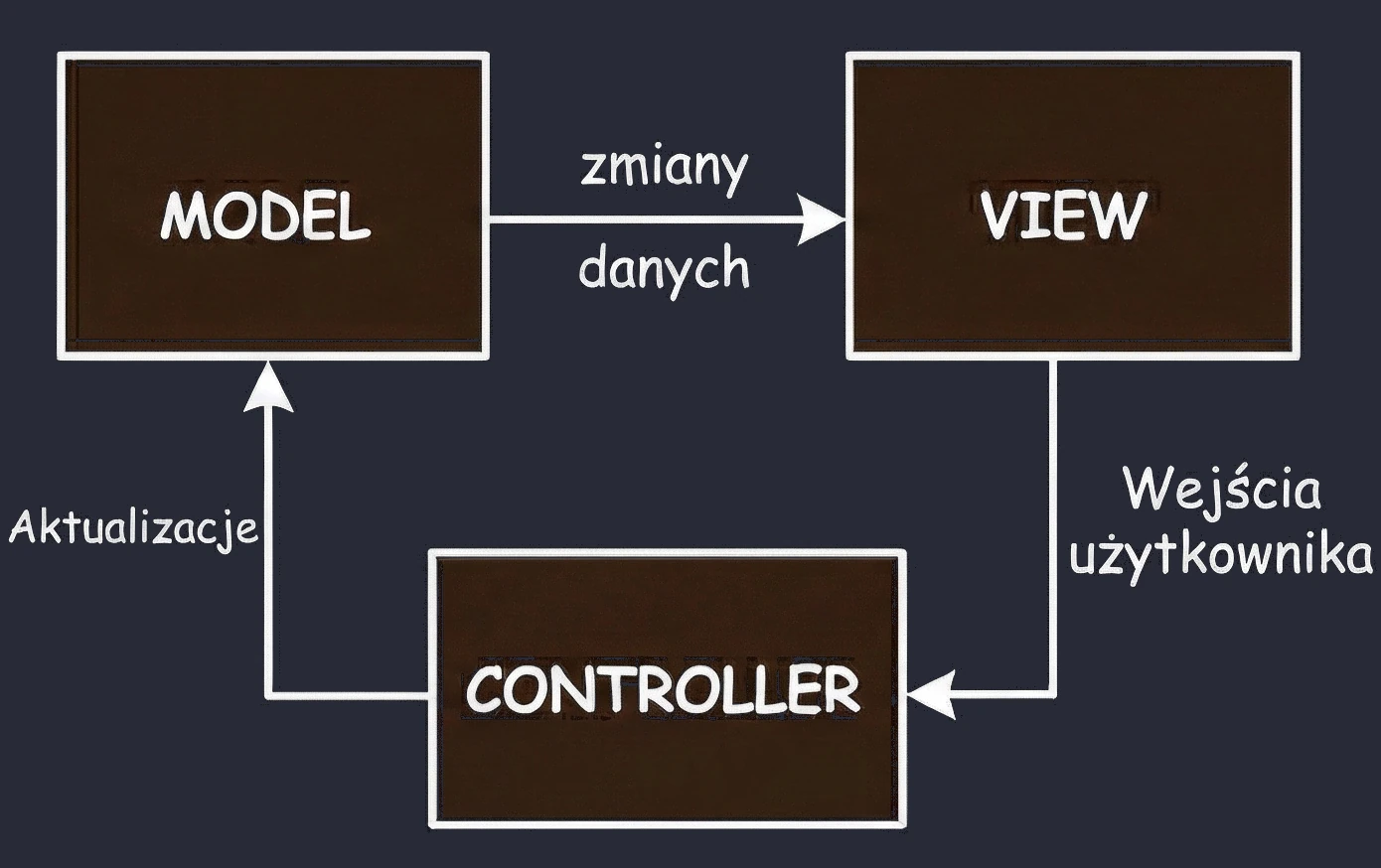
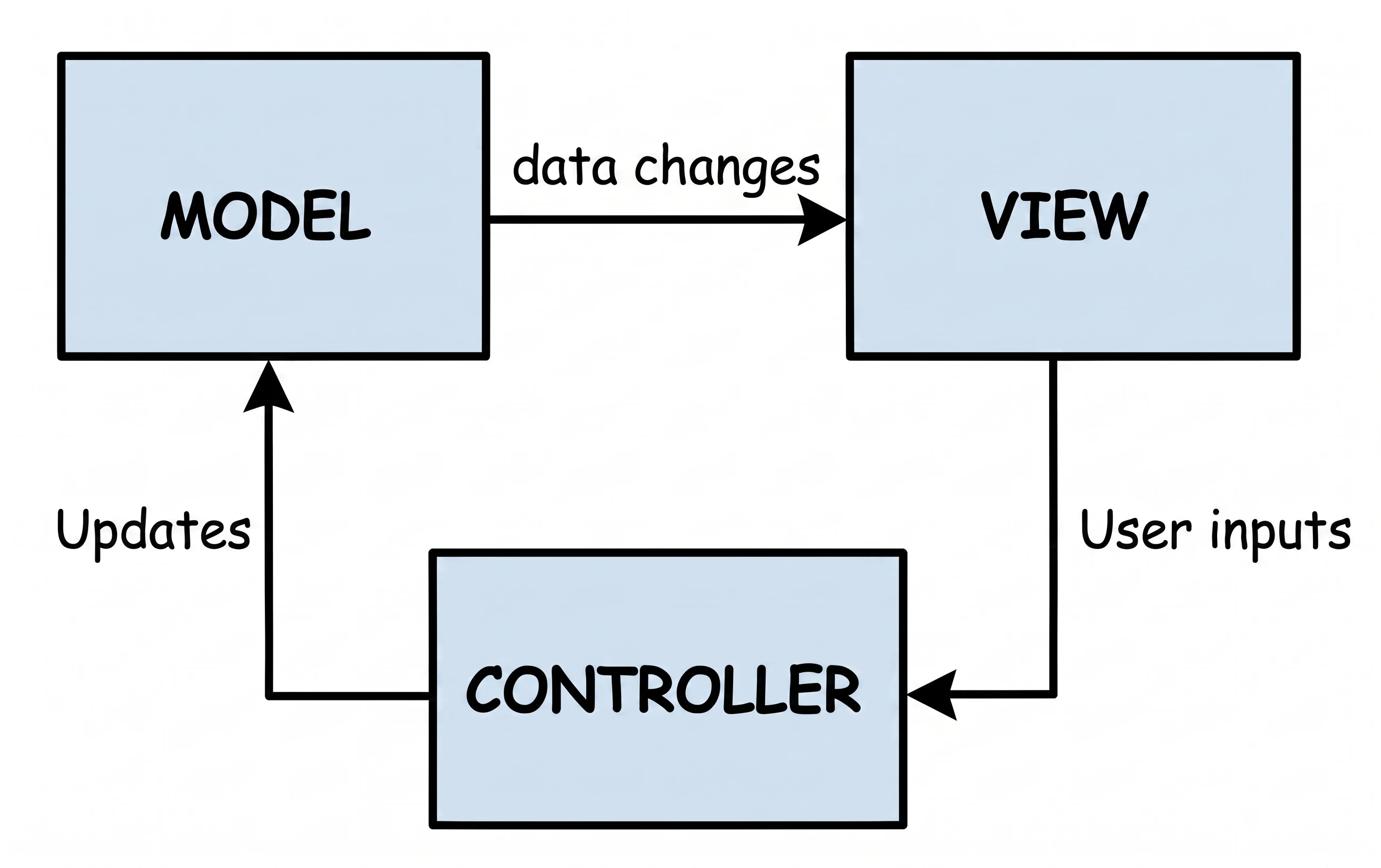
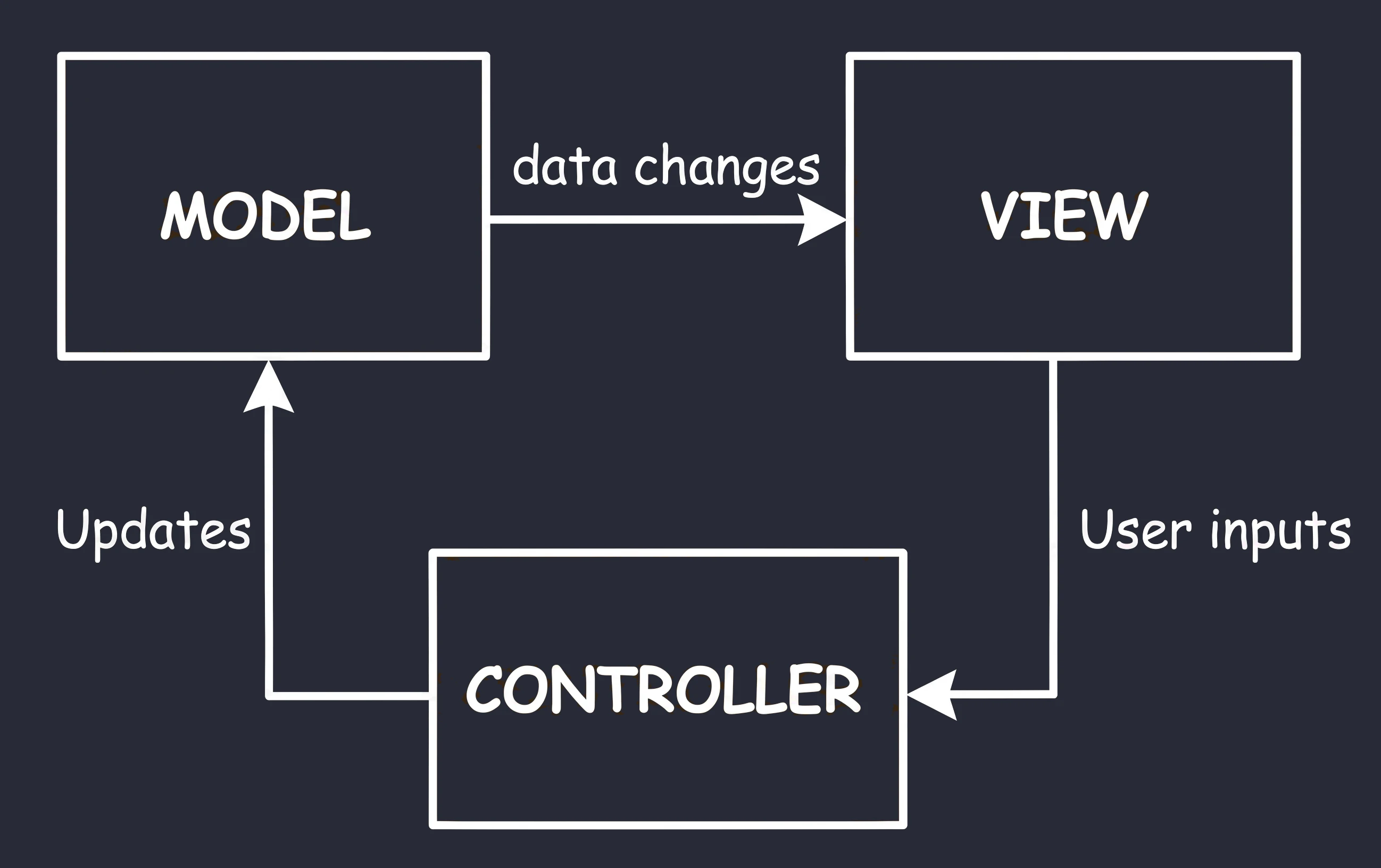
Jest to najstarsze podejście, które można porównać do wizyty w tradycyjnym sklepie, gdzie towar podaje sprzedawca.
- Ty (View): Stoisz przed ladą. Widzisz towar, ale jesteś pasywny - nie możesz go sam wziąć.
- Sprzedawca (Controller): To on rządzi procesem. Mówisz mu: Poproszę chleb (Interakcja).
- Magazyn (Model): Sprzedawca idzie na zaplecze, sprawdza stan magazynowy i bierze towar.
Wniosek: W tym układzie Sprzedawca (Controller) decyduje o wszystkim. To on musi wiedzieć, jak wygląda magazyn i to on decyduje, co pokazać klientowi. Musi też być w stanie wskazać konkretnego klienta, któremu musi wydać towar.
MVP (Model-View-Presenter)
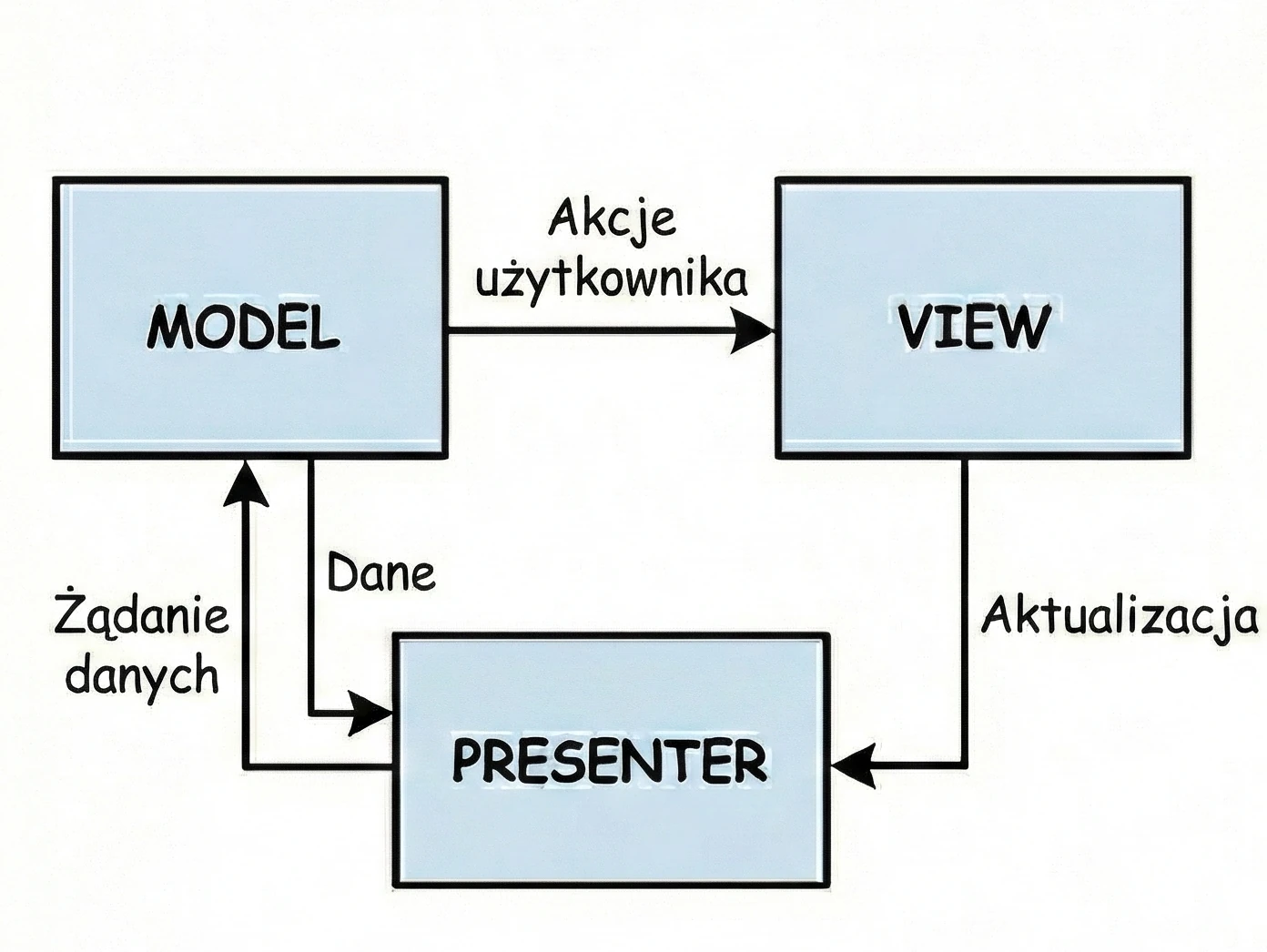
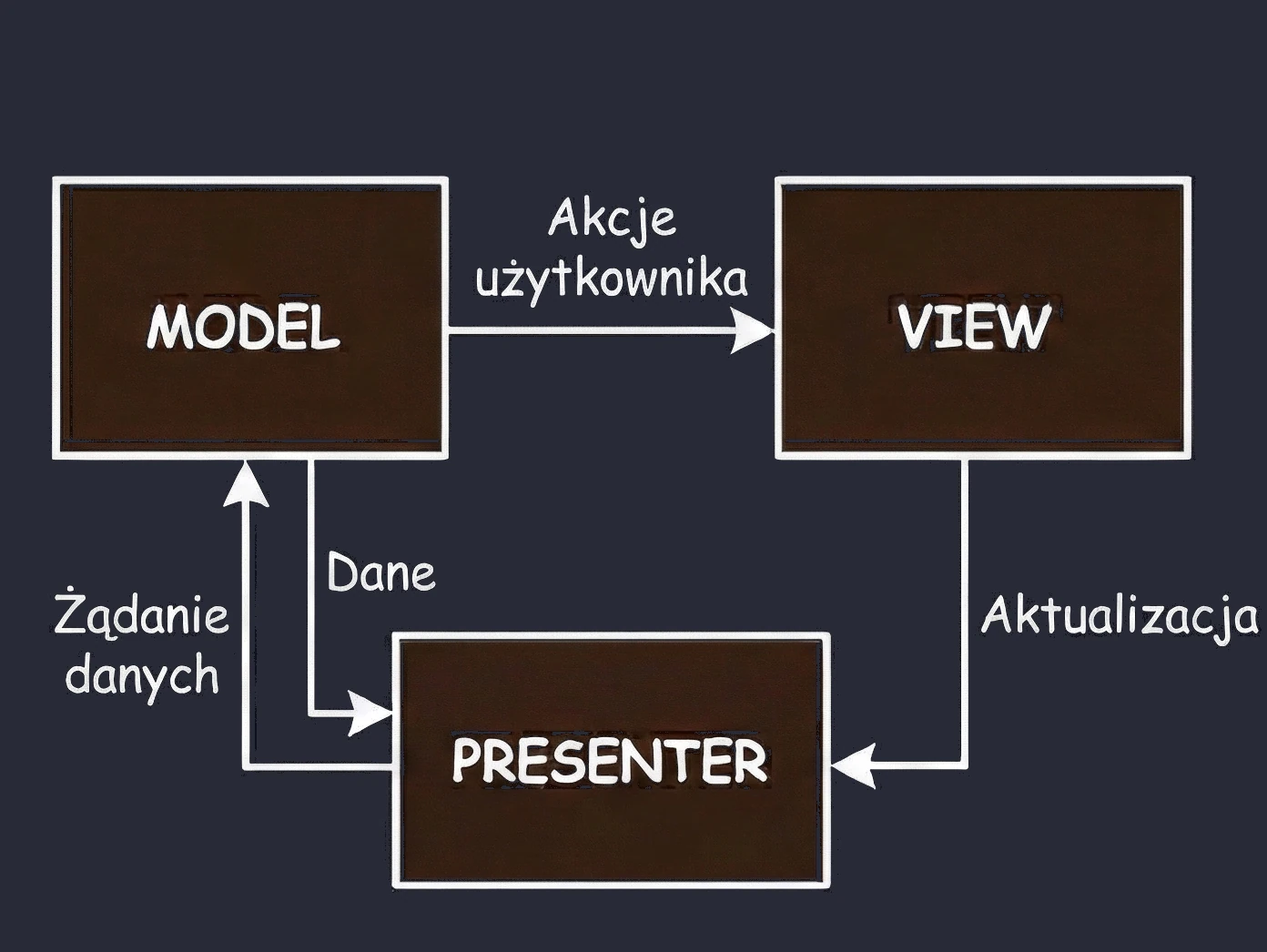
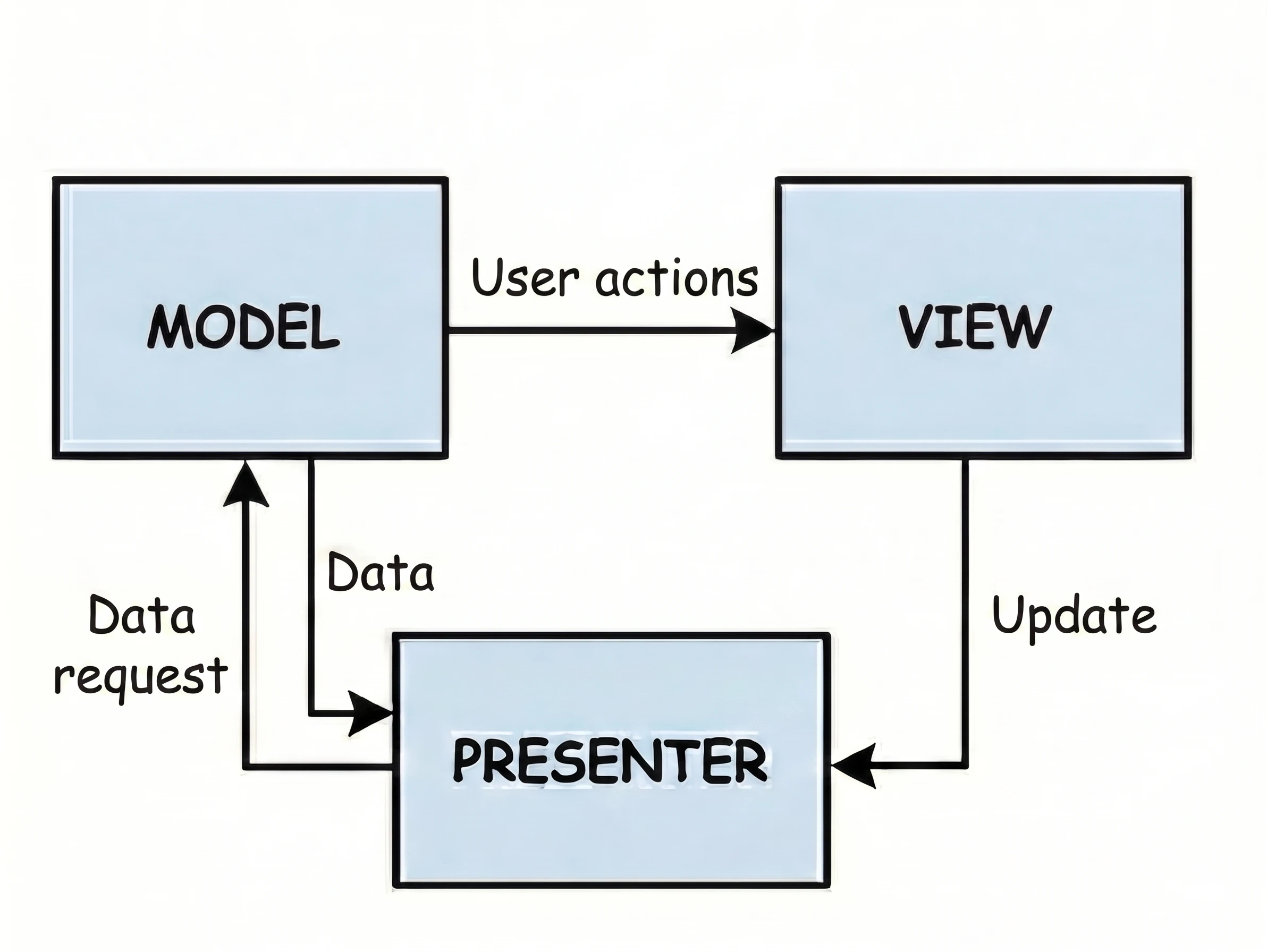
Druga odmiana wzorca z rodziny MVx.
- Klient przy stoliku (View): Siedzisz i czekasz. Nie wiesz i nie interesuje Cię, co się dzieje w kuchni.
- Kelner (Presenter): Przyjmuje zamówienie i idzie do kuchni (Model).
- Kluczowa cecha: Kelner wraca z kuchni i własnoręcznie stawia talerz na Twoim stole.
W kodzie wygląda to tak, że Presenter (Kelner) posiada referencję do Widoku (Klienta). Wywołuje na nim konkretną metodę, np. view.showDinner(). Problem: Jest to sztywne połączenie 1:1. Kelner musi znać konkretny stolik. Jeśli Klient wyjdzie do toalety (Rotacja Ekranu/Zniszczenie Widoku), a Kelner wróci z talerzem i spróbuje go postawić na pustym miejscu, dojdzie do błędu (NullPointerException) - klient musi być dostępny.
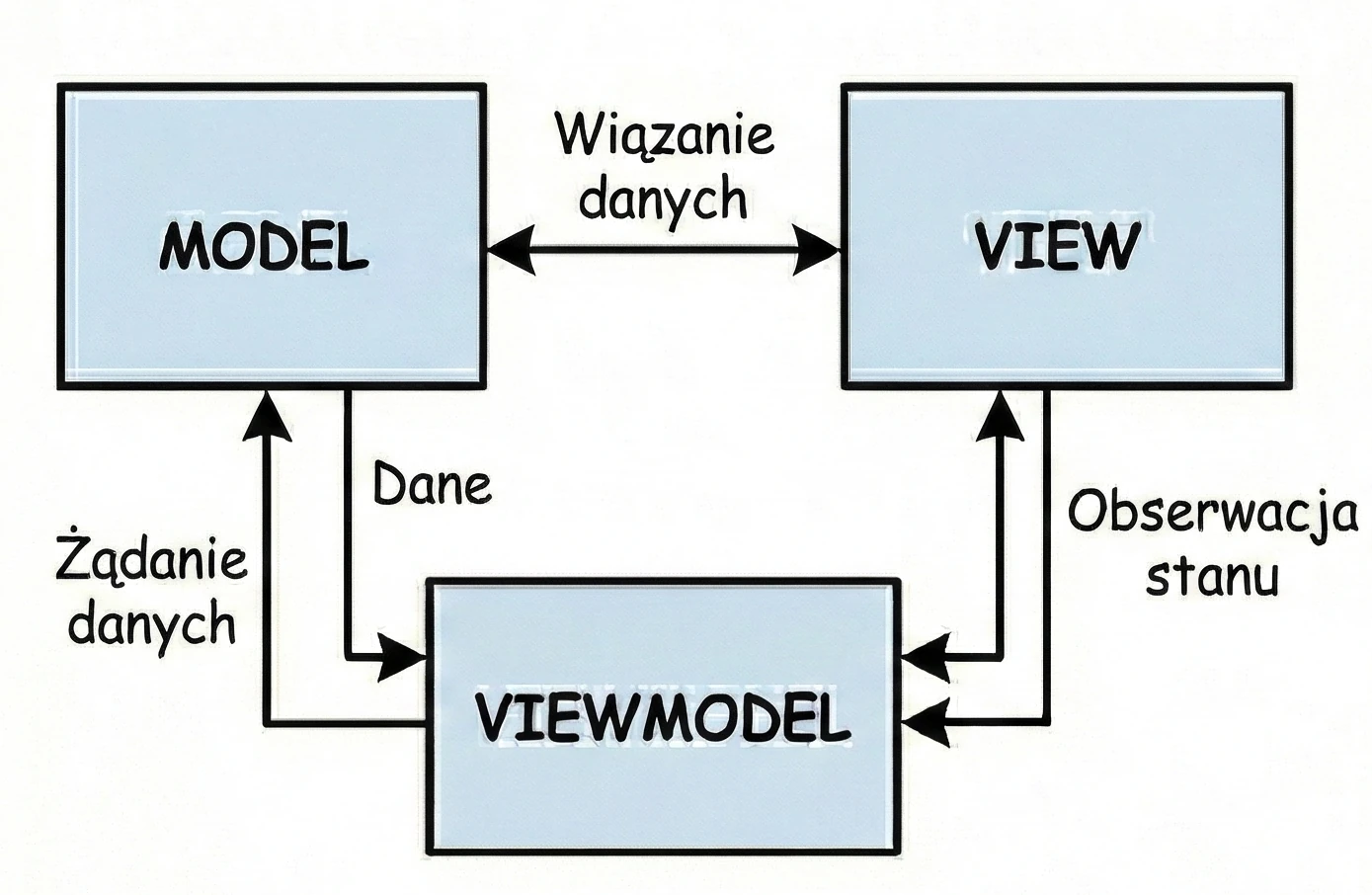
MVVM (Model-View-ViewModel)
To podejście jest często wykorzystywane we współczesnym Androidzie.
- Użytkownik (View): Podchodzi do maszyny i naciska przycisk (Wysyła Event).
- Automat (ViewModel): Odbiera sygnał, mieli kawę, pobiera wodę (komunikuje się z Repozytorium/Modelem).
- Wynik (State): Automat wystawia kubek z kawą do szuflady odbiorczej (Emisja stanu).
Kluczowa różnica - Reaktywność: Automatu nie obchodzi, kto ten kubek weźmie.
- Automat tylko wystawia stan.
- Jeśli nikt nie stoi przed maszyną - kubek (dane) po prostu czeka w szufladzie.
- Jeśli użytkownik odejdzie (obróci ekran) i przyjdzie nowy (
Activityzostanie stworzone na nowo) - kubek z kawą nadal tam jest. Nowy widok po prostu zagląda do szuflady i widzi gotowy napój.
W Compose tą szufladą są strumienie danych, takie jak StateFlow. ViewModel aktualizuje StateFlow, a Widok (Composable) jedynie nasłuchuje zmian. To rozwiązuje nasz problem z rotacją ekranu - ViewModel trzyma napój, niezależnie od tego, co dzieje się z klientem.
MVI (Model-View-Intent)
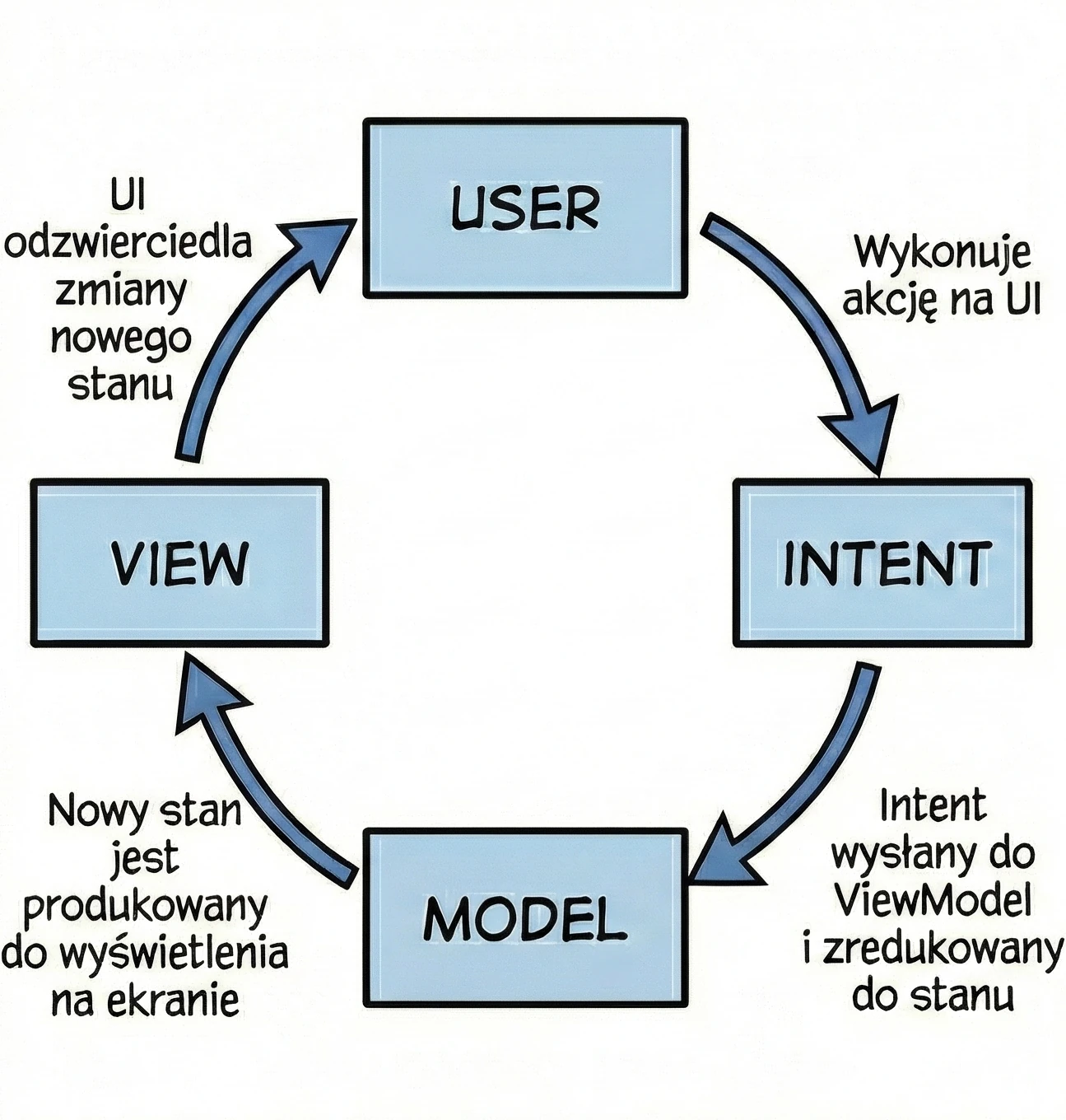
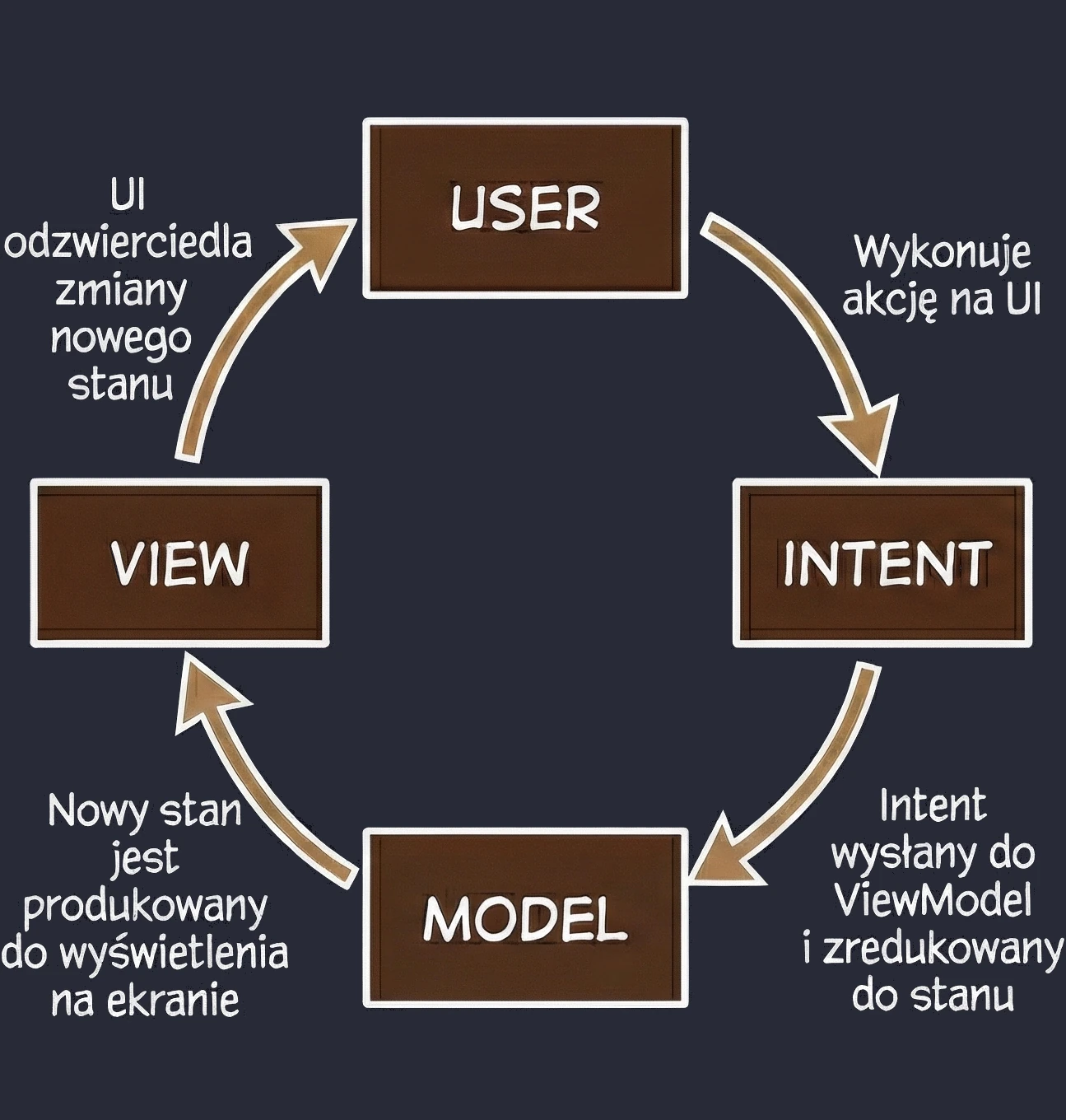
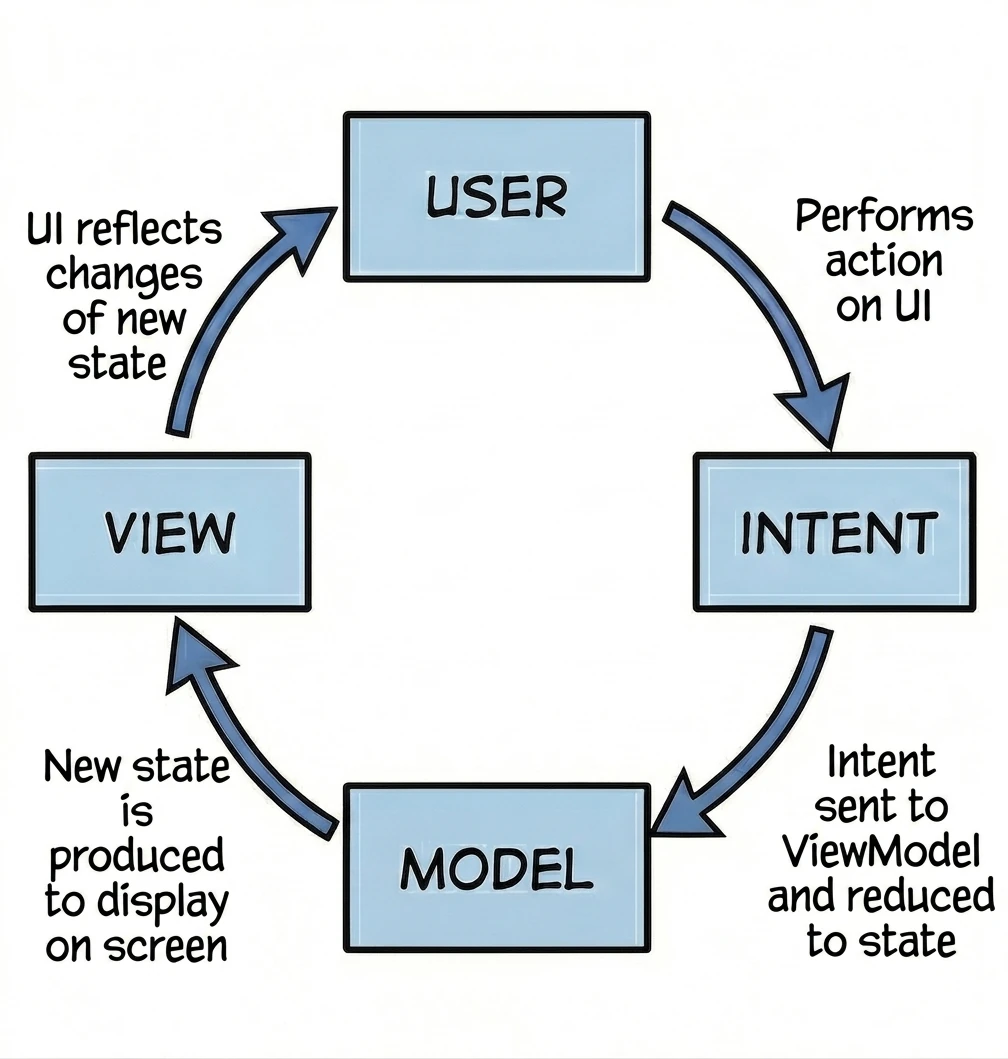
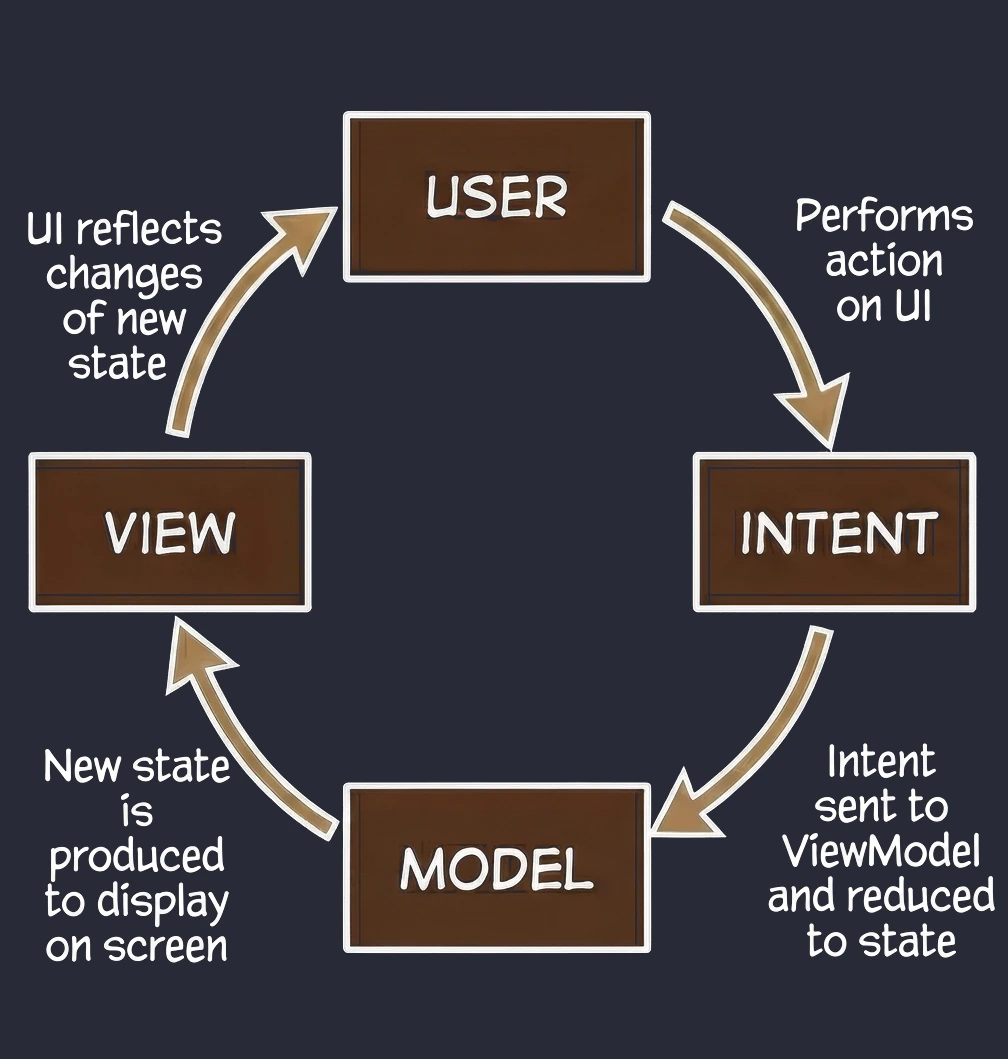
Jest to ewolucja wzorca MVVM, która kładzie rygorystyczny nacisk na jednokierunkowy przepływ danych (Unidirectional Data Flow).
- View (Ekran kiosku): Wyświetla aktualny stan zamówienia. Jest to tylko odczyt.
- Intent (Zamiar/Akcja): Gdy klikasz Dodaj frytki, nie zmieniasz bezpośrednio zamówienia. Wysyłasz do systemu zamiar (Intent) o treści: "Użytkownik chce dodać frytki".
- Model (System): System bierze Twój aktualny paragon, bierze Twój zamiar, przetwarza je i wypluwa zupełnie nowy, zaktualizowany paragon (State).
Kluczowa cecha - Cykliczność i Niezmienność: W przeciwieństwie do MVVM, gdzie ViewModel może mieć wiele różnych strumieni danych (osobno imię, osobno lista, osobno błędy), w MVI dążymy do posiadania jednego obiektu stanu (np. OrderUiState). W naszej metaforze: Nie możesz wziąć długopisu i dopisać frytek do wydrukowanego paragonu. Musisz wysłać żądanie, a system wydrukuje Ci nowy, zaktualizowany paragon. To zapewnia przewidywalność aplikacji - zawsze wiemy, co doprowadziło do obecnego stanu ekranu.
Naturalnie dążymy do MVI, używając pojedynczego StateFlow<UiState> w ViewModelu.
Implementacja MVVM: Analiza Techniczna
W tej sekcji przeanalizujemy implementację wzorca MVVM na prostym przykładzie. Skupimy się na separacji warstw oraz mechanizmie zachowania stanu przy zmianach konfiguracji.
Klasa ViewModel pełni rolę zarządcy stanu. Zwróćmy uwagę na wzorzec Backing Property, który zapewnia pełną enkapsulację danych.
class WordViewModel : ViewModel() {
// 1. Stan wewnętrzny (Mutable) - prywatny
// Używamy mutableStateListOf, który jest implementacją SnapshotStateList.
// Dzięki temu Compose śledzi zmiany i wymusza rekompozycję.
private val _words = mutableStateListOf("Witaj", "Świecie", "Jetpack")
// 2. Stan publiczny (Immutable) - tylko do odczytu
// Widok widzi tylko List<String>. Nie może jej modyfikować bezpośrednio.
// To wymusza Unidirectional Data Flow.
val words: List<String> get() = _words
// 3. Interfejs publiczny (Actions/Events)
// Jedyny sposób na zmianę stanu to wywołanie metody w ViewModelu.
fun addWord(newWord: String) {
_words.add(newWord)
}
fun clearList() {
_words.clear()
}
}Zastosowanie mutableStateListOf zamiast standardowego List jest krytyczne dla reaktywności. W Jetpack Compose system nie obserwuje standardowych kolekcji Javy/Kotlina. Typy ze świata Compose (jak State<T>) implementują wzorzec Obserwatora, automatycznie powiadamiając subskrybentów (funkcje Composable) o zmianach.
Widok (Composable) staje się tzw. Passive View. Nie posiada własnego stanu logicznego, a jedynie renderuje to, co dostarczy ViewModel.
@Composable
fun WordScreen(
// Wstrzykiwanie zależności (Dependency Injection)
// Funkcja viewModel() wykorzystuje ViewModelProvider do pobrania instancji.
viewModel: WordViewModel = viewModel()
) {
Column {
// Odczyt stanu (State Observation)
LazyColumn {
items(viewModel.words) { word ->
Text(text = word, style = MaterialTheme.typography.headlineSmall)
}
}
// Delegacja zdarzeń (Event Propagation)
Button(onClick = {
viewModel.addWord("Nowe Słowo")
}) {
Text("Dodaj element")
}
}
}Aby skorzystać z funkcji viewmodel() musimy dodać odpowiednią zależność do bloku dependencies w pliku konfiguracyjnym projektu.
implementation("androidx.lifecycle:lifecycle-viewmodel-compose:2.9.2")Kluczową zaletą ViewModelu jest przetrwanie rotacji ekranu. Nie dzieje się to jednak w sposób magiczny, lecz wynika z architektonicznego cyklu życia komponentów Androida.
Możemy myśleć o ViewModelu jak o Singletonie zakresowym (Scoped Singleton).
- ViewModelStore: Każda Aktywność posiada obiekt
ViewModelStore. Jest to mapa (HashMap), która przechowuje instancje ViewModeli. - Zmiana Konfiguracji (np. Rotacja):
- Rekonstrukcja (Re-attach):
- Provider zagląda do zachowanego
ViewModelStore. - Znajduje tam istniejącą instancję
WordViewModel(tę samą, która istniała przed obrotem). - Zwraca tę instancję do nowej Aktywności.
Gdy użytkownik obraca ekran, system operacyjny niszczy obiekt Activity i tworzy nowy. Jednakże, obiekt ViewModelStore powiązany z tą aktywnością nie jest niszczony. Jest on cache'owany przez system w pamięci (w obiekcie NonConfigurationInstances).
Nowa instancja Activity startuje. Funkcja viewModel() prosi klasę ViewModelProvider o instancję WordViewModel.
Dzięki temu mechanizmowi, dane wewnątrz ViewModelu (nasza lista słów) pozostają w pamięci RAM nienaruszone, mimo że warstwa UI została całkowicie przebudowana. ViewModel ginie dopiero wtedy, gdy Aktywność zostanie trwale zakończona (np. przez przycisk Back lub finish()), co powoduje wywołanie metody onCleared() i wyczyszczenie ViewModelStore.
Warstwa Danych: Wzorzec Repozytorium
Do tej pory nasz ViewModel trzymał dane w pamięci. W większej aplikacji dane pochodzą z zewnętrznych źródeł: API (Retrofit), bazy danych SQL (Room), plików. Tutaj pojawia się pytanie: Czy ViewModel powinien wiedzieć, skąd pochodzą dane? Zgodnie z zasadą Separation of Concerns - absolutnie nie.
Wróćmy do metafory restauracji:
- ViewModel (Kelner): Chce po prostu otrzymać gotowe danie. Nie interesuje go, czy składniki są z targu, czy z lodówki.
- Repozytorium (Kuchnia/Magazyn): To tutaj zapadają decyzje skąd wziąć dane.
Aby uniezależnić ViewModel od konkretnego źródła danych, używamy interfejsu.
// Kontrakt: Mówi CO można zamówić, ale nie JAK to zdobyć
interface WordRepository {
suspend fun getWords(): List<String>
}W prostym przykładzie Repozytorium może wydawać się zbędną warstwą ("przekazywaczem"). Jednak w większych aplikacjach, które będziemy budować na kolejnych wykładach, Repozytorium pełni kluczowe funkcje:
- 1. Obsługa Trybu Offline (Caching):
- Jest internet: Pobierz dane z API, zapisz je w lokalnej bazie danych (Room), a następnie zwróć dane z bazy.
- Brak internetu: Zwróć dane zapisane w bazie z poprzedniej sesji.
- 2. Agregacja Danych:
- 3. Mapowanie i Czystość Danych:
To najważniejsze zastosowanie, zwane Single Source of Truth. Repozytorium może sprawdzać: Czy mamy internet?.
Dla ViewModelu ten proces jest niewidoczny - on po prostu prosi o dane i je dostaje, niezależnie od stanu sieci.
Często jeden ekran potrzebuje danych z wielu źródeł. Np. ekran Profilu może wymagać danych użytkownika (z endpointa /user) oraz listy ostatnich zamówień (z endpointa /orders). Repozytorium pobiera oba te zasoby równolegle (korzystając z async), łączy je w jeden obiekt UserProfile i dopiero taki gotowy produkt przekazuje ViewModelowi.
API często zwraca dane w formacie technicznym (brudnym), np. user_id_xq2, daty w formacie timestamp itp. Repozytorium służy jako obierak - przetwarza surowe obiekty JSON (DTO - Data Transfer Object) na czyste, czytelne obiekty domenowe, z których łatwo korzysta się w UI.
Problem Konstruktora z Parametrem: ViewModelFactory
Dotarliśmy do ostatniego wyzwania technicznego. Stworzyliśmy WordRepository i chcemy przekazać je do naszego WordViewModel.
Zmieniamy więc konstruktor:
class WordViewModel(private val repository: WordRepository) : ViewModel() { ... }I tu pojawia się problem. Gdy w kodzie Composable wywołamy standardową funkcję: val viewModel: WordViewModel = viewModel(), aplikacja wyrzuci błąd RuntimeException.
Funkcja biblioteczna viewModel() domyślnie potrafi tworzyć tylko obiekty posiadające pusty konstruktor (bez parametrów). Działa ona na zasadzie refleksji.
Aby to zrozumieć, wyobraźmy sobie salon samochodowy:
- ViewModel bez parametrów (Samochód z placu): Wchodzisz, mówisz Poproszę Passata, sprzedawca daje Ci kluczyki do standardowego modelu stojącego na parkingu. Proste i szybkie.
- ViewModel z Repozytorium (Zamówienie Specjalne): Mówisz Poproszę Passata, ale z silnikiem V6 (Repozytorium). Sprzedawca rozkłada ręce - nie ma takiego na placu. Musi wysłać zamówienie do Fabryki, podając dokładną specyfikację, jak ten samochód złożyć.
W programowaniu tą specyfikacją jest wzorzec Factory.
Musimy dostarczyć instrukcję obsługi, która powie systemowi: Jeśli ktoś poprosi Cię o WordViewModel, to najpierw stwórz Repozytorium, a potem włóż je do środka.
Współcześnie najczęściej implementujemy to za pomocą companion object wewnątrz klasy ViewModelu:
class WordViewModel(private val repository: WordRepository) : ViewModel() {
// ... kod ViewModelu ...
// Definicja Fabryki (Instrukcja tworzenia)
companion object {
val Factory: ViewModelProvider.Factory = object : ViewModelProvider.Factory {
@Suppress("UNCHECKED_CAST")
override fun <T : ViewModel> create(modelClass: Class<T>): T {
return WordViewModel(
// Ręczne Wstrzykiwanie Zależności (Manual DI)
repository = NetworkWordRepository()
) as T
}
}
}
}Metoda create to miejsce, w którym przejmujemy kontrolę nad tworzeniem obiektu. To my, a nie system, decydujemy, jaka implementacja repozytorium trafi do środka.
Teraz, gdy mamy już naszą fabrykę, musimy jej użyć w widoku. Zmieniamy wywołanie w funkcji WordScreen:
@Composable
fun WordScreen(
// Przekazujemy fabrykę jako parametr 'factory'
viewModel: WordViewModel = viewModel(factory = WordViewModel.Factory)
) {
// ... reszta kodu bez zmian ...
}Dzięki temu drobnemu dodatkowi, Android wie, jak skonstruować nasz złożony obiekt, zachowując jednocześnie wszystkie zalety cyklu życia ViewModelu (przeżycie rotacji ekranu).
„Czy musimy pisać taki boilerplate (nadmiarowy kod) dla każdego ekranu?”. Na tym etapie - tak. Jest to tzw. Manual Dependency Injection. Musimy rozumieć, jak obiekty są ze sobą łączone pod maską.
W Wykładzie 11 wprowadzimy bibliotekę Hilt. Zrobi ona dokładnie to samo, co my teraz ręcznie, ale automatycznie - za pomocą jednej adnotacji @HiltViewModel. Hilt wygeneruje ten kod fabryki za nas w czasie kompilacji.
Pełny kod przykładu: WordApp
Poniżej znajduje się kompletna implementacja omawianego w tym rozdziale przykładu. Kod łączy w sobie wszystkie poznane elementy: wzorzec Repozytorium (interfejs i implementacja), ViewModel z obsługą stanu i korutyn, Fabrykę (ViewModelProvider.Factory) oraz warstwę widoku w Jetpack Compose.
Możesz skopiować ten kod do jednego pliku (np. WordApp.kt) w swoim projekcie, aby przetestować działanie architektury MVVM.
// ---------------------------------------------------------
// 1. WARSTWA DANYCH (MODEL & REPOSITORY)
// ---------------------------------------------------------
// Kontrakt (Interfejs) - ViewModel wie tylko o tym
interface WordRepository {
suspend fun getWords(): List<String>
}
// Konkretna implementacja (Symulacja sieci)
class NetworkWordRepository : WordRepository {
override suspend fun getWords(): List<String> {
// Symulacja opóźnienia sieciowego (2 sekundy)
delay(2000)
return listOf("Architektura", "MVVM", "w", "Praktyce", "Jest", "Super")
}
}
// ---------------------------------------------------------
// 2. WARSTWA LOGIKI (VIEWMODEL)
// ---------------------------------------------------------
class WordViewModel(private val repository: WordRepository) : ViewModel() {
// Stan prywatny (mutable)
private val _words = mutableStateListOf<String>("Kliknij przycisk...")
// Stan publiczny (read-only)
val words: List<String> get() = _words
// Funkcja wywoływana przez Widok (Event)
fun loadData() {
viewModelScope.launch {
_words.clear()
_words.add("Ładowanie...")
// Pobranie danych z repozytorium (zawieszenie korutyny)
val newWords = repository.getWords()
_words.clear()
_words.addAll(newWords)
}
}
// Fabryka (ViewModel Factory) - Instrukcja tworzenia ViewModelu z parametrem
companion object {
val Factory: ViewModelProvider.Factory = object : ViewModelProvider.Factory {
@Suppress("UNCHECKED_CAST")
override fun <T : ViewModel> create(modelClass: Class<T>): T {
return WordViewModel(
repository = NetworkWordRepository() // Wstrzykiwanie zależności
) as T
}
}
}
}
// ---------------------------------------------------------
// 3. WARSTWA PREZENTACJI (VIEW / COMPOSE)
// ---------------------------------------------------------
@Composable
fun WordScreen(
// Wstrzyknięcie ViewModelu za pomocą Fabryki
viewModel: WordViewModel = viewModel(factory = WordViewModel.Factory)
) {
Column(modifier = Modifier.padding(16.dp)) {
// Przycisk wyzwalający akcję
Button(onClick = { viewModel.loadData() }) {
Text(text = "Pobierz słowa z serwera")
}
// Lista wyświetlająca stan
LazyColumn(modifier = Modifier.padding(top = 16.dp)) {
items(viewModel.words) { word ->
Text(text = "• $word")
}
}
}
}Strumienie
W poprzednich rozdziałach (szczególnie przy omawianiu Coroutines i MVVM) nauczyliśmy się pobierać dane z wykorzystaniem funkcji zawieszających (suspend). Typowa funkcja w naszym repozytorium wyglądała tak:
// Stare podejście: Zwróć i zapomnij
suspend fun getUserNames(): List<String> {
// 1. Wyślij zapytanie
// 2. Czekaj na odpowiedź
return listOf("Anna", "Jan", "Piotr") // 3. Zwróć wynik i zakończ funkcję
}To podejście ma jedną, zasadniczą wadę: jest jednorazowe. Funkcja zwraca wynik i kończy swoje działanie. Jeśli później na serwerze zarejestruje się nowy użytkownik ("Zofia"), nasza aplikacja o tym nie wie. Widok wyświetla nieaktualne dane, dopóki użytkownik ręcznie nie odświeży ekranu.
Współczesne aplikacje rzadko działają na danych statycznych. Większość funkcji, z których korzystamy na co dzień, to procesy rozciągnięte w czasie:
- Czat: Wiadomości przychodzą jedna po drugiej.
- GPS: Lokalizacja zmienia się z każdym krokiem użytkownika.
- Pobieranie pliku: Chcemy widzieć postęp (1%, 2%, ... 100%), a nie czekać ślepo na koniec.
- Giełda/Krypto: Ceny zmieniają się kilkadziesiąt razy na minutę.
Potrzebujemy mechanizmu, który nie zwraca jednej paczki danych, ale otwiera kanał, którym dane mogą płynąć tak długo, jak to konieczne.
Odpowiedzią na to zapotrzebowanie jest Flow (Strumień). Jest to asynchroniczny strumień danych, który emituje wartości sekwencyjnie.
Różnice między klasyczną listą a strumieniem są fundamentalne:
- List<T>: Dane są dostępne natychmiast, cała grupa na raz. Aby uzyskać nowe dane, musisz ponownie wywołać funkcję.
- Flow<T>: Dane są obliczane lub pobierane asynchronicznie i emitowane pojedynczo (lub grupami) w czasie. Aplikacja nasłuchuje zmian, zamiast o nie pytać.
Możemy zapytać: "Przecież używaliśmy mutableStateOf i UI też odświeżało się automatycznie. Po co nam Flow?". Choć oba mechanizmy są reaktywne, służą do czegoś innego:
- mutableStateOf (Stan UI): To kontener na aktualną wartość dla widoku. Mówi Compose: Przerysuj się, gdy to się zmieni. Jest ściśle związane z warstwą UI. Nie powinniśmy używać go w warstwie danych (Repozytorium), ponieważ uzależnilibyśmy logikę biznesową od biblioteki interfejsu.
- Flow (Transport Danych): To mechanizm przesyłania danych z warstw niższych (Baza Danych, Sieć) do ViewModelu. Jest to czysty Kotlin, niezależny od Androida. Posiada operatory (jak
map,filter,combine), które pozwalają obrabiać dane w locie.
Wzorzec architektury wygląda więc tak:
Repozytorium dostarcza strumień zmian (Flow), a ViewModel zamienia go na stabilny stan dla widoku (State).
Flow - Zimny Strumień
Podstawowy typ Flow w Kotlinie jest tzw. strumieniem zimnym (Cold Stream). Oznacza to, że kod produkujący dane (wewnątrz bloku flow { ... }) jest pasywny. Nie wykonuje się, dopóki ktoś nie zażąda danych.
Aby to zrozumieć, wyobraźmy sobie film w serwisie streamingowym (np. YouTube lub Netflix).
- Definicja Flow (Plik na serwerze): Film istnieje na serwerach YouTube. Ma swój scenariusz (klatki wideo następują po sobie). Jednak samo istnienie pliku nie powoduje, że film się odtwarza. Serwer nie zużywa zasobów na przesyłanie danych w pustkę.
- Operator
collect(Przycisk Play): Transmisja danych rozpoczyna się dopiero w momencie, gdy użytkownik kliknie Odtwarzaj. W świecie Flow odpowiednikiem tego przycisku jest funkcjacollect(). - Niezależność Widzów: To najważniejsza cecha. Jeśli trzech użytkowników włączy ten sam film:
- Użytkownik A kliknął "Play" minutę temu -> widzi 60. sekundę filmu.
- Użytkownik B klika "Play" teraz -> widzi 1. sekundę filmu (początek).
Każdy subskrybent otrzymuje swoją własną, niezależną kopię strumienia. Strumień startuje dla niego od zera.
Spójrzmy na przykład:
// 1. DEFINICJA (Przepis / Film na serwerze)
// Ten kod NIE wykonuje się w momencie przypisania do zmiennej!
val numberStream: Flow<Int> = flow {
println("Strumień wystartował!")
for (i in 1..3) {
delay(1000) // Symulacja pracy/pobierania
emit(i) // Emisja danych (klatka filmu)
}
}
// 2. UŻYCIE (Subskrybent 1)
scope.launch {
println("Widz 1 naciska PLAY")
numberStream.collect { value ->
println("Widz 1 otrzymał: $value")
}
}
// 3. UŻYCIE (Subskrybent 2 - po chwili)
scope.launch {
delay(1500)
println("Widz 2 naciska PLAY")
numberStream.collect { value ->
println("Widz 2 otrzymał: $value")
}
}Wynik w logach:
Widz 1 naciska PLAY
Strumień wystartował!
Widz 1 otrzymał: 1
Widz 2 naciska PLAY
Strumień wystartował! <-- Zauważ, że startuje drugi raz!
Widz 1 otrzymał: 2
Widz 2 otrzymał: 1 <-- Widz 2 otrzymuje pierwszą wartość,
mimo że Widz 1 jest już dalejSpójrzmy na wynik działania naszego programu. Logi ujawniają trzy mechanizmy działania Flow:
- Wielokrotny start (Re-ewaluacja):
- Niezależność Czasowa:
- Brak Pamięci (State):
Zauważmy, że komunikat "Strumień wystartował!" pojawia się w logach dwukrotnie.
Wniosek: Blok kodu przekazany do funkcji builder'a flow { ... } nie jest jednorazową inicjalizacją (jak konstruktor obiektu). Jest to instrukcja, która jest uruchamiana od nowa dla każdego subskrybenta.
Gdybyśmy wewnątrz tego bloku umieścili zapytanie HTTP, to przy 10 subskrybentach wykonalibyśmy 10 identycznych zapytań do serwera.
Gdy Widz 1 jest już w trakcie oglądania (otrzymuje liczbę 2), Widz 2 dopiero zaczyna i otrzymuje 1.
Wniosek: Subskrybenci nie dzielą między sobą postępu. Każde wywołanie collect() tworzy całkowicie niezależną instancję przepływu danych. To tak, jakby każdy z nich otworzył ten sam plik wideo w osobnym oknie odtwarzacza.
Gdy Widz 2 dołącza do strumienia, nie ma dostępu do danych, które zostały wyemitowane wcześniej. Strumień zimny nie przechowuje historii - on ją produkuje na bieżąco.
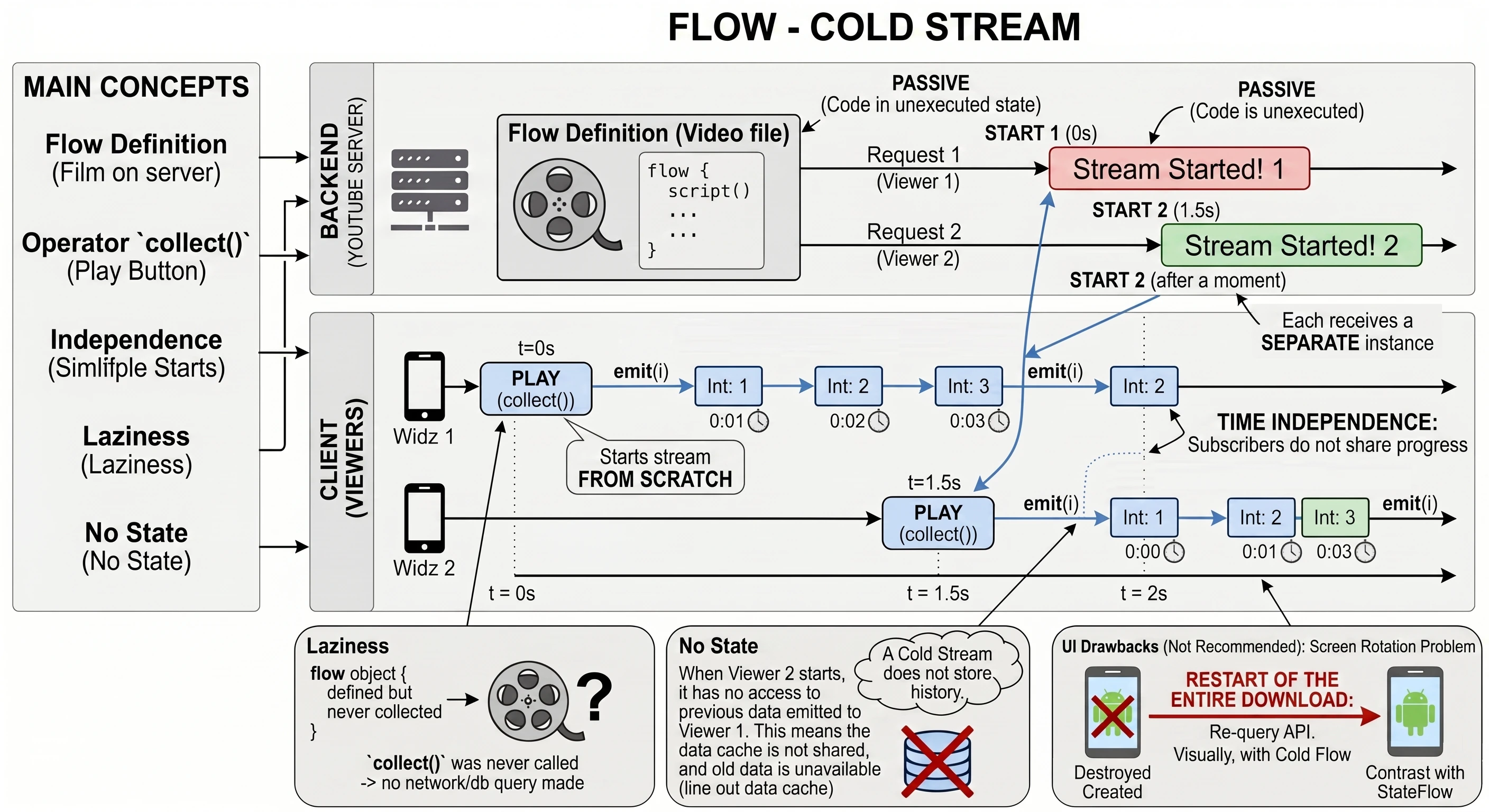
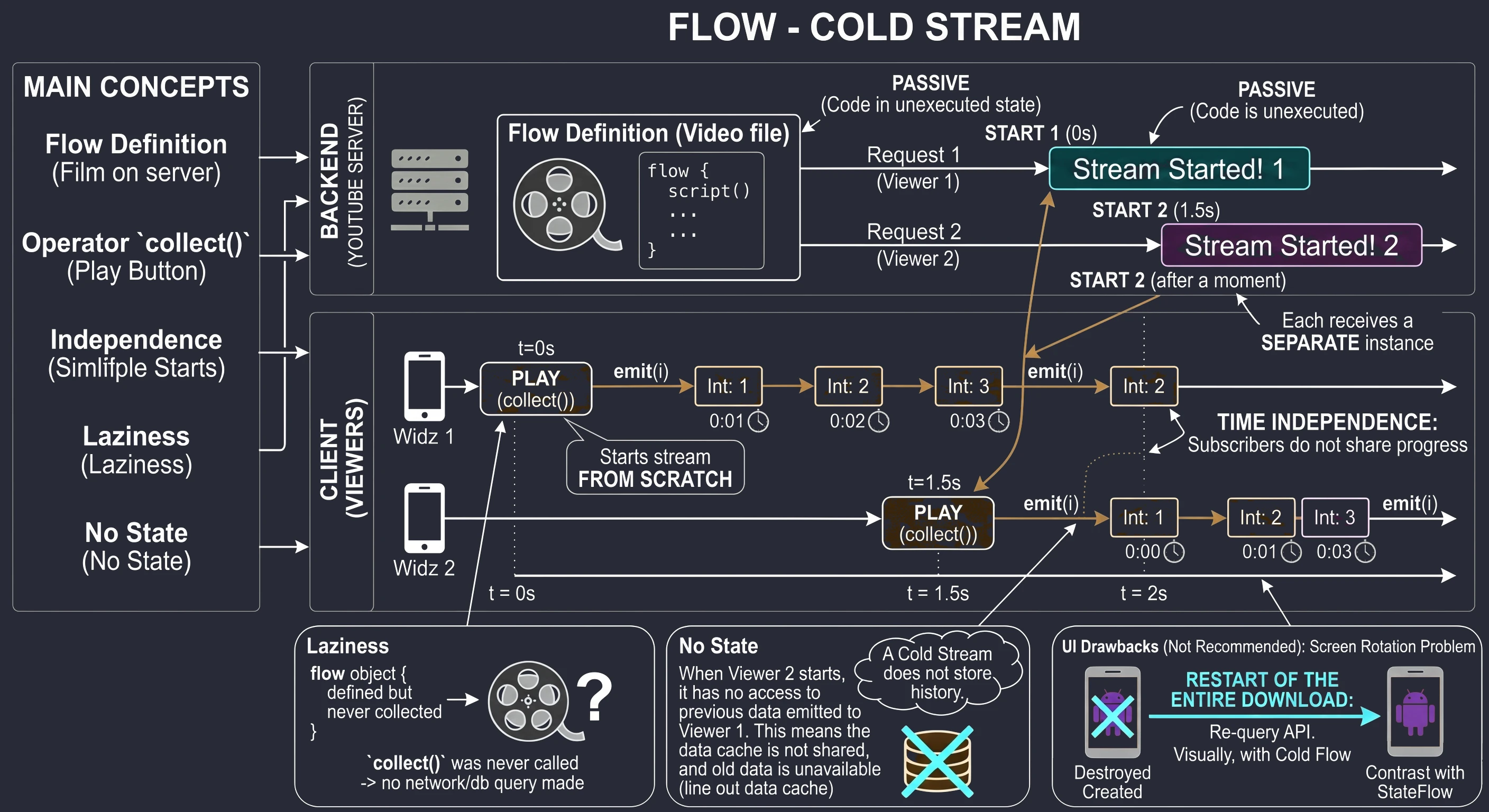
To zachowanie (restartowanie przy każdej subskrypcji) jest bardzo niebezpieczne w warstwie UI (Widoku). Wyobraź sobie, że użytkownik obraca telefon. System Android niszczy i tworzy na nowo Aktywność.
- Stara Aktywność przestaje nasłuchiwać (
cancel). - Nowa Aktywność zaczyna nasłuchiwać (
collect).
W przypadku zwykłego Flow, spowoduje to restart całego procesu pobierania danych (np. ponowne zapytanie do API). Aby tego uniknąć i trzymać dane między obrotami ekranu, potrzebujemy strumienia gorącego - StateFlow.
- Leniwość (Laziness): Jeśli stworzysz obiekt
Flow, ale nigdy nie wywołaszcollect, kod wewnątrzflow { ... }nigdy się nie wykona. Nie zostanie wysłane żadne zapytanie do sieci ani do bazy danych.
Pełny kod przykładu
Poniżej znajduje się kompletny kod demonstrujący koncepcję zimnego strumienia. Aplikacja pozwala symulować dołączanie nowych "widzów" (subskrybentów) do tego samego źródła danych.
Kod wizualizuje na ekranie logi, dzięki czemu widać moment startu strumienia dla każdego subskrybenta osobno.
// 1. Definicja Zimnego Strumienia ("Film na serwerze")
// Zauważ: Ta funkcja tylko zwraca przepis na strumień. Nie uruchamia go.
fun numberStream(log: (String) -> Unit): Flow<Int> = flow {
val time = SimpleDateFormat("HH:mm:ss", Locale.getDefault()).format(Date())
log("[$time] Strumień (re)startuje!")
for (i in 1..5) {
delay(1000) // Symulacja pobierania klatki filmu
emit(i) // Emisja danych
}
}
@Composable
fun ColdStreamScreen() {
// Lista do wyświetlania logów na ekranie
val logs = remember { mutableStateListOf<String>() }
// Helper do dodawania wpisów
fun addLog(msg: String) = logs.add(msg)
val scope = rememberCoroutineScope()
Column(modifier = Modifier.padding(16.dp)) {
Text("Demonstracja Zimnego Flow")
Spacer(Modifier.height(16.dp))
// Przycisk symulujący Widza 1
Button(onClick = {
scope.launch {
addLog("Widz 1 klika START")
// collect() uruchamia strumień OD ZERA
numberStream { msg -> addLog(msg) }.collect { value ->
addLog(" Widz 1 ogląda: $value")
}
}
}) {
Text("Dołącz jako Widz 1")
}
// Przycisk symulujący Widza 2
Button(onClick = {
scope.launch {
addLog("Widz 2 klika START")
// collect() uruchamia OSOBNĄ instancję strumienia
numberStream { msg -> addLog(msg) }.collect { value ->
addLog(" Widz 2 ogląda: $value")
}
}
}) {
Text("Dołącz jako Widz 2")
}
Spacer(Modifier.height(16.dp))
// Wyświetlanie logów
LazyColumn {
items(logs) { log ->
Text(text = log)
}
}
}
}StateFlow - Gorący Strumień
Wiemy już, że zwykły Flow jest strumieniem zimnym. Oznacza to, że każda subskrypcja uruchamia go od nowa. W kontekście warstwy danych (np. pobieranie pliku) jest to pożądane, ale w warstwie UI staje się poważnym problemem. W poprzednim rozdziale pojawił się przykład z wykorzystaniem Flow w warstwie UI i przypadku obrócenia urządzenia. Ponieważ Flow jest zimny, cały proces uruchamia się od początku. Potrzebujemy strumienia, który pamięta ostatnią wartość i działa niezależnie od tego, czy ktoś patrzy na ekran, czy nie. Takim strumieniem jest StateFlow. Różni się od zimnego dwoma kluczowymi cechami:
- Istnieje niezależnie od subskrybentów: Produkuje dane nawet wtedy, gdy nikt ich nie odbiera.
- Przechowuje stan (Replay = 1): Zawsze pamięta jedną, ostatnią wyemitowaną wartość. Nowy subskrybent otrzymuje ją natychmiast po podłączeniu.
Dobrą analogią dla StateFlow jest transmisja na żywo (Twitch):
- Streamer (ViewModel): Nadaje transmisję na żywo. Gra w grę, a licznik punktów i zdrowia zmienia się w czasie rzeczywistym. Transmisja trwa (dane płyną) niezależnie od tego, czy na kanale jest 1000 widzów, czy 0.
- Widz (Widok/UI):
- Gdy nowy widz wchodzi na kanał, nie ogląda transmisji od początku (jak filmu na YouTube).
- Widzi to, co dzieje się dokładnie w tej chwili (aktualny stan gry).
- Jeśli widz zminimalizuje aplikację Twitcha (aplikacja w tle) i wróci po minucie, zobaczy bieżącą akcję. To, co działo się przez tę minutę, przepadło (interesuje nas stan Live).
- Wspólny Obraz: Wszyscy widzowie oglądający ten sam kanał widzą dokładnie ten sam stan (np. ten sam obraz transmisji) w tym samym momencie.
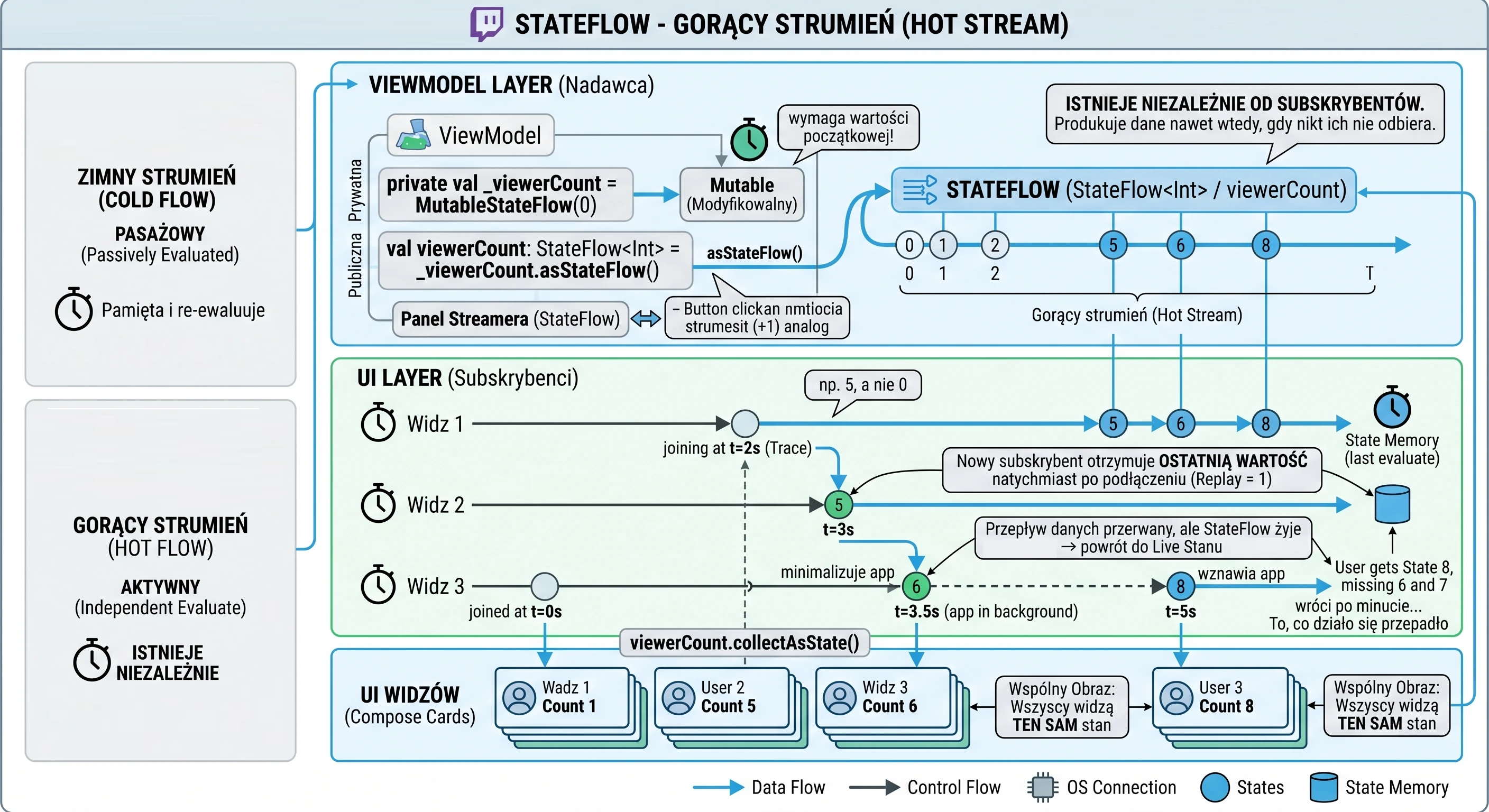
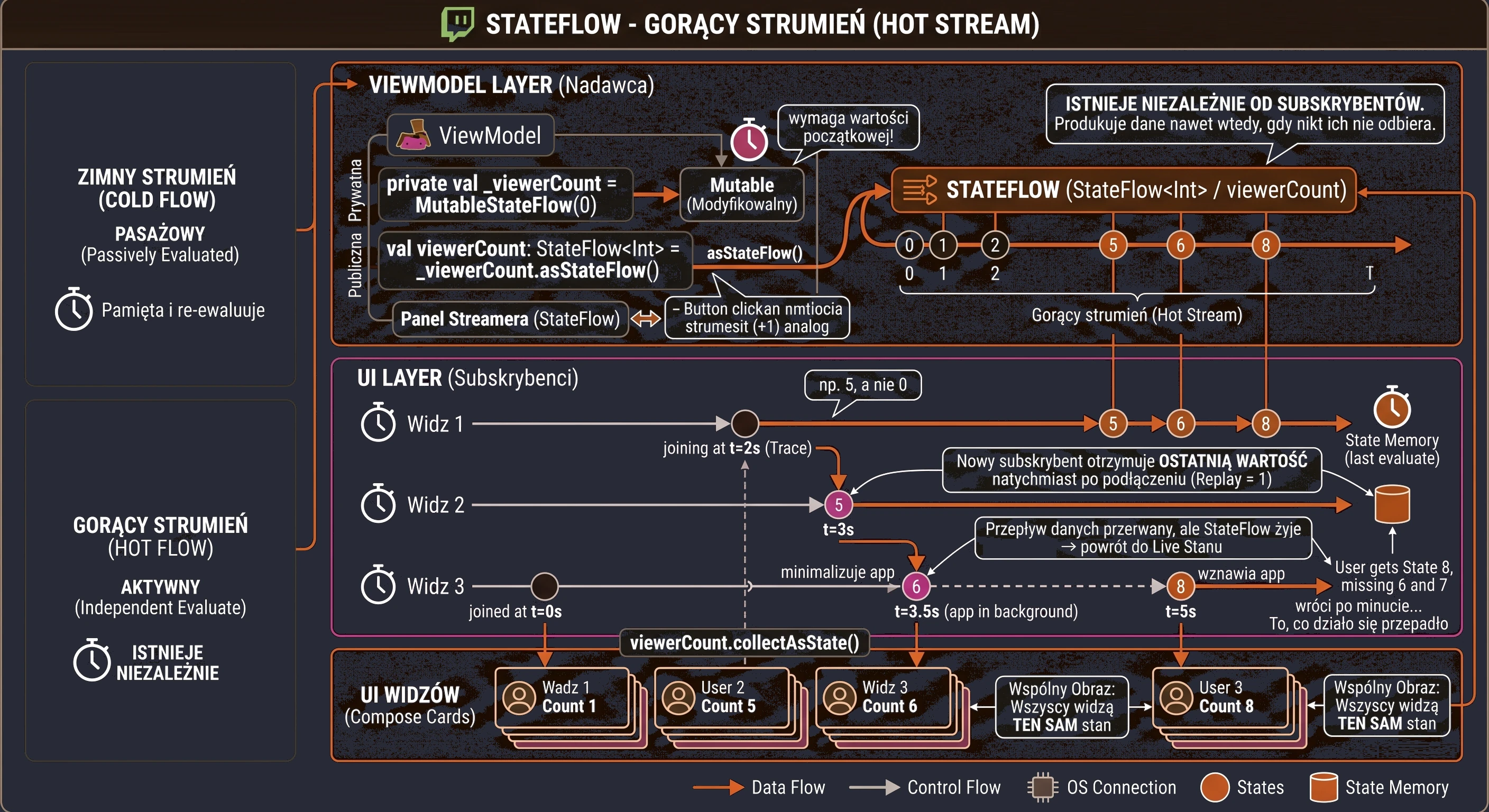
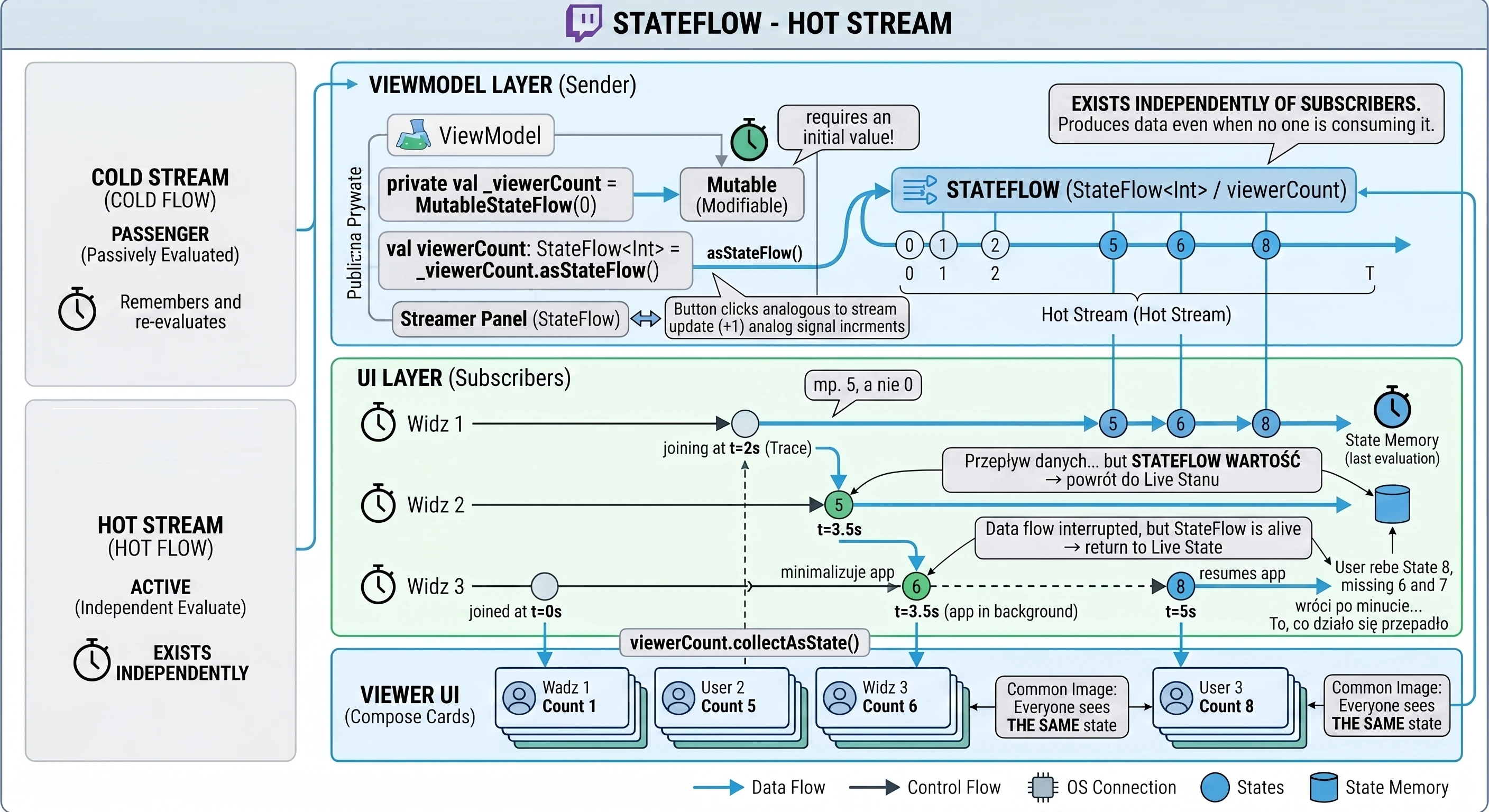
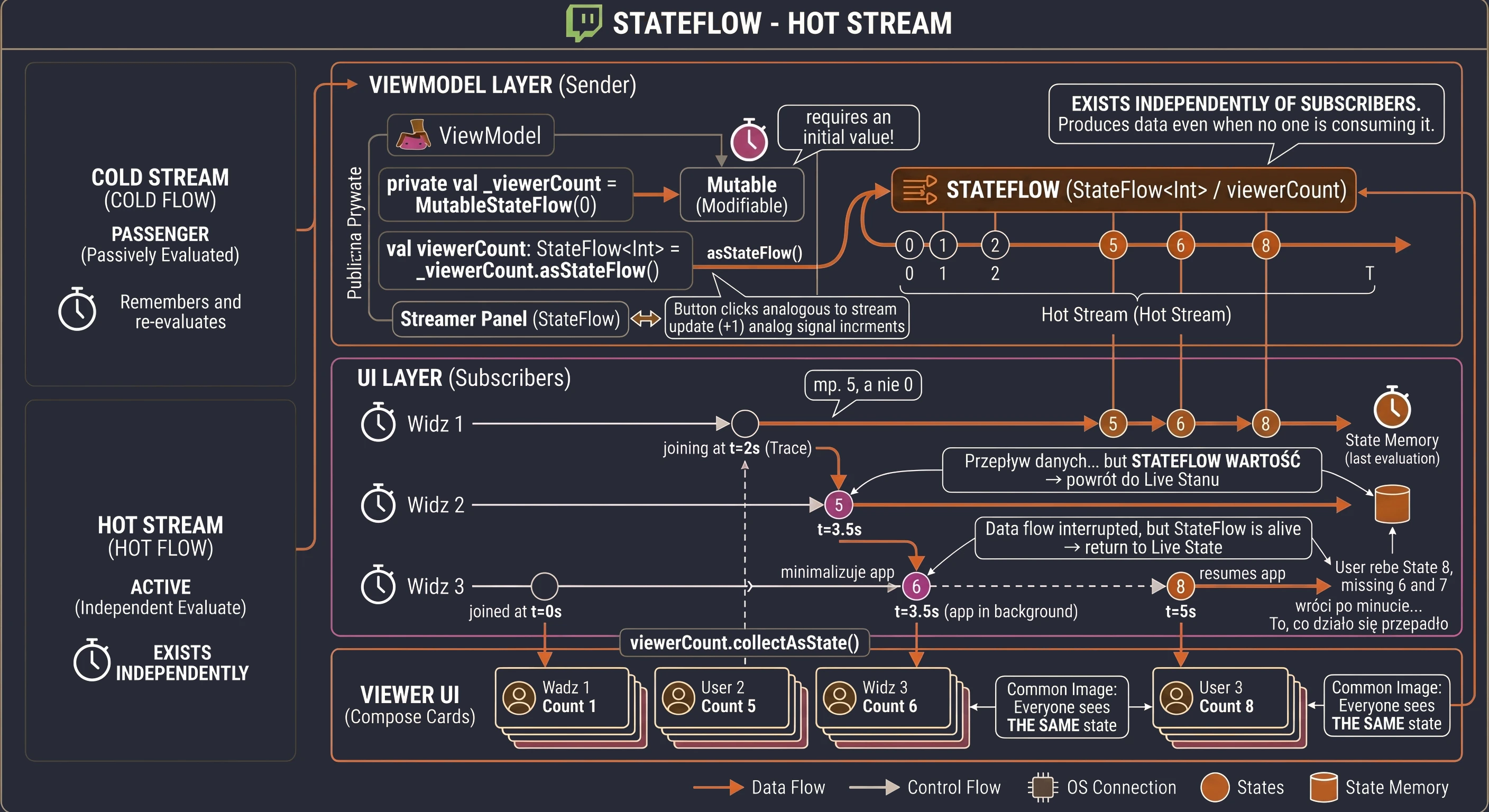
Przejdźmy do przykładu:
class StreamerViewModel : ViewModel() {
// 1. Wersja prywatna, modyfikowalna (MutableStateFlow)
// WYMAGA wartości początkowej! Tablica wyników na starcie musi coś pokazywać (np. 0).
private val _viewerCount = MutableStateFlow(0)
// 2. Wersja publiczna, tylko do odczytu (StateFlow)
val viewerCount: StateFlow<Int> = _viewerCount.asStateFlow()
fun addViewer() {
// Aktualizacja stanu jest natychmiastowa
_viewerCount.value += 1
}
}Warto zauważyć, że MutableStateFlow wymaga podania wartości początkowej w konstruktorze. Jest to logiczne - skoro StateFlow gwarantuje, że zawsze ma wartość (jak tablica wyników), to musi mieć ją od momentu stworzenia.
Pełny kod przykładu
Poniższy kod demonstruje działanie StateFlow. Mamy "Streamera" (ViewModel), który zarządza licznikiem widzów. Zwróć uwagę na zachowanie aplikacji:
- Klikaj Dodaj widza w Panelu Streamera.
- Następnie kliknij Dołącz do transmisji jako Widz 1. Zobaczysz aktualną liczbę (np. 5), a nie 0.
- Dołącz jako Widz 2. Otrzyma on tę samą wartość co Widz 1.
// --- 1. ViewModel (Streamer) ---
class StreamerViewModel : ViewModel() {
// Stan wewnętrzny (Gorący strumień, zawsze ma wartość)
private val _viewerCount = MutableStateFlow(0)
// Stan publiczny (Tylko do odczytu)
val viewerCount: StateFlow<Int> = _viewerCount.asStateFlow()
fun addViewer() {
_viewerCount.value += 1
}
}
// --- 2. Widok (UI) ---
@Composable
fun StateFlowDemoScreen(
viewModel: StreamerViewModel = viewModel()
) {
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Panel Streamera (StateFlow)")
Spacer(Modifier.height(16.dp))
// Panel Sterowania Streamera
Card() {
Column(
modifier = Modifier.padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally) {
Text("Jesteś Streamerem")
Button(onClick = { viewModel.addViewer() }) {
Text("Dodaj widza (+1)")
}
}
}
Spacer(Modifier.height(32.dp))
// Symulacja Widzów
// Każdy komponent ViewerScreen niezależnie subskrybuje
// TEN SAM StateFlow
ViewerScreen(viewModel, "Widz 1")
Spacer(Modifier.height(8.dp))
ViewerScreen(viewModel, "Widz 2")
}
}
@Composable
fun ViewerScreen(viewModel: StreamerViewModel, viewerName: String) {
// collectAsState() zamienia StateFlow w State z Compose
val count by viewModel.viewerCount.collectAsState()
Card(modifier = Modifier.fillMaxWidth()) {
Row(
modifier = Modifier.padding(16.dp),
verticalAlignment = Alignment.CenterVertically,
horizontalArrangement = Arrangement.SpaceBetween
) {
Text(viewerName, style = MaterialTheme.typography.bodyLarge)
Text(
text = "Widzi licznik: $count",
style = MaterialTheme.typography.titleLarge
)
}
}
}SharedFlow: Obsługa Zdarzeń
Mamy już StateFlow, w któym przechowujemy stan (np. liczbą widzów). Jednak w aplikacjach mobilnych często mamy do czynienia z sytuacjami, które nie są stanem, ale zdarzeniem.
Przykłady zdarzeń jednorazowych:
- Wyświetlenie komunikatu Błąd połączenia z siecią (Toast/Snackbar).
- Nawigacja do innego ekranu po pomyślnym logowaniu.
- Wibracja telefonu.
Dlaczego StateFlow się tu nie nadaje? Wyobraźmy sobie, że używamy StateFlow do obsługi błędów.
- Występuje błąd. Wpisujemy go do StateFlow:
state.value = "Error". - Widok wyświetla Toast z błędem.
- Użytkownik obraca telefon.
- Widok tworzy się na nowo i subskrybuje StateFlow.
- Ponieważ StateFlow pamięta ostatnią wartość, nowy widok natychmiast otrzymuje Error i wyświetla Toast ponownie.
Zdarzenia powinny być skonsumowane raz i zniknąć. Przykładowo: nie chcemy, aby dzwonek do drzwi dzwonił w nieskończoność przy każdym otwarciu drzwi. Do obsługi takich scenariuszy służy SharedFlow. Jest to również gorący strumień, ale skonfigurowany domyślnie tak, aby nie pamiętać historii.
Wróćmy do naszej transmisji. O ile obraz wideo (StateFlow) musi być ciągły i dostępny dla każdego, o tyle powiadomienia działają inaczej.
- Alert o donacji (Zdarzenie): Na ekranie pojawia się komunikat Widz1 wpłacił 5 zł.
- Widz obecny (Subskrybent): Widzi komunikat w momencie jego pojawienia się.
- Widz nieobecny (Aplikacja w tle): Jeśli widza nie ma w pokoju w momencie donacji, to po powrocie nie widzi starego alertu.
Działa to jak dzwonek do drzwi: słyszysz go tylko wtedy, gdy naciska go kurier. Jeśli wrócisz do domu godzinę później, dzwonek nie zaczyna nagle dzwonić, informując, że ktoś był.
Zobaczmy przykład. Różnice względem StateFlow są kluczowe:
class StreamerViewModel : ViewModel() {
// 1. Brak wartości początkowej!
// SharedFlow nie musi mieć wartości, on je tylko "przepycha".
// replay = 0 (Domyślnie) -> Nowi subskrybenci NIE dostają starych zdarzeń.
private val _donations = MutableSharedFlow<String>(replay = 0)
val donations = _donations.asSharedFlow()
fun sendDonationAlert(message: String) {
viewModelScope.launch {
// 2. Używamy emit(), a nie .value
// To operacja zawieszająca (suspend), bo bufor może być pełny
_donations.emit(message)
}
}
}- Parametr
replay = 0: - W
StateFlowwartość ta jest sztywno ustawiona na1(dlatego stan odtwarza się po np. obrocie ekranu). - W
SharedFlowustawienie0gwarantuje, że zdarzenie wyemitowane w momencie $T_0$ nie zostanie dostarczone subskrybentowi, który rozpocznie nasłuchiwanie w momencie $T_1$. Zapobiega to błędowi ponownego wyświetlania komunikatów. - Brak pola
.value: - Funkcja
emit()jestsuspend:
To istotna konfiguracja dla zdarzeń jednorazowych. Parametr ten określa, ile ostatnich wartości ma być przechowywanych w pamięci dla nowych subskrybentów.
Zauważmy, że SharedFlow nie posiada właściwości value. Można jedynie oczekiwać na nadchodzące emisje. Wymusza to na programiście podejście czysto reaktywne.
W przeciwieństwie do ustawiania state.value = ..., metoda emit() w SharedFlow jest funkcją zawieszającą. SharedFlow obsługuje mechanizm Backpressure. Jeśli subskrybenci nie nadążają z przetwarzaniem zdarzeń, a bufor wewnętrzny się zapełni, funkcja emit zawiesi korutynę producenta do momentu zwolnienia miejsca w buforze. Zapewnia to bezpieczeństwo wątkowe i chroni przed zalaniem aplikacji nadmiarowymi danymi.
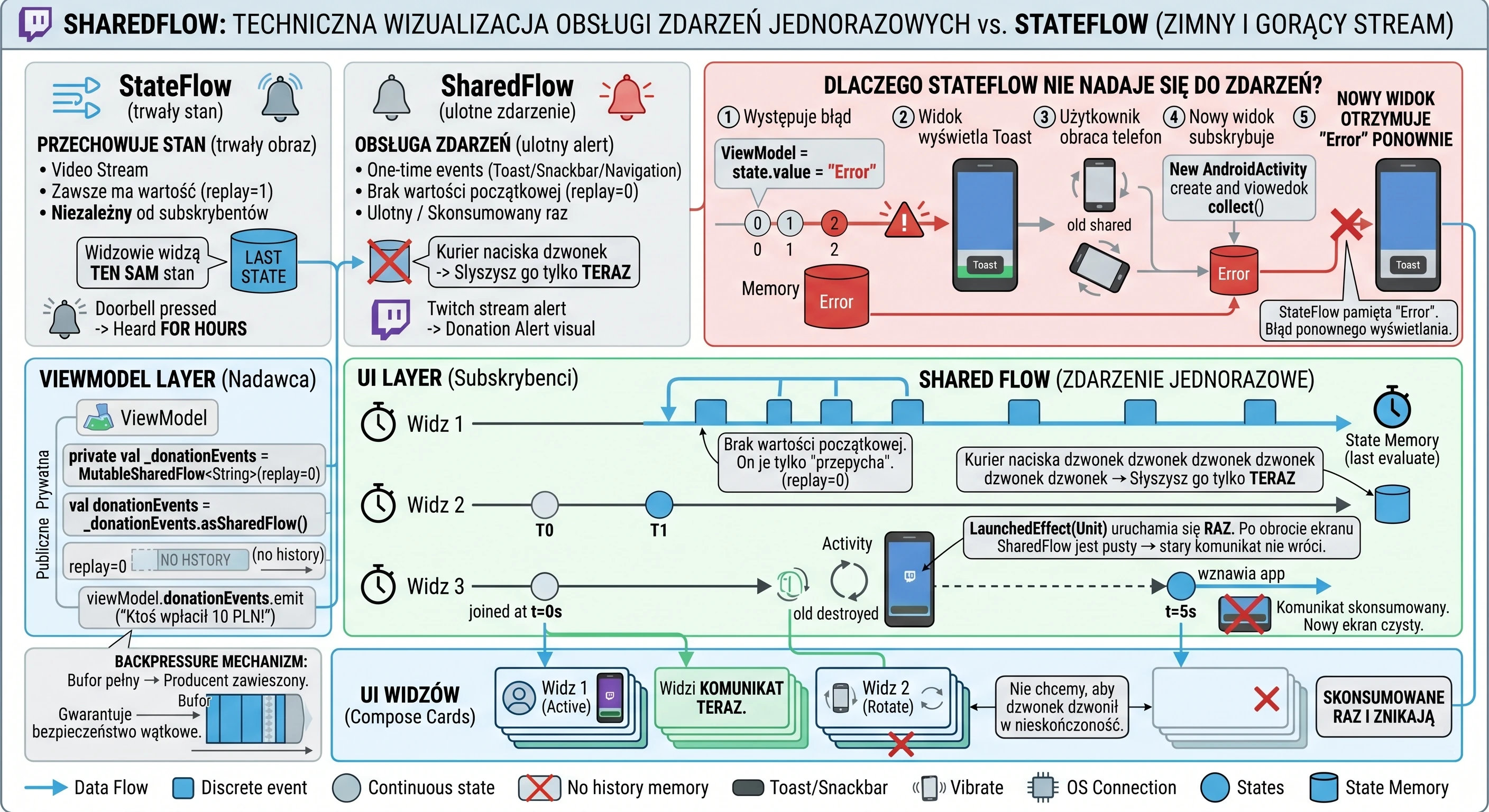
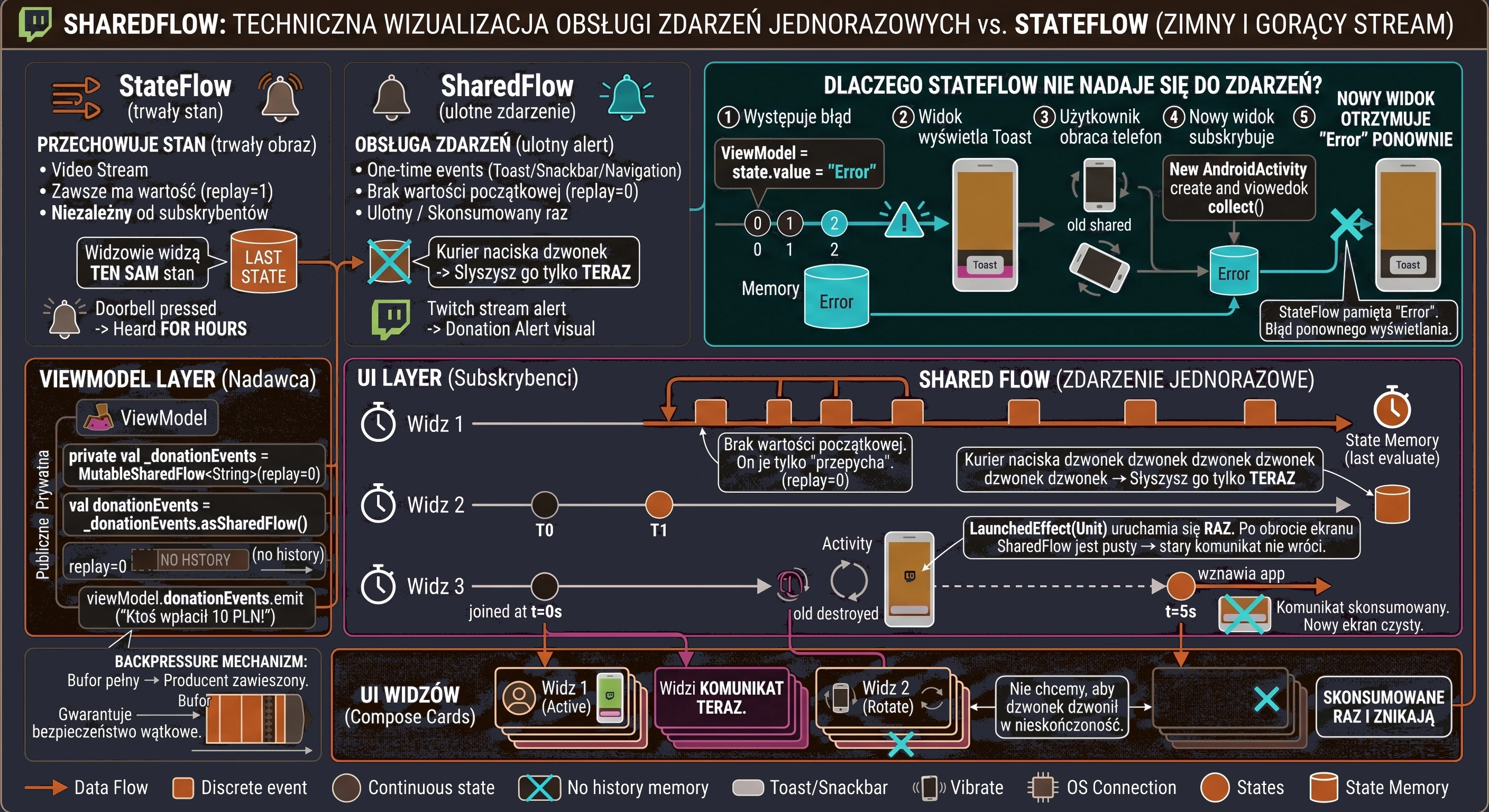
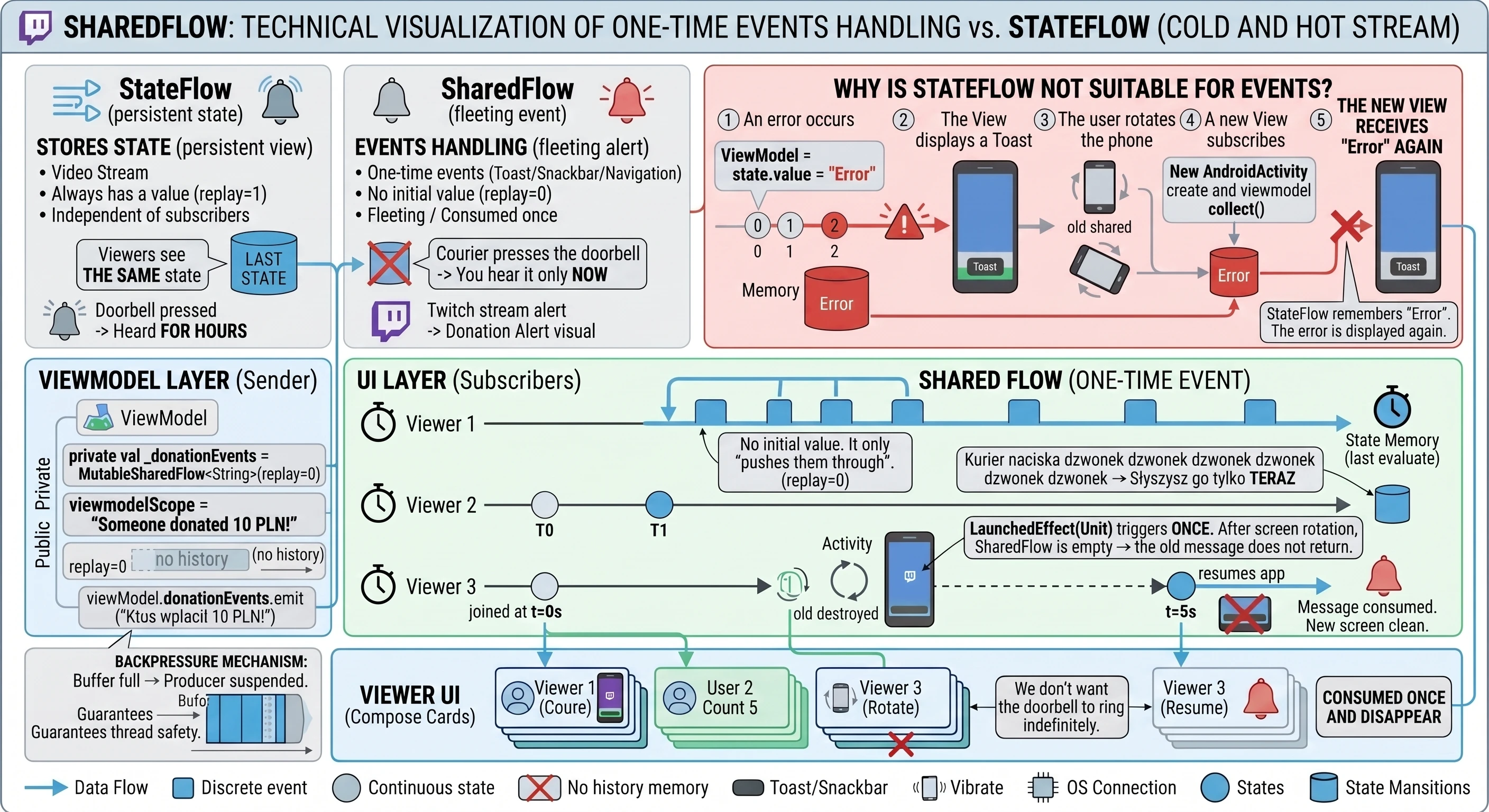
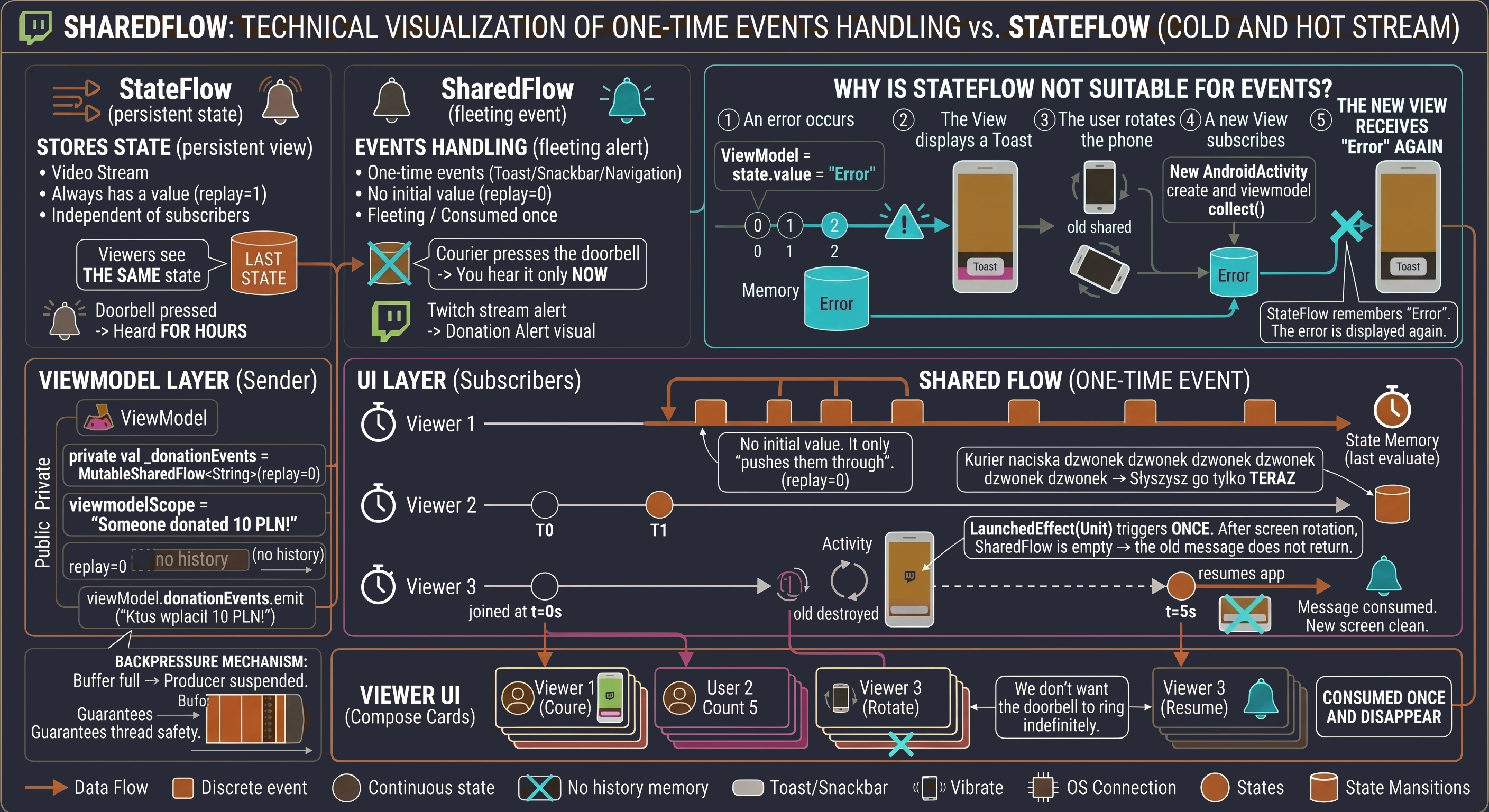
Pełny kod przykładu
Poniższy kod łączy oba światy. Mamy StateFlow dla licznika widzów (trwały) i SharedFlow dla alertów o donacjach (ulotny).
Zwróć uwagę na użycie LaunchedEffect w widoku - to specjalny blok w Compose służący do obsługi jednorazowych zdarzeń z korutyn.
// --- ViewModel ---
class EventsViewModel : ViewModel() {
// Zdarzenia
private val _donationEvents = MutableSharedFlow<String>()
val donationEvents = _donationEvents.asSharedFlow()
fun triggerDonation() {
viewModelScope.launch {
_donationEvents.emit("Ktoś wpłacił 10 PLN!")
}
}
}
// --- Widok ---
@Composable
fun EventsDemoScreen(
viewModel: EventsViewModel = viewModel(),
snackbarHostState: SnackbarHostState // Komponent do wyświetlania Toastów/Snackbarów
) {
// Odbieranie zdarzeń w Compose
// LaunchedEffect(Unit) uruchamia się RAZ przy wejściu na ekran.
// Jeśli obrócisz ekran, uruchomi się ponownie,
// ale SharedFlow jest pusty (nie pamięta historii),
// więc stary komunikat się nie pojawi.
LaunchedEffect(Unit) {
viewModel.donationEvents.collect { message ->
// Reakcja na zdarzenie: Pokaż Snackbar
snackbarHostState.showSnackbar(message)
}
}
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally
) {
Text("Obsługa Zdarzeń (SharedFlow)")
Spacer(Modifier.height(32.dp))
Button(onClick = { viewModel.triggerDonation() }) {
Text("Wyślij Donację (Zdarzenie)")
}
Spacer(Modifier.height(16.dp))
Text("Kliknij i obserwuj Snackbar. Po obrocie ekranu komunikat nie wróci.",
textAlign = TextAlign.Center)
}
}Podsumowanie
Wybór odpowiedniego rodzaju strumienia jest istotny dla poprswnego funkcjonowania aplikacji. Częstym błędem jest używanie StateFlow do wszystkiego (również do zdarzeń), co prowadzi do błędów z powtarzającymi się komunikatami, lub używanie zwykłego Flow w UI, co powoduje niepotrzebne restartowanie zapytań sieciowych. Poniższa tabela zestawia najważniejsze różnice, wykorzystując nasze analogie multimedialne.
| Cecha | Flow | StateFlow | SharedFlow |
|---|---|---|---|
| Metafora | YouTube / VOD (Odtwarzanie od zera) | Twitch Video (Transmisja Live) | Twitch Czat (Ulotne wiadomości) |
| Rodzaj | Zimny (Cold) Startuje przy subskrypcji | Gorący (Hot) Działa zawsze | Gorący (Hot) Działa zawsze |
| Pamięć (Replay) | Brak (Historia tworzona od nowa) | Zawsze 1 (Ostatni stan) | Domyślnie 0 (Konfigurowalne) |
| Wartość inicjalna | Nie | Tak (Wymagana) | Nie |
| Zastosowanie | Warstwa Danych: Baza danych (Room), Sieć (Retrofit) | Warstwa UI: Stan ekranu, Dane formularza | Warstwa UI: Toasty, Nawigacja, Sygnały |
Kiedy piszesz kod i zastanawiasz się, czego użyć, zadaj sobie te pytania:
- Czy to jest stan, który widok musi widzieć zawsze (nawet po obrocie)? -> Użyj
StateFlow. - Czy to jest jednorazowy sygnał (np. "Zalogowano", "Błąd")? -> Użyj
SharedFlow. - Czy pobierasz dane z bazy/sieci i przetwarzasz je sekwencyjnie? -> Użyj zwykłego
Flow.
Bezpieczne pobieranie danych w UI
Na zakończenie musimy poruszyć temat wydajności. W świecie Androida aplikacja może znajdować się w tle (np. użytkownik przeszedł do innej aplikacji), ale wciąż być żywa w pamięci.
Jeśli w funkcji Composable użyjemy zwykłego collect lub collectAsState(), subskrypcja strumienia może pozostać aktywna nawet wtedy, gdy aplikacja jest w tle. Oznacza to, że jeśli ViewModel wciąż emituje dane (np. lokalizację GPS), aplikacja będzie przetwarzać te dane i zużywać baterię, mimo że użytkownik ich nie widzi. Zalecanym standardem jest używanie funkcji collectAsStateWithLifecycle() rozszerzającej dostarczanej przez bibliotekę androidx.lifecycle:lifecycle-runtime-compose.
Funkcja ta jest świadoma cyklu życia (Lifecycle-Aware):
- Gdy aplikacja przechodzi w stan
STOPPED(tło) -> Anuluje subskrypcję strumienia (zatrzymuje pobieranie danych). - Gdy aplikacja wraca do stanu
STARTED(widoczna) -> Ponawia subskrypcję i pobiera najnowszy stan.
// Wymagana zależność w build.gradle w bloku dependencies:
// implementation("androidx.lifecycle:lifecycle-runtime-compose:...")
@Composable
fun UserProfileScreen(viewModel: UserViewModel) {
// mniej wydajnie:
// val state = viewModel.uiState.collectAsState()
// Standard:
val state by viewModel.uiState.collectAsStateWithLifecycle()
Text(text = "Witaj, ${state.userName}!")
}Dzięki temu prostemu zabiegowi nasza aplikacja jest nie tylko reaktywna, ale też oszczędna dla baterii użytkownika.
Powrót do podstaw
W poprzednich rozdziałach nauczyliśmy się tworzyć korutyny, używać launch, async oraz synchronizować zadania za pomocą join. Zanim jednak przejdziemy do zaawansowanych wzorców architektonicznych, musimy wyjaśnić jedno z najczęstszych nieporozumień dotyczących współbieżności w Kotlinie.
Wróćmy do przykładów, które omawialiśmy w Rozdziale 3. Przeanalizujmy dokładnie, na jakim wątku wykonywana jest każda linijka kodu.
Spójrzmy na generator haseł. Użyliśmy tu async, co mocno sugeruje asynchroniczność. Ale gdzie tak naprawdę dzieje się praca?
@Composable fun PasswordGeneratorScreen() {
var password by remember { mutableStateOf("...") }
// Domyślny scope w Compose używa Dispatchers.Main.immediate
val scope = rememberCoroutineScope()
// Funkcja symulująca ciężkie obliczenia
suspend fun generatePassword(): String {
// Tu nadal jesteśmy na WĄTKU GŁÓWNYM!
// delay tylko zawiesza korutynę, nie zmienia wątku.
delay(3000)
return "Kotlin-Is-Super-Secure-123"
}
Column(...) {
Button(onClick = {
password = "Generowanie..."
// 1. START: Jesteśmy na Main Thread (obsługa kliknięcia)
// launch bez argumentów dziedziczy kontekst (tu: Main)
scope.launch {
// 2. WNĘTRZE KORUTYNY: Nadal Main Thread.
// 3. ASYNC: Uruchamia nową korutynę, ale
// dziedziczy dispatcher od rodzica (czyli Main Thread).
val deferredPassword: Deferred<String> = async {
generatePassword() // Wykonanie funkcji na Main Thread
}
// 4. AWAIT: Zawiesza korutynę rodzica (na Main Thread).
// UI nie jest zablokowane tylko dlatego, że użyliśmy 'delay',
// który jest funkcją nieblokującą.
// Gdyby generatePassword() liczyło hashe przez 3 sekundy (CPU),
// aplikacja by "zamarzła" (ANR).
val result = deferredPassword.await()
// 5. WZNOWIENIE: Nadal Main Thread. Aktualizacja UI.
password = result
}
}) { Text("Wygeneruj hasło") }
}
}Wniosek: Cała operacja, od kliknięcia, przez async, aż po wynik, odbyła się na jednym i tym samym wątku (Main). Zadziałało to płynnie tylko dlatego, że delay jest funkcją zawieszającą. Gdybyśmy tam wstawili prawdziwą pracę procesora, UI uległoby zamrożeniu.
Drugi przykład z kucharzami pokazywał współbieżność (robienie dwóch rzeczy naraz). Czy oznacza to jednak równoległość (użycie wielu rdzeni)?
// 1. Szef Kuchni (Rodzic)
// scope.launch domyślnie używa Dispatchers.Main
scope.launch {
// WĄTEK: Main Thread
logs.add("Szef kuchni (rodzic): Zaczynamy")
// 2. Zlecenie zadania Pomocnikowi 1
// launch dziedziczy kontekst -> Dispatchers.Main
val jobMieso = launch {
// WĄTEK: Main Thread
// Korutyna zawiesza się na wątku głównym, ustępując miejsca innym
delay(2000)
logs.add("Kucharz 1: Mięso usmażone (2s).")
}
// 3. Zlecenie zadania Pomocnikowi 2
// launch dziedziczy kontekst -> Dispatchers.Main
val jobWarzywa = launch {
// WĄTEK: Main Thread
delay(3000)
logs.add("Kucharz 2: Warzywa gotowe (3s).")
}
// WĄTEK: Main Thread
logs.add("Szef kuchni: Zadania zlecone...")
// 4. Synchronizacja
// join() to punkt zawieszenia na Main Thread.
// Korutyna rodzica "czeka" (nie blokując wątku), aż dzieci skończą.
jobWarzywa.join()
jobMieso.join()
// 5. Finał
// WĄTEK: Main Thread
logs.add("Szef kuchni: Wszyscy skończyli!")
}Wniosek: Mimo że mamy trzy korutyny (Rodzic, Kucharz 1, Kucharz 2), wszystkie skaczą po tym samym wątku głównym.
Oczywiście, zarówno launch, jak i async przyjmują opcjonalny argument typu CoroutineContext, który pozwala jawnie wskazać dyspozytora.
// Możemy wymusić inny wątek w momencie startu
scope.launch(Dispatchers.IO) {
// Teraz jesteśmy na wątku tła.
// Dobre dla zapisu do pliku.
saveToFile()
// PROBLEM: Nie możemy stąd bezpiecznie dotknąć UI
// textLabel.text = "Zapisano" // BŁĄD!
}Choć jest to możliwe, w architekturze MVVM rzadko używamy tego podejścia bezpośrednio w warstwie UI. Powoduje to problemy z aktualizacją interfejsu (musimy ręcznie wracać na Main Thread) i utrudnia testowanie. Dlatego stosujemy podejście, w którym korutyna startuje na UI (żeby mieć do niego dostęp), a skacze na inne wątki tylko wtedy, gdy to konieczne.
Wyróżniamy dwa główne wzorce przełączania wątków, którymi zajmiemy się w tym rozdziale:
- Podejście Imperatywne (
withContext): Stosowane wewnątrz funkcji. Mówimy: Wykonaj ten fragment kodu na innym wątku i wróć do mnie z wynikiem. - Podejście Reaktywne (
flowOn): Stosowane w strumieniach. Mówimy: Wszystkie dane powyżej tego punktu mają być produkowane na innym wątku.
Podejście Imperatywne: Bezpieczeństwo funkcji z withContext
Wróćmy do problemu blokowania UI. Wiemy już, że wywołanie trudnej obliczeniowo funkcji wewnątrz viewModelScope.launch zablokuje ekran.
Rozwiązaniem tego problemu w podejściu imperatywnym jest funkcja withContext:
- Przyjmuje jako argument
Dispatcher(np.Dispatchers.DefaultlubIO). - Zawiesza bieżącą korutynę (nie blokując wątku, z którego została wywołana).
- Wykonuje blok kodu na wskazanym dyspozytorze.
- Po zakończeniu pracy wznawia korutynę na pierwotnym dyspozytorze.
- Zwraca wynik ostatniej linii bloku kodu (działa jak wyrażenie).
To sprawia, że kod wygląda na sekwencyjny, mimo że pod spodem następuje skomplikowane przełączanie wątków.
// Definicja funkcji Main-Safe (Bezpiecznej dla UI)
suspend fun performHeavyCalculation(): Int {
// 1. Zmiana kontekstu na wątek obliczeniowy
return withContext(Dispatchers.Default) {
// 2. Symulacja ciężkiej pracy (np. przetwarzanie obrazu)
// To nie zablokuje UI, mimo że funkcja 'sleep' normalnie blokuje wątek.
// Blokujemy tu wątek roboczy, a nie główny.
Thread.sleep(2000)
// 3. Obliczenie wyniku
val result = 42 * 100
// 4. Zwrócenie wyniku (ostatnia linia)
result
}
// 5. Automatyczny powrót na wątek, z którego wywołano funkcję
}
// Użycie w ViewModelu
fun onCalculateClicked() {
viewModelScope.launch { // Start na Main Thread
_uiState.value = UiState.Loading // Aktualizacja UI
// Wywołanie - tu korutyna się "zawiesza" na Main Thread
// UI pozostaje responsywne (np. kręci się loader)
val result = performHeavyCalculation()
// Powrót na Main Thread z gotowym wynikiem
_uiState.value = UiState.Success(result)
}
}Podejście Reaktywne: Bezpieczeństwo strumieni z flowOn
O ile withContext świetnie sprawdza się w funkcjach, które wchodzą i wychodzą, o tyle w przypadku strumieni (Flow) sytuacja jest bardziej złożona. Strumień to rurociąg, przez który dane płyną w czasie.
We Flow obowiązuje zasada: kod wewnątrz bloku flow { ... } wykonuje się w tym samym kontekście, w którym wywołano collect().
Ponieważ w Androidzie zazwyczaj zbieramy dane (collect) w warstwie widoku (Activity/Composable), która działa na wątku głównym, oznacza to, że domyślnie producent danych też działałby na wątku głównym.
// BŁĘDNE PODEJŚCIE
// Repository
val usersFlow = flow {
// To wykona się na Main Thread, jeśli collect będzie na Main!
// Spowoduje to zamrożenie UI przy każdym odczycie z bazy.
val data = database.readUsers() // Operacja blokująca IO
emit(data)
}
// ViewModel / UI
viewModelScope.launch {
// Zbieramy na Main Thread (domyślnie w viewModelScope)
usersFlow.collect { show(it) }
}Aby zmienić wątek, na którym produkowane są dane, używamy operatora flowOn. Jego działanie jest specyficzne: zmienia on kontekst wykonania tylko dla operatorów znajdujących się powyżej niego (tzw. upstream).
// PRAWIDŁOWE PODEJŚCIE
val usersFlow = flow {
// 1. To wykona się na Dispatchers.IO
val data = database.readUsers()
emit(data)
}.map { users ->
// 2. To też wykona się na Dispatchers.IO (bo jest powyżej flowOn)
users.filter { it.isActive }
}.flowOn(Dispatchers.IO) // <--- GRANICA ZMIANY KONTEKSTU
.map { users ->
// 3. To wykona się w kontekście odbiorcy (zazwyczaj Main)
// Bo jest PONIŻEJ flowOn
users.map { it.name }
}Dzięki flowOn możemy bezpiecznie wykonywać operacje bazodanowe lub sieciowe w repozytorium, a wynik dostarczać gotowy do wyświetlenia na wątku UI.
Porównanie withContext i flowOn
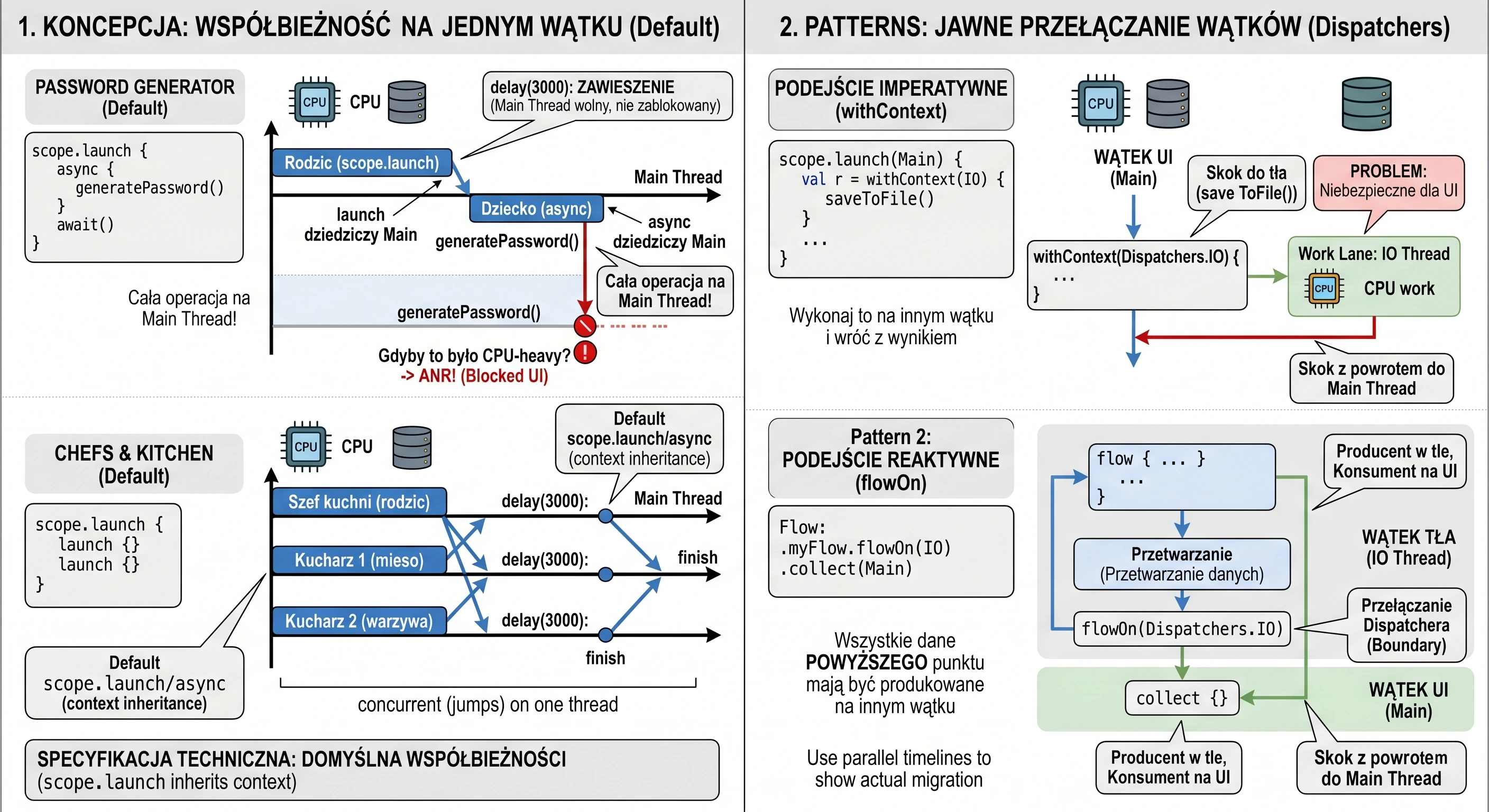
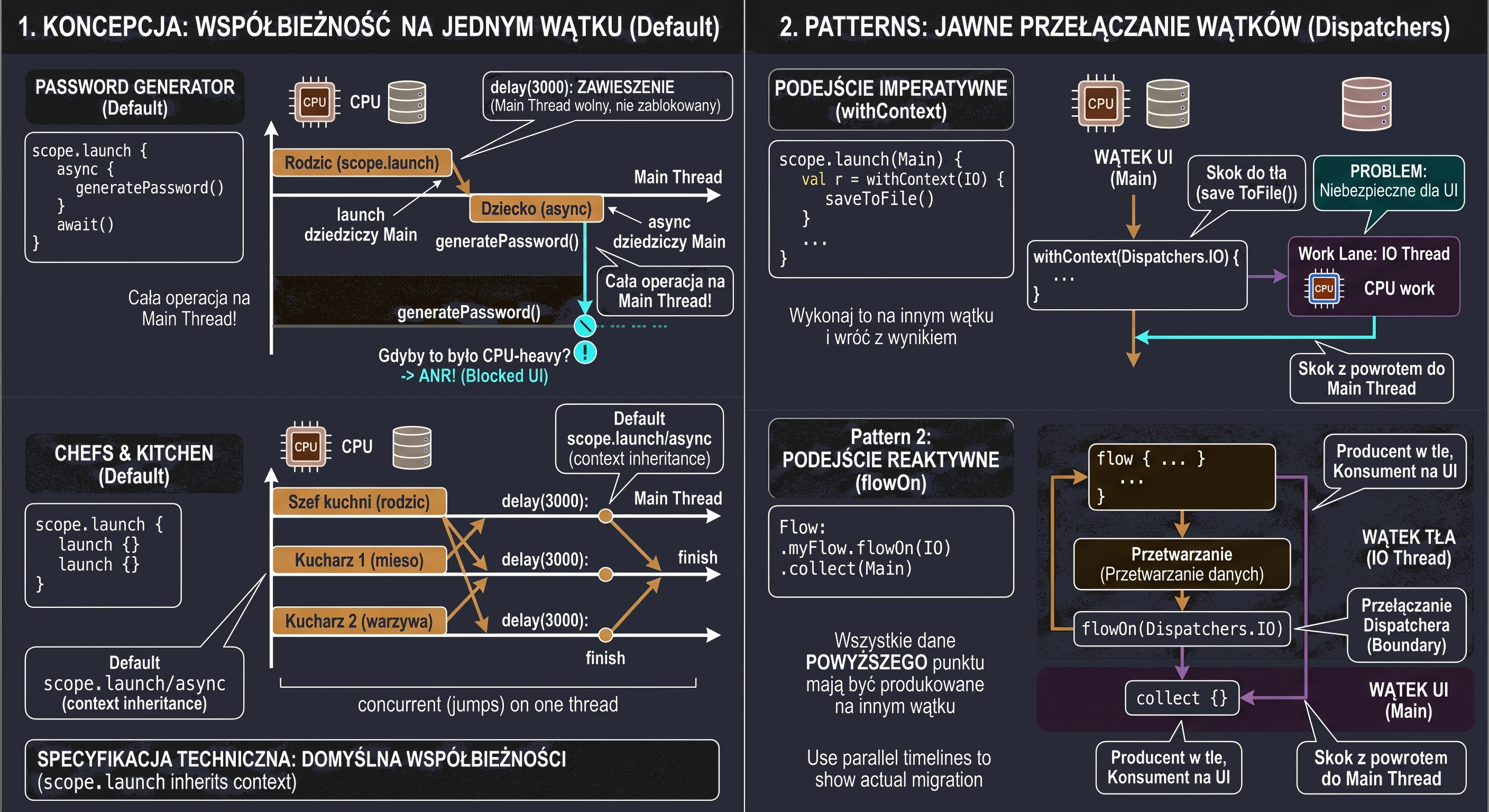
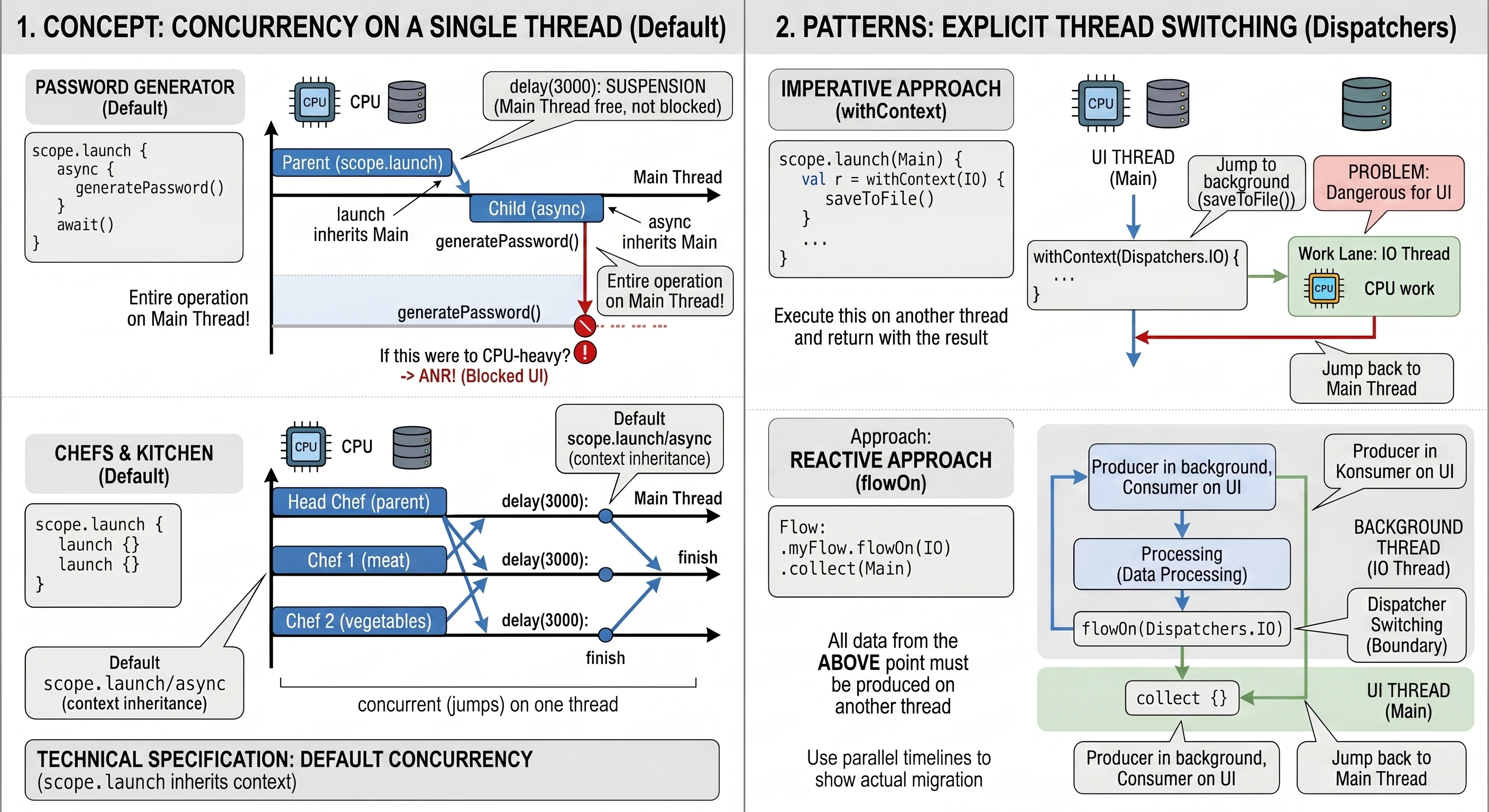
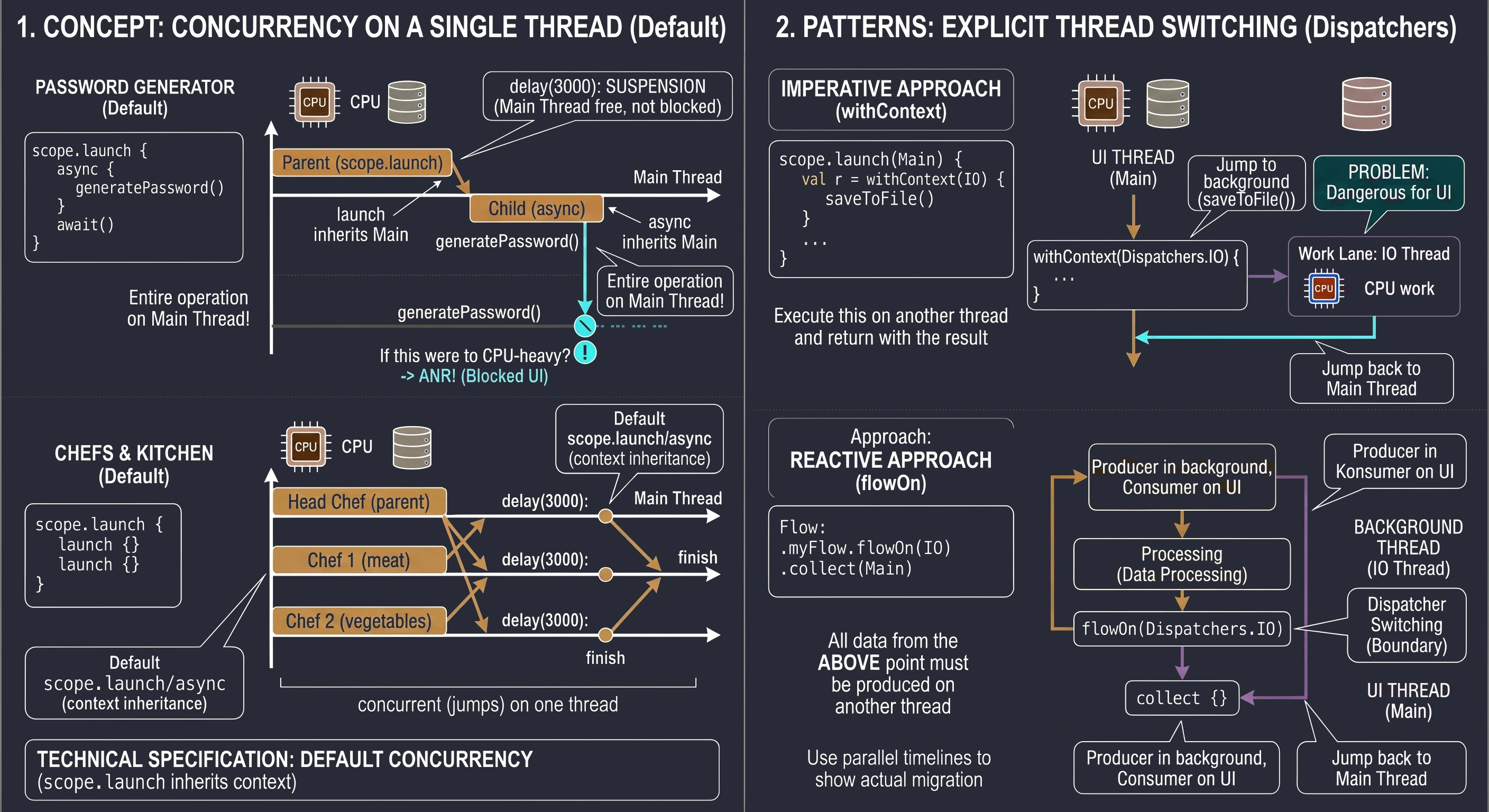
Podsumujmy różnice między tymi dwoma mechanizmami:
| Cecha | withContext | flowOn |
|---|---|---|
| Typ danych | Pojedynczy wynik (T) | Strumień danych (Flow<T>) |
| Kierunek zmian | Zmienia kontekst dla bloku kodu tu i teraz. | Zmienia kontekst dla źródła danych (w górę rzeki). |
| Bezpieczeństwo | Musi być wywołany wewnątrz funkcji suspend. | Jest operatorem nakładanym na obiekt Flow. |
| Zastosowanie | Krótkie operacje (np. sortowanie listy, zapis do pliku). | Długotrwałe obserwowanie danych (np. z bazy Room). |
Transformacja Strumieni
Zanim poznamy operator stateIn, musimy zrozumieć problem architektoniczny, który on rozwiązuje. Wymaga to przypomnienia fundamentalnej różnicy między strumieniami zimnymi a gorącymi oraz przeanalizowania cyklu życia aplikacji w Androidzie.
W Rozdziale 5 zdefiniowaliśmy dwa rodzaje strumieni. Spójrzmy na nie teraz z perspektywy wydajności:
- Zimny Strumień (Flow): To jest przepis na dane.
- Nie przechowuje danych.
- Kod wewnątrz bloku
flow { ... }nie wykonuje się, dopóki ktoś nie zacznie nasłuchiwać (collect). - Każdy nowy subskrybent powoduje ponowne wykonanie kodu producenta od początku.
- Gorący Strumień (StateFlow/SharedFlow): To jest gotowe danie na stole.
- Przechowuje dane (stan) w pamięci.
- Produkuje dane niezależnie od tego, czy ktoś ich słucha.
- Nowy subskrybent otrzymuje natychmiast aktualny stan (talerz z jedzeniem), bez konieczności gotowania wszystkiego od nowa.
W Androidzie zmiana konfiguracji (np. obrót ekranu, zmiana trybu jasny/ciemny) powoduje całkowite zniszczenie i odtworzenie Aktywności. Jeśli w warstwie UI nasłuchujemy na zimny strumień (zwykły Flow) pochodzący bezpośrednio z repozytorium, dochodzi do marnotrawstwa zasobów.
Prześledźmy ten scenariusz krok po kroku:
- Użytkownik uruchamia ekran. Activity woła
collect(). - Zimny Flow startuje: Repozytorium łączy się z bazą danych, wykonuje zapytanie SQL, przetwarza wyniki. Dane trafiają na ekran.
- Użytkownik obraca ekran.
- Stare Activity jest niszczone ->
collect()zostaje anulowany. - Nowe Activity jest tworzone -> woła nowe
collect(). - Zimny Flow startuje OD NOWA: Repozytorium znowu łączy się z bazą, znowu wykonuje to samo zapytanie SQL.
// --- REPOZYTORIUM ---
// Zimny strumień - kod w środku wykona się przy KAŻDEJ subskrypcji
fun getTasks(): Flow<List<Task>> = flow {
println("Pobieram dane z bazy...") // To loguje się przy każdym obrocie!
val tasks = database.queryAll()
emit(tasks)
}
// --- VIEWMODEL (BŁĘDNE PODEJŚCIE) ---
// ViewModel tylko przekazuje zimny strumień dalej
val tasksFlow = repository.getTasks() // To nadal jest zimny FlowArchitektura MVVM daje nam idealne miejsce na rozwiązanie tego problemu. ViewModel przeżywa zmianę konfiguracji urządzenia.
Musimy więc:
- Pobrać dane raz (uruchomić zimny strumień).
- Przechować wynik w pamięci ViewModelu (zamienić w gorący stan).
- Nowe Activity po obrocie powinno otrzymać dane z pamięci ViewModelu, zamiast uderzać do repozytorium.
Do tej transformacji służy operator stateIn, który omówimy w kolejnej sekcji.
Operatory stateIn i shareIn
Skoro wiemy już, że musimy zamienić zimny strumień (przepis) w gorący (danie), Kotlin dostarcza nam do tego dwa dedykowane operatory: stateIn oraz shareIn.
Operator stateIn zamienia dowolny Flow<T> w StateFlow<T>. Przypomnijmy, że StateFlow jest obserwowalnym pojemnikiem na dane, który zawsze posiada wartość. Dlatego operator ten wymaga podania wartości początkowej.
// ViewModel
val uiState: StateFlow<UiState> = repository.getDataStream()
.map { data -> UiState.Success(data) } // Transformacja danych
.stateIn(
scope = viewModelScope, // 1. Gdzie strumień ma żyć?
started = SharingStarted.WhileSubscribed(5000), // 2. Kiedy ma działać?
initialValue = UiState.Loading // 3. Co pokazać na początku?
)Parametr started jest kluczowy dla oszczędzania zasobów. Najczęściej używaną strategią w Androidzie jest SharingStarted.WhileSubscribed(5000).
- Działanie: Utrzymuj połączenie ze źródłem (upstream) tak długo, jak ktoś nasłuchuje w UI.
- Timeout (5000 ms): Jeśli liczba subskrybentów spadnie do zera (np. użytkownik obrócił ekran i stare Activity zniknęło), nie zrywaj połączenia od razu. Poczekaj 5 sekund.
Zmiana konfiguracji często jest niemal natychmiastowa. Stare Activity znika (subskrybenci = 0), a chwilę później nowe Activity się pojawia (subskrybenci = 1).
- Dzięki opóźnieniu 5s, strumień nie zauważa tej krótkiej przerwy. Połączenie z bazą danych nie jest zrywane, a nowe Activity natychmiast dostaje dane z pamięci.
- Jeśli jednak użytkownik naciśnie przycisk Home i wyjdzie z aplikacji na dłużej niż 5 sekund - strumień zostanie zatrzymany, zwalniając zasoby (np. zamykając połączenie sieciowe).
Operator shareIn zamienia Flow<T> w SharedFlow<T>. Używamy go dla danych, które mają charakter zdarzeniowy (Events), a nie stanowy (State). Przykłady to: powiadomienia, toasty, sygnały nawigacyjne.
Różnice względem stateIn:
- Nie wymaga wartości początkowej (zdarzenia nie muszą istnieć na starcie).
- Pozwala konfigurować parametr
replay(ile starych zdarzeń pamiętać dla nowych subskrybentów).
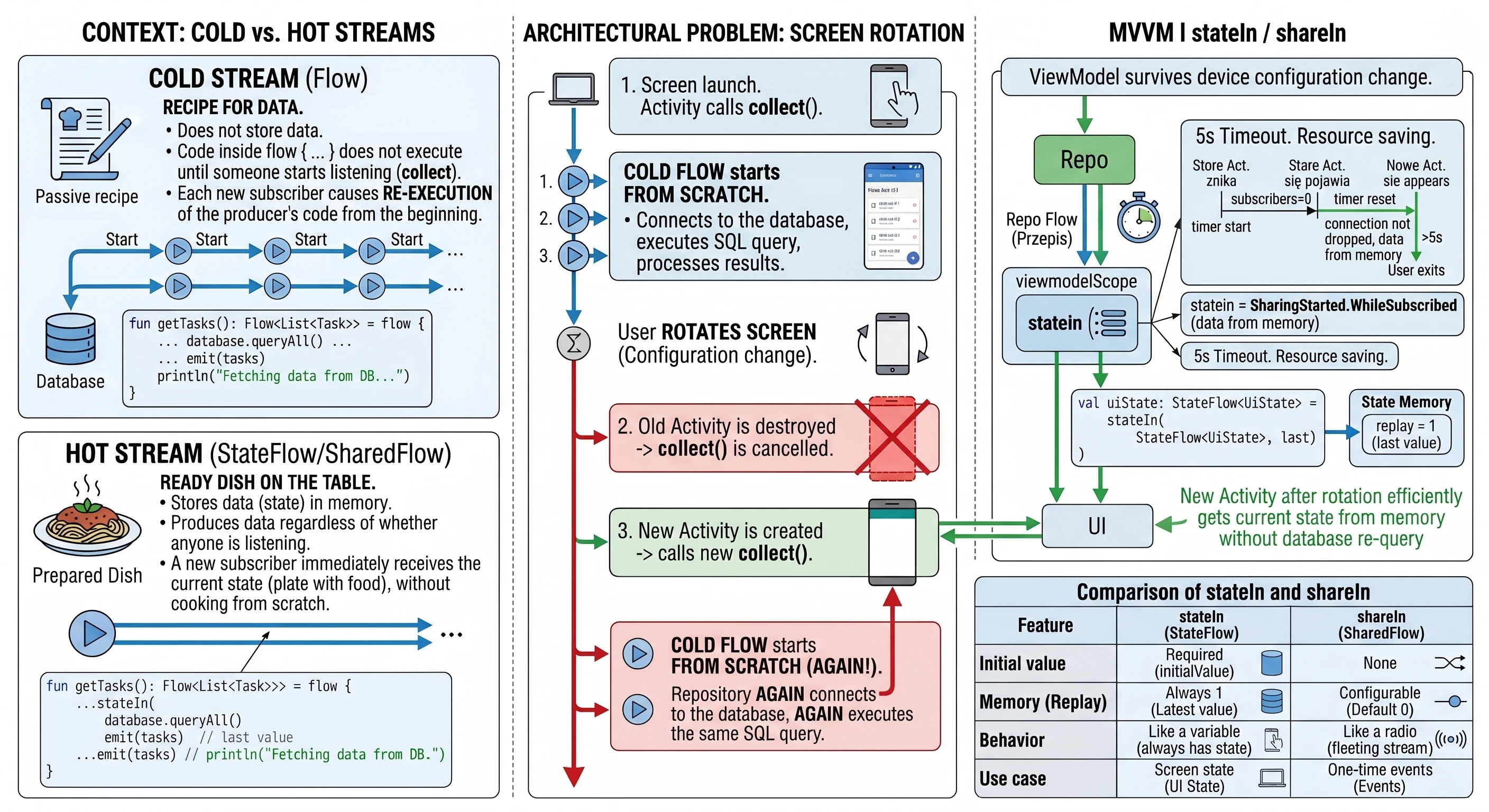
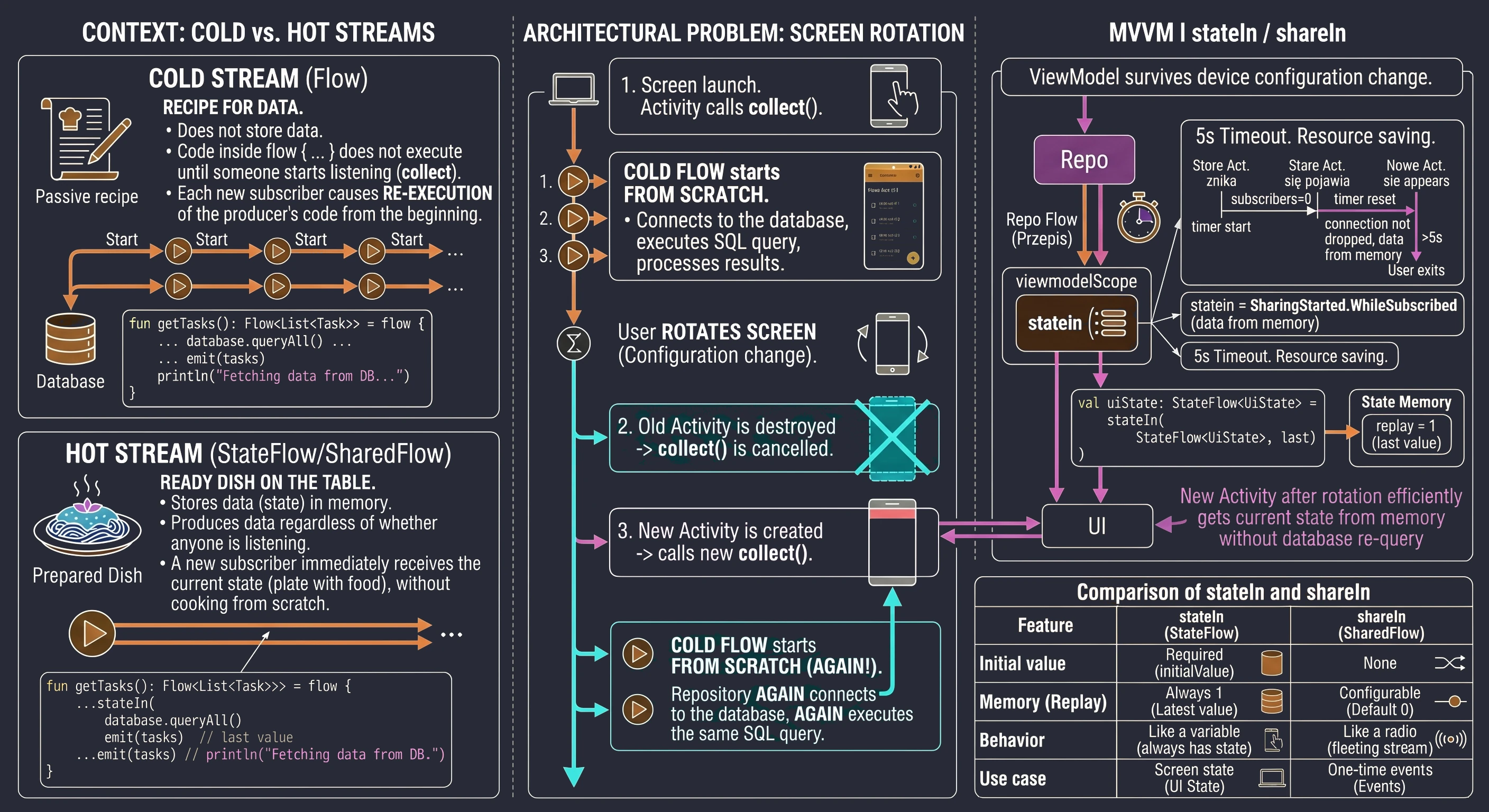
Wyobraźmy sobie strumień alertów z serwera. Chcemy, aby te alerty trafiały do wszystkich ekranów w aplikacji, ale nie chcemy, aby nowy ekran po otwarciu wyświetlał stare, nieaktualne komunikaty.
val notificationEvents: SharedFlow<String> = repository.getAlerts()
.shareIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
replay = 0
)Gdybyśmy ustawili replay = 1, to każdy nowy ekran po otwarciu od razu dostałby ostatni komunikat.
Podsumujmy:
| Cecha | stateIn (StateFlow) | shareIn (SharedFlow) |
|---|---|---|
| Wartość początkowa | Wymagana (initialValue) | Brak |
| Pamięć (Replay) | Zawsze 1 (Ostatnia wartość) | Konfigurowalna (Domyślnie 0) |
| Zachowanie | Jak zmienna (zawsze ma stan) | Jak radio (strumień ulotny) |
| Zastosowanie | Stan ekranu (UI State) | Zdarzenia jednorazowe (Events) |
Łączenie danych: Operator combine
W aplikacjach stan ekranu (UI State) rzadko pochodzi z jednego źródła. Często musimy połączyć dane z dwóch lub więcej niezależnych strumieni.
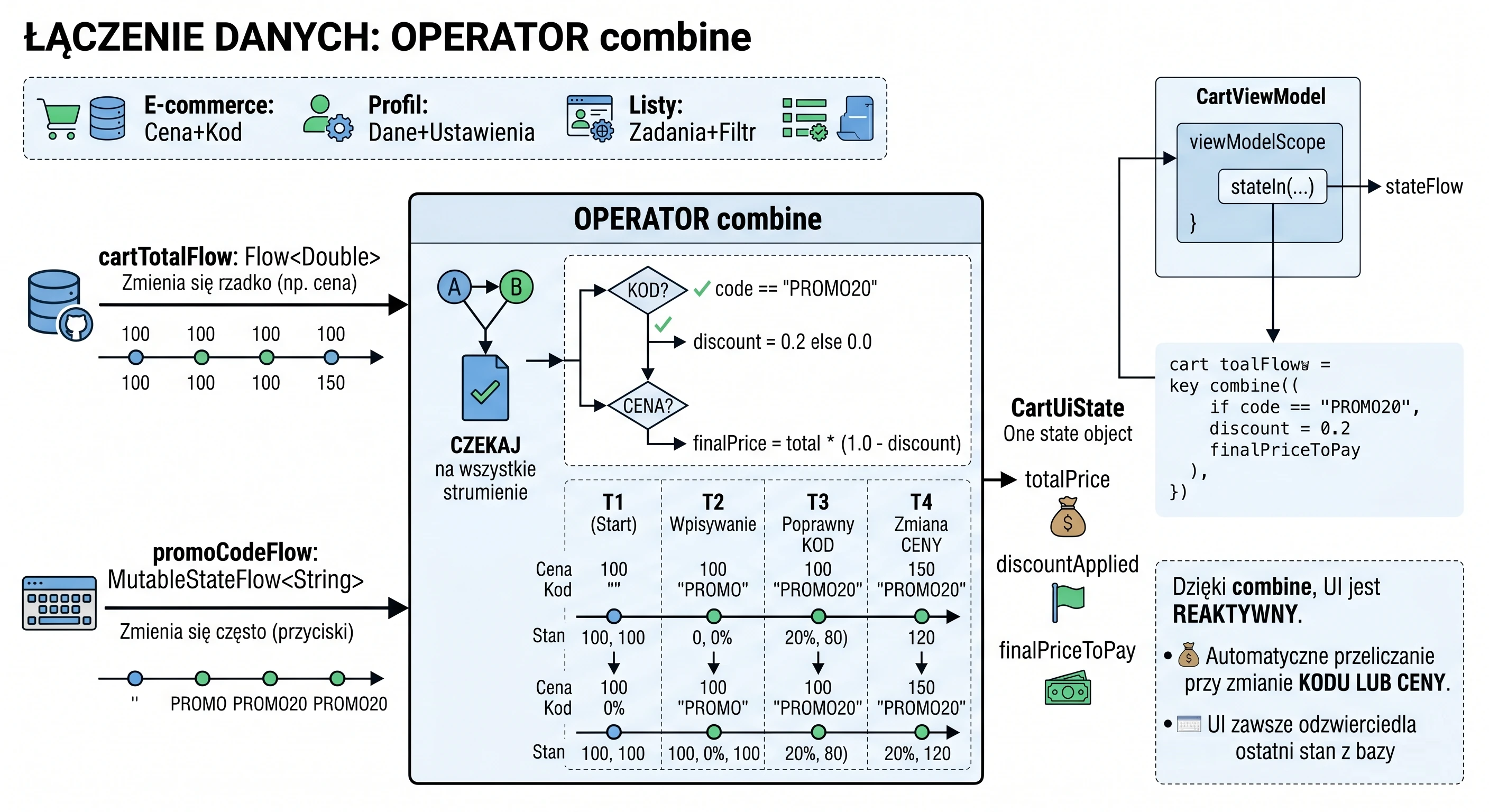
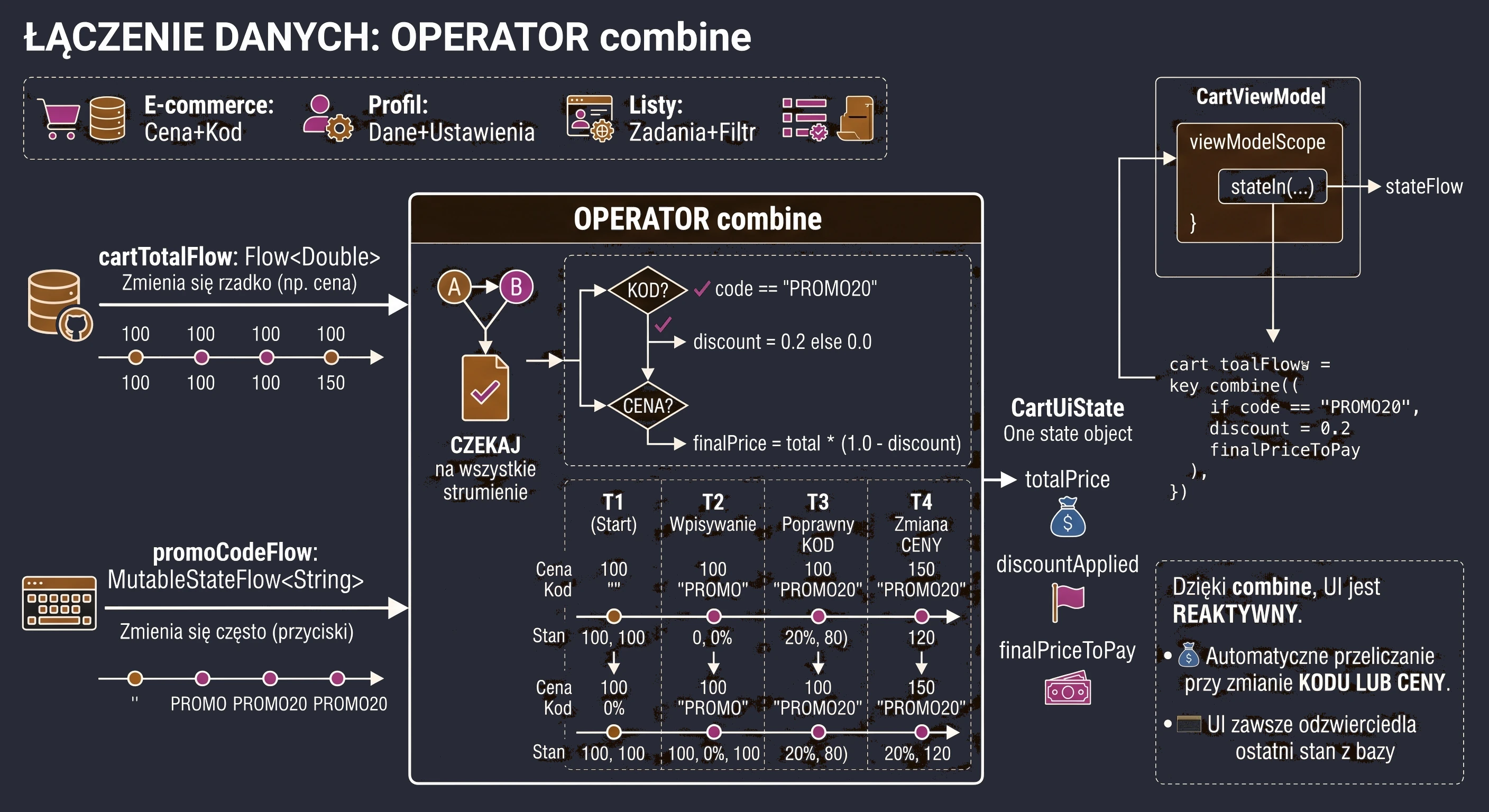
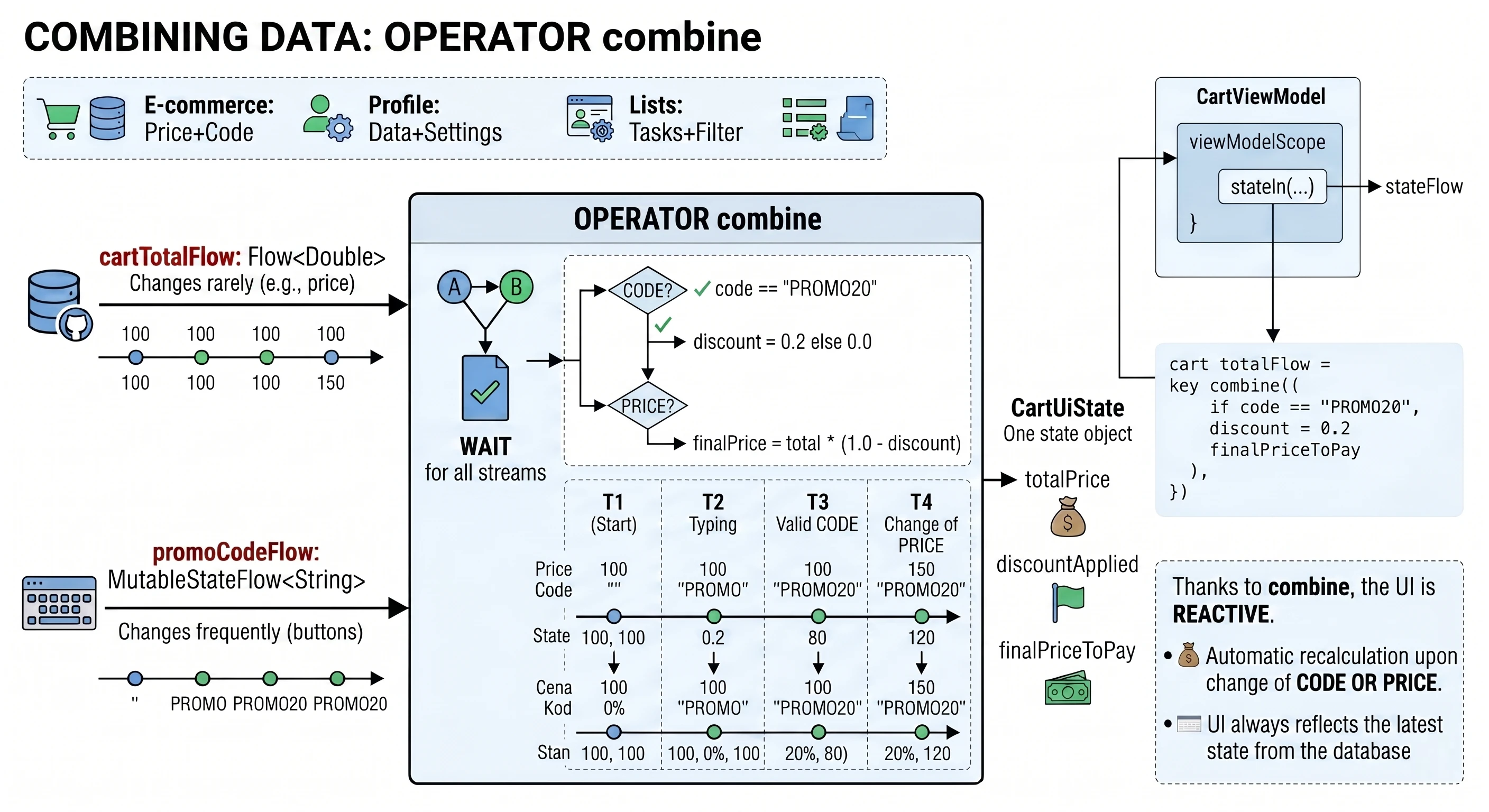
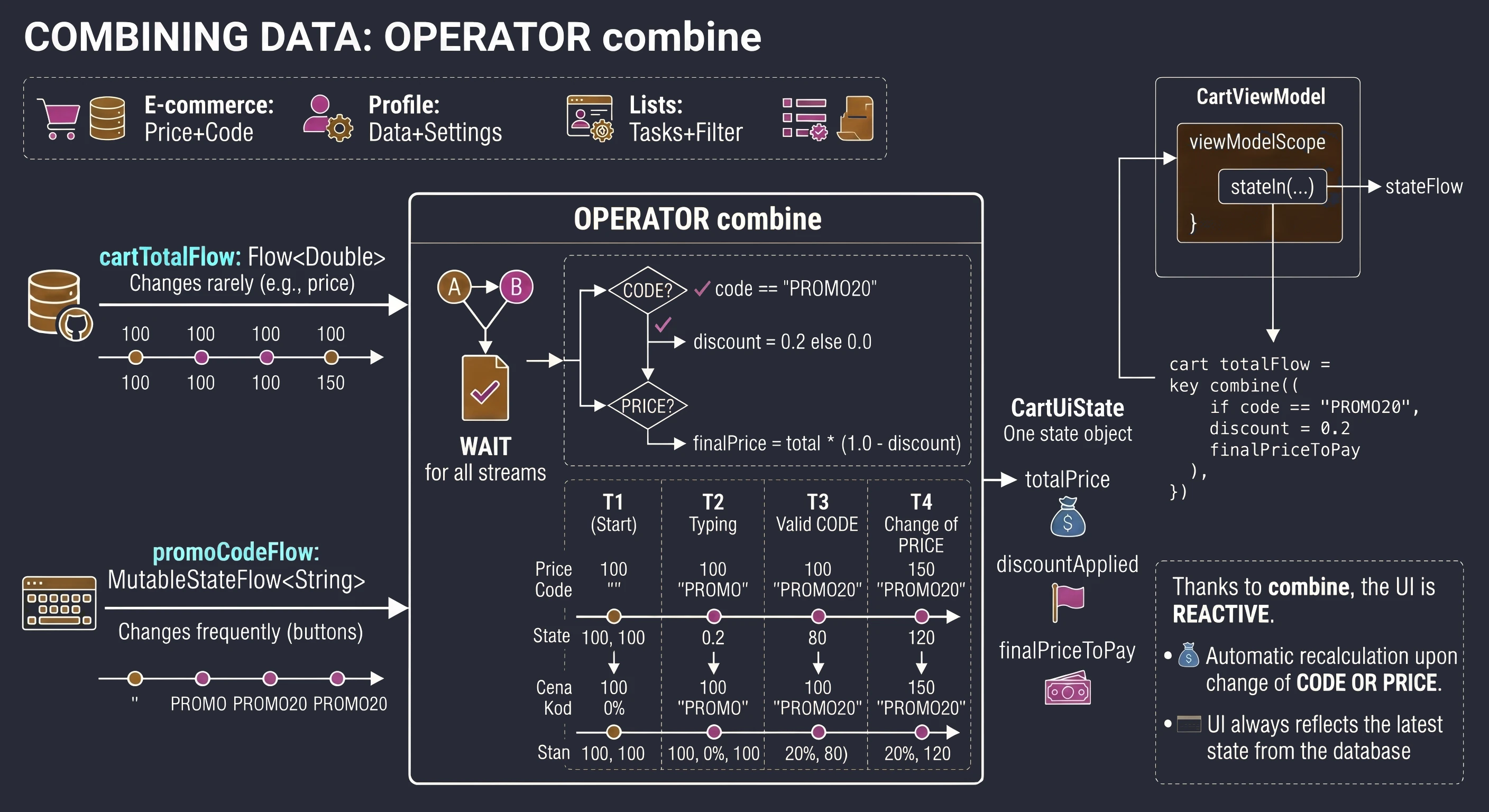
Typowe scenariusze:
- E-commerce: Cena produktów (z Bazy) + Kod rabatowy (z Pola tekstowego).
- Profil: Dane użytkownika (z Sieci) + Ustawienia prywatności (z DataStore).
- Listy: Lista zadań (z Bazy) + Wybrany filtr kategorii (z ViewModela).
Do realizacji tego celu służy operator combine, który nasłuchuje na kilka strumieni jednocześnie. Jego działanie można porównać do formuły w arkuszu kalkulacyjnym (np. =A1+B1).
- Czeka, aż wszystkie strumienie wyemitują pierwszą wartość (synchronizacja startowa).
- Gdy którykolwiek ze strumieni wyemituje nową wartość, operator bierze tę nową wartość oraz ostatnie znane wartości z pozostałych strumieni.
- Uruchamia blok lambda, w którym łączymy te dane w jeden obiekt wynikowy.
Załóżmy, że mamy repozytorium dostarczające aktualną sumę koszyka oraz pole tekstowe w ViewModelu, gdzie użytkownik wpisuje kod rabatowy.
class CartViewModel(repository: CartRepository) : ViewModel() {
// 1. Strumień z repozytorium (np. z bazy danych)
// Zmienia się rzadko (tylko gdy dodamy produkt)
val cartTotalFlow: Flow<Double> = repository.getCartTotal()
// 2. Strumień z pola tekstowego
// Zmienia się często (przy każdym naciśnięciu klawisza)
val promoCodeFlow = MutableStateFlow("")
// 3. Łączenie w jeden stan UI
val uiState: StateFlow<CartUiState> = combine(
cartTotalFlow,
promoCodeFlow
) { total, code ->
// Ta lambda wykonuje się, gdy zmieni się cena LUB kod
val discount = if (code == "PROMO20") 0.20 else 0.0
val finalPrice = total * (1.0 - discount)
// Zwracamy obiekt stanu
CartUiState(
totalPrice = total,
discountApplied = discount > 0,
finalPriceToPay = finalPrice
)
}.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = CartUiState() // Stan początkowy (pusty)
)
fun onCodeChanged(code: String) {
promoCodeFlow.value = code
}
}Dzięki combine, nasz UI jest w pełni reaktywny. Jeśli użytkownik wpisze poprawny kod, cena przeliczy się natychmiast. Jeśli w międzyczasie w tle przyjdzie aktualizacja ceny z bazy danych - cena również przeliczy się automatycznie, uwzględniając wpisany kod.
Pełne Przykłady Implementacji
Poniżej znajdują się kompletne kody źródłowe omawianych zagadnień, gotowe do przekopiowania do projektu.
Przykład 1: Bezpieczne obliczenia z withContext
Ten przykład pokazuje podejście imperatywne. Wykonujemy ciężką operację (symulacja renderowania wideo) na kliknięcie przycisku, nie blokując paska postępu na ekranie.
// 1. Definicja stanów UI (Sealed Interface)
sealed interface UiState {
data object Idle : UiState
data object Loading : UiState
data class Success(val result: Int) : UiState
}
// 2. ViewModel (Logika biznesowa)
class CalculationViewModel : ViewModel() {
private val _uiState = MutableStateFlow<UiState>(UiState.Idle)
val uiState: StateFlow<UiState> = _uiState.asStateFlow()
fun onCalculateClicked() {
viewModelScope.launch {
_uiState.value = UiState.Loading
val result = performHeavyCalculation()
_uiState.value = UiState.Success(result)
}
}
private suspend fun performHeavyCalculation(): Int {
return withContext(Dispatchers.Default) {
Thread.sleep(2000)
42 * 100
}
}
}
// 3. Widok (Composable)
@Composable
fun CalculationScreen(viewModel: CalculationViewModel = viewmodel()) {
val state by viewModel.uiState.collectAsStateWithLifecycle()
Box(
modifier = Modifier.fillMaxSize(),
contentAlignment = Alignment.Center
) {
Column(
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.spacedBy(16.dp)
) {
// Reakcja na konkretny stan
when (val currentState = state) {
is UiState.Idle -> {
Text(text = "Gotowy do obliczeń")
}
is UiState.Loading -> {
CircularProgressIndicator()
Text(text = "Przetwarzanie...")
}
is UiState.Success -> {
Text(
text = "Wynik: ${currentState.result}"
)
}
}
Button(
onClick = { viewModel.onCalculateClicked() },
enabled = state !is UiState.Loading
) {
Text("Rozpocznij ciężką pracę")
}
}
}
}Przykład 2: Optymalizacja strumienia z flowOn
Ten przykład pokazuje podejście reaktywne. Przenosimy przetwarzanie danych strumieniowych (filtrowanie i sortowanie) na wątek tła, podczas gdy repozytorium i widok pozostają czyste.
// 1. Model danych
data class User(val name: String, val isActive: Boolean)
// 2. Repository (Symulacja warstwy danych)
class UserRepository {
// Funkcja zwraca "zimny" strumień (Cold Flow)
fun fetchUsersFromDb(): Flow<List<User>> = flow {
// SYMULACJA BLOKUJĄCEGO IO
// Normalnie zablokowałoby to UI, gdyby nie flowOn
Thread.sleep(2000)
val users = listOf(
User("Anna Kowalska", true),
User("Jan Nowak", false),
User("Marek Zegarek", true),
User("Zofia Samosia", true)
)
emit(users)
}
}
class UserViewModel : ViewModel() {
private val repository = UserRepository()
val uiState: StateFlow<UiState> = repository.fetchUsersFromDb()
.map { users -> users.filter { it.isActive }}
.flowOn(Dispatchers.IO) // <--- GRANICA ZMIANY KONTEKSTU (Upstream na IO)
.map { users ->
// Ten map jest ZA flowOn, więc wykona się na kontekście kolektora (Main)
UiState.Success(users.map { it.name.uppercase() }) as UiState
}
.onStart {
// Emitujemy stan ładowania na początku subskrypcji
emit(UiState.Loading)
}
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = UiState.Loading
)
}
// Definicja stanów widoku
sealed interface UiState {
data object Loading : UiState
data class Success(val userNames: List<String>) : UiState
}
// 4. Widok (Composable)
@Composable
fun UserListScreen(viewModel: UserViewModel = viewModel()) {
val state by viewModel.uiState.collectAsState()
Box(modifier = Modifier.fillMaxSize(), contentAlignment = Alignment.Center) {
when (val currentState = state) {
is UiState.Loading -> {
Column(horizontalAlignment = Alignment.CenterHorizontally) {
CircularProgressIndicator()
Spacer(modifier = Modifier.height(8.dp))
Text("Pobieranie bazy danych...")
Text("(Sprawdź Logcat)")
}
}
is UiState.Success -> {
LazyColumn(
modifier = Modifier.fillMaxSize(),
contentPadding = PaddingValues(16.dp)
) {
item {
Text(
"Aktywni Użytkownicy:",
modifier = Modifier.padding(bottom = 16.dp)
)
}
items(currentState.userNames) { name ->
Card(
modifier = Modifier
.fillMaxWidth()
.padding(vertical = 4.dp),
elevation = CardDefaults.cardElevation(defaultElevation = 2.dp)
) {
Text(
text = name,
modifier = Modifier.padding(16.dp) )
}
}
}
}
}
}
}Przykład 3: Łączenie strumieni danych z combine
// 1. Model Stanu UI
data class CartUiState(
val baseTotal: Double = 0.0,
val finalPrice: Double = 0.0,
val discountApplied: Boolean = false,
val currentCode: String = ""
)
// 2. Repository (Symulacja danych zewnętrznych)
class CartRepository {
// Symuluje koszyk, który zmienia się w czasie
fun getCartTotal(): Flow<Double> = flow {
// Startowa cena koszyka
emit(100.0)
// Po 5 sekundach symulujemy, że np. dodano produkt na innym urządzeniu
delay(5000)
emit(200.0) // Cena rośnie. Combine automatycznie przeliczy wynik.
}
}
// 3. ViewModel (Logika łączenia strumieni)
class CartViewModel : ViewModel() {
private val repository = CartRepository()
// Strumień 1: Cena z bazy danych (Read-only Flow)
private val cartTotalFlow = repository.getCartTotal()
// Strumień 2: Kod wpisywany przez usera (MutableStateFlow)
private val promoCodeFlow = MutableStateFlow("")
// Operator combine
val uiState: StateFlow<CartUiState> = combine(
cartTotalFlow,
promoCodeFlow
) { total, code ->
// Ta lambda uruchamia się, gdy zmieni się ALBO cena, ALBO kod
// Logika biznesowa rabatu
val isPromoValid = code.trim() == "PROMO20"
val discount = if (isPromoValid) 0.20 else 0.0
val finalPrice = total * (1.0 - discount)
// Zwracamy nowy, połączony stan
CartUiState(
baseTotal = total,
finalPrice = finalPrice,
discountApplied = isPromoValid,
currentCode = code
)
}.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = CartUiState()
)
// Funkcja wywoływana z UI przy wpisywaniu tekstu
fun onCodeChanged(newCode: String) {
promoCodeFlow.value = newCode
}
}
// 4. Widok (Composable)
@Composable
fun ShoppingCartScreen(viewModel: CartViewModel = viewModel()) {
// UI reaguje na każdą zmianę w uiState (pochodzącą z dowolnego strumienia)
val state by viewModel.uiState.collectAsStateWithLifecycle()
Column(
modifier = Modifier
.fillMaxSize()
.padding(24.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text("Twój Koszyk")
Spacer(modifier = Modifier.height(32.dp))
// Karta z podsumowaniem
Card(
elevation = CardDefaults.cardElevation(defaultElevation = 4.dp),
modifier = Modifier.fillMaxWidth()
) {
Column(modifier = Modifier.padding(16.dp)) {
Row(
modifier = Modifier.fillMaxWidth(),
horizontalArrangement = Arrangement.SpaceBetween
) {
Text("Cena produktów:")
Text(
"${state.baseTotal} PLN",
fontWeight = FontWeight.Bold
)
}
// Wiersz: Rabat
if (state.discountApplied) {
Row(
modifier = Modifier.fillMaxWidth(),
horizontalArrangement = Arrangement.SpaceBetween
) {
Text("Rabat (PROMO20):")
Text(
"-20%",
fontWeight = FontWeight.Bold
)
}
}
Divider(modifier = Modifier.padding(vertical = 8.dp))
// Wiersz: Suma końcowa
Row(
modifier = Modifier.fillMaxWidth(),
horizontalArrangement = Arrangement.SpaceBetween
) {
Text("Do zapłaty:")
Text(
"${state.finalPrice} PLN",
)
}
}
}
Spacer(modifier = Modifier.height(24.dp))
// Pole tekstowe do wprowadzania kodu
OutlinedTextField(
value = state.currentCode,
onValueChange = { viewModel.onCodeChanged(it) },
label = { Text("Kod rabatowy") },
placeholder = { Text("Wpisz: PROMO20") },
singleLine = true,
modifier = Modifier.fillMaxWidth(),
isError = state.currentCode.isNotEmpty() && !state.discountApplied,
supportingText = {
if (state.currentCode.isNotEmpty() && !state.discountApplied) {
Text("Nieprawidłowy kod")
} else if (state.discountApplied) {
Text("Kod przyjęty!", color = Color(0xFF2E7D32))
}
}
)
}
}W poprzednich rozdziałach do przesyłania danych używaliśmy strumieni (Flow). Strumień działał jak radio: stacja nadawcza emitowała sygnał, a każdy, kto nastroił odbiornik (collect), otrzymywał te same dane.
Co jednak w sytuacji, gdy potrzebujemy precyzyjnej komunikacji jeden-do-jednego? Wyobraźmy sobie fabrykę: jedna maszyna produkuje śruby, a druga je pakuje. Każda śruba wyprodukowana przez maszynę A musi trafić do maszyny B. Nie chcemy, aby śruba zaginęła, ani żeby trafiła do dwóch paczek naraz. Do takich zadań Kotlin udostępnia osobny prymityw synchronizacyjny: Kanały (Channels).
Kanał (Channel) to koncepcyjnie taśmociąg łączący dwie korutyny.
- Nadawca (Producer): Wrzuca dane z jednej strony rury.
- Odbiorca (Consumer): Wyciąga dane z drugiej strony.




Channel.Kluczową cechą kanałów jest to, że służą one nie tylko do przesyłania danych, ale także do synchronizacji pracy korutyn. Jeśli rura jest pusta, odbiorca czeka. Jeśli rura jest pełna (w przypadku kanałów buforowanych), nadawca czeka.
Channel vs Flow (SharedFlow)
Różnica jest fundamentalna i dotyczy modelu dystrybucji danych.
Uwaga: Kanał może mieć wielu odbiorców, ale wtedy działają oni jak konkurencyjni pracownicy - każdy element zostanie obsłużony tylko przez jednego z nich. W SharedFlow każdy pracownik dostałby kopie wszystkich zadań.
- Użyj StateFlow/SharedFlow, gdy dane mają trafić do warstwy UI (Widoku). UI zazwyczaj tylko obserwuje stan i nie konsumuje go bezpowrotnie.
- Użyj Channel, gdy implementujesz mechanizm producent-konsument wewnątrz logiki biznesowej (np. kolejka plików do wysłania na serwer).
Podstawowe API: send() i receive()
W przeciwieństwie do Flow, który definiujemy deklaratywnie, obsługa Kanału przypomina obsługę tradycyjnej kolejki, ale z jedną kluczową różnicą: jest ona asynchroniczna.
Interfejs Channel<T> implementuje dwa mniejsze interfejsy:
SendChannel<T>- pozwala tylko wysyłać i zamykać kanał.ReceiveChannel<T>- pozwala tylko odbierać dane.
Dzięki temu możemy przekazać odbiorcy tylko interfejs ReceiveChannel, mając pewność, że przez pomyłkę nic nie wyśle ani nie zamknie kanału. Dwie główne metody obsługi kanału to send(element) oraz receive(). Obie są funkcjami zawieszającymi (suspend).
- receive() zawiesza, gdy kanał jest pusty.
- send() zawiesza, gdy kanał jest pełny.
Konsument podchodzi do taśmociągu. Jeśli nie ma tam żadnej paczki, nie blokuje wątku (nie stoi bezczynnie). Korutyna zawiesza się (idzie na przerwę) i zostanie wznowiona dopiero, gdy Nadawca wrzuci coś do kanału.
Jeśli taśmociąg ma ograniczoną pojemność (co omówimy w sekcji 7.4) i jest zapchany, Nadawca nie może wrzucić nowej paczki. Korutyna zawiesza się i czeka, aż Konsument zdejmie coś z taśmy, robiąc miejsce.
val channel = Channel<Int>()
// KORUTYNA 1: Producent
launch {
for (x in 1..5) {
// Jeśli odbiorca nie jest gotowy, send() zawiesi tę korutynę
channel.send(x * x)
delay(100)
}
// Ważne: Sygnał, że więcej danych nie będzie
channel.close()
}
// KORUTYNA 2: Konsument
launch {
// Pętla for automatycznie kończy działanie,
// gdy kanał zostanie zamknięty
for (y in channel) {
println("Odebrano: $y")
}
println("Kanał zamknięty, koniec pracy.")
}Kanał jest koncepcyjnie otwarty tak długo, jak go nie zamkniemy. W przeciwieństwie do Flow, który kończy się naturalnie po wykonaniu bloku kodu, Kanał może działać w nieskończoność.
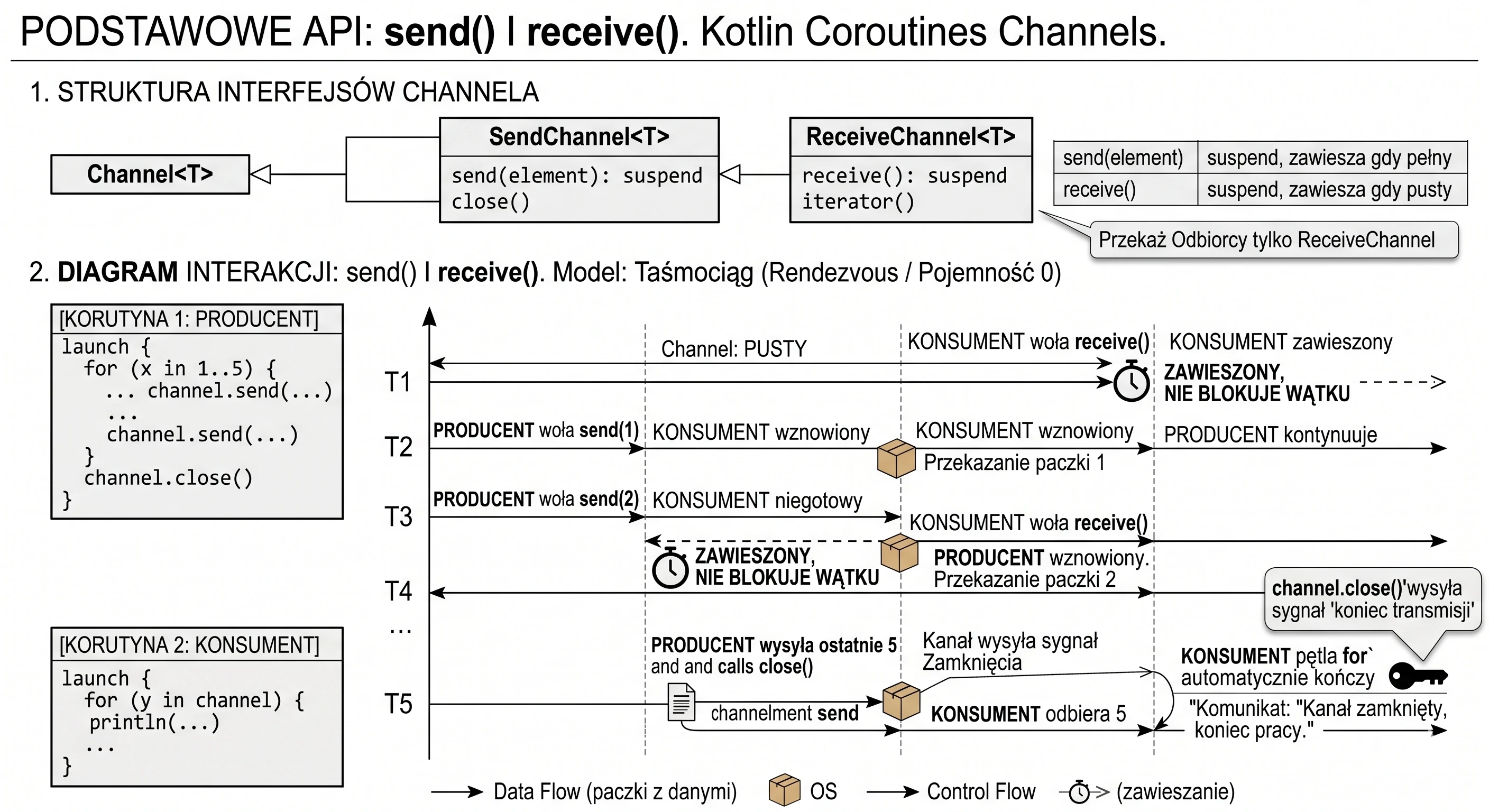
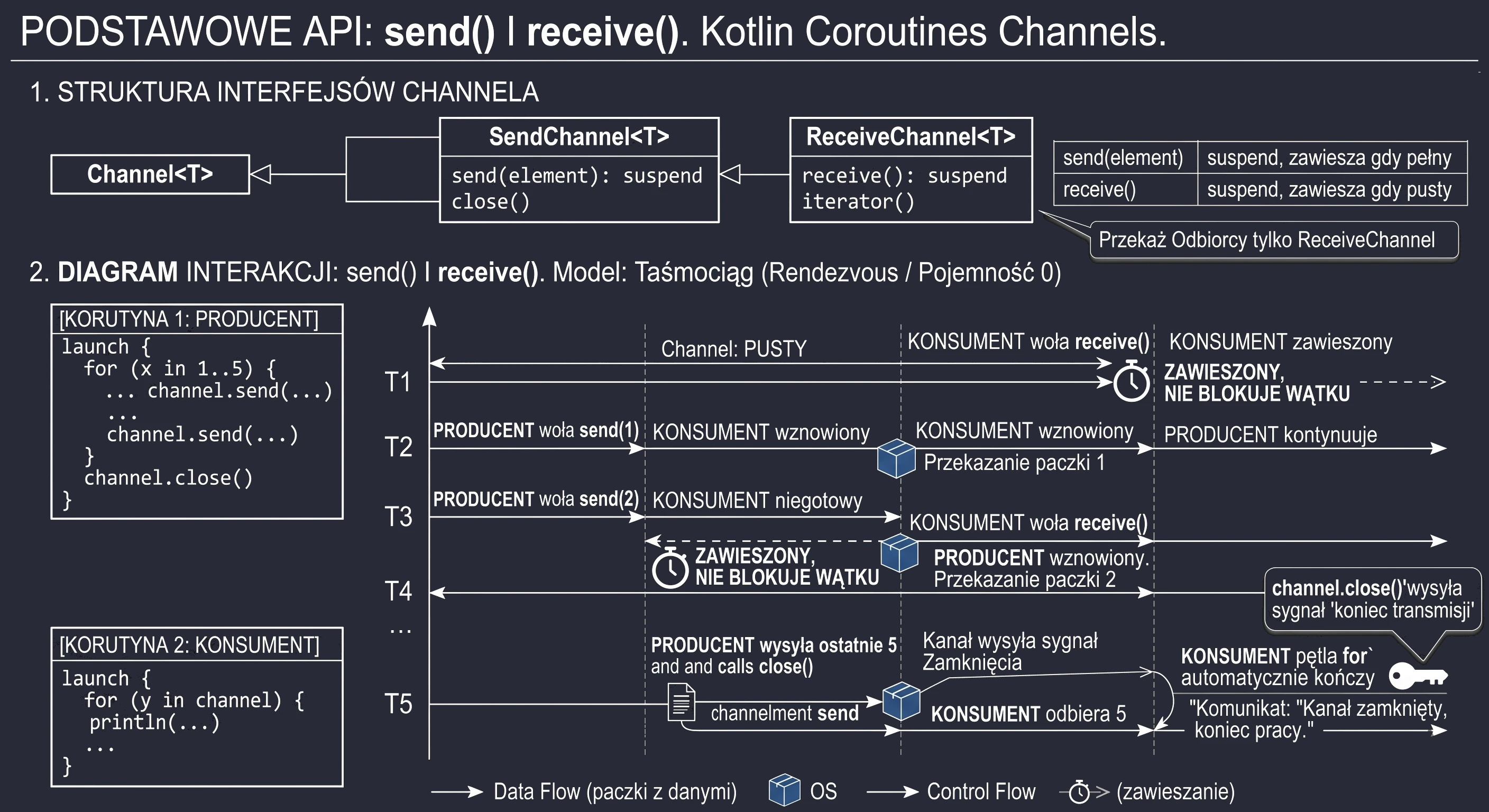
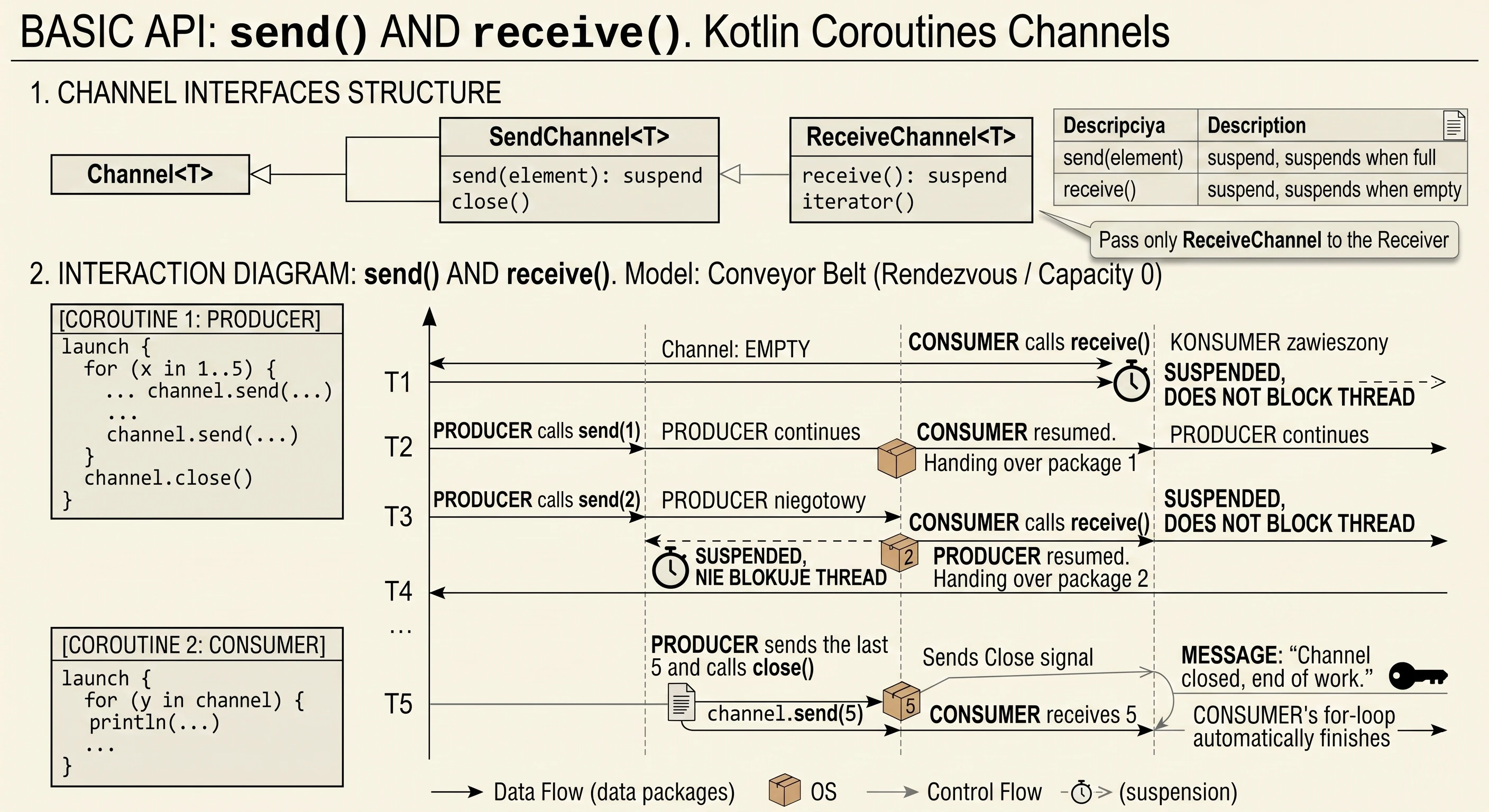
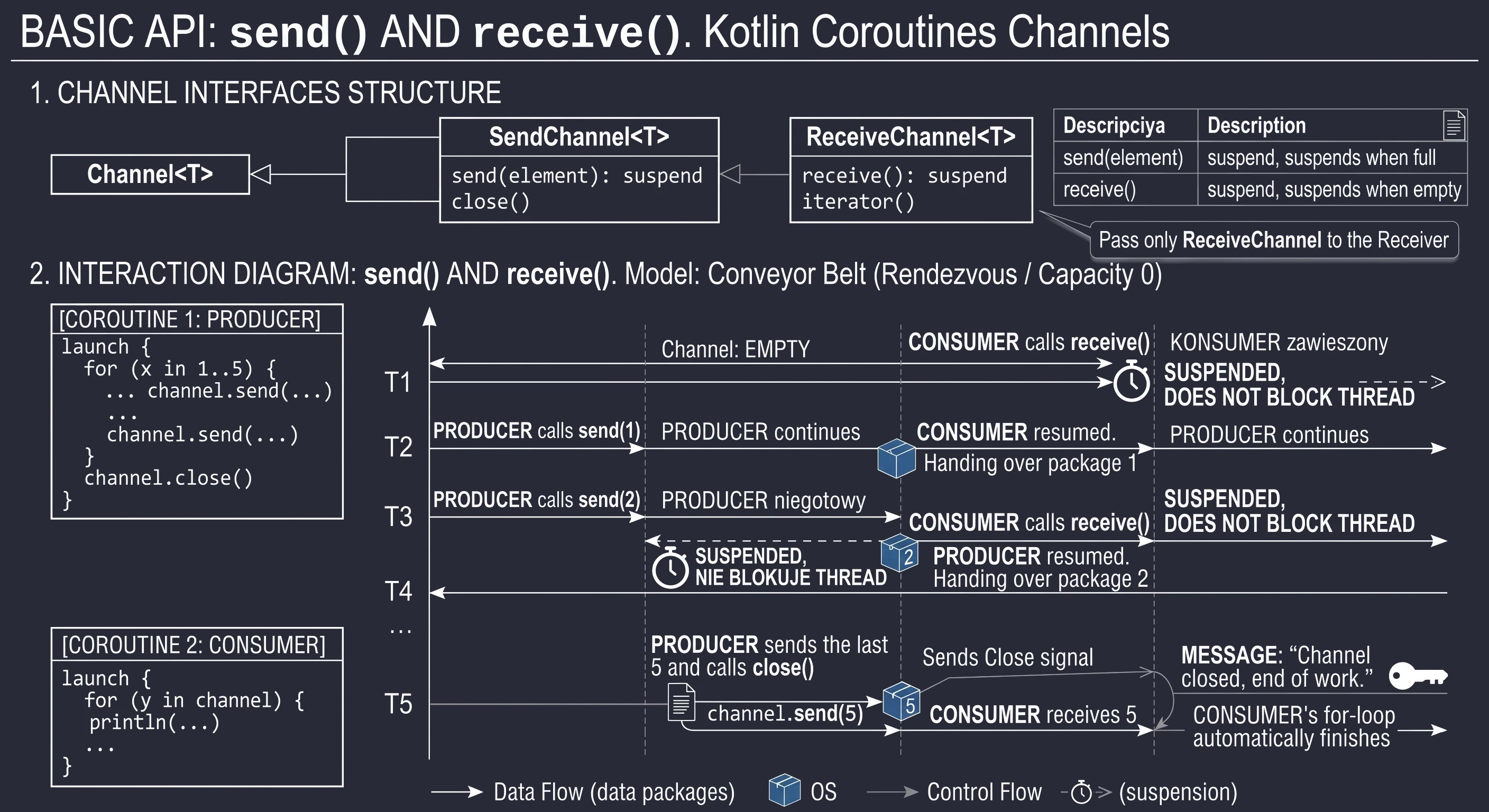
Metoda close() wysyła specjalny sygnał koniec transmisji.
- Próba wysłania (
send) na zamknięty kanał rzuci wyjątekClosedSendChannelException. - Próba odbioru (
receive) z zamkniętego kanału (gdy bufor jest pusty) rzuci wyjątekClosedReceiveChannelException.
Częściej można się spotkać z zastosowaniem for (item in channel), która automatycznie obsługuje zamknięcie kanału i bezpiecznie wychodzi z pętli.
Rodzaje Kanałów (Buforowanie)
Konstruktor klasy Channel przyjmuje opcjonalny parametr capacity. To on decyduje o tym, kiedy funkcja send() zawiesi nadawcę. Wybór odpowiedniego typu bufora jest kluczowy dla zarządzania przepływem danych.
Rendezvous (Domyślny)
capacity = Channel.RENDEZVOUS (lub 0).
To domyślny i najbardziej restrykcyjny typ kanału. Nie posiada on żadnego bufora.
- Działanie: Nadawca i Odbiorca muszą się spotkać (fr. rendezvous) w tym samym momencie.
- Zachowanie:
send()zawiesza się dopóki druga strona nie wywołareceive(). I odwrotnie. - Metafora: Przekazywanie pałeczki w sztafecie. Biegacz A nie może puścić pałeczki, dopóki B jej nie chwyci.
Jest to idealne rozwiązanie do ścisłej synchronizacji dwóch wątków.
Buffered (Buforowany)
capacity = liczba dodatnia (np. 10).
Kanał posiada kolejkę o ustalonym rozmiarze (ArrayChannel).
- Działanie: Nadawca może wysłać tyle elementów, ile mieści bufor, nie czekając na odbiorcę.
- Zachowanie:
send()zawiesza się dopiero, gdy bufor jest pełny. - Metafora: Taśmociąg w fabryce. Maszyna produkująca może pracować szybciej przez chwilę, zapełniając taśmę, nawet jeśli maszyna pakująca chwilowo stanęła.
Conflated (Scalony/Nadpisujący)
capacity = Channel.CONFLATED.
Specyficzny kanał o pojemności 1, który nigdy nie wstrzymuje nadawcy.
- Działanie: Jeśli odbiorca nie nadąża, stare elementy są wyrzucane, a w kanale zostaje tylko ten najnowszy.
- Zachowanie:
send()nigdy się nie zawiesza. - Metafora: Tablica z kursami walut. Nie interesuje nas historia zmian z ostatnich 5 minut, chcemy widzieć tylko aktualną cenę.
Unlimited (Nielimitowany)
capacity = Channel.UNLIMITED.
Kanał z buforem opartym na liście łączonej (LinkedList), która rośnie w nieskończoność.
- Działanie: Przyjmuje wszystko.
- Zachowanie:
send()nigdy się nie zawiesza (chyba że braknie pamięci RAM). - Ostrzeżenie: Używanie tego kanału jest ryzykowne. Jeśli nadawca jest szybszy od odbiorcy, program w końcu wyrzuci błąd
OutOfMemoryError.
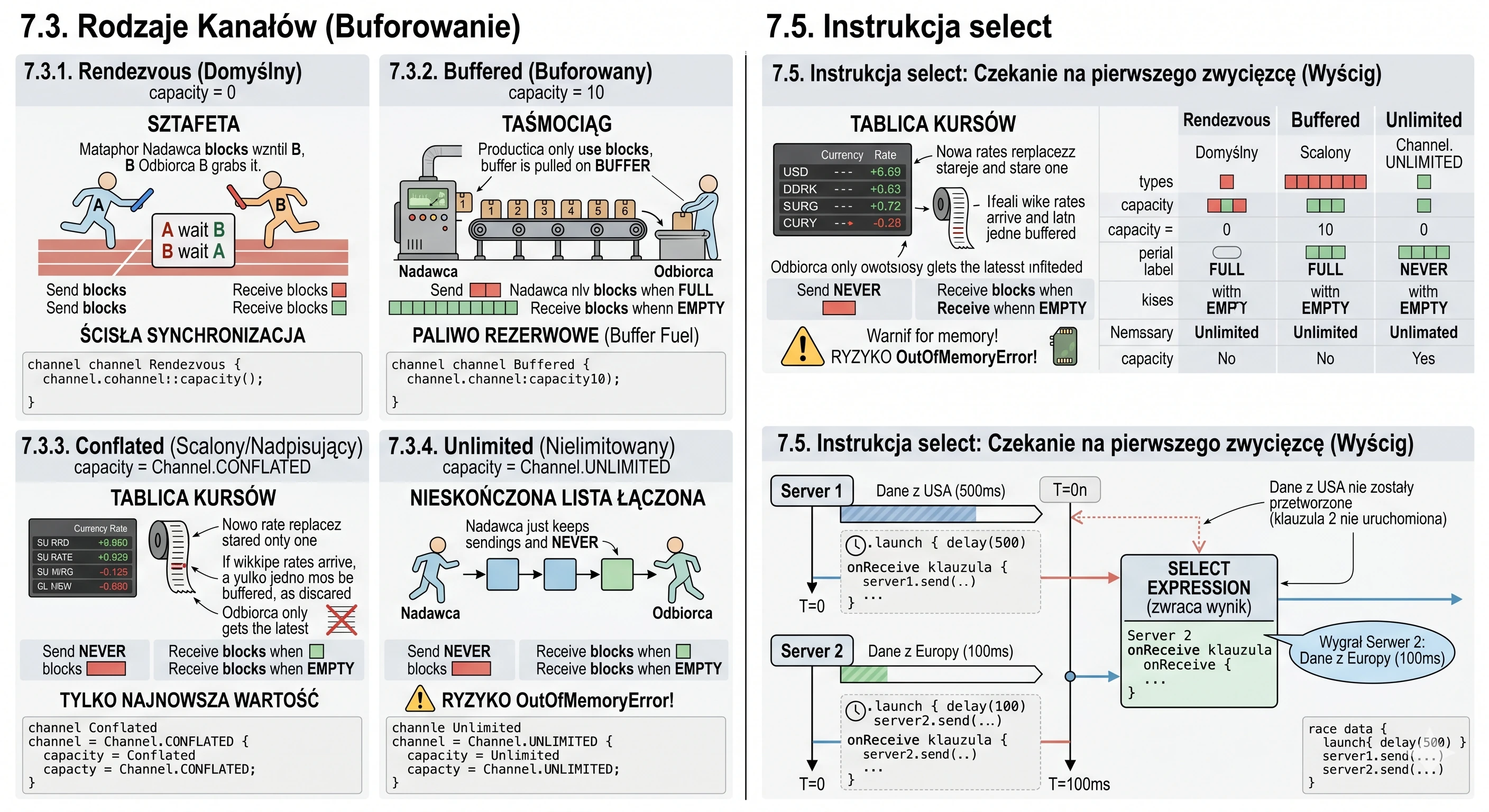
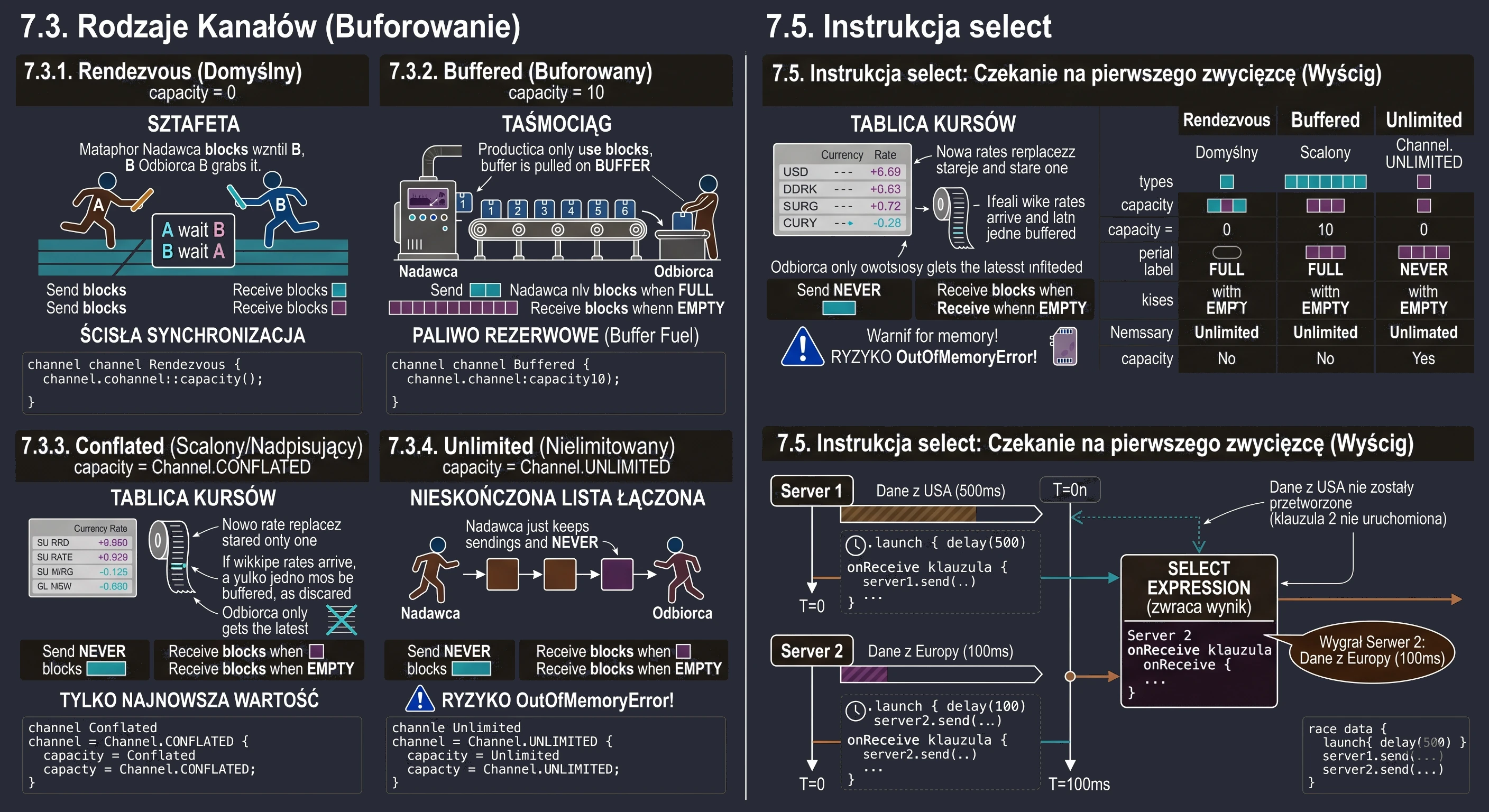
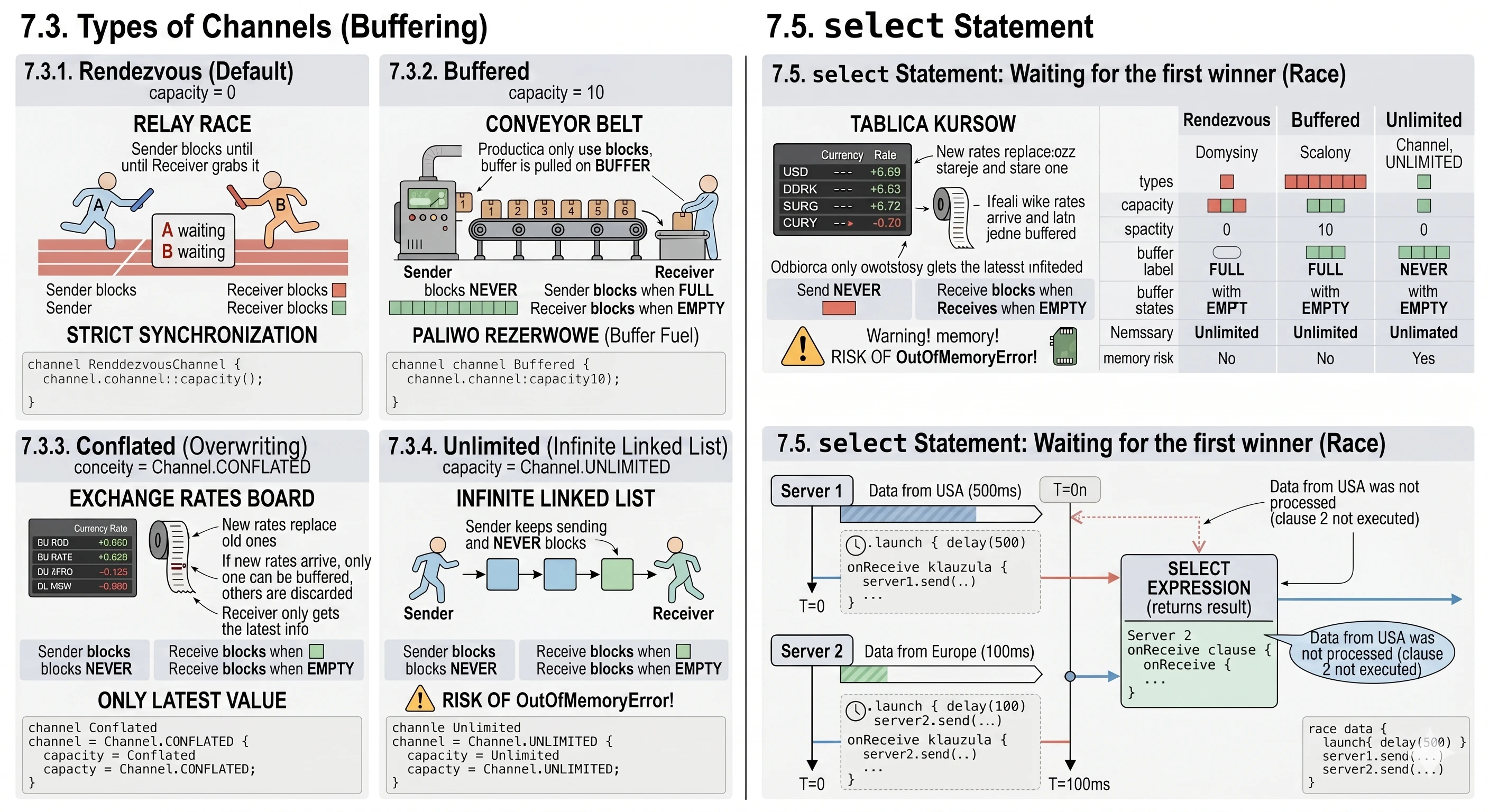
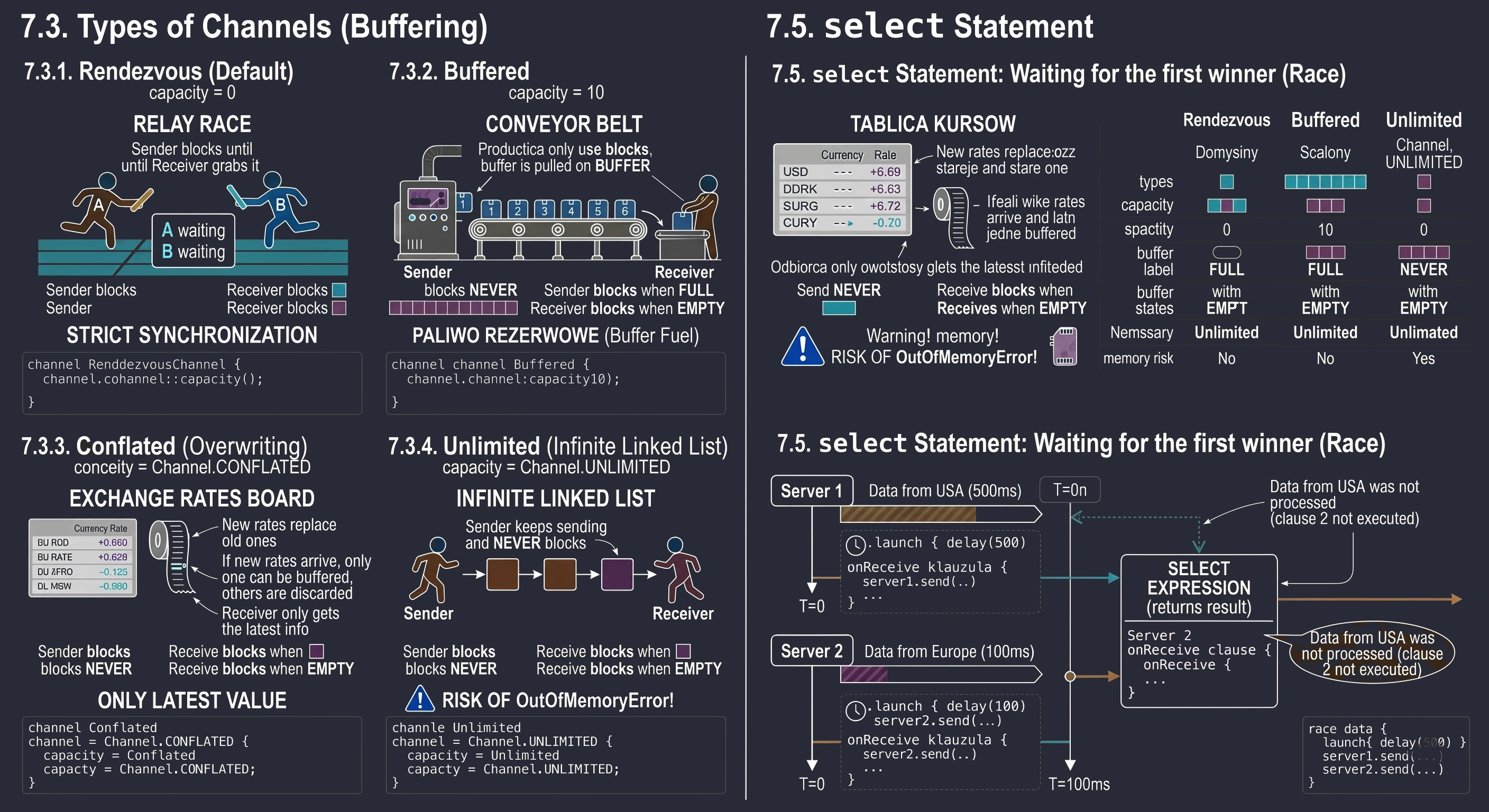
Przykład konfiguracji
// 1. Rendezvous (domyślny) - ścisła synchronizacja
val c1 = Channel<Int>()
// 2. Buffered - bufor na 10 elementów
val c2 = Channel<Int>(10)
// 3. Conflated - tylko najnowsza wartość
val c3 = Channel<Int>(Channel.CONFLATED)Warto zauważyć, że StateFlow działa bardzo podobnie do kanału typu Conflated (trzyma tylko najnowszy stan), podczas gdy zwykły Flow z buforem zachowuje się jak kanał Buffered.
Instrukcja select
W standardowym kodzie asynchronicznym (używając await lub receive) czekamy sekwencyjnie: najpierw na wynik A, potem na wynik B. Mamy jeszcze jedną możliwość: możemy przetworzyć wynik z tego, które odpowie szybciej za pomocą wyrażenia select. Pozwala ono nasłuchiwać na wielu kanałach (lub obiektach Deferred) jednocześnie i uruchomić kod skojarzony tylko z tym zdarzeniem, które nastąpi jako pierwsze.
Wyrażenie select<T> zwraca wynik typu T. Wewnątrz bloku definiujemy klauzule (np. onReceive), które mówią co zrobić, jeśli to źródło wygra wyścig.
suspend fun raceData() {
val server1 = Channel<String>()
val server2 = Channel<String>()
// Symulacja: Serwer 1 jest wolny
launch {
delay(500)
server1.send("Dane z USA (500ms)")
}
// Symulacja: Serwer 2 jest szybki
launch {
delay(100)
server2.send("Dane z Europy (100ms)")
}
// WYŚCIG: Czekamy na PIERWSZY wynik
val winner = select<String> {
// Klauzula 1: Jeśli server1 wyśle pierwszy...
server1.onReceive { msg ->
"Wygrał Serwer 1: $msg"
}
// Klauzula 2: Jeśli server2 wyśle pierwszy...
server2.onReceive { msg ->
"Wygrał Serwer 2: $msg"
}
}
println(winner)
}Zastosowanie Praktyczne: Timeout
Najczęstszym zastosowaniem select jest zastosowanie onTimeout, aby zrezygnować z czekania, jeśli operacja trwa zbyt długo.
val dataChannel = Channel<String>()
val result = select<String?> {
// Opcja 1: Dane przyszły na czas
dataChannel.onReceive { it }
// Opcja 2: Minął czas (np. 1 sekunda)
onTimeout(1000) {
println("Za długo! Anuluję.")
null
}
}Przykład Zastosowania Kanałów
Aby utrwalić wiedzę o kanałach, zbudujmy symulację aukcji internetowej.
Mamy tutaj do czynienia z asymetrią:
- Producenci (Licytujący): Jest ich wielu. Działają na różnych wątkach, w różnym tempie. Nie wiedzą o sobie nawzajem.
- Kanał (Stolik aukcyjny): Punkt synchronizacji. Gwarantuje, że oferty będą przetwarzane po kolei, nawet jeśli wpłynęły w tej samej milisekundzie.
- Konsument (Aukcjoner): Jest jeden. Jego zadaniem jest walidacja ofert (np. czy nowa oferta jest wyższa od poprzedniej) i ogłaszanie zwycięzcy.
Gdybyśmy użyli tutaj zwykłej zmiennej (var currentPrice), musielibyśmy używać mutexów lub blokad, aby uniknąć Race Conditions. Kanał zdejmuje z nas ten ciężar - on kolejkuje dostęp do aukcjonera.
Zobaczmy, jak wygląda to w kodzie. Kluczowym elementem jest pętla for iterująca po kanale.
// Prosty model danych oferty
data class Bid(val bidderName: String, val amount: Int)
class AuctionViewModel : ViewModel() {
// Stan UI (obserwowany przez Compose)
private val _uiState = MutableStateFlow(AuctionUiState())
val uiState = _uiState.asStateFlow()
// KANAŁ: Serce synchronizacji.
// Używamy UNLIMITED lub dużej pojemności, aby nie blokować licytujących,
private val bidChannel = Channel<Bid>(capacity = Channel.UNLIMITED)
init {
// Startujemy "Aukcjonera" w momencie powstania ViewModela
startAuctioneer()
}
// --- KONSUMENT (Aukcjoner) ---
private fun startAuctioneer() {
viewModelScope.launch {
// Pętla for zawiesza się, gdy kanał jest pusty.
// Gdy pojawią się oferty, bierze je PO JEDNEJ na raz.
for (bid in bidChannel) {
// Pobieramy aktualny stan
val currentState = _uiState.value
// Logika Biznesowa: Czy oferta jest ważna?
// ma prawo zmieniać stan w oparciu o oferty!
if (bid.amount > currentState.currentPrice) {
val newLog = "${bid.bidderName} podbija do ${bid.amount} PLN"
_uiState.update {
it.copy(
currentPrice = bid.amount,
winningBidder = bid.bidderName,
logs = it.logs + newLog
)
}
} else {
// Oferta za niska - ignorujemy lub logujemy błąd
val errorLog = "Odrzucono ${bid.amount} od ${bid.bidderName} (za mało)"
_uiState.update { it.copy(logs = it.logs + errorLog) }
}
// Symulacja czasu przetwarzania (np. aukcjoner wykrzykuje cenę)
delay(50)
}
}
}
// --- PRODUCENT (Licytujący) ---
fun placeBid(name: String, amount: Int) {
viewModelScope.launch {
// To jest operacja atomowa.
bidChannel.send(Bid(name, amount))
}
}
// Sprzątanie
override fun onCleared() {
super.onCleared()
bidChannel.close() // Zamykamy kanał
}
}Pełne Przykłady Implementacji
Przykład 1: System Aukcyjny
W tym przykładzie ViewModel pełni rolę "Aukcjonera". Posiada jeden Kanał, do którego spływają oferty z różnych przycisków (symulujących różnych użytkowników). Dzięki pętli for na kanale, oferty są przetwarzane sekwencyjnie, co eliminuje ryzyko błędów współbieżności (Race Condition) przy aktualizacji ceny.
// --- 1. Model Danych ---
data class Bid(val bidderName: String, val amount: Int)
data class AuctionUiState(
val currentPrice: Int = 100,
val winningBidder: String = "Brak",
val recentLogs: List<String> = emptyList(), // Log ostatnich zdarzeń
val isAuctionActive: Boolean = true
)
// --- 2. ViewModel (Aukcjoner) ---
class AuctionViewModel : ViewModel() {
private val _uiState = MutableStateFlow(AuctionUiState())
val uiState = _uiState.asStateFlow()
// KANAŁ: Lejek, do którego wpadają oferty z różnych wątków UI
private val bidChannel = Channel<Bid>(capacity = Channel.UNLIMITED)
init {
startAuctioneer()
}
private fun startAuctioneer() {
viewModelScope.launch {
// KONSUMENT: Ta pętla działa tak długo, jak kanał jest otwarty.
// Gwarantuje przetwarzanie ofert jedna po drugiej.
for (bid in bidChannel) {
val currentState = _uiState.value
// Walidacja oferty (logika biznesowa)
if (bid.amount > currentState.currentPrice) {
_uiState.update {
it.copy(
currentPrice = bid.amount,
winningBidder = bid.bidderName,
recentLogs = (
it.recentLogs +
"${bid.bidderName} przebija na ${bid.amount} PLN"
).takeLast(5)
)
}
} else {
_uiState.update {
it.copy(
recentLogs = (
it.recentLogs +
"Odrzucono ${bid.amount} od ${bid.bidderName} (za mało)"
).takeLast(5)
)
}
}
// Symulacja czasu reakcji aukcjonera
delay(100)
}
}
}
// PRODUCENT: Funkcja wywoływana z UI (Button)
fun placeBid(name: String) {
if (!_uiState.value.isAuctionActive) return
// Wrzucamy ofertę do kanału
val randomBid = _uiState.value.currentPrice + Random.nextInt(10, 50)
viewModelScope.launch {
bidChannel.send(Bid(name, randomBid))
}
}
fun stopAuction() {
_uiState.update {
it.copy(
isAuctionActive = false,
recentLogs = it.recentLogs + "AUKCJA ZAKOŃCZONA")
}
bidChannel.close() // Zamykamy kanał -
//pętla w 'startAuctioneer' zakończy działanie
}
}
// --- 3. Widok (Compose) ---
@Composable
fun AuctionScreen(viewModel: AuctionViewModel = viewModel()) {
val state by viewModel.uiState.collectAsStateWithLifecycle()
Column(modifier = Modifier.padding(16.dp)) {
Text("Aktualna cena: ${state.currentPrice} PLN")
Text("Wygrywa: ${state.winningBidder}")
Spacer(Modifier.height(16.dp))
// Przyciski symulujące różnych graczy
Row(horizontalArrangement = Arrangement.spacedBy(8.dp)) {
Button(
onClick = { viewModel.placeBid("Ania") },
enabled = state.isAuctionActive
) { Text("Ania licytuje") }
Button(
onClick = { viewModel.placeBid("Tomek") },
enabled = state.isAuctionActive
) { Text("Tomek licytuje") }
}
Button(
onClick = { viewModel.stopAuction() },
modifier = Modifier.padding(top = 8.dp)
) { Text("Zakończ aukcję") }
Spacer(Modifier.height(16.dp))
Text("Log aukcji:")
LazyColumn {
items(state.recentLogs) { log -> Text(log) }
}
}
}Przykład 2: Wyścig Serwerów z Select
Przykład pokazujący użycie instrukcji select wewnątrz ViewModela. Użytkownik klika Szukaj oferty, a ViewModel wysyła zapytania do dwóch źródeł równolegle. Wygrywa to, które odpowie pierwsze.
// --- 1. ViewModel ---
class RaceViewModel : ViewModel() {
var resultText by mutableStateOf("Naciśnij start, aby wyszukać")
private set
var isSearching by mutableStateOf(false)
private set
@OptIn(ExperimentalCoroutinesApi::class)
fun startRace() {
viewModelScope.launch {
isSearching = true
resultText = "Szukanie najszybszej oferty..."
// Tworzymy dwa kanały symulujące dwa serwery
val fastServer = Channel<String>()
val slowServer = Channel<String>()
// Uruchamiamy "producentów" danych
launch {
delay(Random.nextLong(200, 1500)) // Losowy czas
fastServer.send("Oferta z Amazon (USA)")
}
launch {
delay(Random.nextLong(200, 1500)) // Losowy czas
slowServer.send("Oferta z Allegro (PL)")
}
// SELECT: Czekamy na PIERWSZY wynik
val winner = select<String> {
fastServer.onReceive { offer -> "Wygrał FastServer: $offer" }
slowServer.onReceive { offer -> "Wygrał SlowServer: $offer" }
// Timeout, jeśli oba serwery będą zbyt wolne (np. > 1000ms)
onTimeout(1000) { "Błąd: Przekroczono limit czasu (Timeout)!" }
}
resultText = winner
isSearching = false
}
}
}
// --- 2. Widok (Compose) ---
@Composable
fun RaceScreen(viewModel: RaceViewModel = viewModel()) {
Column(
modifier = Modifier.fillMaxSize(),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
if (viewModel.isSearching) {
CircularProgressIndicator()
}
Spacer(Modifier.height(16.dp))
Text(viewModel.resultText)
Spacer(Modifier.height(32.dp))
Button(
onClick = { viewModel.startRace() },
enabled = !viewModel.isSearching
) {
Text("Znajdź najlepszą ofertę (Wyścig)")
}
}
}W poprzednich rozdziałach, omawiając architekturę MVVM i zarządzanie stanem, operowaliśmy na danych przechowywanych w pamięci operacyjnej (RAM). Zmienne wewnątrz ViewModel, strumienie StateFlow czy kolekcje danych istnieją tak długo, jak długo żyje proces aplikacji.
W ekosystemie Androida wyróżniamy trzy główne kategorie przechowywania danych, dobierane w zależności od struktury i wolumenu informacji:
- Pliki (File API): Przeznaczone dla danych niestrukturalnych lub strumieni bajtów, takich jak multimedia (zdjęcia, wideo), dokumenty PDF czy pliki cache.
- Relacyjne Bazy Danych (SQLite / Room): Przeznaczone dla dużych zbiorów danych strukturalnych, wymagających złożonych zapytań, relacji i transakcyjności (np. lista zadań, historia zamówień). Temat ten zostanie omówiony szczegółowo w Rozdziale 9.
- Magazyny Klucz-Wartość (Preferences): Przeznaczone dla lekkich danych konfiguracyjnych, flag i prostych ustawień (np.
isDarkModeEnabled,sessionToken). To na tej kategorii skupiamy się w bieżącym rozdziale.
Mechanizm SharedPreferences
Przez wiele lat standardem przechowywania prostych danych w Androidzie była biblioteka SharedPreferences. Choć obecnie jest wypierana przez nowsze rozwiązania, wciąż można ją spotkać w wielu istniejących projektach.
SharedPreferences to API, które zarządza plikiem XML przechowywanym w prywatnym katalogu aplikacji. Dane są zapisywane w formacie pary: Klucz (String) -> Wartość (Int, Boolean, String, Float, Long).
class SettingsManager(context: Context) {
// Utworzenie/Otwarcie pliku "app_settings.xml"
private val prefs = context.getSharedPreferences(
"app_settings",
Context.MODE_PRIVATE
)
fun saveTheme(isDark: Boolean) {
prefs.edit()
.putBoolean("is_dark_mode", isDark)
.apply()
}
fun isDarkMode(): Boolean {
return prefs.getBoolean("is_dark_mode", false)
}
}Analizując powyższy kod, warto pochylić się nad dwoma kluczowymi elementami: rolą obiektu Context oraz trybem otwarcia pliku.
Metoda getSharedPreferences() nie jest metodą statyczną - musi zostać wywołana na instancji Context. Wynika to z architektury bezpieczeństwa systemu Android.
Każda aplikacja w systemie Android działa jako oddzielny użytkownik i posiada swój prywatny, chroniony katalog na dysku. Obiekt Context jest oknem na zasoby systemowe i środowisko aplikacji. To on wie, gdzie fizycznie znajduje się katalog prywatny bieżącej aplikacji. Bez niego biblioteka nie wiedziałaby, w której ścieżce utworzyć lub odczytać plik XML.
Drugim parametrem metody jest flaga mode. Określa ona uprawnienia systemu plików nadawane tworzonemu plikowi XML.
Context.MODE_PRIVATE(0): Oznacza on, że utworzony plik może być odczytany wyłącznie przez aplikację, która go stworzyła. Gwarantuje to, że inne aplikacje zainstalowane na telefonie nie będą mogły podglądać zapisanych tam danych.
Mimo prostoty, SharedPreferences posiada istotne wady architektoniczne, które stały się problematyczne w nowoczesnym, reaktywnym programowaniu.
- Synchroniczne API (Blokowanie Wątku): Najpoważniejszą wadą jest to, że metody odczytu (np.
getString,getBoolean) są wywoływane synchronicznie. - Brak natywnej reaktywności:
SharedPreferencesnie udostępnia strumieni danych. Aby obserwować zmiany w ustawieniach, programista musi rejestrować złożony listenerOnSharedPreferenceChangeListener. Nie integruje się to naturalnie z biblioteką Kotlin Coroutines ani Flow.
Gdy wywołujemy prefs.getBoolean() na Wątku Głównym (UI Thread), aplikacja musi poczekać na odczyt danych z systemu plików. Jeśli plik preferencji jest duży lub urządzenie jest obciążone operacjami I/O, może to doprowadzić do gubienia klatek animacji (Jank), a w skrajnych przypadkach do błędu ANR (Application Not Responding).
DataStore
Google wprowadziło DataStore jako następcę SharedPreferences. Biblioteka ta została zaprojektowana od podstaw z myślą o asynchroniczności i bezpieczeństwie typów.
Główne zalety DataStore:
- Integracja z Korutynami i Flow: Operacje odczytu są wystawiane jako strumień
Flow, a zapisu jako funkcje zawieszającesuspend. - Bezpieczeństwo wątkowe: Operacje dyskowe są domyślnie przenoszone na
Dispatchers.IO. - Obsługa błędów: Posiada wbudowane mechanizmy łapania wyjątków
IOExceptionpodczas odczytu pliku.
Istnieją dwa warianty biblioteki:
- Preferences DataStore: (Omówimy go teraz) Działa jak
SharedPreferences(mapa Klucz-Wartość), nie wymaga definiowania schematu. - Proto DataStore: Przechowuje typowane obiekty (wymaga definicji schematu przy użyciu Protocol Buffers). Zapewnia bezpieczeństwo typów, ale jest trudniejszy w konfiguracji.
DataStore nie zwraca wartości natychmiast. Zwraca strumień (Flow), który emituje nową wartość za każdym razem, gdy dane na dysku ulegną zmianie.
Najpierw tworzymy instancję DataStore jako Singleton (rozszerzenie dla Context). Jest to kluczowe, aby uniknąć konfliktów przy jednoczesnym dostępie do pliku.
// W pliku np. DataStoreConfig.kt
val Context.dataStore: DataStore<Preferences> by preferencesDataStore(name = "user_prefs")
object UserPrefsKeys {
// Definiujemy klucze z określeniem typu danych
val USER_NAME = stringPreferencesKey("user_name")
val IS_DARK_MODE = booleanPreferencesKey("is_dark_mode")
}Dobrą praktyką jest ukrycie bezpośredniego dostępu do DataStore w warstwie repozytorium.
class UserPreferencesRepository(private val context: Context) {
// ODCZYT: Zwracamy Flow. UI będzie nasłuchiwać zmian.
val userNameFlow: Flow<String> = context.dataStore.data
.catch { exception ->
// Obsługa błędów odczytu pliku
if (exception is IOException) {
emit(emptyPreferences())
} else {
throw exception
}
}
.map { preferences ->
// Pobieramy wartość lub domyślną ("")
preferences[UserPrefsKeys.USER_NAME] ?: ""
}
// ZAPIS: Funkcja zawieszająca (suspend)
suspend fun saveUserName(name: String) {
// Metoda edit jest transakcyjna (atomowa)
context.dataStore.edit { preferences ->
preferences[UserPrefsKeys.USER_NAME] = name
}
}
}Integracja z architekturą MVVM
Posiadając warstwę repozytorium (UserPreferencesRepository), która wystawia dane w postaci strumienia Flow, możemy zintegrować je z warstwą prezentacji. Musimy przekonwertować zimny strumień z DataStore na gorący stan UI, dostępny natychmiast dla widoku. Wykorzystamy do tego operator stateIn.
Rola ViewModelu w tym procesie jest dwojaka:
- Transformacja: Zamienia
Flow<String>z repozytorium naStateFlow<String>. - Zarządzanie cyklem życia: Dzięki
viewModelScope, nasłuchiwanie zmian w pliku preferencji odbywa się tylko wtedy, gdy ekran jest aktywny.
class UserViewModel(
private val repository: UserPreferencesRepository
) : ViewModel() {
// 1. Stan pola tekstowego (tymczasowy, edytowalny przez użytkownika)
var textFieldValue by mutableStateOf("")
private set
// 2. Stan zapisany na dysku (trwały, tylko do odczytu)
// Operator stateIn konwertuje Flow na StateFlow
val savedUserName: StateFlow<String> = repository.userNameFlow
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(stopTimeoutMillis = 5000),
initialValue = "" // Wartość początkowa zanim wczytamy plik
)
fun onTextFieldValueChanged(newValue: String) {
textFieldValue = newValue
}
// Wywołanie zapisu (operacja asynchroniczna)
fun onSaveClicked() {
viewModelScope.launch {
repository.saveUserName(textFieldValue)
// UWAGA: Nie musimy ręcznie aktualizować `savedUserName`!
// DataStore sam wykryje zmianę pliku i wyemituje nową wartość,
// która automatycznie trafi do naszego StateFlow.
}
}
}Przykład praktyczny: Ekran Ustawień
Ostatnim elementem jest warstwa widoku (UI). Dzięki zastosowaniu StateFlow, nasz ekran staje się w pełni reaktywny.
@Composable
fun UserSettingsScreen(viewModel: UserViewModel = viewModel()) {
val savedName by viewModel.savedUserName.collectAsStateWithLifecycle()
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = if (savedName.isBlank()) "Witaj nieznajomy!"
else "Witaj, $savedName!",
)
Spacer(Modifier.height(32.dp))
OutlinedTextField(
value = viewModel.textFieldValue,
onValueChange = viewModel::onTextFieldValueChanged,
label = { Text("Wpisz swoje imię") },
modifier = Modifier.fillMaxWidth()
)
Spacer(Modifier.height(16.dp))
Button(
onClick = { viewModel.onSaveClicked() },
modifier = Modifier.fillMaxWidth()
) {
Text("Zapisz trwale")
}
}
}Prześledźmy, co dzieje się po kliknięciu przycisku:
- UI: Użytkownik klika Zapisz. Wywołuje się
viewModel.onSaveClicked(). - ViewModel: Uruchamia korutynę i zleca
repository.saveUserName(). - DataStore: Zapisuje dane do pliku na dysku (wątek IO).
- DataStore (Callback): Wykrywa zmianę w pliku i emituje nową wartość do strumienia
userNameFlow. - ViewModel:
StateFlowodbiera nową wartość i aktualizuje swój stan. - UI: Komponent
UserSettingsScreenotrzymuje powiadomienie o zmianie stanu i przerysowuje się (Recomposition) z nowym imieniem.
Bezpieczeństwo wątkowe
Wróćmy na chwilę do największej bolączki SharedPreferences - blokowania wątku głównego. Jak pamiętamy, wywołanie prefs.getString() działo się dokładnie tam, gdzie zostało wywołane (często na UI Thread).
Biblioteka została zaprojektowana tak, aby można było bezpiecznie wywoływać jej metody z wątku głównego, a ciężka praca (operacje I/O, zapis na dysk) zostanie automatycznie przeniesiona na odpowiedni wątek w tle.
DataStore wewnętrznie wykorzystuje korutyny i dyspozytory. Niezależnie od tego, czy odczytujesz dane, czy je zapisujesz, biblioteka deleguje te zadania do puli wątków Dispatchers.IO, która jest zoptymalizowana pod kątem operacji dyskowych i sieciowych.
- Przy zapisie (
edit): Funkcja jest oznaczona jakosuspend. Gdy ją wywołujesz, DataStore zawiesza korutynę, przełącza się na wątek IO, dokonuje zapisu atomowego do pliku, a następnie wznawia korutynę na oryginalnym wątku. - Przy odczycie (
data): StrumieńFlowemituje wartości, które są odczytywane z dysku w tle.
W tym przypadku (podobnie jak w ROOM i Retrofit (kolejne rozdziały)), nie jest konieczne manualne przełączanie za pomocą withContext. W przypadku DataStore poniższa konstrukcja jest zbędna:
// Podejście Nieprawidłowe (Nadmiarowy kod)
suspend fun saveToken(token: String) {
// DataStore i tak przełączy się na IO, więc to wywołanie jest masłem maślanym
withContext(Dispatchers.IO) {
context.dataStore.edit { prefs ->
prefs[TOKEN_KEY] = token
}
}
}
// Podejście Prawidłowe (Main-Safe)
suspend fun saveToken(token: String) {
// Możemy to bezpiecznie wołać z ViewModelu (Main Thread)
context.dataStore.edit { prefs ->
prefs[TOKEN_KEY] = token
}
}Należy pamiętać, że o ile odczyt z dysku dzieje się na IO, o tyle transformacje danych (operatory .map na strumieniu Flow) wykonują się na tym wątku, na którym nastąpiła subskrypcja (kolekcjonowanie). Dla prostych typów (String, Boolean) nie ma to znaczenia, ale przy skomplikowanym przetwarzaniu warto pamiętać o operatorze flowOn, omawianym w Rozdziale 6.
Pełne Przykłady Implementacji
Poniżej znajdują się kompletne kody źródłowe omawianych zagadnień.
Przykład 1: SharedPreferences
Ten przykład pokazuje "stary styl". Mamy tu menedżera ustawień, który operuje na pliku XML. Zauważ, że aby zaktualizować UI po zmianie przełącznika, musimy ręcznie zmienić stan w Composable (isNotificationsEnabled = newCheckedState), ponieważ SharedPreferences nie powiadamia nas o zmianach automatycznie.
// --- 1. SettingsManager.kt ---
class SettingsManager(context: Context) {
// Tryb MODE_PRIVATE: tylko ta aplikacja ma dostęp do pliku
private val prefs = context.getSharedPreferences(
"app_settings",
Context.MODE_PRIVATE
)
companion object {
private const val NOTIFICATIONS_KEY = "notifications_enabled"
}
// ZAPIS (Asynchroniczny dzięki .apply())
fun saveNotificationsSetting(isEnabled: Boolean) {
prefs.edit {
putBoolean(NOTIFICATIONS_KEY, isEnabled)
apply()
}
}
// ODCZYT (Synchroniczny - uwaga na blokowanie UI przy dużych plikach!)
fun isNotificationEnabled(): Boolean {
return prefs.getBoolean(NOTIFICATIONS_KEY, false)
}
}
// --- 2. Screen.kt ---
@Composable
fun LegacySettingsScreen() {
val context = LocalContext.current
val settingsManager = remember { SettingsManager(context) }
// Stan lokalny UI
var isNotificationsEnabled by remember {
mutableStateOf(settingsManager.isNotificationEnabled())
}
Column(modifier = Modifier.padding(16.dp)) {
Text("Ustawienia (Legacy)")
Spacer(Modifier.height(16.dp))
Row(
modifier = Modifier.fillMaxWidth(),
horizontalArrangement = Arrangement.SpaceBetween,
verticalAlignment = Alignment.CenterVertically
) {
Text("Powiadomienia Push")
Switch(
checked = isNotificationsEnabled,
onCheckedChange = { newState ->
// 1. Aktualizujemy UI
isNotificationsEnabled = newState
// 2. Zapisujemy w tle
settingsManager.saveNotificationsSetting(newState)
}
)
}
}
}Przykład 2: DataStore (Architektura MVVM)
Struktura plików:
DataStoreConfig.kt- Singleton instancji DataStore.UserPreferencesRepository.kt- Logika odczytu (Flow) i zapisu (suspend).UserViewModel.kt- Konwersja Flow na StateFlow.UserScreen.kt- Reaktywny widok.
// --- 1. DataStoreConfig.kt ---
// Delegat tworzący Singleton. Nazwa pliku to "user_prefs.preferences_pb"
val Context.dataStore by preferencesDataStore(name = "user_prefs")
// --- 2. UserPreferencesRepository.kt ---
class UserPreferencesRepository(private val context: Context) {
private object Keys {
val USER_NAME = stringPreferencesKey("user_name")
}
// ODCZYT: Zwracamy Flow, który emituje dane przy każdej zmianie pliku
val userNameFlow: Flow<String> = context.dataStore.data
.catch { exception ->
if (exception is IOException) emit(emptyPreferences())
else throw exception
}
.map { preferences ->
preferences[Keys.USER_NAME] ?: "Anonim"
}
// ZAPIS: Funkcja zawieszająca (działa na Dispatchers.IO)
suspend fun saveUserName(name: String) {
context.dataStore.edit { preferences ->
preferences[Keys.USER_NAME] = name
}
}
}
// --- 3. UserViewModel.kt ---
class UserViewModel(
private val repository: UserPreferencesRepository
) : ViewModel() {
// Stan pola tekstowego
var inputName by mutableStateOf("")
private set
// Stan z dysku (to co jest zapisane)
// stateIn zamienia zimny Flow w gorący StateFlow dostępny dla UI
val savedName: StateFlow<String> = repository.userNameFlow
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = "Wczytywanie..."
)
fun onInputChange(newValue: String) {
inputName = newValue
}
fun saveName() {
viewModelScope.launch {
repository.saveUserName(inputName)
inputName = "" // Czyścimy pole po zapisie
}
}
}
// --- 4. UserScreen.kt ---
@Composable
fun UserScreen(viewModel: UserViewModel = viewModel()) {
// Obserwujemy StateFlow. Każda zmiana w pliku DataStore
// spowoduje automatyczną rekompozycję tego widoku.
val savedName by viewModel.savedName.collectAsStateWithLifecycle()
Column(
modifier = Modifier.fillMaxSize().padding(24.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text("Witaj, $savedName!")
Spacer(Modifier.height(32.dp))
OutlinedTextField(
value = viewModel.inputName,
onValueChange = viewModel::onInputChange,
label = { Text("Zmień swoje imię") },
modifier = Modifier.fillMaxWidth()
)
Spacer(Modifier.height(16.dp))
Button(
onClick = { viewModel.saveName() },
modifier = Modifier.fillMaxWidth()
) {
Text("Zapisz w DataStore")
}
}
}W poprzednim rozdziale nauczyliśmy się zapisywać proste ustawienia. Dla większej ilości danych, szczególnie dla bardziej skomplikowanej struktury użyjemy relacyjnej bazy danych. W Androidzie mamy dostępny Room.
Android posiada wbudowany silnik SQLite. Jest to relacyjna baza danych zamknięta w jednym pliku. Możemy z niej korzystać używając języka SQL. Room to biblioteka z pakietu Android Jetpack, która działa jako warstwa abstrakcji nad SQLite.
- Sprawdza poprawność zapytań SQL podczas kompilacji.
- Automatycznie mapuje wyniki zapytań na obiekty Kotlina (Data Classes).
- Zwraca strumienie
Flow, dzięki czemu UI odświeża się samo.
Zależności (Gradle)
Aby móc skorzystać z biblioteki i wszystkich adnotacji, musimy odpowiednia skonfigurować projekt:
W pliku build.gradle.kts(Project) dodajemy:
plugins {
id("androidx.room") version "2.8.0" apply false
id("com.google.devtools.ksp") version "2.0.21-1.0.27" apply false
}Do pliku build.gradle.kts(Module) dodajemy:
plugins {
id("androidx.room")
id("com.google.devtools.ksp")
}
android {
room {
schemaDirectory("$projectDir/schemas")
}
}
dependencies {
implementation("androidx.room:room-runtime:2.8.0")
ksp("androidx.room:room-compiler:2.8.0")
implementation("androidx.room:room-ktx:2.8.0")
implementation("androidx.lifecycle:lifecycle-viewmodel-compose:2.9.4")
implementation("androidx.lifecycle:lifecycle-runtime-compose:2.9.4")
}Architektura Room
Aby używać Room, musimy zdefiniować trzy główne komponenty. Działa tu analogia do magazynu:
- Entity (Encja): Klasa danych (`data class`), która definiuje strukturę tabeli (kolumny).
- DAO (Data Access Object): Interfejs, który definiujemetody dostęowe do bazy danych. To tu piszemy zapytania SQL.
- Database: Główny punkt dostępu do bazy, który spina Encje z DAO.
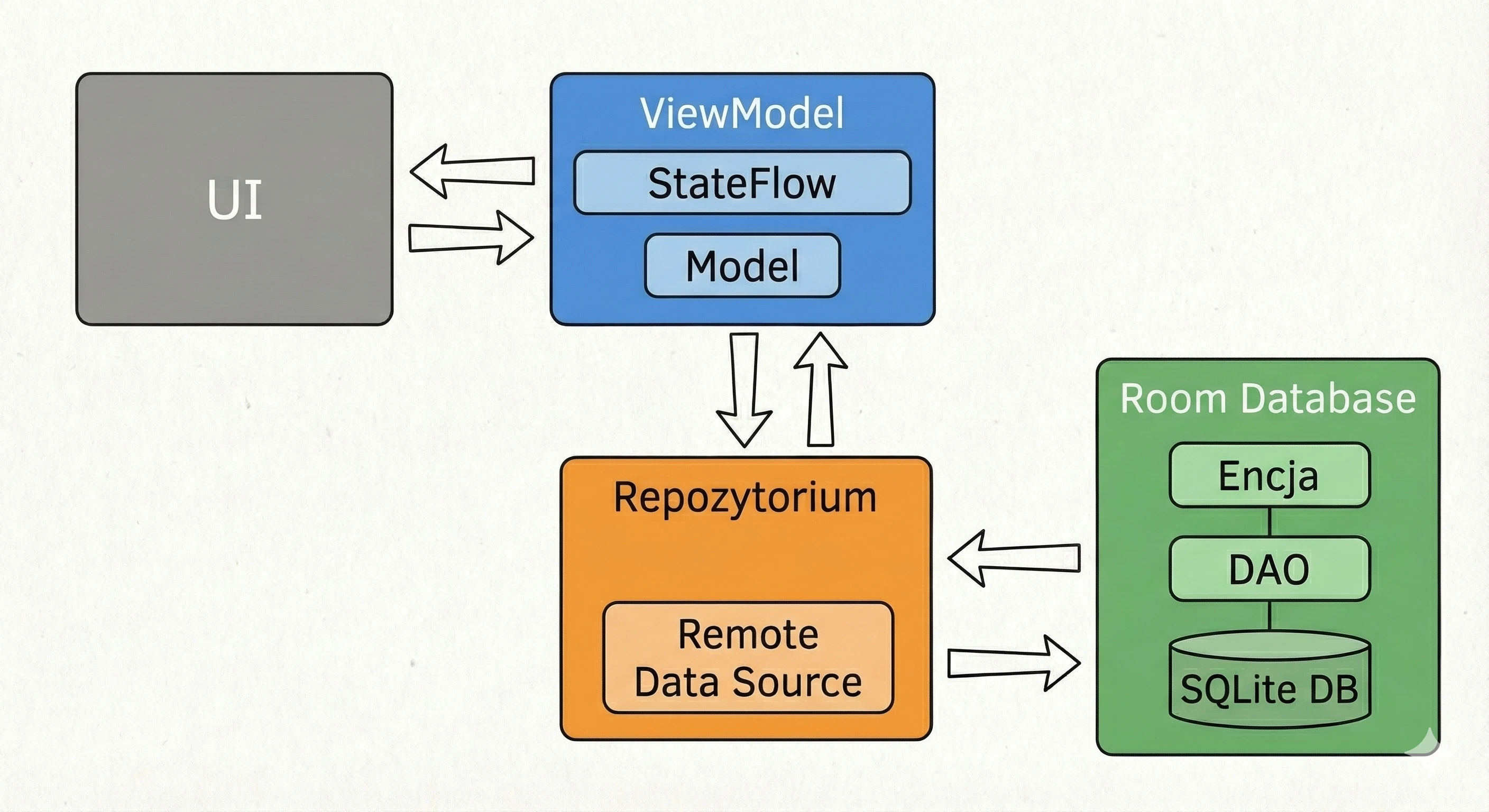
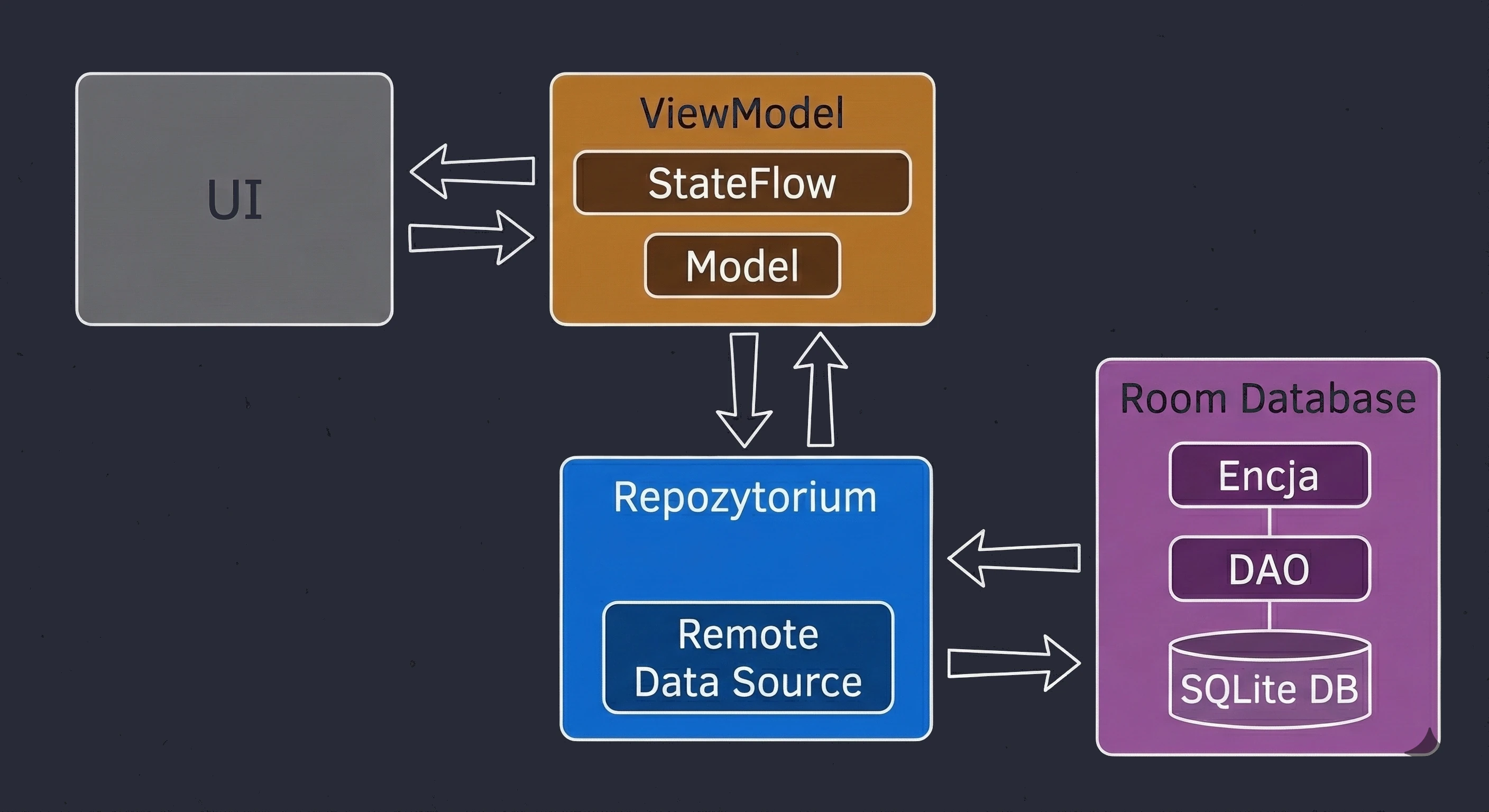
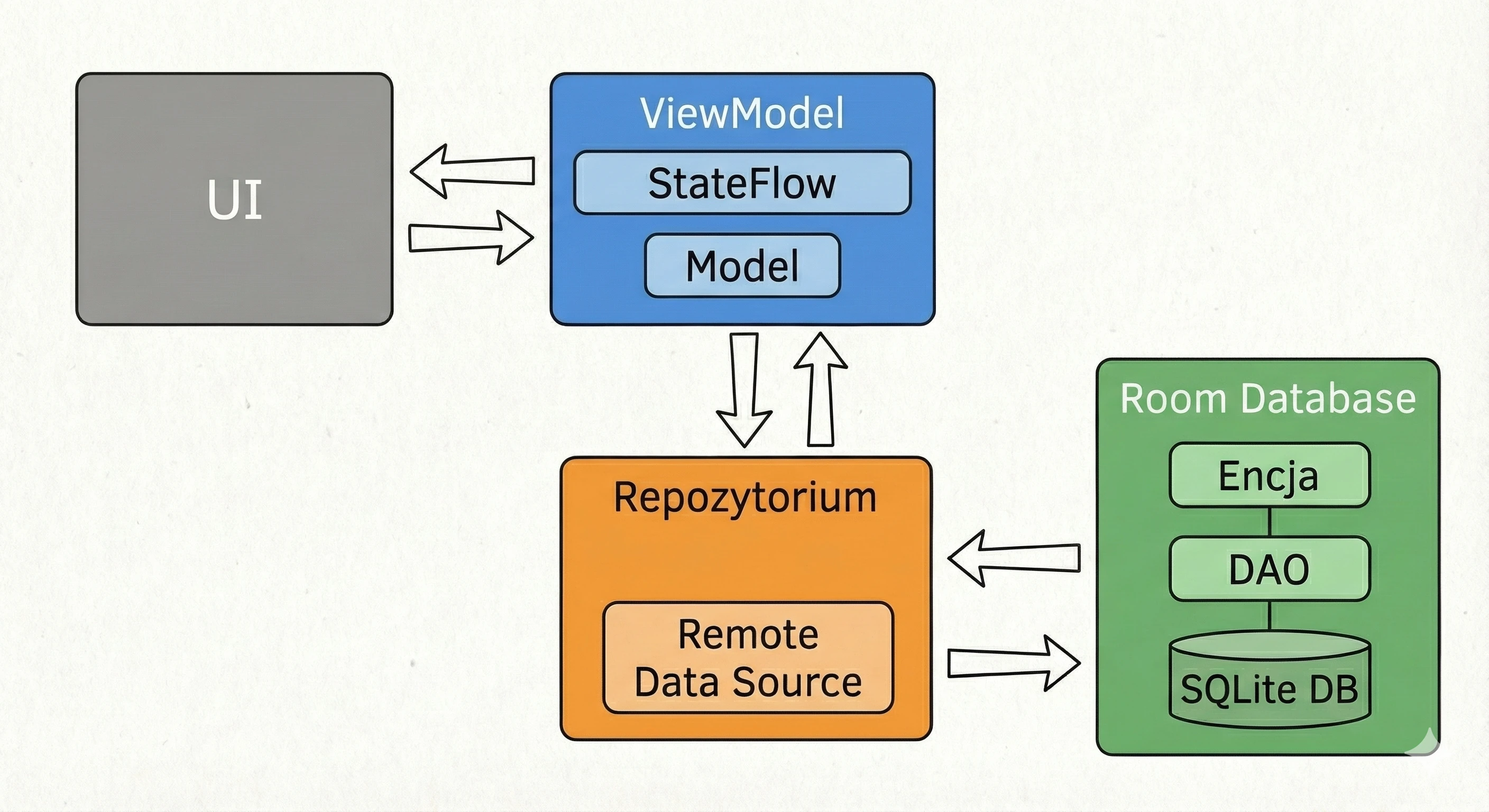
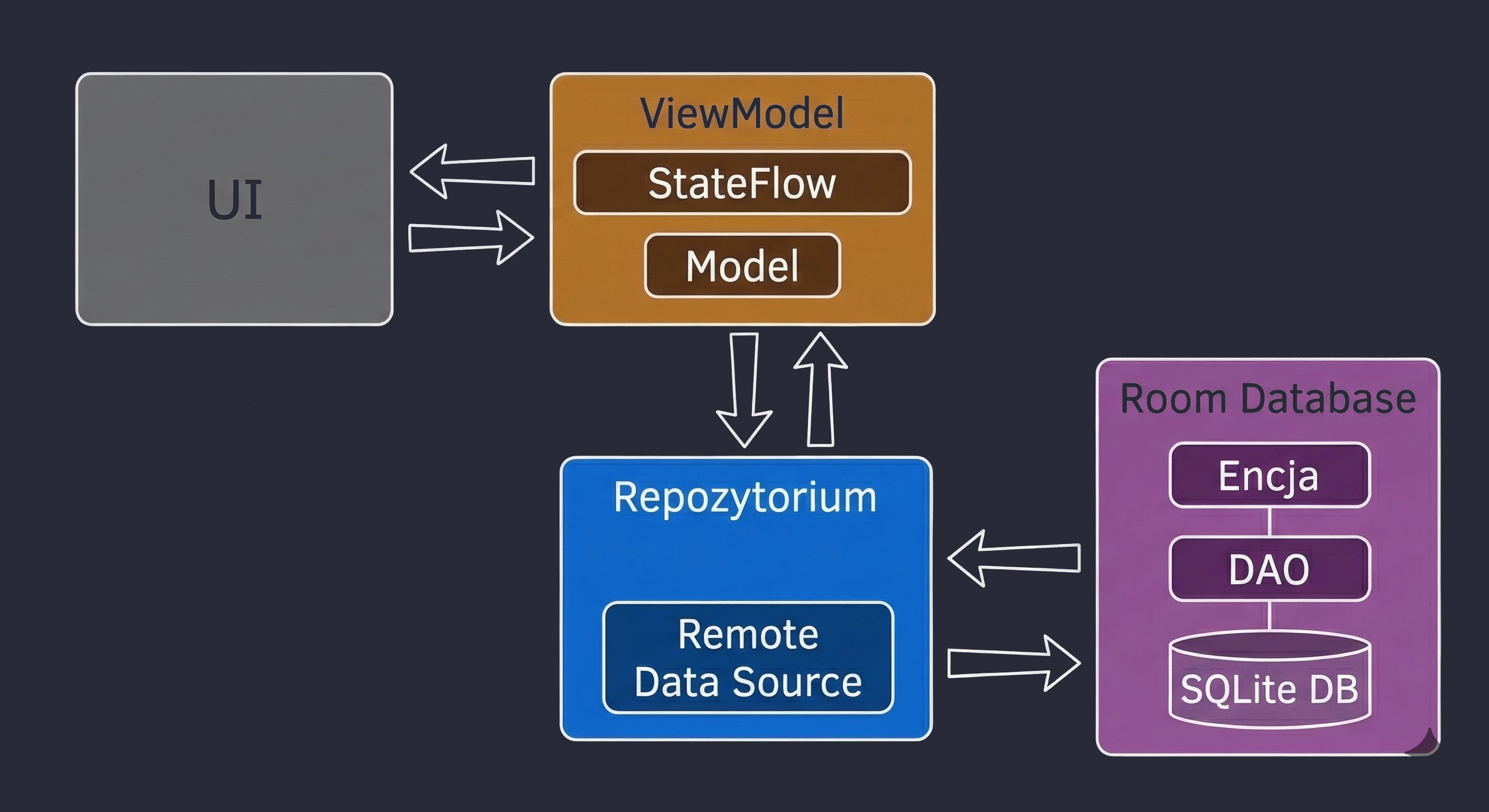
Entity (Definiowanie Tabeli)
Zacznijmy od stworzenia tabeli dla prostego zadania (Task). Używamy adnotacji, aby nauczyć Room, jak traktować naszą klasę.
@Entity(tableName = "tasks_table") // Nazwa tabeli w SQL
data class TaskEntity(
@PrimaryKey(autoGenerate = true)
val id: Long = 0, // Room sam nada kolejne ID
@ColumnInfo(name = "task_title")
val title: String,
val isCompleted: Boolean, // Room domyślnie nazwie
// kolumnę "isCompleted"
val createdAt: Long = System.currentTimeMillis()
)DAO (Operacje na danych)
Data Access Object (DAO) stanowi warstwę abstrakcji oddzielającą logikę biznesową aplikacji od niskopoziomowych operacji na bazie danych SQLite. W bibliotece Room, DAO musi być interfejsem (lub klasą abstrakcyjną), ponieważ właściwa implementacja metod (zawierająca kod SQL i zarządzanie kursorami) jest generowana automatycznie podczas kompilacji.
@Dao
interface TaskDao {
// Operacje jednorazowe (Zapis/Edycja/Usuwanie)
// Muszą być SUSPEND, bo te operacje mogą zająć
// dużo czasu.
// Room automatycznie wykona je na Dispatchers.IO (Main-Safe).
@Upsert
suspend fun upsertTask(task: TaskEntity)
@Delete
suspend fun deleteTask(task: TaskEntity)
@Update
suspend fun updateTask(task: TaskEntity)
// Operacje odczytu (Reaktywne)
// NIE są suspend! Zwracają Flow.
// Flow emituje nową listę za każdym razem,
// gdy cokolwiek zmieni się w tabeli.
@Query("SELECT * FROM tasks_table ORDER BY createdAt DESC")
fun getAllTasks(): Flow<List<TaskEntity>>
// Możemy też robić jednorazowe strzały po konkretną daną
@Query("SELECT * FROM tasks_table WHERE id = :id")
suspend fun getTaskById(id: Long): TaskEntity?
}Metody oznaczone adnotacjami @Upsert, @Delete oraz @Update odpowiadają za modyfikację stanu bazy danych.
- Modyfikator
suspend: Operacje zapisu na dysku (I/O) są z natury blokujące i mogą trwać od kilku do kilkudziesięciu milisekund. Oznaczenie ich jakosuspendwymusza na programiście wywołanie ich wewnątrz korutyny. - Main-Safety: Room gwarantuje bezpieczeństwo wątku głównego. Wygenerowana implementacja tych metod automatycznie przenosi wykonanie zapytania SQL na dedykowany dla bazy danych dyspozytor (zazwyczaj oparty na
Dispatchers.IO), niezależnie od tego, na jakim wątku została uruchomiona korutyna nadrzędna. - Strategia Konfliktów: W starszym kodzie często spotkamy
@Insert(onConflict = OnConflictStrategy.REPLACE), które mapuje się na SQLiteINSERT OR REPLACE. Taka operacja ma semantykę delete + insert, a nie klasycznej aktualizacji in place. Dlatego, gdy chcemy jawnej semantyki insert albo update, w Room warto preferować adnotację@Upsert.
Metoda getAllTasks() zwraca typ Flow<List<TaskEntity>>.
- Brak
suspend: Zauważmy, że ta metoda nie jest funkcją zawieszającą. Wynika to z faktu, że samo wywołanie metody nie wykonuje zapytania SQL. Tworzy ono jedynie i zwraca instancję strumienia (Flow). Dopiero zasubskrybowanie się do strumienia (operacjacollect) uruchamia zapytanie. - Invalidation Tracker: Room automatycznie monitoruje tabele w bazie danych. Gdy nastąpi jakakolwiek zmiana w tabeli
tasks_table(np. przezupsertTask), Room wykrywa to zdarzenie, automatycznie wykonuje zapytanieSELECTponownie i emituje zaktualizowaną listę do strumienia. Zapewnia to spójność widoku z danymi bez konieczności ręcznego odświeżania UI.
Metoda getTaskById jest przykładem klasycznego zapytania zwracającego pojedynczy wynik (Snapshot).
- W przeciwieństwie do zapytania zwracającego
Flow, tutaj musimy użyć słowa kluczowegosuspend, ponieważ zapytanie SQL wykonywane jest natychmiastowo w momencie wywołania funkcji, co wymaga zawieszenia wątku na czas operacji I/O. - Typ zwracany jest nullowalny (
TaskEntity?), co zmusza programistę do obsłużenia sytuacji, w której rekord o danym ID nie istnieje w bazie danych.
Database (Punkt wejścia)
Na koniec tworzymy abstrakcyjną klasę bazy danych.
@Database(entities = [TaskEntity::class], version = 1)
abstract class AppDatabase : RoomDatabase() {
abstract fun taskDao(): TaskDao
companion object {
@Volatile
private var INSTANCE: AppDatabase? = null
fun getDatabase(context: Context): AppDatabase {
// Wzorzec Double-Check Locking dla Singletona
return INSTANCE ?: synchronized(this) {
val instance = Room.databaseBuilder(
context.applicationContext,
AppDatabase::class.java,
"my_todo_database"
)
.fallbackToDestructiveMigration()
.build()
INSTANCE = instance
instance
}
}
}
}Powyższy kod realizuje wzorzec projektowy Singleton z wykorzystaniem mechanizmu Double-Check Locking, mający na celu zapewnienie bezpiecznego dostępu do zasobu w środowisku wielowątkowym przy minimalnym narzucie wydajnościowym.
Adnotacja @Database pełni rolę konfiguratora dla procesora adnotacji (KSP/KAPT).
entities: Definiuje schemat bazy danych. Room zweryfikuje, czy klasy te posiadają poprawne mapowanie na typy SQL.version: Liczba całkowita określająca wersję schematu. Zmiana struktury encji (np. dodanie pola) wymaga inkrementacji tej wartości i dostarczenia strategii migracji.- Klasa jest
abstract, ponieważ to biblioteka Room generuje jej konkretną implementację (suffix_Impl) w czasie kompilacji, wstrzykując kod odpowiedzialny za transakcje SQL.
Zmienna statyczna INSTANCE została oznaczona jako @Volatile. W Java Memory Model (JMM) ma to krytyczne znaczenie dla widoczności zmian w pamięci:
- Problem: Wątki mogą przechowywać wartości zmiennych w lokalnych rejestrach procesora (CPU Cache) zamiast w głównej pamięci RAM. Bez
@Volatile, wątek A mógłby zainicjalizować bazę, ale wątek B wciąż widziałbynullw swojej pamięci podręcznej. - Rozwiązanie:
@Volatilewymusza relację happens-before. Zapis do tej zmiennej jest natychmiast widoczny dla wszystkich innych wątków (flush to main memory), a odczyt zawsze pobiera wartość z pamięci głównej. Zapobiega to również tzw. Instruction Reordering (przeorganizowaniu instrukcji przez kompilator), co mogłoby doprowadzić do użycia nie w pełni zainicjalizowanego obiektu.
Funkcja getDatabase implementuje mechanizm leniwej inicjalizacji (Lazy Initialization) z optymalizacją wydajności:
- Pierwsze sprawdzenie (Bez blokady):
return INSTANCE ?: ...sprawdza, czy instancja już istnieje. Jeśli tak, zwraca ją natychmiast, unikając kosztownego wchodzenia w blok synchronizowany. - Sekcja Krytyczna (Synchronizacja):
synchronized(this)zapewnia, że tylko jeden wątek jednocześnie może wykonywać kod wewnątrz bloku. Chroni to przed sytuacją Race Condition, gdzie dwa wątki równocześnie stwierdziłyby brak instancji i utworzyłyby dwie niezależne kopie bazy danych. - Drugie sprawdzenie (Wewnątrz blokady): Wewnątrz bloku
synchronized(ukryte w logice operatora Elvis i przypisania) następuje ponowna weryfikacja. Jest to konieczne, gdyż między pierwszym sprawdzeniem a wejściem do sekcji krytycznej inny wątek mógł zdążyć utworzyć instancję.
Wywołanie context.applicationContext jest zabezpieczeniem przed wyciekami pamięci (Memory Leaks). Baza danych (jako Singleton) żyje przez cały czas działania procesu aplikacji. Gdybyśmy przekazali do niej Activity Context, Singleton trzymałby referencję do Activity, uniemożliwiając Garbage Collectorowi zwolnienie pamięci po zamknięciu ekranu. Kontekst aplikacji jest niezależny od cyklu życia widoków.
Metoda .fallbackToDestructiveMigration() definiuje zachowanie w przypadku niezgodności wersji schematu (parametr version) ze stanem faktycznym pliku na dysku, przy jednoczesnym braku zdefiniowanej ścieżki migracji (klasy Migration). W trybie tym Room usuwa plik bazy danych i tworzy go na nowo. Jest to dopuszczalne w fazie deweloperskiej (prototypowanie), ale w środowisku produkcyjnym prowadzi do trwałej utraty danych użytkownika i powinno zostać zastąpione implementacją metody .addMigrations().
Integracja z Architekturą MVVM
Posiadając zdefiniowaną bazę danych, nie powinniśmy korzystać z niej bezpośrednio w warstwie prezentacji (Activity/Composable). Zamiast tego zastosujemy wzorzec Repository.
Repozytorium pełni rolę mediatora. ViewModel nie musi wiedzieć, czy dane pochodzą z bazy SQLite, z sieci czy z pliku JSON. On chce tylko danych.
class TaskRepository(private val taskDao: TaskDao) {
// Strumień danych (Obserwowanie)
// Repozytorium po prostu przekazuje Flow z DAO dalej.
// Nie musimy tu używać 'suspend', bo samo pobranie referencji
// do strumienia jest natychmiastowe.
val allTasks: Flow<List<TaskEntity>> = taskDao.getAllTasks()
// Operacje edycyjne
// Tutaj musimy użyć 'suspend', aby nie zablokować wątku,
// z którego wołamy tę funkcję (zazwyczaj ViewModel).
suspend fun addTask(title: String) {
val newTask = TaskEntity(title = title, isCompleted = false)
taskDao.upsertTask(newTask)
}
suspend fun toggleTaskCompletion(task: TaskEntity) {
val updatedTask = task.copy(isCompleted = !task.isCompleted)
taskDao.updateTask(updatedTask)
}
suspend fun removeTask(task: TaskEntity) {
taskDao.deleteTask(task)
}
}To tutaj następuje konwersja strumienia bazodanowego na stan interfejsu użytkownika. Podobnie jak w przypadku DataStore (Rozdział 8), wykorzystamy operator stateIn.
class TaskViewModel(private val repository: TaskRepository) : ViewModel() {
// Konwersja Flow<List<TaskEntity>> -> StateFlow<List<TaskEntity>>
// Dzięki temu UI zawsze ma dostęp do "najświeższej" listy zadań.
val tasks: StateFlow<List<TaskEntity>> = repository.allTasks
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = emptyList()
)
// Funkcje wywoływane przez UI (np. po kliknięciu przycisku)
fun onAddTaskClick(title: String) {
if (title.isBlank()) return
viewModelScope.launch {
// Room automatycznie przeniesie to na Dispatchers.IO
repository.addTask(title)
// Nie musimy ręcznie odświeżać listy!
// Room wykryje zmianę, zaktualizuje Flow,
// a StateFlow wyśle nowe dane do UI.
}
}
fun onTaskCheckedChange(task: TaskEntity) {
viewModelScope.launch {
repository.toggleTaskCompletion(task)
}
}
fun onTaskDelete(task: TaskEntity) {
viewModelScope.launch {
repository.removeTask(task)
}
}
}Przykład Praktyczny: Aplikacja ToDo
Zepnijmy wszystkie omówione elementy w działającą aplikację. Naszym celem jest stworzenie ekranu, na którym użytkownik może dodawać zadania i odznaczać je jako wykonane. Dzięki reaktywności Room, lista będzie aktualizować się automatycznie.
Aby zachować poprawność architektoniczną, instancja bazy danych i repozytorium powinna żyć tak długo, jak aplikacja. Najlepszym miejscem na ich inicjalizację jest klasa dziedzicząca po Application.
// 1. Rejestrujemy tę klasę w AndroidManifest.xml w atrybucie android:name
class TodoApplication : Application() {
// Inicjalizacja leniwa (lazy) - baza powstanie dopiero przy pierwszym użyciu,
// a nie przy starcie aplikacji (szybszy czas uruchamiania).
val database by lazy { AppDatabase.getDatabase(this) }
val repository by lazy { TaskRepository(database.taskDao()) }
}<manifest xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
android:name=".TodoApplication"
android:allowBackup="true"
android:dataExtractionRules="@xml/data_extraction_rules"
android:fullBackupContent="@xml/backup_rules"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:theme="@style/Theme.TodoApp">
<activity
android:name=".MainActivity"
android:exported="true"
android:theme="@style/Theme.TodoApp">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>Ponieważ nasz TaskViewModel przyjmuje parametr w konstruktorze (repository), system Android nie potrafi go domyślnie utworzyć. Musimy dostarczyć fabrykę.
class TaskViewModelFactory(private val repository: TaskRepository) : ViewModelProvider.Factory {
override fun <T : ViewModel> create(modelClass: Class<T>): T {
if (modelClass.isAssignableFrom(TaskViewModel::class.java)) {
@Suppress("UNCHECKED_CAST")
return TaskViewModel(repository) as T
}
throw IllegalArgumentException("Unknown ViewModel class")
}
}Poniżej kod ekranu w Jetpack Compose. Zwróć uwagę na brak logiki odświeżania listy. UI po prostu reaguje na to, co przychodzi ze StateFlow.
@Composable
fun TaskScreen(viewModel: TaskViewModel) {
// 1. Obserwowanie stanu (bezpieczne dla cyklu życia)
val tasks by viewModel.tasks.collectAsStateWithLifecycle()
// Stan lokalny dla pola tekstowego
var newTaskTitle by remember { mutableStateOf("") }
Column(modifier = Modifier.fillMaxSize().padding(16.dp)) {
// Sekcja dodawania
Row(verticalAlignment = Alignment.CenterVertically) {
OutlinedTextField(
value = newTaskTitle,
onValueChange = { newTaskTitle = it },
label = { Text("Nowe zadanie") },
modifier = Modifier.weight(1f)
)
Spacer(Modifier.width(8.dp))
Button(onClick = {
viewModel.onAddTaskClick(newTaskTitle)
newTaskTitle = "" // Wyczyść pole po dodaniu
}) {
Text("Dodaj")
}
}
Spacer(Modifier.height(16.dp))
// Sekcja listy
if (tasks.isEmpty()) {
Text(
text = "Brak zadań. Dodaj coś!",
modifier = Modifier
.align(Alignment.CenterHorizontally)
.padding(top = 32.dp),
)
} else {
LazyColumn {
items(tasks, key = { it.id }) { task ->
TaskItem(
task = task,
onCheckedChange = { viewModel.onTaskCheckedChange(task) },
onDeleteClick = { viewModel.onTaskDelete(task) }
)
}
}
}
}
}
@Composable
fun TaskItem(
task: TaskEntity,
onCheckedChange: () -> Unit,
onDeleteClick: () -> Unit
) {
Card(
modifier = Modifier.fillMaxWidth().padding(vertical = 4.dp),
elevation = CardDefaults.cardElevation(2.dp)
) {
Row(
modifier = Modifier.padding(16.dp),
verticalAlignment = Alignment.CenterVertically
) {
Checkbox(
checked = task.isCompleted,
onCheckedChange = { onCheckedChange() }
)
Text(
text = task.title,
modifier = Modifier.weight(1f).padding(start = 8.dp),
)
IconButton(onClick = onDeleteClick) {
Icon(Icons.Default.Delete, contentDescription = "Usuń")
}
}
}
}Ostatnim elementem jest powiązanie wszystkiego w MainActivity. Pobieramy repozytorium z klasy Application i przekazujemy do fabryki.
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Pobieramy gotowe repozytorium (Singleton)
val appContainer = application as TodoApplication
val repository = appContainer.repository
setContent {
AppTheme {
// Tworzymy ViewModel używając fabryki
val viewModel: TaskViewModel = viewModel(
factory = TaskViewModelFactory(repository)
)
TaskScreen(viewModel = viewModel)
}
}
}
}W poprzednim rozdziale nauczyliśmy się przechowywać dane lokalnie na urządzeniu. Jest to podejście typu Offline-First. Jednak współczesne aplikacje mobilne rzadko działają w izolacji. Aby pobrać prognozę pogody, wyświetlić listę najnowszych wiadomości czy zsynchronizować zadania między urządzeniami, musimy skomunikować się z zewnętrznym serwerem.
Komunikacja sieciowa w aplikacjach mobilnych opiera się zazwyczaj na architekturze REST (Representational State Transfer).
- Klient (Twoja Aplikacja): Wysyła żądanie HTTP (Request) pod określony adres URL.
- Serwer (API): Przetwarza żądanie i odsyła odpowiedź (Response).
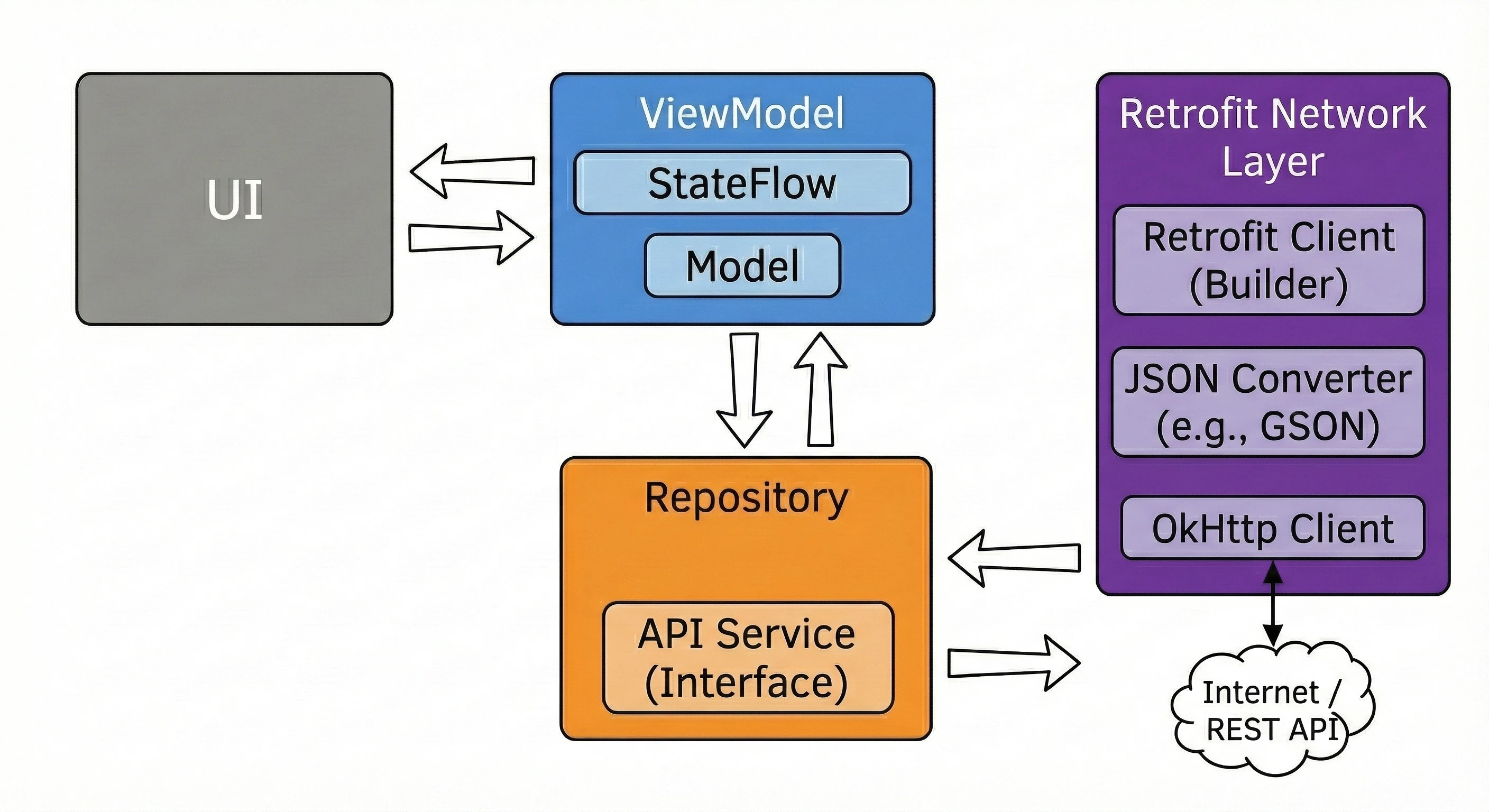
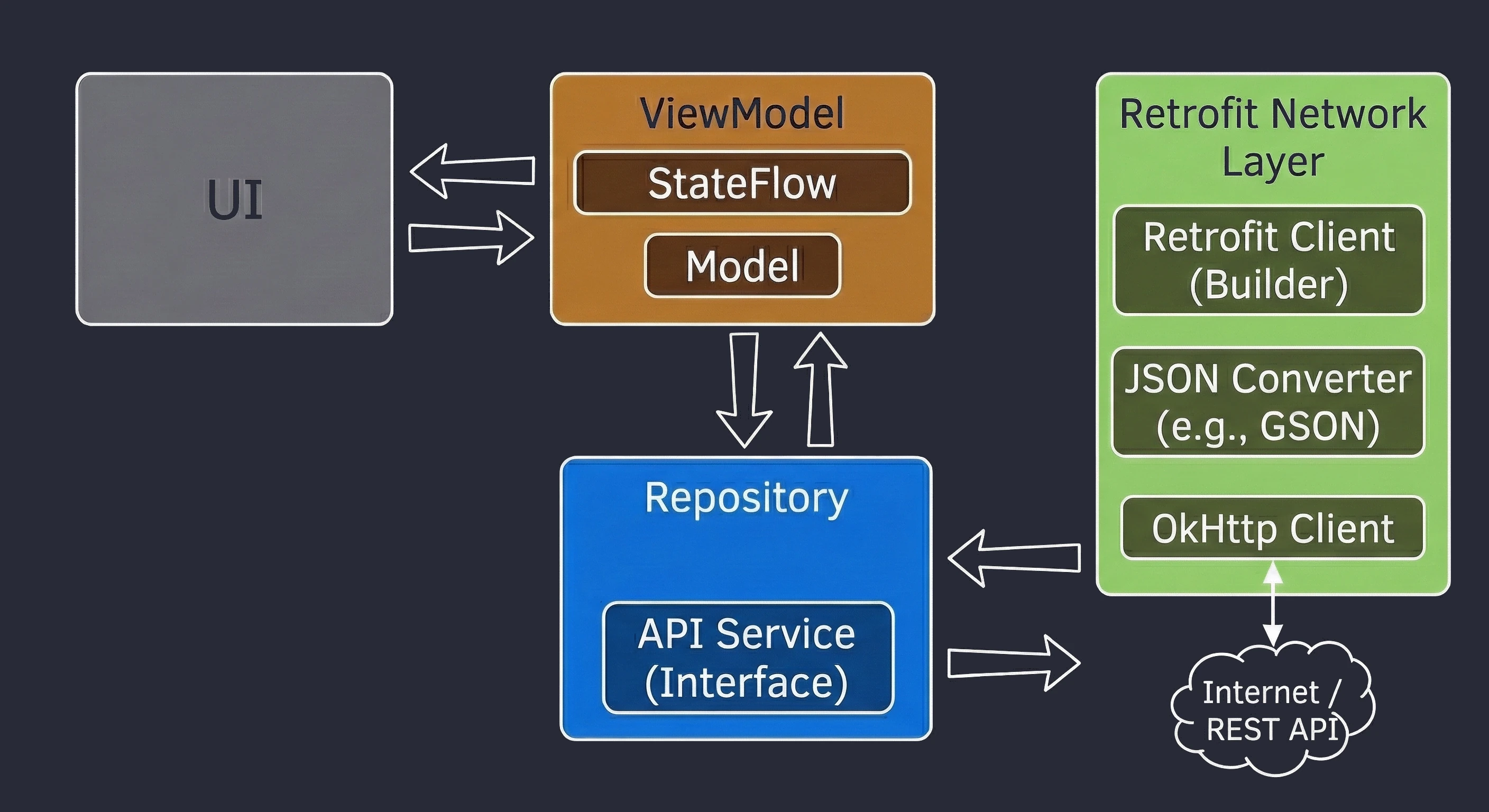
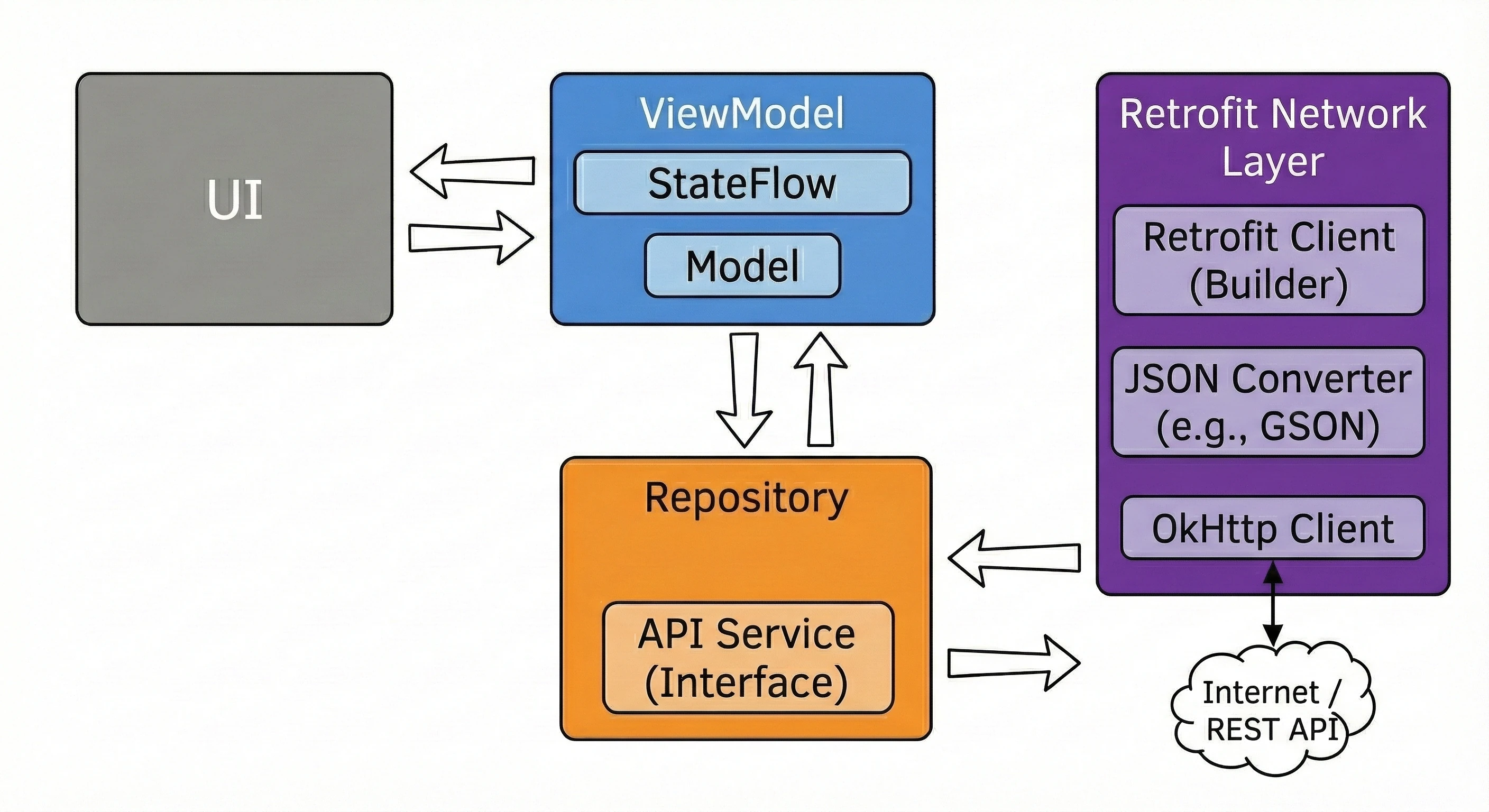
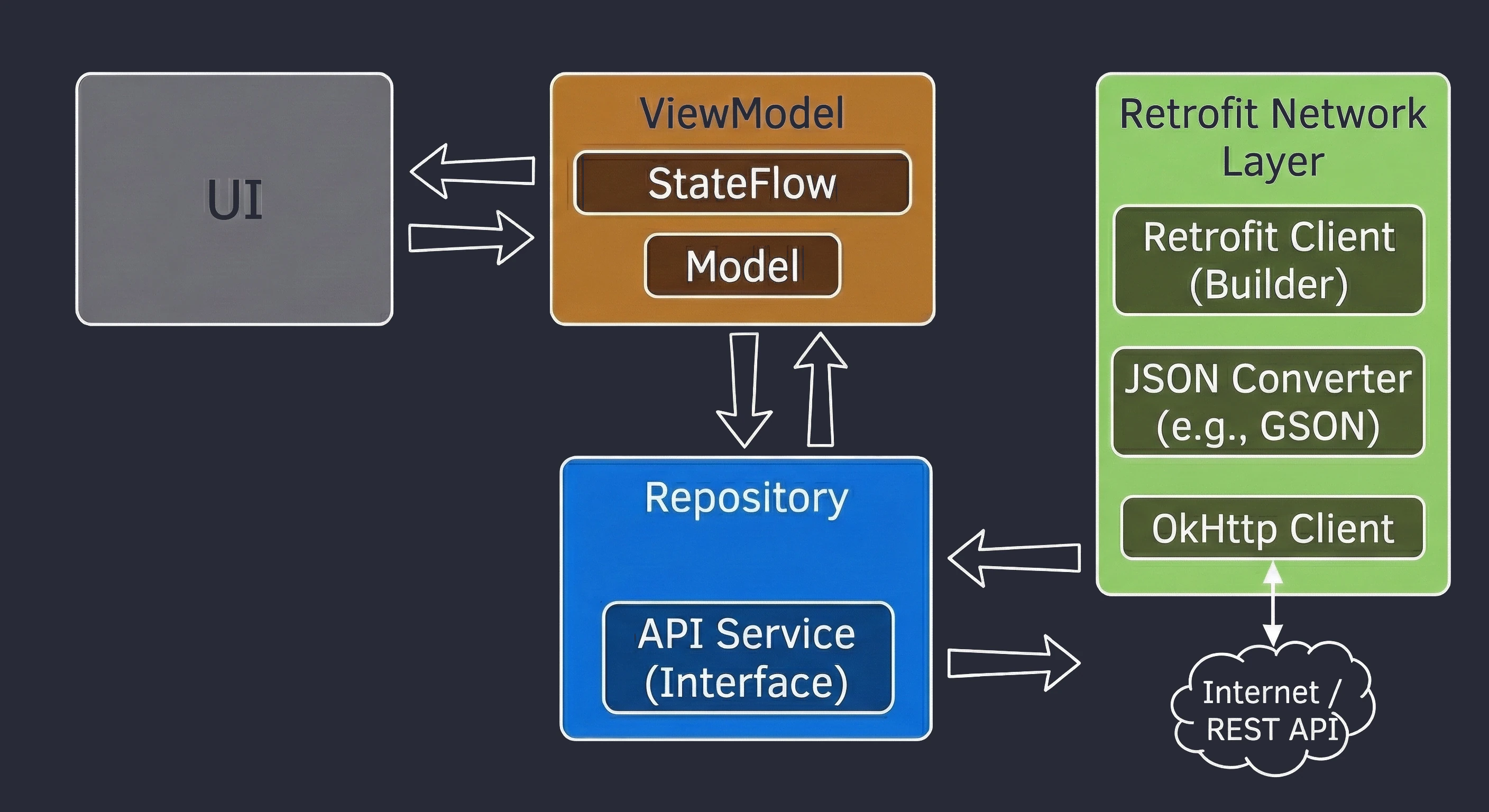
Operacja sieciowa jest zjawiskiem wysoce nieprzewidywalnym. Czas odpowiedzi serwera (Latency) zależy od jakości zasięgu (LTE/5G/WiFi), obciążenia łącza czy odległości geograficznej od serwera. Może to trwać od 50 ms do nawet kilku sekund. Ze względu na tę nieprzewidywalność, system Android narzuca rygorystyczne ograniczenie: Wykonywanie jakichkolwiek operacji sieciowych na Wątku Głównym (UI Thread) jest niewskazane. Próba wykonania kodu sieciowego wewnątrz MainActivity (bez użycia korutyn lub wątków tła) zakończy się natychmiastowym wyrzuceniem wyjątku NetworkOnMainThreadException.
Uprawnienia aplikacji
Domyślnie aplikacja na Androida nie ma prawa łączyć się z Internetem. Aby to umożliwić, musimy zadeklarować odpowiednie uprawnienie w pliku manifestu. Jest to uprawnienie typu Normal, co oznacza, że jest przyznawane automatycznie przy instalacji i nie wymaga odrębnej zgody użytkownika w czasie działania (Runtime Permission).
<manifest xmlns:android="http://schemas.android.com/apk/res/android">
<uses-permission android:name="android.permission.INTERNET" />
<application ...>
...
</application>
</manifest>Biblioteka Retrofit 2
W początkach systemu Android do obsługi sieci używano klasy HttpURLConnection. Wymagało to ręcznego otwierania strumieni, buforowania danych, obsługi kodowania znaków i ręcznego parsowania tekstu zwracanego formatu (np. JSON) na obiekty Javy.
Firma Square stworzyła bibliotekę Retrofit, która ułatwiła ten proces. Retrofit to tzw. Type-safe HTTP client, który pozwala programiście zdefiniować API jako prosty interfejs w Kotlinie. Zamiast pisać kod implementujący połączenie, my tylko deklarujemy, jak wygląda zapytanie (metoda HTTP, ścieżka, parametry). Retrofit automatycznie generuje kod wykonawczy.
Główne zalety:
- Abstrakcja: Ukrywa niskopoziomowe szczegóły protokołu HTTP.
- Automatyczna konwersja (Serializacja/Deserializacja): Współpracuje z bibliotekami takimi jak GSON, Moshi czy Scalars, automatycznie zamieniając odebraną odpowiedź na obiekty
data class. - Integracja z Kotlin Coroutines: Retrofit natywnie wspiera funkcje zawieszające (
suspend).
Dzięki wsparciu dla korutyn, zapytanie sieciowe w kodzie wygląda jak zwykłe wywołanie synchroniczne, ale zachowuje pełne bezpieczeństwo wątkowe (Main-Safety).
// Definicja interfejsu (Retrofit)
interface NewsApi {
@GET("articles")
suspend fun getArticles(): List<Article>
}
// Użycie w ViewModelu
viewModelScope.launch {
try {
// To wywołanie:
// 1. ZAWIESI korutynę (zwolni wątek UI).
// 2. Wykona zapytanie sieciowe w tle.
// 3. WZNOWI korutynę na wątku UI, gdy nadejdą dane.
val articles = api.getArticles()
// Tutaj mamy już gotową listę obiektów, możemy zaktualizować UI
uiState = articles
} catch (e: Exception) {
// Obsługa błędów (np. brak internetu)
}
}W powyższym przykładzie nie musimy używać withContext(Dispatchers.IO). Przełączanie odbywa się, podobnie jak w Room i DataStore, automatycznie.
Metody protokołu HTTP (Semantyka)
W architekturze REST każda operacja na danych (CRUD) jest ściśle powiązana z odpowiednią metodą protokołu HTTP. Wybór metody informuje serwer o intencjach klienta.
Najczęściej używane metody to:
- GET: Służy wyłącznie do pobierania danych. Jest operacją bezpieczną i zazwyczaj nie powinna modyfikować stanu serwera (np. pobierz listę artykułów, pobierz szczegóły użytkownika).
- POST: Służy do wysyłania nowych danych na serwer w celu utworzenia zasobu (np. dodaj nowy komentarz, zarejestruj użytkownika). Dane przesyłane są w ciele żądania (Body).
- PUT: Służy do pełnej aktualizacji istniejącego zasobu. Klient wysyła kompletną nową wersję obiektu, która zastępuje starą.
- PATCH: Służy do częściowej modyfikacji zasobu. Wysyłamy tylko te pola, które mają ulec zmianie (np. zmiana samego hasła, bez przesyłania reszty profilu).
- DELETE: Jak nazwa wskazuje, usuwa wskazany zasób z serwera.
| Operacja CRUD | Metoda HTTP | Adnotacja Retrofit |
|---|---|---|
| Create (Utwórz) | POST | @POST |
| Read (Odczytaj) | GET | @GET |
| Update (Aktualizuj) | PUT / PATCH | @PUT / @PATCH |
| Delete (Usuń) | DELETE | @DELETE |
Modelowanie Danych (Data Transfer Objects)
Zanim zaczniemy pobierać dane, musimy przygotować dla nich pojemniki. W inżynierii oprogramowania obiekty służące wyłącznie do przesyłania danych między podsystemami (np. Serwer -> Aplikacja) nazywamy DTO (Data Transfer Objects).
Serwery REST API najczęściej zwracają dane w formacie JSON (JavaScript Object Notation). Naszym zadaniem jest stworzenie klas w Kotlinie (data class), które odwzorowują strukturę tego JSON-a (Dodajmy tutaj że ten proces można zautomatyzować przez instalację odpowiednich pluginów).
Standardy nazewnictwa w JSON i Kotlinie często się różnią:
- JSON: Często używa notacji
snake_case(np.first_name,created_at). - Kotlin: Często stosujemy notację
camelCase(np.firstName,createdAt).
Aby rozwiązać ten konflikt bez łamania konwencji języka, używamy adnotacji @SerializedName (z biblioteki GSON). Działa ona jak mapa, mówiąca konwerterowi: "Pole 'user_avatar_url' z JSON-a przypisz do zmiennej 'avatarUrl'".
Załóżmy, że serwer zwraca następujący obiekt artykułu:
{
"id": 90210,
"title": "Nowy Android 15 wydany!",
"published_at": "2024-05-12T10:00:00Z",
"author": {
"name": "Jan Kowalski",
"is_admin": true
}
}Odpowiadające mu klasy w Kotlinie wyglądają następująco:
data class ArticleDto(
// Nazwa identyczna jak w JSON -> adnotacja niepotrzebna
val id: Long,
val title: String,
// Mapowanie snake_case -> camelCase
@SerializedName("published_at")
val publishedAt: String,
// Obiekty zagnieżdżone
val author: AuthorDto
)
data class AuthorDto(
val name: String,
@SerializedName("is_admin")
val isAdmin: Boolean
)Definiowanie Interfejsu API (Service)
Sercem biblioteki Retrofit jest interfejs. To tutaj deklarujemy, jakie operacje nasza aplikacja może wykonać na serwerze. Nie piszemy ciała metod - robimy to wyłącznie za pomocą adnotacji i typów zwracanych. Retrofit wygeneruje kod wykonawczy w czasie działania aplikacji.
Najprostszy przypadek to pobranie zasobu ze stałego adresu URL.
interface NewsApiService {
// Żądanie zostanie wysłane na adres: BASE_URL + "articles"
// Funkcja MUSI być suspend, aby współpracować z korutynami.
@GET("articles")
suspend fun getArticles(): List<ArticleDto>
}Rzadko zdarza się, że pobieramy zawsze to samo. Często chcemy pobrać konkretny artykuł lub przefiltrować listę.
Parametr Path (@Path): Używamy, gdy zmienna jest częścią ścieżki URL.
// Zapytanie o konkretny artykuł, np. GET articles/123
@GET("articles/{id}")
suspend fun getArticleDetail(
@Path("id") articleId: Long
): ArticleDtoParametr Query (@Query): Używamy do filtrowania, sortowania lub stronicowania (to, co występuje po znaku ?).
// Zapytanie: GET articles?category=tech&sort=desc
@GET("articles")
suspend fun getArticles(
@Query("category") category: String,
@Query("sort") sortBy: String = "desc"
): List<ArticleDto>Gdy chcemy wysłać obiekt do serwera (np. utworzyć nowy komentarz), używamy metody POST oraz adnotacji @Body. Retrofit automatycznie zserializuje obiekt do formatu JSON przed wysłaniem.
data class CommentRequest(
val articleId: Long,
val content: String
)
interface NewsApiService {
@POST("comments")
suspend fun postComment(@Body request: CommentRequest): Response<Unit>
}Często API wymaga autoryzacji (np. klucza API). Możemy dodać nagłówek statycznie lub dynamicznie.
// 1. Statyczny nagłówek dla metody
@Headers("User-Agent: MyAndroidApp/1.0")
@GET("articles")
suspend fun getNews(): List<ArticleDto>
// 2. Dynamiczny nagłówek (np. token sesji)
@GET("profile")
suspend fun getProfile(
@Header("Authorization") token: String
): UserDtoKonfiguracja Klienta (Retrofit Builder)
Mając zdefiniowany model danych (DTO) oraz interfejs API, musimy utworzyć instancję biblioteki Retrofit. Proces ten przypomina konfigurację bazy danych Room - również tutaj zastosujemy wzorzec Singleton, aby nie tworzyć kosztownych połączeń sieciowych wielokrotnie.
Zależności (Gradle)
Najpierw upewnijmy się, że w pliku build.gradle (Module: app) znajdują się wymagane biblioteki. Retrofit jest modułowy - sam w sobie obsługuje tylko połączenia HTTP. Do parsowania JSON-a potrzebujemy dodatkowego konwertera.
dependencies {
// Silnik Retrofit
implementation("com.squareup.retrofit2:retrofit:2.9.0")
// Konwerter JSON -> Kotlin Object (GSON)
implementation("com.squareup.retrofit2:converter-gson:2.9.0")
// Opcjonalnie: OkHttp do logowania zapytań w konsoli (Debugging)
implementation("com.squareup.okhttp3:logging-interceptor:4.11.0")
}Implementacja Singletona
Tworzymy obiekt, który będzie zarządzał konfiguracją. Kluczowe elementy to:
- Base URL: Adres główny API. Uwaga: Musi zawsze kończyć się znakiem ukośnika
/. - ConverterFactory: Klasa odpowiedzialna za serializację/deserializację (tutaj GSON).
- OkHttpClient: Klient HTTP, w którym możemy skonfigurować np. timeouty (czas oczekiwania na serwer).
object RetrofitInstance {
private const val BASE_URL = "https://newsapi.org/v2/"
// Konfiguracja klienta HTTP (opcjonalne logowanie)
private val client = OkHttpClient.Builder()
.addInterceptor { chain ->
val request = chain.request().newBuilder()
// Możemy tu dodać globalny nagłówek, np. klucz API
.addHeader("X-Api-Key", "TWOJ_KLUCZ_API")
.build()
chain.proceed(request)
}
.build()
// Leniwa inicjalizacja Retrofita
val api: NewsApiService by lazy {
Retrofit.Builder()
.baseUrl(BASE_URL)
.client(client)
.addConverterFactory(GsonConverterFactory.create())
.build()
.create(NewsApiService::class.java)
}
}Obsługa Błędów i Stany UI
W przeciwieństwie do lokalnej bazy danych, zapytanie sieciowe może zakończyć się niepowodzeniem na wiele sposobów (brak zasięgu, błąd 404, błąd 500). Aplikacja musi być na to gotowa.
Zamiast trzymać w ViewModelu osobne zmienne isLoading, errorText, data, eleganckim rozwiązaniem jest użycie Sealed Interface. Dzięki temu widok zawsze znajduje się w jednym, ściśle określonym stanie.
sealed interface NewsUiState {
// 1. Stan początkowy / Ładowanie
data object Loading : NewsUiState
// 2. Sukces - mamy dane do wyświetlenia
data class Success(val articles: List<ArticleDto>) : NewsUiState
// 3. Błąd - coś poszło nie tak
data class Error(val message: String) : NewsUiState
}class NewsViewModel : ViewModel() {
// Stan wewnętrzny (edytowalny)
private val _uiState = MutableStateFlow<NewsUiState>(NewsUiState.Loading)
// Stan publiczny (tylko do odczytu)
val uiState = _uiState.asStateFlow()
init {
fetchNews()
}
fun fetchNews() {
viewModelScope.launch {
// Ustawiamy stan na ładowanie
_uiState.update { NewsUiState.Loading }
try {
// Wywołanie sieciowe (Retrofit + Suspend)
val response = RetrofitInstance.api.getTopHeadlines()
// Sukces: Aktualizujemy stan danymi
_uiState.update {
NewsUiState.Success(response.articles)
}
} catch (e: IOException) {
// Błąd sieci (brak internetu, timeout)
_uiState.update {
NewsUiState.Error("Brak połączenia z internetem")
}
} catch (e: HttpException) {
// Błąd serwera (4xx, 5xx)
_uiState.update {
NewsUiState.Error("Błąd serwera: ${e.code()}")
}
} catch (e: Exception) {
// Inne błędy
_uiState.update {
NewsUiState.Error("Nieznany błąd: ${e.message}")
}
}
}
}
}Przykład Praktyczny: Aplikacja News Reader
Zepnijmy wszystko w całość. Stworzymy ekran, który reaguje na zmiany stanu: wyświetla kręciołek podczas ładowania, listę po pobraniu danych lub komunikat błędu w razie awarii.
Model i API
Zdefiniujmy strukturę danych i endpoint (jak w poprzednich punktach).
// DTO (Data Transfer Object)
data class NewsResponse(val articles: List<ArticleDto>)
data class ArticleDto(val title: String, val description: String?)
// Interfejs Retrofit
interface NewsApiService {
@GET("top-headlines?country=us")
suspend fun getTopHeadlines(): NewsResponse
}Warstwa Repozytorium
Repozytorium ukrywa źródło danych. Jeśli w przyszłości dodamy cache w bazie Room, zmienimy kod tylko tutaj, a ViewModel pozostanie bez zmian.
class NewsRepository(private val apiService: NewsApiService) {
// Funkcja zawieszająca, przekazująca żądanie do Retrofita
suspend fun getNews(): List<ArticleDto> {
return apiService.getTopHeadlines().articles
}
}ViewModel z obsługą StateFlow
ViewModel przyjmuje repozytorium w konstruktorze. Używamy StateFlow do zarządzania stanem.
class NewsViewModel(private val repository: NewsRepository) : ViewModel() {
// Backing property
private val _uiState = MutableStateFlow<NewsUiState>(NewsUiState.Loading)
val uiState = _uiState.asStateFlow()
init {
fetchNews()
}
fun fetchNews() {
viewModelScope.launch {
_uiState.update { NewsUiState.Loading }
try {
// Pobieramy dane z REPOZYTORIUM, nie bezpośrednio z API
val articles = repository.getNews()
_uiState.update { NewsUiState.Success(articles) }
} catch (e: IOException) {
_uiState.update { NewsUiState.Error("Brak internetu") }
} catch (e: HttpException) {
_uiState.update { NewsUiState.Error("Błąd serwera: ${e.code()}") }
} catch (e: Exception) {
_uiState.update { NewsUiState.Error("Nieznany błąd") }
}
}
}
}
// Fabryka potrzebna do wstrzyknięcia Repozytorium do ViewModelu
class NewsViewModelFactory(private val repository: NewsRepository) : ViewModelProvider.Factory {
override fun <T : ViewModel> create(modelClass: Class<T>): T {
if (modelClass.isAssignableFrom(NewsViewModel::class.java)) {
@Suppress("UNCHECKED_CAST")
return NewsViewModel(repository) as T
}
throw IllegalArgumentException("Unknown ViewModel class")
}
}Widok (Compose)
Warstwa UI obserwuje stan i reaguje na niego.
@Composable
fun NewsScreen(viewModel: NewsViewModel) { // ViewModel przekazywany jako parametr
val state by viewModel.uiState.collectAsStateWithLifecycle()
Scaffold(
topBar = { TopAppBar(title = { Text("Wiadomości") }) }
) { padding ->
Box(modifier = Modifier.padding(padding).fillMaxSize(),
contentAlignment = Alignment.Center) {
when (val currentState = state) {
is NewsUiState.Loading -> CircularProgressIndicator()
is NewsUiState.Error -> {
Column(horizontalAlignment = Alignment.CenterHorizontally) {
Text(text = currentState.message)
Button(onClick = { viewModel.fetchNews() }) { Text("Ponów") }
}
}
is NewsUiState.Success -> {
LazyColumn(modifier = Modifier.fillMaxSize()) {
items(currentState.articles) { article ->
ArticleItem(article)
}
}
}
}
}
}
}Punkt wejścia (MainActivity)
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 1. Utworzenie instancji API (z Singletona)
val apiService = RetrofitInstance.api
// 2. Utworzenie Repozytorium
val repository = NewsRepository(apiService)
// 3. Utworzenie ViewModelu przez Fabrykę
val viewModelFactory = NewsViewModelFactory(repository)
setContent {
val viewModel: NewsViewModel = viewModel(factory = viewModelFactory)
NewsScreen(viewModel = viewModel)
}
}
}Singleton vs Application Class
Zauważmy różnicę w sposobie inicjalizacji klienta sieciowego względem bazy danych z Rozdziału 9.
- W przypadku Room, musieliśmy użyć klasy
Application, ponieważ baza danych wymaga dostępu doContext(systemu plików urządzenia). - W przypadku Retrofita, zastosowaliśmy uproszczenie w postaci statycznego obiektu (
object RetrofitInstance). Jest to możliwe, ponieważ klient HTTP w swojej podstawowej formie nie zależy od systemu Android i nie wymagaContextu.
W poprzednich dwóch rozdziałach zbudowaliśmy solidne fundamenty warstwy danych:
- Room (Rozdział 9) do przechowywania danych lokalnych.
- Retrofit (Rozdział 10) do pobierania danych z sieci.
Jednakże, aby połączyć te elementy z widokiem (Compose), musieliśmy pisać dużo kodu sklejającego w MainActivity. Tworzyliśmy tam ręcznie instancje bazy danych, sieci, repozytoriów i fabryk. W tym rozdziale nauczymy się, jak zautomatyzować ten proces, używając standardu przemysłowego w świecie Androida - biblioteki Hilt.
Manualne Wstrzykiwanie Zależności
Zacznijmy od analizy kodu, którym zakończyliśmy poprzedni wykład. Spójrzmy krytycznym okiem na naszą klasę MainActivity.
W podejściu, które stosowaliśmy dotychczas, to Activity (lub klasa Application) pełniła rolę Wszechwiedzącego, który wie wszystko o tym, jak stworzyć każdy obiekt w aplikacji.
// KOD Z POPRZEDNIEGO ROZDZIAŁU (Manual DI)
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 1. Activity musi wiedzieć, jak skonfigurować Retrofita
// (lub pobierać go z singletona)
val apiService = RetrofitInstance.api
// 2. Activity musi wiedzieć, że Repozytorium potrzebuje API
val repository = NewsRepository(apiService)
// 3. Activity musi wiedzieć, jak zbudować ViewModelFactory
val viewModelFactory = NewsViewModelFactory(repository)
setContent {
// 4. Activity wstrzykuje fabrykę do ViewModelu
val viewModel: NewsViewModel = viewModel(factory = viewModelFactory)
NewsScreen(viewModel = viewModel)
}
}
}Powyższe podejście posiada kilka poważnych wad:
- Silne Sprzężenie (Tight Coupling): Nasze widoki (Activity/Compose) wiedzą za dużo o warstwie danych. Jeśli zmienimy konstruktor
NewsRepository(np. dodamy tam bazę danych Room), będziemy musieli poprawić kod w każdym miejscu, gdzie to repozytorium jest tworzone. - Boilerplate Code: W dużej aplikacji, gdzie mamy 50 ViewModeli, pisanie dla każdego z nich osobnej fabryki (
ViewModelProvider.Factory) jest żmudne i podatne na błędy. - Trudne testowanie: Jeśli
MainActivityna sztywno korzysta zRetrofitInstance, bardzo trudno jest podmienić API na fałszywe (Mock) podczas testów UI, aby np. symulować brak internetu.
Wstrzykiwanie Zależności (Dependency Injection) to technika programowania, w której obiekty nie tworzą swoich zależności, ale otrzymują je z zewnątrz.
Można to zobrazować to analogią Komputera i Myszki (Portu USB):
- Bez DI: Komputer ma myszkę przylutowaną na stałe do płyty głównej.
class Computer {
// Komputer sam tworzy myszkę. Jest od niej silnie zależny.
// Nie da się jej wymienić na inny model ani łatwo przetestować.
private val mouse = WiredMouse()
fun click() { mouse.leftClick() }
}Mouse.class Computer(private val mouse: Mouse) { // Wstrzyknięcie przez konstruktor
fun click() { mouse.leftClick() }
}
// Użycie:
// Możemy podłączyć zwykłą myszkę...
val officeComputer = Computer(WiredMouse())
// ...albo wstrzyknąć myszkę gamingową bez zmieniania kodu komputera!
val gamingComputer = Computer(GamingMouseRGB())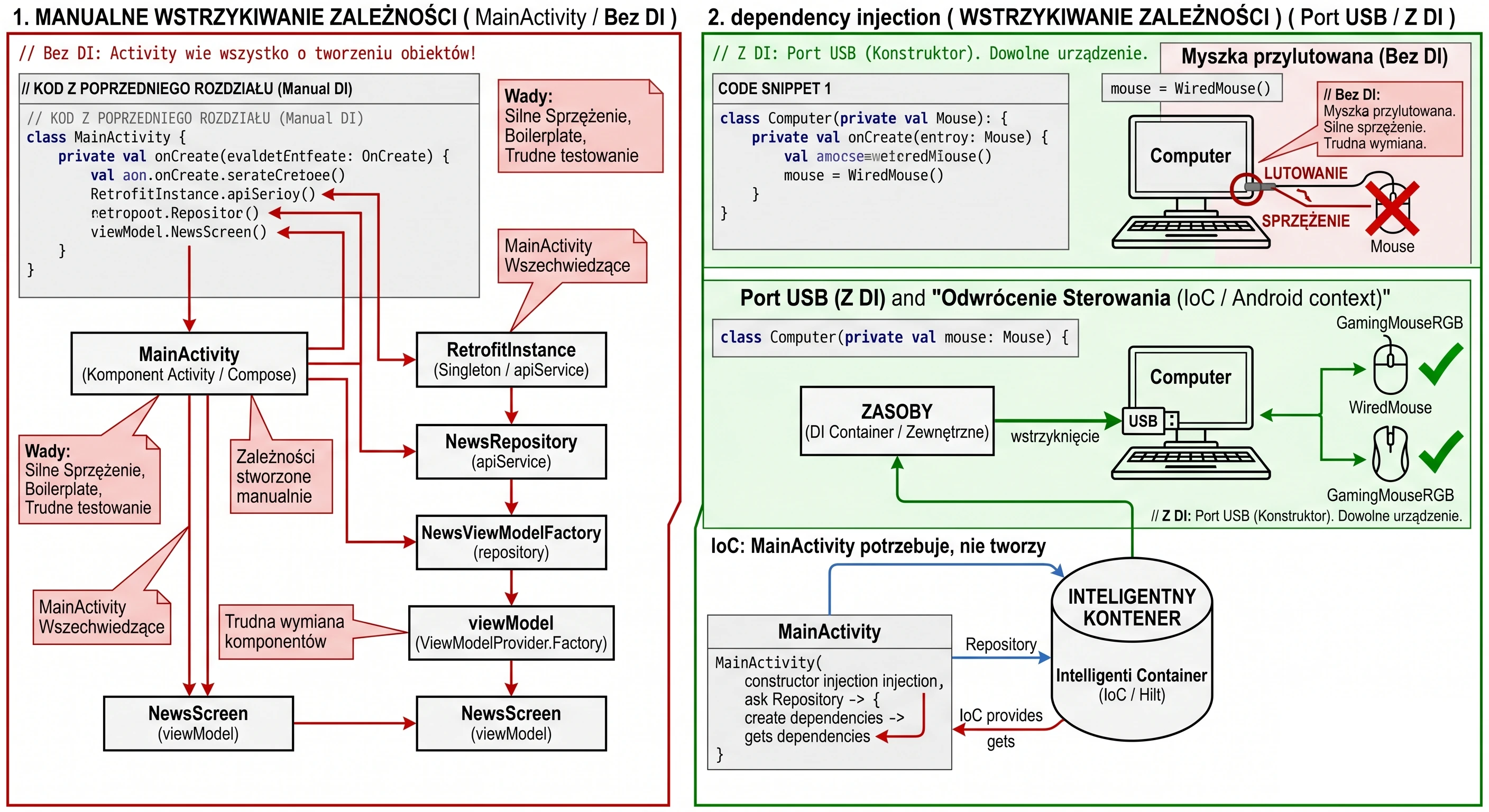
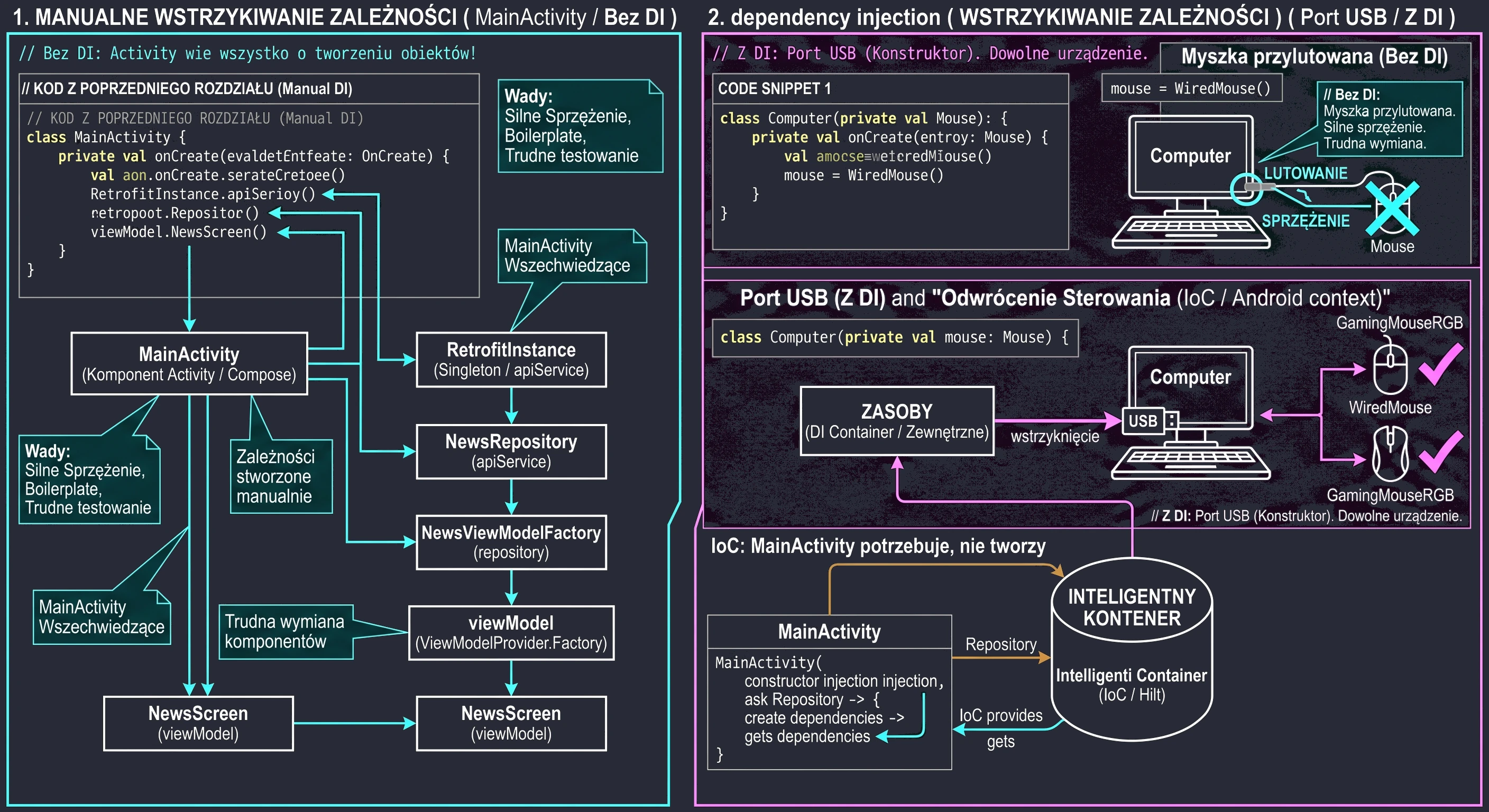
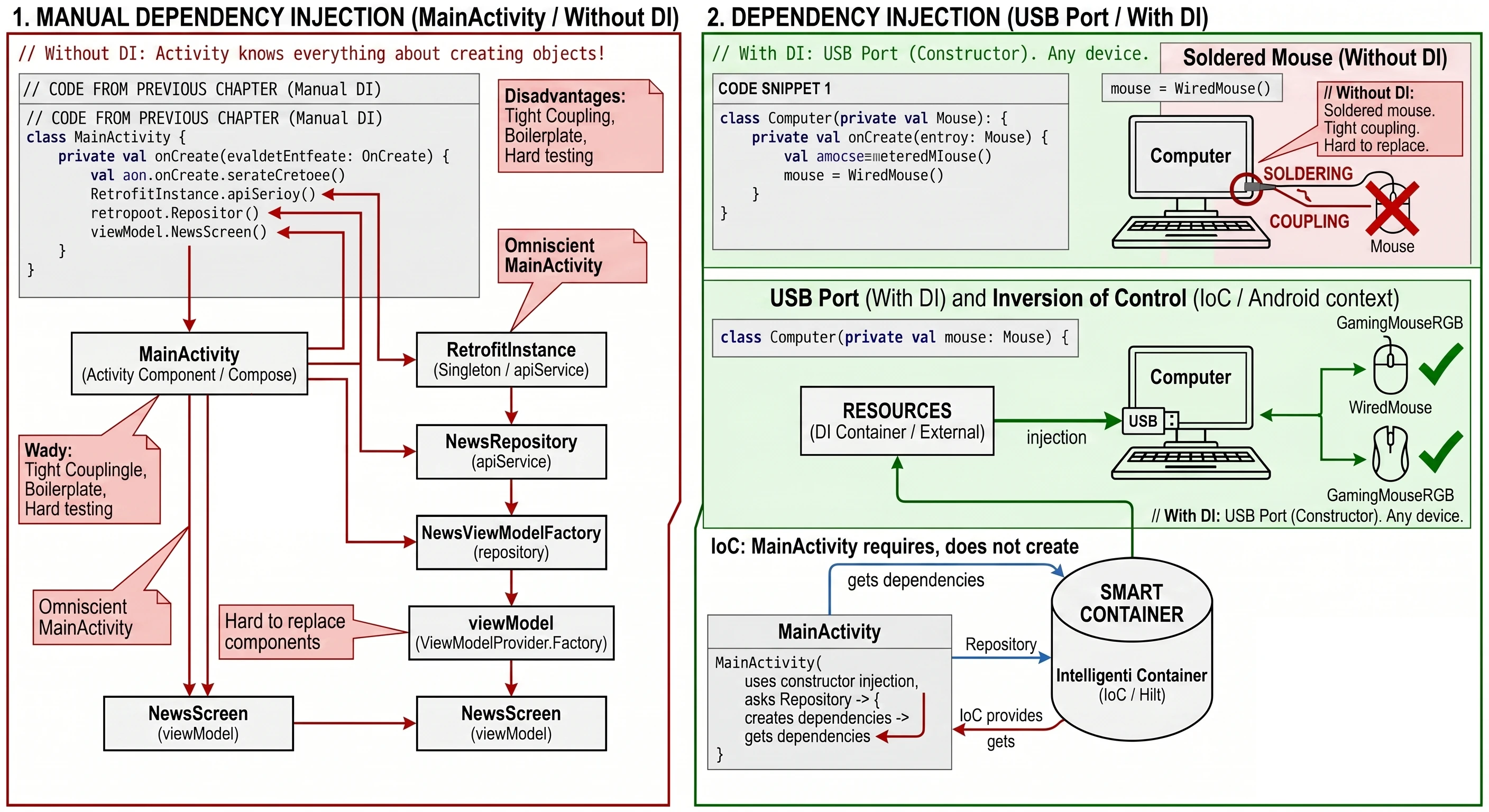
Odwrócenie Sterowania
Aby DI działało w dużej skali, potrzebujemy kogoś, kto będzie zarządzał tymi wszystkimi zależnościami - kontenera, który wie, jak stworzyć wszystkie niezbędne elementy i jak dostarczyć go do komputera. Tę koncepcję nazywamy Odwróceniem Sterowania (Inversion of Control). Zamiast: Ja (Activity) tworzę Repozytorium, mówimy: Ja (Activity) potrzebuję Repozytorium, dostarcz mi je.
W świecie Androida rolę takiego inteligentnego kontenera pełni biblioteka Hilt.
Biblioteka Hilt
Historycznie w świecie Androida dominowała biblioteka Dagger 2, ale wymaga pisania dużej ilości skomplikowanego kodu konfiguracyjnego. Hilt to biblioteka stworzona przez Google, która jest nakładką na Daggera.
- Zaleta: Zachowuje wydajność Daggera (generowanie kodu w czasie kompilacji, brak narzutu w Runtime).
- Ułatwienie: Standaryzuje sposób wstrzykiwania zależności, eliminując potrzebę ręcznego tworzenia Komponentów i Subkomponentów.
Konfiguracja projektu (Gradle)
Aby skorzystać z Hilt, musimy dodać odpowiednie pluginy i zależności.
W pliku build.gradle.kts(Project) dodajemy plugin Hilt w bloku plugins. Wersja biblioteki powinna być zgodna z aktualnymi wydaniami.
plugins {
// ... inne pluginy (np. android.application, kotlin.android)
id("com.google.dagger.hilt.android") version "2.57.2" apply false
}W pliku build.gradle.kts(Module), w module aplikacji musimy zastosować plugin oraz dodać biblioteki. Hilt wykorzystuje procesor adnotacji, dlatego używamy ksp.
plugins {
id("com.android.application")
id("org.jetbrains.kotlin.android")
// 1. Pluginy Hilt i ksp
id("com.google.devtools.ksp")
id("com.google.dagger.hilt.android")
}
dependencies {
// 2. Biblioteka Hilt
implementation("com.google.dagger:hilt-android:2.57.2")
// 3. Kompilator (generuje kod Daggera)
ksp("com.google.dagger:hilt-android-compiler:2.57.2")
}Fundament aplikacji (@HiltAndroidApp)
Wszystkie aplikacje korzystające z Hilt muszą zawierać klasę dziedziczącą po Application, oznaczoną adnotacją @HiltAndroidApp.
Jest to punkt, w którym generowany jest Korzeń Grafu Zależności (Root Component). To stąd Hilt czerpie wiedzę o wszystkich singletonach w aplikacji.
W pierwszym kroku tworzymy klasę reprezentującą aplikację:
// Ta adnotacja jest WYMAGANA. Bez niej Hilt nie zadziała.
@HiltAndroidApp
class NewsApplication : Application()Następnie rejestrujemy klasę w AndroidManifest.xml. Samo stworzenie klasy nie wystarczy. Musimy poinformować system Android, że ma jej użyć przy starcie procesu. Robimy to w atrybucie android:name tagu <application>.
<manifest xmlns:android="http://schemas.android.com/apk/res/android" ...>
<application
android:name=".NewsApplication"
... >
<activity android:name=".MainActivity" ... />
</application>
</manifest>Po wykonaniu tych kroków i przebudowaniu projektu (Sync Gradle), Hilt jest gotowy do pracy.
Podstawy Wstrzykiwania
Po skonfigurowaniu klasy Application, kontener DI jest zainicjalizowany, jednak graf zależności pozostaje pusty. Aby biblioteka Hilt mogła zarządzać obiektami, musimy zdefiniować dwa kluczowe aspekty:
- Binding Definitions (Definicje Wiązań): Instrukcje dla kompilatora, w jaki sposób instancjonować poszczególne klasy.
- Injection Targets (Cele Wstrzykiwania): Komponenty systemu Android, które mają otrzymać zależności z kontenera.
Wyróżniamy dwie techniki wstrzykiwania: Constructor Injection (preferowana) oraz Field Injection (wymuszona przez architekturę systemu Android). Podstawową metodą rozszerzania grafu zależności w Hilt jest adnotacja @Inject umieszczona przy konstruktorze klasy.
Zastosowanie tej adnotacji skutkuje dwoma operacjami podczas kompilacji (Annotation Processing):
- Rejestracja w grafie: Klasa staje się dostępna dla kontenera DI. Hilt generuje dla niej niejawnie fabrykę (Factory).
- Deklaracja zależności: Parametry konstruktora są traktowane jako zależności wymagane do utworzenia instancji. Hilt automatycznie podejmie próbę ich rezolucji (odnalezienia) w grafie.
// Plik: NewsRepository.kt
// Adnotacja @Inject informuje Hilt, jak utworzyć instancję NewsRepository.
// Jest to tzw. "Binding" (Wiązanie).
class NewsRepository @Inject constructor(
// Parametr apiService jest zależnością,
// którą Hilt musi dostarczyć (resolve).
private val apiService: NewsApiService
) {
suspend fun getNews() = apiService.getTopHeadlines()
}W powyższym przykładzie, każde żądanie wstrzyknięcia typu NewsRepository spowoduje automatyczne utworzenie obiektu przez Hilt, przy uprzednim rozwiązaniu zależności apiService.
Integracja z komponentami Androida (@AndroidEntryPoint)
W systemie Android cykl życia kluczowych komponentów (Activity, Fragment, Service, BroadcastReceiver) jest zarządzany przez system operacyjny, a nie przez programistę. Instancjonowanie tych klas odbywa się za pomocą mechanizmu refleksji systemowej, co uniemożliwia zastosowanie wstrzykiwania przez konstruktor.
W takich przypadkach stosujemy wzorzec Field Injection (Wstrzykiwanie do pól). Aby umożliwić wstrzykiwanie do klas systemowych, musimy oznaczyć je adnotacją @AndroidEntryPoint.
Adnotacja ta generuje indywidualny kontener DI (Hilt Component) dla danej klasy, powiązany z jej cyklem życia (np. ActivityComponent).
// Plik: MainActivity.kt
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
// Field Injection: Hilt wstrzyknie instancję po utworzeniu Activity,
// ale przed wywołaniem onCreate().
// Pola nie mogą być prywatne (wymaganie generowanego kodu).
@Inject
lateinit var analytics: AnalyticsLogger
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// W tym momencie pole 'analytics' jest już zainicjalizowane i bezpieczne do użycia.
analytics.logEvent("App Started")
setContent {
// ...
}
}
}Moduły Hilt: Dostarczanie Zależności Zewnętrznych
Mechanizm wsrzykiwania przez konstruktur jest wystarczający dla klas należących do projektu. Napotykamy jednak barierę w przypadku zależności pochodzących z zewnętrznych bibliotek (Third-Party Libraries), takich jak Retrofit, OkHttp czy Room.
Wyróżniamy dwie główne przeszkody uniemożliwiające użycie adnotacji @Inject:
- Brak dostępu do kodu źródłowego: Nie możemy zmodyfikować klasy bibliotecznej, aby dodać adnotację do jej konstruktora.
- Złożona instancjacja: Obiekty te często są tworzone za pomocą wzorca Budowniczy lub Metoda Fabrykująca, a nie poprzez proste wywołanie konstruktora.
Rozwiązaniem tego problemu są Moduły Hilt. Moduł to klasa (lub obiekt) pełniąca rolę fabryki, w której definiujemy metody dostarczające instancje wymaganych typów.
Struktura Modułu (@Module, @InstallIn)
Każdy moduł musi być opatrzony dwiema adnotacjami:
@Module: Informuje Hilt, że ta klasa zawiera definicje wiązań.@InstallIn(Component::class): Określa, w którym kontenerze (komponencie) Hilt mają być dostępne zależności z tego modułu. Determinuje to czas życia obiektów.
Najczęściej używanym komponentem jest SingletonComponent, który jest powiązany z cyklem życia całej aplikacji (klasy Application).
Definiowanie Dostawców (@Provides)
Wewnątrz modułu tworzymy funkcje opatrzone adnotacją @Provides. Ciało takiej funkcji zawiera logikę niezbędną do utworzenia i skonfigurowania instancji obiektu.
Poniżej przedstawiono implementację modułu sieciowego, zastępującą ręcznie tworzony singleton RetrofitInstance z poprzedniego wykładu.
// Plik: di/NetworkModule.kt
@Module
@InstallIn(SingletonComponent::class)
object NetworkModule {
// Definicja wiązania dla typu Retrofit.
// Adnotacja @Singleton gwarantuje, że w obrębie aplikacji powstanie tylko
// jedna instancja klienta (kluczowe dla puli połączeń HTTP).
@Provides
@Singleton
fun provideRetrofit(): Retrofit {
return Retrofit.Builder()
.baseUrl("https://newsapi.org/v2/")
.addConverterFactory(GsonConverterFactory.create())
.build()
}
// Definicja wiązania dla typu NewsApiService.
// Zależność 'retrofit' w parametrze zostanie automatycznie dostarczona
// przez metodę provideRetrofit() zdefiniowaną powyżej.
@Provides
@Singleton
fun provideNewsApiService(retrofit: Retrofit): NewsApiService {
return retrofit.create(NewsApiService::class.java)
}
}Dzięki powyższej konfiguracji, gdy NewsRepository zażąda w konstruktorze obiektu NewsApiService, Hilt automatycznie wywoła metodę provideNewsApiService.
Dostęp do Kontekstu Aplikacji (@ApplicationContext)
Konfiguracja bazy danych Room wymaga dostępu do obiektu Context. Hilt udostępnia predefiniowane wiązanie dla kontekstu aplikacji poprzez adnotację kwalifikującą @ApplicationContext.
Pozwala to na bezpieczne wstrzykiwanie kontekstu do modułów bez ryzyka wycieków pamięci (Memory Leaks) związanych z przechowywaniem referencji do Activity.
// Plik: di/DatabaseModule.kt
@Module
@InstallIn(SingletonComponent::class)
object DatabaseModule {
@Provides
@Singleton
fun provideDatabase(
// Wstrzyknięcie kontekstu systemowego
@ApplicationContext context: Context
): AppDatabase {
return Room.databaseBuilder(
context,
AppDatabase::class.java,
"news_database"
).build()
}
// Udostępnienie DAO bezpośrednio do grafu zależności.
// Dzięki temu Repozytoria nie muszą zależeć od całej bazy (AppDatabase),
// a jedynie od konkretnego DAO (Interface Segregation Principle).
@Provides
fun provideArticleDao(database: AppDatabase): ArticleDao {
return database.articleDao()
}
}Zarządzanie Cyklem Życia i Zakresy (Scopes)
W domyślnej konfiguracji, Hilt (podobnie jak Dagger 2) zachowuje się jak fabryka bezstanowa. Oznacza to, że każde żądanie wstrzyknięcia zależności powoduje utworzenie nowej instancji obiektu.
class AnalyticsAdapter @Inject constructor() { ... }
// Wstrzyknięcie 1: Tworzony jest obiekt A (adres pamięci: @1234)
@Inject lateinit var analytics1: AnalyticsAdapter
// Wstrzyknięcie 2: Tworzony jest obiekt B (adres pamięci: @5678)
@Inject lateinit var analytics2: AnalyticsAdapterDla lekkich obiektów (np. presenterów, helperów) jest to zachowanie pożądane. Jednak w przypadku ciężkich zasobów (Klient HTTP, Połączenie z Bazą Danych) lub obiektów przechowujących stan (Repository z cachem w pamięci RAM), konieczne jest zapewnienie unikalności instancji w określonym czasie. Do sterowania tym zachowaniem służą Zakresy (Scopes).
Dostępne Zakresy w Hilt
Przypisanie zakresu do wiązania (klasy lub metody @Provides) sprawia, że kontener DI przechowuje utworzoną instancję w pamięci podręcznej i zwraca ją przy każdym kolejnym zapytaniu, dopóki dany komponent istnieje.
Zastosowanie @Singleton
Najczęściej używanym zakresem w warstwie danych jest @Singleton. Gwarantuje on, że w całej aplikacji będzie istniała tylko jedna instancja danej klasy. Jest to krytyczne dla:
- Retrofit/OkHttpClient: Utrzymują one pulę połączeń TCP/IP. Tworzenie ich wielokrotnie jest bardzo kosztowne obliczeniowo.
- RoomDatabase: Zarządza połączeniem z plikiem SQLite.
- Repositories (z cache): Jeśli repozytorium trzyma dane w zmiennej (np.
List<Data>), musi być Singletonem, aby dane nie zniknęły przy przeładowaniu widoku.
Przykład z naszego modułu sieciowego:
@Module
@InstallIn(SingletonComponent::class)
object NetworkModule {
@Provides
@Singleton // <--- KLUCZOWE: Wymusza jedną instancję
fun provideRetrofit(): Retrofit {
// Ta metoda wykona się tylko RAZ podczas życia aplikacji.
// Kolejne żądania zwrócą zapamiętany obiekt.
return Retrofit.Builder()...build()
}
}Hierarchia Komponentów
Komponenty Hilt tworzą hierarchię drzewiastą. Zależności są dostępne "w dół" hierarchii:
- Obiekt z
SingletonComponentmoże być wstrzyknięty doActivity,ViewModelczyFragment. - Obiekt z
ActivityComponentnie może być wstrzyknięty doSingletonComponent(błąd kompilacji).
Zasada ta chroni przed wyciekami pamięci (Memory Leaks). Nie można wstrzyknąć obiektu o krótszym cyklu życia (np. Activity) do obiektu o dłuższym cyklu życia (np. Singleton Repozytorium), ponieważ Repozytorium trzymałoby referencję do zniszczonej Aktywności.
Integracja z ViewModel
W standardowym podejściu (bez DI), wstrzykiwanie zależności do ViewModelu jest problematyczne, ponieważ ViewModele muszą przetrwać zmiany konfiguracji (np. obrót ekranu). Wymaga to tworzenia skomplikowanych klas typu ViewModelProvider.Factory, które ręcznie przekazują zależności do konstruktora. Biblioteka Hilt całkowicie eliminuje konieczność pisania fabryk. Udostępnia ona dedykowany komponent ViewModelComponent oraz specjalną adnotację @HiltViewModel.
Adnotacja @HiltViewModel
Aby umożliwić automatyczne wstrzykiwanie zależności do ViewModelu, musimy spełnić dwa warunki:
- Oznaczyć klasę adnotacją
@HiltViewModel. - Użyć
@Inject constructordla konstruktora.
Zmodyfikujmy nasz NewsViewModel z poprzedniego wykładu:
// Plik: NewsViewModel.kt
@HiltViewModel // <--- Krok 1: Informujemy Hilt o tym ViewModelu
class NewsViewModel @Inject constructor(
// <--- Krok 2: Hilt sam wstrzyknie Repozytorium
private val repository: NewsRepository
) : ViewModel() {
// Reszta kodu bez zmian...
private val _uiState = MutableStateFlow<NewsUiState>(NewsUiState.Loading)
val uiState = _uiState.asStateFlow()
init {
fetchNews()
}
// ...
}Pobieranie ViewModelu w Compose
Aby pobrać instancję tak skonfigurowanego ViewModelu wewnątrz funkcji Composable, używamy funkcji pomocniczej hiltViewModel().
Biblioteka ta wykonuje pod spodem następujące kroki:
- Sprawdza, czy istnieje już instancja ViewModelu dla danego ekranu (jeśli tak, zwraca ją).
- Jeśli nie, prosi Hilt o utworzenie nowej instancji, rozwiązując wszystkie zależności w konstruktorze.
- Powiąże ViewModel z cyklem życia obecnego widoku (Activity lub wpisu w Navigation Graph).
// Wymagana zależność w build.gradle:
// implementation("androidx.hilt:hilt-navigation-compose:<version_number>")
@Composable
fun NewsScreen(
// Hilt automatycznie znajdzie i wstrzyknie odpowiedni ViewModel
viewModel: NewsViewModel = hiltViewModel()
) {
val state by viewModel.uiState.collectAsStateWithLifecycle()
// ... reszta UI
}Przykład Praktyczny: Refaktoryzacja
Podsumujmy zdobytą wiedzę, patrząc na to, jak zmienił się nasz punkt wejścia do aplikacji - plik MainActivity.kt.
Przed wprowadzeniem Hilt (Rozdział 10)
Kod był zanieczyszczony logiką konfiguracyjną:
// STARA WERSJA (Manual DI)
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Ręczne tworzenie grafu zależności
val api = RetrofitInstance.api
val repo = NewsRepository(api)
val factory = NewsViewModelFactory(repo) // Ręczna fabryka
setContent {
val viewModel: NewsViewModel = viewModel(factory = factory)
NewsScreen(viewModel)
}
}
}Po wprowadzeniu Hilt
Dzięki przeniesieniu odpowiedzialności za tworzenie obiektów do Modułów (sekcja 11.4) i zastosowaniu automatyzacji, nasza Activity staje się czysta i zgodna z zasadą Single Responsibility Principle.
// NOWA WERSJA (Hilt)
@AndroidEntryPoint // <--- Punkt wejścia
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Brak ręcznego tworzenia obiektów!
// Hilt zarządza wszystkim w tle.
setContent {
// NewsScreen wewnątrz używa hiltViewModel(),
// więc tutaj nie musimy nic przekazywać.
NewsScreen()
}
}
}Przepływ Danych (Podsumowanie)
Kompletny przepływ sterowania w naszej aplikacji wygląda teraz następująco:
- Start Aplikacji: Tworzona jest klasa
NewsApplicationz adnotacją@HiltAndroidApp. Hilt buduje graf zależności, tworząc singletony zdefiniowane wNetworkModule(Retrofit). - Start Activity: Uruchamia się
MainActivityz adnotacją@AndroidEntryPoint. - Start Ekranu: Funkcja
NewsScreenwywołujehiltViewModel(). - Tworzenie ViewModelu: Hilt zauważa, że
NewsViewModelwymagaNewsRepository. - Tworzenie Repozytorium: Hilt zauważa, że
NewsRepositorywymagaNewsApiService. - Wstrzyknięcie: Hilt pobiera gotowego Retrofita (Singleton), tworzy serwis API, tworzy Repozytorium, tworzy ViewModel i dostarcza go do Widoku.
Cały ten skomplikowany proces dzieje się automatycznie, a my musimy jedynie zdefiniować przepisy (Moduły) i oznaczyć klasy odpowiednimi adnotacjami.
Pełny Kod Przykładu: News Reader (Hilt Edition)
Poniżej znajduje się kompletny kod źródłowy kluczowych plików aplikacji, po przeprowadzeniu migracji z ręcznego wstrzykiwania zależności (Manual DI) na bibliotekę Hilt.
Punkt Startowy Aplikacji
// NewsApplication.kt
package com.example.newsreader
@HiltAndroidApp // Generuje graf zależności (Root Component)
class NewsApplication : Application()Moduł Sieciowy (DI)
// di/NetworkModule.kt
package com.example.newsreader.di
@Module
@InstallIn(SingletonComponent::class) // Dostępne w całej aplikacji
object NetworkModule {
@Provides
@Singleton // Jedna instancja Retrofita na całą aplikację
fun provideRetrofit(): Retrofit {
return Retrofit.Builder()
.baseUrl("https://newsapi.org/v2/")
.addConverterFactory(GsonConverterFactory.create())
.build()
}
@Provides
@Singleton
fun provideNewsApi(retrofit: Retrofit): NewsApiService {
return retrofit.create(NewsApiService::class.java)
}
}Warstwa Danych (Repository)
// Model artykułu (powinien pasować do tego z API)
data class Article(
val title: String,
val description: String?,
val url: String? = null,
val urlToImage: String? = null
)
// data/NewsRepository.kt
package com.example.newsreader.data
// @Inject mówi Hiltowi: "Tak twórz instancje tej klasy".
// Hilt automatycznie znajdzie 'apiService' w NetworkModule.
class NewsRepository @Inject constructor(
private val apiService: NewsApiService
) {
suspend fun getTopHeadlines() = apiService.getTopHeadlines().articles
}Warstwa Prezentacji (ViewModel)
// Stany widoku
sealed interface NewsUiState {
data object Loading : NewsUiState
data class Success(val articles: List<Article>) : NewsUiState
data class Error(val message: String) : NewsUiState
}
// ui/NewsViewModel.kt
package com.example.newsreader.ui
@HiltViewModel // Eliminujemy potrzebę pisania ViewModelFactory
class NewsViewModel @Inject constructor(
private val repository: NewsRepository
) : ViewModel() {
private val _uiState = MutableStateFlow<NewsUiState>(NewsUiState.Loading)
val uiState = _uiState.asStateFlow()
init {
fetchData
}
fun fetchData(){
viewModelScope.launch {
try {
val news = repository.getTopHeadlines()
_uiState.update { NewsUiState.Success(news) }
} catch (e: Exception) {
_uiState.update { NewsUiState.Error("Błąd pobierania") }
}
}
}
}Warstwa UI (Compose i Activity)
// MainActivity.kt
package com.example.newsreader
@AndroidEntryPoint // Wymagane, aby Activity mogło
// hostować ekrany korzystające z Hilt
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
NewsScreen()
}
}
}
@Composable
fun NewsScreen(
// ViewModel jest wstrzykiwany
viewModel: NewsViewModel = hiltViewModel()
) {
// Obserwujemy stan ze StateFlow
val state by viewModel.uiState.collectAsState()
Scaffold(
topBar = {
TopAppBar(
title = { Text("News Reader (Hilt)") }
)
}
) { paddingValues ->
// Kontener główny z paddingiem od Scaffolda
Box(
modifier = Modifier
.padding(paddingValues)
.fillMaxSize(),
contentAlignment = Alignment.Center
) {
when (val currentState = state) {
// 1. Stan Ładowania
is NewsUiState.Loading -> {
CircularProgressIndicator()
}
// 2. Stan Błędu
is NewsUiState.Error -> {
Column(
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center,
modifier = Modifier.padding(16.dp)
) {
Text(
text = "Błąd: ${currentState.message}",
color = MaterialTheme.colorScheme.error,
style = MaterialTheme.typography.bodyLarge
)
Spacer(modifier = Modifier.height(8.dp))
Button(onClick = { viewModel.fetchData() }) {
Text("Spróbuj ponownie")
}
}
}
// 3. Stan Sukcesu (Lista)
is NewsUiState.Success -> {
if (currentState.articles.isEmpty()) {
Text("Brak artykułów do wyświetlenia.")
} else {
LazyColumn(
modifier = Modifier.fillMaxSize(),
contentPadding = PaddingValues(16.dp),
verticalArrangement = Arrangement.spacedBy(8.dp)
) {
items(currentState.articles) { article ->
ArticleItem(article)
}
}
}
}
}
}
}
}
// --- POJEDYNCZY ELEMENT LISTY ---
@Composable
fun ArticleItem(article: Article) {
Card(
elevation = CardDefaults.cardElevation(defaultElevation = 4.dp),
modifier = Modifier.fillMaxWidth()
) {
Column(
modifier = Modifier.padding(16.dp)
) {
Text(
text = article.title,
fontWeight = FontWeight.Bold,
maxLines = 2,
overflow = TextOverflow.Ellipsis
)
if (!article.description.isNullOrBlank()) {
Spacer(modifier = Modifier.height(4.dp))
Text(
text = article.description,
maxLines = 3,
overflow = TextOverflow.Ellipsis
)
}
}
}
}W poprzednim rozdziale nauczyliśmy się korzystać z biblioteki Hilt do automatycznego wstrzykiwania zależności. Zastosowaliśmy tam jednak pewne uproszczenie: nasze ViewModele zależały bezpośrednio od konkretnych klas Repozytoriów (np. NewsRepository).
W tym rozdziale podniesiemy jakość naszej architektury, wprowadzając dwa kluczowe ulepszenia:
- Interfejsy w Warstwie Danych: Aby uniezależnić kod od konkretnej implementacji (zgodnie z zasadą Dependency Inversion).
- Warstwę Domeny (Use Cases): Aby wyprowadzić logikę biznesową z ViewModeli.
Ulepszanie Warstwy Danych: Dlaczego potrzebujemy Interfejsów?
Spójrzmy na kod ViewModelu, którym zakończyliśmy poprzedni wykład:
@HiltViewModel
class NewsViewModel @Inject constructor(
// BŁĄD ARCHITEKTONICZNY: Zależność od konkretnej klasy
private val repository: NewsRepository
) : ViewModel() { ... }To podejście, choć działa, posiada poważne wady z punktu widzenia inżynierii oprogramowania (SOLID):
- Trudne testowanie: Aby przetestować
NewsViewModel, musimy dostarczyć mu prawdziwą instancjęNewsRepository, która może łączyć się z internetem. W testach jednostkowych chcielibyśmy użyć zaślepki (FakeRepository), która zwraca dummy data. - Silne sprzężenie (Tight Coupling): Jeśli w przyszłości będziemy chcieli zmienić źródło danych z Retrofit na Firebase lub GraphQL, będziemy musieli przebudować kod wewnątrz wszystkich ViewModeli.
Zamiast wstrzykiwać klasę, powinniśmy wstrzykiwać obiekt o typie interfejsu. Definiuje on kontrakt - mówi co repozytorium potrafi robić, ale nie jak to robi.
// 1. Definiujemy Interfejs (w warstwie Domeny lub Danych)
interface NewsRepository {
suspend fun getTopHeadlines(): List<Article>
}
// 2. Implementujemy Interfejs (w warstwie Danych)
class NewsRepositoryImpl @Inject constructor(
private val api: NewsApiService
) : NewsRepository {
override suspend fun getTopHeadlines() = api.getTopHeadlines().articles
}
// 3. ViewModel zależy teraz od Interfejsu (Dependency Inversion)
class NewsViewModel @Inject constructor(
private val repository: NewsRepository // <--- ZMIANA
) : ViewModel() { ... }Dzięki tej zmianie, ViewModel nie wie, czy dane pochodzą z sieci, z bazy danych, czy z pliku testowego. Interesuje go tylko, że obiekt spełnia kontrakt NewsRepository.
Konfiguracja Hilt dla Interfejsów (@Binds)
Po wprowadzeniu interfejsu napotkamy na problem z biblioteką Hilt.
Gdy Hilt próbuje stworzyć NewsViewModel, widzi, że potrzebuje on NewsRepository. Hilt przeszukuje swoje przepisy (graf zależności), ale nie znajduje instrukcji, jak stworzyć Interfejs. Hilt wie tylko, jak stworzyć klasę NewsRepositoryImpl (bo ma ona adnotację @Inject constructor).
Musimy połączyć te dwa fakty. Musimy powiedzieć Hiltowi: Jeśli ktoś poprosi Cię o NewsRepository, daj mu instancję NewsRepositoryImpl.
Do wiązania interfejsów z implementacjami używamy adnotacji @Binds. Wymaga ona stworzenia modułu abstrakcyjnego.
// Plik: di/RepositoryModule.kt
@Module
@InstallIn(SingletonComponent::class)
abstract class RepositoryModule {
// Adnotacja @Binds działa podobnie do @Provides, ale jest wydajniejsza.
// Metoda musi być abstrakcyjna.
// Parametr metody to konkretna implementacja, którą Hilt już zna (ma @Inject).
// Typ zwracany to obiekt o typie interfejsu, który chcemy wstrzykiwać.
@Binds
@Singleton // Jeśli chcemy, by repozytorium było singletonem
abstract fun bindNewsRepository(
impl: NewsRepositoryImpl
): NewsRepository
}Moglibyśmy osiągnąć ten sam efekt używając znanej nam adnotacji @Provides:
// Podejście z @Provides (mniej optymalne dla interfejsów):
@Provides
fun provideRepository(impl: NewsRepositoryImpl): NewsRepository {
return impl
}Zaleca się jednak stosowanie @Binds, ponieważ:
- Wydajność:
@Bindsnie generuje kodu nowej metody fabrykującej. Hilt po prostu rzutuje typ w wygenerowanym kodzie Javy, co zmniejsza rozmiar aplikacji i przyspiesza kompilację. - Czytelność: Jawnie wskazuje, że wiążemy interfejs, a nie tworzymy nowy obiekt z zewnętrznej biblioteki.
Moduł zawierający metody @Binds musi być klasą abstrakcyjną lub interfejsem. Nie można w nim mieszać zwykłych metod @Provides, chyba że są one statyczne (w Kotlinie w bloku companion object). Dlatego dobrą praktyką jest trzymanie konfiguracji Retrofita/Room w osobnym module (np. NetworkModule), a wiązań repozytoriów w osobnym (np. RepositoryModule).
Wstęp do Czystej Architektury (Clean Architecture)
Wraz ze wzrostem skomplikowania aplikacji, standardowy wzorzec MVVM (Model-View-ViewModel) zaczyna ujawniać swoje ograniczenia. W architekturze, którą stosowaliśmy do tej pory, ViewModel często przejmuje zbyt wiele odpowiedzialności:
- Zarządza stanem UI (poprawnie).
- Obsługuje błędy sieciowe (poprawnie).
- Wykonuje skomplikowane obliczenia matematyczne (np. podatki, rabaty).
- Waliduje dane wejściowe (np. poprawność adresu email).
- Łączy dane z kilku repozytoriów (np. profil użytkownika + historia zamówień).
Takie przeładowane klasy są trudne do czytania, utrzymania i testowania. Rozwiązaniem jest wprowadzenie nowej, środkowej warstwy - Warstwy Domeny. Znajduje się ona pomiędzy warstwą Prezentacji (UI + ViewModel) a warstwą Danych (Repository).
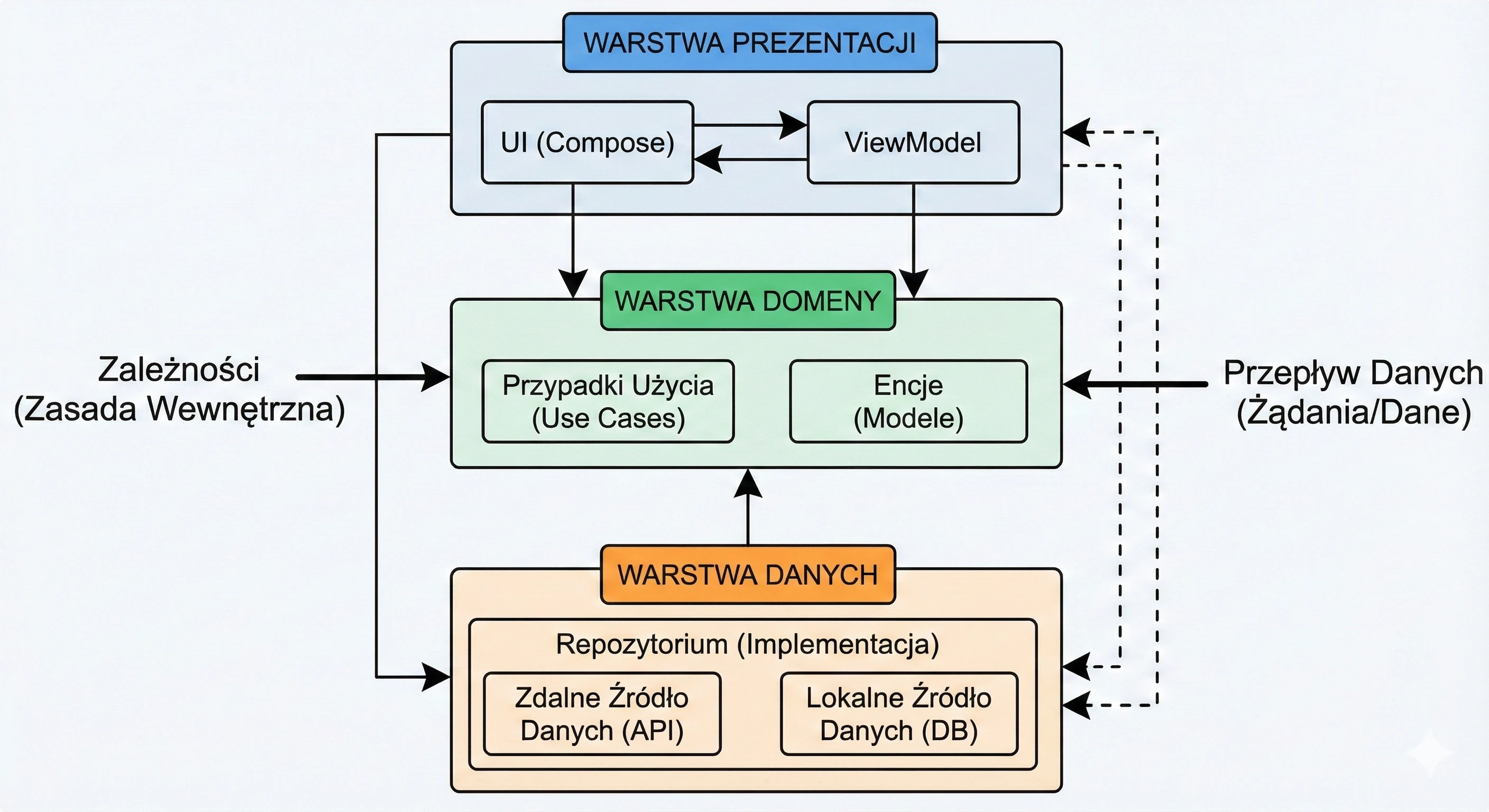
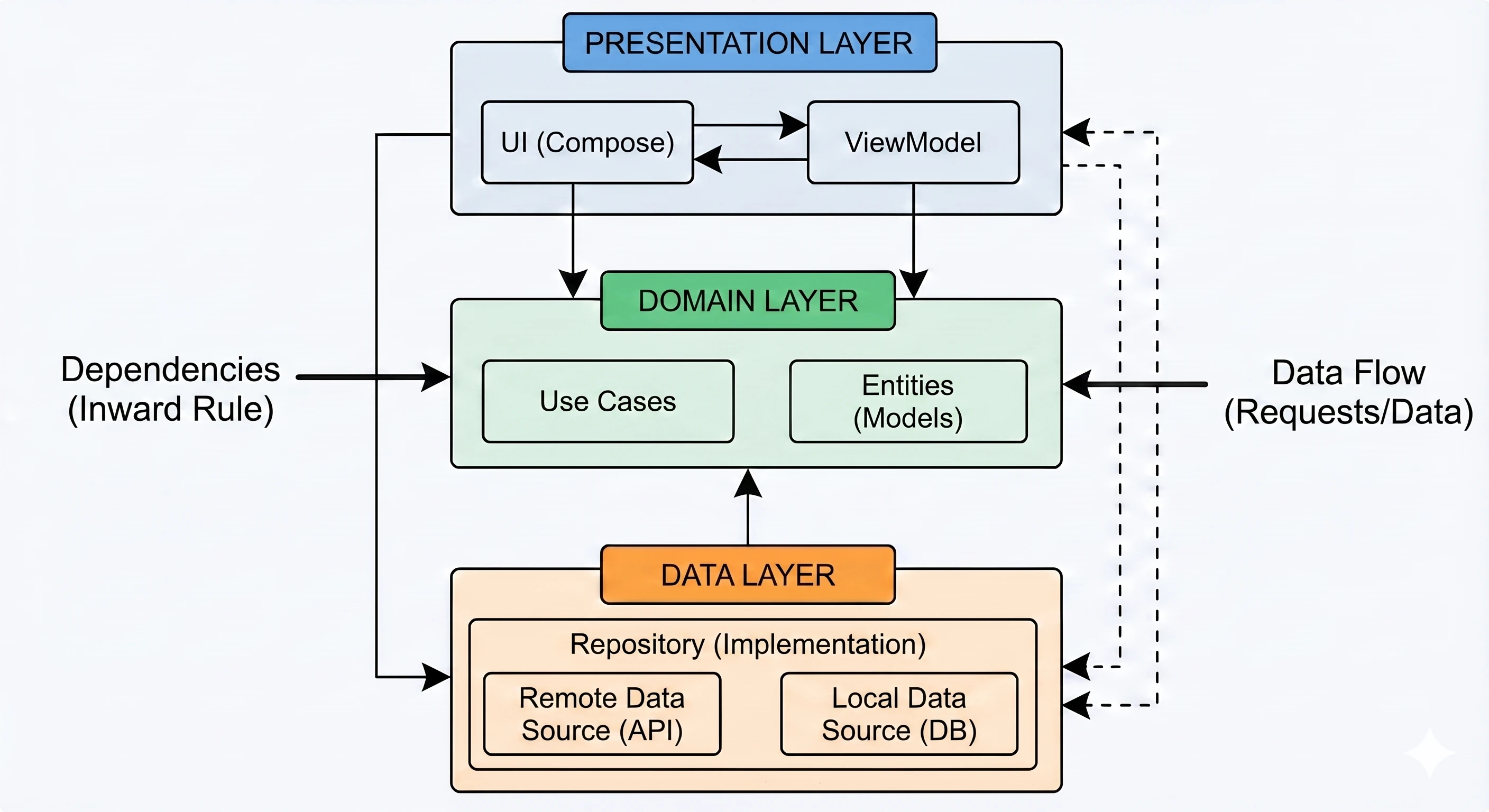
Główne zasady Warstwy Domeny:
- Czysty Kotlin: Kod w tej warstwie nie powinien zależeć od frameworka Android. Nie znajdziemy tu klas
Context,Activity,R.stringani bibliotek typu Retrofit czy Room. - Niezależność: Domena definiuje logikę biznesową aplikacji (np. jak obliczyć cenę koszyka), która pozostaje niezmienna niezależnie od tego, czy wyświetlamy dane na ekranie telefonu, czy na zegarku.
- Stabilność: Jest to najmniej zmienna część aplikacji. Zmiana wyglądu przycisku (UI) lub zmiana bazy danych (Data) nie powinna wpływać na logikę obliczania podatku (Domain).
Warstwa Domeny: UseCase (Przypadek Użycia)
Podstawowym elementem budulcowym warstwy domeny jest Use Case (często nazywany też Interaktorem). Jest to klasa, która realizuje pojedynczą akcję biznesową. Zgodnie z zasadą Single Responsibility Principle (SRP), powinna mieć tylko jeden powód do zmiany.
Przykłady nazw UseCaseów (Zasada: Czasownik + Rzeczownik + UseCase):
LoginUserUseCaseGetArticlesUseCaseCalculateVatPriceUseCaseValidateCouponUseCase
Dzięki takiemu nazewnictwu, patrząc na strukturę plików w projekcie, od razu wiemy, co aplikacja robi, a nie tylko z jakich komponentów się składa. Nazywamy to Screaming Architecture.
W języku Kotlin implementacja UseCaseów jest bardzo prosta dzięki możliwości przeciążania operatorów. Używamy operatora invoke, co pozwala traktować instancję klasy tak, jakby była funkcją. Stwórzmy przykładowy UseCase do obliczania ceny z podatkiem VAT:
// Plik: domain/CalculateVatPriceUseCase.kt
// UseCase to zwykła klasa, którą wstrzykujemy przez konstruktor
class CalculateVatPriceUseCase @Inject constructor() {
// Logika biznesowa: Stała stawka VAT
private val vatRate = 0.23
// Operator invoke pozwala na wywołanie: useCase(price)
operator fun invoke(basePrice: Double): Double {
if (basePrice < 0) throw IllegalArgumentException("Cena nie może być ujemna")
return basePrice * (1 + vatRate)
}
}Bardziej zaawansowane przypadki użycia muszą pobierać dane. Wstrzykujemy do nich repozytoria (zdefiniowane w punkcie 12.1).
// Plik: domain/GetProductDetailsUseCase.kt
class GetProductDetailsUseCase @Inject constructor(
private val productRepository: ProductRepository // Zależność od Interfejsu
) {
// Funkcje suspend są naturalnie wspierane
suspend operator fun invoke(productId: String): Product {
// Tu mogłaby być dodatkowa logika, np. łączenie danych z różnych źródeł
return productRepository.getProductById(productId)
}
}Korzyści z takiego podejścia:
- Reużywalność: Tego samego
CalculateVatPriceUseCasemożemy użyć wCartViewModel,ProductDetailsViewModeliCheckoutViewModel. Nie musimy kopiować wzoru na VAT w trzech miejscach. - Testowalność: Testowanie UseCasea jest trywialne - to czysta funkcja, która przyjmuje dane wejściowe i zwraca wynik. Nie potrzebujemy emulatora ani bibliotek do testowania UI.
- Odchudzenie ViewModelu: ViewModel staje się prostym koordynatorem, który tylko przekazuje dane do odpowiednich UseCaseów.
Implementacja Warstwy Domeny w Hilt
Zobaczmy, jak połączyć go z resztą aplikacji przy użyciu Hilt. Stworzymy kompletny łańcuch zależności dla scenariusza Obliczanie Ceny Końcowej.
Przypadki użycia to idealne miejsce na łączenie danych z różnych źródeł (Repozytoriów) oraz konfiguracji. Hilt radzi sobie z nimi bez żadnych dodatkowych modułów - wystarczy adnotacja @Inject constructor.
// domain/CalculateFinalPriceUseCase.kt
class CalculateFinalPriceUseCase @Inject constructor(
// Hilt automatycznie znajdzie implementację
// tego interfejsu (dzięki @Binds)
private val repository: ProductRepository,
// Możemy wstrzykiwać też inne klasy pomocnicze
private val taxCalculator: TaxCalculator
) {
suspend operator fun invoke(productId: String): Double {
// 1. Pobieramy dane (Warstwa Danych)
val basePrice = repository.getProductPrice(productId)
// 2. Przetwarzamy dane (Logika Biznesowa)
return taxCalculator.addVat(basePrice)
}
}Nasz ViewModel przestaje być świadomy istnienia Repozytorium czy Bazy Danych. Jego jedynym oknem na świat staje się Warstwa Domeny.
// ui/CartViewModel.kt
@HiltViewModel
class CartViewModel @Inject constructor(
// ZMIANA: Zamiast 'ProductRepository', wstrzykujemy konkretną akcję biznesową
private val calculateFinalPriceUseCase: CalculateFinalPriceUseCase
) : ViewModel() {
private val _uiState = MutableStateFlow(CartUiState())
val uiState = _uiState.asStateFlow()
fun loadPrice(productId: String) {
viewModelScope.launch {
try {
// Wywołanie UseCase wygląda jak zwykła funkcja
val price = calculateFinalPriceUseCase(productId)
_uiState.update { it.copy(totalPrice = price) }
} catch (e: Exception) {
// Obsługa błędów UI
}
}
}
}Porównajmy konstruktor ViewModelu przed i po zmianach:
Przed wyczyszczeniem:
class CartViewModel(
val repo: ProductRepository, // Dostęp do wszystkiego (pobierz, usuń, edytuj)
val userRepo: UserRepository,
val promoRepo: PromoRepository
)ViewModel miał dostęp do metod, których nie potrzebował (np. repo.deleteAllProducts()).
Po wyczyszczeniu:
class CartViewModel(
val calculatePrice: CalculateFinalPriceUseCase // Dostęp TYLKO do tego, co potrzebne
)ViewModel otrzymuje wąskie, precyzyjne narzędzie do wykonania konkretnego zadania.
Struktura Pakietów (Packaging Strategies)
Wprowadzenie Czystej Architektury wiąże się ze wzrostem liczby plików. Zamiast jednej klasy NewsViewModel, mamy teraz NewsViewModel, GetNewsUseCase, NewsRepository (interface), NewsRepositoryImpl itd.
Jeśli wrzucimy wszystkie te pliki do jednego worka, projekt stanie się nieczytelny. Istnieją dwie główne strategie organizacji kodu.
Strategia 1: Package by Layer (Pakietowanie Warstwami)
To klasyczne podejście, gdzie pliki grupowane są według ich technicznej roli w systemie.
com.example.shop
+-- data (Wszystkie repozytoria i źródła danych)
| +-- CartRepositoryImpl.kt
| +-- ProductRepositoryImpl.kt
+-- domain (Wszystkie UseCases i Modele)
| +-- Cart.kt
| +-- CalculatePriceUseCase.kt
+-- ui (Wszystkie ekrany i ViewModele)
+-- CartViewModel.kt
+-- ProductListViewModel.ktZalety: Łatwe do zrozumienia dla początkujących.
Wady: Słaba skalowalność. Aby zmodyfikować funkcję Koszyka, musisz skakać między trzema katalogami (data, domain, ui). W dużych projektach te katalogi stają się przepełnione.
Strategia 2: Package by Feature (Pakietowanie Funkcjami)
W nowoczesnym Androidzie (i podejściu Clean Architecture) preferuje się grupowanie plików według funkcjonalności biznesowej.
com.example.shop
+-- cart (Wszystko związane z koszykiem)
| +-- CartRepository.kt
| +-- CartViewModel.kt
| +-- CalculatePriceUseCase.kt
+-- product (Wszystko związane z produktami)
| +-- ProductRepository.kt
| +-- ProductListScreen.kt
+-- checkout (Wszystko związane z płatnością)Zalety:
- Wysoka spójność (High Cohesion): Wszystko, co dotyczy koszyka, jest w jednym miejscu.
- Modularność: Jeśli chcemy usunąć funkcję koszyka, po prostu usuwamy folder
cart. - Czytelność: Patrząc na strukturę plików, od razu wiemy, co robi aplikacja (Screaming Architecture).
Podejście Hybrydowe
W praktyce najlepiej sprawdza się połączenie obu podejść. Na najwyższym poziomie dzielimy aplikację na funkcje (Features), a wewnątrz funkcji zachowujemy podział na warstwy (Layers), jeśli funkcja jest skomplikowana. Dodatkowo wydzielamy elementy wspólne (core, di).
com.example.shop
+-- core (Elementy wspólne dla całej aplikacji)
| +-- ui (Theme, wspólne komponenty Compose)
| +-- util (Rozszerzenia, helpery)
+-- di (Globalne moduły Hilt - NetworkModule, DatabaseModule)
+-- features
+-- cart
| +-- domain (UseCases specyficzne dla koszyka)
| +-- data (Implementacja repozytorium koszyka)
| +-- ui (CartScreen, CartViewModel)
+-- product_list
+-- ...Taka struktura jest odporna na rozrost projektu i ułatwia pracę w zespołach (jeden programista pracuje nad folderem cart, drugi nad profile, nie wchodząc sobie w drogę).
Przykład Praktyczny: Aplikacja Sklepowa (Shopping Cart)
Poniżej znajduje się kompletna implementacja funkcjonalności Koszyk z wykorzystaniem Czystej Architektury i Hilt. Kod został podzielony na pakiety.
Scenariusz biznesowy:
- Pobieramy cenę produktu (Warstwa Danych).
- Użytkownik wpisuje kod rabatowy.
- Aplikacja oblicza VAT i uwzględnia rabat (Warstwa Domeny).
- Wynik wyświetlany jest na ekranie (Warstwa Prezentacji).
Struktura Projektu
Najpierw utwórz odpowiednie pakiety w folderze com.example.shop:
com.example.shop
+-- di (Moduły Hilt)
+-- data (Repozytoria - implementacje)
+-- domain (UseCases i Interfejsy)
+-- ui (ViewModel i Compose Screen)
+-- NewsApplication.kt
+-- MainActivity.ktWarstwa Domeny (Domain Layer)
Tu definiujemy logikę biznesową. Zauważ, że te klasy nie wiedzą nic o Androidzie ani o bazie danych.
// domain/ProductRepository.kt
package com.example.shop.domain
// Interfejs (Kontrakt)
interface ProductRepository {
suspend fun getBasePrice(): Double
}
// domain/CalculateFinalPriceUseCase.kt
package com.example.shop.domain
class CalculateFinalPriceUseCase @Inject constructor(
private val repository: ProductRepository
) {
private val vatRate = 0.23 // 23% VAT
// Funkcja wywoływana operatorem: useCase(coupon)
suspend operator fun invoke(couponCode: String): Double {
val basePrice = repository.getBasePrice()
val priceWithVat = basePrice * (1 + vatRate)
// Prosta logika biznesowa rabatów
return if (couponCode == "STUDENT") {
priceWithVat * 0.5 // 50% zniżki
} else {
priceWithVat
}
}
}Warstwa Danych (Data Layer)
Tu implementujemy interfejs i konfigurujemy Hilt, aby wiedział jak go połączyć.
// data/ProductRepositoryImpl.kt
package com.example.shop.data
class ProductRepositoryImpl @Inject constructor() : ProductRepository {
override suspend fun getBasePrice(): Double {
delay(500) // Symulacja opóźnienia sieciowego
return 100.0 // Cena bazowa produktu
}
}
// di/AppModule.kt
package com.example.shop.di
@Module
@InstallIn(SingletonComponent::class)
abstract class AppModule {
@Binds
@Singleton
abstract fun bindProductRepository(
impl: ProductRepositoryImpl
): ProductRepository
}Warstwa Prezentacji (UI Layer)
ViewModel nie robi obliczeń - on tylko zleca zadanie do UseCasea i aktualizuje stan.
// ui/CartViewModel.kt
package com.example.shop.ui
data class CartUiState(
val finalPrice: String = "---",
val isLoading: Boolean = false
)
@HiltViewModel
class CartViewModel @Inject constructor(
// Wstrzykujemy UseCase, a nie Repozytorium!
private val calculateFinalPrice: CalculateFinalPriceUseCase
) : ViewModel() {
private val _uiState = MutableStateFlow(CartUiState())
val uiState = _uiState.asStateFlow()
fun calculatePrice(coupon: String) {
viewModelScope.launch {
_uiState.update { it.copy(isLoading = true) }
// Wywołanie logiki biznesowej
val result = calculateFinalPrice(coupon)
_uiState.update {
it.copy(
isLoading = false,
finalPrice = String.format("%.2f PLN", result)
)
}
}
}
}Widok (Compose)
// ui/CartScreen.kt
package com.example.shop.ui
@Composable
fun CartScreen(
viewModel: CartViewModel = hiltViewModel()
) {
val state by viewModel.uiState.collectAsState()
var couponText by remember { mutableStateOf("") }
Column(
modifier = Modifier.fillMaxSize().padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text("Koszyk sklepowy")
Spacer(Modifier.height(32.dp))
OutlinedTextField(
value = couponText,
onValueChange = { couponText = it },
label = { Text("Kod rabatowy (np. STUDENT)") }
)
Spacer(Modifier.height(16.dp))
Button(
onClick = { viewModel.calculatePrice(couponText) },
enabled = !state.isLoading
) {
Text("Oblicz cenę")
}
Spacer(Modifier.height(32.dp))
if (state.isLoading) {
CircularProgressIndicator()
} else {
Text(
text = "Do zapłaty: ${state.finalPrice}"
)
}
}
}Konfiguracja Aplikacji
Aby całość zadziałała, potrzebujemy jeszcze punktów startowych dla systemu Android i Hilta.
// ShopApplication.kt
package com.example.shop
@HiltAndroidApp
class ShopApplication : Application()// MainActivity.kt
package com.example.shop
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
CartScreen()
}
}
}W pliku AndroidManifest.xml musisz zarejestrować klasę aplikacji w atrybucie android:name: <application android:name=".ShopApplication" ... >
W poprzednich rozdziałach nauczyliśmy się pobierać dane z Internetu (Retrofit) oraz zapisywać je w lokalnej bazie danych (Room). Do tej pory traktowaliśmy te technologie rozłącznie. Nasze aplikacje działały w trybie Online-Only - jeśli telefon tracił zasięg, użytkownik widział pusty ekran lub komunikat błędu.
W tym rozdziale połączymy te technologie, aby stworzyć aplikację typu Offline-First.
Offline-First
Urządzenia mobilne, ze swojej natury, działają w środowisku o zmiennej jakości połączenia sieciowego. Użytkownik może wejść do windy, przejechać przez tunel w metrze lub po prostu znaleźć się w strefie słabego zasięgu.
W prostych aplikacjach przepływ danych wygląda następująco:
UI <-> ViewModel <-> Retrofit (Internet)Wady tego rozwiązania są krytyczne dla User Experience (UX):
- Brak danych offline: Bez internetu aplikacja jest bezużyteczna.
- Opóźnienia (Latency): Nawet przy dobrym zasięgu, każde wejście na ekran wymaga oczekiwania na odpowiedź serwera (ładowanie spinnera).
- Utrata danych: Jeśli użytkownik wypełni formularz i kliknie Wyślij w momencie utraty zasięgu, dane przepadają.
Paradygmat Offline-First odwraca tę logikę. Zakłada on, że brak dostępu do Internetu nie jest błędem, lecz normalnym stanem pracy aplikacji. W tym modelu aplikacja działa zawsze, niezależnie od sieci. Wyświetla dane, które pobrała wcześniej (cache), a Internet służy jedynie do synchronizacji (aktualizacji) tych danych w tle.
Główne założenia:
- Aplikacja uruchamia się i pokazuje treść natychmiast (korzystając z lokalnej bazy danych).
- Jeśli sieć jest dostępna, pobieramy nowsze dane i aktualizujemy bazę.
- Jeśli sieć jest niedostępna, użytkownik nadal może przeglądać stare dane, a nawet modyfikować stan (np. dodawać do ulubionych) - zmiany te zostaną wysłane, gdy połączenie wróci.
Aby zrealizować ten cel, musimy gruntownie przebudować architekturę naszych Repozytoriów, implementując wzorzec Single Source of Truth (SSoT).
Wzorzec Single Source of Truth (SSoT)
Wzorzec Single Source of Truth (SSoT) (Pojedyncze Źródło Prawdy) to fundament nowoczesnych aplikacji mobilnych. Interfejs użytkownika (UI) oraz ViewModel nigdy nie powinny komunikować się bezpośrednio z siecią (API). Jedynym zaufanym źródłem danych dla widoku jest lokalna baza danych.
Oznacza to, że nawet jeśli mamy świetne połączenie z Internetem, dane najpierw trafiają do bazy (Room), a dopiero stamtąd są wyświetlane na ekranie. W tym podejściu przepływ danych przestaje być liniowy (Pobierz -> Wyświetl). Dzieli się on na dwa niezależne procesy:
- Ścieżka Odczytu (Read Path):
- Odpowiedzialność: Dostarczanie danych do UI.
- Kierunek:
Room -> Repository -> ViewModel -> UI. - Mechanizm: Reaktywność (
Flow). ViewModel subskrybuje zmiany w tabeli. Gdy tylko coś zmieni się w bazie, UI odświeża się automatycznie. - Ścieżka Synchronizacji (Write Path):
- Odpowiedzialność: Aktualizacja danych w bazie.
- Kierunek:
Retrofit -> Repository -> Room. - Mechanizm: Funkcje zawieszające (
suspend). Repozytorium pobiera JSON z sieci, mapuje go na Encje i zapisuje w bazie.
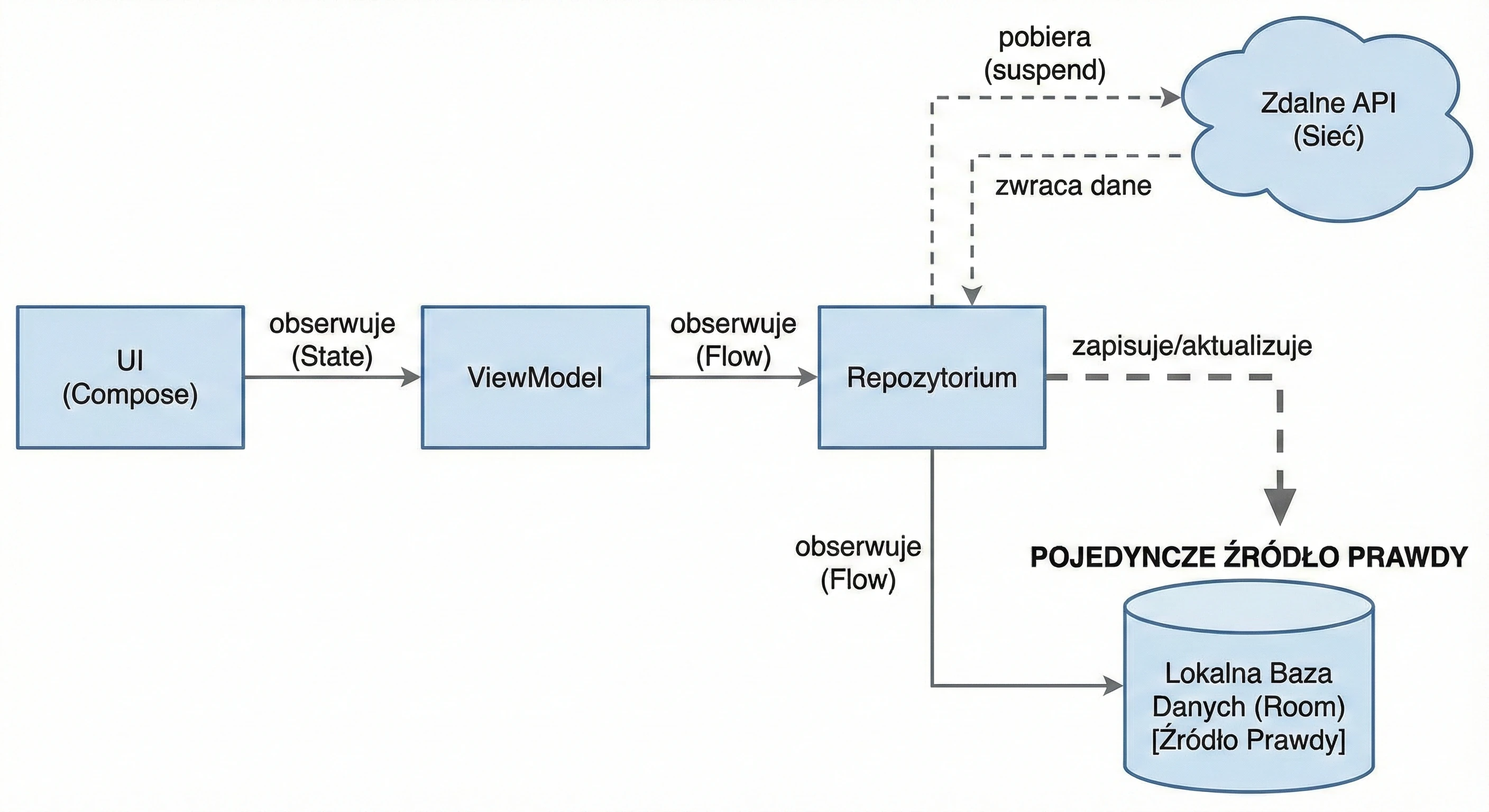
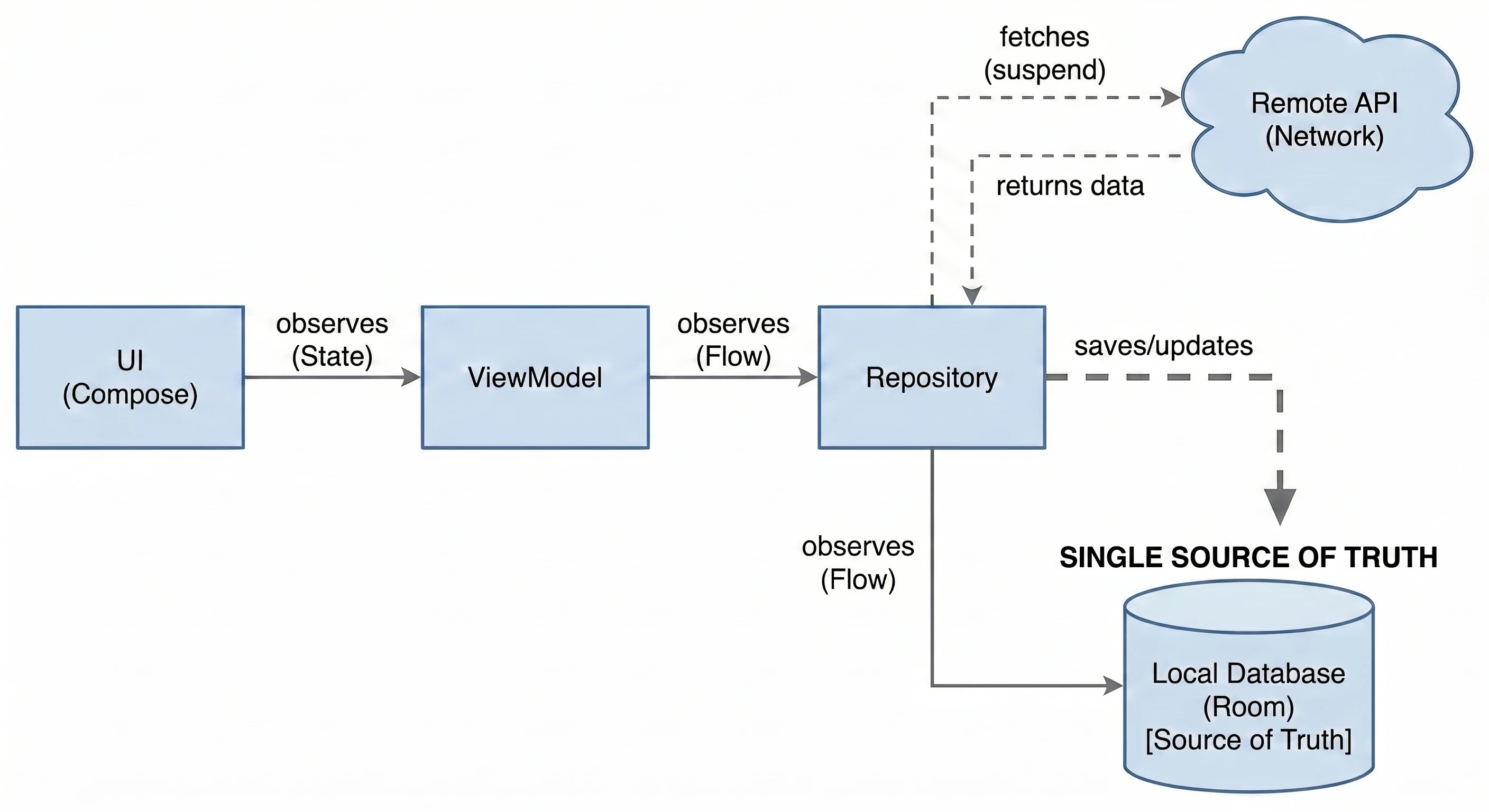
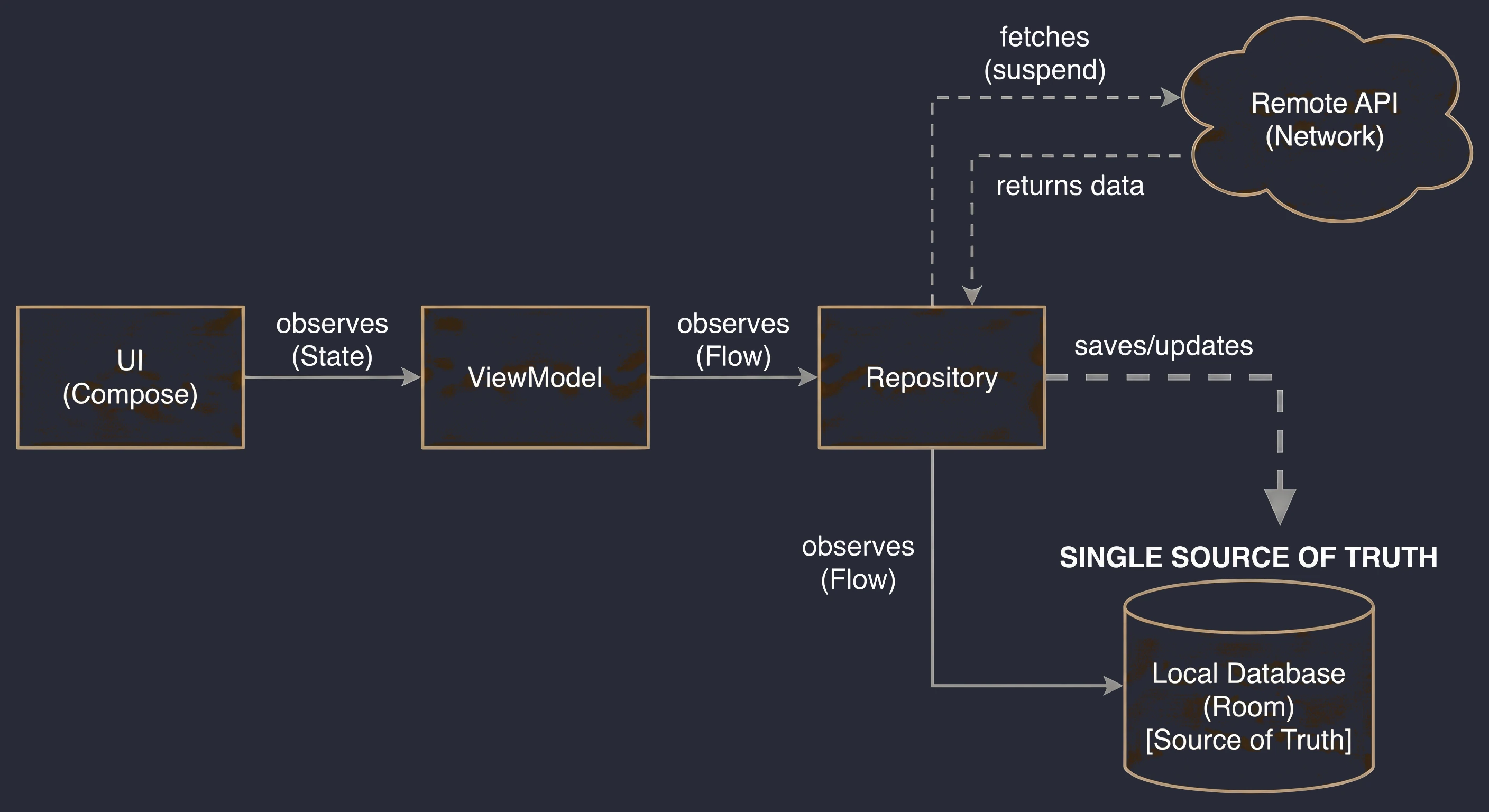
Zobaczmy, jak zmienia się interfejs naszego repozytorium:
// Rozdzielamy obserwację od odświeżania
class UserRepository(
private val api: UserApi,
private val dao: UserDao
) {
// 1. Ścieżka Odczytu: Zwraca Flow z bazy danych.
// Działa zawsze, nawet bez internetu (zwraca puste dane lub stare dane).
fun getUsersStream(): Flow<List<UserEntity>> {
return dao.getAllUsers()
}
// 2. Ścieżka Synchronizacji: Pobiera z sieci i zapisuje do bazy.
// Nie zwraca danych! Zwraca Unit lub błąd sieci.
suspend fun refreshUsers() {
val remoteUsers = api.getUsers()
// Logika zapisu do bazy (np. usuń stare, wstaw nowe)
dao.replaceUsers(remoteUsers.map { it.toEntity() })
}
}Metoda refreshUsers() nie zwraca listy użytkowników. Jej zadaniem jest jedynie aktualizacja bazy danych. Gdy baza zostanie zaktualizowana, Room automatycznie wyemituje nową listę w strumieniu getUsersStream(), co spowoduje odświeżenie ekranu.
Podstawowy Caching
Najprostszym sposobem na zsynchronizowanie lokalnej bazy danych z serwerem jest potraktowanie bazy jako tymczasowego lustra (cache). Przy każdym odświeżeniu usuwamy starą zawartość tabeli i wstawiamy nową, pobraną z API.
Algorytm metody refresh():
- Pobierz listę obiektów z API.
- Otwórz transakcję bazy danych.
- Usuń wszystkie rekordy z tabeli (
DELETE FROM ...). - Wstaw nowe rekordy pobrane w kroku 1.
Dlaczego usuwamy wszystko? Ponieważ na serwerze mogły zostać usunięte pewne elementy. Jeśli byśmy tylko używali Insert (OnConflict = REPLACE), usunięte elementy wisiałyby w naszej lokalnej bazie w nieskończoność.
W Room operacja Wyczyść i Wstaw powinna być atomowa (wykonana w jednej transakcji), aby użytkownik nie zobaczył przez ułamek sekundy pustego ekranu między usunięciem a wstawieniem.
// data/local/UserDao.kt
@Dao
interface UserDao {
// 1. Ścieżka Odczytu (zawsze zwraca najnowszy stan tabeli)
@Query("SELECT * FROM users")
fun getAllUsers(): Flow<List<UserEntity>>
// Operacje pomocnicze dla Ścieżki Zapisu
@Insert(onConflict = OnConflictStrategy.REPLACE)
suspend fun insertAll(users: List<UserEntity>)
@Query("DELETE FROM users")
suspend fun clearAll()
// Transakcja: Gwarantuje, że usunięcie i wstawienie
// zdarzy się "jednocześnie" dla obserwatorów Flow.
@Transaction
suspend fun replaceUsers(users: List<UserEntity>) {
clearAll()
insertAll(users)
}
}Repozytorium łączy API z DAO. Tutaj mapujemy też obiekty sieciowe (DTO) na obiekty bazy danych (Entity).
// data/UserRepository.kt
class UserRepository @Inject constructor(
private val api: UserApi,
private val dao: UserDao
) {
// Ścieżka Odczytu - po prostu przekazujemy Flow
val users: Flow<List<UserEntity>> = dao.getAllUsers()
// Ścieżka Zapisu
suspend fun refreshUsers() {
try {
// 1. Pobierz z sieci
val remoteUsers = api.getUsers()
// 2. Zmapuj na encje
val entities = remoteUsers.map { dto ->
UserEntity(
id = dto.id,
name = dto.name,
email = dto.email
// Uwaga: Nie mapujemy pól lokalnych (np. isFavorite),
// bo API ich nie zwraca!
)
}
// 3. Zaktualizuj bazę (Source of Truth)
dao.replaceUsers(entities)
} catch (e: Exception) {
// Błąd sieci? Trudno.
// Nie rzucamy wyjątku wyżej (chyba że chcemy pokazać Snackbar).
// Dzięki temu UI nadal wyświetla stare dane z 'users' Flow.
throw e
}
}
}ViewModel uruchamia odświeżanie przy starcie, ale dane pobiera ze strumienia.
@HiltViewModel
class UserViewModel @Inject constructor(
private val repository: UserRepository
) : ViewModel() {
// UI obserwuje to pole. Będzie ono zawierać dane z bazy.
// Dzięki stateIn, Flow zamienia się w StateFlow (Hot Stream).
val uiState = repository.users
.stateIn(viewModelScope, SharingStarted.WhileSubscribed(5000), emptyList())
init {
refreshData()
}
fun refreshData() {
viewModelScope.launch {
try {
repository.refreshUsers()
} catch (e: Exception) {
// Tu obsłuż błąd, np. wyślij zdarzenie "Brak sieci" do UI.
// Ale lista użytkowników NIE zniknie z ekranu!
}
}
}
}Powyższa strategia jest świetna dla danych tylko do odczytu (np. lista wiadomości). Ma jednak jedną krytyczną wadę.
Wyobraźmy sobie, że dodajemy do encji pole isFavorite: Boolean, które użytkownik zmienia klikając serduszko w aplikacji.
- Użytkownik klika Ulubione przy użytkowniku Jan Kowalski. W bazie
isFavoritezmienia się natrue. - Następuje odświeżenie danych z sieci (metoda
refreshUsers). - Metoda
clearAll()usuwa wszystkich użytkowników (wraz z informacją o ulubionych). - Metoda
insertAll()wstawia świeże dane z serwera. Serwer nie wie nic o ulubionych, więc pole to przyjmuje wartość domyślną (false).
Efekt: Odświeżenie danych resetuje stan lokalny aplikacji. Aby temu zapobiec, musimy zastosować bardziej zaawansowane podejście.
Zaawansowany Caching
Aby rozwiązać problem znikających serduszek przy odświeżaniu danych, musimy fizycznie odseparować dane pochodzące z serwera od danych generowanych przez użytkownika. Zastosujemy architekturę opartą na dwóch tabelach:
- Tabela Cache (np.
movies_cache): Zawiera surowe dane z API (tytuł, opis, plakat). Ta tabela jest tymczasowa - strategiarefresh()może ją do woli czyścić i nadpisywać. - Tabela Stanu (np.
favorite_ids): Zawiera tylko identyfikatory elementów oznaczonych przez użytkownika. Ta tabela jest trwała - proces synchronizacji z siecią nigdy jej nie modyfikuje.
Ostateczny obiekt domenowy (Movie), który trafi do UI, powstanie w wyniku połączenia tych dwóch tabel w czasie rzeczywistym. Potrzebujemy dwóch osobnych encji w bazie danych Room.
// data/local/MovieCacheEntity.kt
@Entity(tableName = "movies_cache")
data class MovieCacheEntity(
@PrimaryKey val id: Int,
val title: String,
val overview: String
// Tu NIE MA pola isFavorite!
)
// data/local/FavoriteIdEntity.kt
@Entity(tableName = "favorite_ids")
data class FavoriteIdEntity(
@PrimaryKey val id: Int
// Ta tabela przechowuje tylko ID ulubionych filmów
)
// Model Domenowy (to, co widzi UI)
data class Movie(
val id: Int,
val title: String,
val overview: String,
val isFavorite: Boolean // To pole obliczymy dynamicznie
)Najważniejszą częścią jest zapytanie w DAO. Musimy pobrać wszystkie filmy z cache i dokleić do nich informację, czy ich ID znajduje się w tabeli ulubionych. Używamy do tego klauzuli LEFT JOIN.
// data/local/MovieDao.kt
@Dao
interface MovieDao {
// Ścieżka Odczytu: Łączymy dwie tabele
// (f.id IS NOT NULL) zwróci 1 (true) jeśli znaleziono ID w ulubionych,
// lub 0 (false) jeśli nie znaleziono.
@Query("""
SELECT
m.id,
m.title,
m.overview,
(f.id IS NOT NULL) as isFavorite
FROM movies_cache AS m
LEFT JOIN favorite_ids AS f ON m.id = f.id
""")
fun getMoviesStream(): Flow<List<Movie>>
// Operacje na Cache (Sieć)
@Query("DELETE FROM movies_cache")
suspend fun clearCache()
@Insert(onConflict = OnConflictStrategy.REPLACE)
suspend fun insertCache(movies: List<MovieCacheEntity>)
@Transaction
suspend fun refreshCache(movies: List<MovieCacheEntity>) {
clearCache()
insertCache(movies)
}
// Operacje na Ulubionych (Użytkownik)
@Insert(onConflict = OnConflictStrategy.IGNORE)
suspend fun addFavorite(id: FavoriteIdEntity)
@Query("DELETE FROM favorite_ids WHERE id = :id")
suspend fun removeFavorite(id: Int)
}Prześledźmy ten sam scenariusz co w poprzedniej sekcji:
- Użytkownik klika serduszko przy filmie o ID=5.
- Aplikacja dodaje rekord
FavoriteIdEntity(5)do tabelifavorite_ids. - Room automatycznie przelicza zapytanie
LEFT JOIN. Dla filmu ID=5 warunekf.id IS NOT NULLstaje się prawdą. UI odświeża się, pokazując czerwone serce. - Następuje odświeżenie z sieci.
- Metoda
refreshCache()czyści tabelęmovies_cachei wstawia nowe dane. - Tabela
favorite_idsnie jest ruszana. - Room ponownie przelicza
LEFT JOIN. Nowy rekord filmu z cache łączy się z istniejącym rekordem w ulubionych. - UI odświeża się z nowymi opisami filmów, ale serduszko przy ID=5 pozostaje na miejscu.
To podejście jest odporne na błędy i stanowi podstawę aplikacji Offline-First. W tym modelu, jeśli serwer przestanie zwracać film o ID=5 (zostanie on usunięty z oferty), zniknie on również z listy w aplikacji (bo FROM movies_cache go nie zwróci), nawet jeśli jego ID wciąż jest w tabeli ulubionych. Jest to zazwyczaj pożądane zachowanie (tzw. Orphaned Record w ulubionych nie przeszkadza).
Współbieżność (Race Conditions)
Mamy system, który działa poprawnie w 99% przypadków. Jednak w specyficznych warunkach (np. wolna sieć + niecierpliwy użytkownik) może dojść do uszkodzenia danych. Rozważmy następujący scenariusz wyścigu (Race Condition):
- Aplikacja rozpoczyna pobieranie danych z sieci (trwa to 2 sekundy).
- W międzyczasie użytkownik klika Dodaj do ulubionych przy filmie X.
- Aplikacja zapisuje ID filmu X do tabeli
favorite_ids. - Pobieranie z sieci kończy się sukcesem.
- Aplikacja czyści tabelę
movies_cachei wstawia nowe dane.
W powyższym scenariuszu wszystko jest w porządku, ponieważ tabele są rozłączne. Ale co się stanie, jeśli logika biznesowa będzie bardziej złożona?
Załóżmy, że zamiast osobnej tabeli, trzymamy liczbę polubień bezpośrednio w tabeli z filmami (bo API zwraca globalną liczbę lajków, a my chcemy ją lokalnie inkrementować).
// Scenariusz Błędu:
// 1. Użytkownik klika \textit{Like} (Lokalnie: likes = 10 + 1 = 11)
// 2. Repozytorium pobiera dane z sieci (Serwer: likes = 10)
// 3. Repozytorium nadpisuje lokalne zmiany danymi z serwera (likes = 10)W efekcie lajk użytkownika zostaje połknięty przez odświeżenie danych. Nawet przy dwóch tabelach istnieje ryzyko niespójności, jeśli operacje nie są atomowe.
suspend fun toggleFavorite(id: Int) {
// 1. Sprawdź czy jest w ulubionych
val isFavorite = dao.isFavorite(id)
// <--- W tym momencie następuje przełączenie wątku (context switch)
// <--- Inny proces usuwa ten film z bazy
// 2. Jeśli był, to usuń. Jeśli nie, to dodaj.
if (isFavorite) dao.remove(id) else dao.add(id)
}Aby zabezpieczyć się przed takimi sytuacjami, musimy zsynchronizować dostęp do bazy danych, upewniając się, że w danym momencie tylko jedna operacja modyfikująca (Zapis z Sieci lub Zapis od Użytkownika) jest wykonywana.
Rozwiązanie 1: Mutex (Mutual Exclusion)
Aby zapobiec wyścigom (Race Conditions), musimy zagwarantować, że operacje zapisu do bazy danych będą wykonywane sekwencyjnie, a nie równolegle. W świecie Kotlin Coroutines służy do tego narzędzie o nazwie Mutex (od ang. Mutual Exclusion - Wzajemne Wykluczanie).
Działa ono jak zamek w drzwiach: tylko jedna osoba (korutyna) może być w środku (w sekcji krytycznej). Inne muszą czekać w kolejce, aż zamek zostanie zwolniony. Klasa Mutex pochodzi z biblioteki kotlinx.coroutines.sync. Używamy metody withLock { ... }, która automatycznie zamyka zamek na początku bloku i otwiera go na końcu (nawet jeśli wystąpi wyjątek). Zmodyfikujmy nasze repozytorium:
// data/MovieRepository.kt
class MovieRepository @Inject constructor(
private val api: MovieApi,
private val dao: MovieDao
) {
// Obiekt Mutex musi być polem klasy (współdzielony przez wszystkie wywołania)
private val mutex = Mutex()
// Operacja 1: Odświeżanie z sieci
suspend fun refreshMovies() {
// KROK A: Pobieranie z sieci (Długie!)
// Robimy to POZA blokadą. Nie chcemy blokować UI, gdy czekamy na serwer.
val remoteMovies = api.getMovies()
val entities = remoteMovies.map { it.toEntity() }
// KROK B: Zapis do bazy (Krótkie!)
// To jest nasza SEKCJA KRYTYCZNA.
mutex.withLock {
dao.refreshCache(entities)
}
}
// Operacja 2: Zmiana statusu ulubione
suspend fun toggleFavorite(movieId: Int) {
// Cała logika "sprawdź i zapisz" musi być atomowa.
mutex.withLock {
val isFavorite = dao.isFavorite(movieId)
if (isFavorite) {
dao.removeFavorite(movieId)
} else {
dao.addFavorite(FavoriteIdEntity(movieId))
}
}
}
}Wróćmy do scenariusza wyścigu:
- Wątek A (Refresh): Pobiera dane z sieci (trwa to 2 sekundy). Mutex jest otwarty.
- Wątek B (User): Klika Like. Wywołuje
toggleFavorite. - Wątek B: Wchodzi w
mutex.withLock. Zamyka zamek. Zapisuje ulubiony film do bazy. Otwiera zamek. - Wątek A: Kończy pobieranie. Próbuje wejść w
mutex.withLock. - Jeśli Wątek B jeszcze trzyma zamek, Wątek A zawiesza się (suspend) i czeka.
- Gdy Wątek B zwolni zamek, Wątek A wchodzi do sekcji krytycznej i bezpiecznie aktualizuje cache.
Dzięki temu, że operacja zapisu ulubionego filmu (addFavorite) i czyszczenia cache (refreshCache) nigdy nie dzieją się w tym samym czasie, baza danych pozostaje spójna.
Zwróćmy uwagę, że pobieranie danych z sieci (api.getMovies()) znajduje się przed blokiem mutex.withLock. Gdybyśmy objęli blokadą również zapytanie sieciowe, użytkownik nie mógłby kliknąć Lubię to przez cały czas trwania synchronizacji (aplikacja wydawałaby się zacięta). Blokujemy tylko dostęp do zasobu współdzielonego (Bazy Danych).
Zalety metody:
- Prostota implementacji.
- Czytelność kodu (widać gdzie jest sekcja krytyczna).
Wady metody:
- Ryzyko zakleszczenia (Deadlock), jeśli spróbujemy zagnieździć dwa Mutexy lub wejść w ten sam Mutex dwukrotnie w tym samym wątku (choć Mutex w Kotlinie nie jest reentrant).
- Przy bardzo dużej liczbie operacji, ciągłe blokowanie i odblokowywanie może stać się wąskim gardłem wydajności.
Rozwiązanie 2: Wzorzec Aktor (Actor Pattern)
Mutex rozwiązuje problem, ale działa na zasadzie twardej blokady. Jeśli odświeżanie trwa 5 sekund, a użytkownik kliknie Lubię to, operacja ta musi czekać w zawieszeniu.
Alternatywnym podejściem jest Wzorzec Aktor. Zamiast pozwalać wielu wątkom na bezpośredni dostęp do bazy danych (i kazać im czekać w kolejce), tworzymy jednego Aktora - dedykowaną korutynę, która jako jedyna ma prawo pisać do bazy. Reszta aplikacji nie modyfikuje danych bezpośrednio, lecz wysyła do Aktora wiadomości (Prośby/Akcje).
Repozytorium przestaje być tylko zbiorem metod. Staje się aktywnym komponentem, który posiada:
- Kanał (Channel): Skrzynka pocztowa, do której wpadają zlecenia (np. Odśwież, Polub).
- Pętlę Aktora: Nieskończona pętla wewnątrz
init, która pobiera komunikaty jeden po drugim i je przetwarza.
Dzięki temu operacje są naturalnie zsynchronizowane (Aktor robi tylko jedną rzecz naraz), ale wątek wysyłający wiadomość nie jest blokowany - wrzuca list do skrzynki i idzie dalej. Do implementacji użyjemy Channel (kanał) oraz Sealed Interface do zdefiniowania typów wiadomości.
// data/MovieRepository.kt
// 1. Definiujemy możliwe akcje (Intent)
sealed interface DataAction {
data object Refresh : DataAction
data class ToggleFavorite(val id: Int) : DataAction
}
@Singleton
class MovieRepository @Inject constructor(
private val api: MovieApi,
private val dao: MovieDao,
// Potrzebujemy Scope'a, aby uruchomić aktora, który żyje tak długo jak aplikacja
@ApplicationScope private val externalScope: CoroutineScope
) {
// 2. Kanał (Kolejka) o nielimitowanej pojemności
private val actionChannel = Channel<DataAction>(Channel.UNLIMITED)
// Ścieżka Odczytu (bez zmian)
val movies: Flow<List<Movie>> = dao.getMoviesStream()
init {
// 3. Uruchomienie Aktora (Loop)
externalScope.launch {
// consumeEach przetwarza komunikaty sekwencyjnie (FIFO)
actionChannel.consumeEach { action ->
processAction(action)
}
}
}
// Logika przetwarzania (prywatna, dostępna tylko dla Aktora)
private suspend fun processAction(action: DataAction) {
when (action) {
is DataAction.Refresh -> {
try {
val remoteMovies = api.getMovies() // To może trwać długo
dao.refreshCache(remoteMovies.map { it.toEntity() })
} catch (e: Exception) {
// Log error
}
}
is DataAction.ToggleFavorite -> {
val isFavorite = dao.isFavorite(action.id)
if (isFavorite) dao.removeFavorite(action.id)
else dao.addFavorite(FavoriteIdEntity(action.id))
}
}
}
// 4. Publiczne API (Fire and Forget)
// Metody nie są już 'suspend', bo wrzucenie do kanału jest szybkie.
fun refresh() {
actionChannel.trySend(DataAction.Refresh)
}
fun toggleFavorite(id: Int) {
actionChannel.trySend(DataAction.ToggleFavorite(id))
}
}Wróćmy do naszego scenariusza wyścigu:
- UI wywołuje
refresh()-> AkcjaRefreshwpada do kanału. - Aktor wyjmuje
Refreshi zaczyna pobierać dane z sieci. - W międzyczasie UI wywołuje
toggleFavorite(5)-> AkcjaTogglewpada do kanału i czeka. - Aktor kończy pobieranie i zapisuje dane cache.
- Aktor kończy przetwarzanie
Refresh. Pętla wraca na początek. - Aktor wyjmuje z kanału czekające
ToggleFavorite(5). - Aktor aktualizuje tabelę ulubionych.
Mimo że akcja użytkownika musiała poczekać na przetworzenie, została ona zakolejkowana i wykonana poprawnie po zakończeniu synchronizacji. Żadne dane nie zostały utracone.
Zalety metody:
- Brak klasycznego blokowania (deadlocks są niemożliwe).
- Gwarancja kolejności wykonywania operacji (FIFO).
- UI nie czeka na wykonanie operacji zapisu (Fire and Forget).
Wady metody:
- Brak natychmiastowej informacji zwrotnej (metoda
toggleFavoritezwracavoid). UI musi polegać na obserwacjiFlowz bazy danych, aby dowiedzieć się, czy operacja się udała. Jest to zgodne z filozofią SSoT, ale wymaga zmiany myślenia programisty.
Kompletny przykład: Czysta Architektura i Actor Pattern
Poniżej znajduje się kompletny kod źródłowy modułu, który łączy architekturę Offline-First z pełnym podziałem na warstwy (Clean Architecture).
W tym podejściu ViewModel nie rozmawia bezpośrednio z Repozytorium. Pośrednikiem są Przypadki Użycia (Use Cases), które enkapsulują logikę biznesową.
Warstwa Domeny (Domain Layer)
Jest to warstwa niezależna od frameworków Androida. Definiuje modele, interfejsy oraz logikę biznesową.
Model Domenowy:
// Plik: domain/model/Movie.kt
package com.example.movieapp.domain.model
data class Movie(
val id: Int,
val title: String,
val overview: String,
val rating: Double,
val isFavorite: Boolean
)Interfejs Repozytorium (Kontrakt):
// Plik: domain/repository/MovieRepository.kt
package com.example.movieapp.domain.repository
interface MovieRepository {
// Strumień danych (zawsze aktualny)
fun getMoviesStream(): Flow<List<Movie>>
// Akcje (Fire-and-forget lub suspend)
suspend fun refresh()
suspend fun toggleFavorite(id: Int)
}Przypadki Użycia (Use Cases): Każda klasa realizuje jedno zadanie biznesowe.
// Plik: domain/usecase/GetMoviesUseCase.kt
package com.example.movieapp.domain.usecase
class GetMoviesUseCase @Inject constructor(
private val repository: MovieRepository
) {
operator fun invoke(): Flow<List<Movie>> {
return repository.getMoviesStream()
}
}
// Plik: domain/usecase/RefreshMoviesUseCase.kt
package com.example.movieapp.domain.usecase
class RefreshMoviesUseCase @Inject constructor(
private val repository: MovieRepository
) {
suspend operator fun invoke() {
repository.refresh()
}
}
// Plik: domain/usecase/ToggleFavoriteUseCase.kt
package com.example.movieapp.domain.usecase
class ToggleFavoriteUseCase @Inject constructor(
private val repository: MovieRepository
) {
suspend operator fun invoke(id: Int) {
repository.toggleFavorite(id)
}
}Warstwa Danych (Data Layer)
Implementacja dostępu do danych. Tutaj znajduje się logika Room, Retrofit oraz Aktor.
Encje Bazy Danych:
// Plik: data/local/MovieEntities.kt
package com.example.movieapp.data.local
@Entity(tableName = "movies_cache")
data class MovieCacheEntity(
@PrimaryKey val id: Int,
val title: String,
val overview: String,
val voteAverage: Double
)
@Entity(tableName = "favorite_ids")
data class FavoriteIdEntity(
@PrimaryKey val id: Int
)DAO (Data Access Object):
// Plik: data/local/MovieDao.kt
package com.example.movieapp.data.local
@Dao
interface MovieDao {
// SSoT: Łączenie danych z dwóch tabel
@Query("""
SELECT
m.id, m.title, m.overview, m.voteAverage as rating,
(f.id IS NOT NULL) as isFavorite
FROM movies_cache AS m
LEFT JOIN favorite_ids AS f ON m.id = f.id
""")
fun getMoviesStream(): Flow<List<Movie>>
// Operacje atomowe dla Aktora
@Transaction
suspend fun refreshCache(movies: List<MovieCacheEntity>) {
clearCache()
insertCache(movies)
}
@Query("DELETE FROM movies_cache")
suspend fun clearCache()
@Insert(onConflict = OnConflictStrategy.REPLACE)
suspend fun insertCache(movies: List<MovieCacheEntity>)
// Ulubione
@Insert(onConflict = OnConflictStrategy.IGNORE)
suspend fun addFavorite(entity: FavoriteIdEntity)
@Query("DELETE FROM favorite_ids WHERE id = :id")
suspend fun removeFavorite(id: Int)
@Query("SELECT EXISTS(SELECT 1 FROM favorite_ids WHERE id = :id)")
suspend fun isFavorite(id: Int): Boolean
}API (Retrofit):
// Plik: data/remote/TmdbApi.kt
package com.example.movieapp.data.remote
data class TmdbResponse(@SerializedName("results") val results: List<MovieDto>)
data class MovieDto(
val id: Int,
val title: String,
val overview: String,
@SerializedName("vote_average") val voteAverage: Double
)
interface TmdbApi {
@GET("movie/popular")
suspend fun getPopularMovies(
@Query("api_key") apiKey: String,
@Query("language") language: String = "pl-PL"
): TmdbResponse
}Repozytorium (Implementacja Aktora): Klasa ta implementuje interfejs z domeny. Używa kanału do synchronizacji.
// Plik: data/repository/MovieRepositoryImpl.kt
package com.example.movieapp.data.repository
// Wewnętrzne wiadomości aktora
private sealed interface RepoAction {
data object Refresh : RepoAction
data class ToggleFavorite(val id: Int) : RepoAction
}
@Singleton
class MovieRepositoryImpl @Inject constructor(
private val api: TmdbApi,
private val dao: MovieDao,
private val externalScope: CoroutineScope, // Application Scope
private val apiKey: String
) : MovieRepository {
private val actorChannel = Channel<RepoAction>(Channel.UNLIMITED)
override fun getMoviesStream(): Flow<List<Movie>> = dao.getMoviesStream()
init {
// Uruchomienie pętli przetwarzania
externalScope.launch {
actorChannel.consumeEach { action ->
processAction(action)
}
}
}
private suspend fun processAction(action: RepoAction) {
when (action) {
is RepoAction.Refresh -> {
try {
val response = api.getPopularMovies(apiKey)
val entities = response.results.map { dto ->
MovieCacheEntity(dto.id, dto.title, dto.overview, dto.voteAverage)
}
dao.refreshCache(entities)
} catch (e: Exception) { /* Ignoruj błąd sieci */ }
}
is RepoAction.ToggleFavorite -> {
val isFav = dao.isFavorite(action.id)
if (isFav) dao.removeFavorite(action.id)
else dao.addFavorite(FavoriteIdEntity(action.id))
}
}
}
// Metody interfejsu wrzucają zadania do kolejki
override suspend fun refresh() {
actorChannel.send(RepoAction.Refresh)
}
override suspend fun toggleFavorite(id: Int) {
actorChannel.send(RepoAction.ToggleFavorite(id))
}
}Dependency Injection (Hilt)
Moduł spinający implementację Repozytorium z jego interfejsem.
// Plik: di/AppModule.kt
package com.example.movieapp.di
@Module
@InstallIn(SingletonComponent::class)
object AppModule {
@Provides
@Singleton
fun provideDatabase(@ApplicationContext context: Context): MoviesDatabase {
return Room.databaseBuilder(context, MoviesDatabase::class.java, "app.db").build()
}
@Provides
fun provideDao(db: MoviesDatabase): MovieDao = db.movieDao()
@Provides
@Singleton
fun provideApi(): TmdbApi {
return Retrofit.Builder()
.baseUrl("https://api.themoviedb.org/3/")
.addConverterFactory(GsonConverterFactory.create())
.build()
.create(TmdbApi::class.java)
}
@Provides
@Singleton
fun provideAppScope(): CoroutineScope =
CoroutineScope(SupervisorJob() + Dispatchers.Default)
@Provides
fun provideApiKey(): String = "YOUR_API_KEY"
// Wstrzyknięcie Implementacji jako Interfejsu Domenowego
@Provides
@Singleton
fun provideMovieRepository(
impl: MovieRepositoryImpl
): MovieRepository = impl
}Powyższa definicja provideAppScope wymaga komentarza. Wstrzykiwanie CoroutineScope powiązanego z procesem aplikacji (a nie z ekranem) jest krytyczne dla wzorca Offline-First z dwóch powodów:
- Niezależność od cyklu życia UI (Fire-and-Forget):
- Izolacja błędów (SupervisorJob):
Standardowy viewModelScope jest anulowany w momencie wyjścia użytkownika z ekranu lub rotacji urządzenia. Gdybyśmy użyli go do uruchomienia operacji zapisu (np. toggleFavorite), a użytkownik zamknąłby aplikację w trakcie trwania tej operacji, proces zapisu zostałby przerwany w połowie. Mogłoby to doprowadzić do niespójności danych. externalScope gwarantuje, że rozpoczęta operacja zostanie dokończona w tle, nawet jeśli interfejs użytkownika już nie istnieje.
Domyślny Job w korutynach działa na zasadzie odpowiedzialności zbiorowej - jeśli jedna korutyna w zakresie rzuci wyjątek, cały zakres jest anulowany (fail-fast). Dla Aktora obsługującego wiele niezależnych zadań jest to zachowanie niepożądane (błąd synchronizacji sieci nie powinien blokować możliwości dodawania filmów do ulubionych). Użycie SupervisorJob sprawia, że awaria jednej korutyny nie wpływa na pozostałe ani na sam zakres, co zapewnia stabilność pętli przetwarzającej komunikaty Aktora.
Linia kodu:
CoroutineScope(SupervisorJob() + Dispatchers.Default)składa się z trzech istotnych elementów, które razem tworzą bezpieczne środowisko dla operacji w tle. Pierwszy został omówiony powyżej, przyjrzyjmy się pozostałmy dwóm:
Dispatchers.Default:- Operator
+:
Definiuje domyślną pulę wątków dla tego zakresu. Default jest zoptymalizowany pod kątem operacji obciążających procesor (CPU-intensive), co jest dobrym punktem wyjścia dla ogólnej logiki biznesowej (np. przetwarzania logiki Aktora). Należy pamiętać, że operacje wejścia/wyjścia (I/O), takie jak zapytania do Room czy Retrofita, i tak powinny wewnętrznie przełączać się na Dispatchers.IO.
W Kotlinie CoroutineContext działa jak mapa (zbiór elementów). Operator plus służy do łączenia tych elementów. W tym przypadku tworzymy kontekst, który posiada zarówno specyficzne zachowanie błędów (SupervisorJob), jak i specyficzną strategię wątkowania (Dispatchers.Default).
Podsumowując: Tworzymy przestrzeń życiową dla wątków, która jest odporna na pojedyncze awarie i działa na wydajnej puli wątków w tle.
Warstwa Prezentacji (ViewModel)
ViewModel korzysta wyłącznie z Use Caseów. Nie ma dostępu do Repozytorium ani Bazy Danych.
// Plik: presentation/MoviesViewModel.kt
package com.example.movieapp.presentation
@HiltViewModel
class MoviesViewModel @Inject constructor(
getMoviesUseCase: GetMoviesUseCase,
private val refreshMoviesUseCase: RefreshMoviesUseCase,
private val toggleFavoriteUseCase: ToggleFavoriteUseCase
) : ViewModel() {
// Konwersja Flow na StateFlow (UI State)
val uiState: StateFlow<List<Movie>> = getMoviesUseCase()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = emptyList()
)
init {
// Pobranie danych przy starcie
viewModelScope.launch {
refreshMoviesUseCase()
}
}
fun onFavoriteClick(movie: Movie) {
viewModelScope.launch {
toggleFavoriteUseCase(movie.id)
}
}
fun onSwipeRefresh() {
viewModelScope.launch {
refreshMoviesUseCase()
}
}
}Konfiguracja Aplikacji (Hilt & Manifest)
Aby wstrzykiwanie zależności zadziałało, musimy utworzyć klasę dziedziczącą po Application i opatrzyć ją adnotacją @HiltAndroidApp. To tutaj Hilt generuje graf zależności.
// Plik: MovieApplication.kt
package com.example.movieapp
@HiltAndroidApp
class MovieApplication : Application()Nie zapomnij zarejestrować tej klasy w pliku AndroidManifest.xml. Bez tego aplikacja wyrzuci błąd przy starcie.
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.movieapp">
<uses-permission android:name="android.permission.INTERNET" />
<application
android:name=".MovieApplication"
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:theme="@style/Theme.MovieApp">
<activity
android:name=".presentation.MainActivity"
android:exported="true">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>Warstwa Widoku (UI - Jetpack Compose)
Ostatnim elementem jest MainActivity, która pełni rolę punktu wejścia (@AndroidEntryPoint). Interfejs użytkownika budujemy w oparciu o Jetpack Compose, obserwując StateFlow z ViewModelu. Widok jest całkowicie pasywny - jedynie wyświetla stan i przekazuje zdarzenia (kliknięcia) do ViewModelu.
// Plik: presentation/MainActivity.kt
package com.example.movieapp.presentation
@AndroidEntryPoint
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
MaterialTheme {
MoviesScreen()
}
}
}
}
@OptIn(ExperimentalMaterial3Api::class)
@Composable
fun MoviesScreen(
viewModel: MoviesViewModel = hiltViewModel()
) {
// Obserwacja stanu UI (zamiana Flow na State)
val movies by viewModel.uiState.collectAsState()
Scaffold(
topBar = {
TopAppBar(
title = { Text("Filmy Offline-First") },
actions = {
IconButton(onClick = { viewModel.onSwipeRefresh() }) {
Icon(Icons.Default.Refresh, contentDescription = "Odśwież")
}
}
)
}
) { padding ->
LazyColumn(
contentPadding = padding,
modifier = Modifier.fillMaxSize()
) {
items(movies, key = { it.id }) { movie ->
MovieItem(
movie = movie,
onFavoriteClick = { viewModel.onFavoriteClick(movie) }
)
}
}
}
}
@Composable
fun MovieItem(
movie: Movie,
onFavoriteClick: () -> Unit
) {
ListItem(
headlineContent = { Text(movie.title) },
supportingContent = {
Text(
text = movie.overview,
maxLines = 2,
)
},
trailingContent = {
IconButton(onClick = onFavoriteClick) {
// Ikona zmienia się w zależności od pola isFavorite (SSoT)
Icon(
imageVector = if (movie.isFavorite) Icons.Default.Favorite
else Icons.Default.FavoriteBorder,
contentDescription = null,
tint = if (movie.isFavorite) Color.Red else Color.Gray
)
}
},
leadingContent = {
Surface(
color = MaterialTheme.colorScheme.primaryContainer,
shape = MaterialTheme.shapes.small,
modifier = Modifier.size(40.dp)
) {
Box(contentAlignment = Alignment.Center) {
Text(
text = movie.rating.toString(),
)
}
}
},
modifier = Modifier.clickable { /* Otwórz szczegóły */ }
)
Divider()
}Architektura Serverless i Model NoSQL
W poprzednich rozdziałach budowaliśmy aplikacje w oparciu o architekturę, w której my byliśmy odpowiedzialni za lokalną bazę danych (Room), i korzystaliśmy z gotowych API (REST/Retrofit). W tym rozdziale zmieniamy podejście. Skorzystamy z modelu Backend-as-a-Service (BaaS), w którym infrastruktura serwerowa jest dostarczana przez platformę zewnętrzną - w tym przypadku Firebase.
Backend-as-a-Service (BaaS)
Tradycyjne tworzenie backendu wymaga postawienia serwera (np. w Ktor lub Spring Boot), konfiguracji bazy danych (np. PostgreSQL) oraz zarządzania hostingiem (np. AWS lub Google Cloud).
Firebase (platforma Google) zdejmuje z nas ten ciężar, oferując gotowe moduły:
- Firestore: Baza danych w chmurze.
- Authentication: Gotowy system logowania (Google, Facebook, Email).
- Cloud Functions: Logika biznesowa uruchamiana w odpowiedzi na zdarzenia (architektura Serverless).
- Storage: Miejsce na pliki (zdjęcia, wideo).
Dzięki temu programista może stworzyć w pełni funkcjonalny system (od bazy danych po logowanie) bez pisania ani jednej linijki kodu serwerowego.
SQL (Room) vs NoSQL (Firestore)
Najważniejszą zmianą dla programisty jest przejście z relacyjnej bazy danych (SQL) na bazę dokumentową (NoSQL). SQL działa na zasadzie tabel i sztywnych relacji. Musimy z góry zdefiniować schemat (Schema). Jeśli chcemy dodać nowe pole do tabeli, musimy przeprowadzić migrację bazy danych.
Cloud Firestore jest bazą nierelacyjną. Nie ma tu tabel ani wierszy. Zamiast tego mamy:
- Kolekcje (Collections): Kontenery na dokumenty (odpowiednik tabeli, np.
users). - Dokumenty (Documents): Obiekty JSON przechowywane w kolekcji (odpowiednik wiersza).
- Pola (Fields): Pary klucz-wartość wewnątrz dokumentu.
Tabela 14.1 przedstawia mapowanie pojęć między tymi dwoma światami.
| SQL (Room) | NoSQL (Firestore) |
|---|---|
| Tabela (Table) | Kolekcja (Collection) |
| Wiersz (Row) | Dokument (Document) |
| Kolumna (Column) | Pole (Field) |
| Klucz obcy (Foreign Key) | Referencja (Reference) |
| Relacja (Join) | Zazwyczaj brak (Denormalizacja) |
Kluczowa różnica: W Firestore dokumenty mogą mieć różną strukturę w obrębie tej samej kolekcji (schemat jest elastyczny), a zamiast łączyć tabele (JOIN), często duplikujemy dane (denormalizacja), aby przyspieszyć odczyt.
Konfiguracja środowiska (Firebase Setup)
Integracja aplikacji z Firebase różni się od dodania zwykłej biblioteki. Wymaga ona dwustronnej konfiguracji: utworzenia projektu w konsoli chmurowej oraz przedstawienia naszej aplikacji serwerom Google za pomocą unikalnego identyfikatora i pliku konfiguracyjnego.
Pierwszym krokiem jest utworzenie logicznego kontenera na nasze dane w chmurze.
- Przejdź do strony https://console.firebase.google.com/ i zaloguj się kontem Google.
- Kliknij "Add project". Nadaj mu nazwę (np. MovieApp-Cloud) i wyłącz Google Analytics (nie jest potrzebne w tym ćwiczeniu).
- Po utworzeniu projektu, na ekranie głównym kliknij ikonę Androida (Get started by adding Firebase to your app).
Podczas rejestracji aplikacji zostaniesz poproszony o Android package name. Musi on być identyczny z tym w pliku build.gradle twojej aplikacji (np. com.example.movieapp).
| Pole | Opis |
|---|---|
| Package name | Musi dokładnie pasować do applicationId w app/build.gradle.kts. |
| App nickname | Nazwa wyświetlana tylko w konsoli (opcjonalne). |
| SHA-1 | Odcisk cyfrowy klucza, którym podpisana jest aplikacja. Wymagany do logowania przez Google (Auth) i Dynamic Links. Do samego Firestore jest opcjonalny, ale warto go dodać. |
Po zarejestrowaniu aplikacji konsola wygeneruje plik google-services.json. Jest to dowód tożsamości Twojej aplikacji. Zawiera on klucze API, adres URL bazy danych i identyfikatory projektu.
- Pobierz plik
google-services.jsonna dysk. - W Android Studio przełącz widok projektu z Android na "Project" (lewy górny róg panelu plików).
- Przeciągnij plik do katalogu
app/(obok plikubuild.gradlemodułu).
Uwaga dotycząca bezpieczeństwa: Plik ten zawiera klucze API, które teoretycznie są publiczne (zaszyte w aplikacji), ale dobre praktyki sugerują, by nie umieszczać go w publicznych repozytoriach GitHub, jeśli projekt jest open-source. W projektach komercyjnych jest on częścią repozytorium.
Musimy dodać zależności Gradle:
1. Poziom Projektu (Project build.gradle.kts): Definiujemy wersję pluginu Google Services.
// build.gradle.kts (Project)
plugins {
// ...
id("com.google.gms.google-services") version "4.4.0" apply false
}2. Poziom Modułu (App build.gradle.kts): Aplikujemy plugin i dodajemy zależności.
// app/build.gradle.kts (Module)
plugins {
id("com.android.application")
id("org.jetbrains.kotlin.android")
// Aplikujemy plugin Google Services
id("com.google.gms.google-services")
}
dependencies {
// Import Firebase BoM (Bill of Materials)
// To jedyne miejsce, gdzie definiujemy wersję (32.7.0)
implementation(platform("com.google.firebase:firebase-bom:32.7.0"))
// Biblioteki Firebase (BEZ podawania wersji)
// Wersje zostaną pobrane automatycznie z BOM
implementation("com.google.firebase:firebase-firestore-ktx")
implementation("com.google.firebase:firebase-analytics")
}Po dodaniu tych zmian należy wykonać Gradle Sync. Jeśli synchronizacja przebiegnie pomyślnie, aplikacja jest gotowa do komunikacji z chmurą.
Ostatnim krokiem jest utworzenie samej instancji bazy danych w konsoli:
- W menu bocznym konsoli Firebase wybierz Firestore Database.
- Kliknij Create database.
- Wybierz lokalizację serwera (np.
eur3 (europe-west)dla Polski - mniejsze opóźnienia). - W kroku Security Rules wybierz Start in test mode.
Modelowanie danych w Firestore
Firestore jest bazą dokumentową. Oznacza to, że nie definiujemy schematu (Schema) na poziomie bazy danych. Możemy w tej samej kolekcji zapisać dokument posiadający tylko pole name, a obok niego dokument posiadający pola name, age, address.
Mimo tej elastyczności, w aplikacji Androidowej (która jest silnie typowana) dążymy do narzucenia pewnej struktury poprzez klasy DTO (Data Transfer Objects). Model danych w Firestore przypomina system plików na dysku komputera:
- Kolekcja to folder. Może zawierać tylko dokumenty (nie inne kolekcje bezpośrednio).
- Dokument to plik (np. JSON). Zawiera dane oraz ewentualnie linki do podfolderów (Subkolekcji).
Struktura zawsze musi występować naprzemiennie:
Kolekcja -> Dokument -> Kolekcja -> Dokument ...Przykład struktury dla aplikacji E-commerce:
users (kolekcja)
|-- user_abc123 (dokument)
|-- name: "Jan Kowalski"
|-- email: "jan@example.com"
|-- orders (subkolekcja)
|-- order_999 (dokument)
|-- total: 150.00
|-- items: [...]Płytkie zapytania (Shallow Queries): Pobranie dokumentu user_abc123 pobiera tylko jego pola (name, email). Nie pobiera automatycznie danych z subkolekcji orders. Aby pobrać zamówienia, trzeba wykonać osobne zapytanie do subkolekcji. Jest to kluczowa różnica względem relacji w SQL.
Biblioteka Firestore dla Androida posiada wbudowany mechanizm mapowania (POJO mapper), który automatycznie zamienia dokumenty JSON na obiekty Kotlina. Aby działał on poprawnie, musimy spełnić jeden techniczny wymóg: klasa musi posiadać konstruktor bezargumentowy.
W Kotlinie osiągamy to najłatwiej, nadając wszystkim polom w data class wartości domyślne.
// data/remote/model/MovieDto.kt
data class MovieDto(
// 1. Mapowanie ID dokumentu na pole w klasie
@DocumentId
val id: String = "",
// 2. Pola danych (muszą mieć wartości domyślne!)
val title: String = "",
val description: String = "",
// Nazwa pola w bazie musi pasować do nazwy zmiennej
// lub używamy @PropertyName("poster_path")
val posterUrl: String? = null,
val rating: Double = 0.0,
// 3. Obsługa czasu serwerowego
@ServerTimestamp
val createdAt: Date? = null
)Najważniejsze adnotacje:
@DocumentId:@ServerTimestamp:@PropertyName("name"):
W Firestore ID dokumentu jest częścią metadanych, a nie ciałem JSON-a. Ta adnotacja mówi bibliotece: Weź ID tego dokumentu i wpisz go w to pole podczas deserializacji. Dzięki temu nie musimy ręcznie przepisywać ID po pobraniu danych.
Gdy wysyłamy obiekt do bazy, pole to zostanie zamienione na null, a serwer Firestore wstawi w to miejsce swój aktualny czas. Jest to krytyczne dla synchronizacji danych między użytkownikami z różnych stref czasowych lub ze źle ustawionym zegarem w telefonie.
Opcjonalna adnotacja (podobna do @SerializedName z Gsona), jeśli nazwa pola w bazie różni się od nazwy w kodzie (np. first_name vs firstName).
Firestore obsługuje bogatszy zestaw typów niż SQLite:
- Proste: String, Number (Long/Double), Boolean, Null.
- Złożone:
- Map: Zagnieżdżony obiekt JSON (mapuje się na
Map<String, Any>lub inną zagnieżdżoną klasę DTO). - Array: Lista wartości (mapuje się na
List<T>). Uwaga: Tablice w Firestore nie powinny być duże, ponieważ nie można pobrać tylko części tablicy. - Timestamp: Precyzyjny znacznik czasu.
- GeoPoint: Szerokość i długość geograficzna.
Integracja z Czystą Architekturą
W architekturze MVVM zależy nam na tym, aby warstwa UI (ViewModel) otrzymywała dane w postaci strumieni (Flow), nie wiedząc o tym, że pod spodem działa SDK Firebase.
Wyzwanie polega na tym, że biblioteka Firestore została napisana w oparciu o mechanizm Callbacków (interfejsy typu OnSuccessListener, addSnapshotListener), a nie funkcje zawieszające (suspend). Musimy więc zbudować most między tymi technologiami.
Aby zamienić nasłuchiwanie w czasie rzeczywistym na Flow, używamy konstruktora callbackFlow. Tworzy on strumień, który pozostaje otwarty tak długo, jak długo ktoś go obserwuje (collect), i pozwala nam ręcznie emitować wartości wewnątrz callbacka. Poniżej schemat implementacji metody getMoviesStream() w repozytorium:
// data/repository/FirestoreMovieRepository.kt
override fun getMoviesStream(): Flow<List<Movie>> = callbackFlow {
// 1. Referencja do kolekcji
val collection = firestore.collection("movies")
// 2. Rejestracja listenera (To jest API Firebase)
val listenerRegistration = collection.addSnapshotListener { snapshot, error ->
// A. Obsługa błędu
if (error != null) {
close(error) // Zamyka Flow i rzuca wyjątek do kolektora
return@addSnapshotListener
}
// B. Mapowanie danych
if (snapshot != null) {
val movies = snapshot.documents.map { doc ->
// Zamiana JSON na obiekt DTO, a potem na domenę
val dto = doc.toObject(MovieDto::class.java)
// Ważne: toObject może zwrócić null, jeśli dokument jest pusty
dto?.toDomain()
}.filterNotNull()
// C. Emisja do strumienia
trySend(movies)
}
}
// 3. Sprzątanie (Bardzo ważne!)
// Blok awaitClose zawiesza korutynę do momentu, aż Flow zostanie anulowany
// (np. użytkownik zamknie ekran). Wtedy wykonuje się kod w środku.
awaitClose {
listenerRegistration.remove() // Odpinamy listener, by nie wyciekała pamięć
}
}Pułapka awaitClose: Jeśli pominiesz blok awaitClose, funkcja callbackFlow zakończy się natychmiast po zarejestrowaniu listenera, a strumień zostanie zamknięty. awaitClose utrzymuje strumień przy życiu.
Do operacji, które nie wymagają nasłuchiwania w czasie rzeczywistym (np. dodanie produktu, usunięcie, lub jednorazowe pobranie), używamy funkcji zawieszających.
Standardowe API Firebase zwraca obiekt Task<T>. Aby nie używać callbacków addOnSuccessListener, korzystamy z biblioteki pomocniczej kotlinx-coroutines-play-services, która dodaje funkcję rozszerzającą .await().
// data/repository/FirestoreMovieRepository.kt
class FirestoreMovieRepository(...) {
// ZAPIS (Create)
override suspend fun addMovie(movie: Movie) {
val dto = movie.toDto()
// .await() zawiesza korutynę do momentu ukończenia zapisu w chmurze
// Jeśli wystąpi błąd (np. brak sieci + brak cache), rzuci wyjątek.
firestore.collection("movies")
.document(movie.id) // Używamy własnego ID lub .document() dla auto-ID
.set(dto)
.await()
}
// USUWANIE (Delete)
override suspend fun deleteMovie(id: String) {
firestore.collection("movies")
.document(id)
.delete()
.await()
}
// ODCZYT JEDNORAZOWY (One-shot Get)
override suspend fun getMovieDetails(id: String): Movie {
val snapshot = firestore.collection("movies")
.document(id)
.get() // Pobiera stan na ten moment
.await()
return snapshot.toObject(MovieDto::class.java)?.toDomain()
?: throw Exception("Movie not found")
}
}Warto zaznaczyć, że SDK Firestore jest zoptymalizowane.
addSnapshotListenerdomyślnie wywołuje callback na wątku głównym (Main Thread). Jest to bezpieczne, ponieważ Firestore wykonuje operacje sieciowe na własnej puli wątków w tle, a na główny wątek wrzuca tylko gotowe wyniki.- Jeśli jednak mapowanie danych (linia
snapshot.documents.map) jest kosztowne obliczeniowo (np. lista 1000 elementów), warto przenieść emisję na inny dispatcher wewnątrzflowOn(Dispatchers.Default)w ViewModelu lub Repozytorium.
Operacje zapisu i modyfikacji
Firestore oferuje kilka metod zapisu, które różnią się sposobem generowania identyfikatorów oraz zachowaniem w przypadku istniejących danych.
Wszystkie poniższe operacje zwracają obiekt Task<Void>, co oznacza, że w Kotlinie możemy użyć na nich funkcji .await(), aby zawiesić korutynę do momentu potwierdzenia zapisu przez serwer. Biblioteki Firebase są napisane w Javie, gdzie typy generyczne nie obsługują void (pustego zwrotu). Używana jest więc klasa-wrapper java.lang.Void. W Kotlinie funkcja .await() zwraca wtedy wartość null, którą po prostu ignorujemy, traktując całe wywołanie jak funkcję zwracającą Unit. Mamy dwie strategie tworzenia nowych dokumentów:
- Automatyczne ID (
add): - Własne ID (
set):
Gdy nie zależy nam na konkretnym identyfikatorze (np. nowy komentarz, log błędu). Firestore wygeneruje unikalny ciąg 20 znaków.
Gdy identyfikator pochodzi z zewnątrz (np. userId z Firebase Auth, kod EAN produktu, numer PESEL).
// data/repository/FirestoreWriteRepository.kt
// STRATEGIA 1: add() - Firestore generuje ID
suspend fun addComment(content: String) {
val comment = hashMapOf("content" to content)
// Wynikiem jest referencja do nowo utworzonego dokumentu
val newDocRef = firestore.collection("comments").add(comment).await()
println("Utworzono komentarz o ID: ${newDocRef.id}")
}
// STRATEGIA 2: set() - My narzucamy ID
suspend fun createUserProfile(userId: String, name: String) {
val user = UserDto(id = userId, name = name)
// Dokument będzie miał ID takie samo jak userId z Auth
firestore.collection("users")
.document(userId)
.set(user)
.await()
}Przejdźmy do aktualizacji danych, miejsce gdzie najczęściej popełnia się błędy.
set(data)(Nadpisanie):update()(Częściowa edycja):set(..., SetOptions.merge())(Upsert):
Domyślnie metoda set usuwa całą dotychczasową zawartość dokumentu i zastępuje ją nowym obiektem. Jeśli dokument miał 50 pól, a my przekażemy obiekt z 2 polami, pozostałe 48 zostanie skasowanych.
Modyfikuje tylko wskazane pola. Jeśli dokument nie istnieje, operacja zakończy się błędem.
Połączenie Update i Insert. Jeśli dokument istnieje - aktualizuje wskazane pola. Jeśli nie istnieje - tworzy go. Jest to najbezpieczniejsza metoda synchronizacji danych.
// PRZYKŁAD: Zmiana tylko ceny produktu
suspend fun updatePrice(productId: String, newPrice: Double) {
// Sposób A: update() - wymaga, by dokument istniał
try {
firestore.collection("products").document(productId)
.update("price", newPrice)
.await()
} catch (e: Exception) {
// Rzuci błąd, jeśli produkt nie istnieje
}
// Sposób B: Merge (Upsert) - bezpieczniejszy dla synchronizacji
val data = mapOf("price" to newPrice)
firestore.collection("products").document(productId)
.set(data, SetOptions.merge()) // Nie kasuje innych pól!
.await()
}Notacja kropkowa (Dot Notation): Aby zaktualizować pole w zagnieżdżonym obiekcie (Mapie), używamy kropki w nazwie pola. Np. update("address.city", "Wrocław"). Nie przesyłaj całego obiektu address, bo nadpiszesz inne jego pola.
Usuwanie jest proste, ale posiada jedną krytyczną cechę w bazach NoSQL, która jest nieintuicyjna dla osób znających SQL (gdzie działa Cascade Delete).
suspend fun deleteUser(userId: String) {
firestore.collection("users").document(userId)
.delete()
.await()
}Pułapka Subkolekcji: Usunięcie dokumentu w Firestore NIE usuwa zawartych w nim subkolekcji. Jeśli usuniesz dokument users/jan, ale Jan miał subkolekcję users/jan/orders, to zamówienia nadal istnieją w bazie, ale stają się osierocone (nie można ich znaleźć, przeglądając konsolę w zwykły sposób, ale można się do nich odwołać bezpośrednio). Aby usunąć wszystko, trzeba ręcznie pobrać i usunąć każdy dokument z subkolekcji.
Czasami musimy wykonać kilka operacji atomowo (wszystko albo nic).
- WriteBatch: Pozwala wykonać do 500 operacji (set, update, delete) naraz. Jeśli jedna się nie powiedzie (np. brak sieci), żadna nie zostanie wykonana. Nie blokuje to bazy dla innych użytkowników.
- Transaction: Bardziej zaawansowane. Pozwala odczytać wartość, a następnie ją zmienić (np. inkrementacja licznika polubień), gwarantując, że nikt inny nie zmienił jej w międzyczasie.
Zaawansowane zapytania i indeksy
Firestore jest bazą zoptymalizowaną pod kątem szybkości odczytu. Gwarantuje ona, że czas pobierania danych zależy od liczby wyników, a nie od wielkości całej kolekcji. Pobranie 50 filmów z bazy zawierającej 100 dokumentów czas zalezy glownie od liczby zwracanych wynikow, przy poprawnym indeksowaniu.
Aby to osiągnąć, Firestore nakłada na programistów pewne ograniczenia dotyczące konstrukcji zapytań i wymaga indeksowania każdego pola, po którym chcemy wyszukiwać. Zapytania tworzymy poprzez łańcuchowe wywoływanie metod na obiekcie CollectionReference. Każde wywołanie zwraca obiekt Query.
// data/repository/FirestoreQueryExample.kt
fun getSciFiMoviesStream(): Flow<List<Movie>> = callbackFlow {
val query = firestore.collection("movies")
// 1. Filtrowanie (równość)
.whereEqualTo("genre", "Sci-Fi")
// 2. Filtrowanie (zakres)
.whereGreaterThan("rating", 4.0)
// 3. Sortowanie
.orderBy("rating", Query.Direction.DESCENDING)
// 4. Limitowanie wyników
.limit(10)
val listener = query.addSnapshotListener { ... }
awaitClose { listener.remove() }
}W przeciwieństwie do SQL, gdzie klauzula WHERE pozwala na dowolną kombinację warunków, Firestore posiada sztywne reguły:
- Jeden zakres na zapytanie:
- DOBRZE:
whereGreaterThan("age", 18).whereLessThan("age", 30) - ŹLE:
whereGreaterThan("age", 18).whereGreaterThan("income", 5000) - Zgodność sortowania i filtrowania:
- Brak "prawdziwego" OR:
Możesz filtrować zakresem (>, <, >=, <=) tylko po jednym polu w pojedynczym zapytaniu.
Jeśli filtrujesz zakresowo po polu X (np. age > 18), pierwsze sortowanie (orderBy) również musi dotyczyć pola X.
Do niedawna operacja OR nie istniała. Obecnie używamy operatora whereIn (dla tablic) lub Filter.or, ale mają one swoje limity wydajnościowe (maksymalnie 30 klauzul alternatywnych).
Aby zapytania były szybkie, Firestore używa indeksów.
1. Indeksy Jednopolowe (Single-field indexes): Są tworzone automatycznie dla każdego pola w dokumencie. Dzięki temu proste zapytania (whereEqualTo("city", "Warsaw")) działają od razu, bez konfiguracji.
2. Indeksy Złożone (Composite indexes): Są wymagane, gdy zapytanie łączy warunki na wielu polach jednocześnie, np.: Kategoria == "Książki" AND Cena > 50 zł.
Gdy spróbujesz wykonać takie zapytanie bez indeksu, aplikacja wyrzuci błąd, a w Logcat zobaczysz specjalny komunikat:
com.google.firebase.firestore.FirebaseFirestoreException: FAILED_PRECONDITION:
The query requires an index. You can create it here:
https://console.firebase.google.com/v1/r/project/my-app/firestore...Firestore nie obsługuje klasycznego wyszukiwania tekstu (np. znalezienie słowa terminator w długim opisie filmu). Operator whereGreaterThan i startAt pozwalają jedynie na wyszukiwanie prefiksów (słowa zaczynające się na...).
Rozwiązania tego problemu:
- Podejście (Array-contains):
- Podejście Alternatywne:
Podczas zapisywania filmu, tworzymy dodatkowe pole keywords (tablicę słów), np. ["star", "wars", "new", "hope"]. Wyszukiwanie polega na zapytaniu: whereArrayContains("keywords", "hope").
Integracja z zewnętrznym silnikiem wyszukiwania, takim jak Algolia lub Typesense. Dane z Firestore są synchronizowane z silnikiem wyszukiwania (przez Cloud Functions), a aplikacja mobilna pyta silnik o wyniki wyszukiwania, otrzymując ID dokumentów.
Tryb Offline i Synchronizacja
W Rozdziale 13 budowaliśmy obsługę trybu offline ręcznie, tworząc lokalną bazę Room i pisząc logikę synchronizacji w Repozytorium. Firestore oferuje funkcjonalność Offline Persistence wbudowaną bezpośrednio w SDK.
Dla platformy Android (i iOS) tryb ten jest włączony domyślnie. Oznacza to, że każda aplikacja korzystająca z Firestore jest z definicji aplikacją Offline-first.
Gdy aplikacja pobiera dane z chmury, Firestore zapisuje ich kopię w lokalnej, wewnętrznej bazie danych (ukrytej implementacji LevelDB/SQLite) na urządzeniu.
Gdy użytkownik traci zasięg:
- Odczyt: Zapytania
get()oraz listeneryaddSnapshotListenerautomatycznie przełączają się na czytanie z lokalnego cache. Nie trzeba zmieniać kodu repozytorium. - Zapis: Operacje
add/set/updatezapisują zmianę lokalnie i dodają ją do kolejki oczekującej. - Synchronizacja: Gdy urządzenie odzyska połączenie, SDK automatycznie wysyła kolejkę zmian na serwer i pobiera najnowsze aktualizacje.
Jedną z najważniejszych cech Firestore jest tzw. Optimistic UI Update. W klasycznym podejściu REST, gdy użytkownik klika Wyślij wiadomość, aplikacja pokazuje spinner (ładowanie), wysyła żądanie do serwera i dopiero po otrzymaniu HTTP 200 OK wyświetla wiadomość na liście. Przy wolnym internecie trwa to irytująco długo.
W Firestore dzieje się to inaczej:
- Użytkownik klika Wyślij.
- SDK zapisuje wiadomość w lokalnym cache.
- Listener (
onSnapshot) odpala się natychmiast (w ułamku sekundy), emitując nową listę wiadomości zawierającą dodany element. - UI aktualizuje się od razu. Użytkownik ma wrażenie, że aplikacja jest niesamowicie szybka.
- W tle SDK wysyła dane do chmury. Gdy serwer potwierdzi zapis, listener może odpalić się drugi raz (zaktualizować metadane), ale dla użytkownika jest to niewidoczne.
Czasami UI musi wiedzieć, czy dane, które wyświetla, są ostateczne (z serwera), czy tymczasowe (z cache, jeszcze niewysłane). Służą do tego metadane migawki (SnapshotMetadata). Możemy to wykorzystać np. do wyszarzenia wiadomości na czacie, która jeszcze nie dotarła do serwera.
// data/repository/FirestoreChatRepository.kt
collection.addSnapshotListener { snapshot, e ->
if (snapshot != null) {
// Sprawdzenie źródła danych
val source = if (snapshot.metadata.isFromCache) {
"Lokalny Cache"
} else {
"Serwer"
}
Log.d("Firestore", "Dane pochodzą z: $source")
val messages = snapshot.documents.map { doc ->
val message = doc.toObject(MessageDto::class.java)
// hasPendingWrites = true oznacza, że ten konkretny dokument
// został zmodyfikowany lokalnie, ale nie dotarł jeszcze do chmury.
message.isSending = doc.metadata.hasPendingWrites()
message
}
trySend(messages)
}
}Cache Firestore nie rośnie w nieskończoność. Domyślnie limit wynosi 100 MB. Gdy zostanie przekroczony, SDK usuwa najstarsze, nieużywane dokumenty (algorytm LRU - Least Recently Used). Możemy skonfigurować ten limit przy starcie aplikacji:
// Konfiguracja w Module DI
val settings = FirebaseFirestoreSettings.Builder()
.setCacheSizeBytes(FirebaseFirestoreSettings.CACHE_SIZE_UNLIMITED) // Lub np. 50 MB
.setPersistenceEnabled(true) // Domyślnie true, można wyłączyć
.build()
firestore.firestoreSettings = settingsMimo że tryb offline działa świetnie, ma swoje granice:
- Wyszukiwanie: Nie można wykonywać zapytań offline, które wymagają indeksów, których jeszcze nie ma w cache (np. filtrowanie dużej kolekcji, której użytkownik nigdy wcześniej nie pobrał).
- Transakcje: Operacje transakcyjne (
runTransaction) nie działają offline, ponieważ wymagają one połączenia z serwerem w celu sprawdzenia spójności danych. W trybie offline należy używaćWriteBatch. - Reguły bezpieczeństwa: Walidacja uprawnień (Security Rules) odbywa się na serwerze. Jeśli użytkownik spróbuje wykonać niedozwoloną operację offline, dowie się o błędzie dopiero po odzyskaniu połączenia.
Przykład: Współdzielona Lista Zakupów (ToDo)
Jako podsumowanie rozdziału stworzymy kompletną mini-aplikację: listę zadań, która synchronizuje się w czasie rzeczywistym między wieloma urządzeniami. Wykorzystamy wiedzę o callbackFlow, mapowaniu DTO oraz operacjach zapisu.
Aplikacja będzie pozwalała na:
- Wyświetlanie listy zadań (Real-time).
- Dodawanie nowego zadania.
- Oznaczanie zadania jako wykonane (Update).
- Usuwanie zadania (Delete).
Rozdzielamy model domenowy (używany w UI) od modelu DTO (używanego do serializacji JSON w Firestore).
// domain/model/Task.kt
package com.example.todoapp.domain.model
data class Task(
val id: String,
val content: String,
val isDone: Boolean
)
// data/remote/model/TaskDto.kt
package com.example.todoapp.data.remote.model
import com.google.firebase.firestore.DocumentId
import com.google.firebase.firestore.ServerTimestamp
import java.util.Date
// Pamiętaj: Wartości domyślne są wymagane dla pustego konstruktora!
data class TaskDto(
@DocumentId val id: String = "",
val content: String = "",
@field:JvmField val isDone: Boolean = false, // @field pomaga w mapowaniu booleanów
@ServerTimestamp val createdAt: Date? = null
)
// Extension function do mapowania
fun TaskDto.toDomain() = Task(
id = this.id,
content = this.content,
isDone = this.isDone
)Przejdźmy do Repozytorium które implementuje logikę nasłuchiwania zmian.
// data/repository/TaskRepository.kt
package com.example.todoapp.data.repository
class TaskRepository @Inject constructor(
private val firestore: FirebaseFirestore
) {
private val collection = firestore.collection("tasks")
// 1. ODCZYT (Real-time)
fun getTasksStream(): Flow<List<Task>> = callbackFlow {
// Sortujemy: najpierw niewykonane, potem wg daty utworzenia
val query = collection
.orderBy("isDone", Query.Direction.ASCENDING)
.orderBy("createdAt", Query.Direction.DESCENDING)
val listener = query.addSnapshotListener { snapshot, error ->
if (error != null) {
close(error)
return@addSnapshotListener
}
if (snapshot != null) {
val tasks = snapshot.documents.mapNotNull { doc ->
doc.toObject(TaskDto::class.java)?.toDomain()
}
trySend(tasks)
}
}
awaitClose { listener.remove() }
}
// 2. ZAPIS (Create)
suspend fun addTask(content: String) {
val task = TaskDto(
content = content,
isDone = false
// createdAt ustawi serwer dzieki @ServerTimestamp
)
collection.add(task).await()
}
// 3. AKTUALIZACJA (Update)
suspend fun toggleTask(taskId: String, isDone: Boolean) {
// Aktualizujemy tylko jedno pole
collection.document(taskId).update("isDone", isDone).await()
}
// 4. USUWANIE (Delete)
suspend fun deleteTask(taskId: String) {
collection.document(taskId).delete().await()
}
}// di/FirebaseModule.kt
package com.example.todoapp.di
@Module
@InstallIn(SingletonComponent::class)
object FirebaseModule {
@Provides
@Singleton
fun provideFirestore(): FirebaseFirestore {
// Używamy wersji KTX
return Firebase.firestore
}
}ViewModel jest prosty, ponieważ callbackFlow w repozytorium wykonuje całą ciężką pracę związaną z aktualizacją stanu.
// presentation/TasksViewModel.kt
package com.example.todoapp.presentation
@HiltViewModel
class TasksViewModel @Inject constructor(
private val repository: TaskRepository
) : ViewModel() {
// Strumień automatycznie aktualizuje UI, gdy zmieni się coś w chmurze
val tasks: StateFlow<List<Task>> = repository.getTasksStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = emptyList()
)
fun onAddTask(content: String) {
if (content.isBlank()) return
viewModelScope.launch {
repository.addTask(content)
}
}
fun onToggleTask(task: Task) {
viewModelScope.launch {
repository.toggleTask(task.id, !task.isDone)
}
}
fun onDeleteTask(task: Task) {
viewModelScope.launch {
repository.deleteTask(task.id)
}
}
}Interfejs reaguje na zmiany w StateFlow. Dzięki Firestore, jeśli uruchomisz tę aplikację na dwóch telefonach (lub telefonie i emulatorze), kliknięcie Checkboxa na jednym urządzeniu natychmiast odznaczy go na drugim.
// presentation/TasksScreen.kt
@Composable
fun TasksScreen(
viewModel: TasksViewModel = hiltViewModel()
) {
val tasks by viewModel.tasks.collectAsState()
var newTaskText by remember { mutableStateOf("") }
Column(modifier = Modifier.fillMaxSize().padding(16.dp)) {
// Sekcja dodawania
Row(verticalAlignment = Alignment.CenterVertically) {
TextField(
value = newTaskText,
onValueChange = { newTaskText = it },
modifier = Modifier.weight(1f),
placeholder = { Text("Co trzeba kupić?") }
)
Spacer(modifier = Modifier.width(8.dp))
Button(onClick = {
viewModel.onAddTask(newTaskText)
newTaskText = "" // Czyścimy pole po dodaniu
}) {
Text("Dodaj")
}
}
Spacer(modifier = Modifier.height(16.dp))
// Lista zadań
LazyColumn {
items(tasks, key = { it.id }) { task ->
TaskItem(
task = task,
onToggle = { viewModel.onToggleTask(task) },
onDelete = { viewModel.onDeleteTask(task) }
)
}
}
}
}
@Composable
fun TaskItem(
task: Task,
onToggle: () -> Unit,
onDelete: () -> Unit
) {
Row(
modifier = Modifier
.fillMaxWidth()
.padding(vertical = 8.dp),
verticalAlignment = Alignment.CenterVertically
) {
Checkbox(
checked = task.isDone,
onCheckedChange = { onToggle() }
)
Text(
text = task.content,
modifier = Modifier.weight(1f)
)
IconButton(onClick = onDelete) {
Icon(Icons.Default.Delete, contentDescription = "Usuń")
}
}
}